



Based on BERT-wwm for Agricultural Named Entity Recognition



Abstract
1. Introduction
2. Materials and Methods
2.1. Model Structure
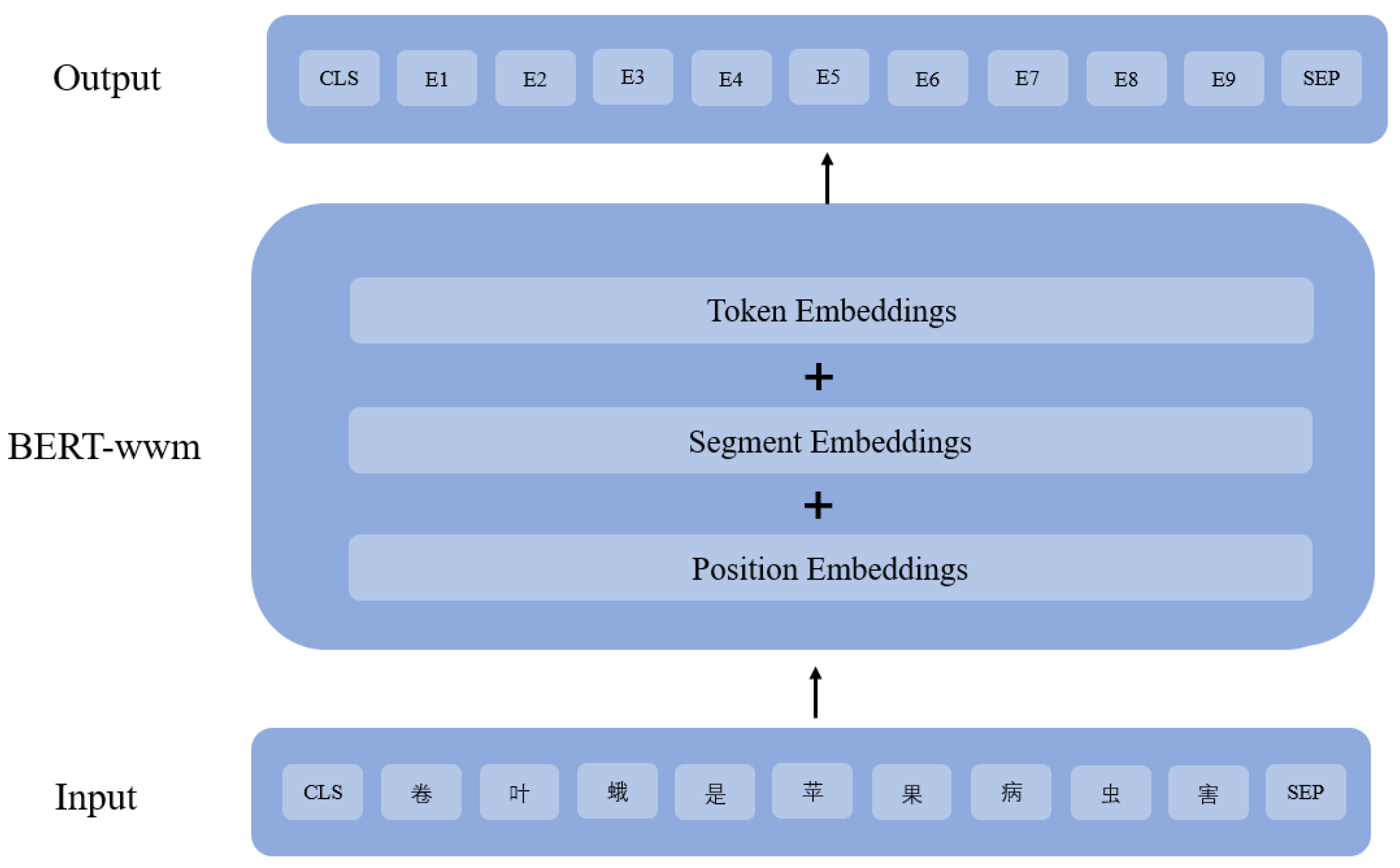
2.2. BERT-wwm Model
2.3. Channel Attention
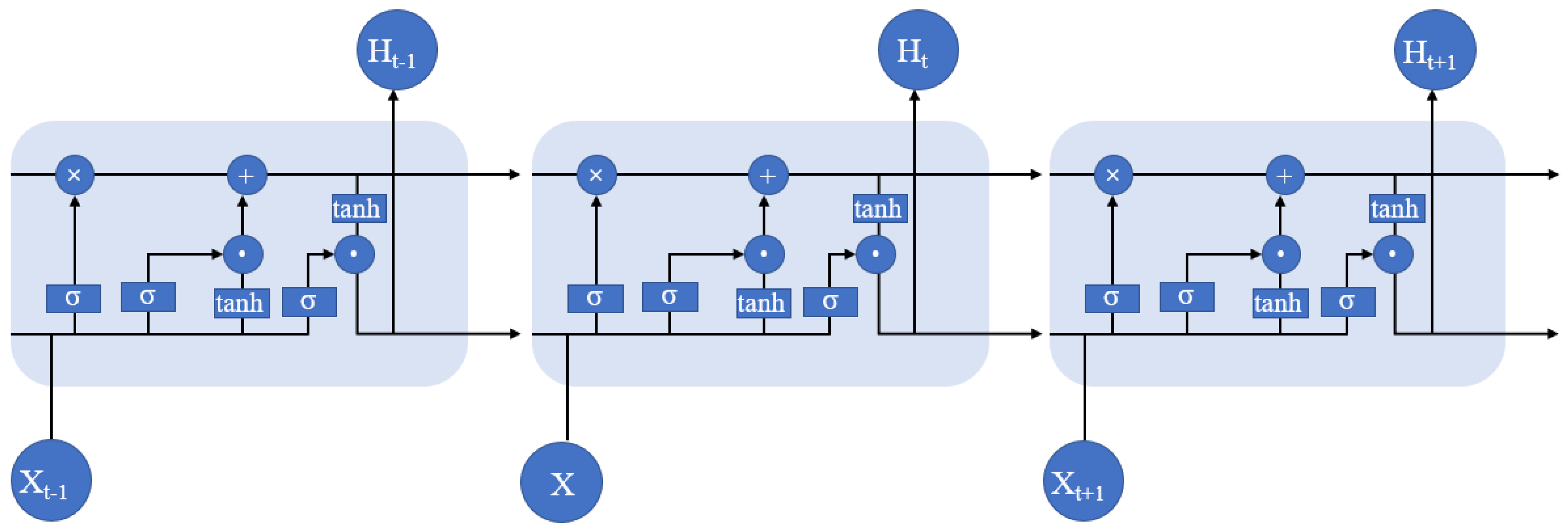
2.4. BILSTM Model
2.5. Conditional Random Field Model
2.6. Experimental Method Design
2.6.1. Dataset
2.6.2. Parameter Setting and Evaluation Metrics
3. Results
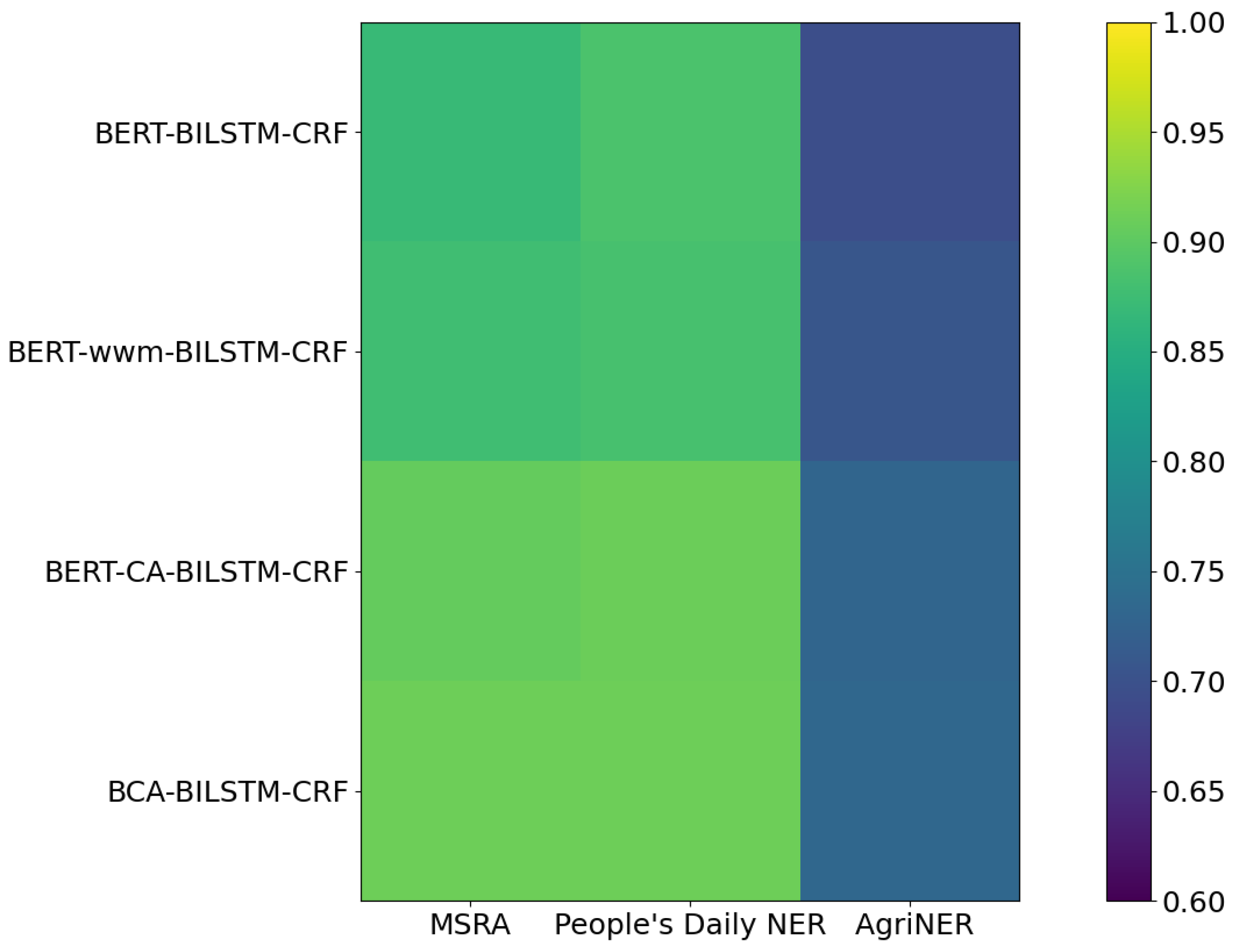
3.1. Results on Dataset
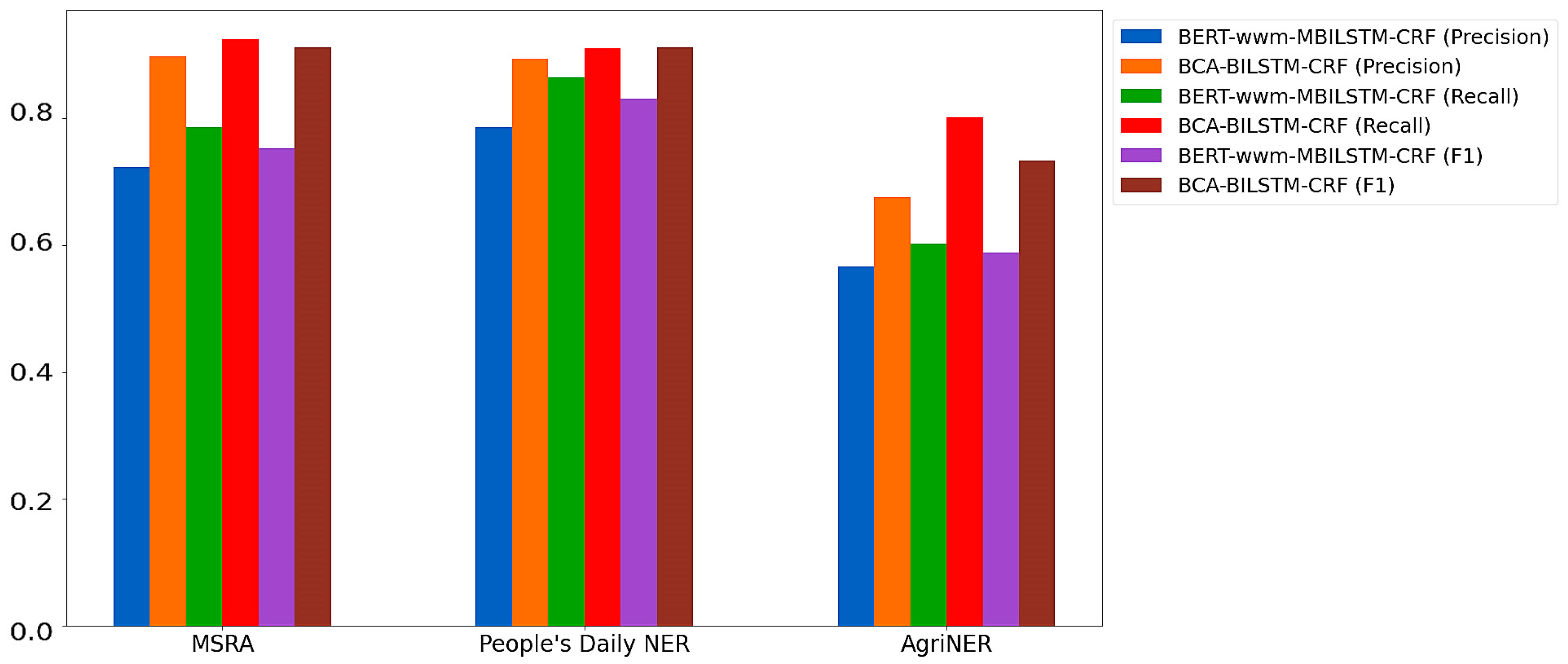
3.2. Comparison of Results under Different Attention Mechanisms
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fountas, S.; Espejo-García, B.; Kasimati, A.; Mylonas, N.; Darra, N. The future of digital agriculture: Technologies and opportunities. IT Prof. 2020, 22, 24–28. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, W.; Liu, H.; Han, M. Recognition of the agricultural named entities with multifeature fusion based on albert. IEEE Access 2022, 10, 98936–98943. [Google Scholar] [CrossRef]
- Asgari-Chenaghlu, M.; Feizi-Derakhshi, M.R.; Farzinvash, L.; Balafar, M.; Motamed, C. CWI: A multimodal deep learning approach for named entity recognition from social media using character, word and image features. Neural Comput. Appl. 2022, 34, 1905–1922. [Google Scholar] [CrossRef]
- Baigang, M.; Yi, F. A review: Development of named entity recognition (NER) technology for aeronautical information intelligence. Artif. Intell. Rev. 2023, 56, 1515–1542. [Google Scholar] [CrossRef]
- Guo, X.; Zhou, H.; Su, J.; Hao, X.; Tang, Z.; Diao, L.; Li, L. Chinese agricultural diseases and pests named entity recognition with multi-scale local context features and self-attention mechanism. Comput. Electron. Agric. 2020, 179, 105830. [Google Scholar] [CrossRef]
- Tikayat Ray, A.; Pinon-Fischer, O.J.; Mavris, D.N.; White, R.T.; Cole, B.F. aeroBERT-NER: Named-entity recognition for aerospace requirements engineering using BERT. In Proceedings of the AIAA SCITECH 2023 Forum, National Harbor, MD, USA, 23–27 January 2023; p. 2583. [Google Scholar]
- Sari, Y.; Hassan, M.F.; Zamin, N. Rule-based pattern extractor and named entity recognition: A hybrid approach. In Proceedings of the 2010 International Symposium on Information Technology, Kuala Lumpur, Malaysia, 15–17 June 2010; pp. 563–568. [Google Scholar]
- Archana, S.; Prakash, J.; Singh, P.K.; Ahmed, W. An Effective Biomedical Named Entity Recognition by Handling Imbalanced Data Sets Using Deep Learning and Rule-Based Methods. SN Comput. Sci. 2023, 4, 650. [Google Scholar] [CrossRef]
- Pande, S.D.; Kanna, R.K.; Qureshi, I. Natural language processing based on name entity with n-gram classifier machine learning process through ge-based hidden markov model. Mach. Learn. Appl. Eng. Educ. Manag. 2022, 2, 30–39. [Google Scholar]
- Sharma, R.; Morwal, S.; Agarwal, B. Named entity recognition using neural language model and CRF for Hindi language. Comput. Speech Lang. 2022, 74, 101356. [Google Scholar] [CrossRef]
- Hamad, R.M.; Abushaala, A.M. Medical Named Entity Recognition in Arabic Text using SVM. In Proceedings of the 2023 IEEE 3rd International Maghreb Meeting of the Conference on Sciences and Techniques of Automatic Control and Computer Engineering (MI-STA), Benghazi, Libya, 21–23 May 2023; pp. 200–205. [Google Scholar]
- Zhang, J.; Shen, D.; Zhou, G.; Su, J.; Tan, C.-L. Enhancing HMM-based biomedical named entity recognition by studying special phenomena. J. Biomed. Inform. 2004, 37, 411–422. [Google Scholar] [CrossRef]
- Song, S.; Zhang, N.; Huang, H. Named entity recognition based on conditional random fields. Clust. Comput. 2019, 22, 5195–5206. [Google Scholar] [CrossRef]
- Lee, K.-J.; Hwang, Y.-S.; Kim, S.; Rim, H.-C. Biomedical named entity recognition using two-phase model based on SVMs. J. Biomed. Inform. 2004, 37, 436–447. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Chang, J.; Han, X. Multi-level context features extraction for named entity recognition. Comput. Speech Lang. 2023, 77, 101412. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Suganthi, M.; Arun Prakash, R. An offline English optical character recognition and NER using LSTM and adaptive neuro-fuzzy inference system. J. Intell. Fuzzy Syst. 2023, 44, 3877–3890. [Google Scholar] [CrossRef]
- DiPietro, R.; Hager, G.D. Deep learning: RNNs and LSTM. In Handbook of Medical Image Computing and Computer Assisted Intervention; Elsevier: Amsterdam, The Netherlands, 2020; pp. 503–519. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Qi, P.; Li, P.; Qin, B. CLGP: Multi-Feature Embedding based Cross-Attention for Chinese NER. In Proceedings of the 2023 International Conference on Communications, Computing and Artificial Intelligence (CCCAI), Shanghai, China, 23–25 June 2023; pp. 109–113. [Google Scholar]
- Chen, Y.; Huang, R.; Pan, L.; Huang, R.; Zheng, Q.; Chen, P. A Controlled Attention for Nested Named Entity Recognition. Cogn. Comput. 2023, 15, 132–145. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Jia, C.; Shi, Y.; Yang, Q.; Zhang, Y. Entity enhanced BERT pre-training for Chinese NER. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6384–6396. [Google Scholar]
- Jia, C.; Liang, X.; Zhang, Y. Cross-domain NER using cross-domain language modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2464–2474. [Google Scholar]
- Liu, Z.; Jiang, F.; Hu, Y.; Shi, C.; Fung, P. NER-BERT: A pre-trained model for low-resource entity tagging. arXiv 2021, arXiv:2112.00405. [Google Scholar]
- Wang, L.; Jiang, J.; Song, J.; Liu, J. A Weakly-Supervised Method for Named Entity Recognition of Agricultural Knowledge Graph. Intell. Autom. Soft Comput. 2023, 37, 833–848. [Google Scholar] [CrossRef]
- VeeraSekharReddy, B.; Rao, K.S.; Koppula, N. Named Entity Recognition using CRF with Active Learning Algorithm in English Texts. In Proceedings of the 2022 6th International Conference on Electronics, Communication and Aerospace Technology, Coimbatore, India, 1–3 December 2022; pp. 1041–1044. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Levow, G.-A. The third international Chinese language processing bakeoff: Word segmentation and named entity recognition. In Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing, Sydney, Australia, 22–23 July 2006; pp. 108–117. [Google Scholar]
- Wang, C.; Gao, J.; Rao, H.; Chen, A.; He, J.; Jiao, J.; Zou, N.; Gu, L. Named entity recognition (NER) for Chinese agricultural diseases and pests based on discourse topic and attention mechanism. Evol. Intell. 2024, 17, 457–466. [Google Scholar] [CrossRef]
- Masumi, M.; Majd, S.S.; Shamsfard, M.; Beigy, H. FaBERT: Pre-training BERT on Persian Blogs. arXiv 2024, arXiv:2402.06617. [Google Scholar]
- Licari, D.; Comandè, G. ITALIAN-LEGAL-BERT models for improving natural language processing tasks in the Italian legal domain. Comput. Law Secur. Rev. 2024, 52, 105908. [Google Scholar] [CrossRef]
- Qian, Y.; Chen, X.; Wang, Y.; Zhao, J.; Ouyang, D.; Dong, S.; Huang, L. Agricultural text named entity recognition based on the BiLSTM-CRF model. In Proceedings of the Fifth International Conference on Computer Information Science and Artificial Intelligence (CISAI 2022), Chongqing, China, 28 March 2023; pp. 525–530. [Google Scholar]
- Wang, S.; Sun, X.; Li, X.; Ouyang, R.; Wu, F.; Zhang, T.; Li, J.; Wang, G. Gpt-ner: Named entity recognition via large language models. arXiv 2023, arXiv:2304.10428. [Google Scholar]
- Majdik, Z.P.; Graham, S.S.; Shiva Edward, J.C.; Rodriguez, S.N.; Karnes, M.S.; Jensen, J.T.; Barbour, J.B.; Rousseau, J.F. Sample Size Considerations for Fine-Tuning Large Language Models for Named Entity Recognition Tasks: Methodological Study. JMIR AI 2024, 3, e52095. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Illustration | Sample |
|---|---|
| Original text | 卷叶蛾是苹果病虫害 |
| Segmented text | 卷叶蛾 是 苹果 病虫害 |
| BERT masking strategy | 卷叶[MASK]是苹果病虫害 |
| BERT-wwm masking strategy | [MASK] [MASK] [MASK]是苹果病虫害 |
| Parameter | Value |
|---|---|
| Batch size | 64 |
| Epoch | 30 |
| Max length | 100 |
| Lr | 0.001 |
| Hidden size | 512 |
| Lr decay rate | 0.8 |
| Model | MSRA | People’s Daily NER | AgriNER | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT-BILSTM-CRF | 0.841 | 0.897 | 0.869 | 0.860 | 0.911 | 0.886 | 0.645 | 0.748 | 0.696 |
| BERT-wwm-BILSTM-CRF | 0.860 | 0.896 | 0.878 | 0.854 | 0.912 | 0.883 | 0.664 | 0.752 | 0.707 |
| BERT-CA-BILSTM-CRF | 0.893 | 0.919 | 0.906 | 0.893 | 0.924 | 0.910 | 0.691 | 0.775 | 0.731 |
| BCA-BILSTM-CRF | 0.898 | 0.925 | 0.912 | 0.894 | 0.911 | 0.912 | 0.675 | 0.801 | 0.733 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Q.; Tao, Y.; Wu, Z.; Marinello, F. Based on BERT-wwm for Agricultural Named Entity Recognition. Agronomy 2024, 14, 1217. https://doi.org/10.3390/agronomy14061217
Huang Q, Tao Y, Wu Z, Marinello F. Based on BERT-wwm for Agricultural Named Entity Recognition. Agronomy. 2024; 14(6):1217. https://doi.org/10.3390/agronomy14061217
Chicago/Turabian StyleHuang, Qiang, Youzhi Tao, Zongyuan Wu, and Francesco Marinello. 2024. "Based on BERT-wwm for Agricultural Named Entity Recognition" Agronomy 14, no. 6: 1217. https://doi.org/10.3390/agronomy14061217
APA StyleHuang, Q., Tao, Y., Wu, Z., & Marinello, F. (2024). Based on BERT-wwm for Agricultural Named Entity Recognition. Agronomy, 14(6), 1217. https://doi.org/10.3390/agronomy14061217