MultiStep Ahead Forecasting for Hourly PM10 and PM2.5 Based on Two-Stage Decomposition Embedded Sample Entropy and Group Teacher Optimization Algorithm




Abstract
:1. Introduction
2. Methods
2.1. ICEEMDAN
- The EMD algorithm is utilized to calculate the local means of n realizations :where the operator is the j th mode of the time series G(t) decomposed by the EMD, represents Gaussian white noise with variance ranging from 0 to 1. , which is utilized to remove the fraction of noise energy action at the stage of algorithm begins. std represents the standard deviation.
- Calculate the first residue , and the first mode can be obtained based on it. The operator E( ) produces the local mean.
- can be estimated by Equation (4), and then compute the second mode .
- and for can be calculated as follows:
- Step 4 is repeated until obtain all the IMFs.
2.2. Wavelet Transform (WT)
2.3. Sample Entropy
2.4. Group Teaching Optimization Algorithm (GTOA)
2.5. Modified Extreme Learning Machine
2.6. Multistep Prediction
2.7. Framework of the Proposed Hybrid Approach
3. Empirical Results and Analysis
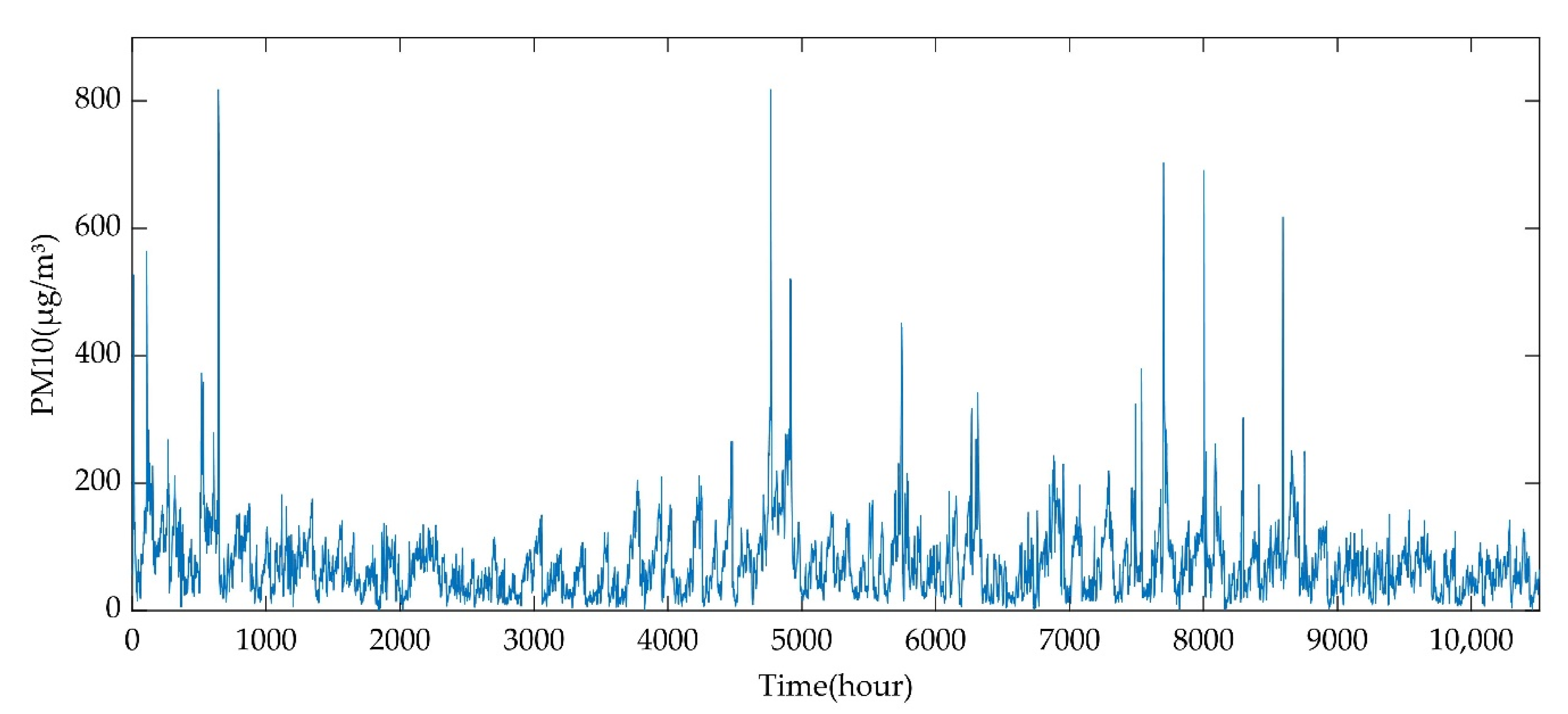
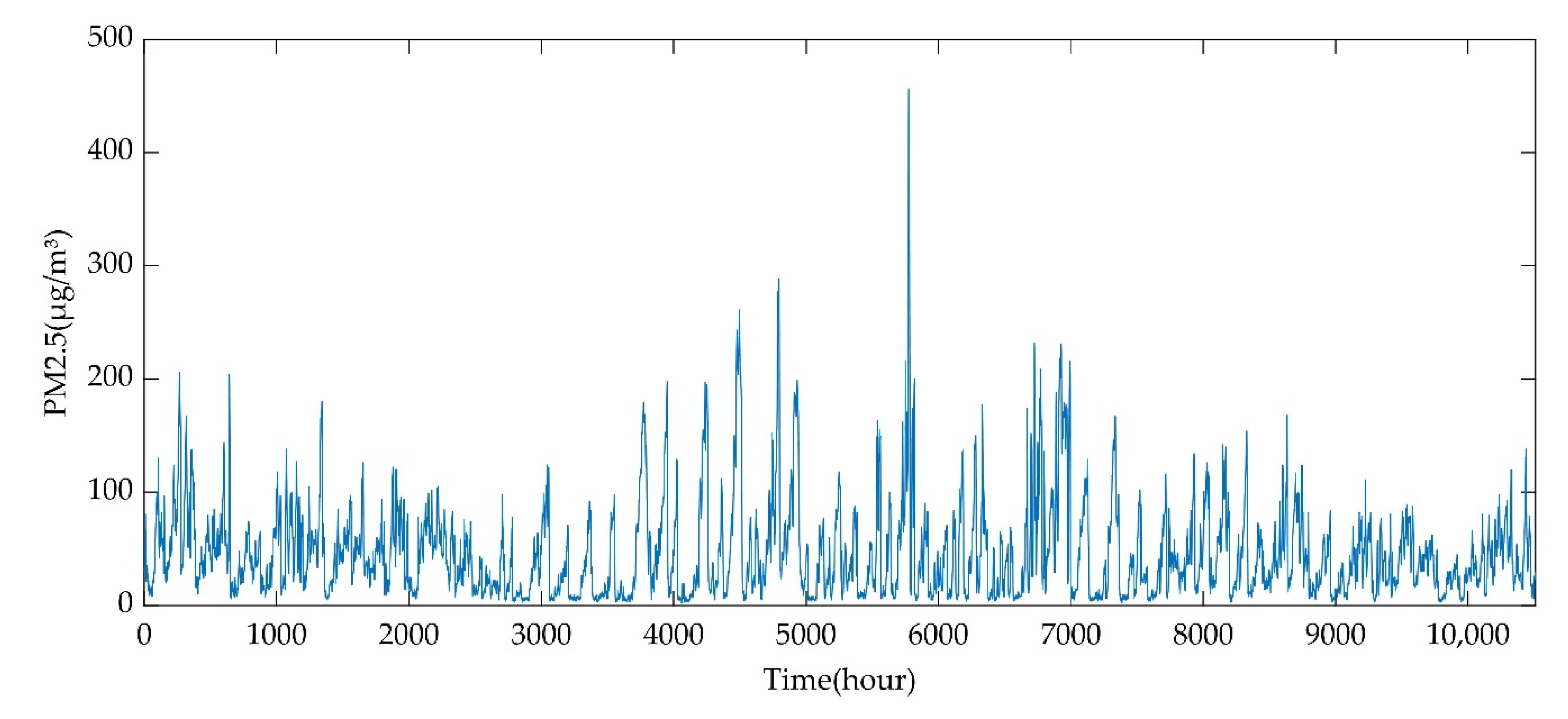
3.1. Data Set and Evaluation Criteria
3.2. Result and Analysis
3.2.1. Subsubsection
3.2.2. Comparison Analysis of PM10 Forecasting
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wen, M.; Li, P.; Zhang, L.; Chen, Y. Stock market trend prediction using high-order information of time series. IEEE Access 2019, 7, 28299–28308. [Google Scholar] [CrossRef]
- Jeff, T. Ocean scientists work to forecast huge plankton blooms in arabian sea. Nature 2018, 555, 569–570. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Kim, D.K.; Noh, J.; Kim, M. Stable Forecasting of Environmental Time Series via Long Short Term Memory Recurrent Neural Network. IEEE Access 2018, 6, 75216–75228. [Google Scholar] [CrossRef]
- Dippner, J.W.; Krncke, I. Ecological forecasting in the presence of abrupt regime shifts. J. Mar. Syst. 2015, 150, 34–40. [Google Scholar] [CrossRef]
- Qiao, W.; Yang, Z. Forecast the electricity price of U.S using a wavelet transform-based hybrid model. Energy 2020, 193, 511–530. [Google Scholar] [CrossRef]
- Zou, B.; Li, S.; Zheng, Z.; Zhan, F.B.; Yang, Z.; Wan, N. Healthier routes planning: A new method and online implementation for minimizing air pollution exposure risk. Comput. Environ. Urban Syst. 2020, 80, 101456. [Google Scholar] [CrossRef]
- Ma, X.; Longley, I.; Gao, J.; Salmond, J. Evaluating the effect of ambient concentrations, route choices, and environmental (in)justice on students dose of ambient no2 while walking to school at population scales. Environ. Sci. Technol. 2020, 54, 12908–12919. [Google Scholar] [CrossRef]
- Afghan, F.R.; Patidar, S.K. Health impacts assessment due to PM2.5, PM10 and NO2 exposure in National Capital Territory (NCT) Delhi. Pollution 2020, 6, 115–126. [Google Scholar] [CrossRef]
- Sharma, E.; Deo, R.C.; Prasad, R.; Parisi, A.V. A hybrid air quality early-warning framework: An hourly forecasting model with online sequential extreme learning machines and empirical mode decomposition algorithms. Sci. Total Environ. 2020, 709, 135934. [Google Scholar] [CrossRef]
- Gualtieri, G.; Carotenuto, F.; Finardi, S.; Tartaglia, M.; Toscano, P.; Gioli, B. Forecasting PM10 hourly concentrations in northern Italy: Insights on models performance and PM10 drivers through self-organizing maps. Atmos. Pollut. Res. 2018, 9, 1204–1213. [Google Scholar] [CrossRef]
- Venkataraman, V.; Usmanulla, S.; Sonnappa, A.; Sadashiv, P.; Mohammed, S.S.; Narayanan, S.S. Wavelet and multiple linear regression analysis for identifying factors affecting particulate matter PM2.5 in Mumbai City. India Int. J. Qual. Reliab. Manag. 2019, 36, 1750–1783. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, J.; Qiu, R.; Hu, X.; Zhang, H.; Chen, Q.; Tian, H.; Lin, D.; Wang, J. Trend analysis and forecast of PM2.5 in Fuzhou, China using the ARIMA model. Ecol. Indic. 2018, 95, 702–710. [Google Scholar] [CrossRef]
- Xiao, Q.; Zeng, Z. Scale-limited lagrange stability and finite-time synchronization for memristive recurrent neural networks on time scales. IEEE Trans. Cybern. 2017, 47, 2984–2994. [Google Scholar] [CrossRef] [PubMed]
- Zhu, S.; Yang, Q.; Shen, Y. Noise further expresses exponential decay for globally exponentially stable time-varying delayed neural networks. Neural Netw. 2016, 77, 7–13. [Google Scholar] [CrossRef]
- Xayasouk, T.; Lee, H.M.; Lee, G. Air pollution prediction using long short-term memory (LSTM) and Deep Autoencoder (DAE) Models. Sustainability 2020, 12, 2570. [Google Scholar] [CrossRef] [Green Version]
- Kouziokas, G.N. SVM kernel based on particle swarm optimized vector and Bayesian optimized SVM in atmospheric particulate matter forecasting. Appl. Soft Comput. J. 2020, 93, 106410. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.J.; Chang, L.C.; Kao, I.F.; Wang, Y.S.; Kang, C.C. Multi-output support vector machine for regional multi-step-ahead PM2.5 forecasting. Sci. Total Environ. 2019, 651, 230–240. [Google Scholar] [CrossRef]
- Zheng, N.; Luo, M.; Zou, X.; Qiu, X.; Lu, J.; Han, J.; Wang, S.; Wei, Y.; Zhang, S.; Yao, H. A novel method for the recognition of air visibility level based on the optimal binary tree support vector machine. Atmosphere 2018, 9, 481. [Google Scholar] [CrossRef] [Green Version]
- Park, S.; Kim, M.; Kim, M.; Namgung, H.G.; Kim, K.T.; Cho, K.H.; Kwon, S.B. Predicting PM 10 concentration in Seoul metropolitan subway stations using artificial neural network (ANN). J. Hazard. Mater. 2018, 341, 75–82. [Google Scholar] [CrossRef]
- Mahajan, S.; Liu, H.M.; Tsai, T.C.; Chen, L.J. Improving the accuracy and efficiency of PM2.5 forecast service using cluster-based hybrid neural network model. IEEE Access 2018, 6, 19193–19204. [Google Scholar] [CrossRef]
- Jiang, F.; He, J.; Tian, T. A clustering-based ensemble approach with improved pigeon-inspired optimization and extreme learning machine for air quality prediction. Appl. Soft Comput. J. 2019, 85, 105827. [Google Scholar] [CrossRef]
- Wang, D.; Liu, Y.; Luo, H.; Yue, C.; Cheng, S. Day-Ahead PM2.5 concentration forecasting using WT-VMD based decomposition method and back propagation neural network improved by differential evolution. Int. J. Environ. Res. Public Health 2017, 14, 764. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, H.; Zhu, Z.; Li, C.; Li, R. A novel combined forecasting system for air pollutants concentration based on fuzzy theory and optimization of aggregation weight. Appl. Soft Comput. J. 2019, 87, 105972. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar] [CrossRef]
- Colominas, M.A.; Schlotthauer, G.; Torres, M.E. Improved complete ensemble EMD: A suitable tool for biomedical signal processing. Biomed. Signal Process. Control 2014, 14, 19–29. [Google Scholar] [CrossRef]
- Altuve, M.; Suárez, L.; Ardila, J. Fundamental heart sounds analysis using improved complete ensemble EMD with adaptive noise. Biocybern. Biomed. Eng. 2020, 40, 426–439. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Sanandaji, B.M.; Poolla, K.; Varaiya, P. Exploiting sparsity of Interconnections inspatio-temporal wind speed forecasting using Wavelet Transform. Appl. Energy 2016, 165, 735–747. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Mi, X.W.; Li, Y.F. Wind speed forecasting method based on deep learning strategy using empirical wavelet transform, long short term memory neural network and Elman neural network. Energy Convers. Manag. 2018, 156, 498–514. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Jin, Z. Group teaching optimization algorithm: A novel metaheuristic method for solving global optimization problems. Expert Syst. Appl. 2020, 148, 113246. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Sun, S.; Wang, S.; Zhang, G.; Zheng, J. A decomposition-clustering-ensemble learning approach for solar radiation forecasting. Sol. Energy 2018, 163, 189–199. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 2002, 20, 134–144. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tested Model | Benchmark Model | ||||||
|---|---|---|---|---|---|---|---|
| ICEEMDAN-GTOA -ELM | ICEEMDAN- ELM | WT-GTOA- ELM | WT-ELM | GTOA-ELM | DE-ELM | ELM | |
| ICEEMDAN-WT -GTOA-ELM | −3.5039 | −6.7207 | −6.0325 | −3.5972 | −6.5332 | −7.4301 | −8.6697 |
| (0.0005) | (0.0000) | (0.0000) | (0.0003) | (0.0000) | (0.0000) | (0.0000) | |
| ICEEMDAN- GTOA-ELM | −3.8489 | −1.4691 | −3.0902 | −6.1659 | −7.0459 | −8.4643 | |
| (0.0001) | (0.1420) | (0.0020) | (0.0000) | (0.0000) | (0.0000) | ||
| ICEEMDAN-ELM | 0.9991 | −2.6930 | −5.8667 | −6.7564 | −8.1801 | ||
| (0.3179) | (0.0071) | (0.0000) | (0.0000) | (0.0000) | |||
| WT-GTOA-ELM | −3.0345 | −6.2075 | −7.0796 | −8.4683 | |||
| (0.0024) | (0.0000) | (0.0000) | (0.0000) | ||||
| WT-ELM | −4.1550 | −4.6741 | −7.2905 | ||||
| (0.0000) | (0.0000) | (0.0000) | |||||
| GTOA-ELM | −2.1288 | −8.1789 | |||||
| (0.0334) | (0.0000) | ||||||
| DE-ELM | −6.7950 | ||||||
| (0.0000) | |||||||
| Tested Model | Benchmark Model | ||||||
|---|---|---|---|---|---|---|---|
| ICEEMDAN-GTOA -ELM | ICEEMDAN- ELM | WT-GTOA- ELM | WT-ELM | GTOA-ELM | DE-ELM | ELM | |
| ICEEMDAN-WT -GTOA-ELM | −3.6835 | −5.7928 | −3.9237 | −5.1016 | −5.7343 | −5.9685 | −6.1007 |
| (0.0001) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | |
| ICEEMDAN- GTOA-ELM | −5.5713 | −2.2100 | −3.3500 | −5.7349 | −5.9697 | −6.1089 | |
| (0.0000) | (0.0136) | (0.0004) | (0.0000) | (0.0000) | (0.0000) | ||
| ICEEMDAN-ELM | 0.6430 | −0.4859 | −5.2907 | −5.5537 | −5.7128 | ||
| (0.7399) | (0.3135) | (0.0000) | (0.0000) | (0.0000) | |||
| WT-GTOA-ELM | −1.1973 | −5.1684 | −5.4130 | −5.5706 | |||
| (0.1156) | (0.0000) | (0.0000) | (0.0000) | ||||
| WT-ELM | −4.9211 | −5.1515 | −5.2924 | ||||
| (0.0000) | (0.0000) | (0.0000) | |||||
| GTOA-ELM | −1.9304 | −1.8217 | |||||
| (0.0268) | (0.0342) | ||||||
| DE-ELM | −1.0706 | ||||||
| (0.1422) | |||||||
| Tested Model | Benchmark Model | ||||||
|---|---|---|---|---|---|---|---|
| ICEEMDAN-GTOA -ELM | ICEEMDAN- ELM | WT-GTOA- ELM | WT-ELM | GTOA-ELM | DE-ELM | ELM | |
| ICEEMDAN-WT -GTOA-ELM | −2.2889 | −4.9527 | −2.6244 | −4.1650 | −5.5552 | −5.8006 | −5.3671 |
| (0.0110) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | |
| ICEEMDAN- GTOA-ELM | −5.0106 | −1.9315 | −3.7159 | −5.5881 | −5.8494 | −5.4298 | |
| (0.0000) | (0.0267) | (0.0001) | (0.0000) | (0.0000) | (0.0000) | ||
| ICEEMDAN-ELM | 0.5495 | −1.2349 | −5.2393 | −5.4961 | −5.1462 | ||
| (0.7087) | (0.1084) | (0.0000) | (0.0000) | (0.0000) | |||
| WT-GTOA-ELM | −2.3284 | −4.9138 | −5.1012 | −4.8171 | |||
| (0.0099) | (0.0000) | (0.0000) | (0.0000) | ||||
| WT-ELM | −4.8673 | −5.0693 | −4.7804 | ||||
| (0.0000) | (0.0000) | (0.0000) | |||||
| GTOA-ELM | 0.0113 | −2.1057 | |||||
| (0.5045) | (0.0176) | ||||||
| DE-ELM | −2.3641 | ||||||
| (0.0090) | |||||||
| Multistep Ahead | Model | MAE (μg/m3) | MAPE (%) | NRMSE | TIC | Ds (%) |
|---|---|---|---|---|---|---|
| One-step ahead | ELM | 4.40 | 19.61 | 16.27 | 0.07 | 62.49 |
| GTOA-ELM | 3.40 | 13.24 | 13.54 | 0.06 | 68.00 | |
| DE-ELM | 3.82 | 15.03 | 14.76 | 0.06 | 56.98 | |
| WT-ELM | 1.71 | 6.71 | 6.62 | 0.03 | 89.17 | |
| WT-GTOA-ELM | 1.26 | 4.78 | 4.95 | 0.02 | 93.71 | |
| ICEEMDAN-ELM | 1.11 | 4.33 | 4.03 | 0.02 | 94.00 | |
| ICEEMDAN-GTOA-ELM | 0.60 | 2.35 | 2.42 | 0.01 | 98.10 | |
| ICEEMDAN-WT-GTOA-ELM | 0.49 | 1.86 | 1.90 | 0.01 | 98.88 | |
| Two-step ahead | ELM | 6.69 | 25.75 | 27.21 | 0.11 | 49.54 |
| GTOA-ELM | 5.56 | 20.43 | 23.52 | 0.10 | 52.07 | |
| DE-ELM | 5.72 | 21.38 | 23.74 | 0.10 | 48.07 | |
| WT-ELM | 2.91 | 11.13 | 11.00 | 0.05 | 80.23 | |
| WT -GTOA-ELM | 2.48 | 9.33 | 9.42 | 0.04 | 83.89 | |
| ICEEMDAN-ELM | 1.97 | 7.59 | 7.77 | 0.03 | 85.46 | |
| ICEEMDAN-GTOA-ELM | 1.31 | 4.87 | 5.25 | 0.02 | 92.92 | |
| ICEEMDAN-WT-GTOA-ELM | 1.13 | 4.31 | 4.31 | 0.02 | 94.39 | |
| Three-step ahead | ELM | 8.91 | 37.23 | 34.62 | 0.14 | 48.24 |
| GTOA-ELM | 7.66 | 28.59 | 31.41 | 0.13 | 47.61 | |
| DE-ELM | 7.99 | 32.80 | 32.18 | 0.13 | 46.92 | |
| WT -ELM | 4.10 | 15.45 | 15.45 | 0.06 | 74.17 | |
| WT -GTOA-ELM | 3.57 | 13.52 | 13.63 | 0.06 | 77.64 | |
| ICEEMDAN-ELM | 2.83 | 10.84 | 11.41 | 0.05 | 78.17 | |
| ICEEMDAN-GTOA-ELM | 1.42 | 5.39 | 6.01 | 0.03 | 92.92 | |
| ICEEMDAN-WT-GTOA-ELM | 1.32 | 5.11 | 5.41 | 0.02 | 93.51 |
| Tested Model | Benchmark Model | ||||||
|---|---|---|---|---|---|---|---|
| ICEEMDAN-GTOA -ELM | ICEEMDAN -ELM | WT-GTOA -ELM | WT-ELM | GTOA-ELM | DE-ELM | ELM | |
| ICEEMDAN-WT -GTOA-ELM | −2.7175 | −13.5408 | −10.7244 | −10.3035 | −10.2518 | −12.9119 | −11.8119 |
| (0.0066) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | |
| ICEEMDAN- GTOA-ELM | −9.3974 | −8.6997 | −9.2922 | −10.1336 | −12.7361 | −11.6786 | |
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | ||
| ICEEMDAN-ELM | −4.0939 | −6.7991 | −9.6258 | −12.2484 | −11.2595 | ||
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | |||
| WT-GTOA-ELM | −6.3891 | −9.4224 | −12.0698 | −11.2966 | |||
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | ||||
| WT-ELM | −9.0503 | −11.5472 | −11.4579 | ||||
| (0.0000) | (0.0000) | (0.0000) | |||||
| GTOA-ELM | −4.5612 | −6.2942 | |||||
| (0.0000) | (0.0000) | ||||||
| DE-ELM | −3.0523 | ||||||
| (0.0023) | |||||||
| Tested Model | Benchmark Model | ||||||
|---|---|---|---|---|---|---|---|
| ICEEMDAN-GTOA -ELM | ICEEMDAN -ELM | WT-GTOA -ELM | WT-ELM | GTOA-ELM | DE-ELM | ELM | |
| ICEEMDAN-WT -GTOA-ELM | −7.2714 | −8.5699 | −15.3825 | −14.6345 | −10.2056 | −10.5647 | −11.1624 |
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | |
| ICEEMDAN- GTOA-ELM | −8.0793 | −13.4719 | −13.5744 | −10.1615 | −10.5384 | −11.1396 | |
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | ||
| ICEEMDAN-ELM | −4.4998 | −7.8214 | −10.0408 | −10.4871 | −11.0846 | ||
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | |||
| WT-GTOA-ELM | −6.7670 | −8.9025 | −9.2585 | −10.1599 | |||
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | ||||
| WT-ELM | −8.3488 | −8.6986 | −9.7565 | ||||
| (0.0000) | (0.0000) | (0.0000) | |||||
| GTOA-ELM | −0.7343 | −5.8911 | |||||
| (0.2314) | (0.0000) | ||||||
| DE-ELM | −6.8786 | ||||||
| (0.0000) | |||||||
| Tested Model | Benchmark Model | ||||||
|---|---|---|---|---|---|---|---|
| ICEEMDAN-GTOA -ELM | ICEEMDAN -ELM | WT-GTOA -ELM | WT-ELM | GTOA-ELM | DE-ELM | ELM | |
| ICEEMDAN-WT -GTOA-ELM | −5.9385 | −8.8548 | −15.2023 | −15.8871 | −11.1402 | −10.9329 | −12.4082 |
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | |
| ICEEMDAN- GTOA-ELM | −8.4679 | −14.6155 | −15.4375 | −11.0997 | −10.8851 | −12.3653 | |
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | ||
| ICEEMDAN-ELM | −4.0254 | −7.7477 | −11.1172 | −10.8874 | −12.3892 | ||
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | (0.0000) | |||
| WT-GTOA-ELM | −5.8209 | −9.5422 | −9.4834 | −11.0517 | |||
| (0.0000) | (0.0000) | (0.0000) | (0.0000) | ||||
| WT-ELM | −9.0141 | −9.0406 | −10.5554 | ||||
| (0.0000) | (0.0000) | (0.0000) | |||||
| GTOA-ELM | −2.1974 | −5.3503 | |||||
| (0.0140) | (0.0000) | ||||||
| DE-ELM | −5.2124 | ||||||
| (0.0000) | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, F.; Qiao, Y.; Jiang, X.; Tian, T. MultiStep Ahead Forecasting for Hourly PM10 and PM2.5 Based on Two-Stage Decomposition Embedded Sample Entropy and Group Teacher Optimization Algorithm. Atmosphere 2021, 12, 64. https://doi.org/10.3390/atmos12010064
Jiang F, Qiao Y, Jiang X, Tian T. MultiStep Ahead Forecasting for Hourly PM10 and PM2.5 Based on Two-Stage Decomposition Embedded Sample Entropy and Group Teacher Optimization Algorithm. Atmosphere. 2021; 12(1):64. https://doi.org/10.3390/atmos12010064
Chicago/Turabian StyleJiang, Feng, Yaqian Qiao, Xuchu Jiang, and Tianhai Tian. 2021. "MultiStep Ahead Forecasting for Hourly PM10 and PM2.5 Based on Two-Stage Decomposition Embedded Sample Entropy and Group Teacher Optimization Algorithm" Atmosphere 12, no. 1: 64. https://doi.org/10.3390/atmos12010064
APA StyleJiang, F., Qiao, Y., Jiang, X., & Tian, T. (2021). MultiStep Ahead Forecasting for Hourly PM10 and PM2.5 Based on Two-Stage Decomposition Embedded Sample Entropy and Group Teacher Optimization Algorithm. Atmosphere, 12(1), 64. https://doi.org/10.3390/atmos12010064