1. Introduction
Rainfall is a major hazard associated with a landfalling tropical cyclone (TC). In fact, water causes more TC-related deaths than winds. Overall, about ninety percent of fatalities are caused by water-related events, and rainfall-induced events, such as freshwater flooding and mudslides, contributed about a quarter of fatalities [
1]. Although TC rainfall prediction is important, it remains a major forecast challenge. Earlier studies based on statistical models (e.g., [
2,
3,
4]) have illustrated that accurate TC track predictions should lead to an improvement of rainfall prediction in landfalling TCs. Moreover, several other factors such as storm speed, storm structure, topography, and environmental moisture can also influence TC precipitation.
In 2017, Hurricane Harvey made landfall in Texas and Louisiana in the U.S. as a category four hurricane on the Saffir–Simpson Hurricane Wind Scale [
5], causing extreme accumulated rainfall of greater than three feet in a large area over five days, with a maximum of 60.58 inches in Jefferson, Texas [
6]. Hurricane Harvey reached major hurricane status at 1800 UTC 25 August and made landfall at 0300 UTC 26 August. Harvey was the first major hurricane to make landfall in the U.S. since 2005. After landfall, Hurricane Harvey meandered over southeastern Texas for more than 60 h until moving back over the Gulf of Mexico at 1800 UTC 28 August, delivering prolonged heavy precipitation to the region. Even after Harvey moved offshore, it continued to produce heavy rainfall over Texas and Louisiana until 30 August, when it made a second landfall in Louisiana and finally dissipated. The disastrous rainfall from Harvey’s outer rainbands occurred in the nearly constant onshore flow to the northeast of Harvey’s center, with the Gulf of Mexico continuously supplying moisture to support heavy precipitation [
6]. According to the National Oceanic and Atmospheric Administration (NOAA), Hurricane Harvey caused more than 68 direct deaths and about 125 billion dollars in economic loss, making it the second-costliest TC after Hurricane Katrina [
7]. Hurricane Harvey’s primary threat was freshwater floods in highly populated regions induced by constant heavy rainfall. Houston’s urbanization may also have exaggerated flood response and increased accumulated rainfall [
8,
9], and anthropogenic activities may shorten return periods and increase the frequency of such an event [
10,
11]. Moreover, a slow-moving TC is likely to produce more rainfall than a fast-moving TC. Due to Harvey’s storm speed and constant moisture supplies, this flooding hazard extended well inland, continued to affect an area after landfall, and caused catastrophic destruction. Therefore, an accurate rainfall prediction is critical for disaster management for reducing loss of life and cost to the economy.
Although TC rainfall can cause significant damage or loss of life, it is also an essential source of freshwater in many regions globally [
12]. Hence, studies that evaluate and improve current numerical quantitative precipitation forecasts (QPFs) are indispensable. Numerous studies focused on QPF validation techniques to evaluate the utility of rainfall forecasts. Initially, the threat score (TS), which is also known as critical success index (CSI) [
13,
14], was utilized to validate QPF (e.g., [
15]). Nowadays, the equitable threat score (ETS) [
16] is more commonly used as it accounts for random model predictions (e.g., [
17,
18,
19]). Ebert et al. [
20] used bias score and ETS to verify numerical models, including the NOAA National Centers for Environmental Prediction (NCEP) Eta model and the European Centre for Medium Range Forecasts (ECMWF) Integrated Forecasting System (IFS), against rain gauge data in regions of the United States, Germany, and Australia.
Besides various scoring methods, Lonfat et al. [
2] studied the National Aeronautics and Space Administration (NASA) Tropical Rainfall Measuring Mission (TRMM) data and provided guidance on the TC rainfall climatology through evaluating rain profiles with rain rate probability distribution functions (PDFs) and contoured frequency by radial distance (CFRD), which represents PDFs as a function of the radius from the storm center. This study also suggested the use of a decibel rain rate (dBR) scale to produce PDF and CFRD diagrams as rain rate is nearly log-normally distributed [
2]. Furthermore, Marchok et al. [
4] developed a standard scheme for validating QPF in landfalling TCs to examine NCEP operational models, and this scheme includes three components: the pattern matching ability, mean rainfall and volume matching skill, and the ability to capture extreme amounts. Moreover, a numerical model is typically considered practical and beneficial only when it outperforms a statistical model. The Rainfall Climatology and Persistence (R-CLIPER) model is commonly used as a standard baseline of statistical TC rainfall predictions [
4,
21]. Lonfat et al. [
3] developed another version of R-CLIPER, called Parametric Hurricane Rainfall Model (PHRaM), to take account of shear and topography effects.
With the aid of these rainfall evaluating approaches, several challenges of numerical model prediction for rainfall have been addressed. Tuleya et al. [
21] pointed out that rainfall performance was highly dependent on both storm intensity and track from the evaluation of the Geophysical Fluid Dynamics Laboratory (GFDL) model performance. Marchok et al. [
4] also emphasized the importance of track forecasts in order to obtain a better rainfall prediction, noting that track bias is possibly caused by physical parameterizations or initialization schemes. Moreover, model resolution may also be key to capture improved storm structure or a more realistic storm intensity. The study from Ebert et al. [
20] stated that models may experience more difficulties in predicting convective rainfall in summer than synoptic-scale rainfall in winter in the U.S. On the other hand, Weisman et al. [
22] suggested that 4-km resolution is sufficient for simulating mesoscale cloud systems, and cloud parameterization is not required for such a high-resolution model. Roberts and Lean [
23] examined the impact of resolution on rainfall prediction of the United Kingdom Met Office Unified Model. Their study addressed that a higher-resolution model can improve the prediction for heavier and more localized rain [
23]. Wu et al. [
24] verified the NASA-unified Weather Research and Forecasting (NU-WRF) [
25] model to investigate the land surface impacts on rainfall; the study also highlighted 3-km NU-WRF has higher accuracy on rainfall predictability than 9-km NU-WRF. Accordingly, a high-resolution forecast model with demonstrated track and intensity prediction skills may potentially lead to more reliable and sensible rainfall estimations.
The Hurricane Weather Research and Forecasting (HWRF) modeling system has been critical to the improvement of TC predictions at NOAA and across the globe. The HWRF model is a regional numerical weather prediction (NWP) model that specializes in TC guidance [
26,
27,
28,
29]. For the last decade, the Hurricane Forecast Improvement Program (HFIP) [
30] has supported improvements to TC track and intensity predictions in HWRF, and, recently, the focus of HFIP has expanded to TC hazards, including rainfall. This study is the first to examine hurricane rainfall predictability of a high-resolution HWRF system following the rainfall evaluation guidance from the studies mentioned above. The NCEP Environmental Modeling Center (EMC) implemented HWRF with high nested resolutions for real-time operation [
31]. Apart from a deterministic forecast, HWRF has also implemented an ensemble prediction system (EPS) to provide probabilistic predictions for better forecast guidance. This HWRF-based EPS takes account of initial and boundary condition perturbations and model physics perturbations [
32,
33]. On the other hand, with the support of HFIP and in collaboration with EMC, the National Weather Service (NWS), and the Developmental Testbed Center (DTC), the Hurricane Research Division (HRD) of the NOAA Atlantic Oceanographic and Meteorological Laboratory (AOML) developed and maintained an experimental “Basin-scale HWRF” model (HWRF-B) [
34,
35,
36]. HWRF-B produced low track errors in 2017 compared with other NOAA models. Due to the high dependence of precipitation on TC track, HWRF-B is leveraged as a rainfall research tool to evaluate the precipitation performance for Hurricane Harvey. In addition, HWRF EPS is also being investigated in this project to explore the potential of probabilistic precipitation forecasting. The ultimate goals of this project are to evaluate TC rainfall performance in NWP and to create new probabilistic rainfall guidance for TC landfalls.
Section 2 describes the methodology of this project, including the models, datasets, and forecasts of interest.
Section 3 presents the results of the rainfall performance in HWRF-B forecasts and introduces NWP-based probabilistic guidance.
Section 4 discusses the overall results and the findings of this case study, and conclusions are provided in
Section 5.
3. Results
3.1. Pattern Analysis
The precipitation pattern analysis is a tool used to examine model performance for accumulated rainfall distribution.
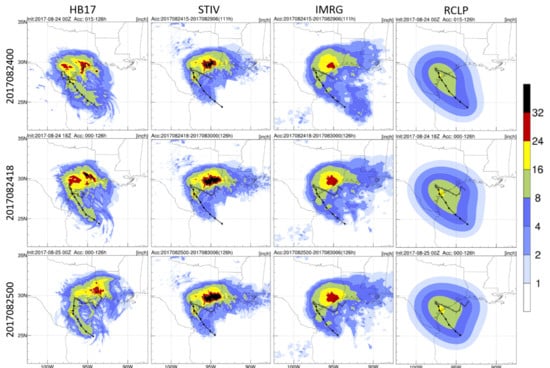
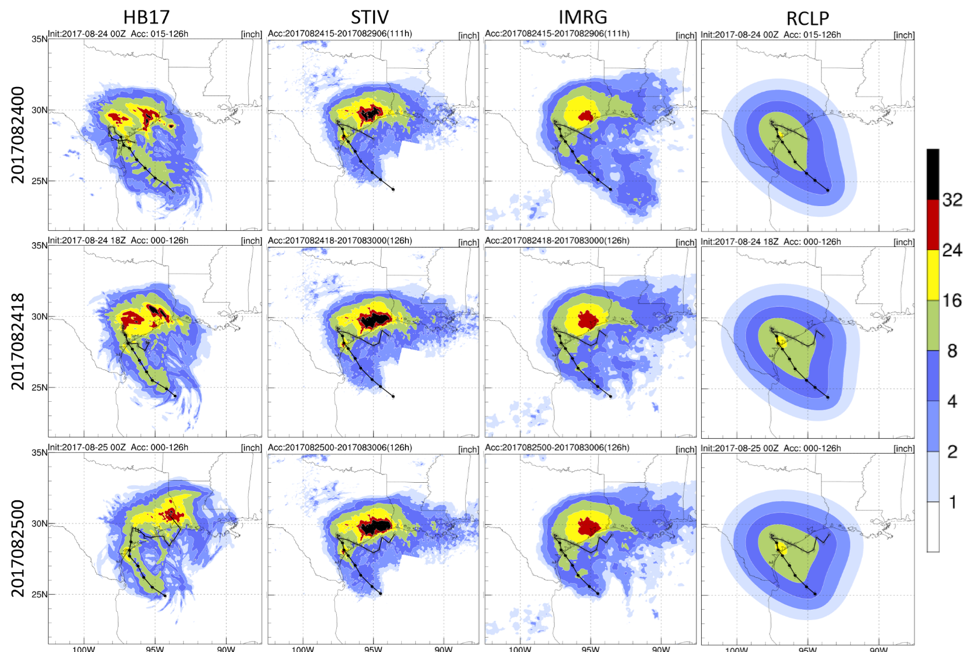
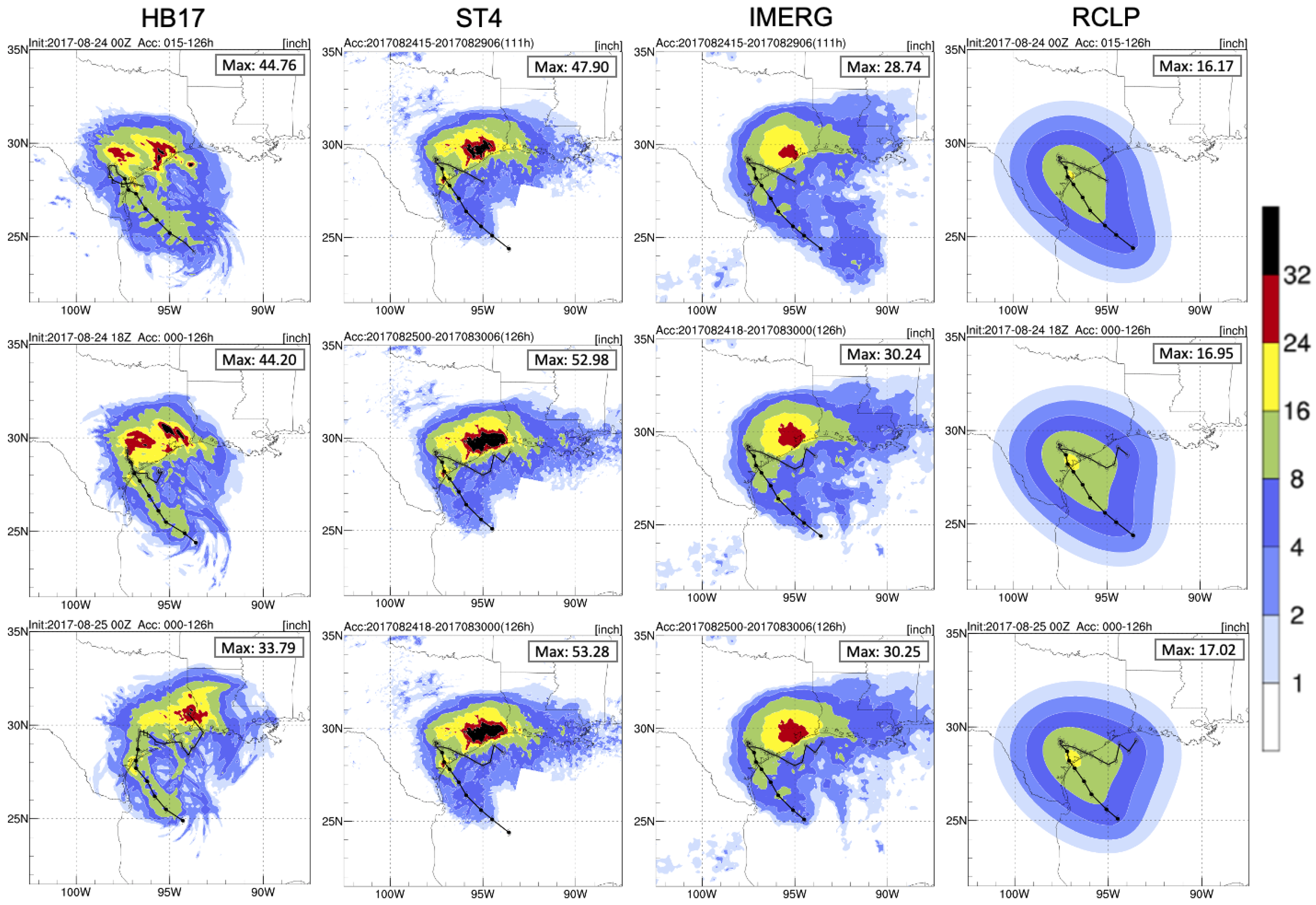
Figure 3 shows total precipitation accumulated during Hurricane Harvey for the three deterministic HB17 forecasts corresponding to periods of 111, 126, and 126 h. Rainfall totals from Stage IV, IMERG, and R-CLIPER were calculated for the same periods. Typically, TC rainfall patterns show the heaviest accumulated precipitation in the eyewall region where the strongest convection occurs. Hurricane Harvey was unusual in that it produced significant rainfall in its outer rainbands, especially those remaining offshore. Observations indicate that the greatest rainfall accumulation occurred over the Houston region whereas the eye had limited direct impact. In addition, IMERG shows rainfall over the ocean was not significantly strong along the track. Stage IV and IMERG show similar rainfall distributions over land, yet Stage IV presents more intense and a broader rainfall accumulation maximum over the Houston area to the Texas–Louisiana border. Stage IV captured 47 to 53 inches of extreme accumulated rainfall, which is about 1.7 times higher than the maximum value from IMERG. The disagreement between two observational data is possibly related to the data resolution, data collection, or calibration. Even though both data were corrected by rain gauges, Stage IV, with the higher resolution and the ground-based measurement, can better represent extreme rainfall values.
The climatological model, R-CLIPER, only shows a main rainfall accumulation pattern along the track without the heavy rainfall accumulation over Houston. The result indicates the heaviest accumulation was at the landfall location; also, the overall rainfall accumulation on land was below 17 inches, which is much lower than the Stage IV accumulation. Compared to R-CLIPER, HB17’s pattern is more similar to the Stage IV and IMERG estimates. In the first two selected cycles, HB17 predicted a large rainfall accumulation occurring not only over Houston, but also over Austin and San Antonio. This second peak-rainfall accumulation was not present in the 0000 UTC 25 August 2017 cycle. The peak value of Houston’s heavy rainfall accumulation dropped from 44 to 33 inches, and the peak center moved towards the east as the second landfall occurred in Louisiana in this cycle. HB17 also predicted a clear strong rainfall accumulation pattern along its track over the ocean as expected. The general rainfall pattern from HB17 appears much more realistic than the one from R-CLIPER in terms of the prediction of the peak rainfall location and the amount of rainfall. The comparison between the HB17 model prediction and Stage IV and IMERG is shown in
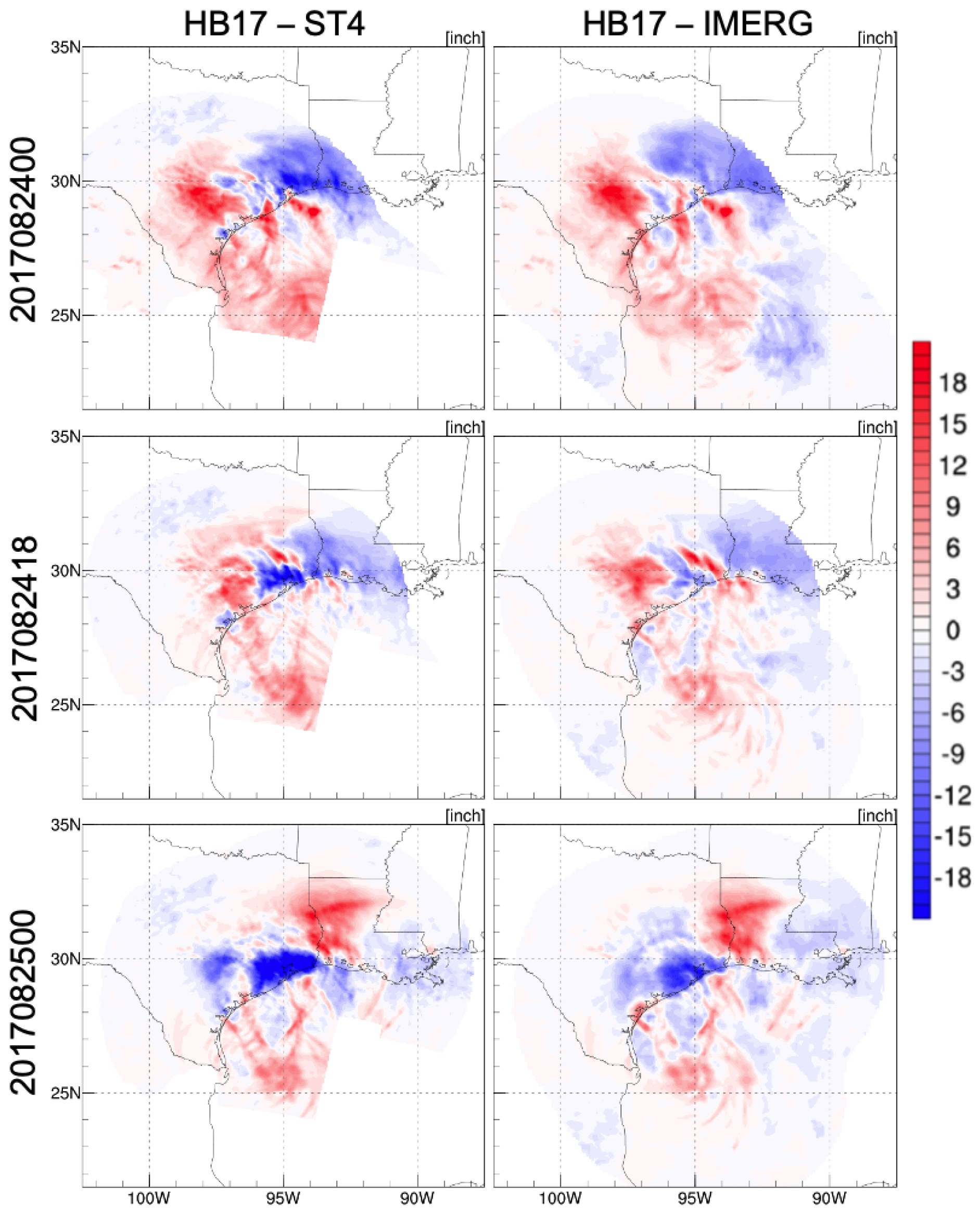
Figure 4. The dipole patterns suggest that the rainfall amount is realistic, but the location shifted. In the first two selected cycles, HB17 overestimated rainfall on the west side of the Texas coastal region and underestimated rainfall on the east side. The amplitudes of the contradictory estimations are comparable. However, in the last cycle, the overestimation pattern shifted from the coastal region of Texas to Louisiana. The shifted dipole pattern indicates that the peak rainfall location was too far to the east, and HB17 still missed the rainfall over the east coastal region of Texas. Moreover, over the Gulf of Mexico, the rainfall was mostly overestimated.
The spatial rainfall patterns show that the HB17 rainfall prediction is significantly better than R-CLIPER. Hurricane Harvey’s strong outer rainband violates the simple symmetric rainfall model in R-CLIPER. Also, the R-CLIPER’s rainfall estimates, while a function of intensity, use the mean rain rate for each intensity class preventing it from correctly capturing a realistic rainfall pattern for this storm. On the other hand, HB17 has the capability to predict realistic rainfall patterns when the peak rainfall falls in the outer rainband region, yet the extreme accumulated rainfall values were missed. Moreover, the extreme values indicate that IMERG has difficulty representing extreme rainfall overland. As IMERG only provides the information on the rainfall distribution over the ocean, the later part of this study will focus on the evaluation of the HWRF models against Stage IV and R-CLIPER.
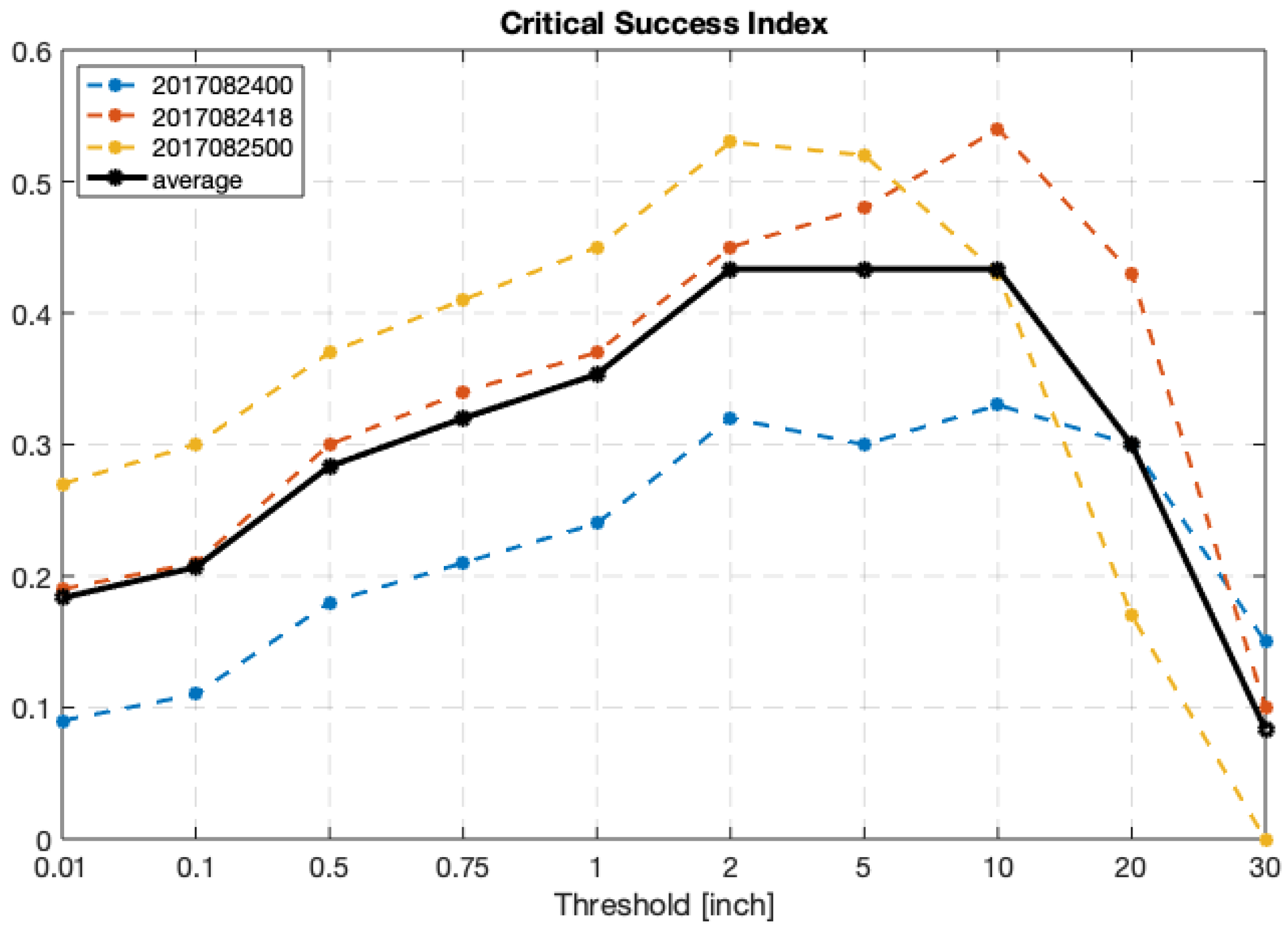
The CSI in
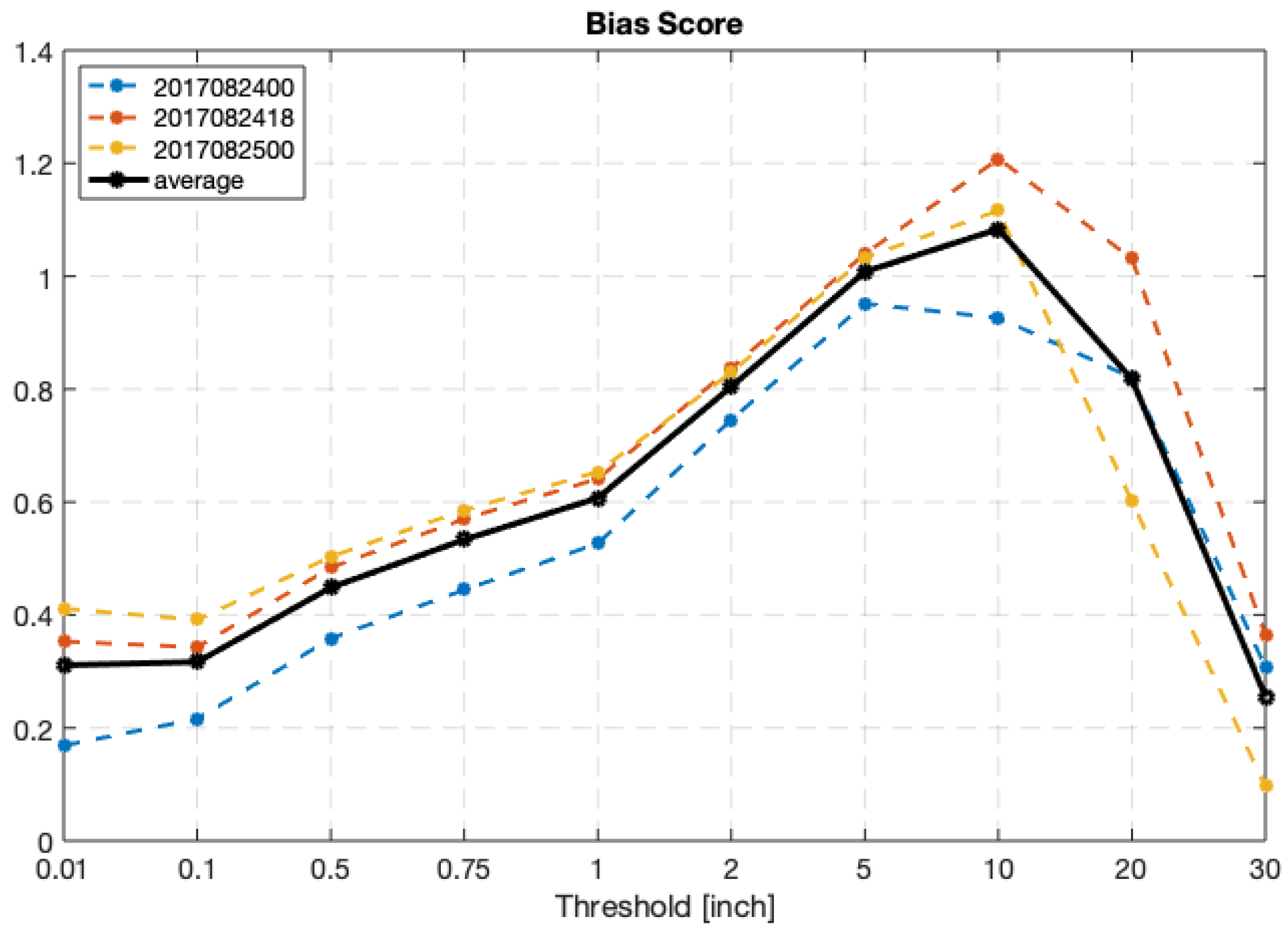
Figure 5 shows HB17 made better predictions in the later cycles. The results from 0000 UTC 25 August gave the best simulations on rain rates below 5 inches, and 1800 UTC 24 August presented the best heavy rainfall simulations (above 10 inches). On average, HB17 is more skillful at predicting accumulated rainfall between 2 to 10 inches than predicting light or heavy rainfall amounts. The bias scores in
Figure 6 present that the model has overall underestimation of observed rainfall amounts, especially for both light (below 1 inch) and extreme (30 inches) accumulated rainfall. Both CSI and bias scores indicate that HB17 predicted accumulated rainfall between 1 to 10 inches better than other thresholds. The missing light rain over eastern Texas may be the reason for the low bias score and CSI of the light rainfall thresholds; imperfect extreme rainfall values and location are possibly responsible for the low scores of the heavy rainfall thresholds.
In this analysis, we found that, with accurate track prediction, HB17 has the capability of predicting a considerably accurate rainfall pattern. Even though the peak rainfall accumulation from HB17 was not correctly predicted, the general amount of rainfall was convincing and could have been useful forecast guidance. The underestimation of extreme values of rainfall may be resolved by enhancing the model physics or parameterizations, and spatial displacement of extreme rainfall may be further improved by the probabilistic rainfall predictions in order to provide a more sensible guidance for forecasting centers.
3.2. Azimuthal Analyses
The azimuthal analysis statistically examines precipitation structures from the center to the outer rainband to assess the rain rate performance of peaks, trends, and distributions. In this study, rain rates are plotted on a logarithmic scale as rain is log normally distributed. Rain-rate values are averaged within each 10 km radius interval from 0 to 300 km.
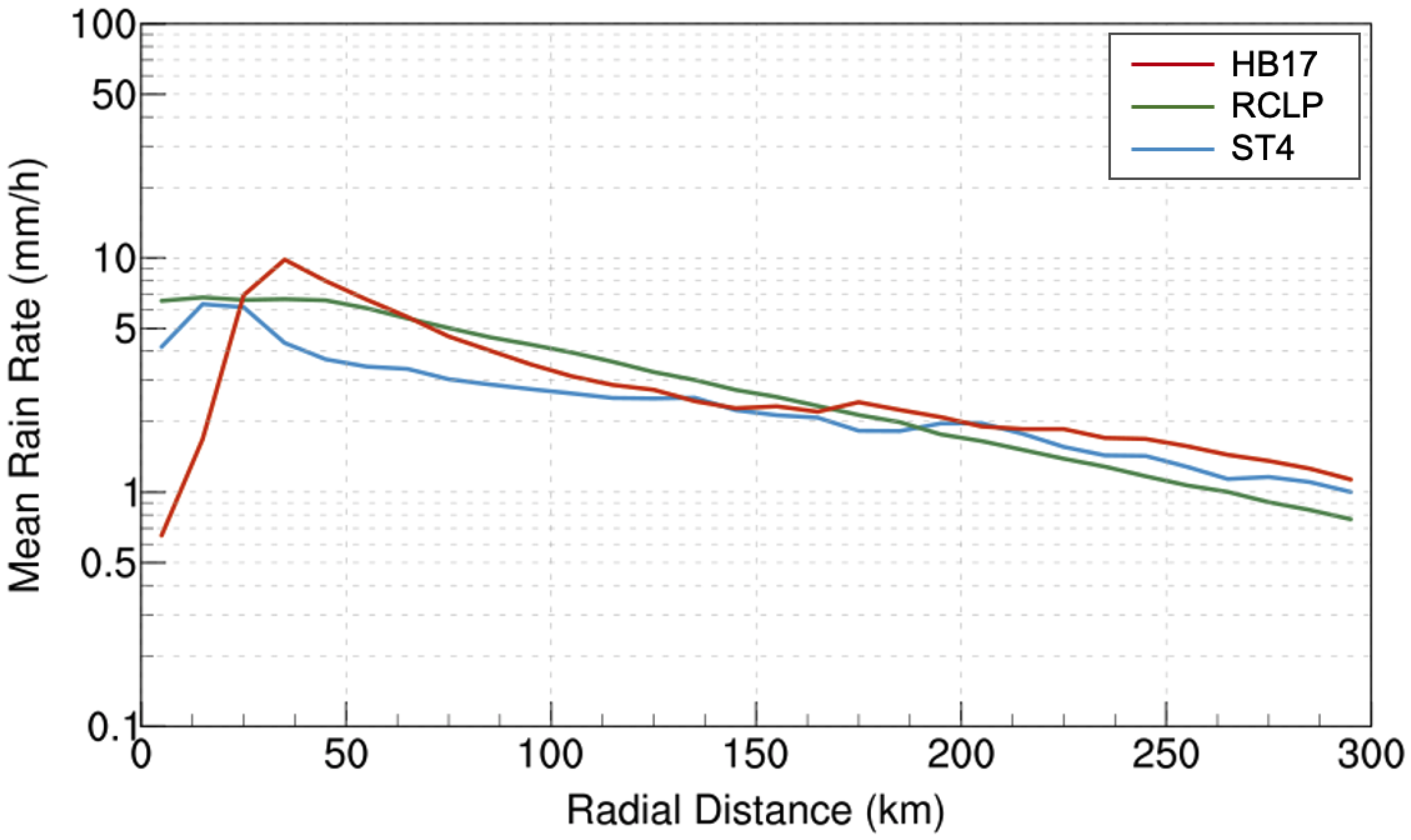
Figure 7 shows radial distribution of averaged rain rates. R-CLIPER (green) predicts a slightly steeper slope than the other datasets. The peak averaged rain rate remains at 7 mm h
in the core, within 50 km, and the value decreases to 1 mm h
in the outer rainband area (100 to 300 km). HB17’s prediction (red) is very close to observational values (blue and purple), especially in the outer rainband. However, in the core region, HB17’s prediction does not match with observational data. Stage IV captures small changes in rain rates varying from 3 to 6 mm h
, and HB17’s value changes from below 1 mm h
at the storm center to a peak of 10 mm h
at 40 km from the center. Due to the high resolution (2 km), HB17 is able to present a clearer eye structure compared to the others. The Stage IV estimates also capture an eyewall-like structure with the 4-km resolution. Low-resolution data tend to smooth out extreme values, which are able to be preserved in a high-resolution dataset.
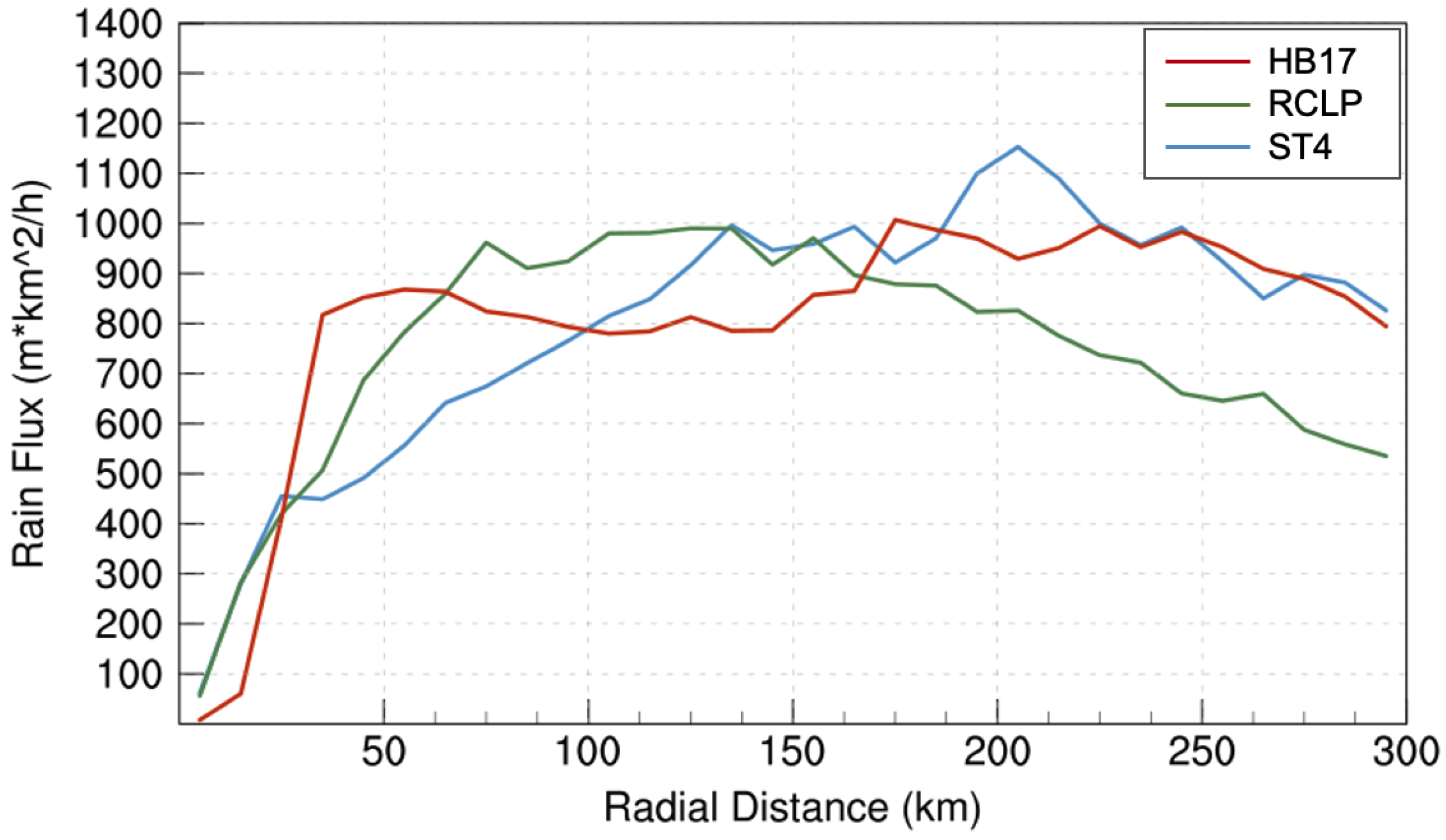
However, both resolution and overestimation can contribute to this peak value, so it is necessary to consider the impact of resolution differences between datasets. Rain flux, shown in
Figure 8, is a function of rain rate and resolution.
Rain flux indicates total amounts of rain within each 10 km annulus around the storm. The rain flux of HB17 is consistent with the observational rain flux from 150 to 300 km, but the amount within 40 to 50 km is almost twice as much as observed. R-CLIPER overestimates the rain flux from the center to 120 km, but it decreases rapidly from 150 to 300 km.
In these radial distribution analyses, HB17 shows skill in producing reasonable rain rates and rain flux for the outer rainband region. R-CLIPER did not produce rain rates similar to Harvey’s rainband region. Similar to Stage IV, HB17 has the capability to produce a clear eyewall structure, but the rain rates in the eye are slightly overestimated.
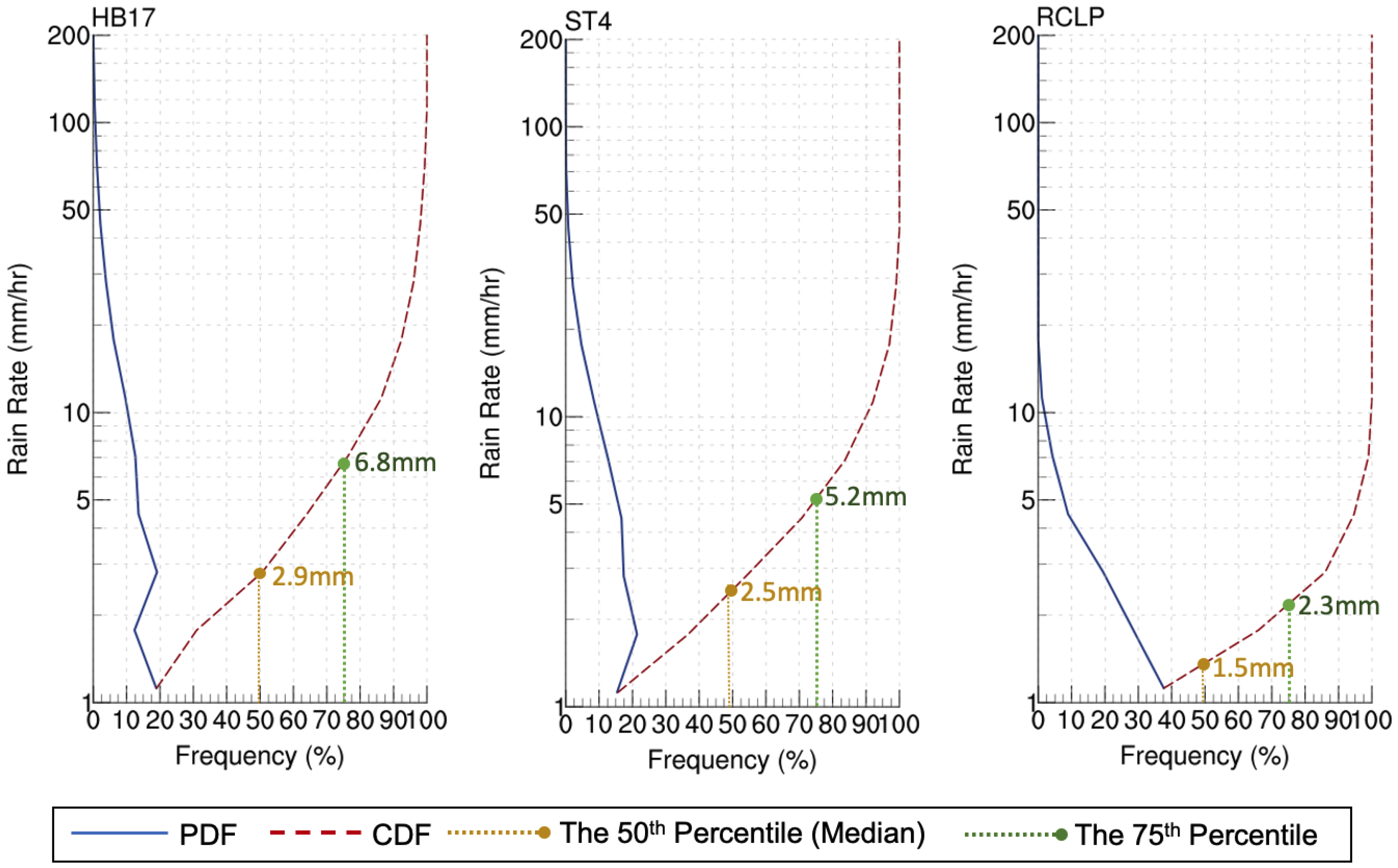
Probability distribution functions (PDFs) and cumulative distribution functions (CDFs) of rain rate (dBR) in
Figure 9 shows the model light/heavy precipitation compared to the observations.
The PDF and the CDF are originally calculated over the rainfall range 0 dBR (1 mm h
) to 27 dBR (500 mm h
) in 14 steps, or 2 dBR intervals.
Figure 9 only shows up to 200 mm h
, and the results show that the median rainfall rate for HB17 (yellow dot) is 2.9 mm h
, R-CLIPER is 1.5 mm h
, and Stage IV is 2.5 mm h
. Accordingly, HB17 produces reasonable amounts of both lighter and heavier rainfall, whereas R-CLIPER produces a significant amount of lighter rainfall, resulting in a low value of the median. On the other hand, HB17’s 75th percentile (green dot) is 6.8 mm h
while Stage IV is 5.2 mm h
, suggesting that HB17 produces a greater proportion of extreme rainfall than the observational data. The PDF reveals similar information. R-CLIPER produces a significant amount of light rain (below 5 mm h
) and rarely produces rainfall above 10 mm h
. HB17’s PDF shows this model produces about 2% of rainfall above 50 mm h
and a very small amount of rainfall around 80–90 mm h
. However, Stage IV captures less than 1% above 50 mm h
. In general, HB17’s PDF profile is comparable to the one from Stage IV but 1% exceeds 100 mm h
. The PDF and the CDF both suggest that HB17 generally produces a representative dBR/rain rate with a slightly higher frequency of extreme rainfall (>50 mm h
). Compared to the results from HB17, R-CLIPER’s profiles are less representative because many light rain rates were generated.
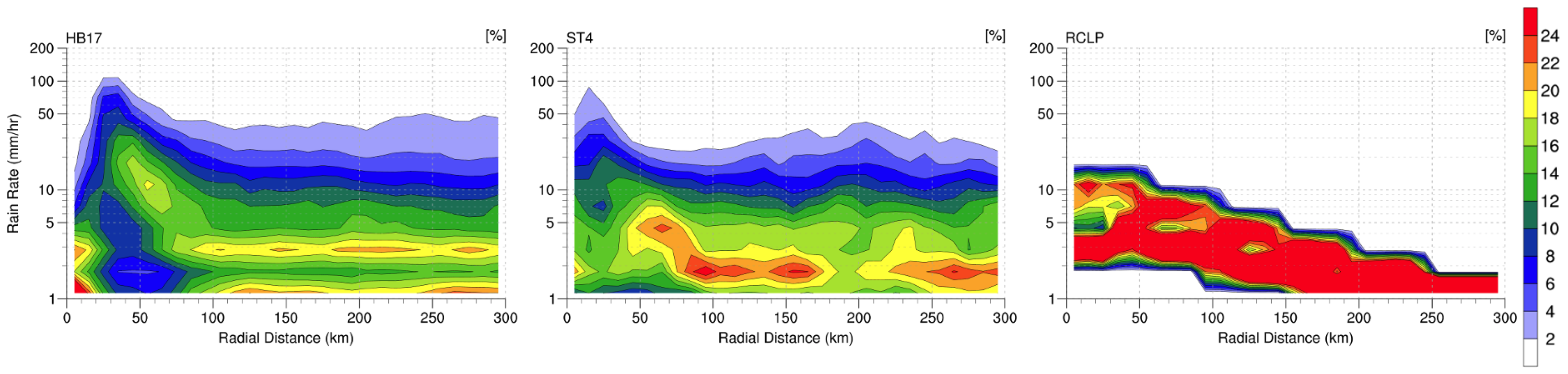
The CFRD plots are shown in
Figure 10. These depict the PDFs within each 10 km annulus from 0 to 300 km. CFRD shows how the PDF varies from the center to the outer rainband region and helps locate where the overestimation of extreme rainfall (>50 mm h
) happened. In Stage IV’s CFRD profile, lighter rain rates are the majority of the rainfall in the core region, but about 20% of rainfall is contributed by heavy rain rates (10–50 mm h
). The trend of heavy rainfall also decreases with the distance from the eyewall and increases again around 150 to 250 km. The outer rainband as stated contributes to this increasing trend.
R-CLIPER’s CFRD shows rain rate gradually decreased from the center to the outer region. At the center, the rain rate mostly varies from 3 to 10 mm h. All rain rates are below 5 mm h from 150 to 300 km. Due to R-CLIPER’s algorithm, the predicted rain rates are highly concentrated in a certain range for each 10-km interval. Unfortunately, compared to the observational dataset, R-CLIPER does not produce a realistic radial rain-rate frequency. In reality, light rain rate can exist in a strong convection area where heavy rainfall usually occurs. On the other hand, heavy rain rates can be observed in a stratiform area. This is not properly represented in the R-CLIPER CFRD profile. HB17 matches Stage IV observations for the most part, except within 50 km, where the rain rate is greater. In the core, HB17 has about 8% frequency above 50 mm h while Stage IV only captures around 4%. Unlike Stage IV, the HB17’s dominant rain rate in the core is heavy rain rates; rain rates below 5 mm h only exist at the center of the core. Otherwise, the profile above 100 km agrees with Stage IV observations with slightly more frequency on the heavy and extreme rain rates and slightly lower frequency on light rain rates.
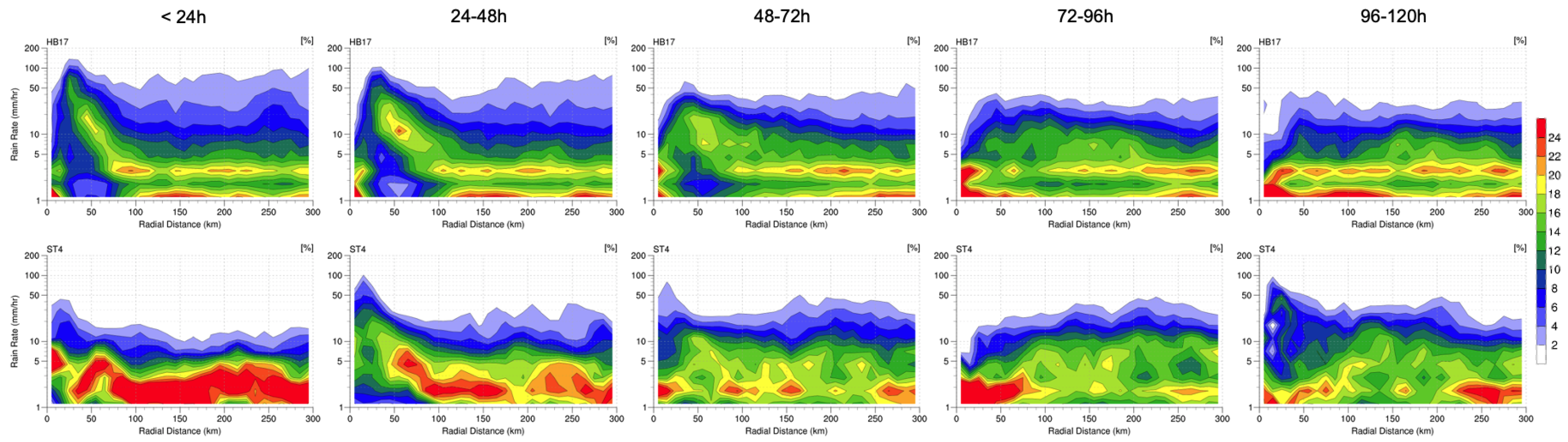
The PDF, the CDF, and the CFRD take the entire forecast cycles into account and provide overall performance on rain-rate frequency. In order to further examine the temporal changes of rain-rate distributions, we calculated the CFRD profiles averaged within 24-h intervals: the period of time within the first 24 h represents the rain-rate frequency prior to the landfall, the 24 to 48 h shows the status during the landfall, and the rain-rate changes during weakening and dissipating are shown in the 48 to 120 h CFRDs. In
Figure 11, HB17 (the first row) predicted a realistic rain-rate frequency from landfall to dissipation compared with the Stage IV results (the second row). Shown in the first column of
Figure 11, HB17 may have overestimated the heavy rain rate at the core before landfall, but Stage IV might not be accurate over the ocean. Therefore, the overestimation of heavy rain-rate frequency in the core of HB17’s overall CFRD (
Figure 10) might be partially contributed by this uncertainty of observations. Despite an underprediction of high rainfall totals in HB17 forecasts (
Section 3.1), the rain rate frequencies were remarkably predicted in terms of radial distributions and temporal changes.
3.3. Precipitation Probabilities
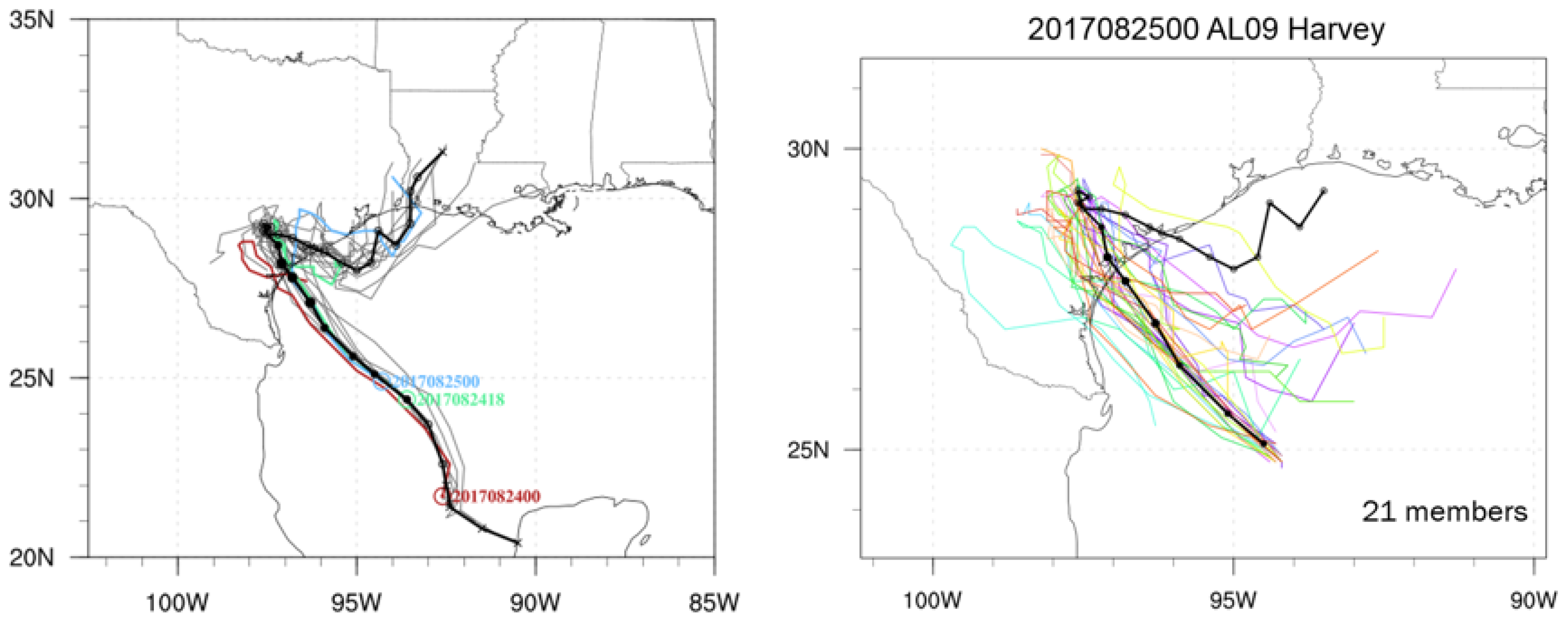
In order to minimize the uncertainty of deterministic forecasting, this study also evaluates an experiment of probabilistic precipitation forecasting using an HWRF ensemble model. This model generated 21 ensemble members (
Figure 2 right panel), and most of the members show that Hurricane Harvey curved back to the Gulf of Mexico after making landfall. However, only a few members predicted the storm track moving towards Louisiana through the Gulf of Mexico.
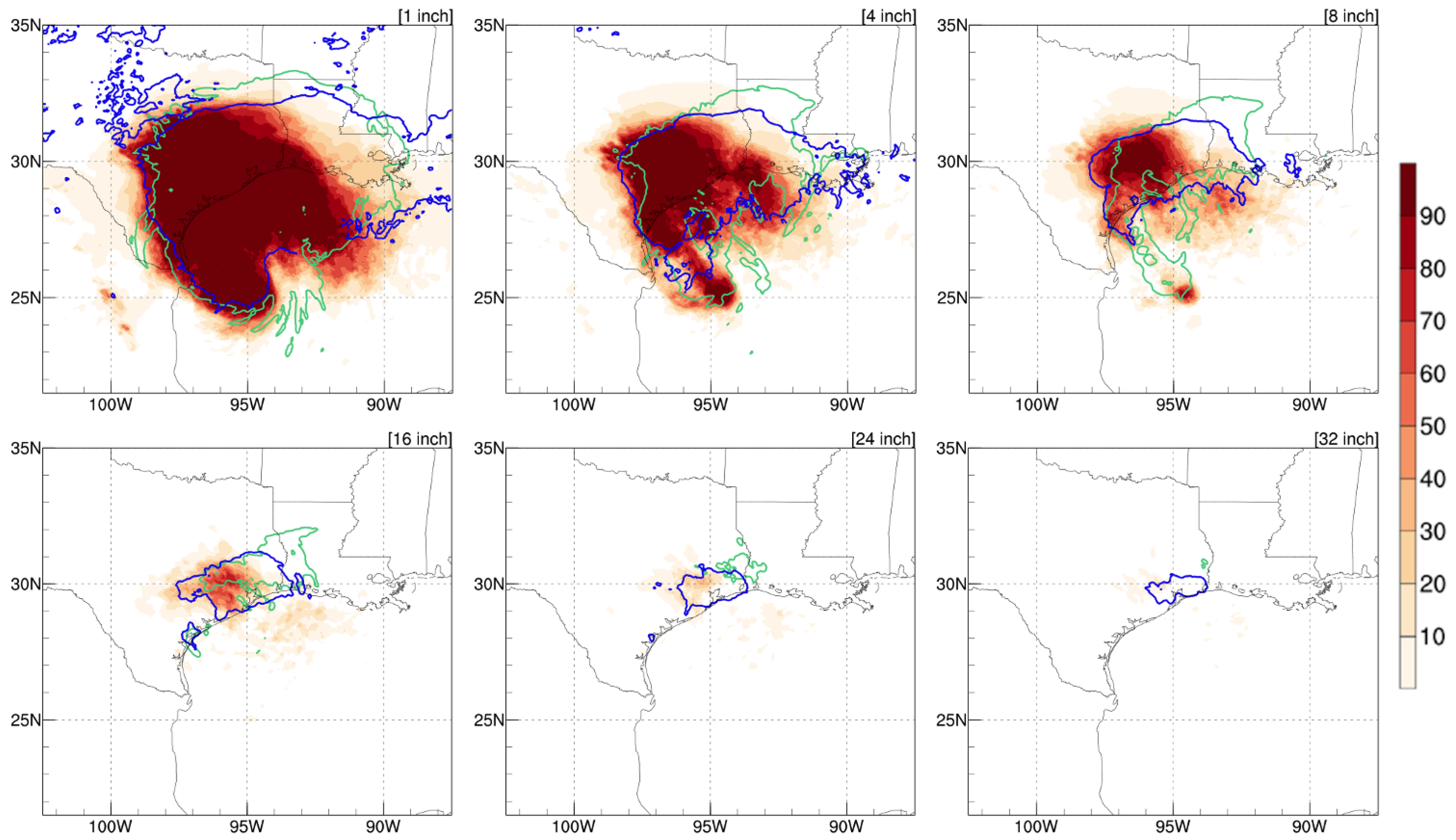
Figure 12 shows the probabilistic precipitation forecasts of 1, 4, 8, 16, 24, and 32 inches compared to Stage IV (blue contours) and HB17 (green contours) at 0000 UTC 25 August. In general, H17E produced reasonable rainfall patterns and predicted realistic rainfall locations. The top 3 panels show 1-, 4-, and 8-inch accumulated rainfall probability. The predictions were mostly contained within Stage IV observations, except the rainfall in Louisiana and southern Mississippi was not successfully captured by the majority of ensemble members. HB17 shows accumulated rainfall is above 8 inches along the track in the Gulf of Mexico, but H17E predicts that the accumulated rainfall in this region is most likely in between 4 inches and 8 inches. The 16-inch accumulated rainfall panel indicates a similar result: even though most of the high possibility region is contained within the observation contours but the predicted region is not sufficient. Unlike the result of the deterministic run where the 16-inch prediction overextended to Louisiana, the probabilistic run only presents the rainfall over Houston and misses the area east of Houston. Moreover, in the 24-inch and 32-inch probabilistic panels, few members indicate that the location of these amounts of rainfall occurs around Houston. H17E matches Stage IV better than HB17, which predicted a peak rainfall closer to Louisiana. However, too few of the members show this extreme rainfall amount as the ensemble members unsuccessfully predicted Harvey’s intensity. The storm intensity was underestimated, which could contribute to the probability of extreme rainfall. This experiment shows that probabilistic rainfall prediction of areas exceeding certain thresholds considering several track possibilities can deliver more realistic extreme rainfall locations than HB17. However, in our case, H17E did not provide the correct rainfall amounts exceeding certain thresholds and missed the lighter rain totals over eastern Texas.
4. Discussion
This study demonstrated the performance and utility of the HWRF precipitation forecasts for Hurricane Harvey (2017) using a deterministic version (HB17) and a probabilistic version (H17E). These versions were compared with robust baselines (Stage IV, IMERG, and R-CLIPER) to show that HWRF is capable of producing realistic rainfall totals and improving the prediction of heavy rainfall locations. Overall, the HWRF precipitation forecasts for Harvey were encouraging. Details of the findings are discussed below:
4.1. Deterministic Hwrf Rainfall Prediction
Deterministic rainfall forecasts are useful because the models that make them can be configured at convective-scale resolutions to better simulate processes important for precipitation. HB17 produced realistic forecasts of rainfall patterns and rain rate distributions over land associated with Hurricane Harvey, including an intense and stationary outer rainband near Houston that had precipitation totals in excess of 32 inches over the forecast period. Although this rainband location was not perfectly predicted, this case study supports the utility of HWRF precipitation forecasts even in difficult scenarios, such as the landfall and subsequent stall of Harvey in southeastern Texas. Further investigation revealed a realistic radial distribution of rain rates and rain flux in Harvey, especially at larger radii where the intense rainband was located. Further modification of the HWRF physics may further improve precipitation forecasts. For example, the convection parameterization in HB17 may have contributed to a frequency of extreme rain rates that was higher than expected. It is recommended that HWRF be considered as QPF guidance for landfalling TCs.
4.2. Probabilistic Hwrf Rainfall Prediction
An advantage of probabilistic rainfall forecasting is that it comprehensively considers several possible atmospheric conditions to account for uncertainty and limited predictability in NWP models. H17E predicted the extreme rainfall location more reliably than HB17. However, the ensemble missed the rainfall in Louisiana, and the heavy rainfall probability was potentially low due to the weaker ensemble intensity forecasts. For practically interpolating the probabilistic outputs, the uncertainty between members should be taken into account. Extreme rainfall should be emphasized even when only a handful of members show the tendency. Also, utilizing an ensemble model with a higher number of members could possibly help to further improve estimates of uncertainty in extreme amounts, but relies on increased computational resources. Regardless, H17E has already shown the potential benefits of the HWRF probabilistic prediction for identifying extreme rainfall locations.
4.3. R-Cliper Rainfall Prediction
Due to the simplicity of the R-CLIPER model, the rainfall pattern was not well presented for Hurricane Harvey. R-CLIPER predicted that rainfall accumulated only along the track while Hurricane Harvey had a strong outer rainband. It is worthy to note that the computational cost of R-CLIPER is very small and this model was originally developed to serve as a climatological baseline for dynamic model rainfall evaluation. The TRMM mode of R-CLIPER rainfall is simply based on a storm intensity, and this method is highly efficient. However, the strongest rainfall does not necessarily happen within eyewall where the strongest wind is. Moreover, shear and topography effects are important elements for rainfall evaluation [
3,
12]. Hence, R-CLIPER can be further upgraded to increase its predictability within affordable computational cost. For example, an ensemble version of R-CLIPER or PHRaM can be developed to take different possibilities of extreme rainfall patterns into account.
4.4. The Limitations of Observational Data
Our study validated model performance against the observational data, which we assumed are the ground truth for rainfall amounts. However, there are limitations of data collections, which might increase the uncertainty of a model’s performance evaluation. In other words, Stage IV is a combination of rain gauge and radar datasets. Rain gauges might not be fully functional during severe weather events, and they only can collect data on land at certain locations. Like gauges, radar sensors only cover a certain range and have limited data over the ocean. Thus, even though Stage IV has a better resolution compared to other datasets, Stage IV is limited to in-land rainfall evaluation. To overcome this limitation, we also examined model performance against IMERG satellite data, which provides rainfall observations over the ocean. However, the drawback of this data is that its resolution is lower than Stage IV.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











