
Efficient Adaptive Incremental Learning for Fruit and Vegetable Classification


Abstract
:1. Introduction
- The ADA-CIL method is developed, combining adversarial domain adaptation and core-set selection to address dynamic changes in fruit and vegetable classification.
- The ResNet34 architecture is employed for robust feature extraction, optimizing the performance on diverse image datasets within the incremental learning framework.
- A dynamic balance between learning new categories and retaining existing ones enhances the model’s generalization and reduces catastrophic forgetting.
- The ADA-CIL method demonstrates proven adaptability and stability across various domains, being effective in real-world agricultural settings with frequent category and domain changes.
2. Materials and Methods
2.1. Dataset
2.2. Problem Definition
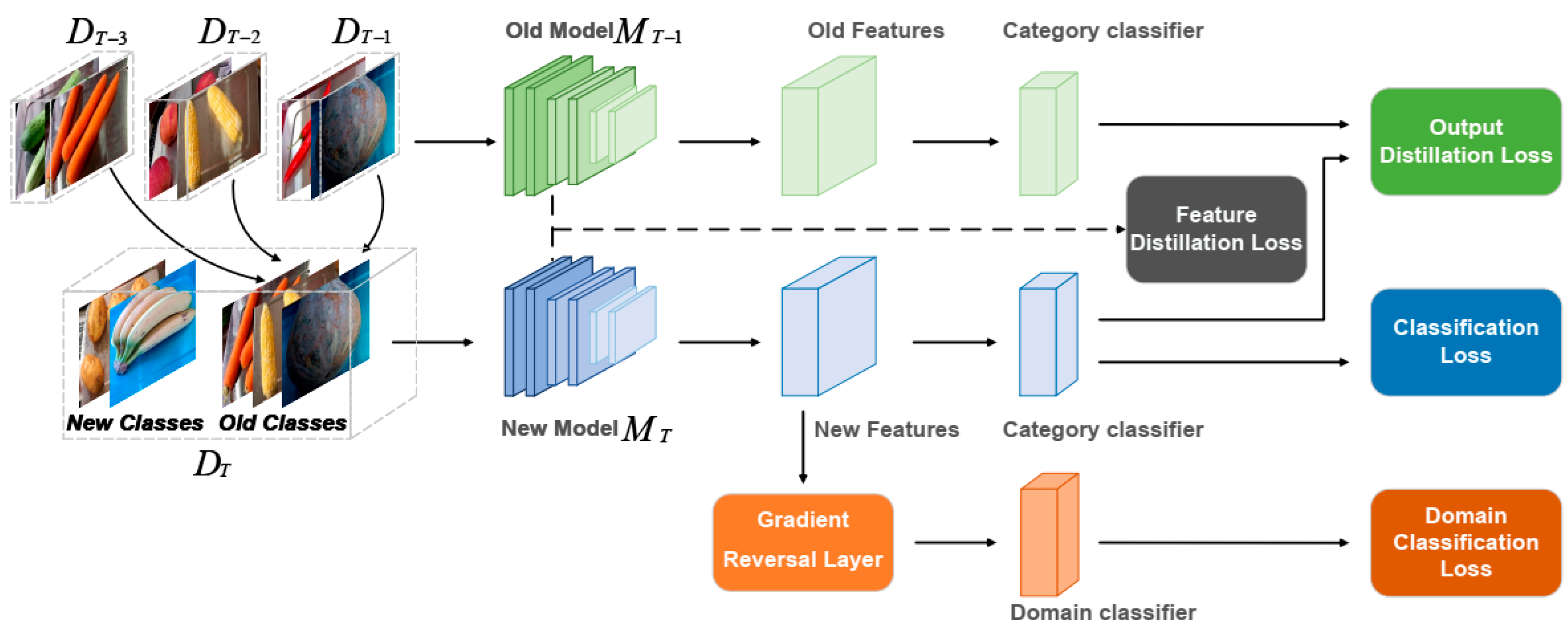
2.3. Architecture of ADA-CIL
2.4. Adversarial Domain Adaptation
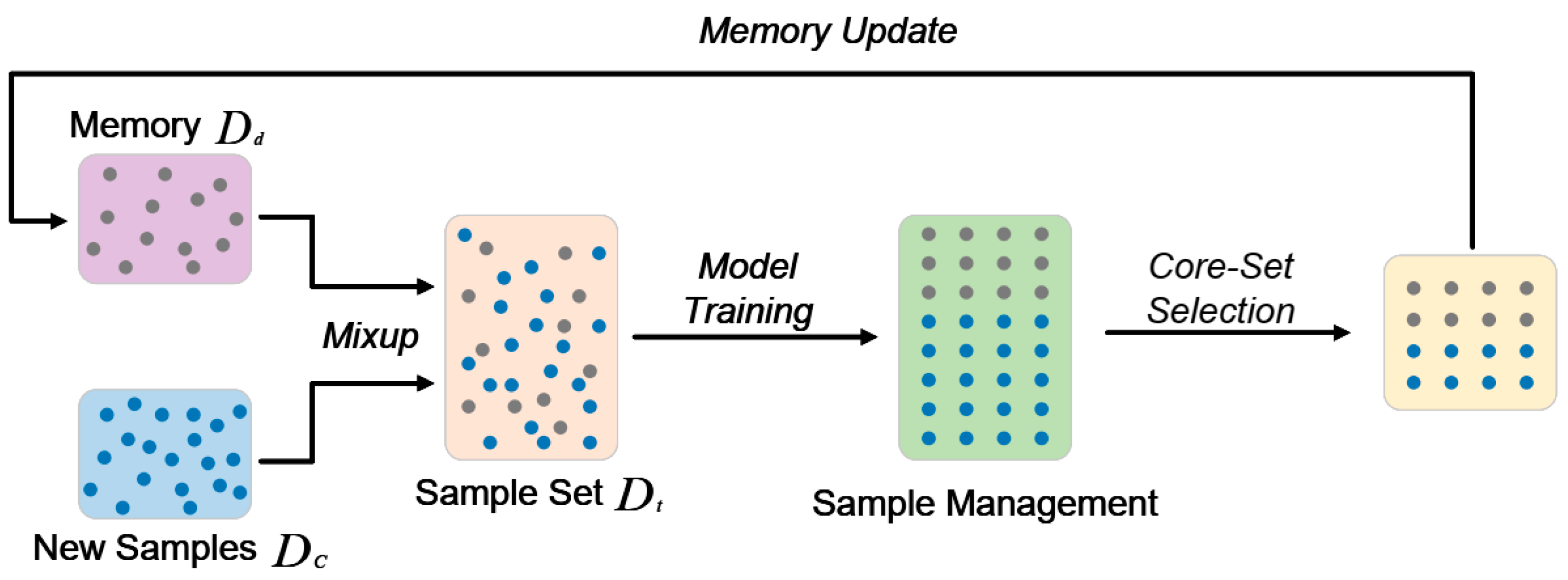
2.5. Distillation and Core-Set Selection
2.6. Online Sample Generation
2.7. Experimental Setup
3. Results and Discussion
3.1. Evaluation Methods
3.2. Results Based on the FruVeg Dataset
3.3. Ablation Experiment
3.4. Effects of Number of Incremental Categories
3.5. Memory Size Variability
3.6. Influence of Sample Generation Proportion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sivaranjani, A.; Senthilrani, S.; Ashok Kumar, B.; Senthil Murugan, A. An overview of various computer vision-based grading system for various agricultural products. J. Hortic. Sci. Biotechnol. 2022, 97, 137–159. [Google Scholar] [CrossRef]
- Anderson, K. Globalization’s effects on world agricultural trade, 1960–2050. Philos. Trans. R. Soc. B Biol. Sci. 2010, 365, 3007–3021. [Google Scholar] [CrossRef] [PubMed]
- Davis, A.S.; Hill, J.D.; Chase, C.A.; Johanns, A.M.; Liebman, M. Increasing cropping system diversity balances productivity, profitability and environmental health. PLoS ONE 2012, 7, e47149. [Google Scholar] [CrossRef] [PubMed]
- Bhargava, A.; Bansal, A. Fruits and vegetables quality evaluation using computer vision: A review. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar] [CrossRef]
- Wang, Z.; Xun, Y.; Wang, Y.; Yang, Q. Review of smart robots for fruit and vegetable picking in agriculture. Int. J. Agric. Biol. Eng. 2022, 15, 33–54. [Google Scholar]
- Rocha, A.; Hauagge, D.C.; Wainer, J.; Goldenstein, S. Automatic fruit and vegetable classification from images. Comput. Electron. Agric. 2010, 70, 96–104. [Google Scholar] [CrossRef]
- Steinbrener, J.; Posch, K.; Leitner, R. Hyperspectral fruit and vegetable classification using convolutional neural networks. Comput. Electron. Agric. 2019, 162, 364–372. [Google Scholar] [CrossRef]
- Toivonen, P.M.; Brummell, D.A. Biochemical bases of appearance and texture changes in fresh-cut fruit and vegetables. Postharvest Biol. Technol. 2008, 48, 1–14. [Google Scholar] [CrossRef]
- Pu, Y.Y.; Feng, Y.Z.; Sun, D.W. Recent progress of hyperspectral imaging on quality and safety inspection of fruits and vegetables: A review. Compr. Rev. Food Sci. Food Saf. 2015, 14, 176–188. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Chen, S.W.; Aditya, S.; Sivakumar, N.; Dcunha, S.; Qu, C.; Taylor, C.J.; Das, J.; Kumar, V. Robust fruit counting: Combining deep learning, tracking, and structure from motion. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1045–1052. [Google Scholar]
- Rahnemoonfar, M.; Sheppard, C. Deep count: Fruit counting based on deep simulated learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef] [PubMed]
- Gulzar, Y. Enhancing soybean classification with modified inception model: A transfer learning approach. Emir. J. Food Agric. 2024, 36, 1–9. [Google Scholar] [CrossRef]
- Hameed, K.; Chai, D.; Rassau, A. A comprehensive review of fruit and vegetable classification techniques. Image Vis. Comput. 2018, 80, 24–44. [Google Scholar] [CrossRef]
- Liu, Y.; Pu, H.; Sun, D.W. Efficient extraction of deep image features using convolutional neural network (CNN) for applications in detecting and analysing complex food matrices. Trends Food Sci. Technol. 2021, 113, 193–204. [Google Scholar] [CrossRef]
- Amri, E.; Gulzar, Y.; Yeafi, A.; Jendoubi, S.; Dhawi, F.; Mir, M.S. Advancing automatic plant classification system in Saudi Arabia: Introducing a novel dataset and ensemble deep learning approach. Model. Earth Syst. Environ. 2024, 10, 2693–2709. [Google Scholar] [CrossRef]
- Gulzar, Y.; Ünal, Z.; Ayoub, S.; Reegu, F.A.; Altulihan, A. Adaptability of deep learning: Datasets and strategies in fruit classification. BIO Web Conf. EDP Sci. 2024, 85, 01020. [Google Scholar] [CrossRef]
- Bolle, R.M.; Connell, J.H.; Haas, N.; Mohan, R.; Taubin, G. Veggievision: A produce recognition system. In Proceedings of the Third IEEE Workshop on Applications of Computer Vision (WACV’96), Sarasota, FL, USA, 2–4 December 1996; IEEE: Piscataway, NJ, USA, 1996; pp. 244–251. [Google Scholar]
- Femling, F.; Olsson, A.; Alonso-Fernandez, F. Fruit and vegetable identification using machine learning for retail applications. In Proceedings of the 2018 14th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Las Palmas de Gran Canaria, Spain, 26–29 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 9–15. [Google Scholar]
- Hossain, M.S.; Al-Hammadi, M.; Muhammad, G. Automatic fruit classification using deep learning for industrial applications. IEEE Trans. Ind. Inform. 2018, 15, 1027–1034. [Google Scholar] [CrossRef]
- Rojas-Aranda, J.L.; Nunez-Varela, J.I.; Cuevas-Tello, J.C.; Rangel-Ramirez, G. Fruit classification for retail stores using deep learning. In Proceedings of the Pattern Recognition: 12th Mexican Conference, MCPR 2020, Morelia, Mexico, 24–27 June 2020; Springer: New York, NY, USA, 2020; pp. 3–13. [Google Scholar]
- Li, Z.; Li, F.; Zhu, L.; Yue, J. Vegetable recognition and classification based on improved VGG deep learning network model. Int. J. Comput. Intell. Syst. 2020, 13, 559–564. [Google Scholar] [CrossRef]
- Bazame, H.C.; Molin, J.P.; Althoff, D.; Martello, M. Detection, classification, and mapping of coffee fruits during harvest with computer vision. Comput. Electron. Agric. 2021, 183, 106066. [Google Scholar] [CrossRef]
- Hameed, K.; Chai, D.; Rassau, A. Class distribution-aware adaptive margins and cluster embedding for classification of fruit and vegetables at supermarket self-checkouts. Neurocomputing 2021, 461, 292–309. [Google Scholar] [CrossRef]
- Gulzar, Y. Fruit image classification model based on MobileNetV2 with deep transfer learning technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Gao, X.; Xiao, Z.; Deng, Z. High accuracy food image classification via vision transformer with data augmentation and feature augmentation. J. Food Eng. 2024, 365, 111833. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Alkanan, M.; Gulzar, Y. Enhanced corn seed disease classification: Leveraging MobileNetV2 with feature augmentation and transfer learning. Front. Appl. Math. Stat. 2024, 9, 1320177. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Mirza, M.; Xiao, D.; Courville, A.; Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv 2013, arXiv:1312.6211. [Google Scholar]
- Rannen, A.; Aljundi, R.; Blaschko, M.B.; Tuytelaars, T. Encoder based lifelong learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1320–1328. [Google Scholar]
- Hou, S.; Pan, X.; Loy, C.C.; Wang, Z.; Lin, D. Learning a unified classifier incrementally via rebalancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 831–839. [Google Scholar]
- Dhar, P.; Singh, R.V.; Peng, K.C.; Wu, Z.; Chellappa, R. Learning without memorizing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5138–5146. [Google Scholar]
- van de Ven, G.M.; Tuytelaars, T.; Tolias, A.S. Three types of incremental learning. Nat. Mach. Intell. 2022, 4, 1185–1197. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Zheng, L.; Guan, T.; Yu, J.; Yang, Y. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2507–2516. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1180–1189. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Xiao, Q.; Luo, H.; Zhang, C. Margin sample mining loss: A deep learning based method for person re-identification. arXiv 2017, arXiv:1710.00478. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 June 2018; pp. 6848–6856. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Wu, Y.; Chen, Y.; Wang, L.; Ye, Y.; Liu, Z.; Guo, Y.; Fu, Y. Large scale incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 374–382. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Parameter | Camera 1 | Camera 2 |
|---|---|---|
| Model | HDR-IR Wide-Angle Camera | HDR-IR Standard Camera |
| Resolution | 1920 × 1080 pixels | 1920 × 1080 pixels |
| Dynamic Range | 120 dB | 100 dB |
| Lens | 16 mm wide-angle lens | 35 mm standard lens |
| Infrared Capability | With IR cut filter | No IR capability |
| Frame Rate | 30 frames per second | 15 frames per second |
| Method | Acc | Forget | Cumul | Cur |
|---|---|---|---|---|
| joint | 97.00 | 5.41 | 94.37 | 99.93 |
| iCaRL | 94.65 | 5.65 | 94.15 | 99.95 |
| BiC | 94.48 | 5.72 | 93.97 | 99.28 |
| ADA-CIL | 96.30 | 2.96 | 96.26 | 98.60 |
| Method | Acc | Forget | Cumul | Cur |
|---|---|---|---|---|
| Lcls | 90.32 | 9.03 | 89.31 | 99.86 |
| Lcls + Ldomain | 90.85 | 8.79 | 89.83 | 99.88 |
| Lcls + Ldomain + Ldis2 | 93.48 | 8.88 | 90.74 | 99.85 |
| Lcls + Ldomain + Ldis + Ldis2 | 95.33 | 4.94 | 94.83 | 99.87 |
| Method | Acc | Forget | Cumul | Cur |
|---|---|---|---|---|
| Baseline | 95.33 | 4.94 | 94.83 | 99.87 |
| Core-Set Selection | 95.53 | 4.87 | 94.72 | 99.90 |
| Mix-up | 94.74 | 3.37 | 94.70 | 99.90 |
| Core-Set Selection + Mix-up | 96.30 | 2.96 | 96.26 | 98.60 |
| 10 | 20 | |||||||
|---|---|---|---|---|---|---|---|---|
| Number | Acc | Forget | Cumul | Cur | Acc | Forget | Cumul | Cur |
| joint | 97.00 | 5.41 | 94.37 | 99.93 | 94.47 | 6.53 | 93.27 | 99.94 |
| iCaRL | 94.65 | 5.65 | 94.15 | 99.95 | 94.76 | 6.9 | 92.89 | 99.93 |
| BiC | 94.48 | 5.72 | 93.97 | 99.28 | 92.95 | 8.04 | 91.53 | 98.84 |
| ADA-CIL | 96.30 | 2.96 | 96.26 | 98.60 | 96.37 | 2.92 | 95.64 | 98.85 |
| 800 | 1000 | |||||||
|---|---|---|---|---|---|---|---|---|
| Number | Acc | Forget | Cumul | Cur | Acc | Forget | Cumul | Cur |
| joint | 97.0 | 5.41 | 94.36 | 99.93 | 97.0 | 5.41 | 94.37 | 99.93 |
| iCaRL | 91.03 | 8.31 | 91.26 | 99.84 | 94.65 | 5.65 | 94.15 | 99.95 |
| BiC | 80.84 | 20.56 | 78.76 | 98.43 | 94.48 | 5.72 | 93.97 | 99.28 |
| ADA-CIL | 88.19 | 6.88 | 91.94 | 99.89 | 96.30 | 2.96 | 96.26 | 98.60 |
| Rate | Acc | Forget | Cumul | Cur |
|---|---|---|---|---|
| 0.0 | 95.53 | 4.87 | 94.72 | 99.90 |
| 0.2 | 96.22 | 5.06 | 95.79 | 98.23 |
| 0.5 | 95.79 | 4.03 | 95.34 | 98.78 |
| 1.0 | 96.30 | 2.96 | 96.26 | 98.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, K.; Chen, H.; Zheng, Y.; Liu, Q.; Ren, S.; Hu, H.; Liang, J. Efficient Adaptive Incremental Learning for Fruit and Vegetable Classification. Agronomy 2024, 14, 1275. https://doi.org/10.3390/agronomy14061275
Guo K, Chen H, Zheng Y, Liu Q, Ren S, Hu H, Liang J. Efficient Adaptive Incremental Learning for Fruit and Vegetable Classification. Agronomy. 2024; 14(6):1275. https://doi.org/10.3390/agronomy14061275
Chicago/Turabian StyleGuo, Kaitai, Hongliang Chen, Yang Zheng, Qixin Liu, Shenghan Ren, Haihong Hu, and Jimin Liang. 2024. "Efficient Adaptive Incremental Learning for Fruit and Vegetable Classification" Agronomy 14, no. 6: 1275. https://doi.org/10.3390/agronomy14061275