
DCS-YOLOv5s: A Lightweight Algorithm for Multi-Target Recognition of Potato Seed Potatoes Based on YOLOv5s

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Assembly
2.2. Enhancements to the YOLOv5s Model
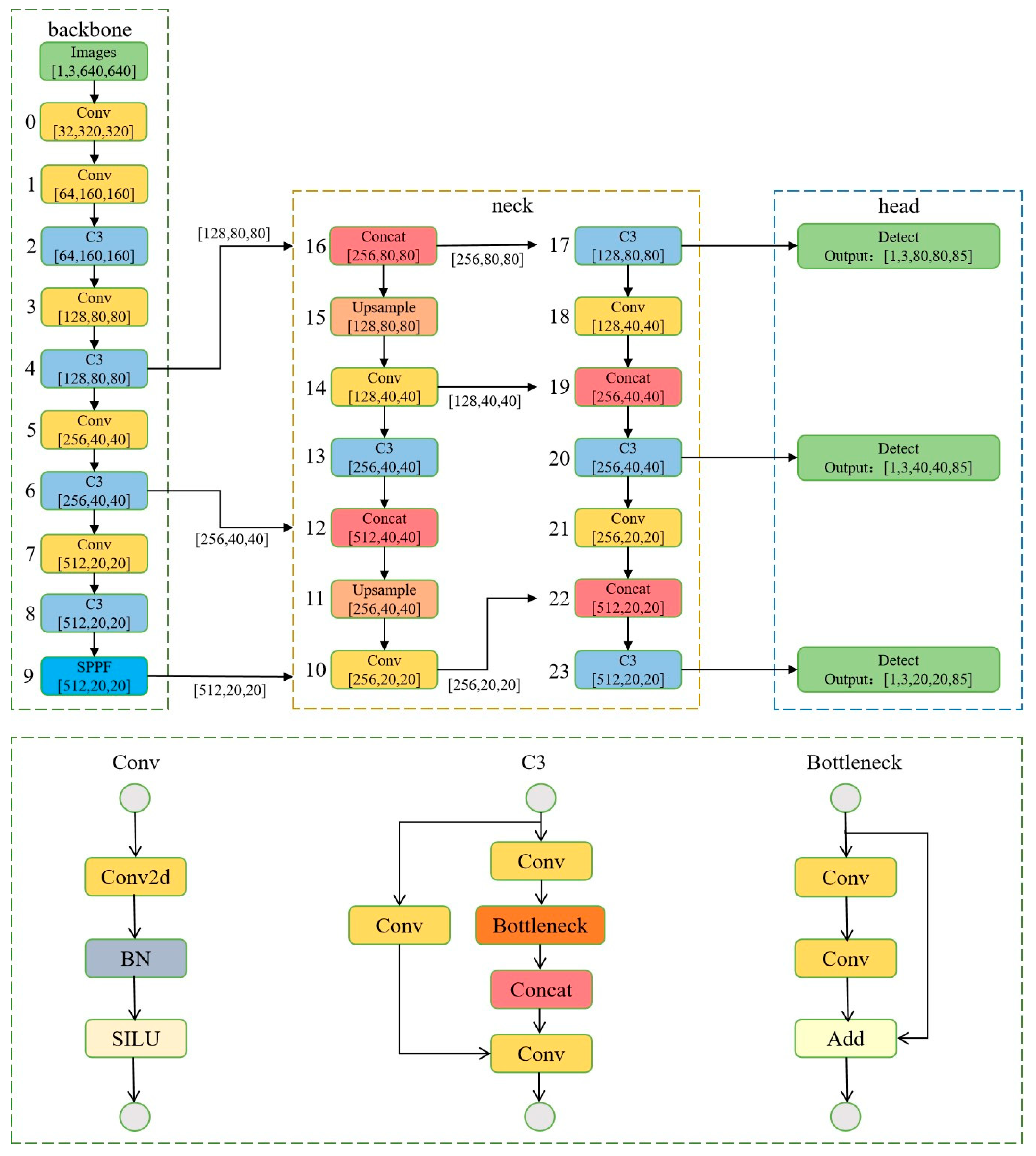
2.2.1. Underlying Framework of the YOLOv5s Network
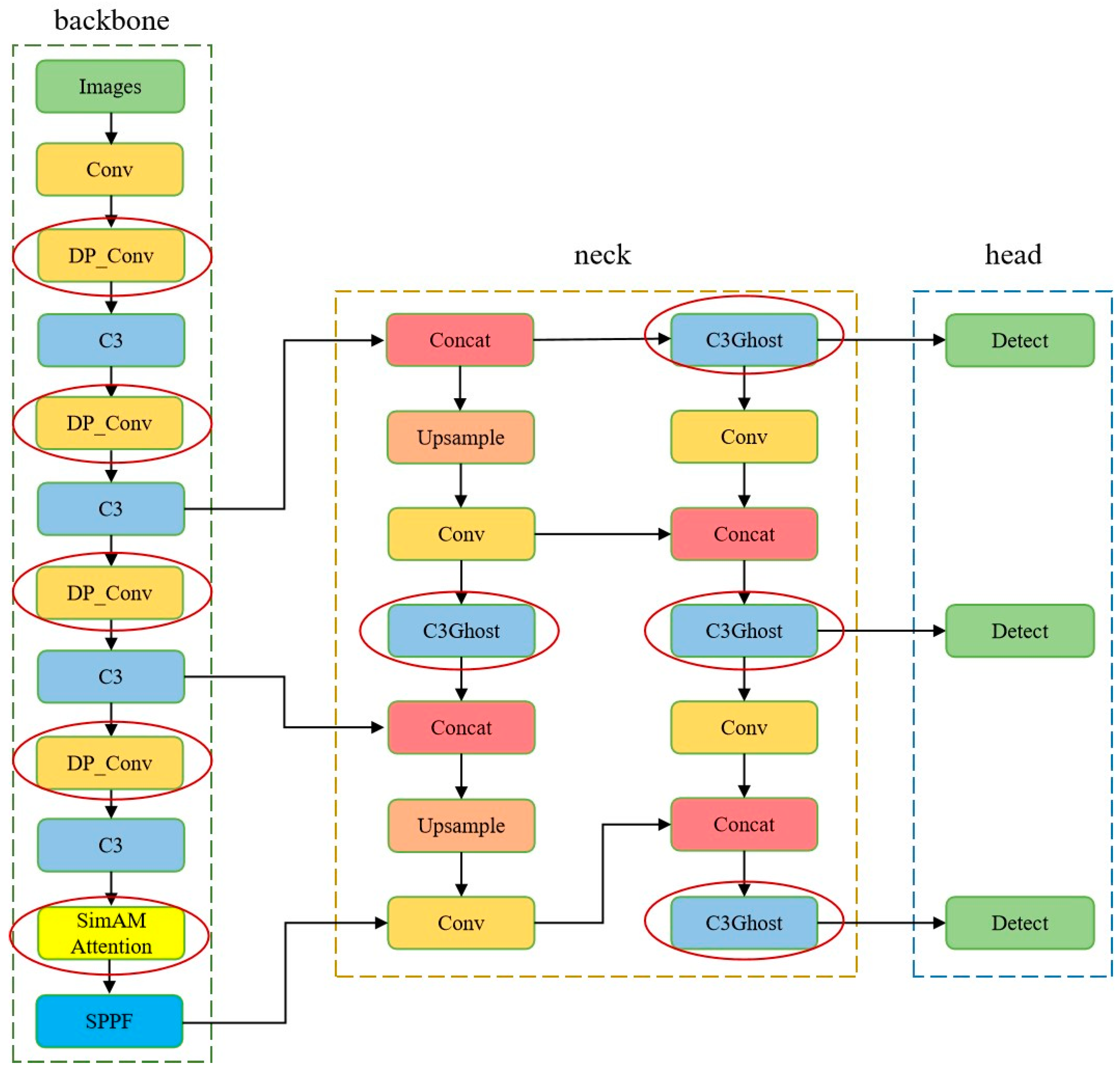
2.2.2. Streamlining the Backbone Network
2.2.3. Streamlining the Neck Network
2.2.4. Incorporation of the Attention Mechanism
2.2.5. Improved YOLOv5s-Based Network Architecture
2.3. Experimental Apparatus
3. Results
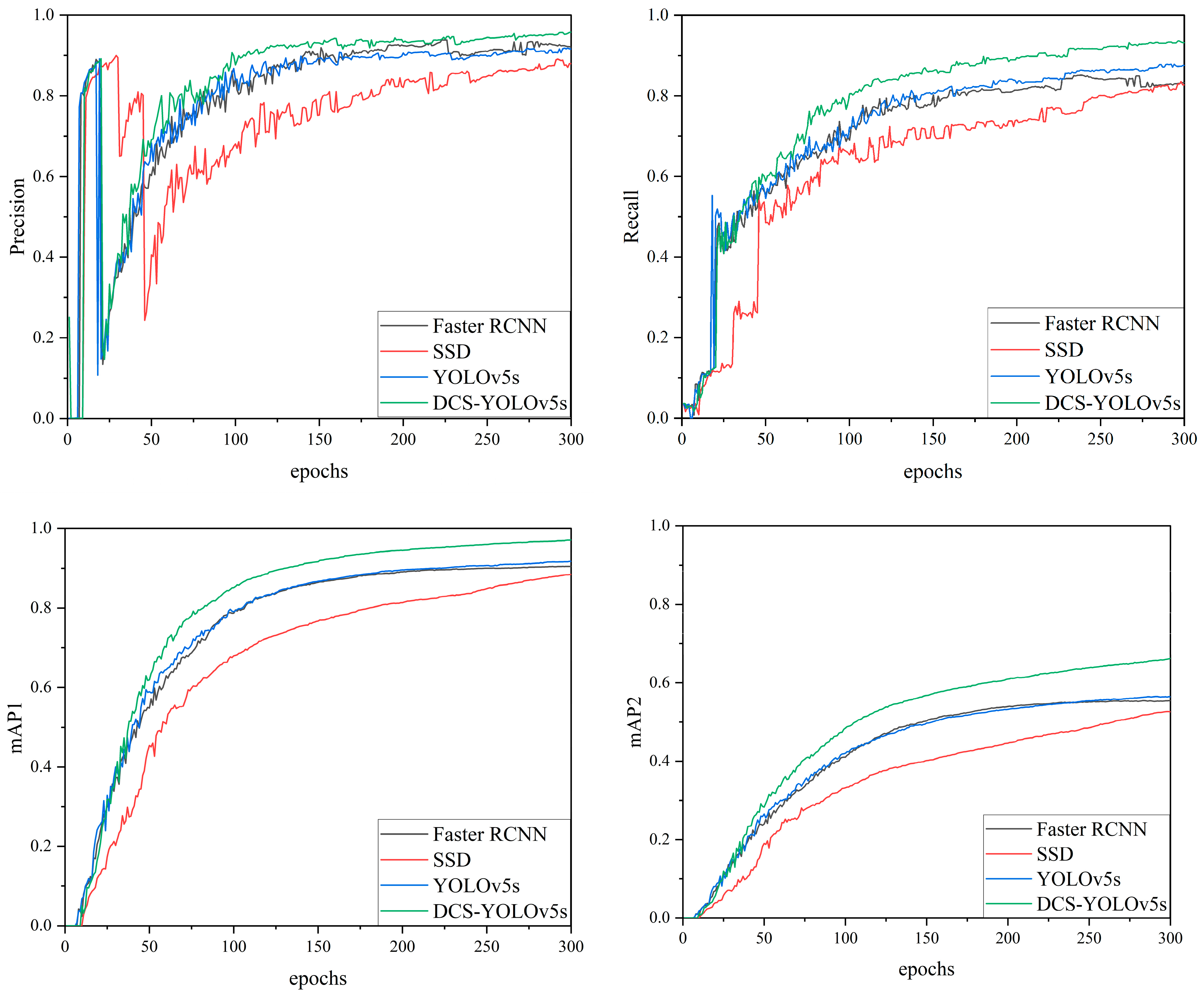
3.1. Comparative Experimental Results with Other Models
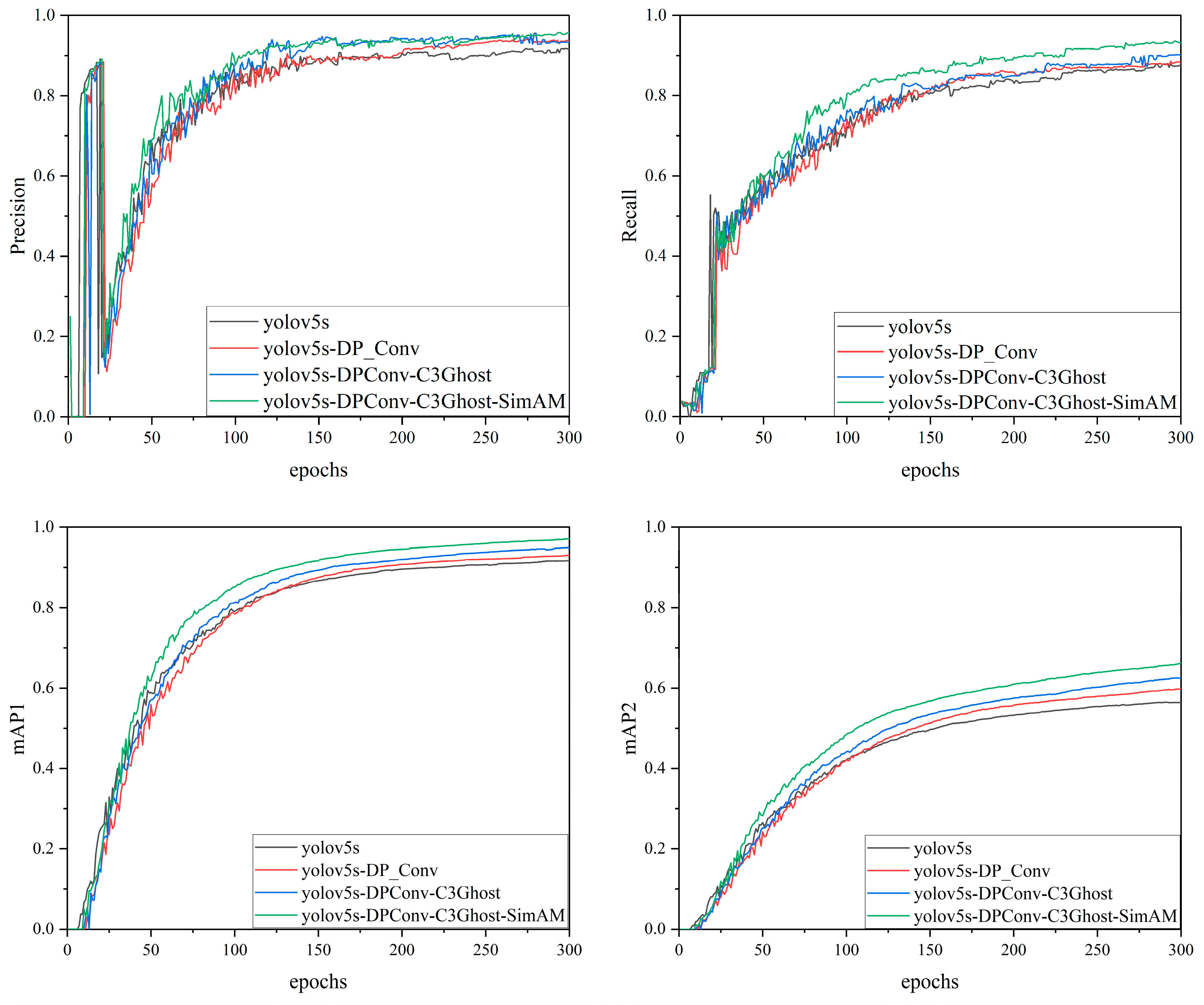
3.2. Ablation Study
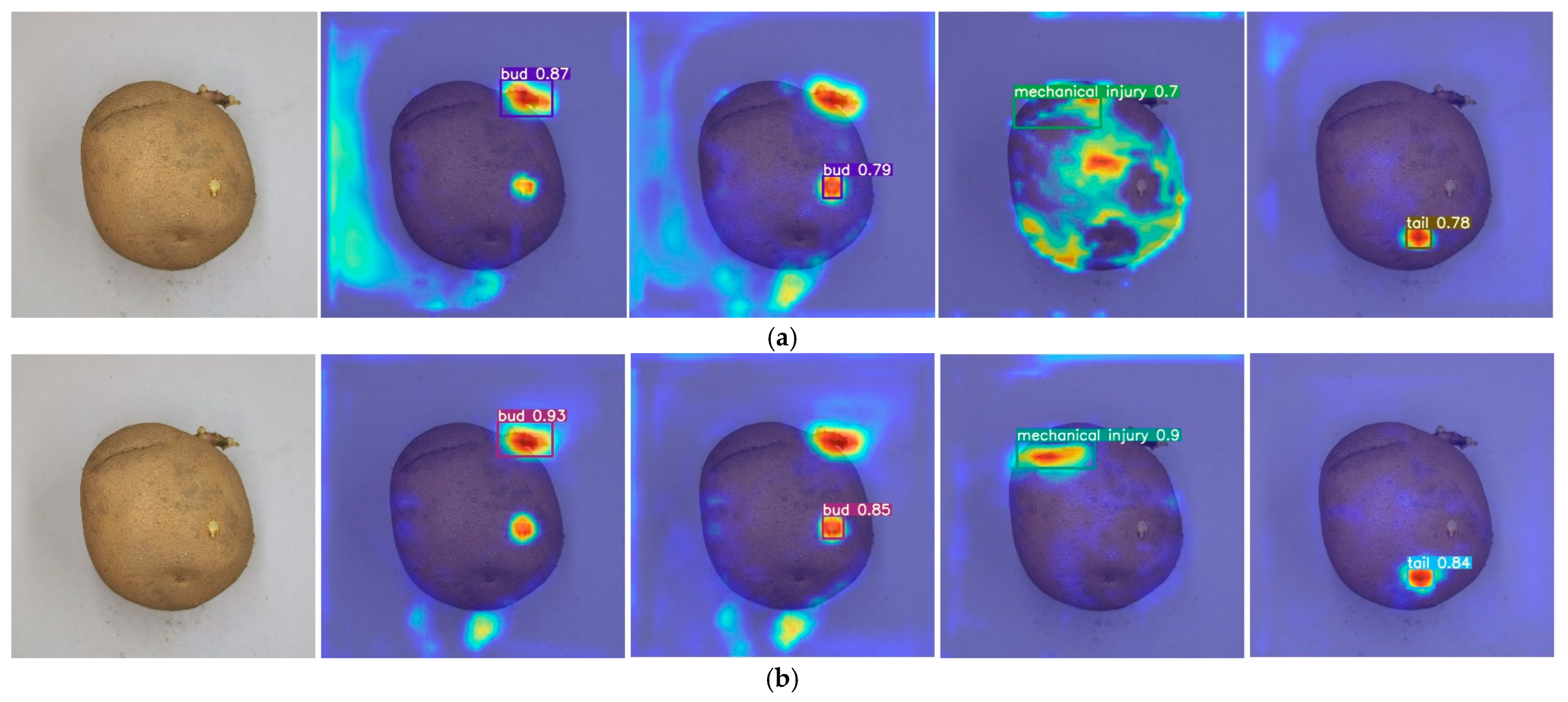
3.3. Post-Improvement Model Result Analysis through Multi-Stage Enhancements
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Devaux, A.; Goffart, J.-P.; Kromann, P.; Andrade-Piedra, J.; Polar, V.; Hareau, G. The potato of the future: Opportunities and challenges in sustainable agri-food systems. Potato Res. 2021, 64, 681–720. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Larkin, R.; Honeycutt, W. Sustainable Potato Production: Global Case Studies; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Xu, N.; Zhang, H.; Zhang, R.; Xu, Y. Current situation and prospect of potato planting in China. Chin. Potato J. 2021, 35, 81–96. [Google Scholar]
- Li, Z.; Wen, X.; Lv, J.; Li, J.; Yi, S.; Qiao, D. Analysis and prospect of research progress on key technologies and equipments of mechanization of potato planting. Trans. Chin. Soc. Agric. Mach. 2019, 50, 1–16. [Google Scholar]
- Yang, Z.; Sun, W.; Liu, F.; Zhang, Y.; Chen, X.; Wei, Z.; Li, X. Field collaborative recognition method and experiment for thermal infrared imaging of damaged potatoes. Comput. Electron. Agric. 2024, 223, 109096. [Google Scholar] [CrossRef]
- Lv, X.; Zhang, X.; Gao, H.; He, T.; Lv, Z.; Zhangzhong, L. When Crops meet Machine Vision: A review and development framework for a low-cost nondestructive online monitoring technology in agricultural production. Agric. Commun. 2024, 2, 100029. [Google Scholar] [CrossRef]
- Xu, J.; Lu, Y. Prototyping and evaluation of a novel machine vision system for real-time, automated quality grading of sweetpotatoes. Comput. Electron. Agric. 2024, 219, 108826. [Google Scholar] [CrossRef]
- Bi, S.; Gao, F.; Chen, J.; Zhang, L. Detection method of citrus based on deep convolution neural network. Trans. Chin. Soc. Agric. Mach. 2019, 50, 181–186. [Google Scholar]
- Xie, W.; Ding, W.; Wang, F.; Wei, S.; Yang, D. Integrity recognition of camellia oleifera seeds based on convolutional neural network. Trans. Chin. Soc. Agric. Mach. 2020, 51, 13–21. [Google Scholar]
- Mao, S.; Liu, Z.; Luo, Y. A deep learning-based method for estimating the main stem length of sweet potato seedlings. Measurement 2024, 238, 115388. [Google Scholar] [CrossRef]
- Yang, Y.; Zhao, X.; Huang, M.; Wang, X.; Zhu, Q. Multispectral image based germination detection of potato by using supervised multiple threshold segmentation model and Canny edge detector. Comput. Electron. Agric. 2021, 182, 106041. [Google Scholar] [CrossRef]
- Ji, Y.; Sun, L. Nondestructive Classification of Potatoes Based on HSI and Clustering. In Proceedings of the 2019 4th International Conference on Measurement, Information and Control (ICMIC), Harbin, China, 23–25 August 2019; pp. 73–77. [Google Scholar]
- Li, Y.; Li, T.; Niu, Z.; Wu, Y.; Zhang, Z.; Hou, J. Potato bud eyes recognition based on three-dimensional geometric features of color saturation. Trans. CSAE 2019, 34, 158–164. [Google Scholar]
- Lopez-Juarez, I.; Rios-Cabrera, R.; Hsieh, S.; Howarth, M. A hybrid non-invasive method for internal/external quality assessment of potatoes. Eur. Food Res. Technol. 2018, 244, 161–174. [Google Scholar] [CrossRef]
- Xi, R.; Hou, J.; Li, L. Fast segmentation on potato buds with chaos optimization-based K-means algorithm. Trans. Chin. Soc. Agric. Eng. 2019, 35, 190. [Google Scholar]
- Barnes, M.; Duckett, T.; Cielniak, G.; Stroud, G.; Harper, G. Visual detection of blemishes in potatoes using minimalist boosted classifiers. J. Food Eng. 2010, 98, 339–346. [Google Scholar] [CrossRef]
- Liu, D.; Li, S.; Cao, Z. State-of-the-art on deep learning and its application in image object classification and detection. Comput. Sci. 2016, 43, 13–23. [Google Scholar]
- Cummins, N.; Baird, A.; Schuller, B.W. Speech analysis for health: Current state-of-the-art and the increasing impact of deep learning. Methods 2018, 151, 41–54. [Google Scholar] [CrossRef]
- Lan, Y.; Zhao, D.; Zhang, Y.; Zhu, J. Exploration and development prospect of eco-unmanned farm modes. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2021, 37, 312–327. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ouf, N.S. Leguminous seeds detection based on convolutional neural networks: Comparison of faster R-CNN and YOLOv4 on a small custom dataset. Artif. Intell. Agric. 2023, 8, 30–45. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lee, H.-S.; Shin, B.-S. Potato detection and segmentation based on mask R-CNN. J. Biosyst. Eng. 2020, 45, 233–238. [Google Scholar] [CrossRef]
- Li, J.; Lin, L.; Tian, K.; Alaa, A.A. Detection of leaf diseases of balsam pear in the field based on improved Faster R-CNN. Trans. Chin. Soc. Agric. Eng. 2020, 36, 179–185. [Google Scholar]
- Chen, K.; Zhu, L.; Song, P.; Tian, X.; Huang, C.; Nie, X.; Xiao, A.; He, L. Recognition of cotton terminal bud in field using improved Faster R-CNN by integrating dynamic mechanism. Trans. CSAE 2021, 37, 161–168. [Google Scholar]
- Xi, R.; Jiang, K.; Zhang, W.; Lv, Z.; Hou, J. Recognition method for potato buds based on improved faster R-CNN. Trans. Chin. Soc. Agric. Mach. 2020, 51, 216–223. [Google Scholar]
- Liang, X.; Zhang, X.; Wang, Y. Recognition method for the pruning points of tomato lateral branches using improved Mask R-CNN. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 112–121. [Google Scholar]
- Shi, Y.; Qing, S.; Zhao, L.; Wang, F.; Yuwen, X.; Qu, M. YOLO-Peach: A High-Performance Lightweight YOLOv8s-Based Model for Accurate Recognition and Enumeration of Peach Seedling Fruits. Agronomy 2024, 14, 1628. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. 2016; pp. 21–37. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, X.; Zhao, Q.; Jiang, P.; Zheng, Y.; Yuan, L.; Yuan, P. LDS-YOLO: A lightweight small object detection method for dead trees from shelter forest. Comput. Electron. Agric. 2022, 198, 107035. [Google Scholar] [CrossRef]
- Dang, F.; Chen, D.; Lu, Y.; Li, Z. YOLOWeeds: A novel benchmark of YOLO object detectors for multi-class weed detection in cotton production systems. Comput. Electron. Agric. 2023, 205, 107655. [Google Scholar] [CrossRef]
- Shi, F.; Wang, H.; Huang, H. Research on potato buds detection and recognition based on convolutional neural network. J. Chin. Agric. Mech. 2022, 43, 159. [Google Scholar]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, S.; Li, X. Design and experiment of directional arrangement vertical and horizontal cutting of seed potato cutter. Trans. Chin. Soc. Agric. Mach. 2020, 51, 334–345. [Google Scholar]
- Yi, S.; Li, J.; Zhang, P. Detecting and counting of spring-see citrus using YOLOv4 network model and recursive fusion of features. Trans. Chin. Soc. Agric. Eng. 2021, 37, 161–169. [Google Scholar]
- Kaur, G.; Sivia, J.S. Development of deep and machine learning convolutional networks of variable spatial resolution for automatic detection of leaf blast disease of rice. Comput. Electron. Agric. 2024, 224, 109210. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, M.; Yang, Z.; Li, J.; Zhao, L. An improved target detection method based on YOLOv5 in natural orchard environments. Comput. Electron. Agric. 2024, 219, 108780. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Qin, X.; Li, N.; Weng, C.; Su, D.; Li, M. Simple attention module based speaker verification with iterative noisy label detection. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6722–6726. [Google Scholar]
- Zhang, W.; Zhang, H.; Liu, S.; Zeng, X.; Mu, G. Detection of potato seed buds based on an improved YOLOv7 model. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2023, 39, 148–158. [Google Scholar]
- Luo, T. Research on Potato Defect Detection Based on Improved YOLOv7. Master’s Thesis, Ningxia University, Yinchuan, China, 2023. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P (%) | R (%) | mAP1 (%) | mAP2 (%) |
|---|---|---|---|---|
| Faster RCNN | 92.0 | 83.3 | 90.5 | 55.4 |
| SSD | 88.0 | 82.8 | 88.4 | 52.6 |
| YOLOv5s | 91.6 | 87.5 | 91.7 | 56.4 |
| DCS-YOLOv5s | 95.8 | 93.2 | 97.1 | 66.2 |
| Model | Parameter Volume | FLOPs (G) | Weight Size (MB) | FPS |
|---|---|---|---|---|
| Faster RCNN | 59.26 × 106 | 132.4 | 105.5 | 9 |
| SSD | 24.28 × 106 | 85.6 | 78.9 | 44 |
| YOLOv5s | 7.03 × 106 | 16.0 | 11.8 | 58 |
| DCS-YOLOv5s | 4.68 × 106 | 10.7 | 9.2 | 65 |
| Number | DP_Conv | C3Ghost | SimAM | P (%) | R (%) | mAP1 (%) | mAP2 (%) |
|---|---|---|---|---|---|---|---|
| 1 | - | - | - | 91.6 | 87.5 | 91.7 | 56.4 |
| 2 | √ | - | - | 93.7 | 88.3 | 93.0 | 59.8 |
| 3 | √ | √ | - | 93.4 | 90.2 | 94.7 | 62.5 |
| 4 | √ | √ | √ | 95.8 | 93.2 | 97.1 | 66.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Wang, W.; Jin, X.; Wang, F.; He, Z.; Ji, J.; Jin, S. DCS-YOLOv5s: A Lightweight Algorithm for Multi-Target Recognition of Potato Seed Potatoes Based on YOLOv5s. Agronomy 2024, 14, 2558. https://doi.org/10.3390/agronomy14112558
Qiu Z, Wang W, Jin X, Wang F, He Z, Ji J, Jin S. DCS-YOLOv5s: A Lightweight Algorithm for Multi-Target Recognition of Potato Seed Potatoes Based on YOLOv5s. Agronomy. 2024; 14(11):2558. https://doi.org/10.3390/agronomy14112558
Chicago/Turabian StyleQiu, Zhaomei, Weili Wang, Xin Jin, Fei Wang, Zhitao He, Jiangtao Ji, and Shanshan Jin. 2024. "DCS-YOLOv5s: A Lightweight Algorithm for Multi-Target Recognition of Potato Seed Potatoes Based on YOLOv5s" Agronomy 14, no. 11: 2558. https://doi.org/10.3390/agronomy14112558
APA StyleQiu, Z., Wang, W., Jin, X., Wang, F., He, Z., Ji, J., & Jin, S. (2024). DCS-YOLOv5s: A Lightweight Algorithm for Multi-Target Recognition of Potato Seed Potatoes Based on YOLOv5s. Agronomy, 14(11), 2558. https://doi.org/10.3390/agronomy14112558