To further analyze the system performance of the male and female litchi flower detection model after feature distillation and its transplantation to the FPGA platform, this study combined YOLO-MPFD multi-teacher feature distillation with various improvement strategies to conduct experiments and analyze data results based on different test platforms such as server, PC, and FPGA, and the configuration environment of each test platform is presented in
Table 2.
F1 measure, mean average precision (m
AP), and Recall are used as the evaluation metrics of model detection accuracy, as shown in Equations (13)–(16). Frames per second (FPS) is used as the evaluation metric of the model detection speed.
where
P denotes the precision,
R the recall,
the number of true-positive samples,
the number of false-positive samples, and
the number of false-negative samples.
5.1. Analysis of Model Test Results
To analyze the performance of the MPFD feature-distillation model, first, training of 150 epochs is performed for YOLOv4 and YOLOv5-l in turn, and the trained model is used as the teacher model in the feature distillation process. Based on the same training set and testing environment, the performances of the undistilled YOLOv4-Tiny and the model after MPFD feature distillation are tested with the following parameters: an input image size of 640 × 640, a training process with reverse gradient, and a validation process without reverse gradient; each model was trained for 150 epochs. In order to compare performance more fairly with respect to algorithm improvement, the test set in this paper is changeless. In the training process, the repeat holdout cross-validation method is used. For each training, the data in the training set are randomly divided into an 80% training set and a 20% validation set. This process repeats five times, the precision, Recall and F1 values of each training are recorded, and the average of the five times is collated as the evaluation metric. In this case, the trained YOLOv4-Tiny model is used as a pre-trained model in the feature-distillation training process. The YOLOv4 standard loss function (Equation (
3)) is used as the training set and test performance metric for the YOLOv4-Tiny model and the validation metric for the distillation model. The proposed distillation loss (Equation (
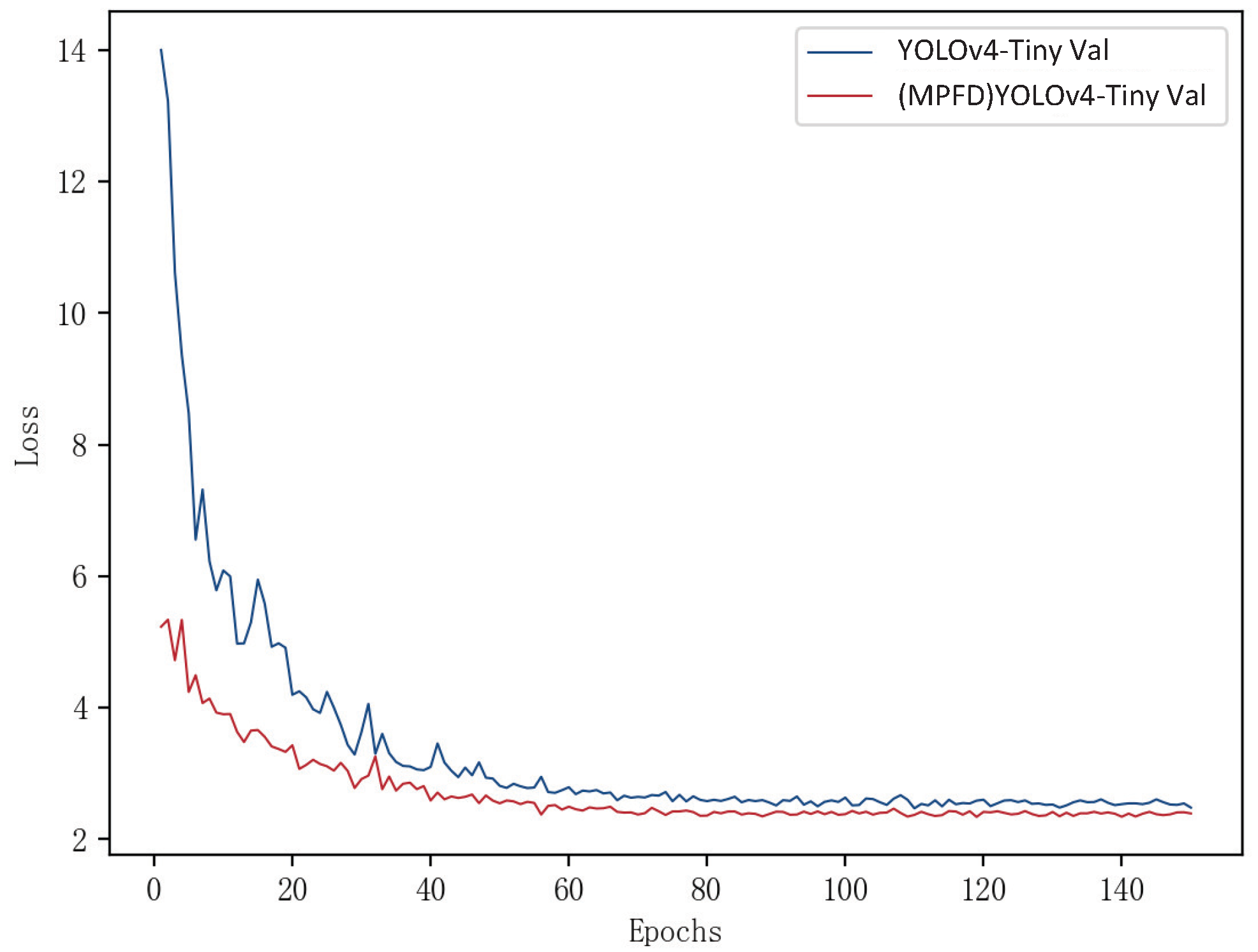
4)) is used as a training metric for the distillation model MPFD YOLOv4-Tiny, and the training process is performed on the server. The variation curves of the model loss values after YOLOv4-Tiny and distillation are shown in
Figure 8, and the model results are compared in
Table 3.
The change in the loss function of the neural network model during the training process can reflect the performance of the completed training model to some extent. Because the distilled model uses the YOLOv4-Tiny model as the pre-trained student model, the validation set loss value in the pre-training period of the undistilled YOLOv4-Tiny model is higher than that of the distilled model, and the overall fluctuation is more remarkable. However, the convergence speed is faster, and the validation loss value of the distilled model is lower than that of the undistilled YOLOv4-Tiny model. The overall loss value is lower, and the fit is better, which proves that MPFD feature distillation can improve the training effect of the model. Finally, the validation loss value of the undistilled student model is stable at approximately 2.8, and the validation loss value of the distilled model is stable at approximately 2.5 with only slight oscillation, which indicates the end of model fitting and proves that MPFD feature distillation reduces the model training loss value.
As presented in
Table 3, the student model improved in all evaluation metrics of model precision after MPFD feature distillation. Among them, the YOLOv4 and YOLOv5-l teacher models have similar detection precision with m
AP values of 94.24% and 94.49%, respectively, with only a 0.25% difference between them. In contrast, the m
AP value of the undistilled YOLOv4-Tiny model is only 89.79%. However, the sizes of the two teacher models, YOLOv4 and YOLOv5-l, are 244.97 and 178.94 MB, respectively, which are 10.84 and 7.92 times larger than that of the student model, YOLOv4-Tiny (22.60 MB), respectively, and neither of them is suitable for deployment to low-power embedded platforms. The m
AP value of the MPFD YOLOv4-Tiny model after feature distillation reaches 94.21%, which is 4.41% higher than that of the undistilled YOLOv4-Tiny model and is very close to the m
AP value of the teacher model YOLOv4, and the Recall and
F1 values are 80.90% and 87.36%, respectively, which are 7.05% and 3.35% higher than those of the undistilled YOLOv4-Tiny. Therefore, MPFD feature distillation can improve the detection index of the student model without changing the model size, making it close to or better than the teacher model performance.
The Precision–Recall (PR) curve reveals the relation between precision and recall, and the larger the area it covers, the better the detection result is. In order to evaluate the classification effect of the distilled model, the
PR curve and
AP are used in this paper. The
PR curves of the distilled model are shown in
Figure 9, with
P representing Precision and
R representing Recall, and the confidence interval is 0.5. The
AP values of litchi male and female flowers can be obtained by calculating the area of the shaded part of the
PR curve. Since five cross-validations were performed, the
AP values of litchi male and female flowers after each training are shown in the figure and averaged separately. The
AP values of litchi male and female flowers were 92.22% and 96.20%; the change trend of the two
PR curves is relatively flat, indicating that the two types of object detection are balanced. Therefore, the detection results meet the requirements of litchi flower male and female detection.
5.2. Ablation Study
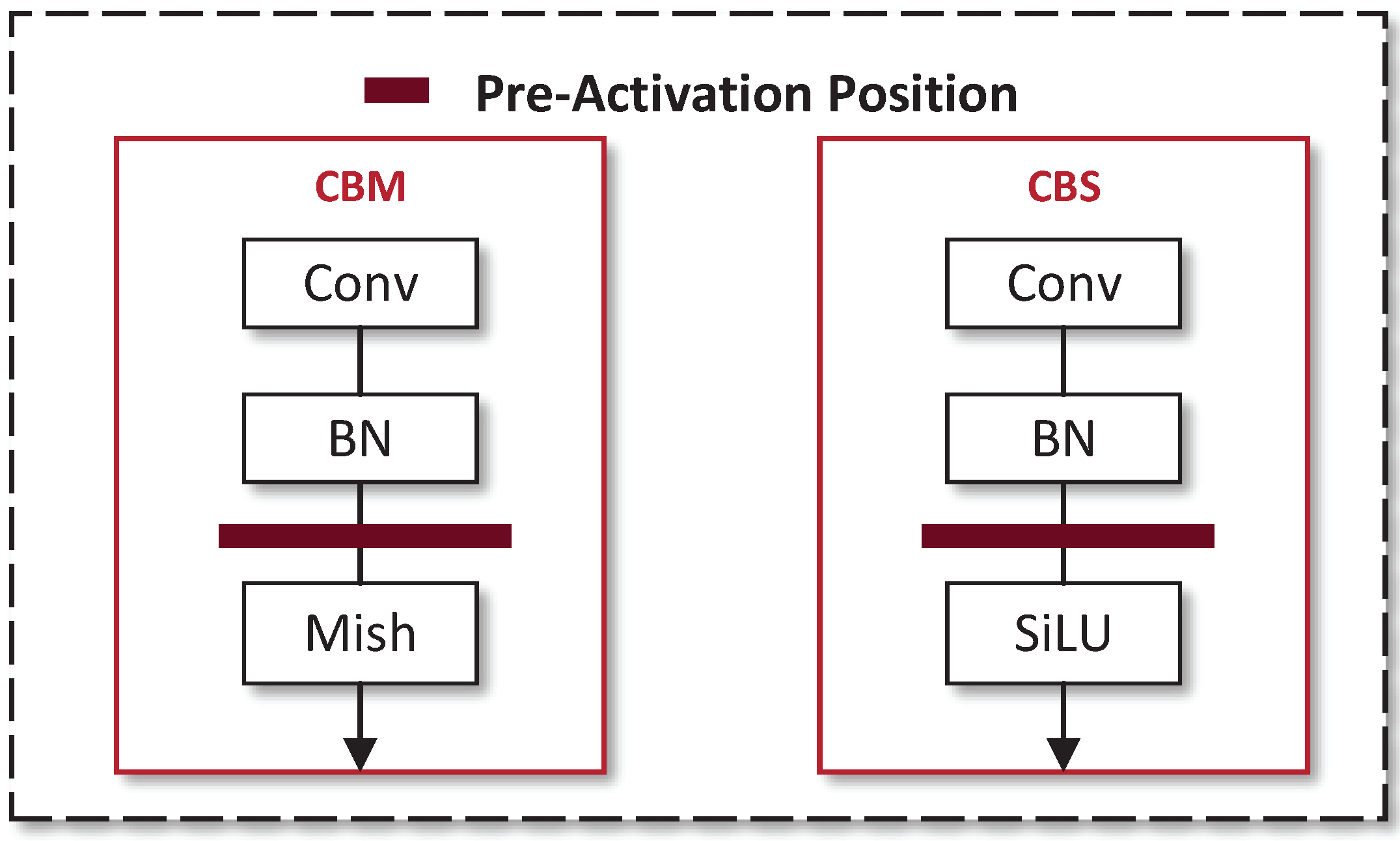
To further analyze the performance of different improvement strategies, this study sequentially tests the performance of different combinations of improvement strategies for YOLO-MPFD feature distillation using the same training set, training method, and testing environment. Among them, the base feature distillation method (Baseline) uses YOLOv4 or YOLOv5-l as the single-teacher model and YOLOv4-Tiny as the student model. The L2 function in FitNets [
39] is used as the distance loss function, the convolution + BN is used as the student transformation, and the feature distillation loss position is set before the activation function. The test results are presented in
Table 4.
As shown in
Table 4, by using YOLOv4 (Teacher1) or YOLOv5-l (Teacher2) as a single-teacher model and training the student model YOLOv4-Tiny using the base feature distillation method (Baseline), respectively, the m
AP values of the trained student models improved by 2.10% and 2.42%. Moreover, because YOLOv4 and YOLOv4-Tiny have a more-similar model structure than YOLOv5 and YOLOv4-Tiny, which is more conducive to the student model learning the feature map knowledge in the implicit layer of the teacher model, the training result of the teacher model YOLOv4 is slightly better than that of YOLOv5-l. The category “+Multiple Teacher” indicates that a two-teacher model was used instead of a single-teacher model. The m
AP, Recall, and
F1 of the student model trained by the multi-teacher model are 92.67%, 77.18%, and 85.58%, respectively. All metrics are improved compared with the training results of the single-teacher model. This is because the multi-teacher model could provide more explanatory information for the detection task of the student model. The student model can take advantage of the “Views” of the teacher model on the precision task and combine the respective strengths of the different teacher models to improve its model performance. The category “+Loss” indicates that the LogCosh-Squared function is used as the loss function, which aims to reduce the influence of outliers and smooth the training results, as well as prevent the transmission of invalid negative information; “+Margin-Activation” indicates that the margin-activation method is used to modify the activation functions of different teacher models, thereby retaining more useful feature distillation information; “+Conv-GN” indicates the use of the Conv-GN structure for the feature distillation of student models, which aims to address the performance degradation of BN in small batch optimization. The data in
Table 4 show that various improvement strategies have a positive effect on the training results of the detection model. After applying various improvement strategies together, the m
AP of the MPFD YOLOv4-Tiny model is 94.21%, which is an improvement of 2.32% (Teacher1) and 2.00% (Teacher2) over the training results of the two single-teacher models, respectively.
To further prove the performance of YOLO-HPFD multi-teacher feature distillation, the distilled model is compared to other lightweight versions of YOLO in the same test environment. The experiment uses the same training and test sets for model training and accuracy testing in TensorFlow (GPU). Speed tests are performed on the same picture with input sizes of 640 × 480. The experimental results are shown in
Table 5. From the empirical observations, it can be noted that the distilled model has many distinct benefits over other models. The m
AP, Recall, and test speeds of YOLOv4-Tiny-MPFD are 94.21%, 80.90% and 17.93ms–all better than the other models. In addition, although the model size of YOLOX-Tiny is the smallest, its Recall is the worst among all models, and it is 12.66 ms slower than YOLOv4-Tiny-MPFD. Thus, the distilled model has the best overall performance and is more compatible with the requirements of the embedded platform.
5.4. Analysis Results of the Distilled Model
The performance tests are conducted by applying the distilled detection model to the same dataset on the server and FPGA platforms, respectively. The data results are presented in
Table 6. The detection precision of female litchi flowers in different testing platforms is better than that of male litchi flowers. This is because compared with female litchi flowers, male litchi flowers are smaller in size, and filaments are more likely to fall off or even appear to have only the receptacle left, all of which make the detection of male flowers more difficult. In addition, the distilled model quantization is ported to the FPGA platform. The m
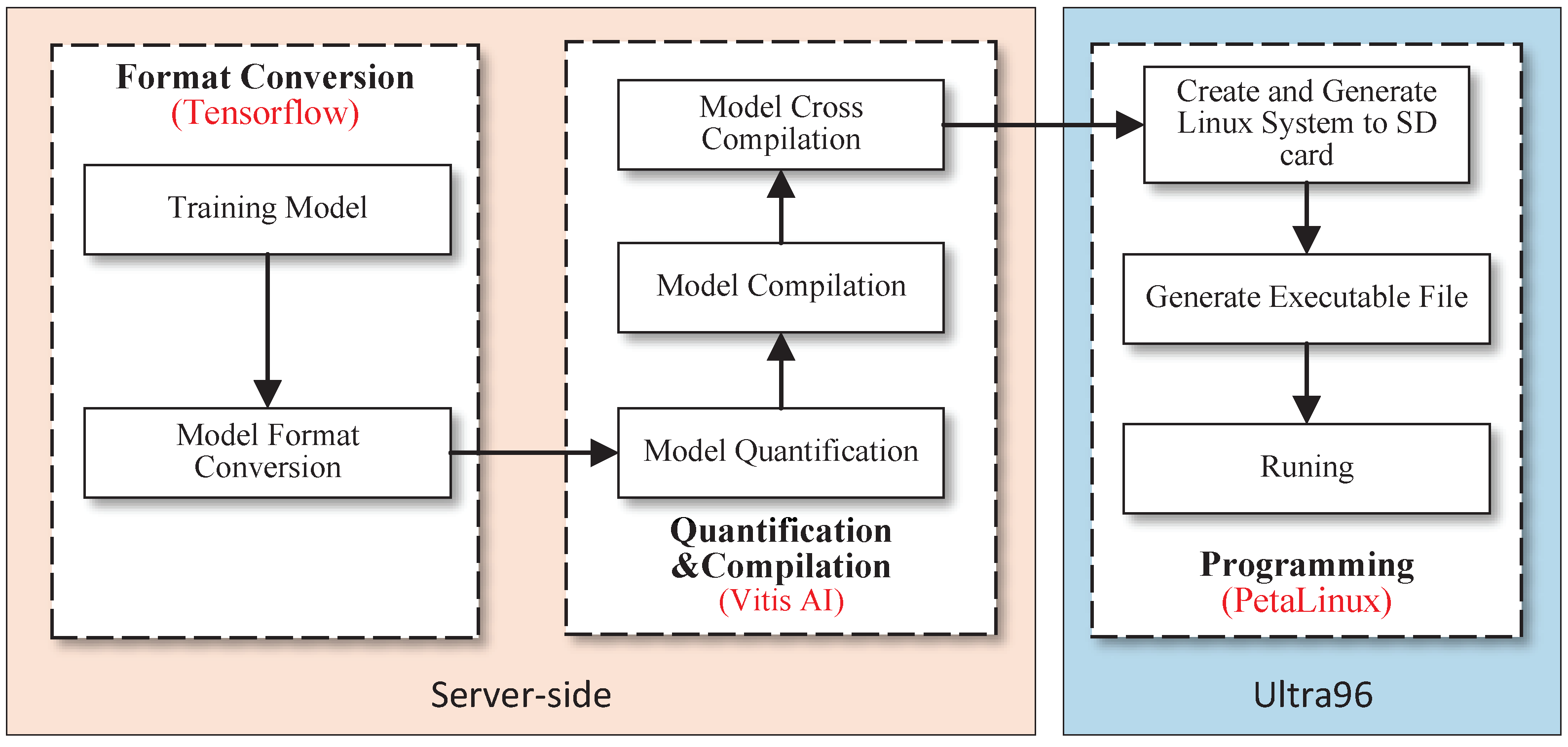
AP value was 93.74%, which is 0.47% lower than that on the server platform. Because the FPGA platform uses a DPU for neural network acceleration, it needs to convert 32-bit floating-point operations into 8-bit fixed-point operations. There is a certain precision loss in this conversion process. However, the size of the detection model ported to the FPGA platform is only 5.91 MB, which is 73.85% lower than that of the detection model of the server platform. Therefore, the porting operation provides significant compression of the model size with no significant reduction in the detection precision of litchi flowers, which improves the real-time detection rate.
To verify the real-time detection of the system, the detection effects of the server, PC, and FPGA platforms on video streams are also compared and tested. The video stream testing scheme, based on the FPGA platform, is depicted in
Figure 11. The camera is connected to the Ultra96-V2 through the USB interface and captures the video stream of the litchi flower in real time. The monitor is connected to Ultra96-V2 through an HDMI interface and displays the real-time detection results processed by Ultra96-V2. The input size of the model is 640 × 640, the video stream resolution is 640 × 480, and a power-metering socket is used to monitor the power consumption of different test platforms. The data results are shown in
Table 7. Among them, the server platform has the fastest video stream detection rate, based on the GPU/RTX 3080 detection rate of 26 FPS. However, its power consumption reached 183 W, far exceeding the PC and FPGA platform power consumption. The FPGA platform has a video stream detection rate of 6 FPS, which is better than that of the PC platform. In addition, the FPGA platform’s power consumption is only 10 W, 94.54% and 82.14% lower than that of the server (GPU) and PC (GPU) platforms, respectively.
To verify the practicality of the male and female litchi flower detection system, this study also conducts a comparison experiment between system detection and manual weighing. Considering that the manual weighing method needs to obtain the exact weight of litchi flowers, this study distinguishes between female and male litchi flowers manually after randomly selecting five groups of samples. The number of female and male litchi flowers in each group is 50, and then the weight of a single male and female flower is estimated using high-precision electronic scales. The experimental comparison samples consist of five groups. Considering the actual proportion of male and female flowers in a single spike, the number of male flowers in each group ranges from 200 to 400, whereas that of female flowers ranges from 30 to 60. The data results (
Table 8) show that the average accuracy of the system detection is 93.25%, which is significantly better than the manual weighing method in terms of detection efficiency and precision.



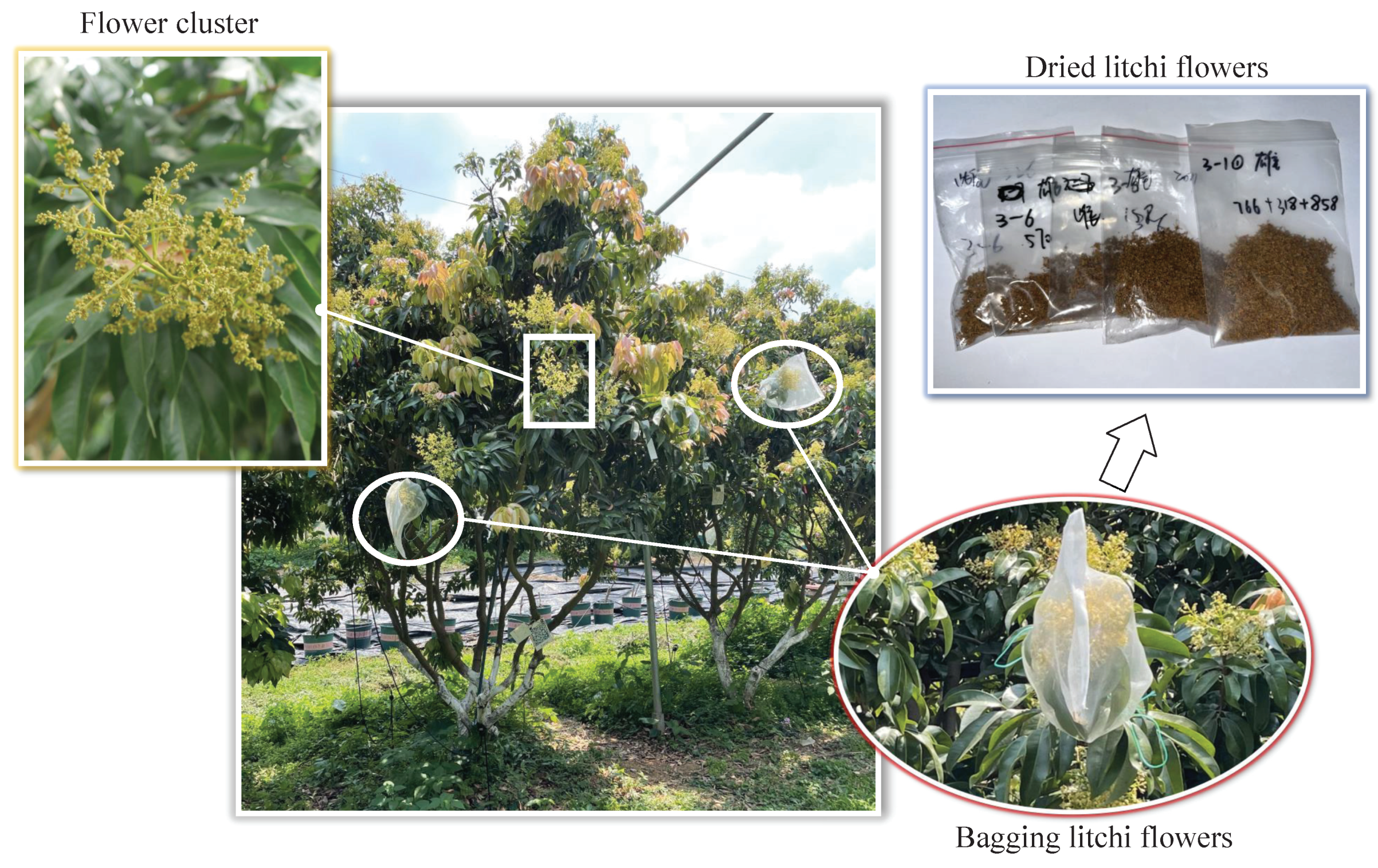











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}