
The Musa Marker Database: A Comprehensive Genomic Resource for the Improvement of the Musaceae Family


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection and Processing
2.2. Marker Development
2.3. User Interface and Database Construction
3. Result
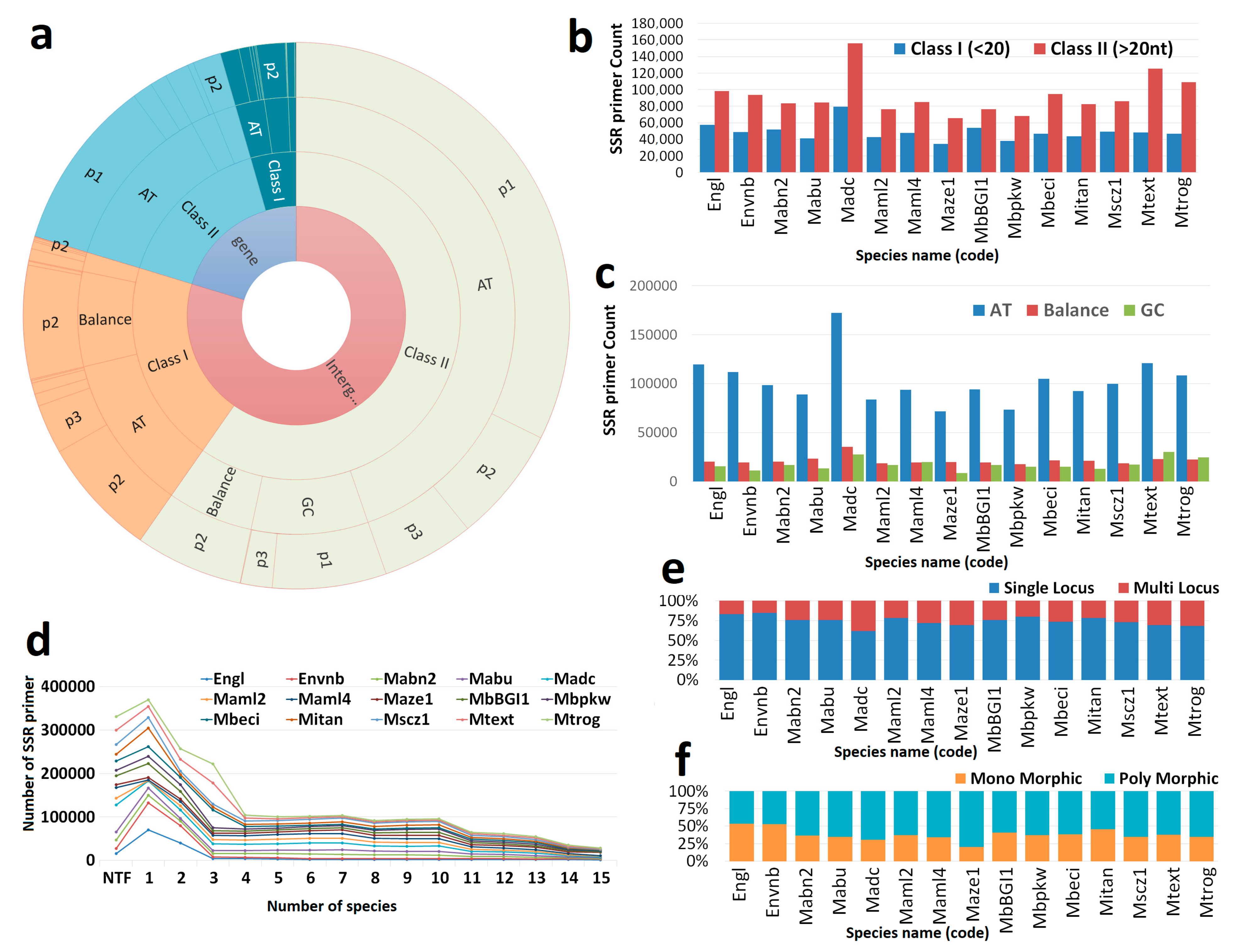
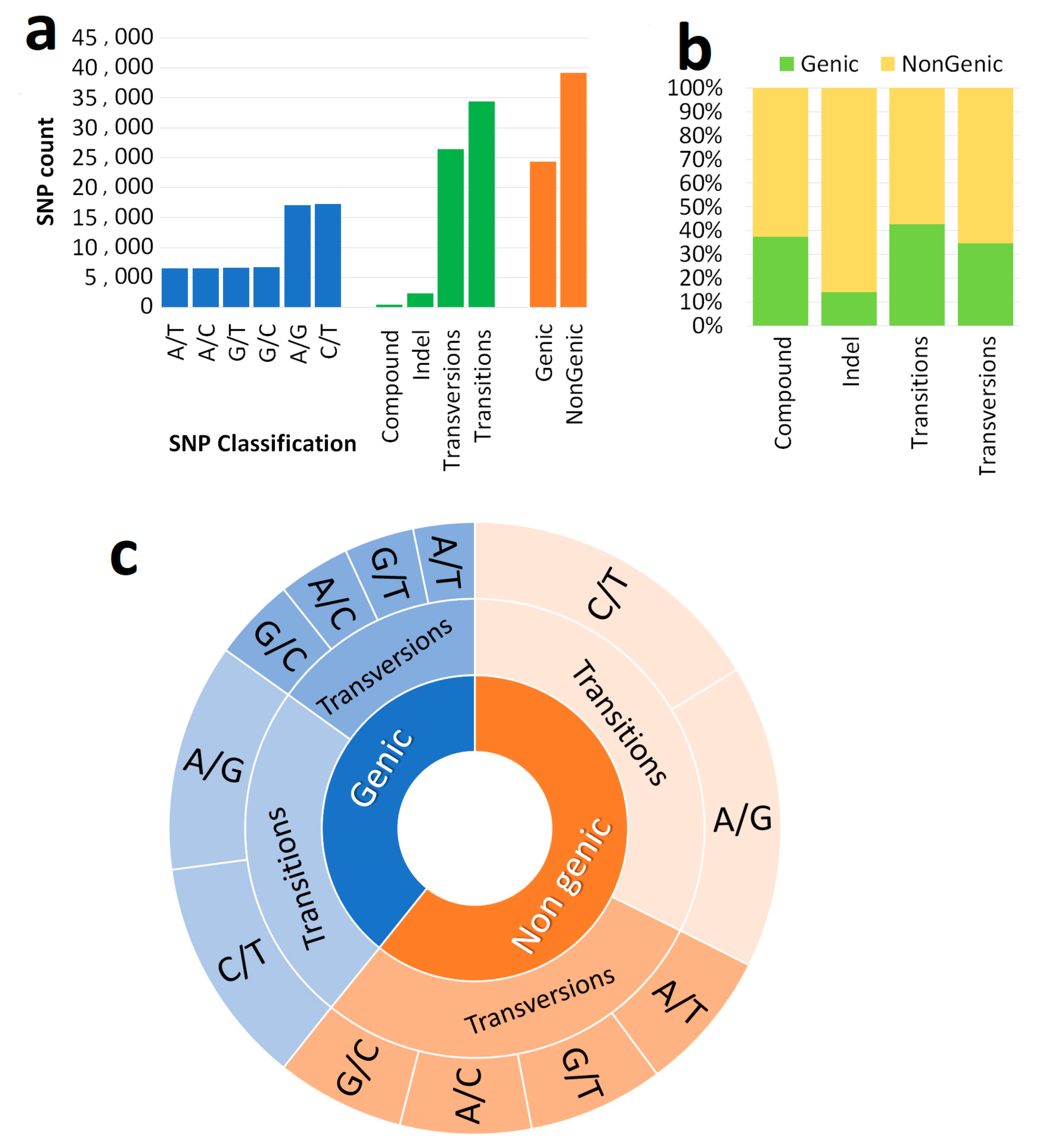
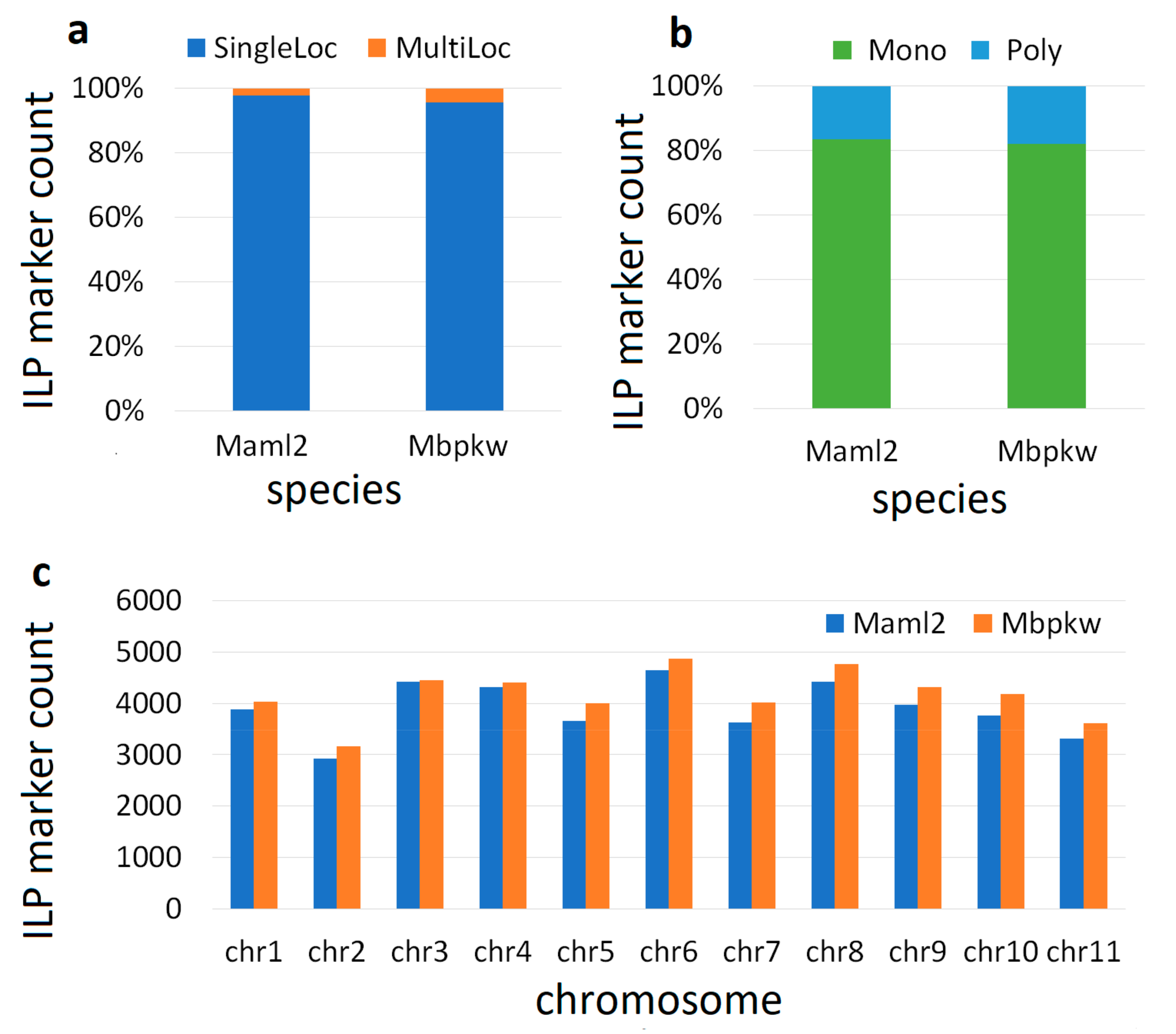
3.1. Genome-Wide Marker Developments
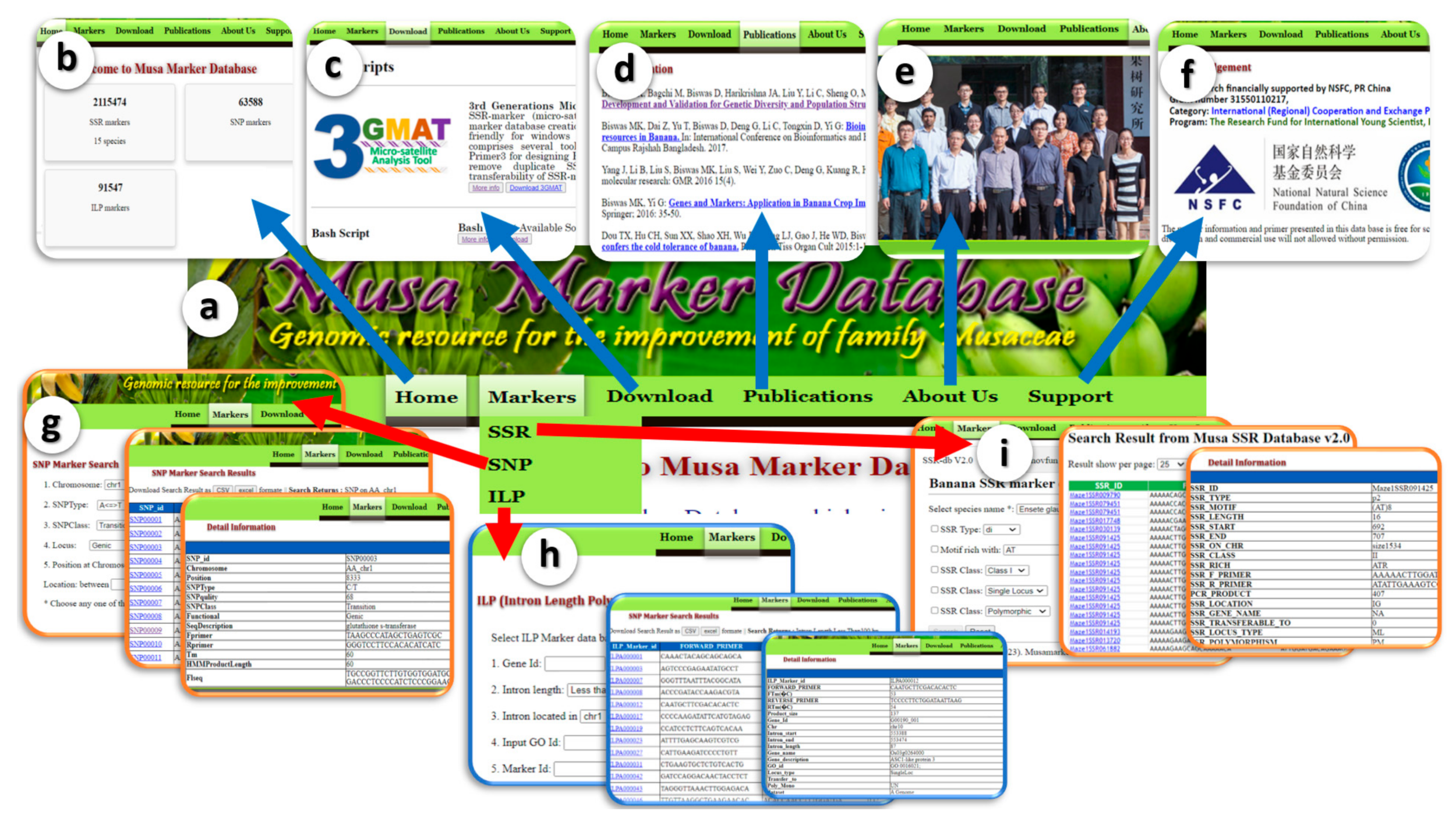
3.2. Interface and Search Criteria
3.3. Unique Feature of MMdb Compared with Other Existing Marker Databases
3.4. Utility and Future Directions
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Christenhusz, M.J.; Byng, J.W. The number of known plants species in the world and its annual increase. Phytotaxa 2016, 261, 201–217. [Google Scholar] [CrossRef]
- Bebber, D.P. The long road to a sustainable banana trade. Plants People Planet 2023, 5, 662–671. [Google Scholar] [CrossRef]
- Maseko, K.H.; Regnier, T.; Meiring, B.; Wokadala, O.C.; Anyasi, T.A. Musa species variation, production, and the application of its processed flour: A review. Sci. Hortic. 2024, 325, 112688. [Google Scholar] [CrossRef]
- Vézina, A. Banana-producing countries. In INIBAP—International Network for the Improvement of Banana and Plantain; Springer: Berlin/Heidelberg, Germany, 2020; p. 19. [Google Scholar]
- Singh, B.; Singh, J.P.; Kaur, A.; Singh, N. Bioactive compounds in banana and their associated health benefits—A review. Food Chem. 2016, 206, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Koul, B.S.; Jadhav, P.R.; Alex, S. Genetic Improvement of Banana. In Genetic Engineering of Crop Plants for Food and Health Security: Volume 1; Springer: Berlin/Heidelberg, Germany, 2024; pp. 305–329. [Google Scholar]
- Bakry, F.; Carreel, F.; Jenny, C.; Horry, J. Genetic improvement of banana. In Breeding Plantation Tree Crops: Tropical Species; Springer: Berlin/Heidelberg, Germany, 2009; pp. 3–50. [Google Scholar]
- Droc, G.; Martin, G.; Guignon, V.; Summo, M.; Sempéré, G.; Durant, E.; Soriano, A.; Baurens, F.; Cenci, A.; Breton, C. The banana genome hub: A community database for genomics in the Musaceae. Hortic. Res. 2022, 9, uhac221. [Google Scholar] [CrossRef] [PubMed]
- Crouch, J.H.; Crouch, H.K.; Ortiz, R.; Jarret, R.L. Microsatellite markers for molecular breeding of Musa. InfoMusa 1997, 6, 5–6. [Google Scholar]
- Kaemmer, D.; Fischer, D.; Jarret, R.L.; Baurens, F.; Grapin, A.; Dambier, D.; Noyer, J.; Lanaud, C.; Kahl, G.; Lagoda, P. Molecular breeding in the genus Musa: A strong case for STMS marker technology. Euphytica 1997, 96, 49–63. [Google Scholar] [CrossRef]
- Creste, S.; Benatti, T.R.; Orsi, M.R.; Risterucci, A.; Figueira, A. Isolation and characterization of microsatellite loci from a commercial cultivar of Musa acuminata. Mol. Ecol. Notes 2006, 6, 303–306. [Google Scholar] [CrossRef]
- Miller, R.N.; Passos, M.A.; Menezes, N.N.; Souza, M.T.; do Carmo Costa, M.M.; Rennó Azevedo, V.C.; Amorim, E.P.; Pappas, G.J.; Ciampi, A.Y. Characterization of novel microsatellite markers in Musa acuminata subsp. burmannicoides, var. Calcutta 4. BMC Res. Notes 2010, 3, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Biswas, M.K.; Liu, Y.; Li, C.; Sheng, O.; Mayer, C.; Yi, G. Genome-wide computational analysis of Musa microsatellites: Classification, cross-taxon transferability, functional annotation, association with transposons & miRNAs, and genetic marker potential. PLoS ONE 2015, 10, e0131312. [Google Scholar]
- Ravishankar, K.V.; Raghavendra, K.P.; Athani, V.; Rekha, A.; Sudeepa, K.; Bhavya, D.; Srinivas, V.; Ananad, L. Development and characterisation of microsatellite markers for wild banana (Musa balbisiana). J. Hortic. Sci. Biotechnol. 2013, 88, 605–609. [Google Scholar] [CrossRef]
- Buhariwalla, H.K.; Jarret, R.L.; Jayashree, B.; Crouch, J.H.; Ortiz, R. Isolation and characterization of microsatellite markers from Musa balbisiana. Mol. Ecol. Notes 2005, 5, 327–330. [Google Scholar] [CrossRef]
- Blenda, A.; Scheffler, J.; Scheffler, B.; Palmer, M.; Lacape, J.; Yu, J.Z.; Jesudurai, C.; Jung, S.; Muthukumar, S.; Yellambalase, P. CMD: A cotton microsatellite database resource for Gossypium genomics. BMC Genom. 2006, 7, 132. [Google Scholar] [CrossRef] [PubMed]
- Shirasawa, K.; Isobe, S.; Tabata, S.; Hirakawa, H. Kazusa Marker DataBase: A database for genomics, genetics, and molecular breeding in plants. Breed Sci. 2014, 64, 264–271. [Google Scholar] [CrossRef]
- Kim, C.; Seol, Y.; Lee, D.; Jeong, I.; Yoon, U.; Lee, G.; Hahn, J.; Park, D. NABIC marker database: A molecular markers information network of agricultural crops. Bioinformation 2013, 9, 887. [Google Scholar] [CrossRef] [PubMed]
- Sarika; Arora, V.; Iquebal, M.A.; Rai, A.; Kumar, D. PIPEMicroDB: Microsatellite database and primer generation tool for pigeonpea genome. Database 2013, 2013, bas054. [Google Scholar] [CrossRef] [PubMed]
- Muthamilarasan, M.; Misra, G.; Prasad, M. FmMDb: A versatile database of foxtail millet markers for millets and bioenergy grasses research. PLoS ONE 2013, 8, e71418. [Google Scholar]
- Doddamani, D.; Katta, M.A.; Khan, A.W.; Agarwal, G.; Shah, T.M.; Varshney, R.K. CicArMiSatDB: The chickpea microsatellite database. BMC Bioinform. 2014, 15, 212. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Jin, G.; Zhao, X.; Zheng, Y.; Xu, Z.; Wu, W. PIP: A database of potential intron polymorphism markers. Bioinformatics 2007, 23, 2174–2177. [Google Scholar] [CrossRef] [PubMed]
- Mokhtar, M.M.; Atia, M.A.M. SSRome: An integrated database and pipelines for exploring microsatellites in all organisms. Nucleic Acids Res. 2019, 47, D244–D252. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Yu, Q.; Shi, Y.; Hua, X.; Tang, H.; Yang, L.; Ming, R.; Zhang, J. PGD: Pineapple genomics database. Hortic. Res. 2018, 5, 66. [Google Scholar] [CrossRef] [PubMed]
- Biswas, M.K.; Natarajan, S.; Biswas, D.; Howlader, J.; Park, J.-I.; Nou, I.-S. Lily Database: A Comprehensive Genomic Resource for the Liliaceae Family. Horticulturae 2024, 10, 23. [Google Scholar] [CrossRef]
- Yu, J.; Dossa, K.; Wang, L.; Zhang, Y.; Wei, X.; Liao, B.; Zhang, X. PMDBase: A database for studying microsatellite DNA and marker development in plants. Nucleic Acids Res. 2017, 45, D1046–D1053. [Google Scholar] [CrossRef] [PubMed]
- Droc, G.; Lariviere, D.; Guignon, V.; Yahiaoui, N.; This, D.; Garsmeur, O.; Dereeper, A.; Hamelin, C.; Argout, X.; Dufayard, J. The banana genome hub. Database 2013, 2013, bat035. [Google Scholar] [CrossRef] [PubMed]
- Arora, V.; Kapoor, N.; Fatma, S.; Jaiswal, S.; Iquebal, M.A.; Rai, A.; Kumar, D. BanSatDB, a whole-genome-based database of putative and experimentally validated microsatellite markers of three Musa species. Crop J. 2018, 6, 642–650. [Google Scholar] [CrossRef]
- Fu, L.; Niu, B.; Zhu, Z.; Wu, S.; Li, W. CD-HIT: Accelerated for clustering the next-generation sequencing data. Bioinformatics 2012, 28, 3150–3152. [Google Scholar] [CrossRef]
- Langmead, B.; Salzberg, S.L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 2012, 9, 357–359. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R. 1000 Genome Project Data Processing Subgroup The sequence alignment/map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [PubMed]
- Untergasser, A.; Cutcutache, I.; Koressaar, T.; Ye, J.; Faircloth, B.C.; Remm, M.; Rozen, S.G. Primer3—New capabilities and interfaces. Nucleic Acids Res. 2012, 40, e115. [Google Scholar] [CrossRef] [PubMed]
- Conesa, A.; Götz, S.; García-Gómez, J.M.; Terol, J.; Talón, M.; Robles, M. Blast2GO: A universal tool for annotation, visualization and analysis in functional genomics research. Bioinformatics 2005, 21, 3674–3676. [Google Scholar] [CrossRef] [PubMed]
- Biswas, M.K.; Nath, U.K.; Howlader, J.; Bagchi, M.; Natarajan, S.; Kayum, M.A.; Kim, H.; Park, J.; Kang, J.; Nou, I. Exploration and exploitation of novel SSR markers for candidate transcription factor genes in Lilium species. Genes 2018, 9, 97. [Google Scholar] [CrossRef] [PubMed]
- Salgotra, R.K.; Chauhan, B.S. Genetic diversity, conservation, and utilization of plant genetic resources. Genes 2023, 14, 174. [Google Scholar] [CrossRef] [PubMed]
- Dida, G. Molecular Markers in Breeding of Crops: Recent Progress and Advancements. J. Microbiol. Biotechnol. 2022, 7. [Google Scholar] [CrossRef]
- Savadi, S.; Muralidhara, B.M.; Venkataravanappa, V.; Adiga, J.D. Genome-wide survey and characterization of microsatellites in cashew and design of a web-based microsatellite database: CMDB. Front. Plant Sci. 2023, 14, 1242025. [Google Scholar] [CrossRef]
- Singh, J.; Sharma, A.; Sharma, V.; Gaikwad, P.N.; Sidhu, G.S.; Kaur, G.; Kaur, N.; Jindal, T.; Chhuneja, P.; Rattanpal, H.S. Comprehensive genome-wide identification and transferability of chromosome-specific highly variable microsatellite markers from citrus species. Sci. Rep. 2023, 13, 10919. [Google Scholar] [CrossRef] [PubMed]
- Biswas, M.K.; Darbar, J.N.; Borrell, J.S.; Bagchi, M.; Biswas, D.; Nuraga, G.W.; Demissew, S.; Wilkin, P.; Schwarzacher, T.; Heslop-Harrison, J.S. The landscape of microsatellites in the enset (Ensete ventricosum) genome and web-based marker resource development. Sci. Rep. 2020, 10, 15312. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Min, X.; Wang, Z.; Wang, Y.; Liu, Z.; Liu, W. Genome-wide development and utilization of novel intron-length polymorphic (ILP) markers in Medicago sativa. Mol. Breed. 2017, 37, 87. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, T.; Rui, F. Development of EST-SSR markers derived from transcriptome of Saccharina japonica and their application in genetic diversity analysis. J. Appl. Phycol. 2018, 30, 2101–2109. [Google Scholar] [CrossRef]
- Liu, S.; An, Y.; Li, F.; Li, S.; Liu, L.; Zhou, Q.; Zhao, S.; Wei, C. Genome-wide identification of simple sequence repeats and development of polymorphic SSR markers for genetic studies in tea plant (Camellia sinensis). Mol. Breed 2018, 38, 59. [Google Scholar] [CrossRef]
- Liu, Q.; Chang, S.; Hartman, G.L.; Domier, L.L. Assembly and annotation of a draft genome sequence for Glycine latifolia, a perennial wild relative of soybean. Plant J. 2018, 95, 71–85. [Google Scholar] [CrossRef]
- Kaur, B.; Mavi, G.S.; Gill, M.S.; Saini, D.K. Utilization of KASP technology for wheat improvement. Cereal Res. Commun. 2020, 48, 409–421. [Google Scholar] [CrossRef]
- Li, B.; Zhang, N.; Wang, Y.; George, A.W.; Reverter, A.; Li, Y. Genomic prediction of breeding values using a subset of SNPs identified by three machine learning methods. Front. Genet. 2018, 9, 237. [Google Scholar] [CrossRef] [PubMed]
- Berget, S.M.; Moore, C.; Sharp, P.A. Spliced segments at the 5′ terminus of adenovirus 2 late mRNA. Proc. Natl. Acad. Sci. USA 1977, 74, 3171–3175. [Google Scholar] [CrossRef] [PubMed]
- Jeffares, D.C.; Mourier, T.; Penny, D. The biology of intron gain and loss. Trends Genet. 2006, 22, 16–22. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Yang, Y.; Sun, X.; Liu, R.; Xia, W.; Shi, P.; Zhou, L.; Wang, Y.; Wu, Y.; Lei, X. Development of Intron Polymorphism Markers and Their Association with Fatty Acid Component Variation in Oil Palm. Front. Plant Sci. 2022, 13, 885418. [Google Scholar] [CrossRef] [PubMed]
- Sharma, H.; Bhandawat, A.; Rahim, M.S.; Kumar, P.; Choudhoury, M.P.; Roy, J. Novel intron length polymorphic (ILP) markers from starch biosynthesis genes reveal genetic relationships in Indian wheat varieties and related species. Mol. Biol. Rep. 2020, 47, 3485–3500. [Google Scholar] [CrossRef]
- Wang, X.; Zhao, X.; Zhu, J.; Wu, W. Genome-wide investigation of intron length polymorphisms and their potential as molecular markers in rice (Oryza sativa L.). DNA Res. 2005, 12, 417–427. [Google Scholar] [CrossRef] [PubMed]
- Duhan, N.; Kaur, S.; Kaundal, R. ranchSATdb: A Genome-Wide Simple Sequence Repeat (SSR) Markers Database of Livestock Species for Mutant Germplasm Characterization and Improving Farm Animal Health. Genes 2023, 14, 1481. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| List of the Genome | Genome Code | Total Number of SSR | Primer Design (Count) | % |
|---|---|---|---|---|
| Musa acuminata banksii | Mabn2 | 183,911 | 135,187 | 74 |
| Musa acuminata Dwarf_Cavendish | Madc | 267,698 | 235,211 | 88 |
| Musa acuminata burmannica | Mabu | 141,919 | 125,946 | 89 |
| Musa acuminata malaccensis V2 | Maml2 | 147,255 | 118,834 | 81 |
| Musa acuminata malaccensis V4 | Maml4 | 185,328 | 132,721 | 72 |
| Musa acuminata zebrina | Maze1 | 111,705 | 100,182 | 90 |
| Musa balbisiana BGI11 | MbBGI1 | 320,858 | 130,377 | 41 |
| Musa balbisiana pkw | Mbpkw | 131,403 | 106,302 | 81 |
| Musa beccarii | Mbeci | 181,767 | 141,466 | 78 |
| Musa itinerans | Mitan | 151,683 | 126,107 | 83 |
| Musa schizocarpa | Mscz1 | 178,889 | 135,556 | 76 |
| Musa textilis | Mtext | 215,660 | 173,840 | 81 |
| Musa troglodytarum | Mtrog | 197,524 | 155,701 | 79 |
| Ensete glaucum | Engl | 181,817 | 155,508 | 86 |
| Ensete ventricosum Bedadeti | Envnb | 163,773 | 142,536 | 87 |
| Total | 2,761,190 | 2,115,474 | 77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biswas, M.K.; Biswas, D.; Yi, G.; Deng, G. The Musa Marker Database: A Comprehensive Genomic Resource for the Improvement of the Musaceae Family. Agronomy 2024, 14, 838. https://doi.org/10.3390/agronomy14040838
Biswas MK, Biswas D, Yi G, Deng G. The Musa Marker Database: A Comprehensive Genomic Resource for the Improvement of the Musaceae Family. Agronomy. 2024; 14(4):838. https://doi.org/10.3390/agronomy14040838
Chicago/Turabian StyleBiswas, Manosh Kumar, Dhiman Biswas, Ganjun Yi, and Guiming Deng. 2024. "The Musa Marker Database: A Comprehensive Genomic Resource for the Improvement of the Musaceae Family" Agronomy 14, no. 4: 838. https://doi.org/10.3390/agronomy14040838
APA StyleBiswas, M. K., Biswas, D., Yi, G., & Deng, G. (2024). The Musa Marker Database: A Comprehensive Genomic Resource for the Improvement of the Musaceae Family. Agronomy, 14(4), 838. https://doi.org/10.3390/agronomy14040838