

Prediction Models of Growth Characteristics and Yield for Chinese Winter Wheat Based on Machine Learning

 ,
, 
Abstract
1. Introduction
2. Data Sources and Research Methods
2.1. Data Sources
2.2. Research Methods
2.3. Regression Models in Machine Learning
2.4. Data Analysis
3. Results and Analysis
3.1. Comparison of Predictive Regression Models
3.2. Validation of Predictive Regression Models
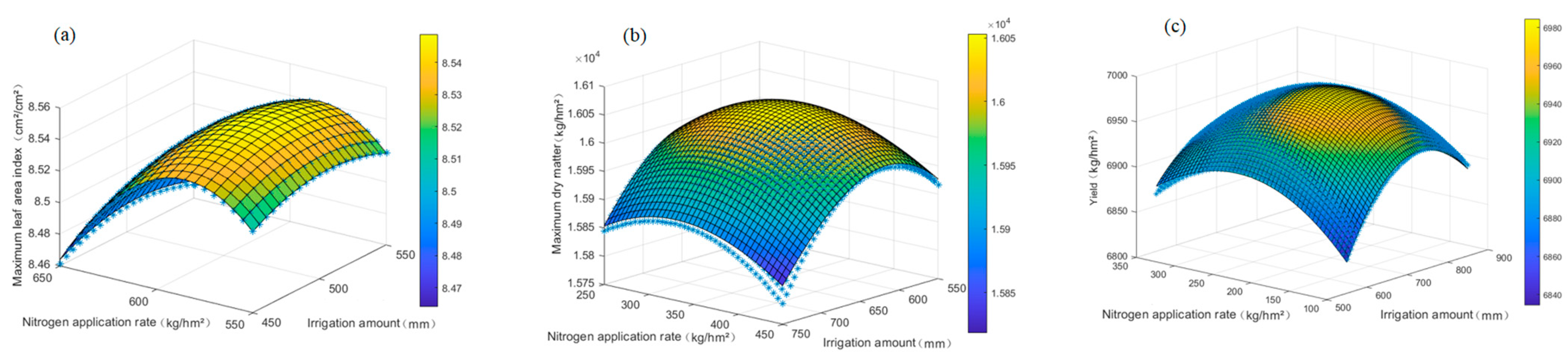
3.3. Construction of Water and Fertilizer Coupling Function
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.J.; Chen, Y.L.; Xiao, G. A review of crop yield prediction based on machine learning. Anhui Agric. Sci. Bull. 2021, 27, 117–119+134. [Google Scholar]
- Pei, Z.J.; Liu, J.; Shi, F.M.; Wang, S.; Lu, F.Y. Research process on the eEffect of climate change about the agricultural production of China. Heilongjiang Agric. Sci. 2017, 8, 112–118. [Google Scholar]
- Fang, J.Y. Global Ecology: Climate Change and Ecological Responses; Beijing Higher Education Press: Beijing, China, 2000. [Google Scholar]
- Su, L.J.; Liu, Y.H.; Wang, Q.J. Rice growth model in China based on growing degree days. Trans. Chin. Soc. Agric. Eng. 2020, 36, 162–174. [Google Scholar]
- Su, L.; Wen, T.; Tao, W.; Deng, M.; Yuan, S.; Zeng, S.; Wang, Q. Growth Indexes and Yield Prediction of Summer Maize in China Based on Supervised Machine Learning Method. Agronomy 2023, 13, 132. [Google Scholar] [CrossRef]
- Zhang, P.; Chen, Z.M.; Liu, C.W.; Wang, F.Z.; Jiang, H.D.; Gao, P. Method for the prediction of wheat yield components. Trans. Chin. Soc. Agric. Eng. 2020, 36, 78–87. [Google Scholar]
- Lin, S.; Deng, M.; Wei, K.; Wang, Q.; Su, L. A new regional cotton growth model based on reference crop evapotranspiration for predicting growth processes. Sci. Rep. 2023, 13, 7368. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Su, L.; Wang, Q.; Zhang, J.; Shan, Y.; Deng, M. Chapter Six–Comprehensive and quantitative analysis of growth characteristics of winter wheat in China based on growing degree days. In Advances in Agronomy; Sparks, D.L., Ed.; Academic Press: Cambridge, MA, USA, 2020; Volume 159, pp. 237–273. [Google Scholar]
- Wang, K.; Su, L.; Wang, Q. Cotton growth model under drip irrigation with film mulching: A case study of Xinjiang, China. Agron. J. 2021, 113, 2417–2436. [Google Scholar] [CrossRef]
- Zhou, Y.X.; Wang, Q.J.; Zhang, J.H.; Tan, S.; He, B. Simulation analysis of the impact of climate change on the yield of winter wheat in Shaanxi Province based on the AquaCrop model. Res. Soil Water Conserv. 2018, 25, 357–364. [Google Scholar]
- Yao, N.; Zhou, Y.G.; Song, L.B.; Liu, J.; Li, Y.; Wu, S.F.; Feng, H.; He, J.Q. Parameter estimation and verification of DSSAT-CERES-Wheat model for simulation of growth and development of winter wheat under water stresses at different growth stages. Trans. Chin. Soc. Agric. Eng. 2015, 31, 138–150. [Google Scholar]
- Khanal, S.; Fulton, J.; Klopfenstein, A.; Douridas, N.; Shearer, S. Integration of high resolution remotely sensed data and machine learning techniques for spatial prediction of soil properties and corn yield. Comput. Electron. Agric. 2018, 153, 213–225. [Google Scholar] [CrossRef]
- Leng, G.; Hall, J.W. Predicting spatial and temporal variability in crop yields: An inter-comparison of machine learning, regression and process-based models. Environ. Res. Lett. 2020, 15, 044027. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Liu, Y.; Ata-Ul-Karim, S.T.; Ge, Q.; Li, X.; Xiao, J. Integrating climate and satellite remote sensing data for predicting county-level wheat yield in China using machine learning methods. Int. J. Appl. Earth Obs. Geoinf. 2022, 111, 102861. [Google Scholar] [CrossRef]
- Shi, J.; Huang, W.; Fan, X.; Li, X.; Lu, Y.; Jiang, Z.; Wang, Z.; Luo, W.; Zhang, M. Yield Prediction Models in Guangxi Sugarcane Planting Regions Based on Machine Learning Methods. Smart Agric. 2023, 5, 82–92. [Google Scholar]
- Liu, J.M.; He, X.T.; Wang, P.X.; Huang, J.X. Early prediction of winter wheat yield with long time series meteorological data and random forest method. Trans. Chin. Soc. Agric. Eng. 2019, 35, 158–166. [Google Scholar]
- Li, L.; Wang, B.; Feng, P.; Wang, H.; He, Q.; Wang, Y.; Liu, D.L.; Li, Y.; He, J.; Feng, H.; et al. Crop yield forecasting and associated optimum lead time analysis based on multi-source environmental data across China. Agric. For. Meteorol. 2021, 308–309, 108558. [Google Scholar] [CrossRef]
- Yan, H.J.; Zhuo, Y.; Li, M.N.; Wang, Y.L.; Guo, H.; Wang, J.J.; Li, C.S.; Ding, F. Alfalfa yield prediction using machine learning and UAV multispectral remote sensing. Trans. Chin. Soc. Agric. Eng. 2022, 38, 64–71. [Google Scholar]
- Sun, S.J.; Wu, M.X.; Zhuang, L.W.; He, Y.B.; Li, X. Forecasting winter wheat yield at county level using CNN and BP neural networks. Trans. Chin. Soc. Agric. Eng. 2022, 38, 151–160. [Google Scholar]
- Ma, Y.R.; Lyu, X.; Yi, X.; Ma, L.L.; Qi, Y.Q.; Hou, T.Y.; Zhang, Z. Monitoring of cotton leaf area index using machine learning. Trans. Chin. Soc. Agric. Eng. 2021, 37, 152–162. [Google Scholar]
- Zhou, Q.; Ismaeel, A. Integration of maximum crop response with machine learning regression model to timely estimate crop yield. Geo-Spat. Inf. Sci. 2021, 24, 474–483. [Google Scholar] [CrossRef]
- Zhao, J.L.; Zhang, X.Y.; Li, Y. Hyperspectral Remote Sensing of Crop Information Based on Machine Learning Algorithm: State of the Art and Beyond. Chin. J. Agrometeorol. 2023, 44, 1057–1071. [Google Scholar]
- Teng, K.K. Effects of sowing quantity and additional quantity of nitrogen fertilizer on growth and development, yield and quality of wheat. J. Anhui Agric. 2012, 40, 11980–11983+12062. [Google Scholar]
- Cai, D.Y.; Zhou, L.L.; Gu, T.; Yan, H.J. Yield and nitrogen utilization of winter wheat under different nitrogen application frequencies with sprinkler Irrigation system. Agric. Mach. Newsp. 2018, 49, 278–286. [Google Scholar]
- Xue, B.; Li, X.; Yan, H.J. Effects of different irrigation and fertilization amount on winter wheat yield under center pivot irrigation system. Water Sav. Irrig. 2016, 8, 33–37. [Google Scholar]
- Chen, S.Y.; Zhang, X.Y.; Mao, R.Z.; Wang, Y.M.; Sun, H.Y. Effect of sowing date and rate on canopy intercepted photo-synthetically active radiation and yield of winter wheat. Chin. J. Eco-Agric. 2009, 17, 681–685. [Google Scholar] [CrossRef]
- Wang, Z.Y.; Bai, Y.H.; Wang, L.; Wang, H.; Cheng, M.F. Effects of nitrogen rates on grain yield and biological characteristies of winter wheat. Chin. Soil Fertil. 2011, 4, 22–25. [Google Scholar]
- Jiao, Y.-P.; Wang, F.-T.; Wu, J.; Li, Y.-X.; Tan, H.-B. Effects of drip irrigation and micro-sprinkler irrigation of hoses on growth and yield of winter wheat. J. Hebei Agric. Sci. 2017, 21, 17–22. [Google Scholar]
- Zhai, Y.L.; Wei, Y.H.; Zhang, H.L.; Chen, F. Effect of tillage and seeding methods on grain filling and yield of winter wheat. Agric. Res. Arid Areas 2017, 35, 211–216. [Google Scholar]
- Liu, L.P.; Hu, H.H.; Li, R.Q.; Li, H.L.; Chang, C.L.; Li, Y.M. Effects of spacing pattern and planting density on population quality and grain yield of a winter wheat cultivar Henong822. Acta Agric. Sin. 2008, 23, 125–131. [Google Scholar]
- Li, S.-J.; Chen, J.-K.; Chen, F.; Li, L.; Zhang, H.-L. Characteristics of growth and development of winter wheat under Zero-tillage in North China Plain. Acta Agron. Sin. 2008, 34, 290–296. [Google Scholar] [CrossRef]
- Wang, W.P.; Zhou, Y.F.; Li, Y.S.; Han, J.L. Studies on effects of irrigation systems in spring on winter wheat in eastem area of Hebei. Chin. Agric. Sci. Bull. 2005, 21, 336–339. [Google Scholar]
- Wu, Z.D.; Wang, Q.J. Effects of stage water shortage on water consumption and leaf area index of winter wheat. Trans. Chin. Soc. Agric. Eng. 2010, 26, 63–68. [Google Scholar] [CrossRef]
- Dong, W.-X.; Chen, S.-Y.; Hu, C.-S.; Yin, C.-M. The effect of minimum tillage and no-tillage on growth and yield of winter wheat. North China Agric. J. 2007, 2, 141–144. [Google Scholar]
- Liu, B.H.; Su, Y.H.; Wang, X.X.; Zhang, G.Z.; Chen, D.M.; Ma, Y.A.; Li, Y.M. Effects of planting density on the main agronomic traits and yield of winter wheat Hanmai No. 13. J. Hebei Agric. Sci. 2014, 18, 13–17. [Google Scholar]
- Lv, L.H.; Li, Q.; Dong, Z.Q.; Zhang, L.H.; Liang, S.B.; Jia, X.L.; Yao, H.P. Effects of different irrigation methods and amount on rootand canopy structure of winter wheat. J. Triticeae Crops 2014, 34, 1537–1544. [Google Scholar]
- Sun, H.Y.; Zhang, Y.Q.; Zhang, X.Y.; Mao, X.S.; Pei, D.; Gao, L.J. Effects of water stress on growth and development of winter wheat in the north China plains. North China Agric. J. 2003, 18, 23–26. [Google Scholar]
- Wang, S.J.; Kang, S.Z.; Li, T. Suitable water deficit mode for winter wheat basing objective of water saving as well as high yield and quality. Trans. Chin. Soc. Agric. Eng. 2015, 31, 111–118. [Google Scholar]
- Wu, Z.D.; Wang, Q.J. Field study on impacts of soil water-salt distribution and winter wheat yield by different saline water combination irrigations. Trans. Chin. Soc. Agric. Eng. 2007, 11, 71–76. [Google Scholar]
- Liu, W.D.; Chen, X.Y.; Yin, J.; Du, P.X. Effect of sowing date and planting density on population trait and grain yield of winter wheat cultivar Yumai 49-198. J. Triticeae Crops 2009, 29, 464–469. [Google Scholar]
- Miao, Y.F.; Li, Y.J.; Fu, G.Z.; Han, R.Y.; Ma, Q.H.; Shi, G.A. Study on the effect of different nitrogen and potassium ratio for winter wheat production increase. Tritical Crops 1998, 2, 40–43. [Google Scholar]
- Wu, J.Z.; Huang, M.; Li, Y.J.; Chen, M.C.; Yao, Y.Q.; Guo, D.Y.; Huang, H.X. Effects of different tillage systems on the photosynthesis funetions grain yield and WUE in winter wheat. Agric. Res. Arid Areas 2008, 26, 17–21. [Google Scholar]
- Xue, Z.W.; Dong, J.H.; Liu, G.T.; Guan, L.; Hou, J.H.; Yang, C.L. The effects of plant growth regulators on the factors of wheat output and output constituent. Agric. Technol. 2018, 38, 1–3. [Google Scholar]
- Sheng, K.; Zhang, L.; Guo, Y.; Zhao, J.; Yang, L.; Ma, H. Effects of row spacing on population quality and grain yield of winter wheat cultivar Xinmai-26. J. Henan Agric. Sci. 2015, 44, 26–30. [Google Scholar]
- Gao, Y.; Qiu, X.Q.; Gong, W.J.; Duan, A.-W.; Wang, J.L.; Meng, Z.J.; Sun, J.S. Effects of soil moisture before sowing on growth and yield of winter wheat. J. Irrig. Drain. 2012, 31, 17–20. [Google Scholar]
- Li, Y.J.; Hu, T.L.; Zhang, S.M.; Han, H.L.; Qi, X. Studies of the application techniques of nitrogen and potassium fertilizer in high yield and efficient winter wheat culture. J. Luoyang Agric. Coll. 1996, 4, 11–15. [Google Scholar]
- Liu, H.B.; Wang, L.; Wang, Y.F.; Xi, L. Prediction method of wheat yield in Henan Province based on PSO-SVR model. Jiangsu Agric. Sci. 2023, 51, 157–163. [Google Scholar]
- Cao, H.X.; Dong, Y.H.; Wang, X.Q.; Xu, J.F.; Gao, L.Z. Studies on dynanicsi mulation models of optimum leaf area Index of wheat under different melding levels. J. Triticeae Crops 2006, 26, 128–131+139. [Google Scholar]
- Zhang, J.H.; Liu, J.L.; Lv, F.; Li, H.X. Effect of nitrogen application on accumulation and transportation of matter and nitrogen in above-ground organs of wheat in Rice-wheat rotation area. J. Triticeae Crops 2009, 29, 892–896. [Google Scholar]
- Li, D.S.; Wen, M.X.; Cai, J.H.; Qu, C.X.; Chen, A.D. Effect of sowing date and the combination of planting ensity and nitrogen application on yield and dry matter accumulation of Zhenmai 10. J. Triticeae Crops 2015, 35, 1426–1432. [Google Scholar]
- Wei, G.F.; Liu, Y.g.; Jiang, W.; Zhang, H.S.; Lin, Q.; Zhao, C.X.; Zhang, Y.M. The impact of different drip irrigation on the dry material and yield of winter wheat. J. Irrig. Drain. 2013, 32, 67–70+99. [Google Scholar]
- Wang, C.Y.; Dai, X.L.; Shi, Y.H.; Cao, Q.; Men, H.W.; He, M.R. Effects of leaf area index on photosynthesis and yield of winter wheat after anthesis. Plant Nutr. Fertil. Sci. 2012, 18, 27–34. [Google Scholar]
- Wang, X.F.; Wu, W.L.; Pan, Z.Y.; Chen, S.F.; Liu, G.D.; Xia, X.F. Efflects of various water and nitrogen managem ents on grow th of winter wheat and water use efficiency. J. Agro-Environ. Sci. 2007, 26, 741–745. [Google Scholar]
- Shi, X.F.; Qiu, S.Y.; Shi, Z.L.; Xie, F.L.; Gao, W.; Song, L.H. Effect of sowing date and sowing amount on population traitsand yield of winter wheat cultivar Yaomai 16. J. Triticeae Crops 2017, 37, 357–365. [Google Scholar]
- Ding, J.J.; Li, L.; Wang, X.Y. The impact of water and fertilizer on winter wheat growth and yield. Soil Water Conserv. Sci. Technol. Shanxi 2014, 4, 12–14. [Google Scholar]
- Xue, L.Z.; Sun, M.; Gao, Z.Q.; Yan, R.A.; Lei, M.M.; Yang, Z.P. Effeets of sowing date and rate on soil water storage and dry weight accumulation and grain yield in land wheat. J. Shanxi Agric. Univ. (Nat. Sci. Ed.) 2017, 37, 547–552+556. [Google Scholar]
- Yang, J.J.; Cai, H.J.; Wang, J.; Wang, S.H. Effects of limited irrigation on physiological characteristics and WUE of winter wheat. J. Irrig. Drain. 2009, 28, 52–55. [Google Scholar]
- Shen, X.J.; Sun, J.S.; Liu, Z.G.; Zhang, J.P.; Liu, X.F. Effects of low irrigation limits on yield and grain quality of winter wheat. Trans. Chin. Soc. Agric. Eng. 2010, 26, 58–65. [Google Scholar]
- Qi, L.-H.; Dang, T.-H.; Chen, L. The water use characteristics of winter wheat and response to fertilization on dry-land of loess plateau. Res. Soil Water Conserv. 2009, 16, 105–109. [Google Scholar]
- Hu, H.W.; Cai, H.J.; Wang, X.Y.; Sun, Y.A.; Wang, Y.F. Effects of Supplementary Irrigation on Biomass, WUE and Yield of Winter Wheat under Different Nitrogen Fertilizer Conditions. J. Irrig. Drain. 2020, 39, 51–59. [Google Scholar]
- Lu, J.F.; Zhao, H.B.; Yang, J.; Qu, H.f.; Lei, B.H. Yield of winter wheat after anthesis in upland Effects of reduced nitrogen fertilizer combined with soil surface management on physiological characteristics and grain. Chin. Soil Fertil. 2018, 1, 16–22. [Google Scholar]
- Ma, Z.H.; Kou, C.L.; Kang, L.Y. Influence of phosphorus application in different soil depth on growthand yield of winter wheat under different water conditions. J. Henan Agric. Sci. 2016, 45, 49–55. [Google Scholar]
- Xu, Y.B.; Li, Y.M.; Yin, M.H.; Ren, Q.M.; Wang, X.Y.; Chen, Z.W. Effect of micro-sprinkler irrigation on growth, yield andwater use efficiency of winter wheat. Agric. Res. Arid Areas 2018, 36, 121–125. [Google Scholar]
- Shi, C.X.; Chen, T.; Feng, F.; Wang, C.J.; Lv, X.K.; Zhang, L.; Liao, Y.C.; Qin, X.L. Production of mixed planting winter wheat and soil water efficiency in Guanzhong Irrigation Zone. Agric. Res. Arid Areas 2017, 35, 29–37. [Google Scholar]
- Wu, R.; Li, Y.-N. Growth and nitrogen nutrition diagnosis of winter wheat under different water and nitrogen conditions. Water Sav. Irrig. 2017, 12, 27–32. [Google Scholar]
- Zhang, M.Z.; Niu, W.Q.; Lu, Z.G.; Wang, J.W.; Qiu, X.Q.; Li, Y. Effects of moistube irrigation on winter wheat’s yield and irrigation water use efficiency. J. Irrig. Drain. 2018, 37, 8–15. [Google Scholar]
- Hu, T.T.; Cui, X.L.; Li, M.Y.; Lu, J.S.; Luo, L.H.; Chen, S.M. Effect of different nitrogen fertilizer synergists, water and nitrogen amount on winter wheat yield. Agric. Mach. J. 2021, 52, 302–310. [Google Scholar]
- Jia, L.; Zhai, B.N.; Feng, M.L.; Wang, M.Y.; Qing, X.M.; Zhao, F.P.; Dang, S.M. Effects of different optimized water and fertilizer modeson the yield and growth of winter wheat. J. Northwest AF Univ. (Nat. Sci. Ed.) 2012, 40, 75–81. [Google Scholar]
- Yang, Y. Effects of Different Combinations of Water and Fertilizers on the Growth and Nutrient Uptake of Winter Wheat and Maize. Master’s Thesis, Northwest A&F University, Xianyang, China, 2016. [Google Scholar]
- Jia, L.; Zhai, B.N.; Hu, Z.P.; Li, X.Z.; Jia, H.X.; Liu, G.F. Effects of various water and fertilizer controlling measures on the yield and population dynamics of winter wheat. Chin. Agric. Sci. Bull. 2014, 30, 175–179. [Google Scholar]
- Sun, Q.-K.; Zhang, J.-X.; Zhao, L.-J.; Xue, L.-H.; Duan, L.-N. Water consumption and dry matter accumulation and distribution of winter wheat under different drip irrigation amount. Agric. Res. Arid Areas 2017, 35, 66–73. [Google Scholar]
- Zhao, L.J.; Xue, L.H.; Sun, O.K.; Zhang, J.X. Effect of different irrigation and nitrogen application on water consumption characteristics and the water and Nitrogen use efficiencies under drip irrigation in winter wheat. J. Triticeae Crops 2016, 36, 1050–1059. [Google Scholar]
- Zhang, N.; Zhang, Y.Q.; Tang, J.H.; Niu, H.S.; Xu, W.X.; Li, H.S.; Hao, W.W. Effect of drip irrigation layout on growth and yield of winter wheat. J. Triticeae Crops 2013, 33, 1197–1201. [Google Scholar]
- Xiao, J.; Jia, Z.L. Effects of water and fertilizer coupling on the northern Xinjiang winter wheat physiological growth and yield under drip Irrigation. J. Anhui Agric. 2014, 42, 8915–8918. [Google Scholar]
- Xue, L.H.; Zhao, L.J.; Chen, X.W.; Sun, S.R.; Zhang, H.Z.; Sai, L.H.; Lei, J.J.; Zhang, Y.Q. Effect of nitrogen application rate on photosynthetic characteristics, yield and nitrogen utilization efficiency of winter wheat under drip irrigation. Chin. Agric. Sci. Bull. 2018, 34, 11–16. [Google Scholar]
- Lei, J.J.; Zhang, Y.Q.; Liang, Y.C.; Sai, L.H.; Xue, L.H.; Zhang, H.Z.; Qiao, X.; Wang, C.; Chen, X.W. Effects of different nitrogen application rates on photosynthetic characteristics and yield of winter wheat under drip irrigation. Xinjiang Agric. Sci. 2015, 52, 1576–1582. [Google Scholar]
- Zhang, Y.Q.; Chen, X.W.; Sai, S.K.; Xue, L.H.; Lei, J.J. Effect of density on diurnal variation of photosynthesis of winter wheat under drip irrigation during grain filling stage under shading condition. Xinjiang Agric. Sci. 2017, 54, 2164–2173. [Google Scholar]
- McQueen, R.J.; Garner, S.R.; Nevill-Manning, C.G.; Witten, I.H. Applying machine learning to agricultural data. Comput. Electron. Agric. 1995, 12, 275–293. [Google Scholar] [CrossRef]
- Liu, H.L.; Liu, Q.Y.; Guo, Y.X. Research on collision detection of foot robot based on gaussian process regression. Modul. Mach. Tool Autom. Manuf. Tech. 2021, 9, 94–99. [Google Scholar]
- Qin, S.S.; Hou, Z.J.; Wu, Z.D.; Ma, D.H.; Huang, P. Effects of water and nitrogen coupling on nitrogen absorption and yield of winter wheat. J. Drain. Irrig. Mach. Eng. 2017, 35, 440–447. [Google Scholar]
- Liu, Q.F.; Ma, Y.G.; Chen, D.M.; Liu, B.H.; Su, Y.H.; Wang, X.X.; Liu, H.Y.; Zhang, Q.H.; He, W.Z. The number of irrigation and the period of irrigation is used for winter wheat Hangmai No. 13 output and the impact of the main agricultural traits. Agric. Sci. Technol. Commun. 2020, 8, 110–114. [Google Scholar]
- Wu, L.F.; Zhang, F.C.; Zhang, P.; Li, Z.J.; Zhou, H.Y. Effect of irrigation and nitrogen fertilizer on growth and yield of spring wheat in Hexi oasis of Gansu. J. Northwest AF Univ. (Nat. Sci. Ed.) 2011, 39, 55–63. [Google Scholar]
- Li, H. The impact of planting density on wheat output and onstituent factors under high fertilizer conditions. Farm Staff 2017, 19, 26–27+55. [Google Scholar]
- Xian, T.Z.; Zhao, D.Z.; Ren, H.P.; Yang, Y.W. Study on the impact of main weather factors on the production of wheat output in the central and western parts. Mod. Agric. Technol. 2011, 20, 297+304. [Google Scholar]
- Liu, F.L. Effect of Sowing Date and Planting Density on Grain Yield and Quality of Winter Wheat Pubing 151. Master’s Thesis, Northwest A&F University, Xianyang, China, 2016. [Google Scholar]
- Sahoo, R.N.; Gakhar, S.; Rejith, R.G.; Verrelst, J.; Ranjan, R.; Kondraju, T.; Meena, M.C.; Mukherjee, J.; Daas, A.; Kumar, S.; et al. Optimizing the Retrieval of Wheat Crop Traits from UAV-Borne Hyperspectral Image with Radiative Transfer Modelling Using Gaussian Process Regression. Remote Sens. 2023, 15, 5496. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| District | Leaf Area Index | Dry Matter Mass | Yield | |||
|---|---|---|---|---|---|---|
| Sample Size of Each City | Data Source | Sample Size of Each City | Data Source | Sample Size of Each City | Data Source | |
| Anhui | 12 | [23] | 12 | [23] | 18 | [23] |
| Beijing | 9 | [24] | 11 | [24,25] | ||
| Hebei | 44 | [26,27,28,29,30,31,32,33,34,35] | 29 | [24,27,29,30,31,35] | 84 | [26,27,28,29,30,31,32,33,34,35,36,37,38,39] |
| Henan | 37 | [40,41,42,43,44,45] | 26 | [40,41,42] | 65 | [40,41,42,43,45,46,47] |
| Jiangsu | 3 | [48,49] | 26 | [50] | 30 | [49,50] |
| Shandong | 19 | [51,52] | 15 | [51,53] | 27 | [51,52,53] |
| Shanxi | 31 | [54,55] | 40 | [55,56] | 39 | [55,56] |
| Shaanxi | 41 | [57,58,59,60] | 33 | [27,58,59,61] | 127 | [57,58,59,60,61,62,63,64,65,66,67,68,69,70] |
| Xinjiang | 46 | [71,72,73,74,75,76,77] | 20 | [71,73,75,77] | 43 | [71,72,73,74,75,76,77] |
| Total | 233 | 210 | 444 | |||
| Learning Parameters | Input Amount |
|---|---|
| Training set | Irrigation amount (mm), nitrogen application amount (kg/hm2), potassium application amount (kg/hm2), phosphorus application amount (kg/hm2), organic matter content (%), available phosphorus content (mg/kg), alkaline hydrolysis nitrogen content (mg/kg), total nitrogen amount (g/kg), available potassium content (mg/kg), planting density (kg/hm2) |
| Response variable | Maximum leaf area index (cm2/cm2), maximum dry matter mass (kg/hm2), yield (kg/hm2) |
| Number of datasets | 255 (maximum leaf area index), 210 (maximum dry matter mass), 444 (yield) |
| Cross validation fold | 10 |
| Regression model | Linear regression model, regression tree, support vector machine, Gaussian regression model |
| Validation Literature | Predictive Indicators | Irrigation Amount (mm) | Nitrogen Application Amount (kg/hm2) | Measured Value | Predicted Value | Relative Error (%) |
|---|---|---|---|---|---|---|
| [53] | Maximum leaf area index | 473 | 0 | 3.447 | 3.898 | 13.08 |
| 473 | 100 | 4.553 | 4.446 | 2.35 | ||
| 473 | 200 | 4.585 | 5.197 | 13.35 | ||
| 473 | 300 | 7.178 | 6.065 | 15.51 | ||
| 428 | 0 | 4.207 | 4.042 | 3.92 | ||
| 428 | 100 | 5.068 | 4.606 | 9.12 | ||
| 428 | 200 | 5.386 | 5.349 | 0.35 | ||
| 428 | 300 | 6.406 | 6.191 | 3.36 | ||
| [72] | Maximum dry matter mass | 553 | 0 | 13,466.5 | 14,820 | 10.05 |
| 691.1 | 0 | 13,251 | 15,040 | 13.5 | ||
| 708.5 | 0 | 13,131 | 15,050 | 14.61 | ||
| 559.75 | 180 | 12,781 | 15,730 | 23.07 | ||
| 691.32 | 180 | 12,978 | 15,840 | 22.05 | ||
| 712.5 | 180 | 14,434.5 | 15,810 | 9.53 | ||
| 563.26 | 270 | 13,356 | 15,930 | 19.27 | ||
| 700.23 | 270 | 16,077 | 15,960 | 0.72 | ||
| 713.16 | 270 | 16,042.5 | 15,940 | 0.64 | ||
| [80] | Yield | 502.66 | 150 | 6318.4 | 5861 | 7.24 |
| 502.66 | 190 | 6636 | 6417 | 3.47 | ||
| 502.66 | 230 | 7005.4 | 6654 | 5.01 | ||
| 502.66 | 270 | 7146.2 | 6643 | 7.04 | ||
| 576.1 | 150 | 6653.9 | 5846 | 12.14 | ||
| 576.1 | 190 | 7072.3 | 6370 | 9.35 | ||
| 576.1 | 230 | 7185.2 | 6542 | 8.95 | ||
| 576.1 | 270 | 7240.5 | 6468 | 10.67 | ||
| 612.25 | 150 | 6040.3 | 5801 | 3.96 | ||
| 612.25 | 190 | 7007.1 | 6303 | 10.05 | ||
| 612.25 | 230 | 7060.1 | 6452 | 8.61 | ||
| 612.25 | 270 | 6535.88 | 6363 | 2.65 | ||
| 642.92 | 150 | 5149 | 5737 | 11.42 | ||
| 642.92 | 190 | 5434.6 | 6214 | 14.34 | ||
| 642.92 | 230 | 5299.4 | 6342 | 19.67 | ||
| 642.92 | 270 | 5347.3 | 6244 | 16.77 | ||
| 720.92 | 150 | 5467.9 | 5516 | 0.8 |
| Year | Wheat Yield in Henan Province (kg/hm2) | Wheat Yield in Xinxiang City (kg/hm2) |
|---|---|---|
| 2013 | 6012 | 6791 |
| 2012 | 5950 | 6757 |
| 2011 | 5867 | 6703 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Su, L.; Luo, P.; Tao, W.; Wang, Q.; Deng, M. Prediction Models of Growth Characteristics and Yield for Chinese Winter Wheat Based on Machine Learning. Agronomy 2024, 14, 839. https://doi.org/10.3390/agronomy14040839
Liu F, Su L, Luo P, Tao W, Wang Q, Deng M. Prediction Models of Growth Characteristics and Yield for Chinese Winter Wheat Based on Machine Learning. Agronomy. 2024; 14(4):839. https://doi.org/10.3390/agronomy14040839
Chicago/Turabian StyleLiu, Fangliang, Lijun Su, Pengcheng Luo, Wanghai Tao, Quanjiu Wang, and Mingjiang Deng. 2024. "Prediction Models of Growth Characteristics and Yield for Chinese Winter Wheat Based on Machine Learning" Agronomy 14, no. 4: 839. https://doi.org/10.3390/agronomy14040839
APA StyleLiu, F., Su, L., Luo, P., Tao, W., Wang, Q., & Deng, M. (2024). Prediction Models of Growth Characteristics and Yield for Chinese Winter Wheat Based on Machine Learning. Agronomy, 14(4), 839. https://doi.org/10.3390/agronomy14040839