
Flooded Extent and Depth Analysis Using Optical and SAR Remote Sensing with Machine Learning Algorithms

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
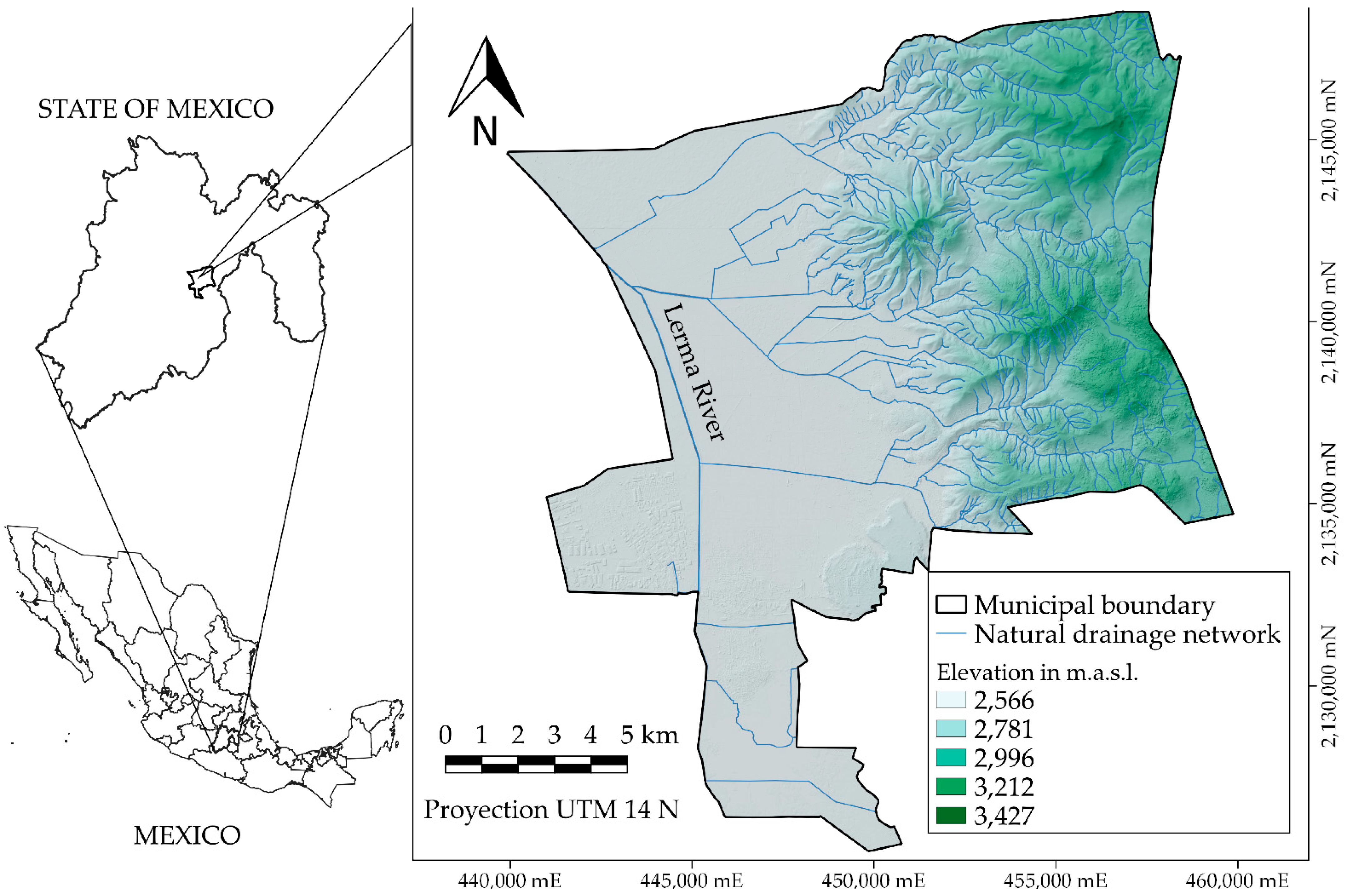
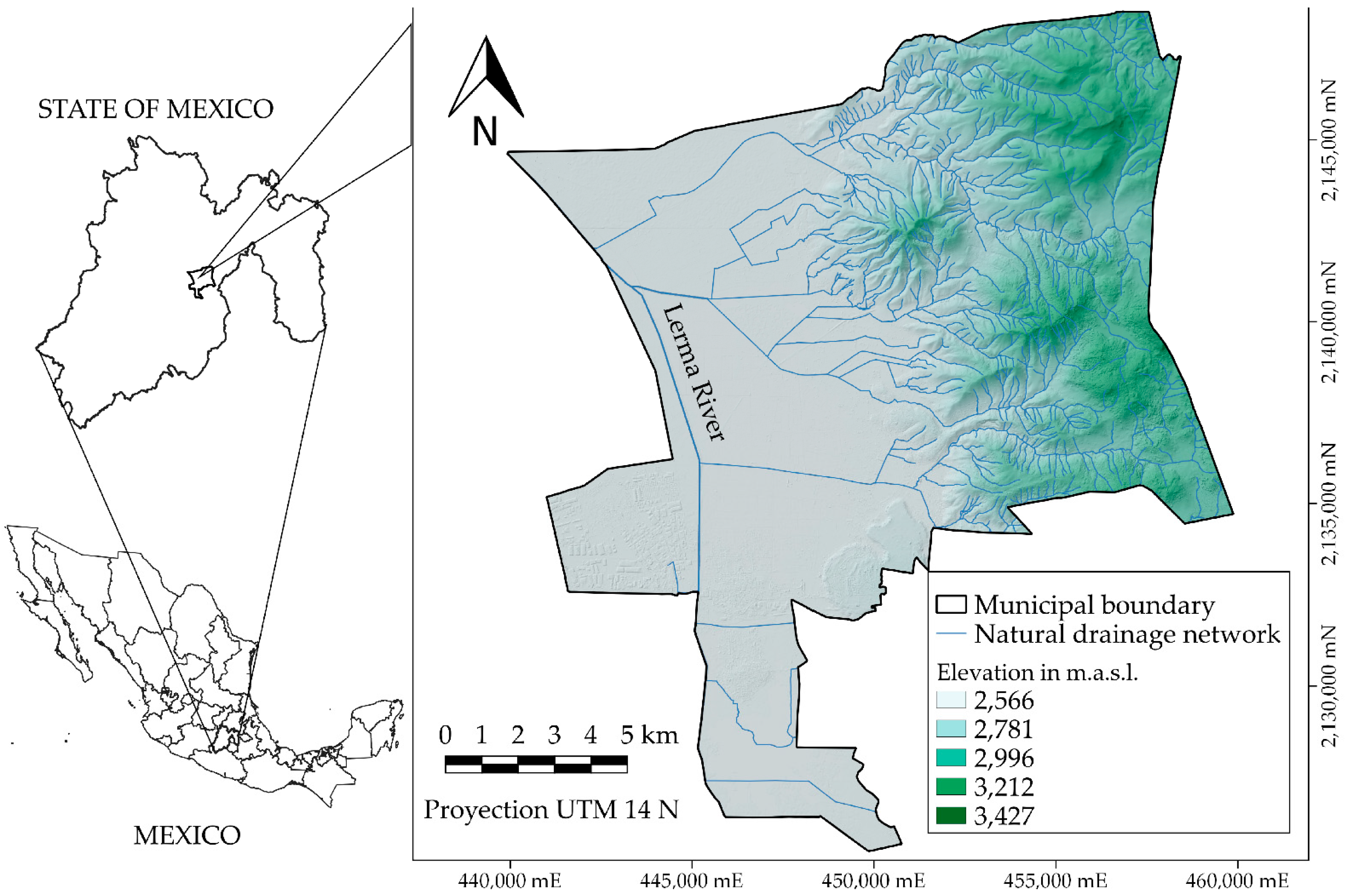
2.1. Study Area
2.2. Rainfall Data Analysis
2.3. Satellite Images Used
2.4. Software and Computing Requirements
2.5. Sample Selection and Resampling
- (a)
- In Phase 1, the coordinates (x, y) of a set of pixels representing the two target classes were obtained. This procedure was performed on a subset of the image of variable size to select pixels with greater detail. For this, three methods were used: (1) growth by region [36,37], (2) manual definition of the threshold, and (3) use of the entire subset. The method for manually defining the threshold and using the entire subset consisted of defining a threshold for binary segmentation based on analysis of the histogram of the subset and the graphic display. This procedure starts with the transformation of the input image to a single band. In the case of Sentinel-1 (SAR), only one polarization is used. Next, the histogram of the scene is calculated [7]. In the case of Sentinel-2, a limit value is defined that allows the separation of water bodies and that also allows a pixel-by-pixel validation on the RGB composite image. Before exporting the coordinates of the sampling pixels, the intra- and inter-class duplicates database was purged, based on the value of the RGB false-color pixels for the “non-water” class and backscatter (VV) values for the “water” class.
- (b)
- In Phase 2, the database of phase 1 was updated, and using the geographic coordinates, the pixel values were recovered for the following input combinations: RGB and HSV composite of Sentinel-2, Sentinel-1 VV, and VH polarization, and DEM and indices to detect bodies of water (Table 2). Bands 4, 3, and 2 of the Sentinel-2 image were assigned to generate the RGB composite. The HSV model represents color of three components: Hue (H), Saturation (S), and Value (V). In uniform spaces, the color difference (Euclidean distance) is proportional to the human perception of that difference. In this sense, RGB is not uniform [38]. The conversion from RGB to HSV was obtained from the OpenCV library, using the cvtColor function in Python-3.
2.6. Machine Learning Algorithms Used
2.6.1. Gradient Boosting
2.6.2. Random Forest
2.7. The Training Algorithms
- (a)
- For Gradient Boosting (GB):
- ➢
- Loss function to be optimized (log_loss, binomial and multinomial deviation).
- ➢
- Learning rate (learning_rate = 0.1).
- ➢
- Number of estimators (n_estimators = 100).
- ➢
- Criterion to measure the quality of the branches (‘friedman_mse’, for the mean squared error with improvement score by Friedman).
- ➢
- Minimum samples for each internal node split (min_samples_split = 2).
- ➢
- Minimum number of samples to define a leaf (min_samples_leaf = 1).
- ➢
- Maximum depth (max_depth = 3).
- ➢
- Randomization seed (random_state = 1).
- ➢
- Maximum features (None, set equal to the number of features or attributes available).
- (b)
- For Random Forest (RF):
- ➢
- Number of trees that make up the forest (n_estimators = 100).
- ➢
- Function or criterion to measure the quality of the ramifications (gini index).
- ➢
- Maximum depth (None).
- ➢
- Minimum samples for each internal node split (min_samples_split = 2).
- ➢
- Minimum samples to define a leaf (min_samples_leaf = 1).
- ➢
- Maximum features or attributes (max_features = “sqrt”), square root of the number of features.
- ➢
- Randomization seed (random_state = 1).
2.7.1. Training Algorithms of Machine Learning Models for Flood Prediction
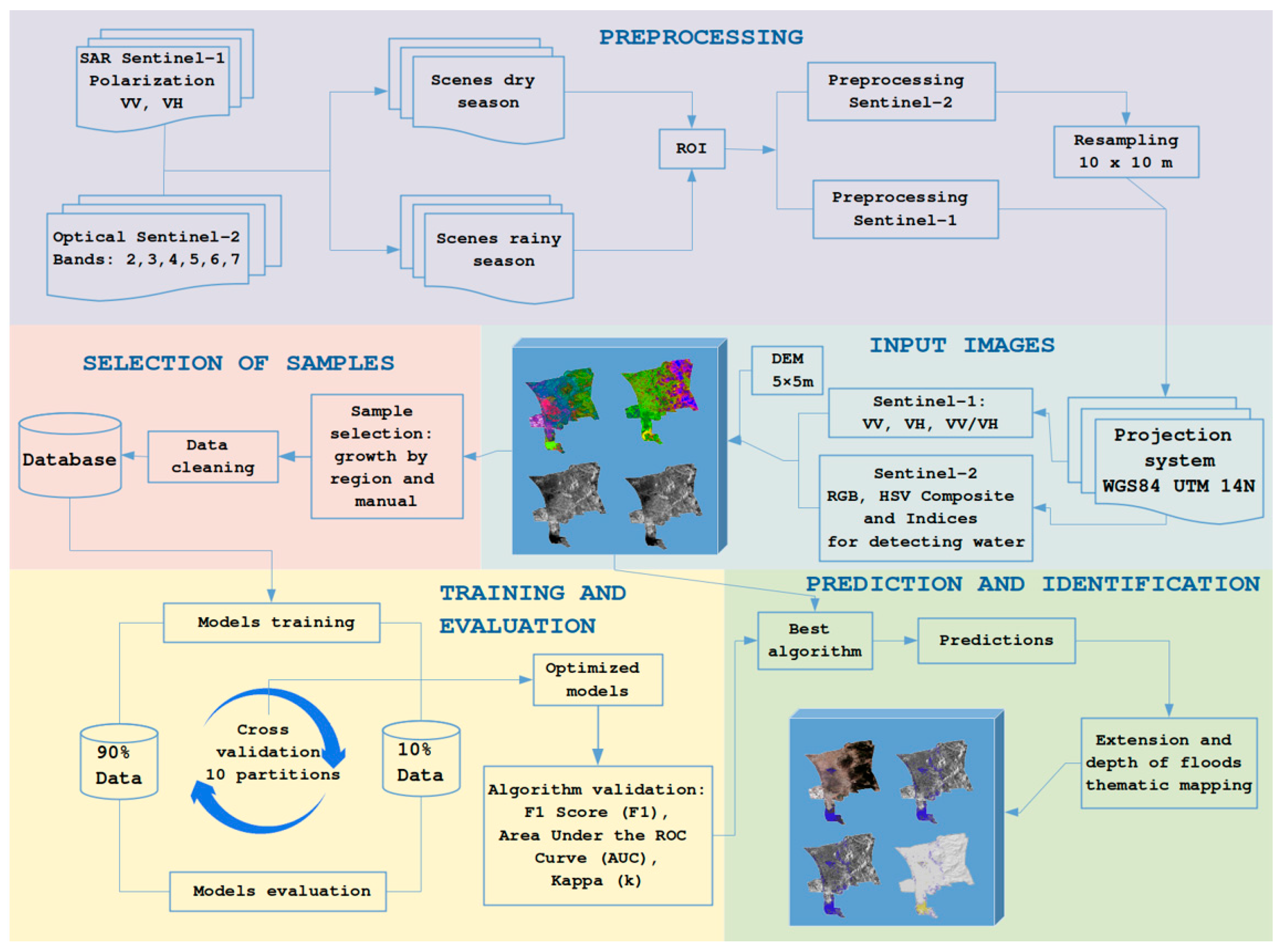
2.8. Workflow
2.9. Input Combinations for Algorithm Training
2.10. Flood Extent
2.11. Depth of Flooding
3. Results
3.1. Rainfall Record during 2021
3.2. Samples Selected for Algorithm Training
3.3. Evaluation of Algorithms to Determine Flooded Areas
3.3.1. Results for Gradient Boosting Algorithm
3.3.2. Results for Random Forest Algorithm
3.4. The Best Combinations for Determining Flooding According to Season and Algorithm
3.4.1. Dry Season
3.4.2. Rainy Season
3.5. Extent of Flooding According to Season
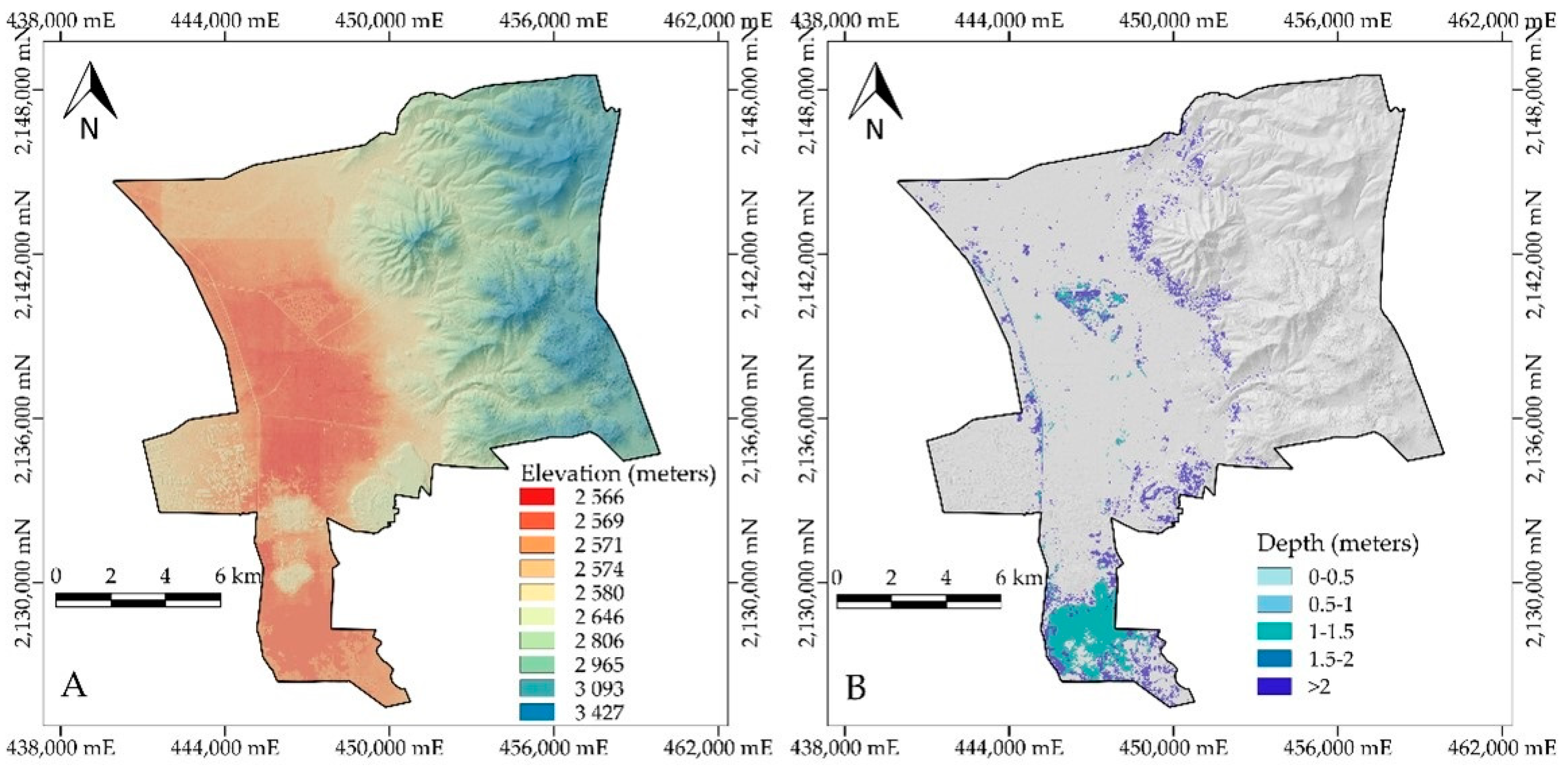
3.6. Depth of Flooded Areas
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- IPCC. Summary for Policymakers. In Climate Change 2021: The Physical Science Basis, Contribution of Working Group to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Masson-Delmotte, V., Zhai, P., Pirani, A., Connors, S.L., Péan, C., Berger, S., Caud, N., Chen, Y., Goldfarb, L., Gomis, M.I., et al., Eds.; IPCC: Geneva, Switzerland; Cambridge University: Cambridge, UK, 2021; pp. 1–40. [Google Scholar]
- NSTC. Science and Technology to Support Fresh Water Availability in the United States; National Science and Technology Council: Washington, DC, USA, 2004; pp. 1–19.
- Futrell, J.H.; Gephart, R.E.; Kabat, E.; McKnight, D.M.; Pyrtle, A.; Schimel, J.P.; Smyth, R.L.; Skole, D.L.; Wilson, J.L. Water: Challenges at the intersection of human and natural systems. NSF/DOE Tech. Rep. 2005, PNWD-3597, 1–50. [Google Scholar] [CrossRef] [Green Version]
- NRC. When Weather Matters: Science and Service to Meet Critical Societal Needs; National Academies Press: Washington, DC, USA, 2010; pp. 1–198. [Google Scholar]
- Hao, C.; Yunus, A.P.; Silva-Subramanian, S.; Avtar, R. Basin-wide flood depth and exposure mapping from SAR images and machine learning models. J. Environ. Manag. 2021, 297, 113367. [Google Scholar] [CrossRef] [PubMed]
- Soria-Ruíz, J.; Fernández-Ordoñez, Y.M.; Chapman, B. Radarsat-2 and Sentinel-1 SAR to detect and monitoring flooding areas in Tabasco, México. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 1323–1326. [Google Scholar]
- Carreño-Conde, F.; De Mata-Muñoz, M. Flood monitoring based on the study of Sentinel-1 SAR images: The Ebro river case study. Water 2019, 11, 2454. [Google Scholar] [CrossRef] [Green Version]
- Schlaer, S.; Matgen, P.; Hollaus, M.; Wagner, W. Flood detection from multi-temporal SAR data using harmonic analysis and change detection. Int. J. Appl. Earth Obs. Geoinf. 2015, 38, 15–24. [Google Scholar] [CrossRef]
- Pulvirenti, L.; Chini, M.; Pierdicca, N.; Guerriero, L.; Ferrazzoli, P. Flood monitoring using multi-temporal COSMO-SkyMed data: Image segmentation and signature interpretation. Remote Sens. Environ. 2011, 115, 990–1002. [Google Scholar] [CrossRef]
- Refice, A.; Zingaro, M.; D’Addabbo, A.; Chini, M. Integrating C- and L-band SAR imagery for detailed flood monitoring of remote vegetated areas. Water 2020, 12, 2745. [Google Scholar] [CrossRef]
- Konapala, G.; Kumar, S.V.; Khalique-Ahmad, S. Exploring Sentinel-1 and Sentinel-2 diversity for flood inundation mapping using deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 180, 163–173. [Google Scholar] [CrossRef]
- Rahman, M.R.; Thakur, P.K. Detecting, mapping and analysing of flood water propagation using synthetic aperture radar (SAR) satellite data and GIS: A case study from the Kendrapara District of Orissa State of India. Egypt. J. Remote Sens. Space Sci. 2017, 21, S37–S41. [Google Scholar] [CrossRef]
- Xu, Y.; Xiao-Chun, Z.; Xiu-Gui, W.; Yu, Z. Flood disaster monitoring based on Sentinel-1 data: A case study of Sihu Basin and Huaibei Plain, China. Water Sci. Eng. 2021, 14, 87–96. [Google Scholar] [CrossRef]
- Cai, Y.; Li, X.; Zhang, M.; Lin, H. Mapping wetland using the object-based stacked generalization method based on multi-temporal optical and SAR data. Int. J. Appl. Earth Obs. Geoinf. 2020, 92, 102164. [Google Scholar] [CrossRef]
- Atirah, N.; Fikri, A.; Khairunniza, S.; Razif, M.; Mijic, A. The use of LiDAR-Derived DEM in flood applications: A review. Remote Sens. 2020, 12, 2308. [Google Scholar] [CrossRef]
- Munawar, H.S.; Hammad, A.W.A.; Waller, S.T. Remote sensing methods for flood prediction: A review. Sensors 2022, 22, 960. [Google Scholar] [CrossRef] [PubMed]
- Polat, N.; Uysal, M.; Toprak, A.S. An investigation of DEM generation process based on LiDAR data filtering, decimation, and interpolation methods for an urban area. Measurement 2015, 75, 50–56. [Google Scholar] [CrossRef]
- Avand, M.; Kuriqi, A.; Khazaei, M.; Ghorbanzadeh, O. DEM resolution effects on machine learning performance for flood probability mapping. J. Hydro-Environ. Res. 2022, 40, 1–16. [Google Scholar] [CrossRef]
- Cohen, S.; Raney, A.; Munasinghe, D.; Derek-Loftis, J.; Molthan, A.; Bell, J.; Rogers, L.; Galantowicz, J.; Robert-Brakenridge, G.; Kettner, A.J.; et al. The Floodwater Depth Estimation Tool (FwDET v2.0) for improved remote sensing analysis of coastal flooding. Nat. Hazards Earth Syst. Sci. 2019, 19, 2053–2065. [Google Scholar] [CrossRef] [Green Version]
- Xie, Q.; Wang, J.; Lopez-Sanchez, J.M.; Peng, X.; Liao, C.; Shang, J.; Zhu, J.; Fu, H.; Ballester-Berman, J.D. Crop height estimation of corn from multi-year Radarsat-2 polarimetric observables using machine learning. Remote Sens. 2021, 13, 392. [Google Scholar] [CrossRef]
- Liang, J.; Liu, D. A local thresholding approach to flood water delineation using Sentinel-1 SAR imagery. ISPRS J. Photogramm. Remote Sens. 2019, 159, 53–62. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ghaderi, K.; Omidvar, E.; Al-Ansari, N.; Clague, J.; Geertsema, M.; Khosravi, K.; Amini, A.; Bahrami, S. Flood detection and susceptibility mapping using Sentinel-1 remote sensing data and a Machine Learning approach: Hybrid intelligence of bagging ensemble based on K-Nearest Neighbor classifier. Remote Sens. 2020, 12, 266. [Google Scholar] [CrossRef] [Green Version]
- Hasanuzzaman, M.; Islam, A.; Bera, B.; Kumar Shit, P. A comparison of performance measures of three machine learning algorithms for flood susceptibility mapping of river Silabati (tropical river, India). Phys. Chem. Earth 2022, 127, 103198. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B. Modeling flood susceptibility using data-driven approaches of Naïve Bayes Tree, alternating Decision Tree, and Random Forest methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Arreguín-Cortés, F.G.; Rubio-Gutiérrez, H. Análisis de las inundaciones en la planicie tabasqueña en el periodo 1995–2010. Tecnol. Cienc. Agua 2014, 5, 3. [Google Scholar]
- Perevochtchikova, M.; Lezama de la Torre, J.L. Causas de un desastre: Inundaciones del 2007 en Tabasco, México. J. Lat. Am. Geogr. 2010, 9, 73–98. [Google Scholar] [CrossRef]
- Fernández-Ordoñez, Y.M.; Soria-Ruiz, J.; Leblon, B.; Macedo-Cruz, A.; Ramírez-Guzmán, M.E.; Escalona-Maurice, M. Imágenes de radar para estudios territoriales, caso: Inundaciones en Tabasco con el uso de imágenes SAR Sentinel-1A y Radarsat-2. Rev. Int. Estad. Geogr. 2020, 11, 4–21. [Google Scholar]
- López-Caloca, A.A.; Tapia-Silva, F.O.; López, F.; Pilar, H.; Ramírez-González, A.O.; Rivera, G. Analyzing short term spatial and temporal dynamics of water presence at a basin-scale in Mexico using SAR data. GISci. Remote Sens. 2020, 57, 985–1004. [Google Scholar] [CrossRef]
- López-Caloca, A.A.; Valdiviezo-Navarro, J.C.; Tapia-Silva, F.O. Tracking short-term seasonally flooded areas to understand the dynamics of the Coatzacoalcos river in Veracruz, Mexico. J. Appl. Remote Sens. 2021, 15, 4. [Google Scholar] [CrossRef]
- Amani, M.; Brisco, B.; Mahdavi, S.; Ghorbanian, A.; Moghimi, A.; DeLancey, E.R.; Merchant, M.; Jahncke, R.; Fedorchuk, L.; Mui, A.; et al. Evaluation of the Landsat-Based Canadian wetland inventory map using multiple sources: Challenges of large-scale wetland classification using remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 32–52. [Google Scholar] [CrossRef]
- Servicio Meteorológico Nacional (SMN). Resúmenes Mensuales de Temperaturas y Lluvia. Available online: https://smn.conagua.gob.mx/es/climatologia/temperaturas-y-lluvias/resumenes-mensuales-de-temperaturas-y-lluvias (accessed on 5 October 2021).
- European Spatial Agency (ESA); Scientific Exploitation of Operational Missions (SEOM). Sentinel Application Platform (SNAP 7.0). 2021. Available online: http://step.esa.int/main/download/snap-download/ (accessed on 5 August 2021).
- Tarpanelli, A.; Mondini, A.; Camici, S. Effectiveness of Sentinel-1 and Sentinel-2 for flood detection assessment in Europe. Nat. Hazards Earth Syst. Sci. 2022, 22, 2473–2489. [Google Scholar] [CrossRef]
- Congedo, L. Semi-Automatic Classification Plugin: A Python tool for the download and processing of remote sensing images in QGIS. J. Open Source Softw. 2021, 6, 3172. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mehnert, A.; Jackway, P. An improved seeded region growing algorithm. Pattern Recognit. Lett. 1997, 18, 1065–1071. [Google Scholar] [CrossRef]
- Li, W.; Du, Y.; Li, H.; Wang, X.; Zhu, J. Decision tree algorithm based on regional growth. Proc. Sci. 2015, 6, 1–7. [Google Scholar]
- Chernov, V.; Alander, J.; Bochko, V. Integer-based accurate conversion between RGB and HSV color spaces. Comput. Electr. Eng. 2015, 46, 328–337. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 14, 3025–3033. [Google Scholar] [CrossRef]
- Rogers, A.S.; Kearney, M.S. Reducing signature variability in unmixing coastal marsh thematic mapper scenes using spectral indices. Int. J. Remote Sens. 2004, 25, 2317–2335. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the normalized difference water index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated water extraction index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Oxfordshire, UK, 1984; 368p. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Swamynathan, M. Mastering Machine Learning with Python in Six Steps; Apress: New York, NY, USA, 2017; pp. 1–374. [Google Scholar] [CrossRef]
- Friedman, J. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Si, M.; Du, K. Development of a predictive emissions model using a gradient boosting machine learning method. Environ. Technol. Innov. 2020, 20, 101028. [Google Scholar] [CrossRef]
- Tangirala, S. Evaluating the impact of GINI index and information gain on classification using decision tree classifier algorithm. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 612–619. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Gini, C. Variability and Mutability. In Memorie Di Metodologica Statistica; Pizetti, E., Salvemini, T., Eds.; Libreria Eredi Virgilio Veschi: Rome, Italy, 1912. [Google Scholar]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning; Department of Statistics, University of Wisconsin–Madison: Madison, WI, USA, 2018; pp. 1–49. [Google Scholar]
- Raschka, S.; Mirjalili, V. Python Machine Learning, 2nd ed.; Packt Publishing Ltd.: Birmingham, UK, 2017; pp. 1–850. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Congalton, R.G. A Review of assessing the accuracy of classifications of remotely rensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Clerici, N.; Valbuena-Calderón, C.A.; Posada, J.M. Fusion of Sentinel-1A and Sentinel-2A data for land cover mapping: A case study in the lower Magdalena region, Colombia. J. Maps 2017, 13, 718–726. [Google Scholar] [CrossRef] [Green Version]
- Gašparovic, M.; Klobucar, D. Mapping floods in lowland forest using Sentinel-1 and Sentinel-2 data and an object-based approach. Forests 2021, 12, 553. [Google Scholar] [CrossRef]
- Congedo, L. Tutorial 2. Available online: https://semiautomaticclassificationmanual-v5.readthedocs.io/es/latest/tutorial_2.html (accessed on 5 October 2021).
- Baillarin, S.J.; Meygret, A.; Dechoz, C.; Petrucci, B.; Lacherade, S.; Tremas, T.; Isola, C.; Martimort, P.; Spoto, F. Sentinel-2 level 1 products and image processing performances. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 197–202. [Google Scholar]
- Congedo, L. Breve Introducción a la Teledetección. Available online: https://semiautomaticclassificationmanual-v5.readthedocs.io/es/latest/remote_sensing.html#image-conversion-to-reflectance (accessed on 5 October 2021).
- MathWorks. Cvpartition. Available online: https://la.mathworks.com/help/stats/cvpartition.html (accessed on 5 October 2021).
- Instituto Nacional de Estadística y Geografía (INEGI). Mapas. Available online: https://www.inegi.org.mx/app/mapas/?tg=1015 (accessed on 5 September 2021).
- Comisión Nacional Para el Conocimiento y Uso de la Biodiversidad (CONABIO). Portal de Geoinformación. 2021. Available online: http://www.conabio.gob.mx/informacion/gis/ (accessed on 5 September 2021).
- Yang, Y.; Liu, Y.; Zhou, M.; Zhang, S.; Zhan, W.; Sun, C.; Duan, Y. Landsat 8 OLI image based terrestrial water extraction from heterogeneous backgrounds using a reflectance homogenization approach. Remote Sens. Environ. 2015, 171, 14–32. [Google Scholar] [CrossRef]
- Huang, M.; Jin, S. Rapid flood mapping and evaluation with a supervised classifier and change detection in Shouguang using Sentinel-1 SAR and Sentinel-2 optical data. Remote Sens. 2020, 12, 2073. [Google Scholar] [CrossRef]
- Bioresita, F.; Puissant, A.; Stumpf, A.; Malet, J.P. Fusion of Sentinel-1 and Sentinel-2 image time series for permanent and temporary surface water mapping. Int. J. Remote Sens. 2019, 40, 9026–9049. [Google Scholar] [CrossRef]
- Solórzano, J.; Mas, J.; Gao, Y.; Gallardo, A. Land use land cover classification with U-Net: Advantages of combining Sentinel-1 and Sentinel-2 imagery. Remote Sens. 2021, 13, 3600. [Google Scholar] [CrossRef]
- Gašparović, M.; Jogun, T. The effect of fusing Sentinel-2 bands on land-cover classification. Int. J. Remote Sens. 2018, 39, 822–841. [Google Scholar] [CrossRef]
- Chini, M.; Pelich, R.; Pulvirenti, L.; Pierdicca, N.; Hostache, R.; Matgen, P. Sentinel-1 InSAR coherence to detect floodwater in urban areas: Houston and hurricane harvey as a test case. Remote Sens. 2019, 11, 107. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Date | Season | Resolution (m) | Processing | Polarization and Bands | Orbit and Clouds (%) |
|---|---|---|---|---|---|---|
| Sentinel-1 | 10 April 2021 | Dry | 10 | IW 1 GRH | VH, VV | Descending |
| Sentinel-2 | 11 April 2021 | Dry | 10 | MSIL1C | 4, 3, 2, 7, 6, 5 | 5.8 |
| Sentinel-1 | 7 September 2021 | Rainy | 10 | IW 1 GRH | VH, VV | Descending |
| Sentinel-2 | 8 September 2021 | Rainy | 10 | MSIL1C | 4, 3, 2, 7, 6, 5 | 28.8 |
| Index | Reference |
|---|---|
| [39] | |
| [40] | |
| [41] | |
| [42] | |
| [42] |
| Entry | Combination | Description |
|---|---|---|
| S2 | 1 | Algorithm + RGB composite of S2. |
| S2 | 2 | Algorithm + HSB composite of S2 |
| S2 | 3 | Algorithm + HSV composite of S2 + MNDWI1 index. |
| S2 | 4 | Algorithm + HSV composite of S2 + MNDWI2 index. |
| S2 | 5 | Algorithm + HSV composite of S2 + NDWI index. |
| S2 | 6 | Algorithm + HSV composite of S2 + AWEI index. |
| S2 | 7 | Algorithm + HSV composite of S2 + AWEISH index. |
| S2, DEM | 8 | Algorithm + HSV composite of S2 + DEM |
| S2, DEM | 9 | Algorithm + H, V bands from HSV composite of S2 + DEM |
| S1 | 10 | Algorithm + (VH, VV) dual polarization of S1. |
| S1, DEM | 11 | Algorithm + (VH, VV) dual polarization of S1 + DEM |
| S1, DEM | 12 | Algorithm + (VH, VV) dual polarization of S1 + (VV/VH) polarization of S1 + DEM |
| S2, S1 | 13 | Algorithm + HSV composite of S2 + VH polarization of S1. |
| S2, S1 | 14 | Algorithm + HSV composite of S2 + VV polarization of S1. |
| S2, S1, DEM | 15 | Algorithm + HSV composite of S2 + VV polarization of S1 + DEM |
| S2, S1, DEM | 16 | Algorithm + H, V bands from HSV composite of S2 + VV polarization of S1 + AWEI index + DEM |
| Combination | F1m | AUC | Kappa | F1m | AUC | Kappa |
|---|---|---|---|---|---|---|
| Dry | Rainy | |||||
| 1 | 0.9815 | 0.9981 | 0.9631 | 0.8958 | 0.9595 | 0.7916 |
| 2 | 0.9816 | 0.9983 | 0.9632 | 0.8935 | 0.961 | 0.7871 |
| 3 | 0.9843 | 0.9986 | 0.9686 | 0.8935 | 0.961 | 0.7871 |
| 4 | 0.9835 | 0.9985 | 0.967 | 0.8935 | 0.961 | 0.7871 |
| 5 | 0.9839 | 0.9985 | 0.9677 | 0.8935 | 0.961 | 0.7871 |
| 6 | 0.9838 | 0.9986 | 0.9676 | 0.9209 | 0.9753 | 0.8419 |
| 7 | 0.9845 | 0.9986 | 0.9689 | 0.9171 | 0.9736 | 0.8343 |
| 8 | 0.9948 | 0.9998 | 0.9895 | 0.9858 | 0.9988 | 0.9716 |
| 9 | 0.9927 | 0.9997 | 0.9854 | 0.983 | 0.9984 | 0.9659 |
| 10 | 0.9538 | 0.9912 | 0.9076 | 0.9488 | 0.9903 | 0.8975 |
| 11 | 0.9786 | 0.9984 | 0.9571 | 0.978 | 0.9985 | 0.956 |
| 12 | 0.9787 | 0.9984 | 0.9574 | 0.9776 | 0.9984 | 0.9552 |
| 13 | 0.9916 | 0.9994 | 0.9832 | 0.9748 | 0.9968 | 0.9497 |
| 14 | 0.9945 | 0.9996 | 0.989 | 0.9754 | 0.9973 | 0.9508 |
| 15 | 0.9973 | 0.9999 | 0.9945 | 0.9944 | 0.9998 | 0.9887 |
| 16 | 0.9968 | 0.9999 | 0.9936 | 0.9953 | 0.9999 | 0.9905 |
| Combination | AUC | Kappa | AUC | Kappa | ||
|---|---|---|---|---|---|---|
| Dry Season | Rainy Season | |||||
| 1 | 0.9812 | 0.9961 | 0.9623 | 0.8866 | 0.9494 | 0.7732 |
| 2 | 0.9805 | 0.9956 | 0.961 | 0.8859 | 0.9499 | 0.7718 |
| 3 | 0.984 | 0.9976 | 0.9681 | 0.885 | 0.9496 | 0.7701 |
| 4 | 0.9837 | 0.9968 | 0.9675 | 0.885 | 0.9496 | 0.7701 |
| 5 | 0.9834 | 0.9972 | 0.9668 | 0.885 | 0.9496 | 0.7777 |
| 6 | 0.9832 | 0.9974 | 0.9664 | 0.92 | 0.9736 | 0.8444 |
| 7 | 0.9848 | 0.9971 | 0.9695 | 0.9167 | 0.9706 | 0.8334 |
| 8 | 0.9942 | 0.9995 | 0.9885 | 0.9861 | 0.998 | 0.9721 |
| 9 | 0.9921 | 0.999 | 0.9843 | 0.9825 | 0.9971 | 0.9649 |
| 10 | 0.9484 | 0.9846 | 0.8968 | 0.9433 | 0.9833 | 0.8866 |
| 11 | 0.9774 | 0.9973 | 0.9547 | 0.9777 | 0.9977 | 0.9554 |
| 12 | 0.9771 | 0.9974 | 0.9543 | 0.9772 | 0.9974 | 0.9543 |
| 13 | 0.992 | 0.9983 | 0.9839 | 0.9741 | 0.9952 | 0.9482 |
| 14 | 0.9944 | 0.9988 | 0.9887 | 0.975 | 0.9952 | 0.9555 |
| 15 | 0.9969 | 0.9996 | 0.9937 | 0.9933 | 0.9996 | 0.9866 |
| 16 | 0.9963 | 0.9997 | 0.9926 | 0.9939 | 0.9996 | 0.9878 |
| Algorithm | Combination | AUC | Kappa | |
|---|---|---|---|---|
| GB | 15 | 0.9973 | 0.9999 | 0.9945 |
| RF | 15 | 0.9969 | 0.9996 | 0.9937 |
| Algorithm | Combination | VP | FP | VN | FN | PG (%) |
|---|---|---|---|---|---|---|
| GB | 15 | 995 | 5 | 2199 | 1 | 0.998 |
| RF | 15 | 992 | 8 | 2198 | 2 | 0.996 |
| Algorithm | Combination | Extent of Water Bodies | |
|---|---|---|---|
| (ha) | (%) | ||
| GB | 15 | 968.43 | 4.20 |
| RF | 15 | 836.6 | 3.63 |
| Algorithm | Combination | AUC | Kappa | |
|---|---|---|---|---|
| GB | 16 | 0.9953 | 0.9999 | 0.9905 |
| RF | 16 | 0.9939 | 0.9996 | 0.9878 |
| Algorithm | Combination | VP | FP | VN | FN | PG (%) |
|---|---|---|---|---|---|---|
| GB | 16 | 998 | 2 | 2032 | 8 | 0.996 |
| RF | 16 | 995 | 5 | 2029 | 11 | 0.994 |
| Algorithm | Combination | Extent of Flooding (ha) (%) | |
|---|---|---|---|
| GB | 16 | 1835.71 | 7.96 |
| RF | 16 | 1623.98 | 7.04 |
| Algorithm | Combination | Water Body Dry Season | Flooded Area Rainy Season | ||
|---|---|---|---|---|---|
| (ha) | (%) | (ha) | (%) | ||
| GB | 15 and 16 | 722.35 | 3.13 | 1113.36 | 4.83 |
| RF | 15 and 16 | 670.46 | 2.91 | 953.52 | 4.13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soria-Ruiz, J.; Fernandez-Ordoñez, Y.M.; Ambrosio-Ambrosio, J.P.; Escalona-Maurice, M.J.; Medina-García, G.; Sotelo-Ruiz, E.D.; Ramirez-Guzman, M.E. Flooded Extent and Depth Analysis Using Optical and SAR Remote Sensing with Machine Learning Algorithms. Atmosphere 2022, 13, 1852. https://doi.org/10.3390/atmos13111852
Soria-Ruiz J, Fernandez-Ordoñez YM, Ambrosio-Ambrosio JP, Escalona-Maurice MJ, Medina-García G, Sotelo-Ruiz ED, Ramirez-Guzman ME. Flooded Extent and Depth Analysis Using Optical and SAR Remote Sensing with Machine Learning Algorithms. Atmosphere. 2022; 13(11):1852. https://doi.org/10.3390/atmos13111852
Chicago/Turabian StyleSoria-Ruiz, Jesús, Yolanda M. Fernandez-Ordoñez, Juan P. Ambrosio-Ambrosio, Miguel J. Escalona-Maurice, Guillermo Medina-García, Erasto D. Sotelo-Ruiz, and Martha E. Ramirez-Guzman. 2022. "Flooded Extent and Depth Analysis Using Optical and SAR Remote Sensing with Machine Learning Algorithms" Atmosphere 13, no. 11: 1852. https://doi.org/10.3390/atmos13111852
APA StyleSoria-Ruiz, J., Fernandez-Ordoñez, Y. M., Ambrosio-Ambrosio, J. P., Escalona-Maurice, M. J., Medina-García, G., Sotelo-Ruiz, E. D., & Ramirez-Guzman, M. E. (2022). Flooded Extent and Depth Analysis Using Optical and SAR Remote Sensing with Machine Learning Algorithms. Atmosphere, 13(11), 1852. https://doi.org/10.3390/atmos13111852