1. Introduction
Tea is the second most consumed beverage in the world [
1,
2]. While it is beneficial to human beings, harvesting tea is often a major challenge for farmers. Currently, there are two primary methods for harvesting tea, which are hand-picking (manual) and mechanical harvesting. Famous tea picking is highly time-sensitive, and the main problem with the hand-picking process is the time delay due to its time-consuming and labor-intensive nature [
3]. Although the mechanical harvesting method partly improves labor productivity, its “one-size-fits-all” cutting operation greatly reduces the economic value of tea products [
4], especially Chinese famous tea production, which is limited as nearly all the tea shoots are manually picked.
With the development of agricultural harvesting robots, developing intelligent famous tea picking platforms is a vital trend to promote the famous tea industry. Accurate and rapid detection of tea canopy shoots in complex field environments is one of the crucial technologies for intelligent picking platforms. Computer vision technology has been widely applied in target detection of various fruits and vegetables, such as apple [
5], tomato [
6], strawberry [
7], kiwifruit [
8], and grape [
9]. The primary techniques used for tea shoot detection involve traditional image processing and deep learning methods. Traditional image processing methods typically rely on differences in color, texture, and shape between the target foreground and background to extract the detection target [
10,
11]. Wu et al. proposed a method to detect tea shoots based on image G and G-B component information, and to automatically extract segmentation thresholds through maximum variance [
3]. Yang et al. used the G component as a color feature to segment the background and tea shoots with the double thresholds, and detected the edges of tea leaves based on shape features [
12]. Zhang et al. employed the process of improved G-B algorithm graying, median filtering, OTSU binarization processing, morphological processing, and edge smoothing to extract the tea fresh leaves shape from the RGB images of the tea canopy [
13]. Karunasena et al. developed a cascade classifier based on the histogram of oriented gradients features and support vector machine to detect tea shoots [
14]. Zhang et al. constructed G-B’ components to enhance the distinction between tea shoots and background in images by a segmented linear transformation, and then detected tea shoots based on the watershed segmentation algorithm [
15]. The effectiveness of image feature extraction is crucial for the detection performance of the above-mentioned methods, but it is often compromised by the complex and variable light conditions of the tea field environment.
The rapid advancement of deep learning techniques has led to the deployment of numerous deep learning models for recognition and detection tasks of agricultural robots in unstructured environments [
16]. These models are designed to leverage the ability of automatic feature extraction to enhance detection performance and improve robustness [
17]. Zhu et al. constructed a tea shoots detection model based on the Faster RCNN and evaluated the model detection performance under different shoot types. That model had the highest detection accuracy for one bud and one leave/two leaves with an
AP of 76% [
18]. Xu et al. compared the detection performance of Faster RCNN and SSD models with VGG16, ResNet50, and ResNet101 as feature extraction networks for tea shoots, and found that the Faster RCNN with VGG16 as its feature extraction network had the better detection performance with the precision of 85.14%, recall of 78.90%, and a mAP of 82.17% [
19]. Lv et al. compared several detection models based on the same dataset, and their results revealed that YOLOv5+CSPDarknet53 outperformed SSD+VGG16, Faster RCNN+VGG16, YOLOv3+Darknet53, and YOLOv4+CSPDarknet53 for the detection of tea shoots, with precision and recall of 88.2% and 82.1%, respectively [
20]. Yang et al. proposed an improved YOLOv3 model for the detection of tea shoots by adding an image pyramid structure and residual block structure, and the average detection accuracy was found to be over 90% [
21]. Xu et al. proposed a two-level fusion model for tea bud’ detection with an accuracy of 71.32%. The detection process used YOLOv3 to extract the tea shoot regions from the input images, followed by classification of the extracted regions using DenseNet201 [
22]. Using deep learning methods for detecting tea shoots have be shown to demonstrate a significantly better performance compared to traditional image processing methods, thanks to their excellent feature-extracting ability. As the depth of the network layers and the number of model parameters increase, it becomes increasingly challenging to deploy deep learning models on movable and embedded devices with limited computing power. This limitation poses a challenge to the development of intelligent tea picking equipment that requires real-time and on-site tea shoots detection. Furthermore, previous research mainly focused on the detection of tea shoots under natural light conditions, and to our knowledge, there are no reports of detection under artificial light conditions at night. Since nighttime takes up one-third of the whole day, the efficiency of the all-day work will be significantly improved with continuous and effective harvesting at night [
23]. Tea harvesting is time-sensitive, and tea shoots must be picked at the right time to ensure the best quality of tea. Enabling all-day picking, including at night, can significantly increase the efficiency of the harvest and the income of tea farmers.
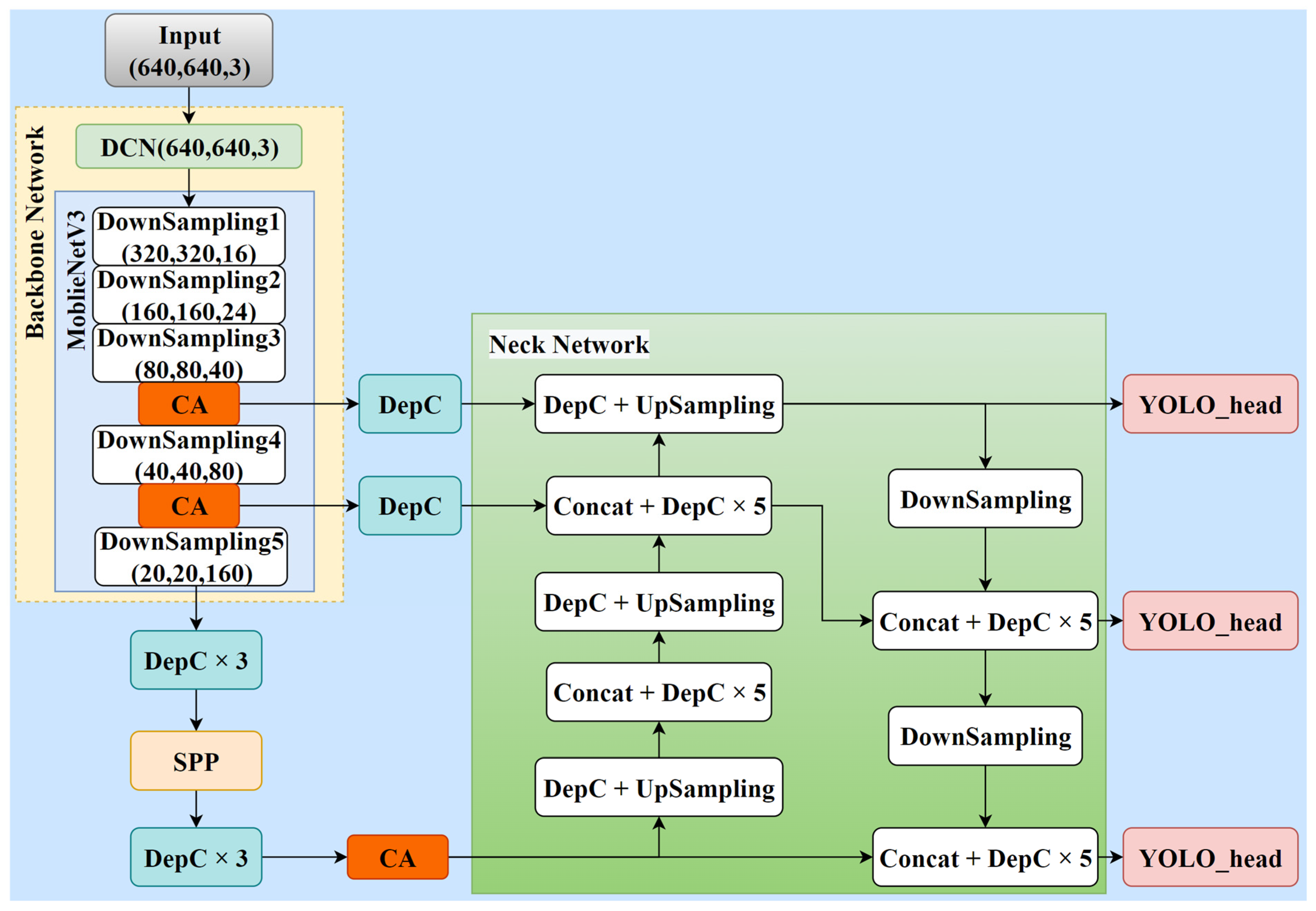
The current detection models have slow inference speed and are not easily deployable on movable platforms, which hinders the development of intelligent tea picking equipment. Furthermore, the detection of tea canopy shoots is currently limited to natural daylight conditions, with no reported studies on detecting tea shoots under artificial lighting during the nighttime. Developing an all-day tea picking platform would therefore significantly improve the efficiency of tea picking. Considering these issues, the research objective for our study was to propose an all-day lightweight detection model for tea canopy shoots (TS-YOLO) based on YOLOv4. The main contributions of this study were:
- (1)
To collect an image dataset of tea canopy shoots samples under natural light and artificial light at night, and to establish and annotate an all-day light conditions image dataset of tea canopy shoots;
- (2)
To reduce the model size and increase the inference speed, with the feature extraction network of YOLOv4 and the standard convolution of entire network being replaced by the lightweight neural network and the depth-wise separable convolution;
- (3)
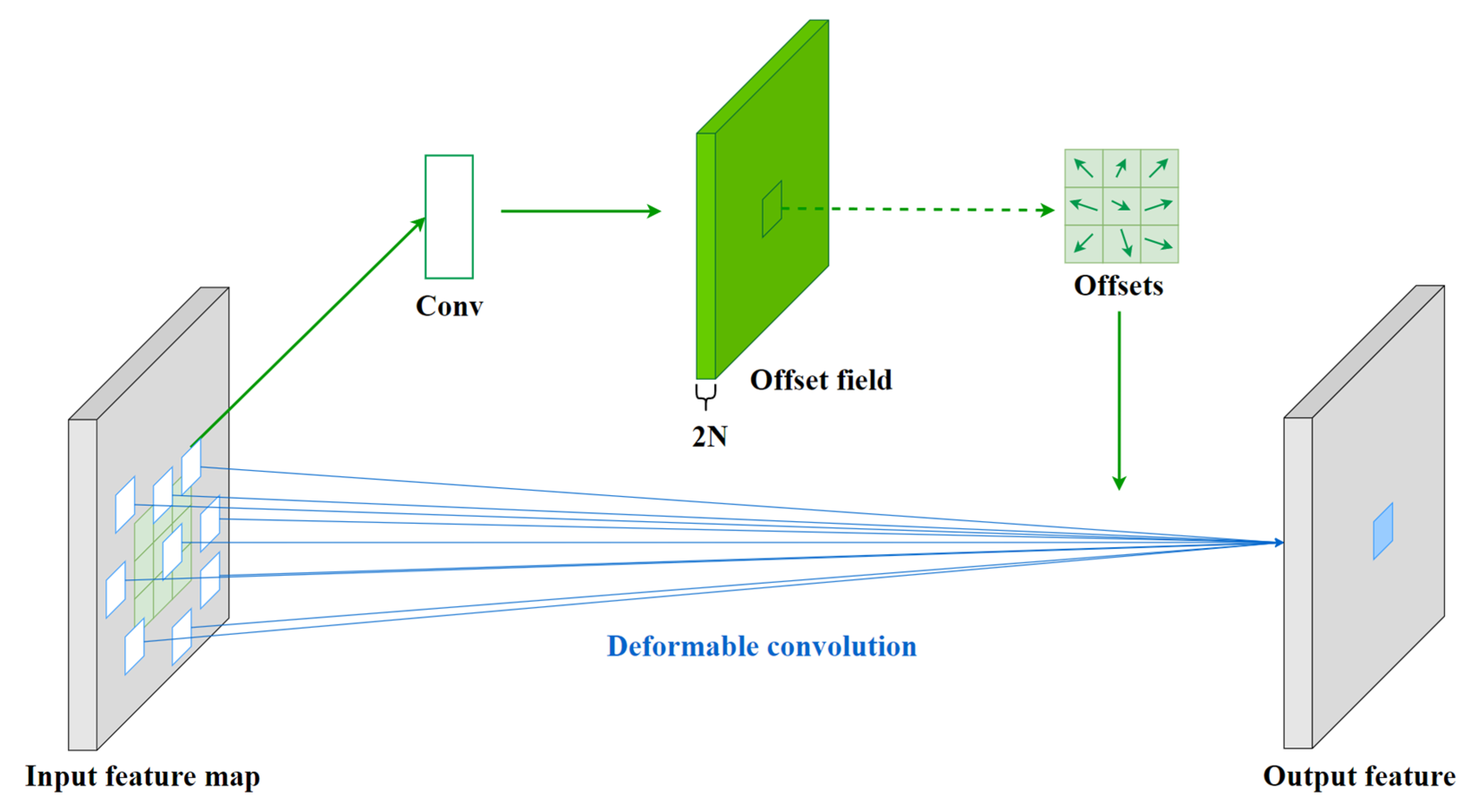
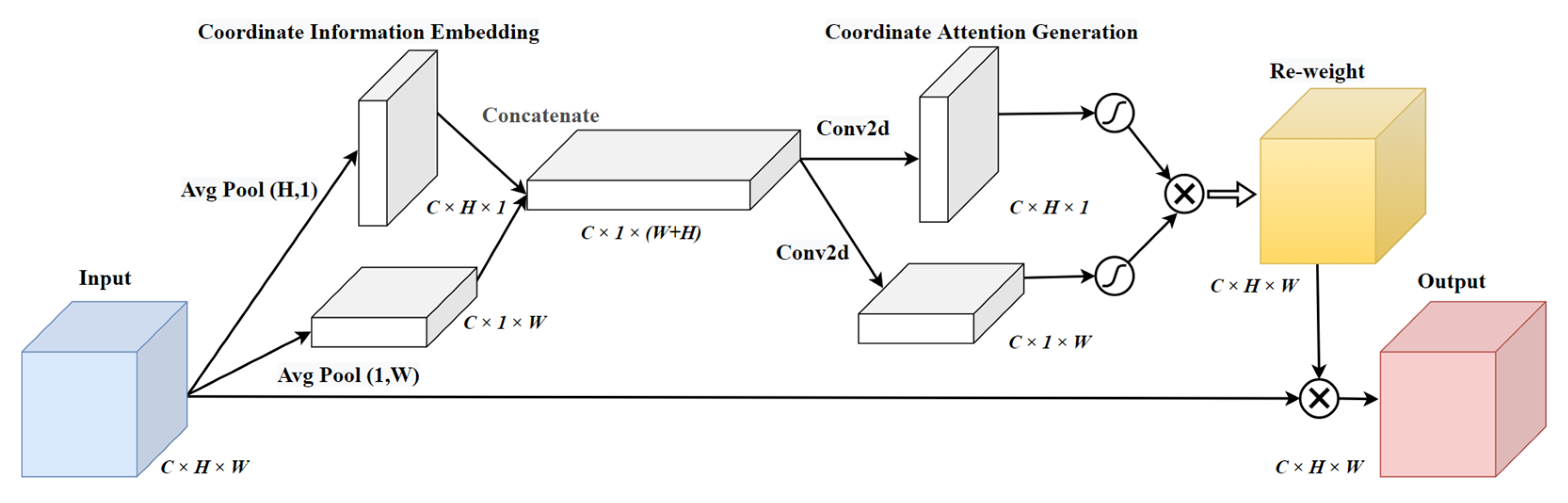
A deformable convolutional layer and coordinate attention modules were introduced into the network to compensate for the shortage of the lightweight neural network on feature extraction ability.
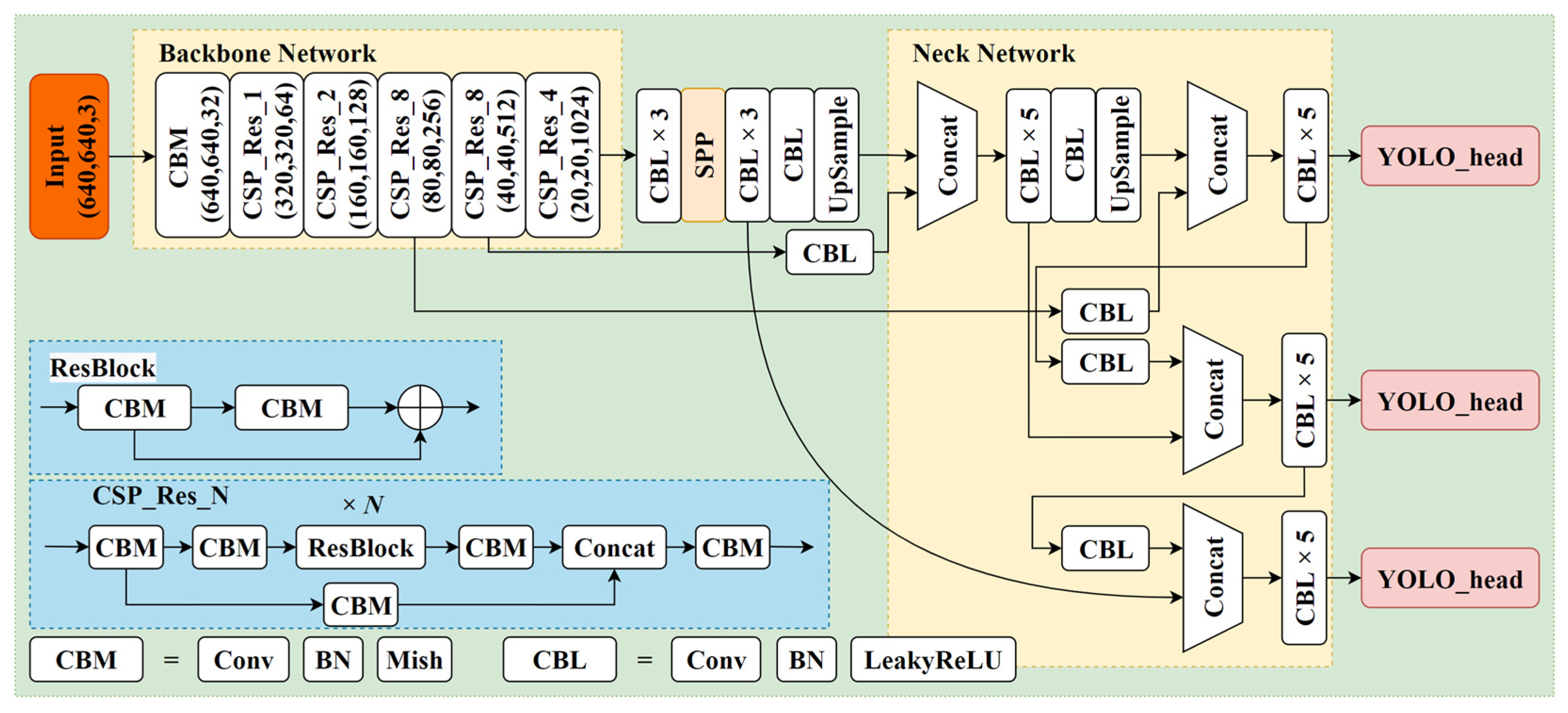
We constructed an image dataset of tea canopy shoots under natural daylight and artificial light conditions at night in tea plantations, and proposed our TS-YOLO model which combines YOLOv4, MobileNetV3, deformable convolutional, and coordinate attention modules. Our model can efficiently and accurately detect tea canopy shoots under natural daylight and artificial light conditions, making it an innovative all-day application.
3. Results and Analysis
The hardware environment used for the experiment is shown in
Table 2. The standard stochastic gradient descent was used to train the models. The momentum set was 0.937, the initial learning rate was 0.001, and the weight decay was 0.0005. Considering the calculation speed of model training, the input image size was set to 640 × 640, the batch size was 4, and a total of 100 epochs were performed.
3.1. Evaluation of Model Performance
The performance of the trained models in detecting the tea canopy shoots was evaluated using common target detection metrics, including precision (P), recall (R), average precision (AP), model size, and frame per second (FPS). The equations for the relevant metrics are as follows:
where
TP is the sample accurately predicted as tea shoot by the model,
FP is the sample falsely predicted as tea shoot by the model,
FN is the sample wrongly judged as background, and
AP is the area under the
P-R curve. The precision evaluates the percentage of objects in the returned list which are correctly detected, and the recall evaluates the percentage of correctly detected objects in total.
3.2. Performance Effect of Different Modules on the Model
3.2.1. Anchor Boxes Optimization and Data Augmentation
The YOLO series network utilizes anchor boxes as a prior box to aid in predicting the boundaries of the targets, and the appropriate size of the anchor boxes can further enhance the performance of target detection. In this paper, based on the annotation information of the training dataset, 1 −
IoU was used as the clustering distance, and the size of the anchor boxes was calculated by the k-means algorithm. Nine groups of anchor boxes {(13,21), (15,35), (24,26), (21,52), (35,40), (31,71), (57,58), (47,106), and (85,154)} were obtained, and the average IoU was 0.74, which was found to be 0.12 higher than the default size of the anchor boxes in YOLOv4. To improve the generalization ability of the model based on limited datasets and mitigate overfitting, data augmentation was used to enable the model learning more robust features [
38]. The performance impact on these models after the process of anchors boxes optimization (AO) and data augmentation (DA) is shown in
Table 3.
After the process of AO, the P was improved by 2.19%, while AP and R did not change significantly. After the process of DA, the AP, R, and P were all improved by 19.52%, 19.19%, and 6.95%, respectively. After the process of combining AO and DA, the AP, R, and P were all improved by 20.08%, 20.91%, and 7.47%, respectively.
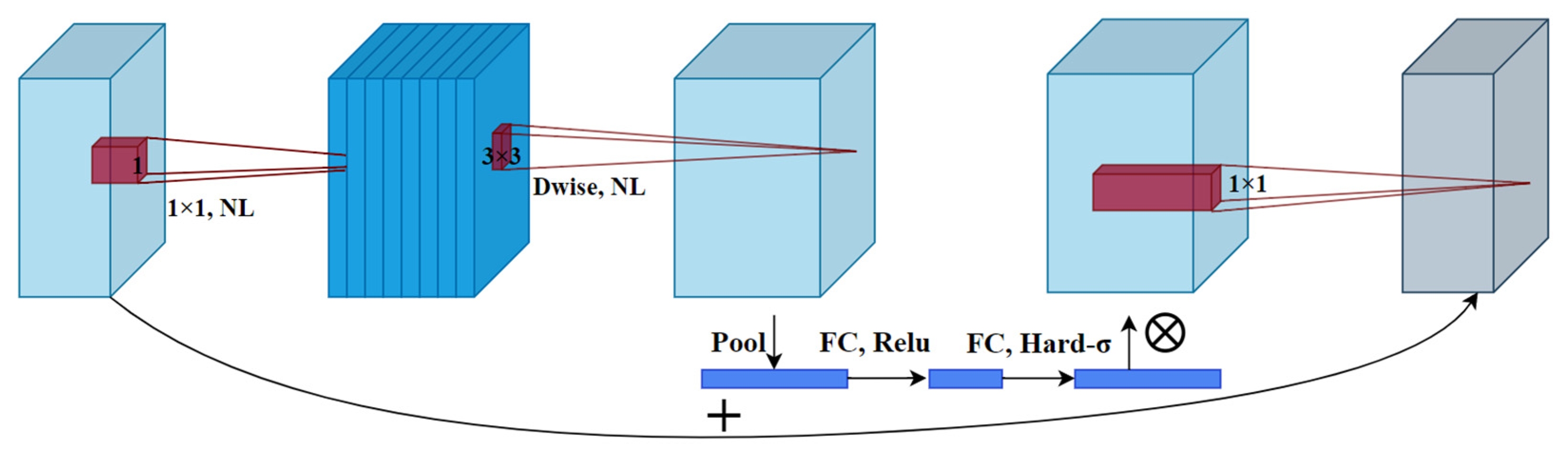
3.2.2. Lightweight Convolutional Neural Networks
To improve the portability of the model and increase the inference speed based on AO and DA, lightweight neural networks were used as the feature extraction network, and depth-wise separable convolution was applied in replacing standard convolution in the neck network. Five kinds of lightweight neural networks, which were ShuffleNetV2 [
39], MobileNetV2, MobileNetV3, EfficientNetV2 [
40], and GhostNet [
41], were compared and analyzed (
Table 4).
After replacing the original feature extraction network with the lightweight neural network, MobileNetV3 was found to have the highest
AP value of 73.92%, which was 10.69% lower than that of CSPDarknet53. For EfficientNetV2, it was found to have the highest
P value of 84.75%, which was 2.94% lower than that of CSPDarknet53. GhostNet had the highest
R value of 68.73%, which was 9.35% lower compared to CSPDarknet53. ShuffleNetV2 had the smallest model size of 9.89 M, which was 84.63% lower compared to CSPDarknet53. MobileNetV2 had the highest FPS of 54.39, which improved by 46.29% compared to CSPDarknet53. Although the model size of EfficientNetV2 was found to be significantly lower than that of CSPDarknet53, FPS decreased rather than increased, unlike the results published in other studies [
42,
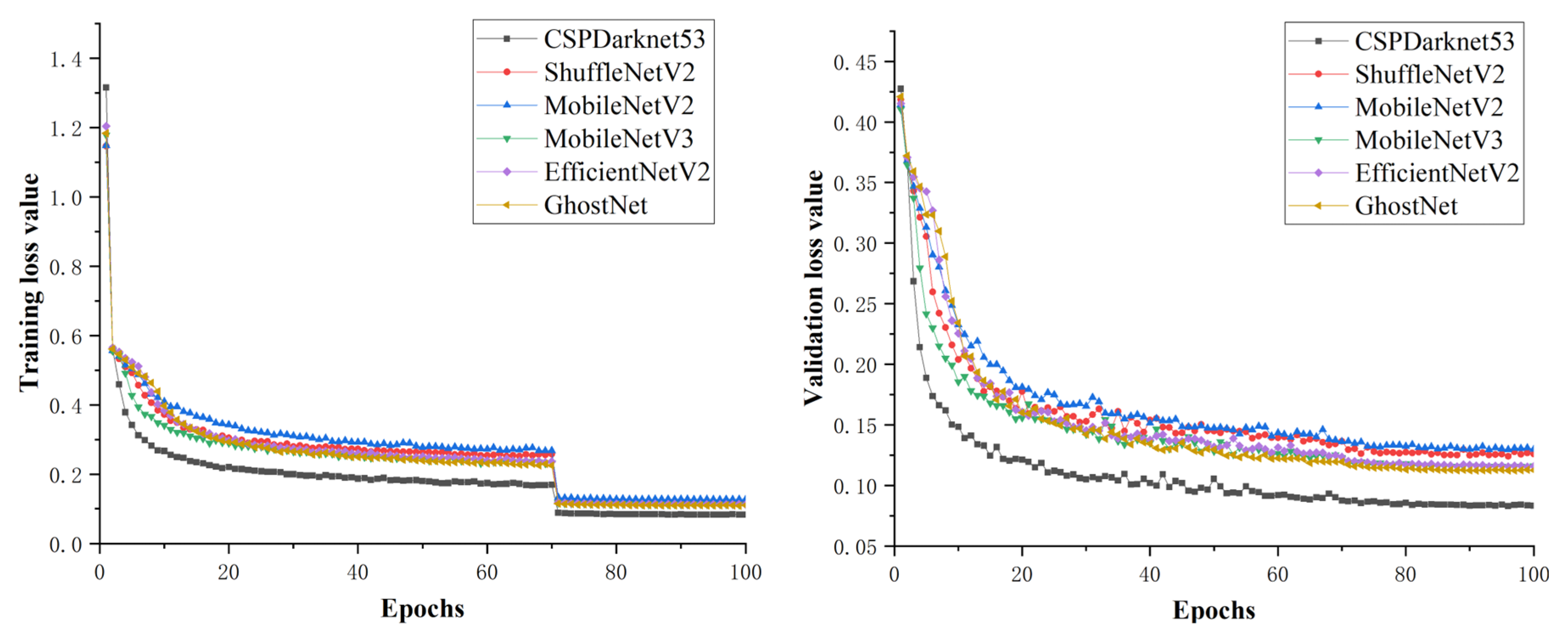
43], which may be caused by the compatibility of the experimental hardware platform with the model inference process. The training loss value of different models all plummeted at the 70th epoch, which may be caused by the change of learning rate during model training. With the combination of the validation loss value, all the models converged off after the 70th epoch in the different models (
Figure 11). To balance the model size, inference speed, and detection performance, MobileNetV3 was chosen as the feature extraction network in this paper. Similar to previous research [
44,
45,
46], using MobileNetV3 as the feature extraction network had achieved a better detection performance.
3.2.3. Ablation Experiments
To evaluate the effectiveness of the proposed improved model on detection performance, we validated the model performance using different modules based on YOLOv4 (
Table 5). MobileNetV3 was used as the feature extraction network to develop the model 1; A deformable convolutional layer was added in model 1 to develop the model 2; SE, CBAM, and CA attention modules were added in model 2 to establish the models 3, 4, and 5, respectively.
The backbone structure of the lightweight network was relatively simple, and the detection performance of the tea tree canopy shoots of different morphologies and sizes was yet to be improved. To improve the detection performance of the model, a deformable convolutional layer and attention modules were added to improve the model’s ability to extract complex features. As shown in
Table 4, when a deformable convolutional layer was added, the
R value was significantly improved by 7.96%, compared to model 1 with almost no change of model size and inference speed. When the attention modules were introduced, the detection performance of the model was further improved. Among them, model 3 with the added SE modules had improved
AP,
R, and
P by 3.39%, 1.4%, and 0.27%, respectively, compared to model 2. Model 4 with the added CBAM modules had improved
AP,
R, and
P by 5.67%, 3.4%, and 0.79%, respectively, compared to model 2. Model 5 with the added CA modules had improved
AP,
P, and
R by 6.74%, 4.56%, and 0.42%, respectively compared to model 2. Heat map visualization of the detection process of the tea canopy shoots by Grad-CAM for the model adding attention modules was shown in
Figure 12. After adding CA, the focus range of the model became broader and more focused compared to SE and CBAM. Thus, when CA was introduced, it effectively improved the detection performance of the model for the tea canopy shoots.
3.3. Detection Performance under Different Light Conditions
The complex and variable light conditions in the field environment are crucial factors that affect the accuracy of target detection tasks, and the tea canopy exhibits diverse characteristics that vary under different lighting conditions. As illustrated in
Figure 2, in low light conditions, the tea canopy shoots exhibited a bright yellow marginal part, with clearly visible light green veins on the leaves. Moreover, the branches and old leaves of the tea trees displayed a greater degree of color difference from the shoots, and dew can be observed on the surface of old leaves. Under medium light conditions, the color differentiation between the tea shoots and old leaves was reduced, and the color of tea shoots became greener. However, the contours of the tea shoots remained clearly defined, making it possible to detect them accurately. Under high light conditions, the high intensity of the light can cause reflection on the surface of old leaves and tea shoots, which can make it challenging to detect and distinguish them from the surrounding environment. Moisture condensation on the surface of tea leaves can occur due to high environmental humidity at night, while the reflection phenomenon on the surfaces of tea leaves and shoots can be caused by high light exposure. The non-uniformity of light intensity can cause shadows to appear under high light and artificial light conditions, which can further complicate the detection of tea canopy shoots.
Table 6 presents the detection performance of the model for tea canopy shoots under various light conditions.
Under medium light conditions, the model’s detection performance was the best, with AP, P, and R of 83.44%, 78.96%, and 85.93%, respectively. The model’s detection performance was the worst under artificial light conditions at night, as indicated by the lowest AP, P, and R values of 82.68%, 77.58%, and 85.87%, respectively. Despite several variations in the detection performance of the model under different light conditions, the differences observed were relatively small. Therefore, it can be inferred that the model exhibits a good robustness in detecting tea canopy shoots throughout the day, regardless of variations in the natural or artificial lighting conditions.
3.4. Comparative Experiments of the Different Detection Models
In this paper, different object detection models were compared with proposed TS-YOLO, such as Faster RCNN, SSD, YOLOv3, YOLOv4, M-YOLOv4 (MobileNetV3-YOLOv4), and YOLOv5, and experimental results are shown in
Table 7.
Based on the results, the two-stage detection model Faster RCNN exhibited significantly lower
AP and
P values compared to the other models. Faster R-CNN does not incorporate image feature pyramid, which may therefore limit its ability to accurately detect objects of different scales and sizes. The image feature pyramid is a commonly used technique in object detection models, which involves extracting multi-scale features from different layers of the network. These features are then used to detect objects of varying sizes and scales. Compared with YOLOv4, the proposed TS-YOLO
AP and
P values decreased by 2.49% and 2.34%, respectively, but the model size was reduced by 81.70% and inference speed was increased by 31.41%. Compared with M-YOLOv4, the
AP, R, and
P values of TS-YOLO increased by 8.20%, 12.52%, and 1.08%, respectively. Compared with YOLOv5 (the selected YOLOv5m, which has a similar size to the proposed model), the
AP and
R values of TS-YOLO increased by 2.83% and 6.70%, while the model size was reduced by 44.40%, respectively. The comparison results revealed that there is a trade-off between the complexity of the network structure and the model detection performance.
AP is a comprehensive evaluation index of model precision and recall, while FPS measures the model’s inference speed. However, there is currently no evaluation index that considers both the detection performance, and the inference speed of these object detection models. In practical applications, it is necessary to comprehensively consider the detection performance and inference speed of the model in conjunction with the computing performance of the picking platform. On high-performance computing platforms,
AP can be given more weight since it has little impact on the real-time detection performance. However, on platforms with limited computing resources, both
AP and the inference speed of the model should be considered to meet the requirements of real-time detection. TS-YOLO uses a trade-off strategy to balance the detection performance and the inference speed. By reducing the model size and optimizing the network architecture, it can achieve a faster inference speed while maintaining a certain level of detection performance. In the future, we aim to focus on improving the model by implementing high-accuracy strategies to minimize the loss of detection performance. The results of these different models for the detection of tea canopy shoots are as shown in
Figure 13.
4. Discussion
The results of this study compared to other studies are summarized in
Table 8. Yang et al. [
12], Wu et al. [
47], Karunasena et al. [
14], and Zhang et al. [
15], used traditional image processing methods for the detection of tea shoots. When using traditional image processing methods for target detection, the feature characters used for the description are artificially designed, and the method performs well for detection performance when the image is clear, uniformly illuminated, and minimally occluded. In the practical tea field, however, these conditions are often not met. Among the deep learning methods, Zhu et al. [
18], Wang et al. [
48], Li et al. [
49], Wang et al. [
50], and Chen et al. [
51] used Faster RCNN, Mask RCNN, YOLOV3, YOLOv5, and so on, to detect the tea shoots, respectively. Although its detection results are better and the robustness to complex field environments are higher, the large model size and slow inference speed are not suitable to be deployed on movable platforms for the real-time detection of tea canopy shoots. With respect to model light-weighting, it is mainly achieved by using lightweight modules and model compression. Gui et al. used ghost convolution to replace the standard convolution and added the bottleneck attention module to the backbone feature extraction network [
52]. Huang et al. replaced the feature extraction network with GohstNet and replaced the standard convolution in the neck network with ghost convolution [
53]. Cao et al. introduced the GhostNet module and coordinated attention module in the feature extraction network and replaced PAN with BiFPN [
54]. Guo et al. add attention modules and replaced PAN with FPN to achieve a lightweight model [
55]. Compared with these related studies, the detection performance of the proposed model in this paper was found to be slightly lower, and its main reasons were probably the following: (1) The dataset used in this paper was acquired under natural and artificial light conditions with more complex light variations; (2) The height and angle of the shots during image capture wee variable, and the morphology of the tea shoots were more diverse compared to the fixed height and angle shots. Thus, for further improving the detection performance of the model for all-day tea canopy shoots, the following approaches will be used for future research: (a) Elimination of the effects of light variations with image enhancement processing; (b) Combination with the tea picking platform, with the suitable height and angle to take images; (c) Multiple detections can be realized by adjusting the position of the picking platform cameras to improve the picking success rate. In conclusion, this study introduces a novel model, TS-YOLO, for detecting tea canopy shoots, and creates an image dataset captured under varying lighting conditions, including under natural daylight and artificial light at night. The proposed model exhibits a high efficiency and accuracy in detecting tea canopy shoots under all-day lighting conditions, which has significant implications for the development of all-day intelligent tea-picking platforms.
5. Conclusions
The research proposed an all-day lightweight detection model for tea canopy shoots (TS-YOLO) based on YOLOv4, which employed MobileNetV3 as the backbone network for YOLOv4, and replaced the standard convolution with depth-wise separable convolution to achieve the reduction in model size and increase the inference speed. To overcome the detection limitations, a deformable convolutional layer and coordinate attention modules were introduced. Compared with YOLOv4, the TS-YOLO model size was 18.30% of it, and the detection speed was improved by 11.68 FPS. The detection accuracy, recall, and AP of tea canopy shoots under different light conditions were 85.35%, 78.42%, and 82.12%, respectively, which were 1.08%, 12.52%, and 8.20% higher than that of MobileNetV3-YOLOv4, respectively.
While this study yielded promising results, there were two limitations that require attention. Firstly, the position, phenotype, and occlusions during the picking process must be considered to determine whether the tea canopy shoot can be harvested. Secondly, to improve the model’s applicability across various tea varieties, future research should integrate an intelligent tea picking platform to analyze the harvestability of the detected tea shoots and evaluate the model’s effectiveness.
Although there were several minor research limitations, the developed lightweight model has demonstrated its efficacy in detecting tea canopy shoots quickly and effectively, even under all-day light conditions. This breakthrough could pave the way for the development of an all-day intelligent tea picking platform, which could revolutionize the tea industry.




 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}