
YOLO Recognition Method for Tea Shoots Based on Polariser Filtering and LFAnet

Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Dataset Acquisition
2.2. Intense Light Image Processing
- (1)
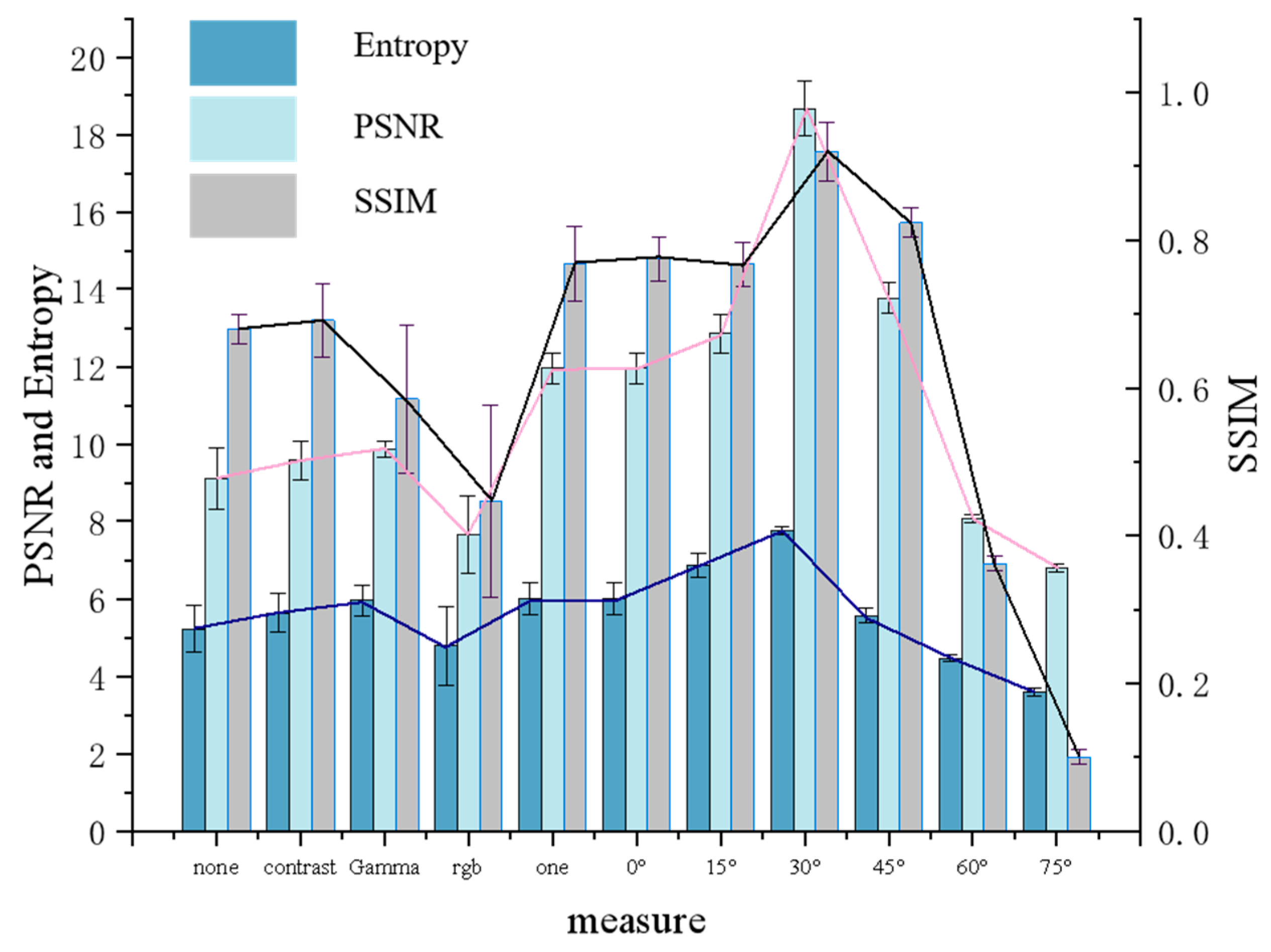
- SSIM characterises the similarity of two images. This index assessed the degree of similarity between two images based on their brightness, contrast, and structural similarities and according to the proportion of each factor, as shown in Equation (1). To evaluate the quality of the processed image, processed image x and ideal image y can be selected to determine the structural similarity. The luminance and contrast of the x and y images are calculated based on the luminance value of each pixel of each channel of the two images, and the SSIM of the two images is measured by the degree of change in the pixel gray value of the image, as shown in Equation (2). The closer the value of SSIM is to 1, the higher the degree of similarity of the x and y images. When the SSIM value is less than 0.7, it can be considered that the degree of similarity between the x and y images is low.
- (2)
- PSNR characterises the difference between two images and is used to quantitatively assess the gap between the processed image and ideal image; the larger the PSNR value, the closer the image is to the ideal image. A PSNR value less than 10 dB indicates that there is a large difference between the image and ideal image, and the quality of the image processing is poor. The formula for calculating PSNR is as follows:where MSE is the average of the mean square error of the pixel values of the three RGB channels of images I and K at coordinates . z is the difference between the maximum and minimum gray values obtained from the image.
- (3)
- Entropy measures the amount of information contained in an image. The higher the entropy value, the more informative the image is. The information content of an image is quantitatively calculated using the distribution of the gray values of the image, as shown in Equation (10).where a is the gray value, and is the probability distribution of pixel points with gray value a.
2.2.1. Image Preprocessing
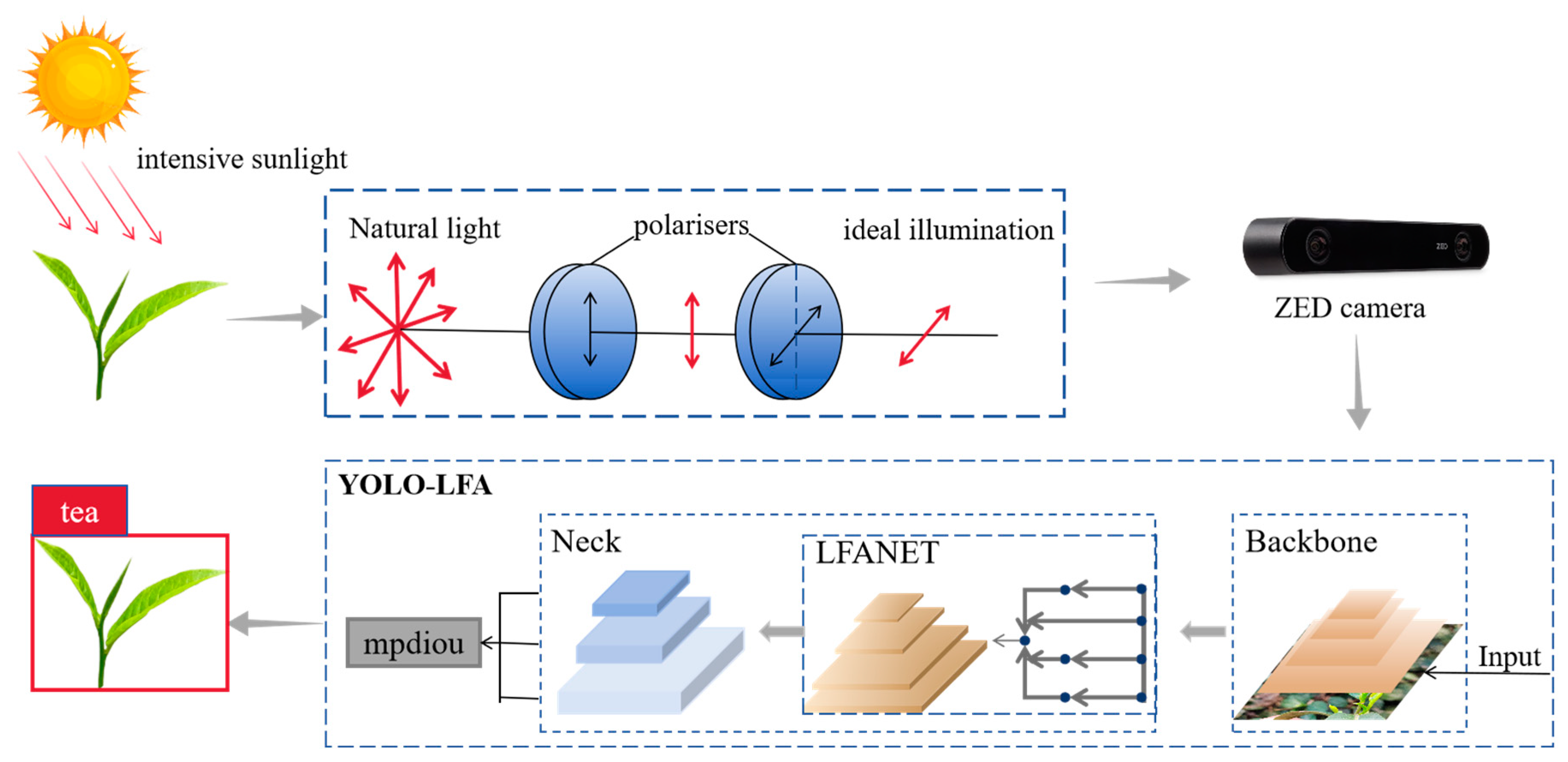
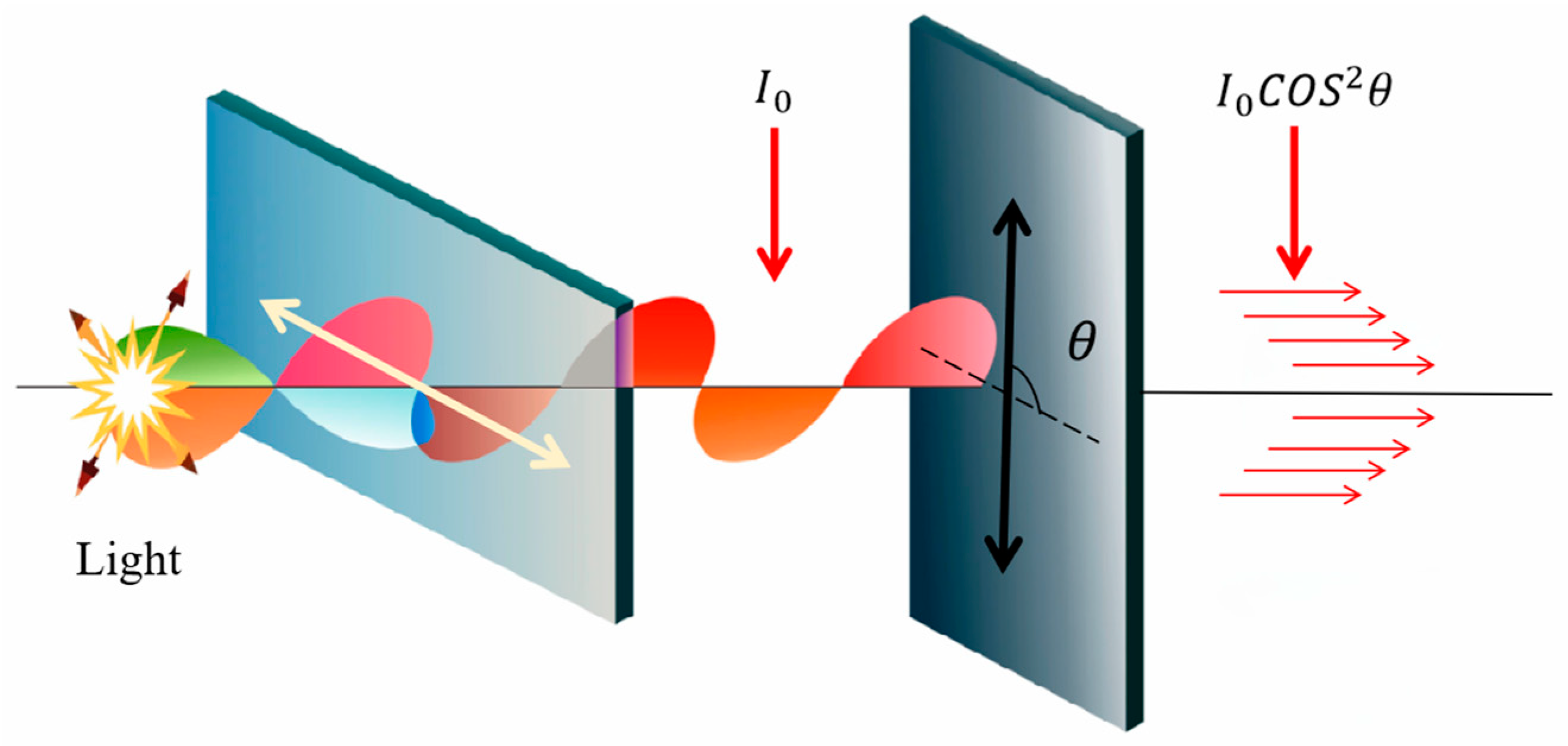
2.2.2. Polariser Filtering
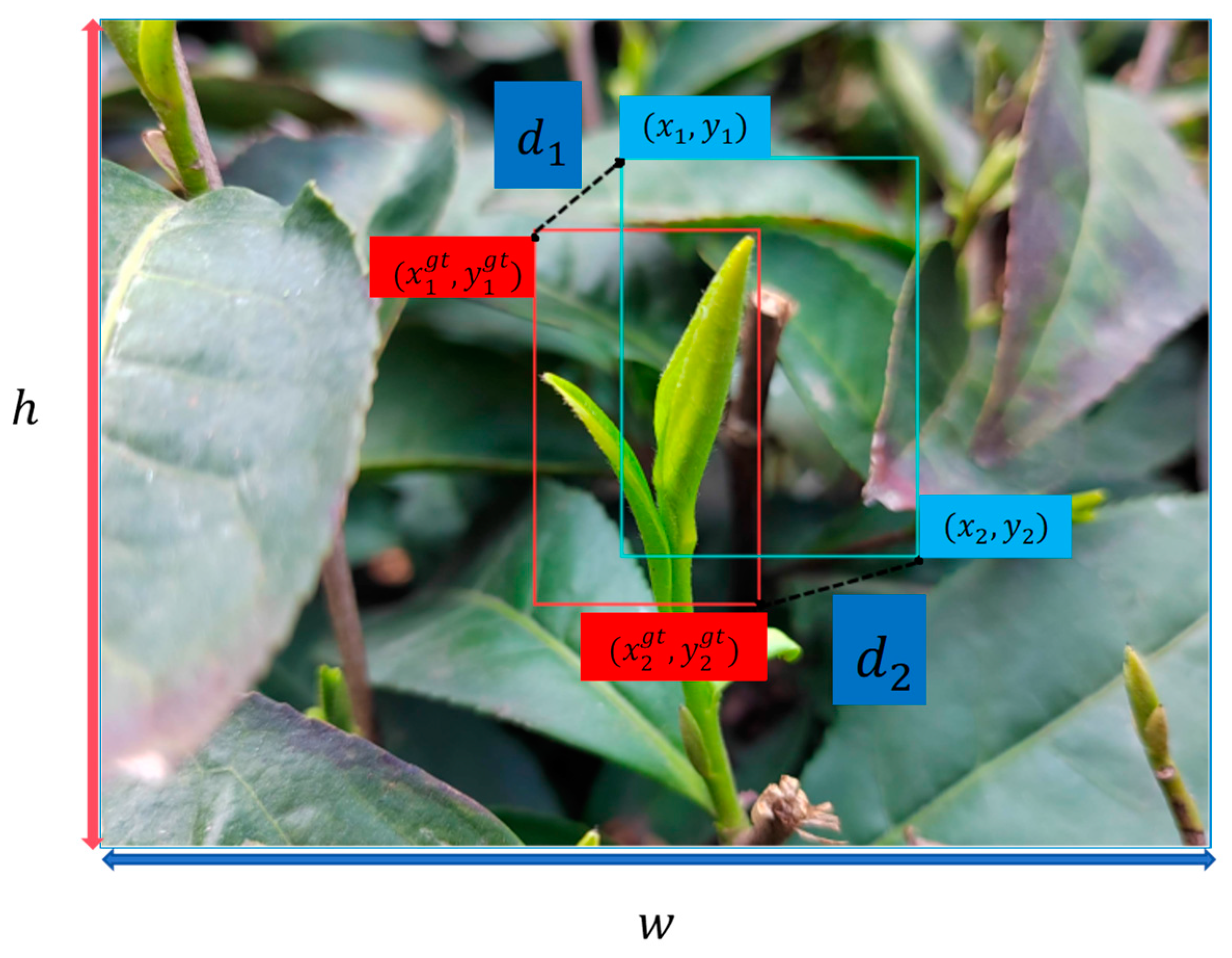
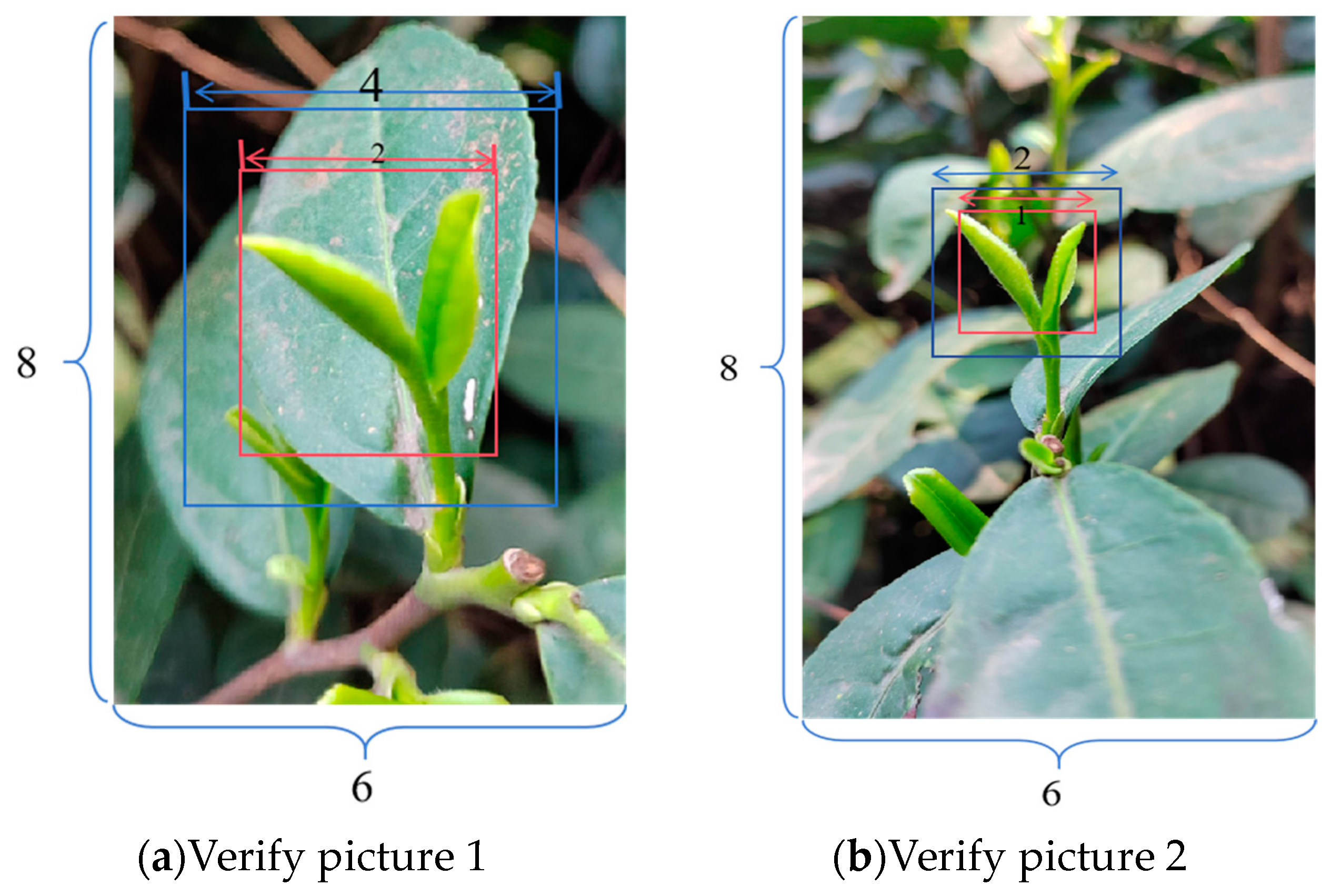
2.3. Machine Vision Inspection Based on YOLO+LFA+mpdiou
3. Results and Discussion
3.1. Image Processing Experiment
3.2. Evaluation of YOLO+LFA+mpdiou Performance
3.3. Evaluation of the Effect of Each Model in Different Environments
3.3.1. General Light Intensity Test
3.3.2. Intense Light Test
3.4. YOLOv5s+LFA+mpdiou+PF Test
3.4.1. Normal Light Intensity Test
3.4.2. Intense Light Test
4. Conclusions
4.1. Conclusions
- (1)
- When the outdoor strong light exceeds the intensity of ambient lighting, the PF method proposed in this study can significantly enhance image quality, as evidenced by a 35.7% increase in SSIM, 90.1% improvement in PSNR, and 33.3% boost in entropy compared to the original image. In other words, selecting two polarisers at appropriate angles for capturing images under intense lighting conditions can effectively prevent overexposure and improve the overall image quality.
- (2)
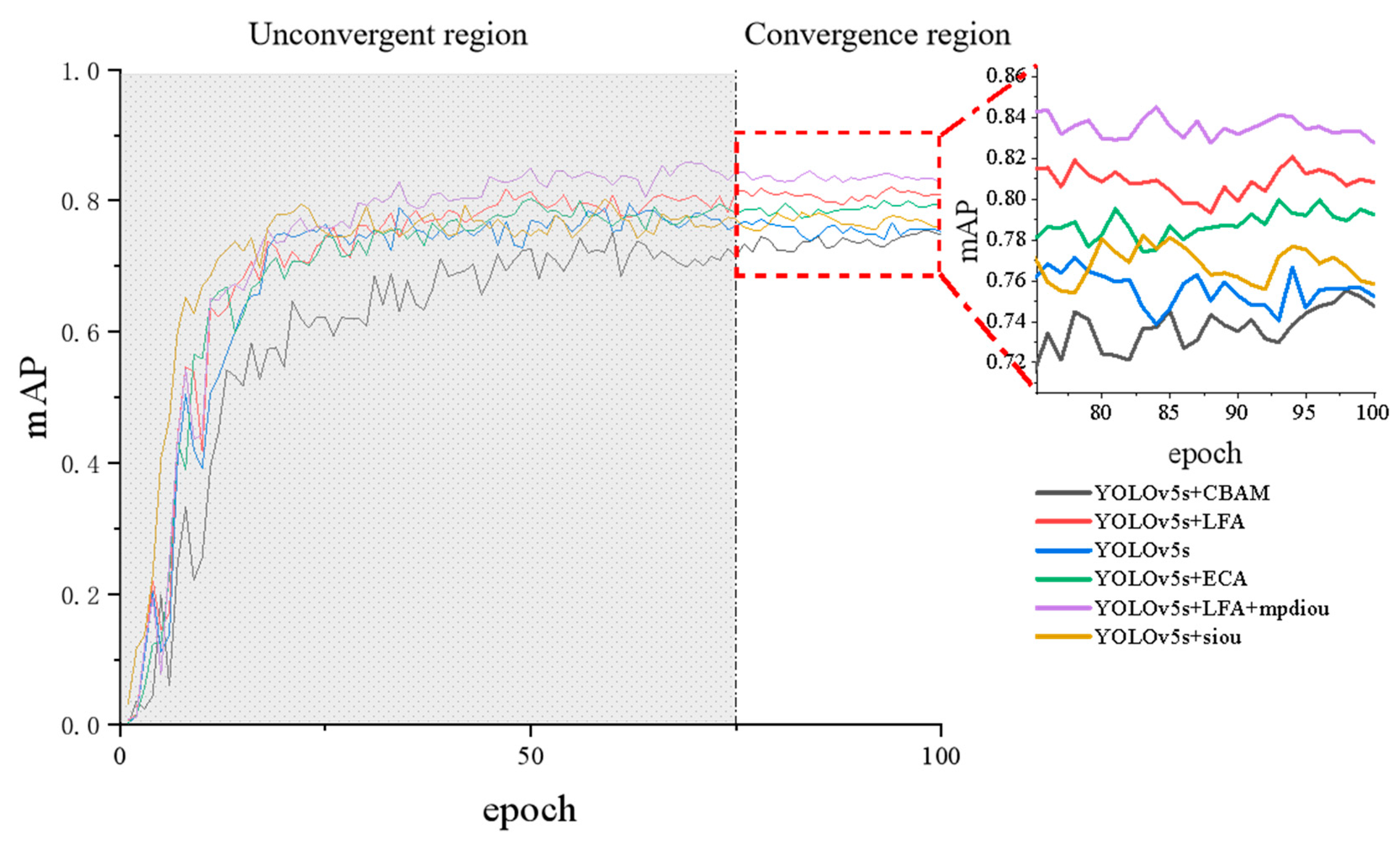
- The YOLOv5+LFA method proposed in this study enhances the detection accuracy across varying lighting conditions, including strong, ordinary, and low light conditions. Compared to the current mainstream detection algorithms’ optimal mAP value, our model achieved an approximate 4% enhancement.
- (3)
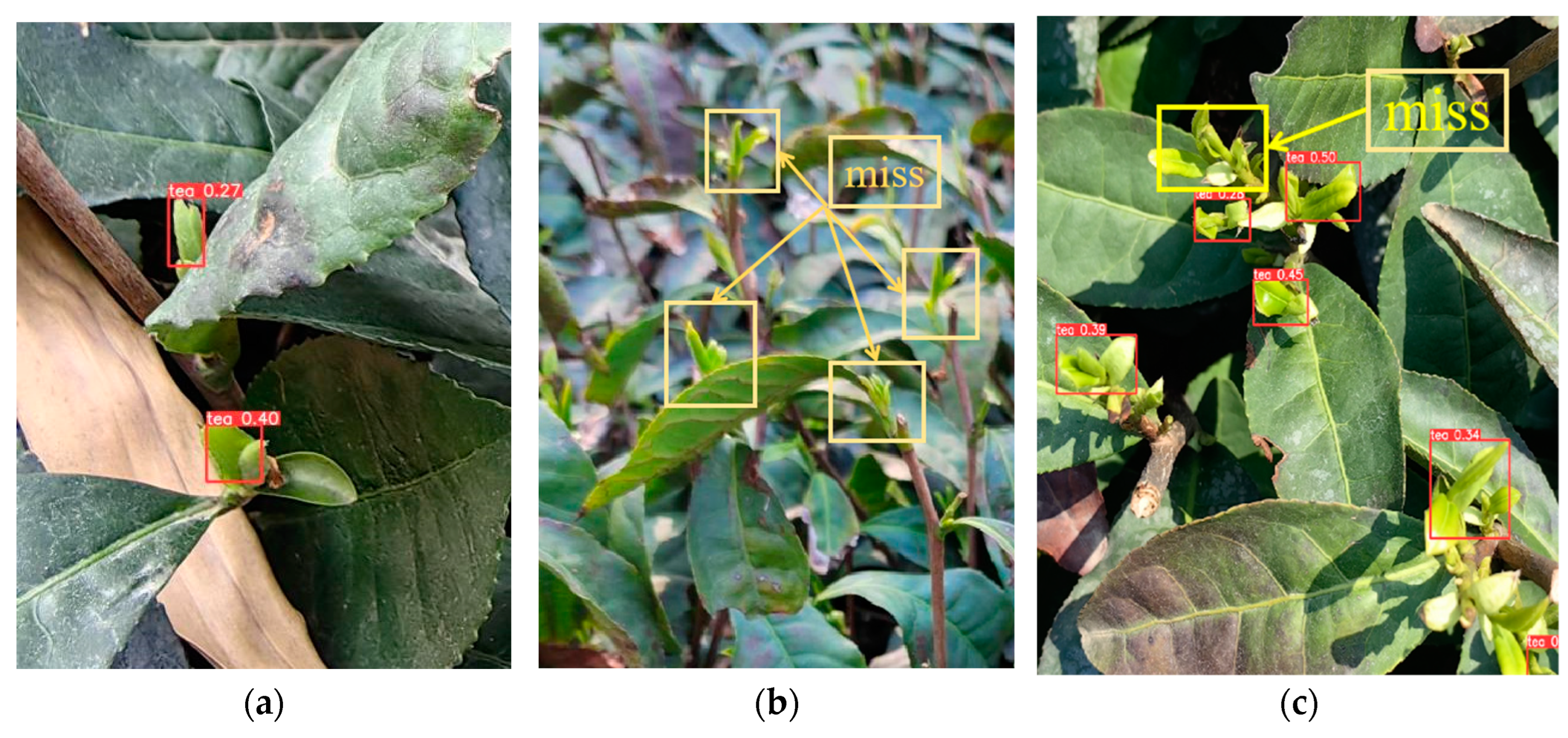
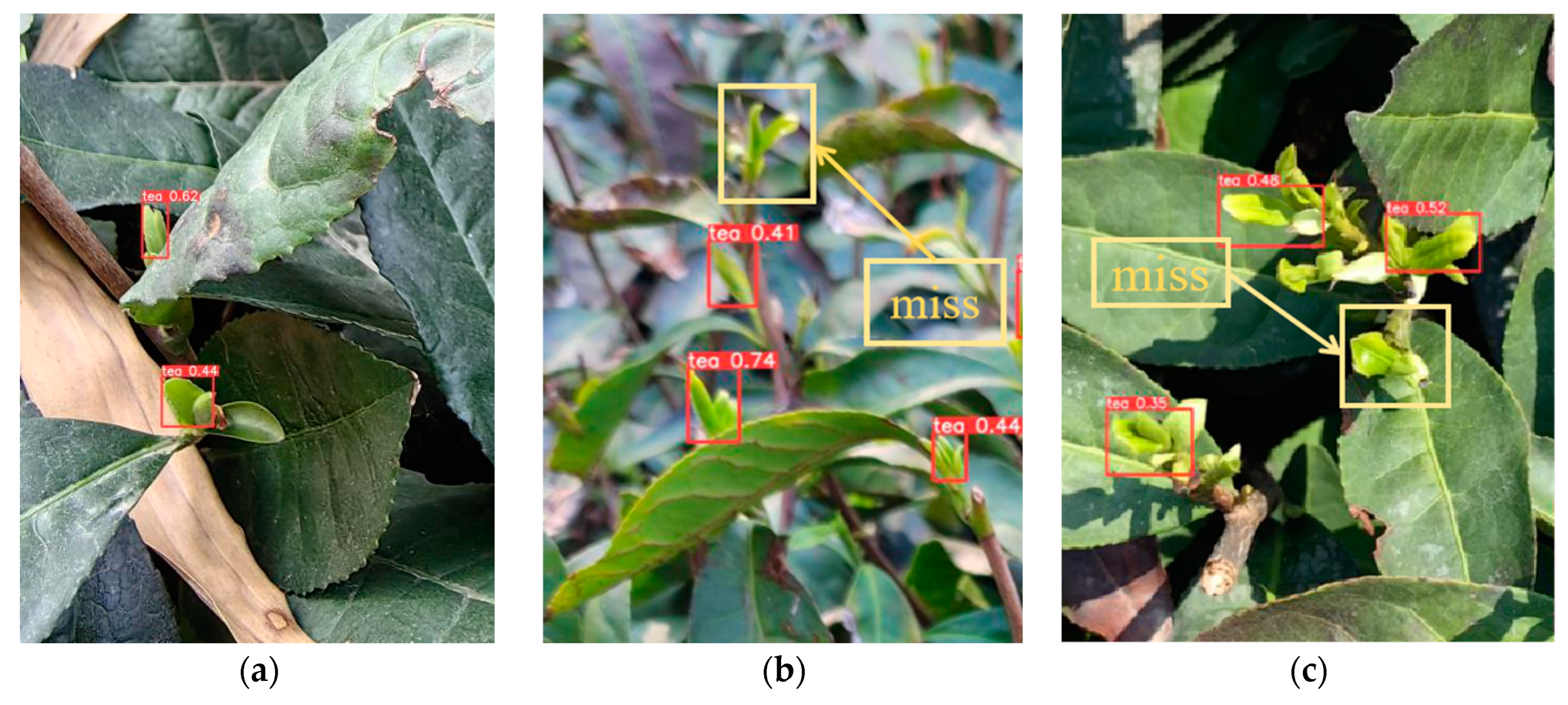
- The YOLOv5+LFA+mpdiou+PF method presented in this research effectively addresses the challenges posed by strong light in tea bud visual recognition tasks. Compared to existing mainstream methods, it reduces misdetection rates by approximately 35% while also decreasing false positive rates by approximately 10%. However, when operating outdoors without significantly strong or weak lighting conditions present, this model may not be necessary; instead, utilising the proposed YOLOv5s+LFA+mpdiou approach will suffice to improve tea bud picking accuracy by approximately 4% compared with the current optimal mainstream detection model.
4.2. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Higdon, J.V.; Frei, B. Tea catechins and polyphenols: Health effects, metabolism, and antioxidant functions. Crit. Rev. Food Sci. Nutr. 2003, 43, 89–143. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.X.; Feng, W.Z.; Xiong, Z.C.; Dong, S.; Sheng, C.Y.; Wu, Y.D.; Deng, G.J.; Deng, W.W.; Ning, J.M. Investigation of the effect of over-fired drying on the taste and aroma of Lu’an Guapian tea using metabolomics and sensory histology techniques. Food Chem. 2024, 437, 137851. [Google Scholar] [CrossRef]
- Zhang, F.Y.; Sun, H.W.; Xie, S.; Dong, C.W.; Li, Y.; Xu, Y.T.; Zhang, Z.W.; Chen, F.N. A tea bud segmentation, detection and picking point localization based on the MDY7-3PTB model. Front. Plant Sci. 2023, 14, 1199473. [Google Scholar] [CrossRef]
- Luo, K.; Zhang, X.C.; Cao, C.M.; Wu, Z.M.; Qin, K.; Wang, C.; Li, W.Q.; Chen, L.; Chen, W. Continuous identification of the tea shoot tip and accurate positioning of picking points for a harvesting from standard plantations. Front. Plant Sci. 2023, 14, 1211279. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2016; Volume 39, pp. 1137–1149. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, H.D.; Chen, Y.D.; Dai, S.H.; Li, X.M.; Imou, K.; Liu, Z.H.; Li, M. Real-time monitoring of optimum timing for harvesting fresh tea leaves based on machine vision. Int. J. Agric. Biol. Eng. 2019, 12, 6–9. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Mirhaji, H.; Soleymani, M.; Asakereh, A.; Mehdizadeh, S.A. Fruit detection and load estimation of an orange orchard using the YOLO models through simple approaches in different imaging and illumination conditions. Comput. Electron. Agric. 2021, 191, 106533. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X.W. Tomato Diseases and Pests Detection Based on Improved Yolo V3 Convolutional Neural Network. Front. Plant Sci. 2020, 11, 898. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Bouwmans, T.; Jayed, S.; Sultana, M.; Jung, S.K. Deep neural network concepts for background subtraction: A systematic review and comparative evaluation. Neural Netw. 2019, 117, 8–66. [Google Scholar] [CrossRef]
- Cao, M.L.; Fu, H.; Zhu, J.Y.; Cai, C.G. Lightweight tea bud recognition network integrating GhostNet and YOLOv5. Math. Biosci. Eng. 2022, 19, 12897–12914. [Google Scholar] [CrossRef]
- Zhao, R.M.; Liao, C.; Yu, T.J.; Chen, J.N.; Li, Y.T.; Lin, G.C.; Huan, X.L.; Wang, Z.M. IMVTS: A Detection Model for Multi-Varieties of Famous Tea Sprouts Based on Deep Learning. Horticulturae 2023, 9, 819. [Google Scholar] [CrossRef]
- Wang, S.Y.; Wu, D.S.; Zheng, X.Y. TBC-YOLOv7: A refined YOLOv7-based algorithm for tea bud grading detection. Front. Plant Sci. 2023, 14, 1223410. [Google Scholar] [CrossRef] [PubMed]
- Zhong, L.H.; Hu, L.N.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Shuai, L.Y.; Mu, J.; Jiang, X.Q.; Chen, P.; Zhang, B.D.; Li, H.D.; Wang, Y.C.; Li, Z.Y. An improved YOLOv5-based method for multi-species tea shoot detection and picking point location in complex backgrounds. Biosyst. Eng. 2023, 231, 117–132. [Google Scholar] [CrossRef]
- Li, J.; Li, J.H.; Zhao, X.; Su, X.H.; Wu, W.B. Lightweight detection networks for tea bud on complex agricultural environment via improved YOLO v4. Comput. Electron. Agric. 2023, 211, 107955. [Google Scholar] [CrossRef]
- Chen, C.L.; Lu, J.Z.; Zhou, M.C.; Yi, J.; Liao, M.; Gao, Z.M. A YOLOv3-based computer vision system for identification of tea buds and the picking point. Comput. Electron. Agric. 2022, 198, 107116. [Google Scholar] [CrossRef]
- Fu, L.H.; Yang, Z.; Wu, F.Y.; Zou, X.J.; Lin, J.Q.; Cao, Y.J.; Duan, J.L. YOLO-Banana: A Lightweight Neural Network for Rapid Detection of Banana Bunches and Stalks in the Natural Environment. Agronomy 2022, 12, 391. [Google Scholar] [CrossRef]
- Li, Y.T.; He, L.Y.; Jia, J.M.; Chen, J.N.; Lyu, J.; Wu, C.A.Y. High-efficiency tea shoot detection method via a compressed deep learning model. Int. J. Agric. Biol. Eng. 2022, 15, 159–166. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, Y.Z.; Zhao, Y.Q.; Pan, Q.M.; Jin, K.; Xu, G.; Hu, Y.G. TS-YOLO: An All-Day and Lightweight Tea Canopy Shoots Detection Model. Agronomy 2023, 13, 1411. [Google Scholar] [CrossRef]
- Osokin, A.; Sidorov, D. Modification of SSIM Metrics. In Proceedings of the 13th International Scientific Conference on Information Technologies and Mathematical Modelling (ITMM), Anzhero Sudzhensk, Russia, 20–22 November 2014; Volume 487, pp. 351–355. [Google Scholar]
- Qian, Z.X.; Wang, W.W.; Zhang, X.P. Generalized Quality Assessment of Blocking Artifacts for Compressed Images. In Proceedings of the 9th International Forum on Digital TV and Wireless Multimedia Communication, IFTC 2012, Shanghai, China, 9–10 November 2012. [Google Scholar]
- Kattumannil, S.K.; Sreedevi, E.P.; Balakrishnan, N. A Generalized Measure of Cumulative Residual Entropy. Entropy 2022, 24, 444. [Google Scholar] [CrossRef]
- Malik, S.; Soundararajan, R. A Model Learning Approach for Low Light Image Restoration. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Electr Network, Abu Dhabi, United Arab Emirates, 25–28 September 2020; pp. 1033–1037. [Google Scholar]
- Farid, H. Blind inverse gamma correction. IEEE Trans. Image Process. 2001, 10, 1428–1433. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.H.; Wang, P.; Ren, D.W.; Liu, W.; Ye, R.G.; Hu, Q.H.; Zuo, W.M. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Yan, B.; Fan, P.; Lei, X.Y.; Liu, Z.J.; Yang, F.Z. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Qi, J.T.; Liu, X.N.; Liu, K.; Xu, F.R.; Guo, H.; Tian, X.L.; Li, M.; Bao, Z.Y.; Li, Y. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantity (Sheets) | Ambient Light Intensity | |
|---|---|---|
| Training set | 1450 | |
| Validation set | 400 | |
| Test set | 50 | |
| 50 | ||
| 50 |
| Loss Function | Value |
|---|---|
| (a) 0.75 | |
| (b) 0.75 | |
| (a) 0.79 | |
| (b) 0.76 |
| Model | Precision | Recall | mAP50 | mAP50_95 | Params/M | GFlops/G |
|---|---|---|---|---|---|---|
| YOLOv5s | 87.3% | 64.1% | 79.1% | 51.4% | 7.012822 | 15.8 |
| YOLOv5s+CBAM | 72.5% | 72.0% | 74.7% | 45.5% | 6.705268 | 15.2 |
| YOLOv5s+ECA | 84.1% | 68.0% | 79.3% | 48.5% | 7.185881 | 15.6 |
| YOLOv5s+siou | 81.6% | 72.9% | 80.3% | 51.7% | 7.012822 | 15.0 |
| YOLOv5s+LFA | 84.7% | 70.3% | 81.5% | 51.2% | 8.296342 | 17.9 |
| YOLOv5s+LFA+mpdiou | 84.5% | 75.5% | 83.6% | 54.8% | 8.397863 | 17.9 |
| Threshold | Models | Miss Rate | False Rate |
|---|---|---|---|
| iou = 0.5 | YOLOv5s | 8.2% | 24.7% |
| YOLOv5s+CBAM | 10.4% | 26.9% | |
| YOLOv5s+ECA | 5.2% | 20.1% | |
| YOLOv5s+siou | 7.4% | 21.8% | |
| YOLOv5s+LFA+mpdiou | 2.5% | 14.4% | |
| iou = 0.6 | YOLOv5s | 10.3% | 20.1% |
| YOLOv5s+CBAM | 13.9% | 21.3% | |
| YOLOv5s+ECA | 9.0% | 17.2% | |
| YOLOv5s+siou | 11.6% | 19.8% | |
| YOLOv5s+LFA+mpdiou | 5.1% | 15.9% | |
| iou = 0.7 | YOLOv5s | 13.1% | 13.1% |
| YOLOv5s+CBAM | 15.9% | 15.5% | |
| YOLOv5s+ECA | 11.5% | 11.4% | |
| YOLOv5s+siou | 14.4% | 14.0% | |
| YOLOv5s+LFA+mpdiou | 7.0% | 4.6% | |
| iou = 0.8 | YOLOv5s | 16.5% | 9.7% |
| YOLOv5s+CBAM | 19.3% | 10.5% | |
| YOLOv5s+ECA | 14.5% | 8.1% | |
| YOLOv5s+siou | 16.1% | 8.5% | |
| YOLOv5s+LFA+mpdiou | 11.2% | 4.1% |
| Experimental Environment | Processing Method | Miss Rate | False Rate |
|---|---|---|---|
| Without intense light | YOLOv5s | 14.56% | 8.2% |
| YOLOv5s+PF | 13.98% | 8.2% | |
| YOLOv5s+LFA+mpdiou | 9.96% | 3.9% | |
| YOLOv5s+PF+LFA+mpdiou | 10.01% | 3.9% | |
| YOLOv5s+CBAM | 15.33% | 8.5% | |
| YOLOv5s+ECA | 13.21% | 8.2% | |
| YOLOv5s+siou | 14.22% | 8.3% | |
| Low light | YOLOv5s | 29.76% | 19.88% |
| YOLOv5s+PF | 32.44% | 21.65% | |
| YOLOv5s+LFA+mpdiou | 25.72% | 15.73% | |
| YOLOv5s+PF+LFA+mpdiou | 30.01% | 18.43% | |
| YOLOv5s+CBAM | 30.51% | 20.11% | |
| YOLOv5s+ECA | 28.61% | 18.93% | |
| YOLOv5s+siou | 28.81% | 19.41% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, J.; Zhang, Y.; Xian, J.; Wang, X.; Shi, Y. YOLO Recognition Method for Tea Shoots Based on Polariser Filtering and LFAnet. Agronomy 2024, 14, 1800. https://doi.org/10.3390/agronomy14081800
Peng J, Zhang Y, Xian J, Wang X, Shi Y. YOLO Recognition Method for Tea Shoots Based on Polariser Filtering and LFAnet. Agronomy. 2024; 14(8):1800. https://doi.org/10.3390/agronomy14081800
Chicago/Turabian StylePeng, Jinyi, Yongnian Zhang, Jieyu Xian, Xiaochan Wang, and Yinyan Shi. 2024. "YOLO Recognition Method for Tea Shoots Based on Polariser Filtering and LFAnet" Agronomy 14, no. 8: 1800. https://doi.org/10.3390/agronomy14081800