

Regional Winter Wheat Yield Prediction and Variable Importance Analysis Based on Multisource Environmental Data

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
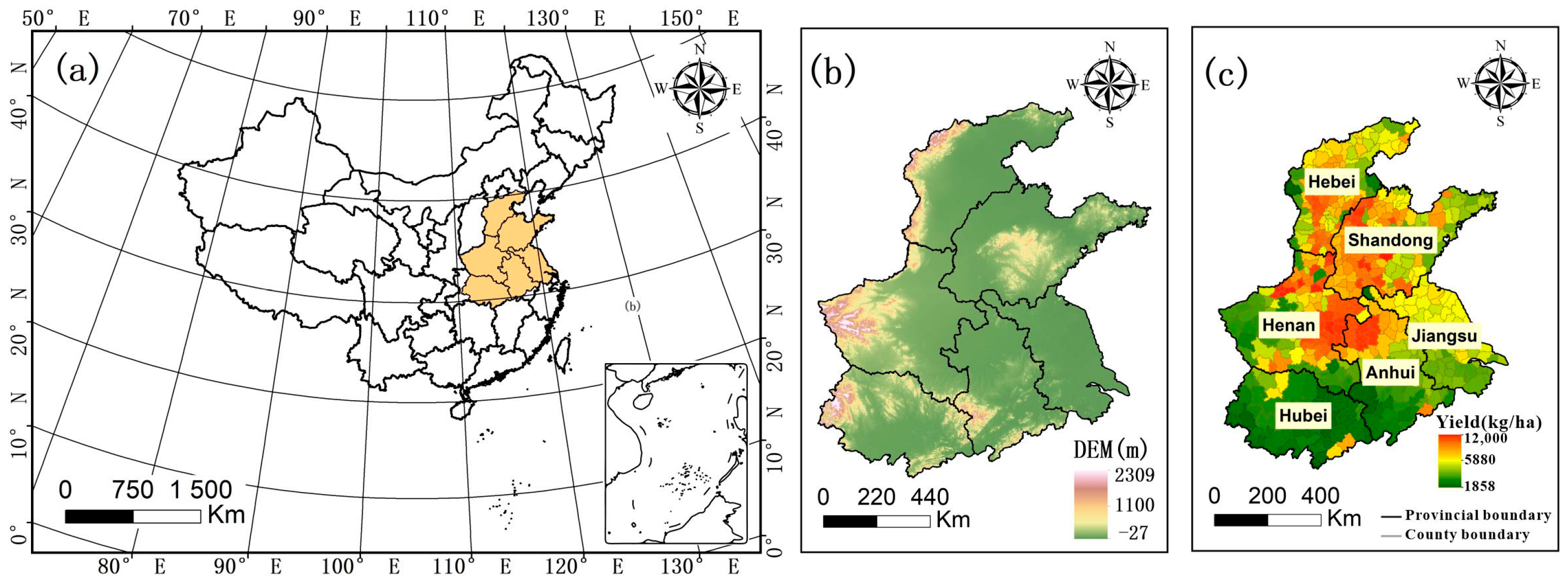
2.1. Research Area
2.2. Data Description
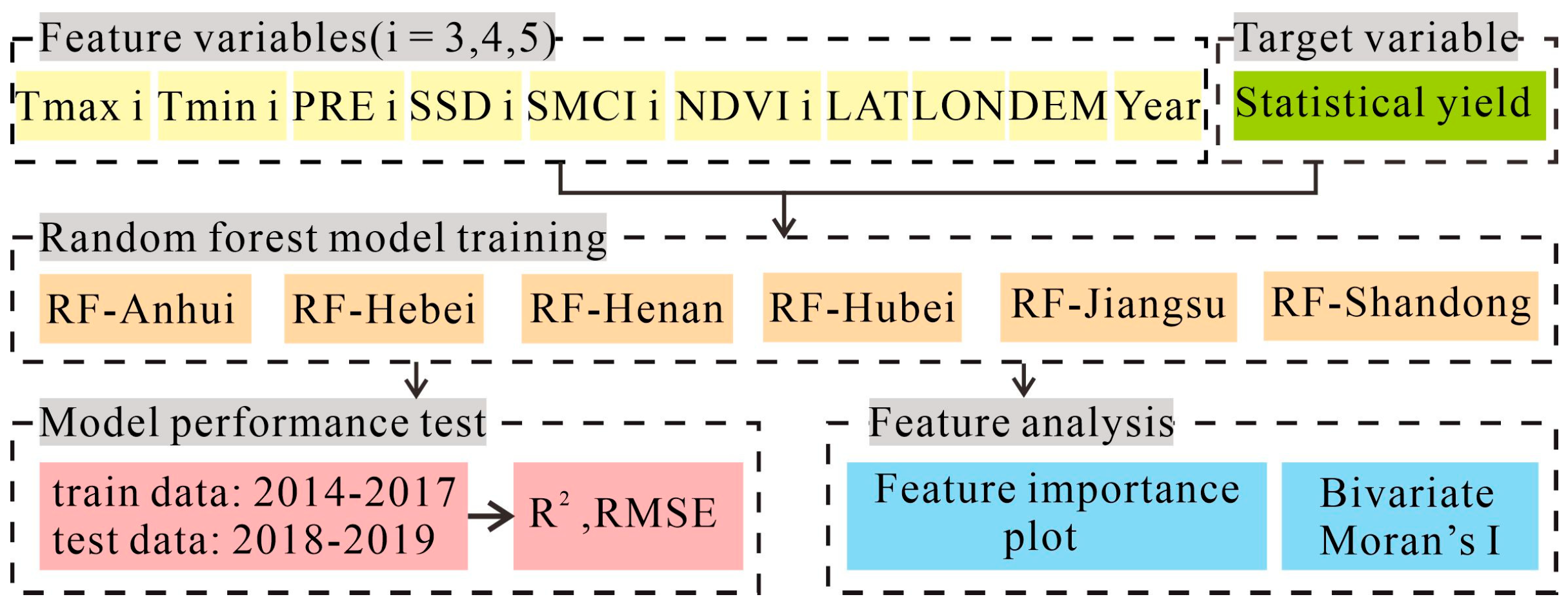
2.3. Analysis Workflow
2.4. Random Forest
2.5. Bivariate Moran’s I
3. Results and Discussion
3.1. Descriptive Statistics
3.2. Model Performance Evaluation
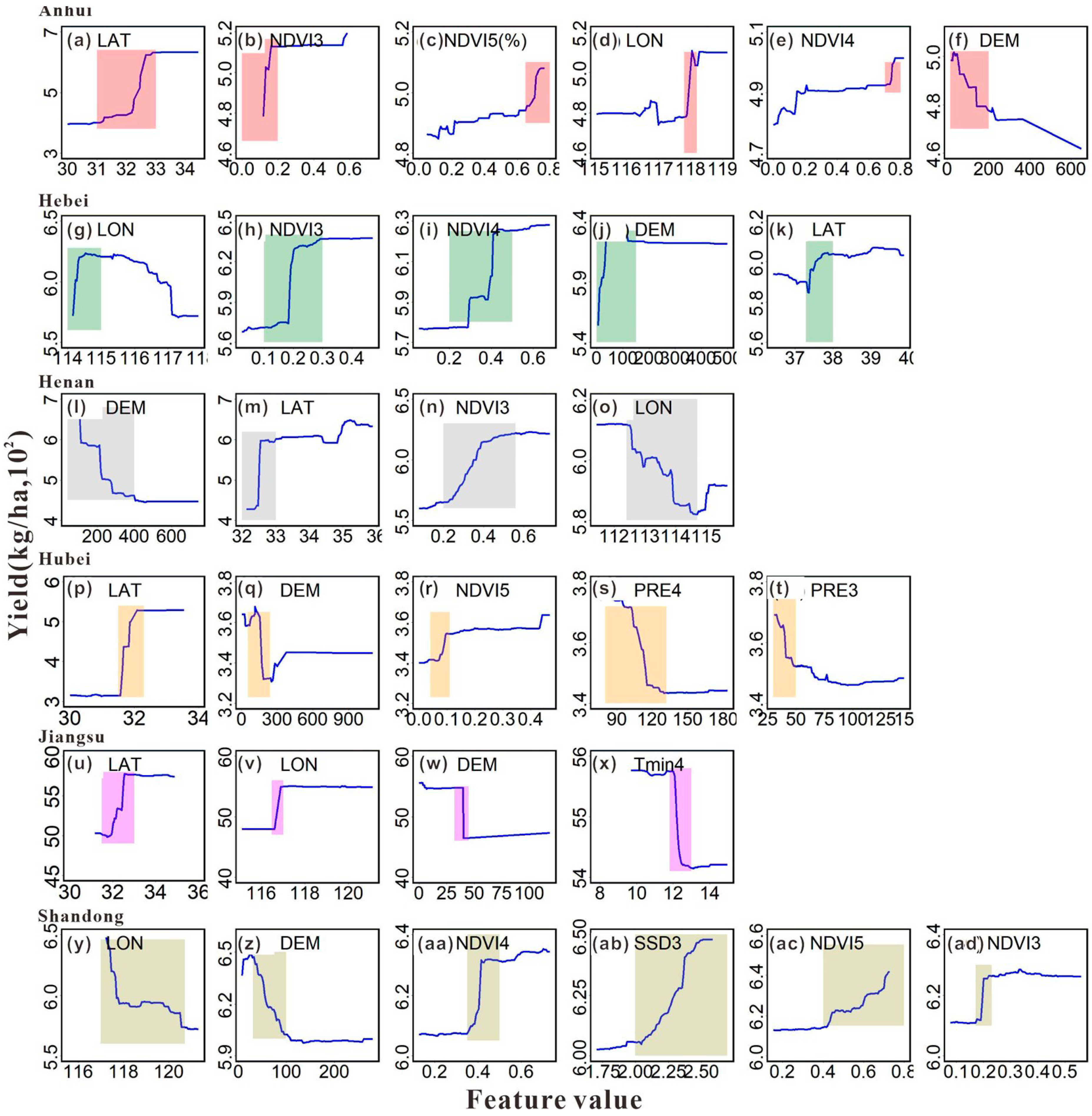
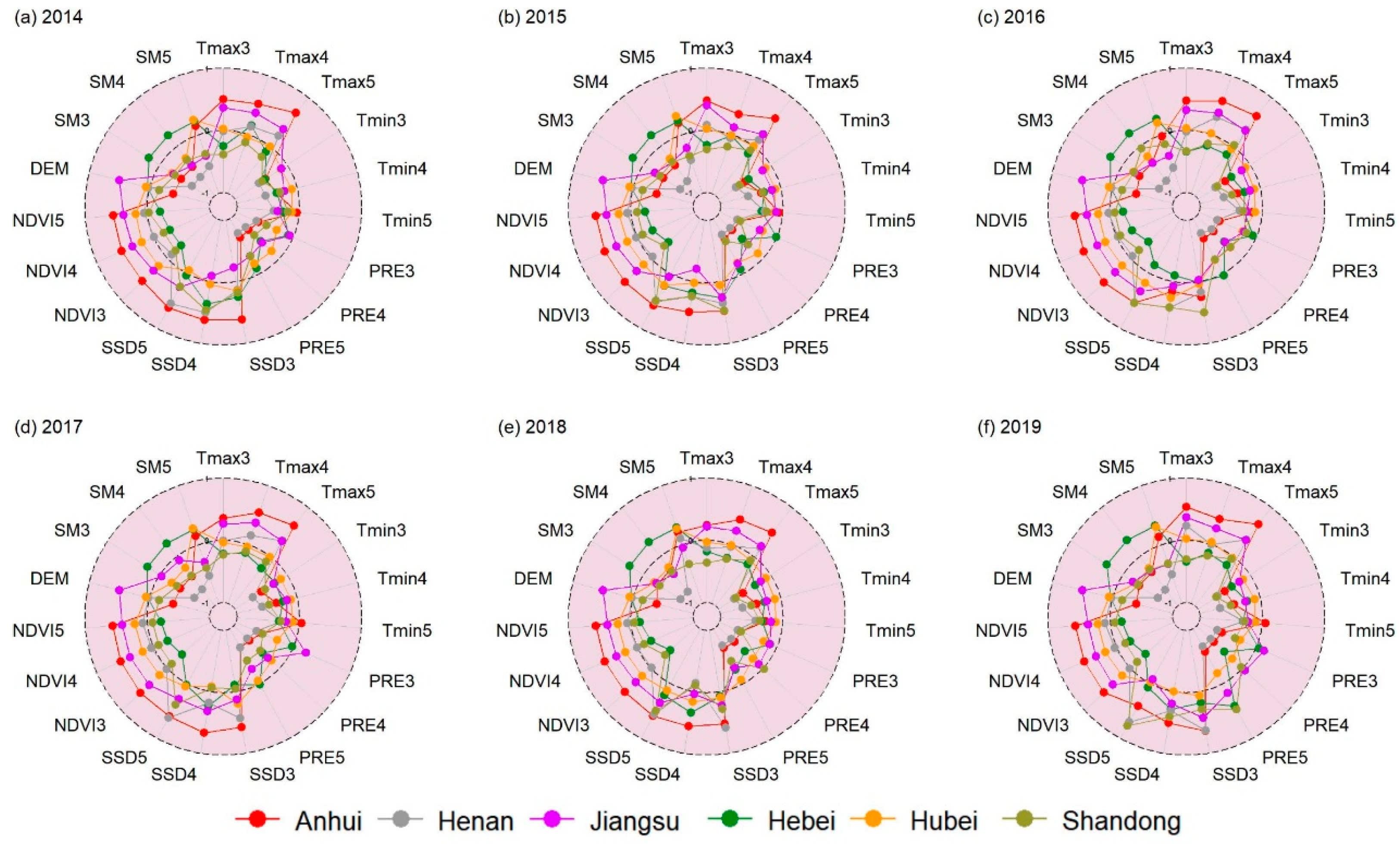
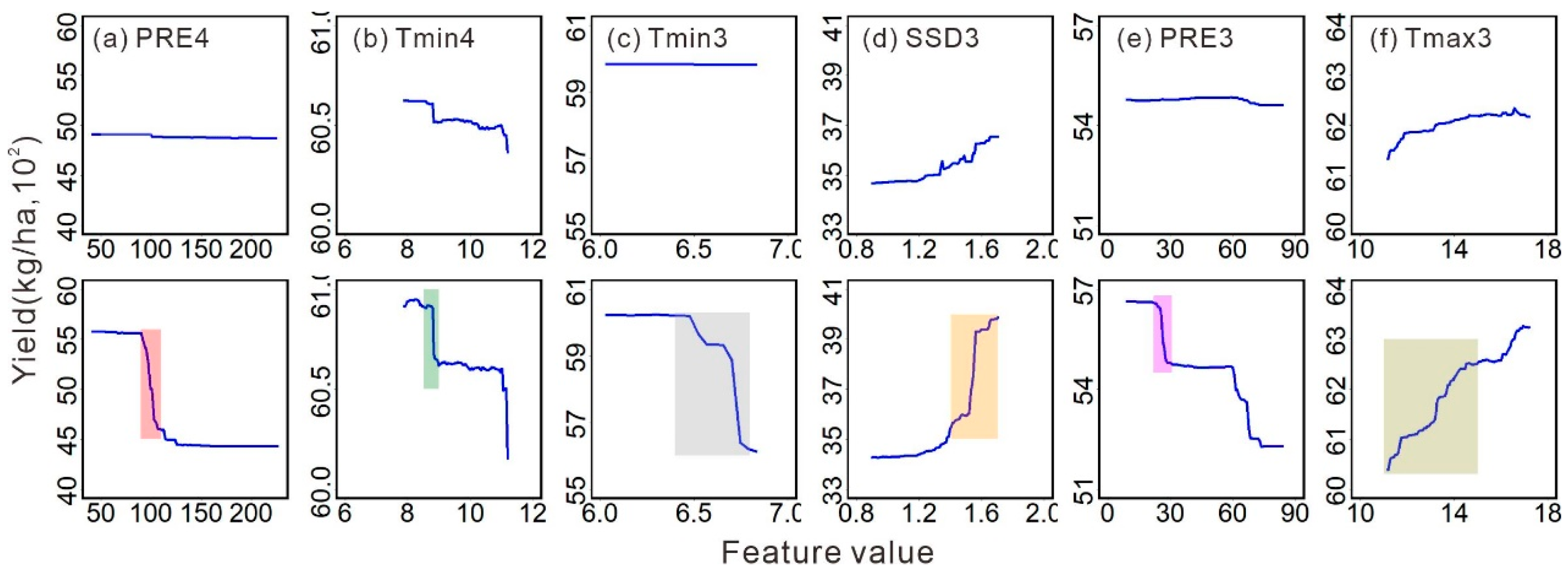
3.3. Variable Importance
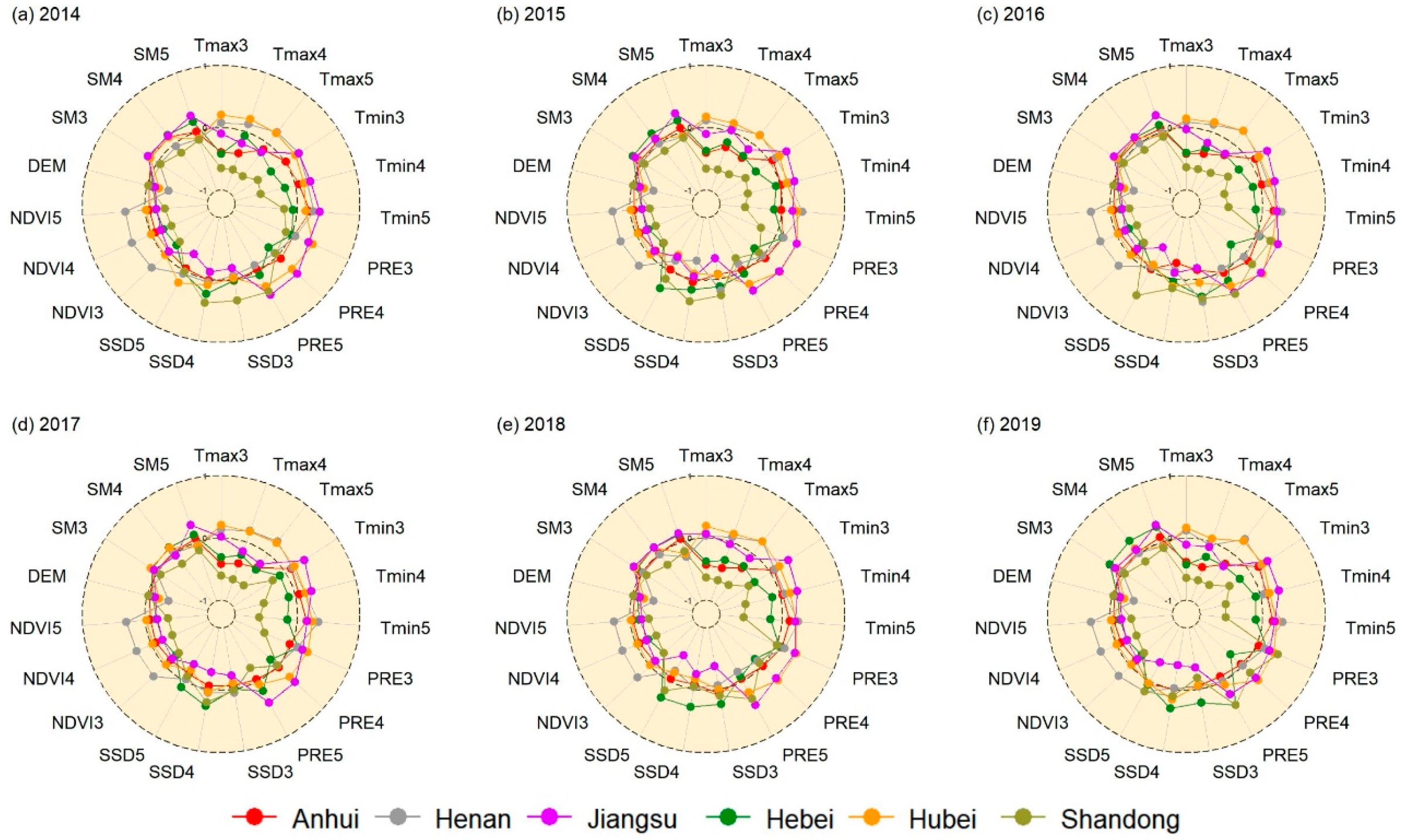
3.4. Bivariate Moran’s I
3.5. Limitations of This Research
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sunoj, S.; Polson, B.; Vaish, I.; Marcaida, M., III; Longchamps, L.; van Aardt, J.; Ketterings, Q.M. Corn grain and silage yield class prediction for zone delineation using high-resolution satellite imagery. Agric. Syst. 2024, 218, 104009. [Google Scholar] [CrossRef]
- Gang, Z.; Siebert, S.; Enders, A.; Rezaei, E.E.; Yan, C.; Ewert, F. Demand for multi-scale weather data for regional crop modeling. Agric. For. Meteorol. 2015, 200, 156–171. [Google Scholar] [CrossRef]
- Dilli, P.; Boogaard, H.; de Wit, A.; van der Velde, M.; Claverie, M.; Nisini, L.; Janssen, S.; Osinga, S.; Athanasiadis, I.N. Machine learning for regional crop yield forecasting in Europe. Field Crops Res. 2022, 276, 108377. [Google Scholar] [CrossRef]
- Ryoya, T.; Matsui, T.; Tanaka, T.S.T. Winter wheat yield prediction using convolutional neural networks and UAV-based multispectral imagery. Field Crops Res. 2023, 291, 108786. [Google Scholar] [CrossRef]
- Rosenzweig, C.; Elliott, J.; Deryng, D.; Ruane, A.C.; Müller, C.; Arneth, A.; Boote, K.J.; Folberth, C.; Glotter, M.; Khabarov, N.; et al. Assessing agricultural risks of climate change in the 21st century in a global gridded crop model intercomparison. Proc. Natl. Acad. Sci. USA 2014, 11, 3268–3273. [Google Scholar] [CrossRef] [PubMed]
- Yi, X. Combining CERES-Wheat model, Sentinel-2 data, and deep learning method for winter wheat yield estimation. Int. J. Remote Sens. 2022, 43, 630–648. [Google Scholar] [CrossRef]
- Zare, H.; Weber, T.K.D.; Ingwersen, J.; Nowak, W.; Gayler, S.; Streck, T. Within-season crop yield prediction by a multi-model ensemble with integrated data assimilation. Field Crops Res. 2024, 308, 109293. [Google Scholar] [CrossRef]
- Wei, L.; Yang, H.; Niu, Y.; Zhang, Y.; Xu, L.; Chai, X. Wheat biomass, yield, and straw-grain ratio estimation from multi-temporal UAV-based RGB and multispectral images. Biosyst. Eng. 2023, 234, 187–205. [Google Scholar] [CrossRef]
- Bansal, Y.; Lillis, D.; Kechadi, M.T. A neural meta model for predicting winter wheat crop yield. Mach. Learn. 2024, 113, 3771–3788. [Google Scholar] [CrossRef]
- Hoffman, A.L.; Kemanian, A.R.; Forest, C.E. Analysis of climate signals in the crop yield record of sub-Saharan Africa. Glob. Chang. Biol. 2018, 24, 143–157. [Google Scholar] [CrossRef]
- Li, L.; Wang, B.; Feng, P.; Wang, H.; He, Q.; Wang, Y.; Liu, D.L.; Li, Y.; He, J.; Feng, H.; et al. Crop yield forecasting and associated optimum lead time analysis based on multi-source environmental data across China. Agric. For. Meteorol. 2021, 308, 108558. [Google Scholar] [CrossRef]
- Karsoliya, S. Approximating number of hidden layer neurons in multiple hidden layer BPNN architecture. Int. J. Eng. Trends Technol. 2012, 3, 714–717. [Google Scholar]
- El-Sharkawy, M.; Li, J.; Kamal, N.; Mahmoud, E.; Omara, A.E.-D.; Du, D. Assessing and Predicting Soil Quality in Heavy Metal-Contaminated Soils: Statistical and ANN-Based Techniques. J. Soil. Sci. Plant Nutr. 2023, 23, 6510–6526. [Google Scholar] [CrossRef]
- Barlow, K.M.; Christy, B.P.; O’Leary, G.J.; Riffkin, P.A.; Nuttall, J.G. Simulating the impact of extreme heat and frost events on wheat crop production: A review. Field Crops Res. 2015, 171, 109–119. [Google Scholar] [CrossRef]
- Yang, H.S.; Bishop, T.F.A.; Filippi, P. Data-driven, early-season forecasts of block sugarcane yield for precision agriculture. Field Crops Res. 2022, 276, 108360. [Google Scholar] [CrossRef]
- Xu, H.; Huang, F.; Zuo, W.; Tian, Y.; Zhu, Y.; Cao, W.; Zhang, X. Impacts of spatial zonation schemes on yield potential estimates at the regional scale. Agronomy 2020, 10, 631. [Google Scholar] [CrossRef]
- Zheng, J.; Yin, Y.H.; Li, B.Y. A new scheme for climate regionalization in China. Acta Geogr. Sin. 2010, 65, 3–12. [Google Scholar] [CrossRef]
- Li, Q.; Shi, G.; Shangguan, W.; Nourani, V.; Li, J.; Li, L.; Huang, F.; Zhang, Y.; Wang, C.; Wang, D.; et al. A 1 km daily soil moisture dataset over China using in situ measurement and machine learning. Earth Syst. Sci. Data 2022, 14, 5267–5286. [Google Scholar] [CrossRef]
- International Food Policy Research Institute (IFPRI). Global Spatially-Disaggregated Crop Production Statistics Data for 2020 Version 1.0.0. Harvard Dataverse, V1. Available online: https://www.agrodep.org/resource/harvestchoice-spatial-production-allocation-model-spam-2000 (accessed on 19 December 2023).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Elbeltagi, A.; Srivastava, A.; Deng, J.; Li, Z.; Raza, A.; Khadke, L.; Yu, Z.; El-Rawy, M. Forecasting vapor pressure deficit for agricultural water management using machine learning in semi-arid environments. Agric. Water Manag. 2023, 283, 108302. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lee, S.-I. Developing a bivariate spatial association measure: An integration of Pearson’s r and Moran’s I. J. Geogr. Syst. 2001, 3, 369–385. [Google Scholar] [CrossRef]
- Hu, B.; Shao, S.; Ni, H.; Fu, Z.; Huang, M.; Chen, Q.; Shi, Z. Assessment of potentially toxic element pollution in soils and related health risks in 271 cities across China. Environ. Pollut. 2021, 270, 116196. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Zhang, X.; Ye, Z.; Jiang, L.; Qiu, X.; Tian, Y.; Zhu, Y.; Cao, W. Machine learning approaches can reduce environmental data requirements for regional yield potential simulation. Eur. J. Agron. 2021, 129, 126335. [Google Scholar] [CrossRef]
- Arshad, S.; Kazmi, J.H.; Javed, M.G.; Mohammed, S. Applicability of machine learning techniques in predicting wheat yield based on remote sensing and climate data in Pakistan, South Asia. Eur. J. Agron. 2023, 147, 126837. [Google Scholar] [CrossRef]
- Narin, M.G.; Noyan, M.F.; Abdikan, S. Monitoring Vegetative Stages of Sunflower and Wheat Crops with Sentinel-2 Images According to BBCH-Scale. J. Agric. Fac. Gaziosmanpasa Univ. 2021, 38, 46–52. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Luo, Y.; Zhang, L.; Zhang, J.; Li, Z.; Tao, F. Wheat yield predictions at a county and field scale with deep learning, machine learning, and google earth engine. Eur. J. Agron. 2021, 123, 126204. [Google Scholar] [CrossRef]
- Wei, J.; Tang, X.; Gu, Q.; Wang, M.; Ma, M.; Han, X. Using solar-induced chlorophyll fluorescence observed by OCO-2 to predict autumn crop production in China. Remote Sens. 2019, 11, 1715. [Google Scholar] [CrossRef]
- Leo, S.; De Antoni Migliorati, M.; Grace, P.R. Predicting within-field cotton yields using publicly available datasets and machine learning. Agron. J. 2021, 113, 1150–1163. [Google Scholar] [CrossRef]
- Tziachris, P.; Aschonitis, V.; Chatzistathis, T.; Papadopoulou, M. Assessment of spatial hybrid methods for predicting soil organic matter using DEM derivatives and soil parameters. CATENA 2019, 174, 206–216. [Google Scholar] [CrossRef]
- Fridgen, J.J.; Kitchen, N.R.; Sudduth, K.A.; Drummond, S.T.; Wiebold, W.J.; Fraisse, C.W. Management zone analyst (MZA) software for subfield management zone delineation. Agron. J. 2004, 96, 100–108. [Google Scholar] [CrossRef]
- Mu, H.; Jiang, D.; Wollenweber, B.; Dai, T.; Jing, Q.; Cao, W. Long-term low radiation decreases leaf photosynthesis, photochemical efficiency and grain yield in winter wheat. J. Agron. Crop Sci. 2010, 196, 38–47. [Google Scholar] [CrossRef]
- You, L.; Rosegrant, M.W.; Wood, S.; Sun, D. Impact of growing season temperature on wheat productivity in China. Agric. For. Meteorol. 2009, 149, 1009–1014. [Google Scholar] [CrossRef]
- Liu, B.; Liu, L.; Tian, L.; Cao, W.; Zhu, Y.; Asseng, S. Post-heading heat stress and yield impact in winter wheat of China. Glob. Chang. Biol. 2014, 20, 372–381. [Google Scholar] [CrossRef]
- Coyne, P.I.; Aiken, R.M.; Maas, S.J.; Lamm, F.R. Evaluating YieldTracker forecasts for maize in western Kansas. Agron. J. 2009, 101, 671–680. [Google Scholar] [CrossRef]
- Jia, X.; Hu, B.; Marchant, B.P.; Zhou, L.; Shi, Z.; Zhu, Y. A methodological framework for identifying potential sources of soil heavy metal pollution based on machine learning: A case study in the Yangtze Delta, China. Environ. Pollut. 2019, 250, 601–609. [Google Scholar] [CrossRef] [PubMed]
- Tiefelsdorf, M. Some practical applications of Moran’s I’s exact conditional distribution. Pap. Reg. Sci. 1998, 77, 101–129. [Google Scholar] [CrossRef]
- Tiefelsdorf, M.; Boots, B. A note on the extremities of local Moran’s Iis and their impact on global Moran’s I. Geogr. Anal. 1997, 29, 248–257. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, L.; Qiu, X.; Qiu, J.; Wang, J.; Zhu, Y. An improved method of delineating rectangular management zones using a semivariogram-based technique. Comput. Electron. Agric. 2016, 121, 74–83. [Google Scholar] [CrossRef]
- Albornoz, V.M.; Cid-García, N.M.; Ortega, R.; Ríos-Solís, Y.A. A hierarchical planning scheme based on precision agriculture. In Handbook of Operations Research in Agriculture and the Agri-Food Industry; Springer: New York, NY, USA, 2015; pp. 129–162. [Google Scholar] [CrossRef]
- Shao, J.; Li, Y.; Ni, J. The characteristics of temperature variability with terrain, latitude and longitude in Sichuan-Chongqing Region. J. Geogr. Sci. 2012, 22, 223–244. [Google Scholar] [CrossRef]
- Hopkins, J.W. Correlation of air temperature normals for the Canadian Great Plains with latitude, longitude, and altitude. Can. J. Earth Sci. 1968, 5, 199–210. [Google Scholar] [CrossRef]
- Zheng, Z.; Hoogenboom, G.; Cai, H.; Wang, Z. Winter wheat production on the Guanzhong Plain of Northwest China under projected future climate with SimCLIM. Agric. Water Manag. 2020, 239, 106233. [Google Scholar] [CrossRef]
- Raza, A.; Saber, K.; Hu, Y.; Ray, R.L.; Kaya, Y.Z.; Dehghanisanij, H.; Kisi, O.; Elbeltagi, A. Modelling reference evapotranspiration using principal component analysis and machine learning methods under different climatic environments. Irrig. Drain. 2023, 72, 945–970. [Google Scholar] [CrossRef]
- Yuan, W.; Liu, S.; Liu, W.; Zhao, S.; Dong, W.; Tao, F.; Chen, M.; Lin, H. Opportunistic market-driven regional shifts of crop practices reduce food production capacity of China. Earth’s Future 2018, 6, 634–642. [Google Scholar] [CrossRef]
- Perich, G.; Turkoglu, M.O.; Graf, L.V.; Wegner, J.D.; Aasen, H.; Walter, A.; Liebisch, F. Pixel-based yield map and prediction from Sentinel-2 using spectral indices and neural networks. Field Crops Res. 2023, 292, 108824. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Element | Format | Source | Time Resolution | Spatial Resolution |
|---|---|---|---|---|---|
| Meteorological data | Highest temperature (Tmax), minimum temperature (Tmin), sunshine hours (SSD), and precipitation (PRE) | tiff | Meteorological Information Center of China Meteorological Administration (https://data.cma.cn/, accessed on 19 December 2023) | Monthly | 1 km |
| Soil data | Ten-cm soil surface moisture | tiff | A Big Earth Data Platform for Three Poles (https://poles.tpdc.ac.cn/zh-hans/, accessed on 1 April 2023) | Daily | 1 km |
| Yield data | Statistical wheat yield | csv | China Economic and Social Big Data Research Platform (data.cnki.net) | Yearly | County area |
| Remote sensing data | Visible light band and near-infrared band | tiff | Sentinel-2, Google Earth Engine | Monthly, median composite | 10 m |
| Terrain data | Digital elevation model (DEM) | tiff | SRTMGL1_003 DEM (https://lpdaac.usgs.gov/products/srtmgl1v003/, accessed on 19 December 2023) | / | 30 m |
| Other data | Wheat planting area | tiff | Spatial production allocation model (SPAM) | / | 10 km |
| Year | Absolute Difference of the Regional Mean (kg/ha) | |||||
|---|---|---|---|---|---|---|
| Anhui | Hebei | Henan | Hubei | Jiangsu | Shandong | |
| 2018 | 270.4 | 176.7 | 209.9 | 68.2 | 36.9 | 86.5 |
| 2019 | 85.6 | 225.5 | 129 | 73.2 | 142.9 | 108.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Yin, H.; Liu, Y.; Wang, B.; Song, H.; Zheng, Z.; Zhang, X.; Jiang, L.; Wang, S. Regional Winter Wheat Yield Prediction and Variable Importance Analysis Based on Multisource Environmental Data. Agronomy 2024, 14, 1623. https://doi.org/10.3390/agronomy14081623
Xu H, Yin H, Liu Y, Wang B, Song H, Zheng Z, Zhang X, Jiang L, Wang S. Regional Winter Wheat Yield Prediction and Variable Importance Analysis Based on Multisource Environmental Data. Agronomy. 2024; 14(8):1623. https://doi.org/10.3390/agronomy14081623
Chicago/Turabian StyleXu, Hao, Hongfei Yin, Yaohui Liu, Biao Wang, Hualu Song, Zhaowen Zheng, Xiaohu Zhang, Li Jiang, and Shuai Wang. 2024. "Regional Winter Wheat Yield Prediction and Variable Importance Analysis Based on Multisource Environmental Data" Agronomy 14, no. 8: 1623. https://doi.org/10.3390/agronomy14081623