
Interpretable Machine Learning-Based Influence Factor Identification for 3D Printing Process–Structure Linkages


 , and
, and
Abstract
1. Introduction
2. Research Data and Methodology
2.1. Description of the Dataset Used
2.2. Support Vector Regression
2.3. Integration Method Based on Regression Tree
2.4. Feature Importance
2.5. Shapley Additive Explanation
2.6. Models Performance Measurements
3. Results and Discussion
3.1. Model Fitness Analysis Based on Machine Learning Prediction
3.1.1. Determination of Model Parameters
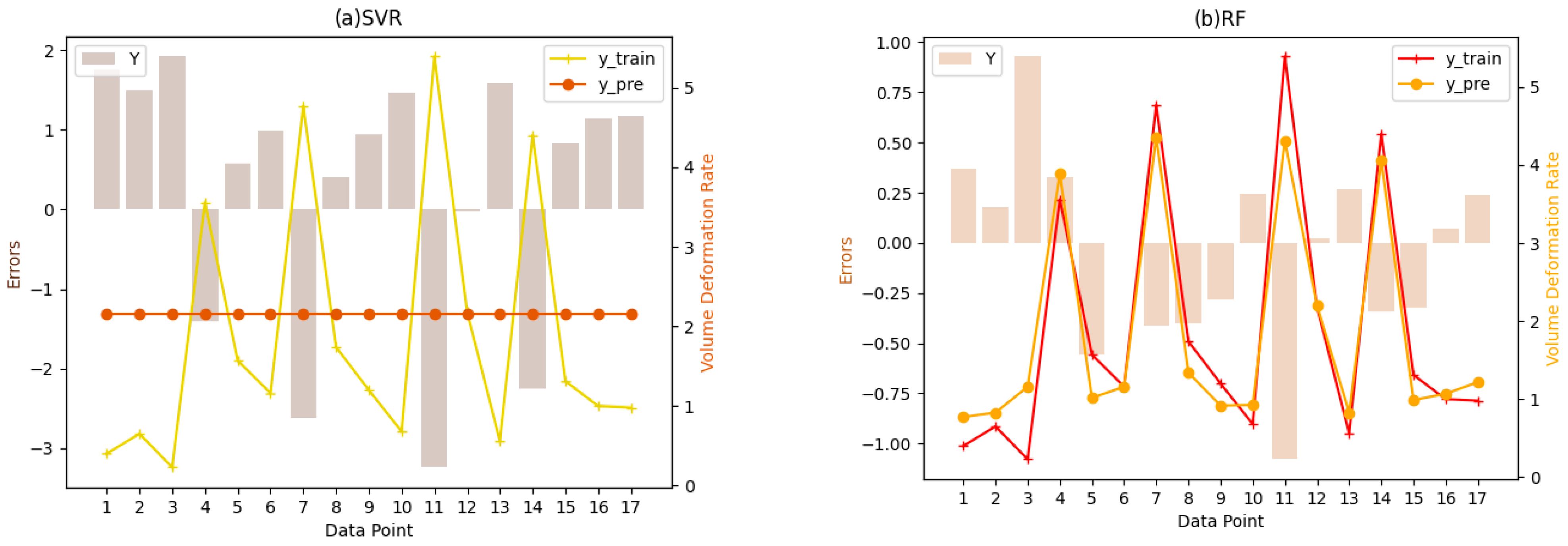
3.1.2. The Fitting Results of Four Machine Learning Methods
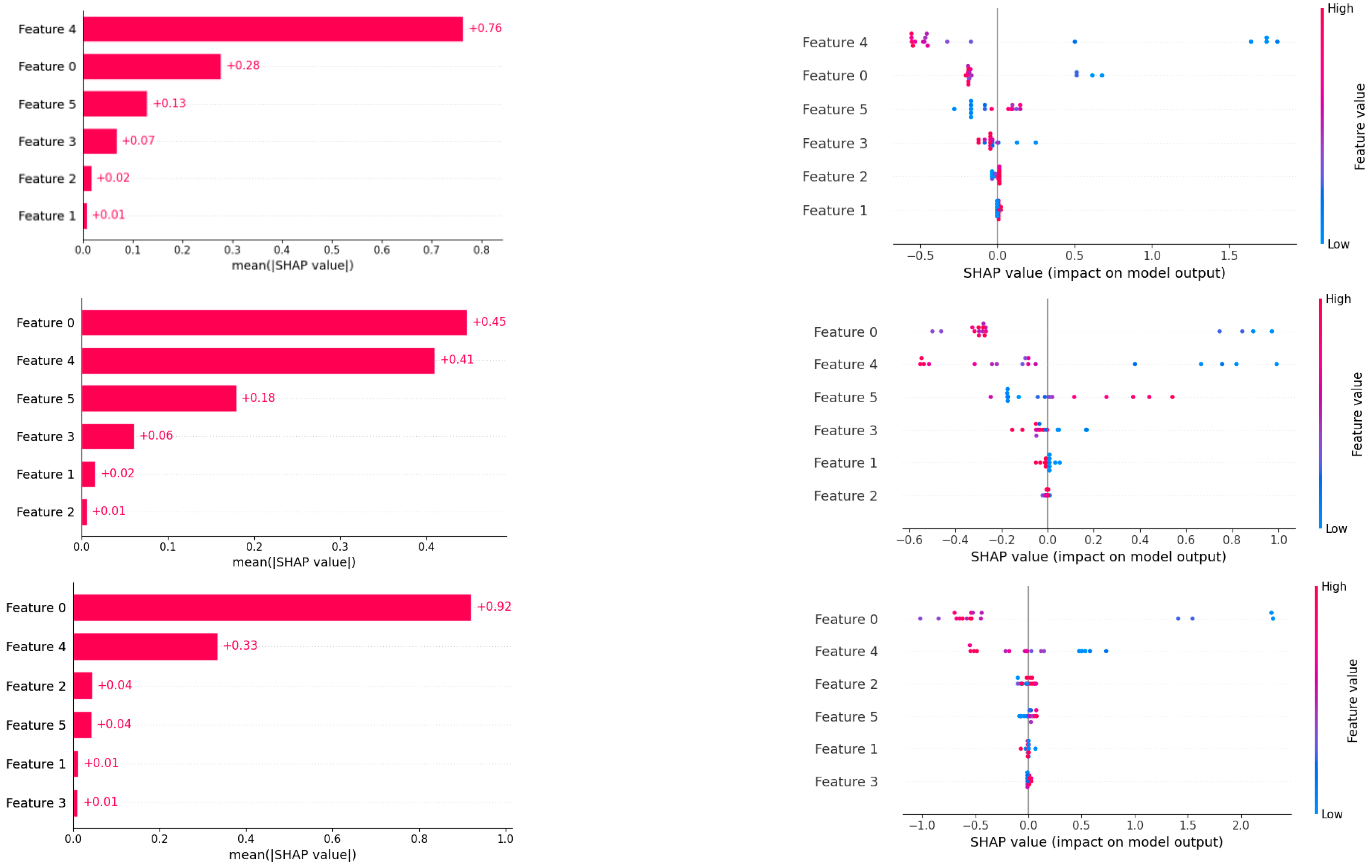
3.2. Print Factor Recognition Based on Interpretative Machine Learning Method
4. Conclusions
- Through correlation coefficient analysis, we found that among the input variables, the PLA content and elastic modulus showed the highest correlation with warpage, with a correlation coefficient of 80%. There was also a high degree of multicollinearity between PLA content, elastic modulus, and warpage. On the other hand, there was a weak correlation between ADR 4468 crosslinking agent, twin-screw blending, extrusion swell ratio, and both warpage and the other three input variables.
- In terms of model selection, we employed three machine learning algorithms, namely, gradient boosting decision trees (GBDTs), random forest (RF), and support vector regression (SVR), to predict “spline warpage,” achieving satisfactory results. It is worth noting that these results were obtained through debugging using a small dataset, yet these models demonstrated good generalization capabilities and can be applied to larger-scale datasets.
- Additionally, we introduced the SHAP (Shapley additive explanations) interpretable machine learning framework to explain the predictions of the models. Through SHAP value analysis, we discovered that fracture elongation, fracture strength, elastic modulus, and impact strength have significant impacts on 3D printing outcomes, with the influence decreasing in that order. This conclusion is consistent with practical experience and aligns with our preliminary finding that chemical properties affect physical features, which, in turn, determine printing outcomes.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Meredig, B.; Agrawal, A.; Kirklin, S.; Saal, J.E.; Doak, J.; Thompson, A.; Zhang, K.; Choudhary, A.; Wolverton, C. Combinatorial screening for new materials in unconstrained composition space with machine learning. Phys. Rev. B 2014, 89, 094104. [Google Scholar] [CrossRef]
- Hanakata, P.Z.; Cubuk, E.D.; Campbell, D.K.; Park, H.S. Accelerated search and design of stretchable graphene kirigami using machine learning. Phys. Rev. Lett. 2018, 121, 255304. [Google Scholar] [CrossRef] [PubMed]
- Ward, L.; Agrawal, A.; Choudhary, A.; Wolverton, C. A general-purpose machine learning framework for predicting properties of inorganic materials. npj Comput. Mater. 2016, 2, 16028. [Google Scholar] [CrossRef]
- Compton, B.G.; Lewis, J.A. 3D-printing of lightweight cellular composites. Adv. Mater. 2014, 26, 5930–5935. [Google Scholar] [CrossRef] [PubMed]
- Aoyagi, K.; Wang, H.; Sudo, H.; Chiba, A. Simple Method to Construct Process Maps for Additive Manufacturing Using a Support Vector Machine. Addit. Manuf. 2019, 27, 353–362. [Google Scholar] [CrossRef]
- Menon, A.; Póczos, B.; Feinberg, A.W.; Washburn, N.R. Optimization of Silicone 3D Printing with Hierarchical Machine Learning. 3D Print. Addit. Manuf. 2019, 6, 181–189. [Google Scholar] [CrossRef]
- He, H.; Yang, Y.; Pan, Y. Machine Learning for Continuous Liquid Interface Production: Printing Speed Modelling. J. Manuf. Syst. 2019, 50, 236–246. [Google Scholar] [CrossRef]
- Stavroulakis, P.; Chen, S.; Delorme, C.; Bointon, P.; Tzimiropoulos, G.; Leach, R. Rapid Tracking of Extrinsic Projector Parameters in Fringe Projection Using Machine Learning. Opt. Lasers Eng. 2019, 114, 7–14. [Google Scholar] [CrossRef]
- Baturynska, I.; Semeniuta, O.; Martinsen, K. Optimization of Process Parameters for Powder Bed Fusion Additive Manufacturing by Combination of Machine Learning and Finite Element Method: A Conceptual Framework. In Procedia CIRP; Elsevier B.V.: Heidelberg, Germany, 2018; pp. 227–232. [Google Scholar] [CrossRef]
- Francis, J.; Bian, L. Deep Learning for Distortion Prediction in Laser-Based Additive Manufacturing Using Big Data. Manuf. Lett. 2019, 20, 10–14. [Google Scholar] [CrossRef]
- Khanzadeh, M.; Rao, P.; Jafari-Marandi, R.; Smith, B.K.; Tschopp, M.A.; Bian, L. Quantifying Geometric Accuracy with Unsupervised Machine Learning: Using Self-Organizing Map on Fused Filament Fabrication Additive Manufacturing Parts. J. Manuf. Sci. Eng. 2018, 140, 301011. [Google Scholar] [CrossRef]
- Zhu, Z.; Anwer, N.; Huang, Q.; Mathieu, L. Machine Learning in Tolerancing for Additive Manufacturing. CIRP Ann. 2018, 67, 157–160. [Google Scholar] [CrossRef]
- Tootooni, M.S.; Dsouza, A.; Donovan, R.; Rao, P.K.; Kong, Z.; Borgesen, P. Classifying the Dimensional Variation in Additive Manufactured Parts from Laser-Scanned Three-Dimensional Point Cloud Data Using Machine Learning Approaches. J. Manuf. Sci. Eng. 2017, 139, 091005. [Google Scholar] [CrossRef]
- Scime, L.; Beuth, J. Using Machine Learning to Identify in situ Melt Pool Signatures Indicative of Flaw Formation in a Laser Powder Bed Fusion Additive Manufacturing Process. Addit. Manuf. 2019, 25, 151–165. [Google Scholar] [CrossRef]
- Caggiano, A.; Zhang, J.; Alfieri, V.; Caiazzo, F.; Gao, R.; Teti, R. Machine Learning-based Image Processing for On-Line Defect Recognition in Additive Manufacturing. CIRP Ann. 2019, 68, 451–454. [Google Scholar] [CrossRef]
- Zhang, B.; Liu, S.; Shin, Y.C. In-Process Monitoring of Porosity During Laser Additive Manufacturing Process. Addit. Manuf. 2019, 28, 497–505. [Google Scholar] [CrossRef]
- Gu, G.X.; Chen, C.-T.; Richmond, D.J.; Buehler, M.J. Bioinspired Hierarchical Composite Design Using Machine Learning: Simulation, Additive Manufacturing, and Experiment. Mater. Horiz. 2018, 5, 939–945. [Google Scholar] [CrossRef]
- Hamel, C.M.; Roach, D.J.; Long, K.N.; Demoly, F.; Dunn, M.L.; Qi, H.J. MachineLearning Based Design of Active Composite Structures for 4D Printing. Smart Mater. Struct. 2019, 28, 065005. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Z.; Shi, J.; Wu, D. Prediction of Surface Roughness in Extrusion-Based Additive Manufacturing with Machine Learning. Robot. Comput. Integr. Manuf. 2019, 57, 488–495. [Google Scholar] [CrossRef]
- Jiang, J.; Hu, G.; Li, X.; Xu, X.; Zheng, P.; Stringer, J. Analysis and Prediction of Printable Bridge Length in Fused Deposition Modelling Based on Back Propagation Neural Network. Virtual Phys. Prototyp. 2019, 14, 253–266. [Google Scholar] [CrossRef]
- Yao, X.; Moon, S.K.; Bi, G. A hybrid machine learning approach for additive manufacturing design feature recommendation. Rapid Prototyp. J. 2017, 23, 983–997. [Google Scholar] [CrossRef]
- Gu, G.X.; Chen, C.T.; Buehler, M.J. De novo composite design based on machine learning algorithm. Extrem. Mech. Lett. 2018, 18, 19–28. [Google Scholar] [CrossRef]
- Jin, Z.; Zhang, Z.; Shao, X.; Gu, G.X. Monitoring Anomalies in 3D Bioprinting with Deep Neural Networks. ACS Biomater. Sci. Eng. 2021, 9, 3945–3952. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Dong, J.; Hu, D.; Yan, Y.; Peng, L.; Zhang, P.; Niu, Y.; Duan, X. Interpretability machine learning based urban O3 driver mining. J. Environ. Sci. 2023, 44, 3660–3668. [Google Scholar] [CrossRef]
- Liao, B.; Wang, Z.; Li, M. Prediction and Characteristic Analysis Method of Football players’ worth based on XGBoost and SHAP Model. J. Comput. Sci. 2019, 49, 195–204. [Google Scholar]
- Mao, S.; Zhou, J.; Zhang, R. Probability Theory and Mathematical Statistics, 4th ed.; China Statistics Press: Beijing, China, 2020. [Google Scholar]
- Hameed, M.M.; AlOmar, M.K.; Baniya, W.J.; AlSaadi, M.A. Prediction of high-strength concrete: High-order response surface methodology modeling approach. Eng. Comput. 2021, 38, 1655–1668. [Google Scholar] [CrossRef]
- Naderpour, H.; Rafiean, A.H.; Fakharian, P. Compressive strength prediction of environmentally friendly concrete using artificial neural networks. J. Build. Eng. 2018, 16, 213–219. [Google Scholar] [CrossRef]
- Xiao, Z.; Chen, K.; Chen, X.; Chen, Y. Inflation factors influencing recognition—And inspection based on machine learning method. Stat. Res. 2022, 33, 132–147. [Google Scholar]
- Oza, N.C. Online Bagging and Boosting. In Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics, Waikoloa, HI, USA, 12 October 2005; pp. 2340–2345. [Google Scholar] [CrossRef]
- Wang, G.W.; Zhang, C.X.; Guo, G. Investigating the Effect of Randomly Selected Feature Subsets on Bagging and Boosting. Commun. Stat.-Simul. Comput. 2015, 44, 636–646. [Google Scholar] [CrossRef]
- Kaloop, M.R.; Kumar, D.; Samui, P.; Hu, J.W.; Kim, D. Compressive strength prediction of high-performance concrete using gradient tree boosting machine—ScienceDirect. Constr. Build. Mater. 2023, 264, 120198. [Google Scholar] [CrossRef]
- Huang, J.; Sun, Y.; Zhang, J. Reduction of computational error by optimizing SVR kernel coefficients to simulate concrete compressive strength through the use of a human learning optimization algorithm. Eng. Comput. 2021, 38, 3151–3168. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. Int. Sci. Eng. J. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Baykasoglu, A.; Oeztas, A.; Oezbay, E. Prediction and multi-objective optimization of high-strength concrete parameters via soft computing approaches. Expert. Syst. Appl. 2009, 36, 6145–6155. [Google Scholar] [CrossRef]
- Qin, S.; Wang, K.; Ma, X.; Wang, W.; Li, M. Ensemble Learning-Based Wind Turbine Fault Prediction Method with Adaptive Feature Selection. In Proceedings of the Data Science: Third International Conference of Pioneering Computer Scientists, Engineers and Educators, ICPCSEE 2017, Changsha, China, 22–24 September 2017. [Google Scholar] [CrossRef]
- Hey, J.D.; Lambert, P.J. Relative Deprivation and the Gini Coefficient: Comment. Q. J. Econ. 1980, 95, 567–573. [Google Scholar] [CrossRef]
- Aas, K.; Jullum, M.; Løland, A. Explaining Individual Predictions when Features are Dependent: More Accurate Approximations to Shapley Values. Artif. Intell. 2021, 298, 103502. [Google Scholar] [CrossRef]
- Anyaoha, U.; Zaji, A.; Liu, Z. Soft computing in estimating the compressive strength for high-performance concrete via concrete composition appraisal. Constr. Build. Mater. 2020, 257, 119472. [Google Scholar] [CrossRef]
- Alabdullah, A.A.; Iqbal, M.; Zahid, M.; Khan, K.; Amin, M.N.; Jalal, F.E. Prediction of rapid chloride penetration resistance of metakaolin based high strength concrete using light GBM and XGBoost models by incorporating SHAP analysis. Constr. Build. Mater. 2022, 345, 128296. [Google Scholar] [CrossRef]
- Farooq, F.; Nasir Amin, M.; Khan, K.; Rehan Sadiq, M.; Javed, M.F.; Aslam, F.; Alyousef, R. A Comparative Study of Random Forest and Genetic Engineering Programming for the Prediction of Compressive Strength of High Strength Concrete (HSC). Appl. Sci. 2020, 10, 7330. [Google Scholar] [CrossRef]
- Kuenneth, C.; Rajan, A.C.; Tran, H.; Chen, L.; Kim, C.; Ramprasad, R. Polymer informatics with multi-task learning. Patterns 2021, 2, 100238. [Google Scholar] [CrossRef]
- Kim, C.; Batra, R.; Chen, L.; Tran, H.; Ramprasad, R. Polymer design using genetic algorithm and machine learning. Comput. Mater. Sci. 2021, 186, 110067. [Google Scholar] [CrossRef]
- Mannodi-Kanakkithodi, A.; Pilania, G.; Ramprasad, R. Critical assessment of regression-based machine learning methods for polymer dielectrics. Comput. Mater. Sci. 2016, 125, 123–135. [Google Scholar] [CrossRef]
- Safwan, A.; Maysa, A.; Ala, H. Artificial neural network modeling to evaluate polyvinylchloride composites’ properties. Comput. Mater. Sci. 2018, 153, 1–9. [Google Scholar] [CrossRef]
- Ekanayake, I.U.; Meddage, D.P.; Rathnayake, U. A novel approach to explain the black-box nature of machine learning in compressive strength predictions of concrete using Shapley additive explanations (SHAP). Case Stud. Constr. Mater. 2022, 16, e01059. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PLA (100%) | Chain Extender ADR4468 (100%) | Twin-Screw Extrusion Experimental Conditions | Die Swell Ratio (r/r0) (100%) | Elastic Modulus (GPa) | Impact Strength (kJ/m2) | Warping (100%) | |
|---|---|---|---|---|---|---|---|
| Count | 23 | 23 | 23 | 23 | 23 | 23 | 23 |
| Mean | 0.652 | 0.002608696 | 3.695652174 | 1.689130435 | 1584.827391 | 5.11821739 | 1.8786957 |
| Std | 0.279 | 0.00255377 | 1.329209697 | 0.512559647 | 654.5020297 | 1.68434678 | 1.9694007 |
| Min | 0 | 0 | 1 | 1 | 392.8 | 3.334 | 0.23 |
| 0.25 | 0.5 | 0 | 2.5 | 1.275 | 1110.065 | 3.858 | 0.61 |
| 0.5 | 0.7 | 0.005 | 4 | 1.8 | 1657 | 4.477 | 1.16 |
| 0.75 | 0.85 | 0.005 | 5 | 2 | 2015.395 | 6.1065 | 1.96 |
| Max | 1 | 0.005 | 5 | 3.3 | 2708.84 | 9.94 | 7.8 |
| Assessment Criteria | Standard Range |
|---|---|
| , : observed data, : predicted data, and is the mean | 0 to 1 |
| , : observed data, : predicted data | 0 to 1 |
| , : observed data, : predicted data and is the number of observations | 0 is the best value |
| , : observed data, : predicted data, and is the number of observations | 0 is the best value |
| Model Name | Parameter Configuration |
|---|---|
| SVR | C = 4.9284, Kernel = RBF |
| Random Forest | max_depth = 3, max_features = 5, n_estimators = 422 |
| GBDT | max_depth = 3, max_features = 4, n_estimators = 18 |
| XGBoost | max_depth = 2, n_estimators = 18, reg_lambda = 1.4423 |
| SVR | RF | GBDT | XGB | |
|---|---|---|---|---|
| 0.8096 | 0.8498 | 0.9369 | 0.9794 | |
| 0.8179 | 0.8509 | 0.9377 | 0.9794 | |
| 0.3367 | 0.2364 | 0.0556 | 0.2742 | |
| 0.2026 | 0.1038 | 0.0043 | 0.1919 |
| RF | GBDT | XGB | |
|---|---|---|---|
| PLA | 0.212644311 | 0.328358355 | 0.5503053 |
| ADR 4468 chain extender | 0.00365122 | 0.002253861 | 0.010976699 |
| Modulus of elasticity | 0.002183382 | 0.002425572 | 0.030449962 |
| Breaking strength | 0.056911609 | 0.023243075 | 0.015605606 |
| Elongation at break | 0.631832284 | 0.393985351 | 0.37159628 |
| Impact strength | 0.092777195 | 0.249733786 | 0.021066085 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Chen, Z.; Xu, J.; Zheng, Y.; Su, W.; Tian, M.; Li, G. Interpretable Machine Learning-Based Influence Factor Identification for 3D Printing Process–Structure Linkages. Polymers 2024, 16, 2680. https://doi.org/10.3390/polym16182680
Liu F, Chen Z, Xu J, Zheng Y, Su W, Tian M, Li G. Interpretable Machine Learning-Based Influence Factor Identification for 3D Printing Process–Structure Linkages. Polymers. 2024; 16(18):2680. https://doi.org/10.3390/polym16182680
Chicago/Turabian StyleLiu, Fuguo, Ziru Chen, Jun Xu, Yanyan Zheng, Wenyi Su, Maozai Tian, and Guodong Li. 2024. "Interpretable Machine Learning-Based Influence Factor Identification for 3D Printing Process–Structure Linkages" Polymers 16, no. 18: 2680. https://doi.org/10.3390/polym16182680
APA StyleLiu, F., Chen, Z., Xu, J., Zheng, Y., Su, W., Tian, M., & Li, G. (2024). Interpretable Machine Learning-Based Influence Factor Identification for 3D Printing Process–Structure Linkages. Polymers, 16(18), 2680. https://doi.org/10.3390/polym16182680