

Machine Learning-Based Fog Nowcasting for Aviation with the Aid of Camera Observations
 , , and
, , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. The Target Site and Its Climatology
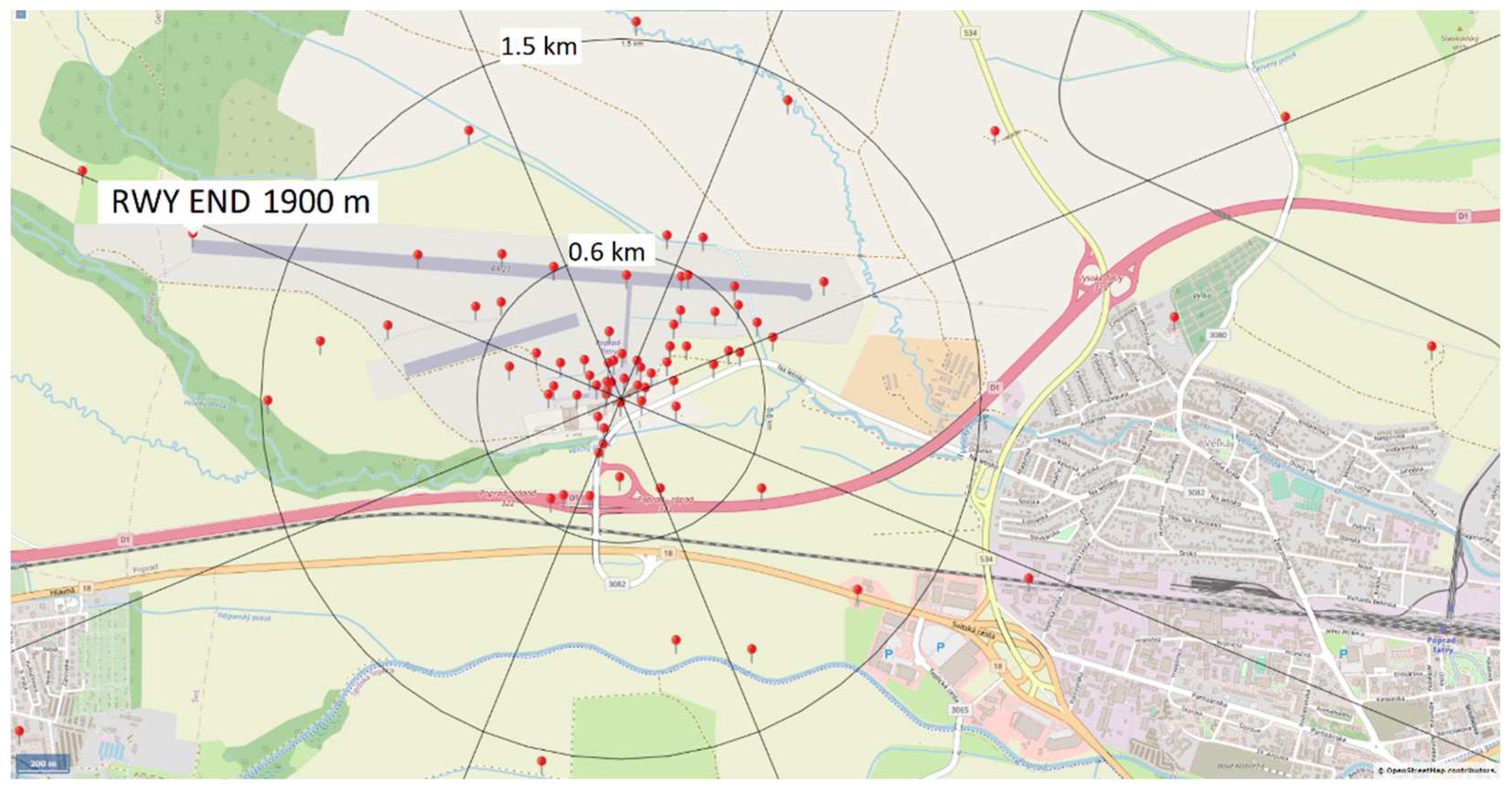
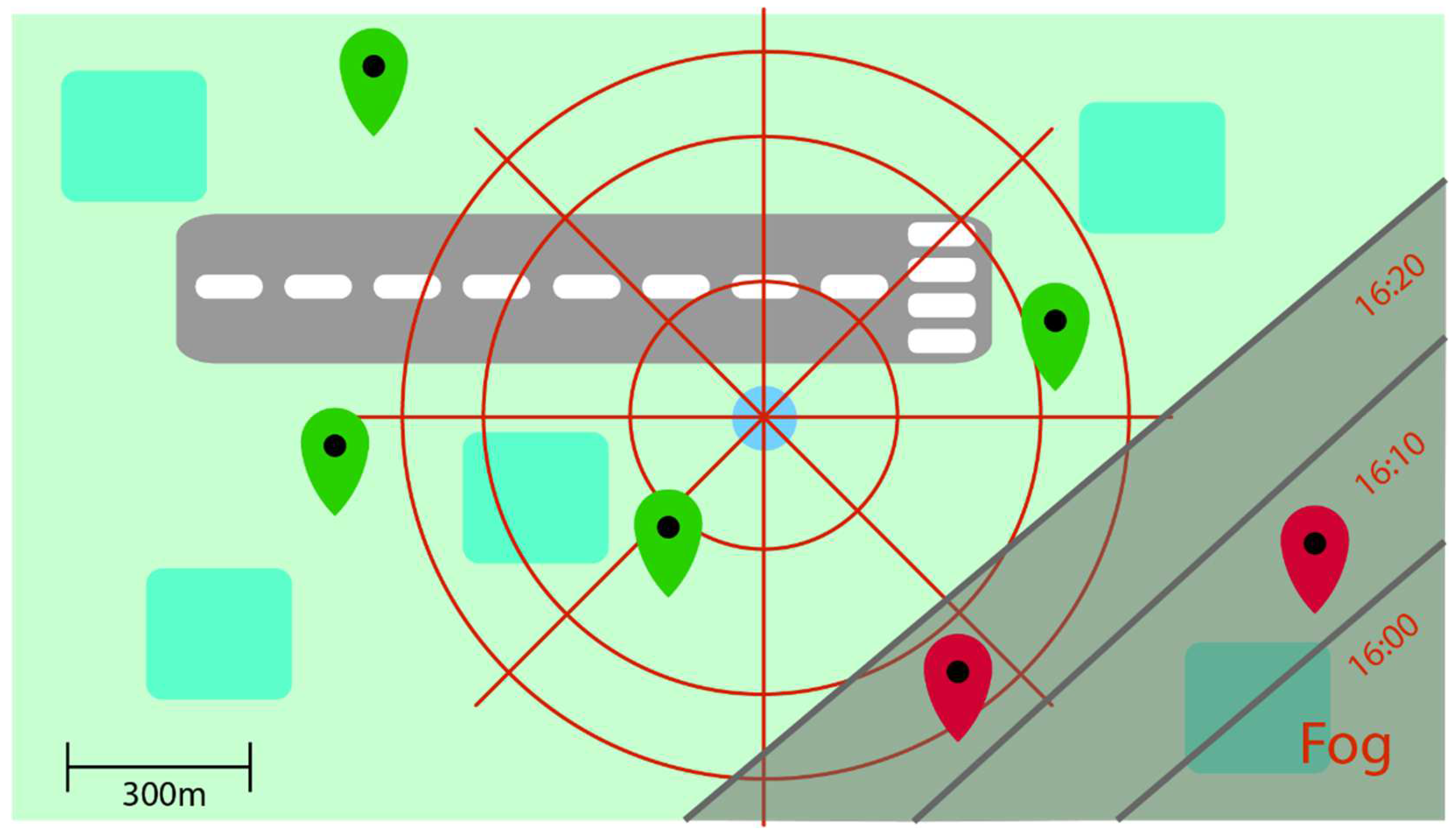
2.2. Camera-Based Observations of Visibility
- If all the markers are visible in a given direction, then the visibility is larger than the distance of the most distant marker in this direction.
- If some markers are not recognizable in a given direction, then the visibility is determined by the distance of the nearest visible marker preceding the first obscured one.
2.3. Dataset
- information from the METAR messages available with a frequency of 30 min;
- FS sensor measurements available with a frequency of 1 min, averaged through a 10 min moving window as per ICAO rules [33];
- other AWOS sensor measurements at the same intervals;
- camera imagery with frequency of 5 min supplemented by preceding sensor/camera measurements to these times.
2.4. Data Mining Methods
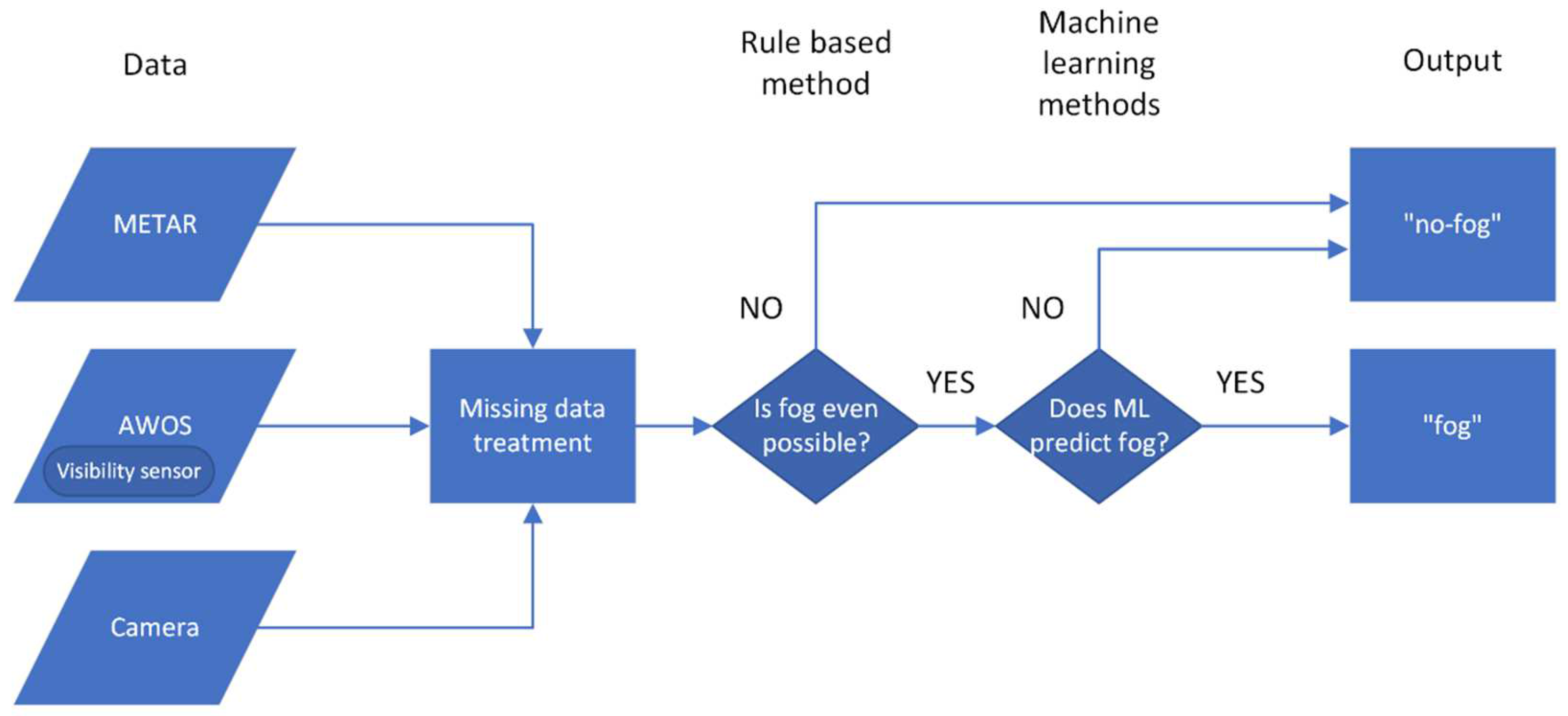
2.4.1. Rule-Based Methods in the Context of Unbalanced Datasets
- Rule-based system: Based on the input features, determine whether one can safely conclude the occurrence of ‘no-fog’ event. If yes, end the task. Else, continue to step #2.
- Machine learning classification: Based on the input features, predict the outcome (‘fog’ or ‘no-fog’).
2.4.2. Machine Learning Methods
K-Nearest Neighbors
Support Vector Machine
Decision Trees
2.5. Verification Methodology
- 1.
- Create a list of promising ML methods.
- i.
- For each ML method, create a list of hyperparameters.
The list should include ML methods suitable both from performance and deployment perspectives—accurate and fast enough, moderately computationally demanding, with modest memory requirements, etc. The corresponding hyperparameters can help in fine-tuning the performance of the methods. An example could be KNN with k = 3 or 5. - 2.
- Based on the available dataset, create systematic sets of features.One should start by making a full list of available features, and subsequently, imposing restrictions, such as no more than a certain amount of N features at a time, to avoid overfitting. The generated subsets should each contain N or less elements. Another option would be to rely on expert knowledge/intuition and select elements based on rules.
- 3.
- Split the dataset into training and testing parts.It is a common practice to divide the dataset into two parts: the first one for training the ML models and the second one for testing their performance. In the current study, the data were randomly divided into two groups in a ratio of 70% for training to 30% for testing with a random seed, which ensured the reproducibility of the splitting.
- 4.
- Loop over models, hyperparameters, and features:
- i.
- Train the model;
- ii.
- Evaluate the model.
- 5.
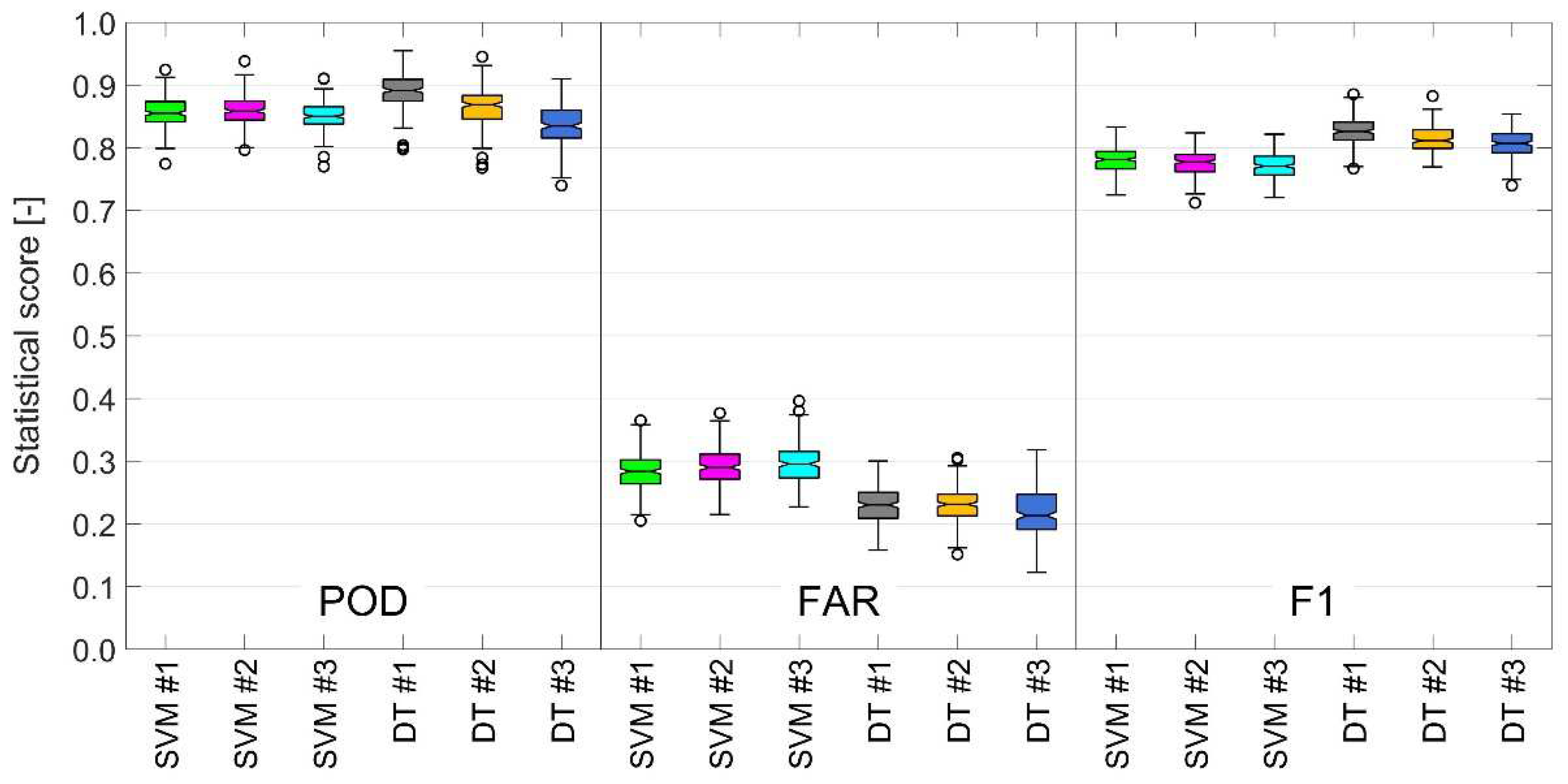
- Repeat steps #3 and #4 with different random splits.Generally speaking, this step is optional. However, inspired by the statistical technique of bootstrapping [47], in order to obtain more accurate and robust results, the original dataset was resampled 200 times with the same ratio (70:30) and with random seed repetition.
- 6.
- Evaluate the overall statistics.In this step, the obtained results were analyzed. The overall statistical scores were calculated as the mean of the 200-model runs with different random seeds.
- TN is the number of cases, in which no fog was predicted and no fog occurred (true negatives or correct negatives or zeros);
- FP is the number of cases with a fog forecast but fog did not occur (false positives or false alarms);
- FN is the number of cases, in which no fog was predicted but fog occurred (false negatives or misses); and
- TP is the number of cases, in which fog was forecasted and fog also occurred (true positives or hits).
3. Results
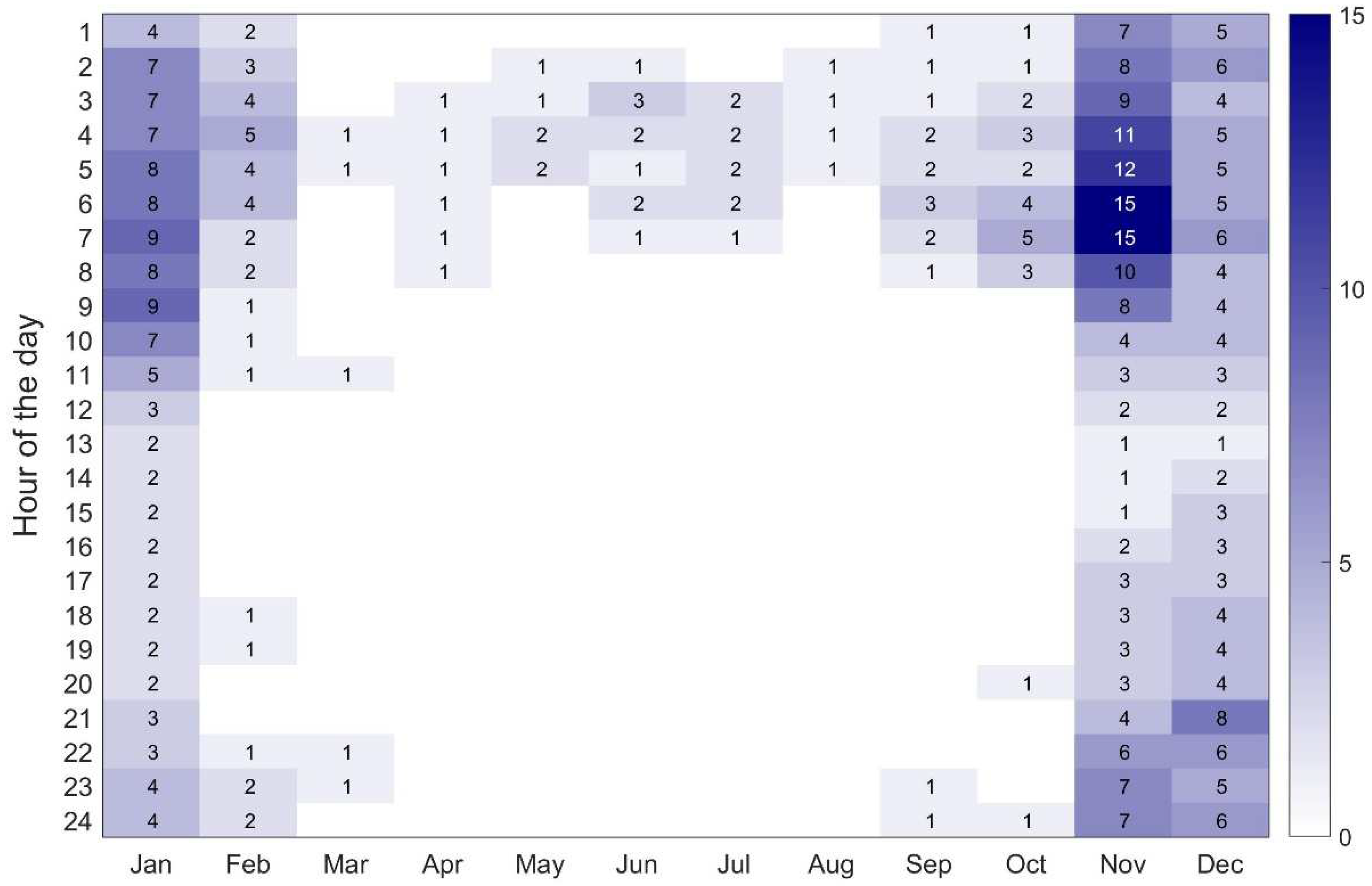
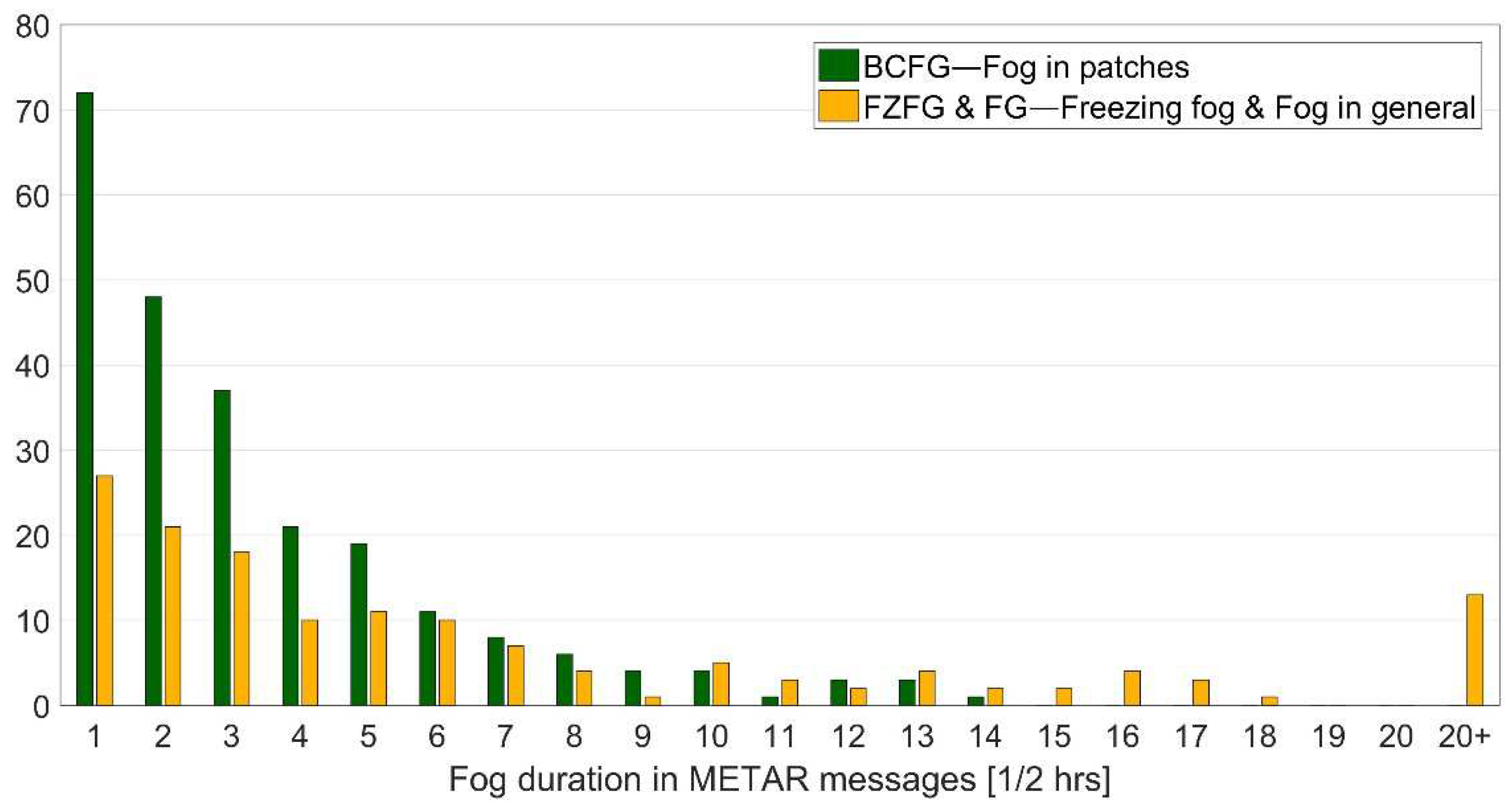
3.1. Statistical Analysis of Local Fog Patterns
- BC—fog patches randomly covering the aerodrome;
- MI—shallow fog, reaching at most 2 m (6 ft) above ground level;
- PR—partial fog, in which a substantial part of the aerodrome is covered by fog whereas the remainder is clear;
- VC—fog in the vicinity, i.e., between the radii of approx. 8 and 16 km of the aerodrome reference point.
3.2. Target Attribute Definition
- The majority of fog occurs in the cold half of the year (Figure 4); thus, fog forecasting has the right justification in this time of the year;
- The operationally significant visibility threshold for air traffic controllers and airport operators is 300 m (see ILS CAT II in Table 1; additionally, personal communication with several air traffic controllers);
- On the basis of the METAR records, the number of events in the cold half of the year with a visibility below 300 m that were caused by meteorological phenomena not related to any type of fog was negligible. The detailed analysis of these low-visibility events revealed that they were exclusively caused by heavy snow, and consequently, they were excluded from the fog occurrences.
- ‘fog’ event (fog = 1/true) = when the 10 min running average of the visibility standardly available in METAR messages is less than or equal to 300 m;
- ‘no-fog’ event (fog = 0/false) = when the 10 min running average of the visibility standardly available in METAR messages is higher than 300 m.
3.2.1. First Step of Modelling
- ws—wind speed in 10 m [m/s];
- wg—wind gust in 10 m [m/s];
- wd—wind direction in 10 m [degrees];
- at—air temperature in 2 m [°C];
- rh—relative humidity [%];
- ap—atmospheric pressure [hPa];
- ps—precipitation sum [mm/h];
- sr—solar radiation [W/m2].
- ws: [0.2 m/s; 3.0 m/s]— neither wind calm nor strong wind support fog genesis;
- wg: [0.3 m/s; 4.0 m/s]—the same reasoning as in the case of the common wind speed holds true;
- at: [−14 °C; 16 °C]—considerably low air temperatures during the winter are associated with a low relative humidity; thus, no fog genesis is expected in such cases;
- rh: [86%; 100%]— lower humidity favors no-fog;
- ap: [920 hPa; 955 hPa];
- ps: 0 mm/hr;
- sr: [0 W/m2; 300 W/m2].
- IF all the above-listed seven conditions are met, keep the dataset sample and proceed to step #2 (ML classification);
- ELSE discard the dataset sample and predict ‘no-fog’.
3.2.2. Figure Based Analysis



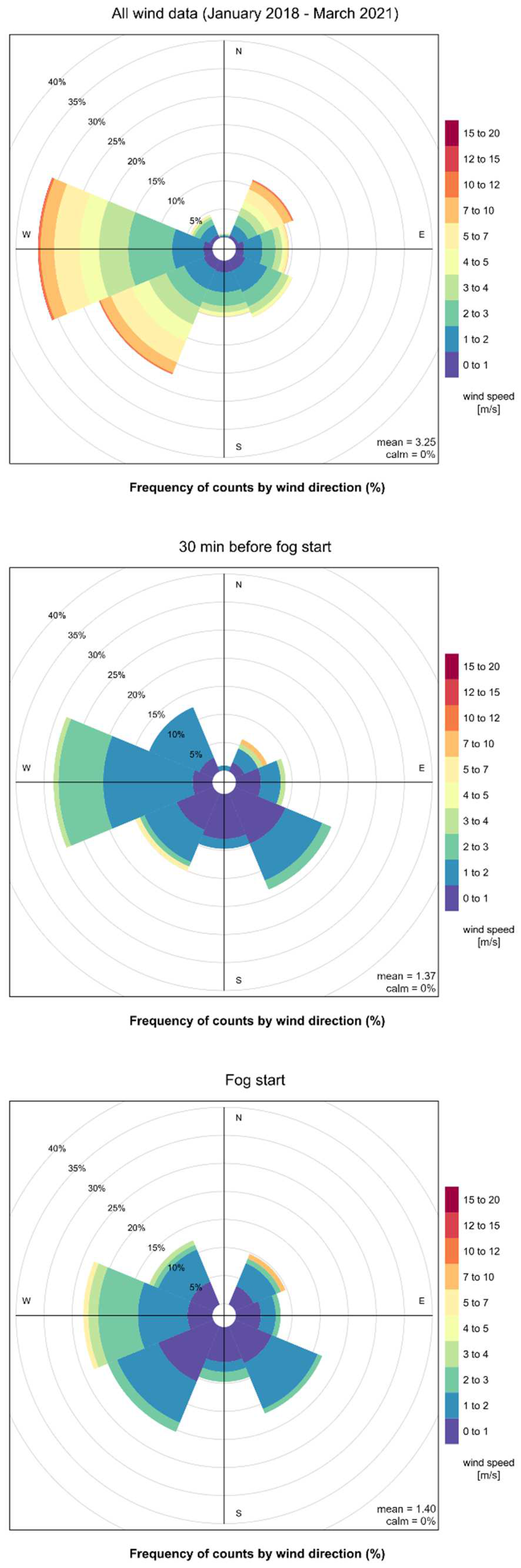
3.3. Feature Selection
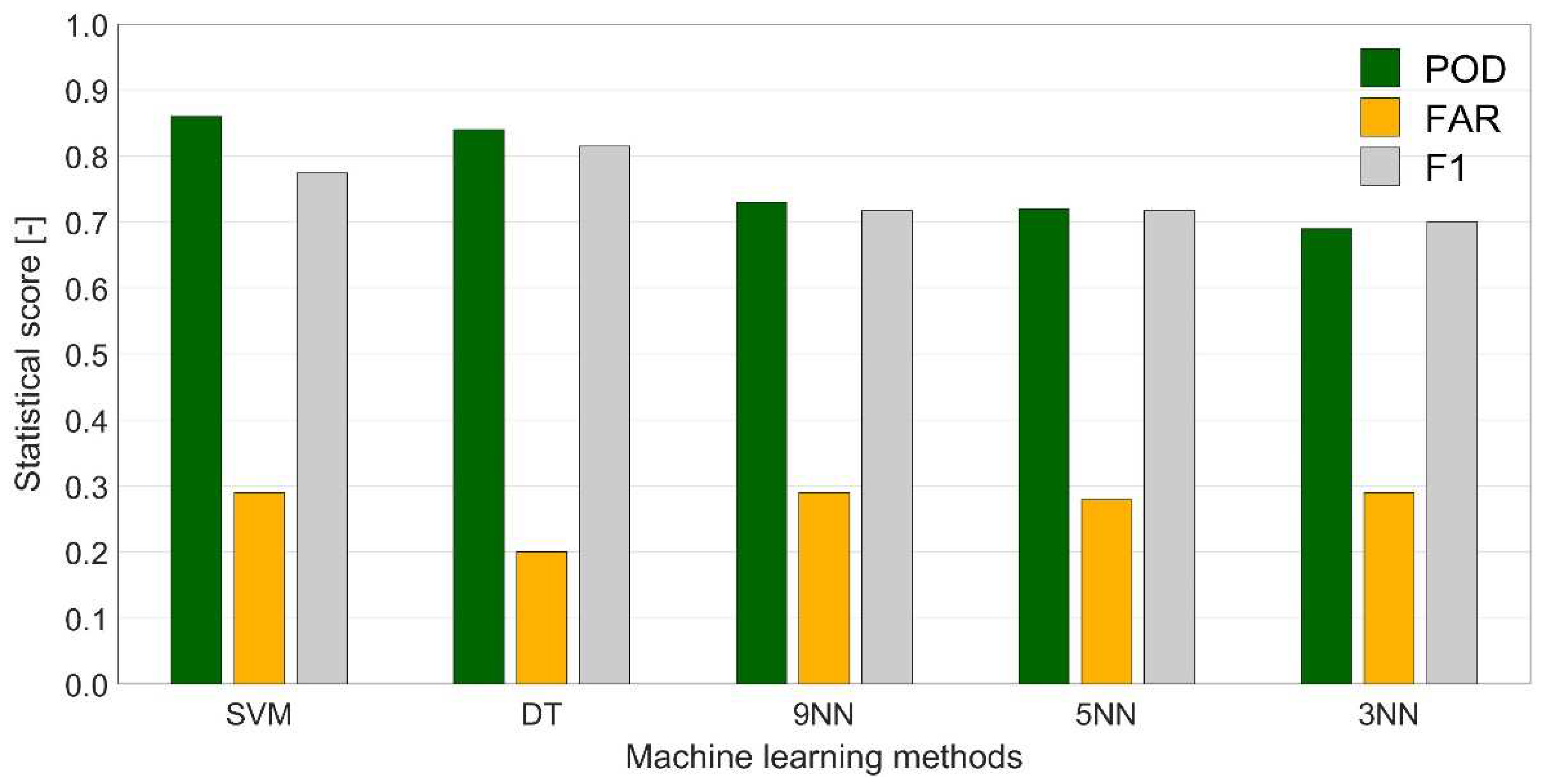
3.4. Machine Learning Performance
- the forward scatter sensor (vsFS), i.e., the visibility measured by the automated tool with a 1 min frequency (averaged through a 10 min window);
- the METAR messages (vsMM), i.e., visibility determined by professional observers with a 30 min frequency;
- the camera records (vsCR) with a 5 min frequency; more specifically, the minimum camera visibility constructed on the basis of the concurrent values from the eight cardinal directions.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Basic Relationships and Settings of the Adopted Machine Learning Methods
Appendix A.1. K-Nearest Neighbors
Appendix A.2. Support Vector Machine
Appendix A.3. Decision Trees
Appendix A.4. Parameter/Option Settings for the Machine Learning Modelling
- KNN—default values, number of neighbors varied depending on the model;
- SVM—kernel = rbfdot (Radial Basis kernel ‘Gaussian’), type = C-svc (classification), C = 5 (regularization constant), sigma = 0.05 (inverse kernel width for the Radial Basis kernel function ‘rbfdot’ and the Laplacian kernel ‘laplacedot’);
- DT—loss matrix = , method = class (decision tree).
References
- WMO—World Meteorological Organization. Manual on Codes–International Codes, Volume I.1, Annex II to the WMO Technical Regulations: Part A Alphanumeric Codes; WMO–No. 306; WMO: Geneva, Switzerland, 2011; 480p. [Google Scholar]
- Koračin, D. Modeling and Forecasting Marine Fog. In Marine Fog: Challenges and Advancements in Observations, Modeling, and Forecasting; Koračin, D., Dorman, C.E., Eds.; Springer Atmospheric Sciences: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Koračin, D.; Dorman, C.E.; Lewis, J.M.; Hudson, J.G.; Wilcox, E.M.; Torregrosa, A. Marine Fog: A Review. Atmos. Res. 2014, 143, 142–175. [Google Scholar] [CrossRef]
- Wilkinson, J.M.; Porson, A.N.F.; Bornemann, F.J.; Weeks, M.; Field, P.R.; Lock, A.P. Improved Microphysical Parametrization of Drizzle and Fog for Operational Forecasting Using the Met Office Unified Model. Q. J. R. Meteorol. Soc. 2013, 139, 488–500. [Google Scholar] [CrossRef]
- Boutle, I.A.; Finnenkoetter, A.; Lock, A.P.; Wells, H. The London Model: Forecasting Fog at 333 m Resolution. Q. J. R. Meteorol. Soc. 2016, 142, 360–371. [Google Scholar] [CrossRef]
- Ducongé, L.; Lac, C.; Vié, B.; Bergot, T.; Price, J.D. Fog in Heterogeneous Environments: The Relative Importance of Local and Non-Local Processes on Radiative-Advective Fog Formation. Q. J. R. Meteorol. Soc. 2020, 146, 2522–2546. [Google Scholar] [CrossRef]
- Smith, D.K.; Renfrew, I.A.; Dorling, S.R.; Price, J.D.; Boutle, I.A. Sub-km Scale Numerical Weather Prediction Model Simulations of Radiation Fog. Q. J. R. Meteorol. Soc. 2021, 147, 746–763. [Google Scholar] [CrossRef]
- Boutle, I.; Angevine, W.; Bao, J.-W.; Bergot, T.; Bhattacharya, R.; Bott, A.; Ducongé, L.; Forbes, R.; Goecke, T.; Grell, E.; et al. Demistify: A Large-Eddy Simulation (LES) and Single-Column Model (SCM) Intercomparison of Radiation Fog. Atmos. Chem. Phys. 2022, 22, 319–333. [Google Scholar] [CrossRef]
- Colabone, R.O.; Ferrari, A.L.; Vecchia, F.A.S.; Tech, A.R.B. Application of Artificial Neural Networks for Fog Forecast. J. Aerosp. Technol. Manag. 2015, 7, 240–246. [Google Scholar] [CrossRef]
- Durán-Rosal, A.M.; Fernández, J.C.; Casanova-Mateo, C.; Sanz-Justo, J.; Salcedo-Sanz, S.; Hervás-Martínez, C. Efficient Fog Prediction with Multi-Objective Evolutionary Neural Networks. Appl. Soft. Comput. 2018, 70, 347–358. [Google Scholar] [CrossRef]
- Cornejo-Bueno, S.; Casillas-Pérez, D.; Cornejo-Bueno, L.; Chidean, M.I.; Caamaño, A.J.; Cerro-Prada, E.; Casanova-Mateo, C.; Salcedo-Sanz, S. Statistical Analysis and Machine Learning Prediction of Fog-Caused Low-Visibility Events at A-8 Motor-Road in Spain. Atmosphere 2021, 12, 679. [Google Scholar] [CrossRef]
- Zhu, L.; Zhu, G.; Han, L.; Wang, N. The Application of Deep Learning in Airport Visibility Forecast. Atmos. Clim. Sci. 2017, 7, 314–322. [Google Scholar] [CrossRef] [Green Version]
- Bari, D.; Ouagabi, A. Machine-Learning Regression Applied to Diagnose Horizontal Visibility from Mesoscale NWP Model Forecasts. SN Appl. Sci. 2020, 2, 556. [Google Scholar] [CrossRef] [Green Version]
- Benáček, P.; Borovička, P. Application of Machine Learning in Fog Prediction in the Czech Republic. Meteorol. Bull. 2021, 74, 141–148. (In Czech) [Google Scholar]
- Dutta, D.; Chaudhuri, S. Nowcasting Visibility During Wintertime Fog Over the Airport of a Metropolis of India: Decision Tree Algorithm and Artificial Neural Network Approach. Nat. Hazards 2015, 75, 1349–1368. [Google Scholar] [CrossRef]
- Bartoková, I.; Bott, A.; Bartok, J.; Gera, M. Fog Prediction for Road Traffic Safety in a Coastal Desert Region: Improvement of Nowcasting Skills by the Machine-Learning Approach. Bound. Layer Meteorol. 2015, 157, 501–516. [Google Scholar] [CrossRef]
- Negishi, M.; Kusaka, H. Development of Statistical and Machine Learning Models to Predict the Occurrence of Radiation Fog in Japan. Meteorol. Appl. 2022, 29, e2048. [Google Scholar] [CrossRef]
- Guijo-Rubio, D.; Gutiérrez, P.A.; Casanova-Mateo, C.; Sanz-Justo, J.; Salcedo-Sanz, S.; Hervás-Martínez, C. Prediction of Low-Visibility Events Due to Fog Using Ordinal Classification. Atmos. Res. 2018, 214, 64–73. [Google Scholar] [CrossRef]
- Boneh, T.; Weymouth, G.T.; Newham, P.; Potts, R.; Bally, J.; Nicholson, A.E.; Korb, K.B. Fog Forecasting for Melbourne Airport Using a Bayesian Decision Network. Weather Forecast. 2015, 30, 1218–1233. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Pérez-Aracil, J.; Ascenso, G.; Del Ser, J.; Casillas-Pérez, D.; Kadow, C.; Fister, D.; Barriopedro, D.; García-Herrera, R.; Restelli, M.; et al. Analysis, Characterization, Prediction and Attribution of Extreme Atmospheric Events with Machine Learning: A Review. arXiv 2022, arXiv:2207.07580. [Google Scholar] [CrossRef]
- Castillo-Botón, C.; Casillas-Pérez, D.; Casanova-Mateo, C.; Ghimire, S.; Cerro-Prada, E.; Gutierrez, P.A.; Deo, R.C.; Salcedo-Sanz, S. Machine Learning Regression and Classification Methods for Fog Events Prediction. Atmos. Res. 2022, 272, 106157. [Google Scholar] [CrossRef]
- Bartok, J.; Bott, A.; Gera, M. Fog Prediction for Road Traffic Safety in a Coastal Desert Region. Bound. Layer Meteorol. 2012, 145, 485–506. [Google Scholar] [CrossRef]
- Bott, A.; Trautmann, T. PAFOG—A New Efficient Forecast Model of Radiation Fog and Low-Level Stratiform Clouds. Atmos. Res. 2002, 64, 191–203. [Google Scholar] [CrossRef]
- Skamarock, W.C.; Klemp, J.B.; Dudhia, J.; Gill, D.O.; Barker, D.; Duda, M.G.; Huang, X.; Wang, W.; Powers, J.G. A Description of the Advanced Research WRF Version 3; (No. NCAR/TN-475+STR); University Corporation for Atmospheric Research: Boulder, CO, USA, 2008; 125p, NCAR Technical Notes 475. [Google Scholar] [CrossRef]
- SESAR Joint Undertaking. Available online: https://sesarju.eu/ (accessed on 22 August 2022).
- MET Performance Management. Available online: https://sesarju.eu/sesar-solutions/met-performance-management (accessed on 22 August 2022).
- Remote Tower. Available online: https://www.remote-tower.eu/ (accessed on 22 August 2022).
- Solution PJ.05-05 ‘Advanced Automated MET System’: TRL4 Data Pack. Available online: https://www.remote-tower.eu/wp/wp-content/uploads/2022/02/PJ05-05_TRL4_Data_Pack.zip (accessed on 22 August 2022).
- NATS–National Air Traffic Services. Available online: https://www.nats.aero/ (accessed on 26 August 2022).
- ICAO–International Civil Aviation Organization. Annex 6 to the Convention on International Civil Aviation—Operation of Aircraft. Part I—International Commercial Air Transport—Aeroplanes, 12th ed.; ICAO: Montreal, QC, Canada, 2022. [Google Scholar]
- Slovak Hydrometeorological Institute. Climate Atlas of Slovakia; Slovak Hydrometeorological Institute: Bratislava, Slovakia, 2015; 132p. [Google Scholar]
- Bartok, J.; Ivica, L.; Gaál, L.; Bartoková, I.; Kelemen, M. A Novel Camera-Based Approach to Increase the Quality, Objectivity and Efficiency of Aeronautical Meteorological Observations. Appl. Sci. 2022, 12, 2925. [Google Scholar] [CrossRef]
- ICAO–International Civil Aviation Organization. Meteorological Service for International Air Navigation. In Annex 3 to the Convention on International Civil Aviation, 17th ed.; ICAO: Montreal, QC, Canada, 2010. [Google Scholar]
- Grosan, C.; Abraham, A. Intelligent Systems: A Modern Approach; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw Hill: New York, NY, USA, 1997; 432p. [Google Scholar]
- Zeyad, M.; Hossain, M.S. A Comparative Analysis of Data Mining Methods for Weather Prediction. In Proceedings of the International Conference on Computational Performance Evaluation (ComPE), Online, 1–3 December 2021; pp. 167–172. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Barua, S.; Islam, M.M.; Yao, X.; Murase, K. MWMOTE—Majority Weighted Minority Oversampling Technique for Imbalanced Dataset Learning. IEEE T. Knowl. Data En. 2014, 26, 405–425. [Google Scholar] [CrossRef]
- Ting, K.M. A Comparative Study of Cost-Sensitive Boosting Algorithms. In Proceedings of the 17th International Conference on Machine Learning, Stanford University, Stanford, CA, USA, 29 June–2 July 2000; pp. 983–990. [Google Scholar]
- Jiang, L.; Li, C.; Wang, S. Cost-Sensitive Bayesian Network Classifiers. Pattern Recogn. Lett. 2014, 45, 211–216. [Google Scholar] [CrossRef]
- Goldstein, M.; Uchida, S. A Comparative Evaluation of Unsupervised Anomaly Detection Algorithms for Multivariate Data. PLoS ONE 2016, 11, e0152173. [Google Scholar] [CrossRef] [Green Version]
- Fix, E.; Hodges, J.L. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties. Int. Stat. Rev. 1951, 57, 238–247. [Google Scholar] [CrossRef]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Jolliffe, I.T.; Cadima, J. Principal Component Analysis: A Review and Recent Developments. Phil. Trans. R. Soc. A 2016, 374, 2015020220150202. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Data Mining with Decision Trees: Theory and Applications, 2nd ed.; World Scientific Pub Co., Inc.: Singapore, 2014. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap Methods: Another Look at the Jackknife. Ann. Statist. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Marzban, C. Scalar Measures of Performance in Rare-Event Situations. Weather Forecast. 1998, 13, 753–763. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences, 3rd ed.; Academic Press: New York, NY, USA, 2011; 676p. [Google Scholar]
- Michalovič, A.; Jarošová, M. Comparison of fog Occurrence at Slovak International Airports for the Period 1998-2018. In Studies of the Air Transport; Department of the University of Žilina: Žilina, Slovakia, 2021; Volume 10, pp. 159–162. [Google Scholar] [CrossRef]
- Vorndran, M.; Schütz, A.; Bendix, J.; Thies, B. Current Training and Validation Weaknesses in Classification-Based Radiation Fog Nowcast Using Machine Learning Algorithms. Artif. Intell. Earth Syst. 2022, 1, e210006. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Smola, A.; Hornik, K. Kernlab: Kernel-Based Machine Learning Lab. R Package Version 0.9-31. 2022. Available online: https://CRAN.R-project.org/package=kernlab (accessed on 20 August 2022).
- Therneau, T.; Atkinson, B.; Ripley, B. Rpart: Recursive Partitioning. R Package Version 4.1-3. 2013. Available online: http://CRAN.R-project.org/package=rpart (accessed on 20 August 2022).
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S., 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Lakshmanan, V.; Elmore, K.L.; Richman, M.B. Reaching Scientific Consensus Through a Competition. Bull. Am. Meteorol. Soci. 2010, 91, 1423–1427. [Google Scholar] [CrossRef]
- Quinlan, J. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Minimum Visibility [m] | Height of the Lowest Cloud Base > 4 Octas [ft] |
|---|---|---|
| VFR | 5000 | 1500 |
| ILS CAT I | RVR ≥ 550 | DH ≥ 200 |
| ILS CAT II | RVR ≥ 300 | DH ≥ 100 |
| ILS CAT III | RVR ≥ 200 | DH < 100/no DH |
| Distance Interval [m] | Number of Markers |
|---|---|
| 0–300 | 35 |
| 300–600 | 21 |
| 600–1500 | 26 |
| 1500–5000 | 30 |
| >5000 | 41 |
| Total | 153 |
| Rank | Fog Type— Code | Fog Type— Short Explanation | Annual Frequency of Occurrence |
|---|---|---|---|
| 1 | BCFG | fog in patches | 225.5 |
| 2 | FZFG | freezing fog | 221.2 |
| 3 | FG | fog with no further specification | 112.6 |
| 4 | MIFG | shallow fog | 36.0 |
| 5 | PRFG | partial fog | 33.5 |
| 6 | VCFG | fog in the vicinity | 24.6 |
| 7 | BR BCFG | mist and fog in patches | 13.2 |
| No-Fog | Fog | |||||||
|---|---|---|---|---|---|---|---|---|
| Variable | Min | q2.5% | q97.5% | Max | Min | q2.5% | q97.5% | Max |
| ws [m/s] | 0.1 | 0.6 | 8.9 | 19.9 | 0.2 | 0.4 | 2.2 | 5.6 |
| wg [m/s] | 0.1 | 0.9 | 11.2 | 24.1 | 0.3 | 0.5 | 2.8 | 8.4 |
| at [°C] | −22.8 | −9.7 | 14.0 | 33.2 | −14.4 | −10.8 | 12.9 | 15.9 |
| rh [%] | 10 | 36 | 97 | 99 | 86 | 90 | 99 | 99 |
| ap [hPa] | 906.4 | 919.6 | 948.7 | 962.0 | 921.7 | 923.4 | 948.9 | 953.0 |
| ps [mm/hr] | 0 | 0 | 0 | 1.5 | 0 | 0 | 0 | 0 |
| sr [W/m2] | 0 | 0 | 824 | 1392 | 0 | 0 | 158 | 296 |
| Variant | Predictors | POD | FAR | F1 | GSS | TSS | FgIni | FgEnd |
|---|---|---|---|---|---|---|---|---|
| SVM #1 | ws, wd, at, rh, ap, ps, vsFS | 0.86 | 0.28 | 0.78 | 0.50 | 0.70 | 0.39 | 0.13 |
| SVM #2 | ws, wd, at, rh, ap, ps, vsMM | 0.86 | 0.29 | 0.78 | 0.49 | 0.70 | 0.43 | 0.16 |
| SVM #3 | ws, wd, at, rh, ap, ps, vsCR-D10 | 0.85 | 0.30 | 0.77 | 0.48 | 0.69 | 0.50 | 0.25 |
| Variant | Predictors | POD | FAR | F1 | GSS | TSS | FgIni | FgEnd |
|---|---|---|---|---|---|---|---|---|
| DT #1 | ws, wd, at, rh, ap, ps, vsFS | 0.89 | 0.23 | 0.83 | 0.57 | 0.75 | 0.36 | 0.09 |
| DT #2 | ws, wd, at, rh, ap, ps, vsFS-D05 | 0.87 | 0.23 | 0.81 | 0.55 | 0.73 | 0.32 | 0.08 |
| DT #3 | ws, wd, at, rh, ap, ps, vsCR-D10 | 0.84 | 0.22 | 0.81 | 0.54 | 0.71 | 0.40 | 0.40 |
| Fog Prediction Model | POD | FAR | F1 |
|---|---|---|---|
| fog climatology | 0.35 | 0.50 | 0.41 |
| TREND nowcast | 0.68 | 0.31 | 0.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bartok, J.; Šišan, P.; Ivica, L.; Bartoková, I.; Malkin Ondík, I.; Gaál, L. Machine Learning-Based Fog Nowcasting for Aviation with the Aid of Camera Observations. Atmosphere 2022, 13, 1684. https://doi.org/10.3390/atmos13101684
Bartok J, Šišan P, Ivica L, Bartoková I, Malkin Ondík I, Gaál L. Machine Learning-Based Fog Nowcasting for Aviation with the Aid of Camera Observations. Atmosphere. 2022; 13(10):1684. https://doi.org/10.3390/atmos13101684
Chicago/Turabian StyleBartok, Juraj, Peter Šišan, Lukáš Ivica, Ivana Bartoková, Irina Malkin Ondík, and Ladislav Gaál. 2022. "Machine Learning-Based Fog Nowcasting for Aviation with the Aid of Camera Observations" Atmosphere 13, no. 10: 1684. https://doi.org/10.3390/atmos13101684
APA StyleBartok, J., Šišan, P., Ivica, L., Bartoková, I., Malkin Ondík, I., & Gaál, L. (2022). Machine Learning-Based Fog Nowcasting for Aviation with the Aid of Camera Observations. Atmosphere, 13(10), 1684. https://doi.org/10.3390/atmos13101684