When the study is first conducted, there were 11,317 instances (cases) from 1982 to 2016, and 571 (approximately 5.0%) were under rapid intensification (RI). A random stratified sampling process based on TC cases with consideration of RI/non-RI ratio is performed. In other words, a TC is included in either the training set or the testing set with all the instances for the same TC to avoid autocorrelation for instances in the same TCs. This division process resulted in 10,185 instances (including 523 RI cases, 5.1%) in the training validation set, and 1132 instances (48 RI cases, 4.2%) were in the test dataset.
After the training was done, however, 465 instances in 2017 and the last tropical cyclone in 2016 are added to the SHIPS developmental database, and all of these instances are added to the test dataset. The test dataset proportion ends up with 1597 (14.1%) instances in total with 95 RI instances (5.9%).
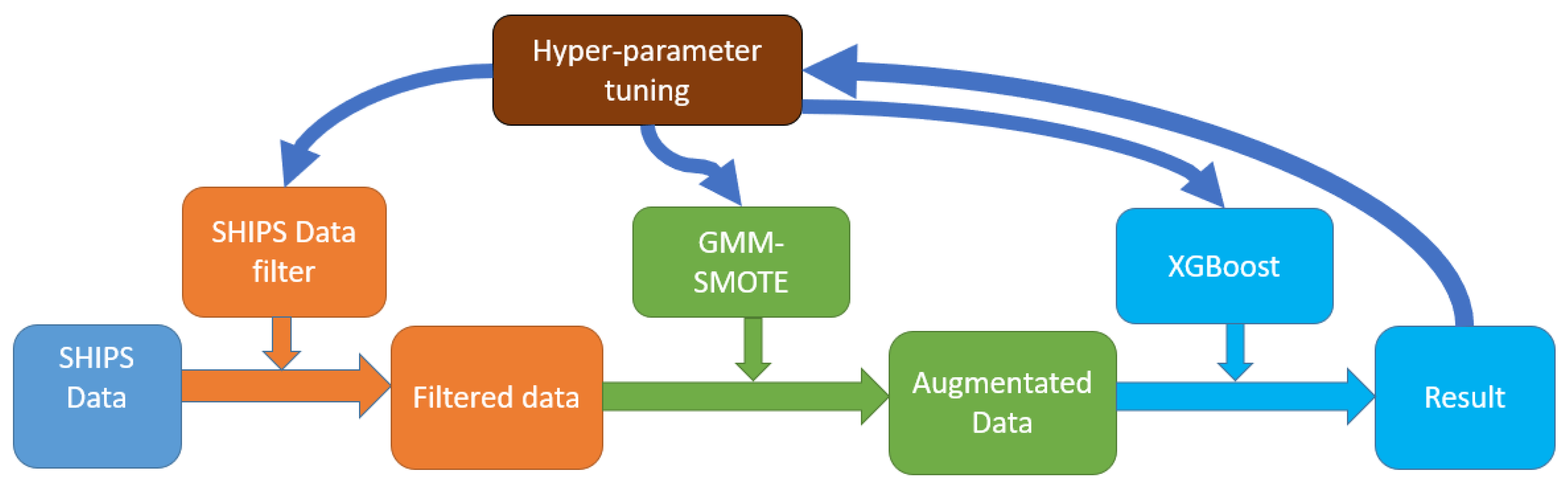
All algorithms, including those for data processing, data visualization, and data mining and machine learning in this study, are performed with R (version 3.5.1), python base (v3.7.0), python multiprocessing package (v2.5), scikit-learn package (v1.9.2), XGBoost package (v0.83), and pyspark package (Spark API) (v2.21).
5.3. Feature Importance
Generally, the variable (feature) importance is used to leverage the variable contribution and is defined as a quantitative score. The higher the score is, the more the variable contributes, and the more useful that variable is for classifying RI. The classifier used in this study, XGBoost, provides the scaled importance scores with the sum of all scores being one.
Table 10 displays the variables with the top 10 importance scores and their definition [
16]. The full list of the 72 variables is given in
Table A2. The past 12-h intensity change, BD12, has the largest importance score, 0.0362, which almost doubles the importance score of the second important variable. Because BD18 and BD06 are highly correlated with BD12 (see
Table A1), we can safely assume that they are as important as BD12. This result confirms the findings of KD03 and Yang et al. [
3] and means RI takes place more likely when a TC is in a relatively long-term intensification phase. The second most important variable is DTL, the distance from a TC to the nearest major land. The importance of DTL is slightly higher than the third to seventh most important variables, CFLX, SHRD, G150, jd, and VMAX, which are related to dry air, vertical wind shear magnitude between 850–200 hPa, the temperature perturbation at 150 hPa, annual Julian day, and the current TC intensity, respectively. The eighth to ninth variables are IRM1_5 and PW08.
It is interesting to note that IRM1_5, the standard deviation (STD) of GOES (Geostationary Operational Environmental Satellite) [
29] BT (brightness temperature) in 100–300 km radius 1.5 h before the initial time, is more important than the average BT value itself (IRM1_2). The phenomenon plausibly says that the non-uniform BT distribution around the TC center plays a greater role than the uniform BT level for the RI. The same thing takes place with PW08, the 600–800 km total precipitable water (TPW) standard deviation from the GFS analysis [
30], which is more important than the corresponding TPW value, PW07 represented by the highly correlated RHMD (
Table A1). This finding is consistent with the relationship between TC intensity and the symmetricity of the TC structure. Asif et al. [
31] used the STD and other statistics of BT in centric bands to establish a relationship with TC intensity, and those statistics play a similar role of the variance of the deviation angle described by Piñeros et al. [
32] and Ritchie et al. [
33]. A careful checking of the roles of the STDs of IRM1_5 and PW08 found that the means for RI cases are smaller than those means for non-RI cases, or a negative impact to RI. That means smaller STDs or more symmetric cloud features favor RI, consistent with the findings on symmetric convective structure related to shear direction [
34,
35,
36]. The tenth most important variable is VMPI, the maximum potential intensity, which ranked higher in other RI studies.
A two-side t-test is used for variable selection in KD03, and the KD03 model was built based on the five variables, DVMX (intensity change during the previous 12 h), SST, POT (maximum potential intensity (MPI)–maximum sustained surface wind speed), SHR (850–200 hPa vertical shear averaged from r = 200–800 km), and RHLO (850–700 hPa relative humidity averaged from r = 200–800 km), which are found significant in a 99.9% level and with the highest individual RI prediction power. In the first 10 importance variables identified by our model, BD12 (ranked 1st), SHRD (4th), VMPI (10th), and VMAX (7th) (POT = VMPI − VMAX) are consistent with the selected variables in KD03. The missed variables in the top ten compared with the top five in KD03 are SST and RHLO. SST is highly correlated with the selected E000, which is listed 52nd in the importance ranks. RHLO is highly correlated with RHMD, which is listed 57th in the importance ranks (
Table A1 and
Table A2).
Compared with variables selected by KD03, in KDK10, SST is removed, and four additional variables, D200 (time averaged 200 hPa divergence within a 1000-km radius), OHC (time averaged oceanic heat content), SDBT (STD of GOES-IR BT (t = 0 h) within a 50–200 km radius), and PX30 (the percentage area from 50 to 200 km radius covered by IR cloud-top BT of −30 °C or colder), are added. Among the four new variables, D200 is ranked 44th with a 0.0131 importance score (
Table A2). The OHC related parameters include COHC, NOHC, and RHCN, and among them, the highest importance score is achieved by COHC, which is highly correlated with CD26 ranked 30th with a score of 0.0153. The PX30 is corresponding to IR00_8, which is highly correlated with IRM1_16 ranked 50th with a 0.0119 score value. The only caught new KRD10 variable in our top ten is the SDBT by IRM1_5 (ranked 8th), representing GOES BT STD within the 100–300 km around the TC centers but 1.5 h before the current time.
KRD15 replaced RHLO with TPW (percentage of an area with TPW < 45 mm within a 500-km radius and ±45° of the up-shear SHIPS wind direction (t = 0 h)), and PX30 with PC2 (the second principal component of GOES-IR imagery within a 440 km radius (t = 0 h)), and added two new variables, inner-core dry-air (ICDA) predictor (time avg), and VMX0 (max sustained wind (t = 0 h)), comparing with variable used in KDK10. Among the four new variables, VMX0 is consistent with VMAX, ranked 7th in the importance list. ICDA is not directly included in SHIPS data, but the related parameter found is CFLX, the dry air predictor except for a factor of VMX0 in KRD15, and CFLX is ranked the 3rd in the top 10 parameter list. The definition of TPW is the same as MTPW_19 in the SHIPS, which ranked only 37th with an importance score of 0.014. The PC2 equivalent parameter in SHIPS is PC00, which ranked only 70th.
In summary, variables used by KD03, KDK10, and KRD15 for RI prediction are mostly consistent with our top 10 variables. The missed variables in KD03 are RHLO and SST, and RHLO was actually replaced by TPW later (KRD15), and TPW is ranked 37th in our list, much more important than the RHLO via the highly correlated RHMD at the 57th place. Among the four newly added parameters in KDK10, three, OHC, D200, and PX30, are outside the top 10 list. There are several variables in SHIPS representing the OHC. The most important one is found to be climatological OHC via the highly correlated parameter CD26 at the 30th rank. KRD15 mentioned that OHC works well only when the other two variables POT and ICDA are included in a model. D200 was introduced to SHIPS in 1998 [
37], but it was eliminated in 2001 and added back in 2002 [
2]. DeMaria et al. [
2] also found that the role of this divergence in TC intensity forecasting is sensitive to the data sources. Therefore, it is not very unusual if this model did not rank this predictor high. The last parameter not in the top 10 list, PX30, was replaced by PC2 in KRD15. Actually, PC2 is ranked 70th in this study, and it is hard to interpret the result. It is very unfortunate that the GOES-IR principal components were mistreated initially in this work, and we missed the opportunity to rank the importance of other PCs among the first nine PCs. The other missed parameter in KRD15 is the TPW, ranked only 37th. It is plausible that the humidity effects are also reflected in the 3rd ranked parameter CFLX.
In contrast to the missed parameters in the top 10 list, four out of the 10 variables, DTL, G150, jd, and PW08, are not included in the cited RI studies. The first such variable is the DTL, the distance to nearest major landmass, ranked the 2nd, which was introduced in the original SHIPS [
38] but removed in 1994 from the model. Since most RI events take place over the ocean, no other model includes this parameter. One reason for the importance of DTL is possibly that we did not remove TCs near land or landfall TCs. A detailed DTL distribution for RI and non-RI cases (not shown) demonstrates a complex role of DTL on RI. When DTL is less than ~700 km, a larger distance favors RI, not a surprising result. On the contrary, when the DTL is relatively large, the DTL for RI cases is smaller than that for the non-RI cases. Actually, it is not totally unexpected, because most weak TCs in their early lives are far from the landmass. G150 was added to the SHIPS database in 2015 without many direct applications/discussions in the relevant literature [
16]. It could be related to the tropopause temperature anomaly [
39,
40] and the height of the tropopause, and the related tropospheric stability (the authors thank one anonymous reviewer for this point). The Julian day, jd, was introduced in the first version of SHIPS [
38] with respect to the peak date, but it was found that the coefficients in the multiple linear regressions are not statistically significant for less than 48 h forecasting. Since 2003, the Julian day term in SHIPS was modified to a Gaussian function of the day with a 25-day scale to reduce the penalty on the very early and very late TCs [
2]. The Gaussian modification of jd in SHIPS and the important finding in this work possibly say that the Julian day has an influence on the RI, but its role may be nonlinear. It is interesting to notice that PW08 (the same as MPTW_8), the 600–800 km environmental TPW STD from the GFS analysis, is a more important feature than the corresponding TPW mean value (PW07). That means the variation of TPW in that range is more important than TPW amount, which also says the outer structure of TCs plays a role in the RI process.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}