
An Overview of Recent Advances in Greenhouse Strawberry Cultivation Using Deep Learning Techniques: A Review for Strawberry Practitioners
Abstract
:1. Introduction
- This paper provides an overview of recent advancements in strawberry cultivation utilizing DL techniques.
- Recent advanced variants of the DL model are discussed, along with a fundamental overview of CNN architecture. In addition, techniques for fine-tuning DL models are covered.
- Various strawberry-planting-related datasets are examined in the literature. In addition, the limitations of using research models for real-time research are discussed.
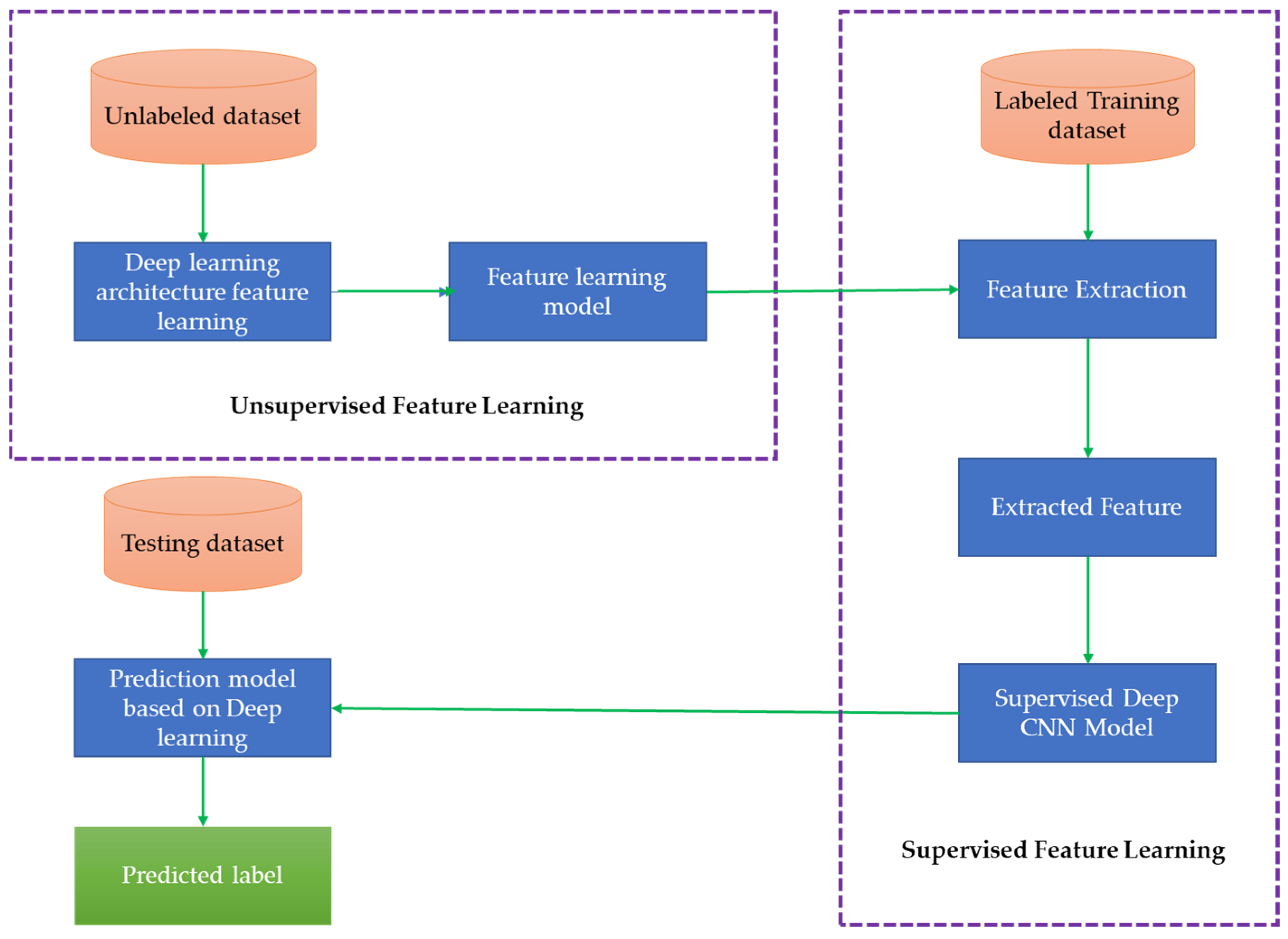
2. Deep Learning Networks
- The potential lack of spatial information in the resulting image may lead to non-contiguous segmented regions.
- The choice of a threshold is important.
- Extremely sensitive to noise.
- Worst-case scenario conduct is bad.
- It necessitates clusters of similar size.
- Performed poorly for a picture with a lot of edges.
- It is difficult to find the right object edge.
- More computation time and memory were required, and the process was sequential.
- User seed selection that is noisy results in faulty segmentation.
- Splitting segments appear square due to the region’s splitting scheme.
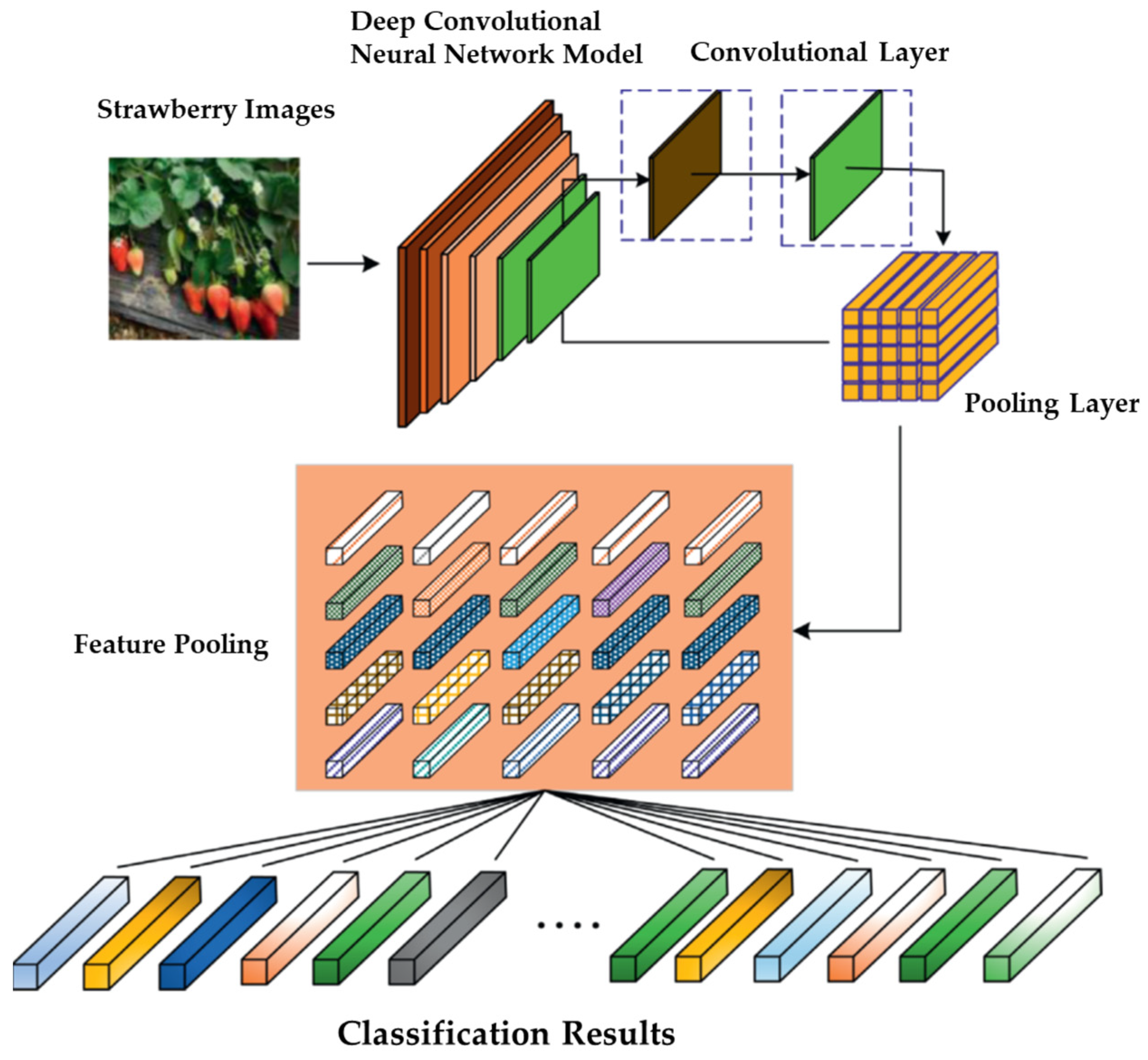
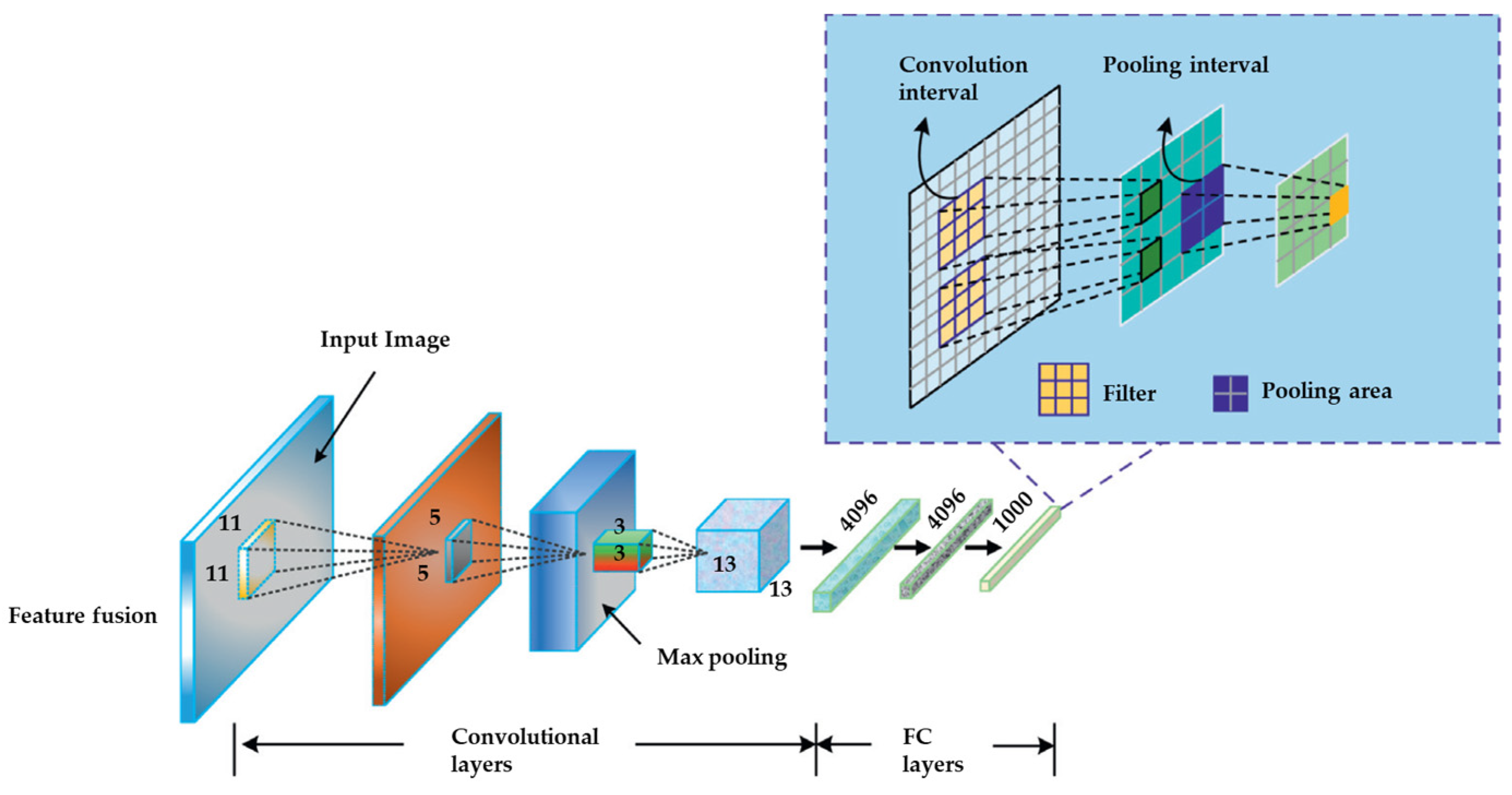
2.1. Convolutional Neural Network (CNN)
2.1.1. Convolution Layers
2.1.2. Pooling Layers
2.1.3. Fully Connected Layers
2.1.4. Activation Functions
- Sigmoid: This activation function takes real numbers as input and output numbers between zero and one.
- Tanh: It is similar to the sigmoid function in that it accepts real numbers as input, but its output is limited to values between −1 and 1.
- ReLU: In the CNN context, the most widely used function is ReLU. It converts the input’s full values to positive numbers. The key advantage of ReLU over the others is its lower computational load. Occasionally, a few severe difficulties may arise while using ReLU. Consider an error back-propagation algorithm that has a higher gradient running through it. Passing this gradient through the ReLU function will update the weights in such a way that the neuron will never be stimulated again. This is known as the “Dying ReLU” problem. There are some ReLU solutions available to address such difficulties. Instead of ReLU downscaling negative inputs, this activation function ensures they are never ignored. It is used to solve the Dying ReLU issue.
- Noisy ReLU: This function makes ReLU noisy by using a Gaussian distribution.
- Parametric Linear Units: This is similar to Leaky ReLU. The primary distinction is that in this function, the leak factor is updated during the model training process.
2.1.5. Loss Function
- Cross-Entropy or Softmax Loss Function: This function is often used to assess the performance of CNN models. It is also known as the log loss function. It returns the probability p ∈ {0,1}. Furthermore, it is commonly used to replace the square error loss function in multi-class classification tasks. It uses softmax activations in the output layer to generate output within a probability distribution.
- Euclidean Loss Function: The Euclidean Loss Function is commonly utilized in regression issues. Furthermore, it is the so-called mean square error.
- Hinge Loss Function: This function is often used in binary classification situations. This issue is related to maximum-margin-based classification. This is especially relevant for SVMs that use the hinge loss function, in which the optimizer strives to maximize the margin around dual objective classes.
2.2. Other Important Variants of CNN
2.2.1. AlexNet
2.2.2. Visual Geometry Group (VGG)
2.2.3. GoogLeNet
2.2.4. U-Net
2.2.5. R-CNN
2.2.6. YOLO
2.2.7. ResNet
3. Applications of Deep Learning in Strawberry Farming
3.1. Strawberry Disease Detection
3.1.1. Multiple Disease Detection

3.1.2. Particular Disease Detection
3.2. Strawberry Fruit Detection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Parameters | Used Tools and Techniques | Reference |
|---|---|---|---|
| Disease detection | Multiple classes | AlexNet | [72,73] |
| Improved ResNet50 | [8] | ||
| DCNN | [44] | ||
| AlexNet, DenseNet-169, Inception v3, ResNet-34, SqueezeNet-1.1 and VGG13 | [33] | ||
| Class-attention-based lesion proposal convolutional neural network | [77] | ||
| GoogLeNet model, Resnet50, and VGG 16 | [71] | ||
| DNN (PlantNet) | [75] | ||
| YOLO | [4] | ||
| CNN (a location network, a feedback network, and a classification network) | [82] | ||
| Mask R-CNN | [9] | ||
| CNN | [83] | ||
| AlexNet and GoogLeNet | [84] | ||
| YOLO | [27] | ||
| Fungal leaf disease | Multi-directional Attention Mechanism—Dual Channel Residual Network | [85] | |
| DCNN | [86] | ||
| DCNN | [53] | ||
| UNet | [29] | ||
| CNN, VGG 16, GoogleNet, and Resnet 50 | [74] | ||
| Gray mold disease | UNet | [28] | |
| Verticillium Wilt | Faster R-CNN and multi-task learning | [31] | |
| Powdery mildew disease detection (Leaf) | AlexNet, SqueezeNet, GoogLeNet, ResNet-50, SqueezeNet-MOD1, and SqueezeNet-MOD2. | [56] | |
| Known and unknown diseases | Deep Metric Learning-Based KNN Classifier | [76] | |
| Fruit detection | Ripe or unripe fruit | Mask-RCNN | [62] |
| AlexNet | [81] | ||
| R-CNN | [79] | ||
| Mask R-CNN | [80] | ||
| Species detection | CNN | [37] | |
| Fruit quality | Plumpness assessment | Faster-RCNN | [34] |
| External quality of fruits | CNN | [11] | |
| AlexNet, MobileNet, GoogLeNet, VGGNet, and Xception, and Two layers CNN architecture | [35] | ||
| Wellbeing | Leaf wetness detection | CNN | [87] |
| Yield | Yield detection | Faster-RCNN | [14] |
3.3. Strawberry Fruit Type Detection
3.4. Strawberry Fruit Quality Detection
3.5. Leaf Wetness Detection
3.6. Yield Detection
4. Discussions
4.1. Limitations of the Datasets
4.1.1. Smaller Dataset Problems
4.1.2. Dataset Availability
4.1.3. Data Collection Issues
4.2. Regularization of DL Models
5. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hannum, S.M. Potential Impact of Strawberries on Human Health: A Review of the Science. Crit. Rev. Food Sci. Nutr. 2004, 44, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Janse, J.D.; Rossi, M.P.; Gorkink, R.F.J.; Derks, J.H.J.; Swings, J.; Janssens, D.; Scortichini, M. Bacterial Leaf Blight of Strawberry (Fragaria (×) Ananassa) Caused by a Pathovar of Xanthomonas arboricola, Not Similar to Xanthomonas fragariae Kennedy & King. Description of the Causal Organism as Xanthomonas arboricola Pv. fragariae (Pv. Nov., Comb. Nov.). Plant Pathol. 2001, 50, 653–665. [Google Scholar] [CrossRef]
- Carew, J.G.; Morretini, M.; Battey, N.H. Misshapen Fruits in Strawberry. Small Fruits Rev. 2003, 2, 37–50. [Google Scholar] [CrossRef]
- Cruz, M.; Mafra, S.; Teixeira, E.; Figueiredo, F. Smart Strawberry Farming Using Edge Computing and IoT. Sensors 2022, 22, 5866. [Google Scholar] [CrossRef]
- Choi, S.H.; Kim, D.Y.; Lee, S.Y.; Chang, M.S. Growth and Quality of Strawberry (Fragaria Ananassa Dutch. Cvs. ‘Kuemsil’) Affected by Nutrient Solution Supplying Control System Using Drainage Rate in Hydroponic Systems. Horticulturae 2022, 8, 1059. [Google Scholar] [CrossRef]
- FAO. World Food and Agriculture—Statistical Yearbook 2022; FAO: Rome, Italy, 2022; ISBN 9789251369302. [Google Scholar]
- U.S. Department of Agriculture, NASS. 2017 Census of Agriculture: United States Summary and State Data; U.S. Department of Agriculture: Washington, DC, USA, 2019; Volume 1, 820p. [Google Scholar]
- Wenchao, X.; Zhi, Y. Research on Strawberry Disease Diagnosis Based on Improved Residual Network Recognition Model. Math. Probl. Eng. 2022, 2022, 6431942. [Google Scholar] [CrossRef]
- Afzaal, U.; Bhattarai, B.; Pandeya, Y.R.; Lee, J. An Instance Segmentation Model for Strawberry Diseases Based on Mask R-CNN. Sensors 2021, 21, 6565. [Google Scholar] [CrossRef]
- Baggio, J.S.; Mertely, J.C.; Peres, N.A. Leaf Spot Diseases of Strawberry. Edis 2020, 2020, PP359. [Google Scholar] [CrossRef]
- Choi, J.Y.; Seo, K.; Cho, J.S.; Moon, K.D. Applying Convolutional Neural Networks to Assess the External Quality of Strawberries. J. Food Compos. Anal. 2021, 102, 104071. [Google Scholar] [CrossRef]
- Elanchezhian, A.; Basak, J.K.; Park, J.; Khan, F.; Okyere, F.G.; Lee, Y.; Bhujel, A.; Lee, D.; Sihalath, T.; Kim, H.T. Evaluating Different Models Used for Predicting the Indoor Microclimatic Parameters of a Greenhouse. Appl. Ecol. Environ. Res. 2020, 18, 2141–2161. [Google Scholar] [CrossRef]
- Jackulin, C.; Murugavalli, S. A Comprehensive Review on Detection of Plant Disease Using Machine Learning and Deep Learning Approaches. Meas. Sens. 2022, 24, 100441. [Google Scholar] [CrossRef]
- Chen, Y.; Lee, W.S.; Gan, H.; Peres, N.; Fraisse, C.; Zhang, Y.; He, Y. Strawberry Yield Prediction Based on a Deep Neural Network Using High-Resolution Aerial Orthoimages. Remote Sens. 2019, 11, 584. [Google Scholar] [CrossRef]
- Wang, D.; Cao, W.; Zhang, F.; Li, Z.; Xu, S.; Wu, X. A Review of Deep Learning in Multiscale Agricultural Sensing. Remote Sens. 2022, 14, 559. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X. Plant Diseases and Pests Detection Based on Deep Learning: A Review. Plant Methods 2021, 17, 22. [Google Scholar] [CrossRef]
- Arulmozhi, E.; Bhujel, A.; Moon, B.E.; Kim, H.T. The Application of Cameras in Precision Pig Farming: An Overview for Swine-Keeping Professionals. Animals 2021, 11, 2343. [Google Scholar] [CrossRef]
- Saiz-Rubio, V.; Rovira-Más, F. From Smart Farming towards Agriculture 5.0: A Review on Crop Data Management. Agronomy 2020, 10, 207. [Google Scholar] [CrossRef]
- Vimala Devi, P.; Vijayarekha, K. Machine Vision Applications to Locate Fruits, Detect Defects and Remove Noise: A Review. Rasayan J. Chem. 2014, 7, 104–113. [Google Scholar]
- Yang, D.; Li, S.; Peng, Z.; Wang, P.; Wang, J.; Yang, H. MF-CNN: Traffic Flow Prediction Using Convolutional Neural Network and Multi-Features Fusion. IEICE Trans. Inf. Syst. 2019, E102.D, 1526–1536. [Google Scholar] [CrossRef]
- Sundararajan, S.K.; Sankaragomathi, B.; Priya, D.S. Deep Belief CNN Feature Representation Based Content Based Image Retrieval for Medical Images. J. Med. Syst. 2019, 43, 174. [Google Scholar] [CrossRef]
- Melnyk, P.; You, Z.; Li, K. A High-Performance CNN Method for Offline Handwritten Chinese Character Recognition and Visualization. Soft Comput. 2020, 24, 7977–7987. [Google Scholar] [CrossRef]
- Li, J.; Mi, Y.; Li, G.; Ju, Z. CNN-Based Facial Expression Recognition from Annotated RGB-D Images for Human-Robot Interaction. Int. J. Humanoid Robot. 2019, 16, 1941002. [Google Scholar] [CrossRef]
- Kumar, S.; Singh, S.K. Occluded Thermal Face Recognition Using Bag of CNN (BoCNN). IEEE Signal Process. Lett. 2020, 27, 975–979. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Liu, M.; Zhu, J. Towards Better Analysis of Machine Learning Models: A Visual Analytics Perspective. Vis. Inform. 2017, 1, 48–56. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A Review of the Use of Convolutional Neural Networks in Agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Lee, S.; Arora, A.S.; Yun, C.M. Detecting Strawberry Diseases and Pest Infections in the Very Early Stage with an Ensemble Deep-Learning Model. Front. Plant Sci. 2022, 13, 991134. [Google Scholar] [CrossRef] [PubMed]
- Bhujel, A.; Khan, F.; Basak, J.K.; Jaihuni, M.; Sihalath, T.; Moon, B.E.; Park, J.; Kim, H.T. Detection of Gray Mold Disease and Its Severity on Strawberry Using Deep Learning Networks. J. Plant Dis. Prot. 2022, 129, 579–592. [Google Scholar] [CrossRef]
- Aleynikov, A.F.; Barillo, D.V. Application of Neural Convolutional Networks to Identify Fungal Diseases of Strawberry Leaves. IOP Conf. Ser. Earth Environ. Sci. 2021, 839, 032043. [Google Scholar] [CrossRef]
- Kewat, K. Plant Disease Classification Using Alex Net; Research Square: Durham, NC, USA, 2023. [Google Scholar]
- Nie, X.; Wang, L.; Ding, H.; Xu, M. Strawberry Verticillium Wilt Detection Network Based on Multi-Task Learning and Attention. IEEE Access 2019, 7, 170003–170011. [Google Scholar] [CrossRef]
- Alruwaili, M.; Siddiqi, M.H.; Khan, A.; Azad, M.; Khan, A.; Alanazi, S. RTF-RCNN: An Architecture for Real-Time Tomato Plant Leaf Diseases Detection in Video Streaming Using Faster-RCNN. Bioengineering 2022, 9, 565. [Google Scholar] [CrossRef]
- Brahimi, M.; Arsenovic, M.; Laraba, S.; Sladojevic, S.; Boukhalfa, K.; Moussaoui, A. Deep Learning for Plant Diseases: Detection and Saliency Map Visualisation BT—Human and Machine Learning: Visible, Explainable, Trustworthy and Transparent; Zhou, J., Chen, F., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 93–117. ISBN 978-3-319-90403-0. [Google Scholar]
- Zhou, C.; Hu, J.; Xu, Z.; Yue, J.; Ye, H.; Yang, G. A Novel Greenhouse-Based System for the Detection and Plumpness Assessment of Strawberry Using an Improved Deep Learning Technique. Front. Plant Sci. 2020, 11, 559. [Google Scholar] [CrossRef]
- Sustika, R.; Subekti, A.; Pardede, H.F.; Suryawati, E.; Mahendra, O.; Yuwana, S. Evaluation of Deep Convolutional Neural Network Architectures for Strawberry Quality Inspection. Int. J. Eng. Technol. 2018, 7, 75–80. [Google Scholar] [CrossRef]
- Amoriello, T.; Ciccoritti, R.; Ferrante, P. Prediction of Strawberries’ Quality Parameters Using Artificial Neural Networks. Agronomy 2022, 12, 963. [Google Scholar] [CrossRef]
- Aish, R.A.M. Strawberry Classification Using Deep Learning. Int. J. Acad. Inf. Syst. Res. 2021, 5, 6–13. [Google Scholar]
- Nassar, L.; Okwuchi, I.E.; Saad, M.; Karray, F.; Ponnambalam, K.; Agrawal, P. Prediction of Strawberry Yield and Farm Price Utilizing Deep Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Patil, A.; Rane, M. Convolutional Neural Networks: An Overview and Its Applications in Pattern Recognition. Smart Innov. Syst. Technol. 2021, 195, 21–30. [Google Scholar] [CrossRef]
- Manjula, K.; Spoorthi, S.; Yashaswini, R.; Sharma, D. Plant Disease Detection Using Deep Learning. Lect. Notes Electr. Eng. 2022, 783, 1389–1396. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions; Springer International Publishing: Cham, Switzerland, 2021; Volume 8, ISBN 4053702100444. [Google Scholar]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef]
- Ma, L.; Guo, X.; Zhao, S.; Yin, D.; Fu, Y.; Duan, P.; Wang, B.; Zhang, L. Algorithm of Strawberry Disease Recognition Based on Deep Convolutional Neural Network. Complexity 2021, 2021, 6683255. [Google Scholar] [CrossRef]
- Janocha, K.; Czarnecki, W.M. On Loss Functions for Deep Neural Networks in Classification. Schedae Inform. 2016, 25, 49–59. [Google Scholar] [CrossRef]
- Munkhdalai, L.; Munkhdalai, T.; Park, K.H.; Lee, H.G.; Li, M.; Ryu, K.H. Mixture of Activation Functions with Extended Min-Max Normalization for Forex Market Prediction. IEEE Access 2019, 7, 183680–183691. [Google Scholar] [CrossRef]
- Wojciuk, M.; Swiderska-Chadaj, Z.; Siwek, K.; Gertych, A. The Role of Hyperparameter Optimization in Fine-Tuning of Cnn Models; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar] [CrossRef]
- Labhsetwar, S.R.; Mumbai, N.; Deshpande, R.; Mumbai, N.; Haridas, S.; Mumbai, N.; Kolte, P.A.; Mumbai, N.; Panmand, R.; Mumbai, N.; et al. Performance Analysis of Optimizers for Plant Disease Classification with Convolutional Neural Networks. In Proceedings of the 2021 4th Biennial International Conference on Nascent Technologies in Engineering (ICNTE), Navi Mumbai, India, 15–16 January 2021. [Google Scholar]
- Cayamcela, M.E.M.; Lim, W. Fine-Tuning a Pre-Trained Convolutional Neural Network Model to Translate American Sign Language in Real-Time. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019. [Google Scholar] [CrossRef]
- Kandel, I.; Castelli, M. How Deeply to Fine-Tune a Convolutional Neural Network: A Case Study Using a Histopathology Dataset. Appl. Sci. 2020, 10, 3359. [Google Scholar] [CrossRef]
- Kundu, R.; Chauhan, U.; Chauhan, S.P.S. Plant Leaf Disease Detection Using Image Processing. In Proceedings of the 2022 2nd International Conference on Innovative Practices in Technology and Management (ICIPTM), Gautam Buddha Nagar, India, 23–25 February 2022; pp. 393–396. [Google Scholar] [CrossRef]
- Chen, H.C.; Widodo, A.M.; Wisnujati, A.; Rahaman, M.; Lin, J.C.W.; Chen, L.; Weng, C.E. AlexNet Convolutional Neural Network for Disease Detection and Classification of Tomato Leaf. Electronics 2022, 11, 951. [Google Scholar] [CrossRef]
- Kerre, D.; Muchiri, H. Detecting the Simultaneous Occurrence of Strawberry Fungal Leaf Diseases with a Deep Normalized CNN. In Proceedings of the ICMLT 2022: 2022 7th International Conference on Machine Learning Technologies, Rome, Italy, 11–13 March 2022; pp. 147–154. [Google Scholar] [CrossRef]
- Sujatha, R.; Chatterjee, J.M.; Jhanjhi, N.Z.; Brohi, S.N. Performance of Deep Learning vs. Machine Learning in Plant Leaf Disease Detection. Microprocess. Microsyst. 2021, 80, 103615. [Google Scholar] [CrossRef]
- Alatawi, A.A.; Alomani, S.M.; Alhawiti, N.I.; Ayaz, M. Plant Disease Detection Using AI Based VGG-16 Model. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 718–727. [Google Scholar] [CrossRef]
- Shin, J.; Chang, Y.K.; Heung, B.; Nguyen-Quang, T.; Price, G.W.; Al-Mallahi, A. A Deep Learning Approach for RGB Image-Based Powdery Mildew Disease Detection on Strawberry Leaves. Comput. Electron. Agric. 2021, 183, 106042. [Google Scholar] [CrossRef]
- Albahar, M. A Survey on Deep Learning and Its Impact on Agriculture: Challenges and Opportunities. Agriculture 2023, 13, 540. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, C. Modified U-Net for Plant Diseased Leaf Image Segmentation. Comput. Electron. Agric. 2023, 204, 107511. [Google Scholar] [CrossRef]
- Chowdhury, M.E.H.; Rahman, T.; Khandakar, A.; Ayari, M.A.; Khan, A.U.; Khan, M.S.; Al-Emadi, N.; Reaz, M.B.I.; Islam, M.T.; Ali, S.H.M. Automatic and Reliable Leaf Disease Detection Using Deep Learning Techniques. AgriEngineering 2021, 3, 294–312. [Google Scholar] [CrossRef]
- Khalid, M.; Sarfraz, M.S.; Iqbal, U.; Aftab, M.U.; Niedbała, G.; Rauf, H.T. Real-Time Plant Health Detection Using Deep Convolutional Neural Networks. Agriculture 2023, 13, 510. [Google Scholar] [CrossRef]
- Kundu, N. A review of the fruits detection and counting in agriculture using deep learning. Inspira-J. Com. Econ. Comput. Sci. 2020, 6, 75–78. [Google Scholar]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit Detection for Strawberry Harvesting Robot in Non-Structural Environment Based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Kalinina, M.; Nikolaev, P. Research of YOLO Architecture Models in Book Detection. In Proceedings of the 8th Scientific Conference on Information Technologies for Intelligent Decision Making Support (ITIDS 2020), Ufa, Russia, 6–9 October 2020; Atlantis Press: Dordrecht, The Netherlands, 2020; Volume 174, pp. 218–221. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Loganathan, P.; Karthikeyan, R.; Scholar, R. Residual Neural Network (ResNet) Based Plant Leaf Disease Detection and Classification. Turk. Online J. Qual. Inq. 2021, 12, 1395–1401. [Google Scholar]
- Kumar, V.; Arora, H.; Harsh; Sisodia, J. ResNet-Based Approach for Detection and Classification of Plant Leaf Diseases. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 495–502. [Google Scholar] [CrossRef]
- Patil, R.Y.; Gulavani, S.; Waghmare, V.B.; Mujawar, I.K. Image Based Anthracnose and Red-Rust Leaf Disease Detection Using Deep Learning. Telkomnika (Telecommun. Comput. Electron. Control) 2022, 20, 1256–1263. [Google Scholar] [CrossRef]
- Brodzicki, A.; Jaworek-Korjakowska, J.; Kleczek, P.; Garland, M.; Bogyo, M. Pre-Trained Deep Convolutional Neural Network for Clostridioides Difficile Bacteria Cytotoxicity Classification Based on Fluorescence Images. Sensors 2020, 20, 6713. [Google Scholar] [CrossRef] [PubMed]
- Korznikov, K.A.; Kislov, D.E.; Altman, J.; Doležal, J.; Vozmishcheva, A.S.; Krestov, P.V. Using U-Net-like Deep Convolutional Neural Networks for Precise Tree Recognition in Very High Resolution Rgb (Red, Green, Blue) Satellite Images. Forests 2021, 12, 66. [Google Scholar] [CrossRef]
- Santiago, A.; Solaque, L.; Velasco, A. Strawberry Disease Detection in Precision Agriculture. In Proceedings of the 18th International Conference on Informatics in Control, Automation and Robotics, ICINCO 2021, Paris, France, 6–8 July 2021; pp. 537–544. [Google Scholar]
- Xiao, J.-R.; Chung, P.-C.; Wu, H.-Y.; Phan, Q.-H.; Yeh, J.-L.A.; Hou, M.T. Detection of Strawberry Diseases Using a Convolutional Neural Network. Plants 2021, 10, 31. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Zhang, Z.; Yue, J.; Zhou, L. Classification of Strawberry Diseases and Pests by Improved AlexNet Deep Learning Networks. In Proceedings of the 2021 13th International Conference on Advanced Computational Intelligence, ICACI 2021, Wanzhou, China, 14–16 May 2021; pp. 359–364. [Google Scholar]
- Dong, C.; Zhang, Z.; Yue, J.; Zhou, L. Automatic Recognition of Strawberry Diseases and Pests Using Convolutional Neural Network. Smart Agric. Technol. 2021, 1, 100009. [Google Scholar] [CrossRef]
- Kim, B.; Han, Y.K.; Park, J.H.; Lee, J. Improved Vision-Based Detection of Strawberry Diseases Using a Deep Neural Network. Front. Plant Sci. 2021, 11, 559172. [Google Scholar] [CrossRef]
- You, J.; Jiang, K.; Lee, J. Deep Metric Learning-Based Strawberry Disease Detection with Unknowns. Front. Plant Sci. 2022, 13, 891785. [Google Scholar] [CrossRef]
- Hu, X.; Wang, R.; Du, J.; Hu, Y.; Jiao, L.; Xu, T. Class-Attention-Based Lesion Proposal Convolutional Neural Network for Strawberry Diseases Identification. Front. Plant Sci. 2023, 14, 1091600. [Google Scholar] [CrossRef]
- Zhang, B.; Tan, Q.; Yu, S.; Liu, Y.; Ou, Y.; Qiu, W. Gray Mold and Anthracnose Disease Detection on Strawberry Leaves Using Hyperspectral Imaging; Research Square: Durham, NC, USA, 2022. [Google Scholar]
- Habaragamuwa, H.; Ogawa, Y.; Suzuki, T.; Shiigi, T.; Ono, M.; Kondo, N. Detecting Greenhouse Strawberries (Mature and Immature), Using Deep Convolutional Neural Network. Eng. Agric. Environ. Food 2018, 11, 127–138. [Google Scholar] [CrossRef]
- Pérez-Borrero, I.; Marín-Santos, D.; Gegúndez-Arias, M.E.; Cortés-Ancos, E. A Fast and Accurate Deep Learning Method for Strawberry Instance Segmentation. Comput. Electron. Agric. 2020, 178, 105736. [Google Scholar] [CrossRef]
- Gao, Z.; Shao, Y.; Xuan, G.; Wang, Y.; Liu, Y.; Han, X. Real-Time Hyperspectral Imaging for the in-Field Estimation of Strawberry Ripeness with Deep Learning. Artif. Intell. Agric. 2020, 4, 31–38. [Google Scholar] [CrossRef]
- Guo-feng, Y.; Yong, Y.; Zi-kang, H.E.; Xin-yu, Z.; Yong, H.E. A Rapid, Low-Cost Deep Learning System to Classify Strawberry Disease Based on Cloud Service. J. Integr. Agric. 2022, 21, 460–473. [Google Scholar] [CrossRef]
- Chohan, M.; Khan, A.; Chohan, R.; Katper, S.; Mahar, M. Plant Disease Detection Using Deep Learning. Int. J. Recent. Technol. Eng. 2020, 9, 909–914. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed]
- Liao, T.; Yang, R.; Zhao, P.; Zhou, W.; He, M.; Li, L. MDAM-DRNet: Dual Channel Residual Network with Multi-Directional Attention Mechanism in Strawberry Leaf Diseases Detection. Front. Plant Sci. 2022, 13, 869524. [Google Scholar] [CrossRef]
- Ferentinos, K.P. Deep Learning Models for Plant Disease Detection and Diagnosis. Comput. Electron. Agric. 2018, 145, 311–318. [Google Scholar] [CrossRef]
- Patel, A.M.; Lee, W.S.; Peres, N.A. Imaging and Deep Learning Based Approach to Leaf Wetness Detection in Strawberry. Sensors 2022, 22, 8558. [Google Scholar] [CrossRef]
- Van Kruistum, G.; Blom, G.; Meurs, B.; Evenhuis, B. Malformation of Strawberry Fruit (Fragaria × Ananassa) in Glasshouse Production in Spring. Acta Hortic. 2006, 708, 413–416. [Google Scholar] [CrossRef]
- Patel, A.; Lee, W.S.; Peres, N.A.; Fraisse, C.W. Strawberry Plant Wetness Detection Using Computer Vision and Deep Learning. Smart Agric. Technol. 2021, 1, 100013. [Google Scholar] [CrossRef]
- Montone, V.O.; Fraisse, C.W.; Peres, N.A.; Sentelhas, P.C.; Gleason, M.; Ellis, M.; Schnabel, G. Evaluation of Leaf Wetness Duration Models for Operational Use in Strawberry Disease-Warning Systems in Four US States. Int. J. Biometeorol. 2016, 60, 1761–1774. [Google Scholar] [CrossRef] [PubMed]
- Swarup, A.; Lee, W.S.; Peres, N.; Fraisse, C. Strawberry Plant Wetness Detection Using Color and Thermal Imaging. J. Biosyst. Eng. 2020, 45, 409–421. [Google Scholar] [CrossRef]
- Schmidt, J.; Marques, M.R.G.; Botti, S.; Marques, M.A.L. Recent Advances and Applications of Machine Learning in Solid-State Materials Science. NPJ Comput. Mater. 2019, 5, 83. [Google Scholar] [CrossRef]
- Elaraby, A.; Hamdy, W.; Alruwaili, M. Optimization of Deep Learning Model for Plant Disease Detection Using Particle Swarm Optimizer. Comput. Mater. Contin. 2022, 71, 4019–4031. [Google Scholar] [CrossRef]


| Common Strawberry Diseases | Description |
|---|---|
| Bacterial wilt | This disease, also referred to as strawberry leaf blight, is distinguished by dry, brown necrotic leaf patches and huge brown V-shaped lesions along the leaf margin, midrib, and major veins, which are caused by Pseudomonas solanacearum. |
| Verticillium wilt | It is caused by Verticillium dahliae (Kleb.), a soil-borne plant fungus that can lay dormant in the soil for years until it recognizes the presence of a healthy strawberry plant less than 2 mm away. When this happens, the fungus produces lengthy hyphae that feed on the plant. |
| Leaf spot | The disease, known as Mycospherella leaf spot, is caused by the fungus Mycosphaerella fragariae and is one of the most common illnesses in strawberries. The fungi mostly damage the leaflets, causing them to turn purple, which eventually turns brown. |
| Angular leaf spot | The disease, commonly known as bacterium stain, is caused by the bacteria Xanthomonas fragaria. The term is obtained by the appearance of pale green dots that grow until they are visible on the sheet. |
| Anthracnose fruit rot | It is a rot produced by Colletotrichum fragariae, Colletotrichum acutatum, and Colletotrichum gloeoporioides. When the plant is subjected to high temperatures and humidity, rot develops. |
| Blossom blight | It caused by Pseudomonas marginalis and disease symptoms began with gray sporulation of the fungus on the stigmas and anthers of strawberry flowers, followed by necrosis and complete flower abortion |
| Snake eye | It is a widespread disease caused by microclimate changes, such as night temperature increase and a wet environment, that can damage strawberries at any stage of development. Infections are recognized by the appearance of small, deep purple/brown, spots shaped like round snake eyes on the plant’s upper leaf surface. |
| Gray mold | Caused by the Botrytis cinerea Pers. F. fungi or simply Botrytis. The name gray mold is given due to the appearance of gray-colored mold formed on the leaf and calyx, which may affect the fruit. |
| Powdery mildew leaf | Caused by the Sphaerotheca macularis fungi. Powdery mildew is caused when the plantation is submitted to a dry and hot climate. It manifests as the apparition of whitish spots on the inferior face of the leaf. It also affects the fruits and can be observed by the fruit’s discoloration and spots. |
| Powdery mildew | It is caused by Sphaerotheca macularis fungi, affects the fruits, and can be observed by the fruit’s discoloration and spots. |
| Botrytis rot | Botrytis rot or fruit rot is caused by Botrytis cinerea Pers. F. fungi or simply Botrytis. It can infect strawberry flowers when spores land on them and are exposed to free water during cool weather. Infections can either cause flowers to rot or Botrytis can become dormant in floral tissues. |
| Dataset Name | Collection Environment | Link |
|---|---|---|
| PlantVillage-Dataset: 50,000 images of classified plant diseases of 14 crop varieties and 26 diseases | Field—detached leaves on a plain background | https://github.com/spMohanty/PlantVillage-Dataset (accessed on 6 November 2023) |
| New Plant Diseases Dataset (Augmented): 87 K RBB images of healthy and diseased crop leaves, which are categorized into 38 different classes | Detached leaves on a plain background | https://www.kaggle.com/vipoooool/new-plant-diseases-dataset/ (accessed on 6 November 2023) |
| 38 disease classes from the PlantVillage dataset and 1 background class from Stanford’s open dataset of background images—DAGS | Network | https://github.com/MarkoArsenovic/DeepLearning_PlantDiseases (accessed on 6 November 2023) |
| PlantDoc dataset: 2598 data points in total across 13 plant species and up to 17 classes of diseases | Field | https://github.com/pratikkayal/PlantDoc-Object-Detection-Dataset (accessed on 6 November 2023) https://github.com/pratikkayal/PlantDoc-Dataset (accessed on 6 November 2023) |
| IP102: Insect Pest Recognition Database: 75,000 images belonging to 102 categories | Field | https://github.com/xpwu95/IP102 (accessed on 6 November 2023) |
| Dataset of annotated strawberry fruits images with various developmental stages | Field | https://data.mendeley.com/datasets/z6dtfdpzz8/1 (accessed on 6 November 2023) |
| Use of Fourier transform infrared spectroscopy and partial least squares regression for the detection of the adulteration of strawberry purees | Field | https://csr.quadram.ac.uk/example-datasets-for-download/ (accessed on 6 November 2023) |
| Strawberry Disease Detection Dataset (SDDD)—2500 images for seven different types of strawberry diseases | Field | https://www.kaggle.com/datasets/usmanafzaal/strawberry-disease-detection-dataset (accessed on 6 November 2023) |
| Strawberry wilt disease Dataset | Field | https://github.com/boxyao/Strawberry_wilt_dataset (accessed on 6 November 2023) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.-W.; Kim, H.-I. An Overview of Recent Advances in Greenhouse Strawberry Cultivation Using Deep Learning Techniques: A Review for Strawberry Practitioners. Agronomy 2024, 14, 34. https://doi.org/10.3390/agronomy14010034
Yang J-W, Kim H-I. An Overview of Recent Advances in Greenhouse Strawberry Cultivation Using Deep Learning Techniques: A Review for Strawberry Practitioners. Agronomy. 2024; 14(1):34. https://doi.org/10.3390/agronomy14010034
Chicago/Turabian StyleYang, Jong-Won, and Hyun-Il Kim. 2024. "An Overview of Recent Advances in Greenhouse Strawberry Cultivation Using Deep Learning Techniques: A Review for Strawberry Practitioners" Agronomy 14, no. 1: 34. https://doi.org/10.3390/agronomy14010034
APA StyleYang, J.-W., & Kim, H.-I. (2024). An Overview of Recent Advances in Greenhouse Strawberry Cultivation Using Deep Learning Techniques: A Review for Strawberry Practitioners. Agronomy, 14(1), 34. https://doi.org/10.3390/agronomy14010034