
Prediction of Carbon Emissions in China’s Power Industry Based on the Mixed-Data Sampling (MIDAS) Regression Model

Abstract
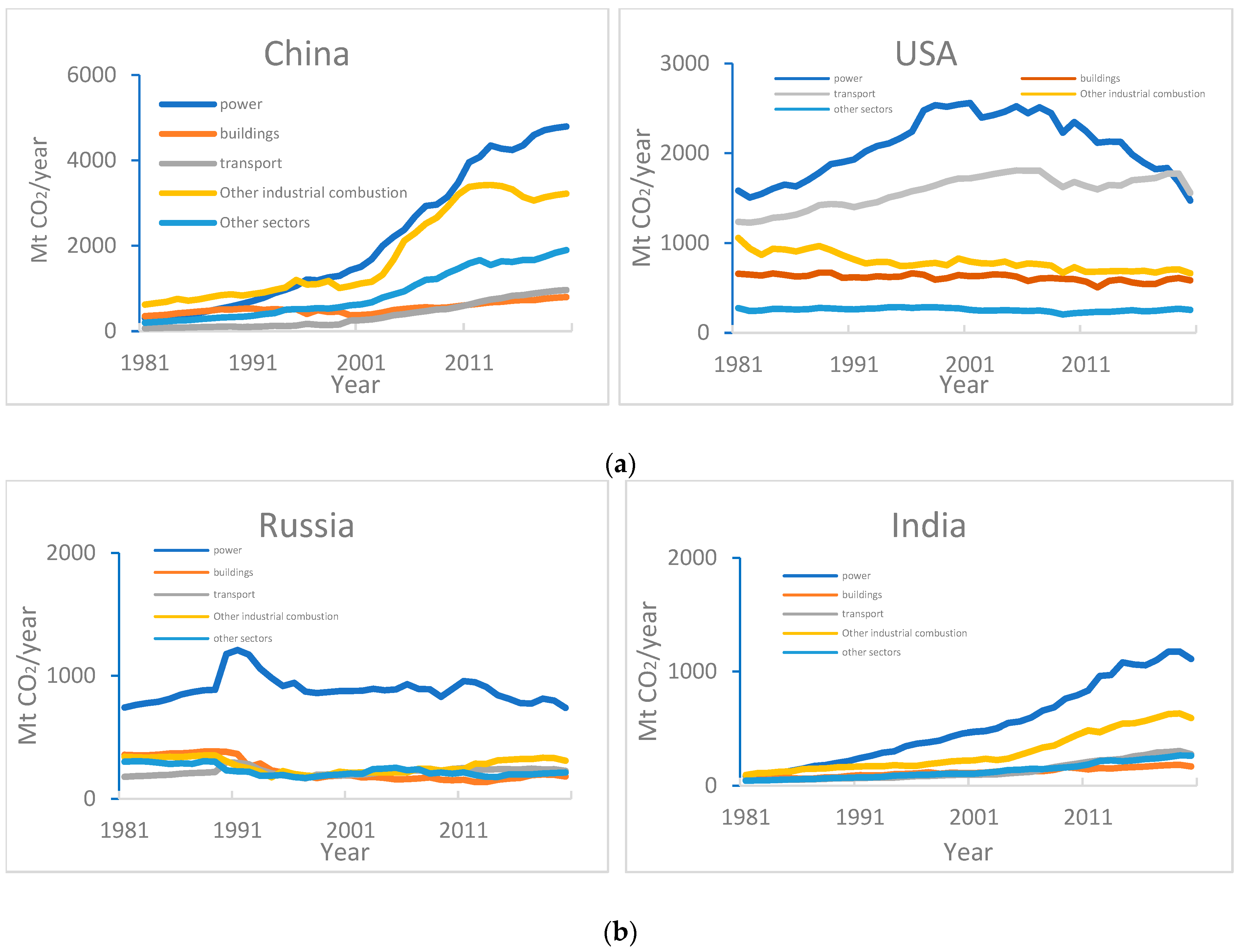
:1. Introduction
2. Literature Review
3. Methodology
3.1. ARDL Model
3.2. The MIDAS Model
3.2.1. The Basic MIDAS Model
3.2.2. Multiple Independent Variables MIDAS Model
3.2.3. The h-Step Ahead MIDAS Model
3.3. Accuracy Index
4. Data
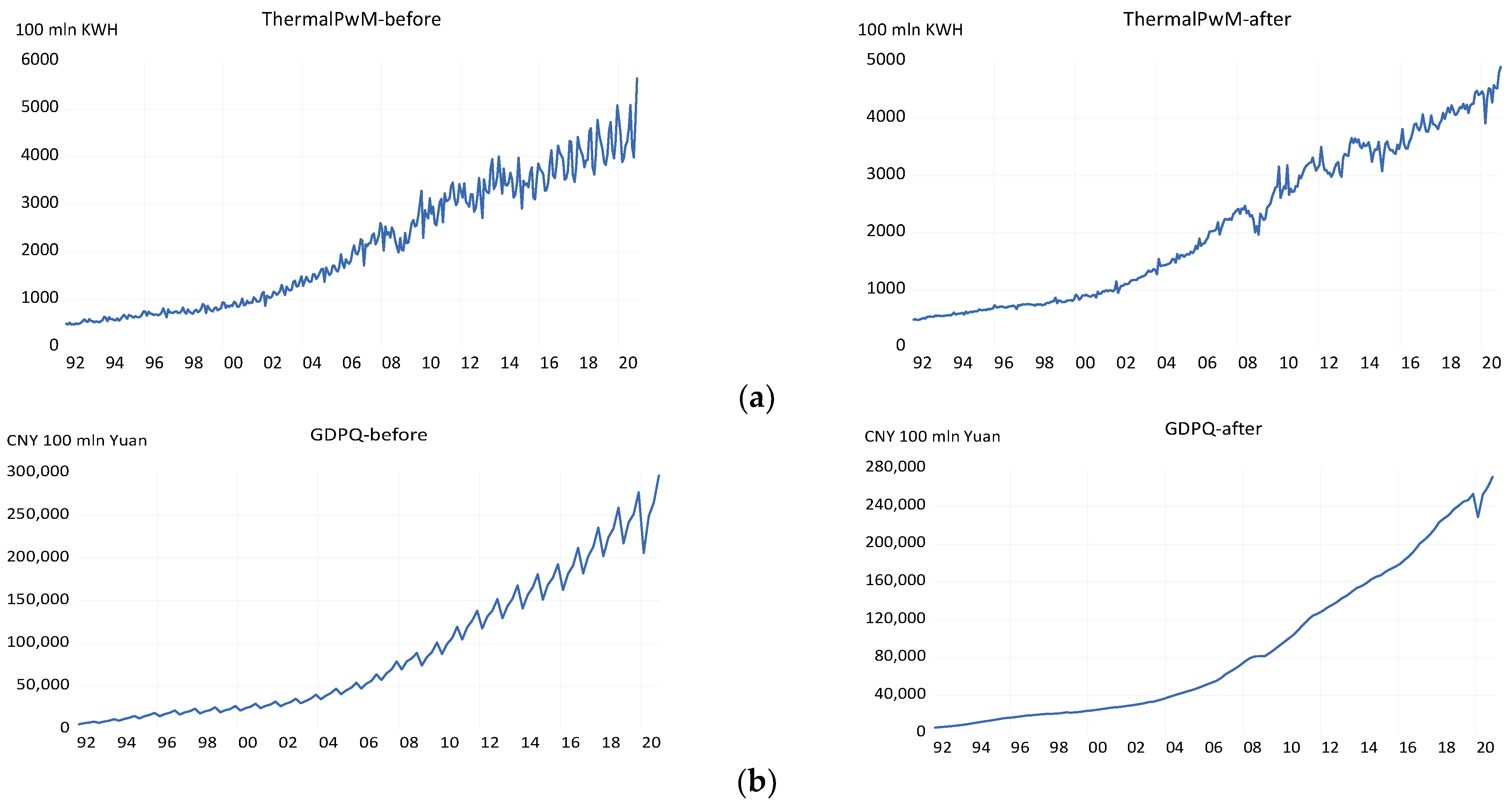
4.1. Data Pre-Processing
4.2. Stationary Test
5. Empirical Analysis
5.1. Model Estimation
5.2. Nowcasting and Forecasting
6. Conclusions
7. Discussion and Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Crippa, M.; Guizzardi, D.; Solazzo, E.; Muntean, M.; Schaaf, E.; Monforti-Ferrario, F.; Banja, M.; Olivier, J.; Grassi, G.; Rossi, S.; et al. GHG Emissions of All World Countries, EUR 30831 EN; Publications Office of the European Union: Luxembourg, 2021; ISBN 978-92-76-41547-3. [CrossRef]
- National Bureau of Statistics of P.R. China. Available online: https://data.stats.gov.cn (accessed on 10 February 2022). (In Chinese)
- The State Council of China. China Releases White Paper on Climate Change Response, 28 October 2021. Available online: http://english.www.gov.cn/news/videos/202110/28/content_WS617a1072c6d0df57f98e4115.html (accessed on 10 February 2022).
- Ghysels, E.; Santa-Clara, P.; Valkanov, R. The MIDAS Touch: Mixed Data Sampling Regression Models. UCLA, Finance. 2004. Available online: https://escholarship.org/uc/item/9mf223rs (accessed on 10 February 2022).
- Giannone, D.; Reichlin, L.; Small, D. Nowcasting: The real-time informational content of macroeconomic data. J. Monet. Econ. 2008, 55, 665–676. [Google Scholar] [CrossRef]
- Fang, D.; Zhang, X.; Yu, Q.; Jin, T.C.; Tian, L. A novel method for carbon dioxide emission forecasting based on improved Gaussian processes regression. J. Clean. Prod. 2018, 173, 143–150. [Google Scholar] [CrossRef]
- Wu, L.; Liu, S.; Liu, D.; Fang, Z.; Xu, H. Modelling and forecasting CO2 emissions in the BRICS (Brazil, Russia, India, China, and South Africa) countries using a novel multi-variable grey model. Energy 2015, 79, 489–495. [Google Scholar] [CrossRef]
- Chang, H.; Sun, W.; Gu, X. Forecasting Energy CO2 Emissions Using a Quantum Harmony Search Algorithm-Based DMSFE Combination Model. Energies 2013, 6, 1456–1477. [Google Scholar] [CrossRef] [Green Version]
- Köne, A.Ç.; Büke, T. Forecasting of CO2 emissions from fuel combustion using trend analysis. Renew. Sustain. Energy Rev. 2010, 14, 2906–2915. [Google Scholar] [CrossRef]
- Zhao, X.; Han, M.; Ding, L.; Calin, A.C. Forecasting carbon dioxide emissions based on a hybrid of mixed data sampling regression model and back propagation neural network in the USA. Environ. Sci. Pollut. Res. 2017, 25, 2899–2910. [Google Scholar] [CrossRef]
- Hosseini, S.M.; Saifoddin, A.; Shirmohammadi, R.; Aslani, A. Forecasting of CO2 emissions in Iran based on time series and regression analysis. Energy Rep. 2019, 5, 619–631. [Google Scholar] [CrossRef]
- Fang, K.; Tang, Y.; Zhang, Q.; Song, J.; Wen, Q.; Sun, H.; Ji, C.; Xu, A. Will China peak its energy-related carbon emissions by 2030? Lessons from 30 Chinese provinces. Appl. Energy 2019, 255, 113852. [Google Scholar] [CrossRef]
- Li, M.; Wang, W.; De, G.; Ji, X.; Tan, Z. Forecasting Carbon Emissions Related to Energy Consumption in Beijing-Tianjin-Hebei Region Based on Grey Prediction Theory and Extreme Learning Machine Optimized by Support Vector Machine Algorithm. Energies 2018, 11, 2475. [Google Scholar] [CrossRef] [Green Version]
- Lin, B.; Long, H. Emissions reduction in China’s chemical industry—Based on LMDI. Renew. Sustain. Energy Rev. 2016, 53, 1348–1355. [Google Scholar] [CrossRef]
- Fatima, T.; Xia, E.; Cao, Z.; Khan, D.; Fan, J.-L. Decomposition analysis of energy-related CO2 emission in the industrial sector of China: Evidence from the LMDI approach. Environ. Sci. Pollut. Res. 2019, 26, 21736–21749. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; O’Connell, J.F. Short-term carbon emissions forecast for aviation industry in Shanghai. J. Clean. Prod. 2020, 275, 122734. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, J.; Zheng, W. Decomposition Analysis of Energy-Related CO2 Emissions and Decoupling Status in China’s Logistics Industry. Sustainability 2018, 10, 1340. [Google Scholar] [CrossRef] [Green Version]
- Bahmani-Oskooee, M.; Chi Wing Ng, R. Long-Run Demand for Money in Hong Kong: An Application of the ARDL Model. Int. J. Bus. Econ. 2002, 1, 147–155. [Google Scholar]
- Ozturk, I.; Acaravci, A. The causal relationship between energy consumption and GDP in Albania, Bulgaria, Hungary and Romania: Evidence from ARDL bound testing approach. Appl. Energy 2010, 87, 1938–1943. [Google Scholar] [CrossRef]
- Chen, S. The Urbanization Impacts on the Policy Effects of the Carbon Tax in China. Sustainability 2021, 13, 6749. [Google Scholar] [CrossRef]
- Wang, Q.; Xiao, K.; Lu, Z. Does Economic Policy Uncertainty Affect CO2 Emissions? Empirical Evidence from the United States. Sustainability 2020, 12, 9108. [Google Scholar] [CrossRef]
- Foroni, C.; Marcellino, M.; Schumacher, C. Unrestricted mixed data sampling (MIDAS): MIDAS regressions with unrestricted lag polynomials. J. R. Stat. Soc. Ser. A Stat. Soc. 2013, 178, 57–82. [Google Scholar] [CrossRef]
- Ghysels, E.; Sinko, A.; Valkanov, R. MIDAS Regressions: Further Results and New Directions. Econ. Rev. 2007, 26, 53–90. [Google Scholar] [CrossRef]
- Galvão, A.B. Changes in predictive ability with mixed frequency data. Int. J. Forecast. 2013, 29, 395–410. [Google Scholar] [CrossRef] [Green Version]
- Guérin, P.; Marcellino, M. Markov-switching MIDAS models. J. Bus. Econ. Stat. 2013, 31, 45–56. [Google Scholar] [CrossRef] [Green Version]
- Breitung, J.; Roling, C. Forecasting inflation rates using daily data: A nonpara-metric MIDAS approach. J. Forecast. 2015, 34, 588–603. [Google Scholar] [CrossRef]
- Ghysels, E.; Santa-Clara, P.; Valkanov, R. Predicting volatility: Getting the most out of return data sampled at different frequencies. J. Econom. 2006, 131, 59–95. [Google Scholar] [CrossRef] [Green Version]
- Forsberg, L.; Ghysels, E. Why Do Absolute Returns Predict Volatility So Well? J. Financ. Econom. 2007, 5, 31–67. [Google Scholar] [CrossRef]
- Alper, C.E.; Fendoglu, S.; Burak, S. Forecasting Stock Market Volatilities Using MIDAS Regressions: An Application to the Emerging Markets. Munich Pers. RePEc Arch. 2008, 7460. Available online: https://mpra.ub.uni-muenchen.de/7460/ (accessed on 10 February 2022).
- Körs, M.; Karan, M.B. Stock exchange volatility forecasting under market stress with MIDAS regression. Int. J. Finance Econ. 2021, 1–12. [Google Scholar] [CrossRef]
- Kuzin, V.; Marcellino, M.; Schumacher, C. MIDAS vs. mixed-frequency VAR: Nowcasting GDP in the euro area. Int. J. Forecast. 2011, 27, 529–542. [Google Scholar] [CrossRef] [Green Version]
- Pan, Z.; Wang, Q.; Wang, Y.; Yang, L. Forecasting U.S. real GDP using oil prices: A time-varying parameter MIDAS model. Energy Econ. 2018, 72, 177–187. [Google Scholar] [CrossRef]
- Li, X.; Shang, W.; Wang, S.; Ma, J. A MIDAS modelling framework for Chinese inflation index forecast incorporating Google search data. Electron. Commer. Res. Appl. 2015, 14, 112–125. [Google Scholar] [CrossRef]
- Gunay, S.; Can, G.; Ocak, M. Forecast of China’s economic growth during the COVID-19 pandemic: A MIDAS regression analysis. J. Chin. Econ. Foreign Trade Stud. 2020, 14, 3–17. [Google Scholar] [CrossRef]
- Chevallier, J. COVID-19 Outbreak and CO2 Emissions: Macro-Financial Linkages. J. Risk Financ. Manag. 2020, 14, 12. [Google Scholar] [CrossRef]
- Friedlingstein, P.; Jones, M.W.; O’Sullivan, M.; Andrew, R.M.; Bakker, D.C.E.; Hauck, J.; Le Quéré, C.; Peters, G.P.; Peters, W.; Pongratz, J.; et al. Global Carbon Budget 2021. Earth Syst. Sci. Data Discuss. 2021, 1–191. [Google Scholar] [CrossRef]
- Borowski, P.F. Significance and Directions of Energy Development in African Countries. Energies 2021, 14, 4479. [Google Scholar] [CrossRef]
- Borowski, P.F.; Patuk, I.; Bandala, E.R. Innovative Industrial Use of Bamboo as Key “Green” Material. Sustainability 2022, 14, 1955. [Google Scholar] [CrossRef]
- Mitchell, C.D.; Harper, R.J.; Keenan, R.J. Current status and future prospects for carbon forestry in Australia. Aust. For. 2012, 75, 200–212. [Google Scholar] [CrossRef]
- Liu, H.; Gallagher, K.S. Catalyzing strategic transformation to a low-carbon economy: A CCS roadmap for China. Energy Policy 2010, 38, 59–74. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Variable Definitions | Frequency | Observations | Data Source |
|---|---|---|---|---|
| CO2 | CO2 emissions of the power industry | yearly | 29 | European Commission [1] |
| GDPY | GDP based on year | yearly | 29 | National Bureau of Statistics of China [2] |
| ThermalPwY | Electricity generated by thermal power stations per year | yearly | 29 | National Bureau of Statistics of China |
| GDPQ | GDP per quarter | quarterly | 116 | National Bureau of Statistics of China |
| ThermalPwM | Electricity generated by thermal power stations per month | monthly | 348 | National Bureau of Statistics of China |
| Symbol | Definitions | Observations | Min | Max | Mean | SD |
|---|---|---|---|---|---|---|
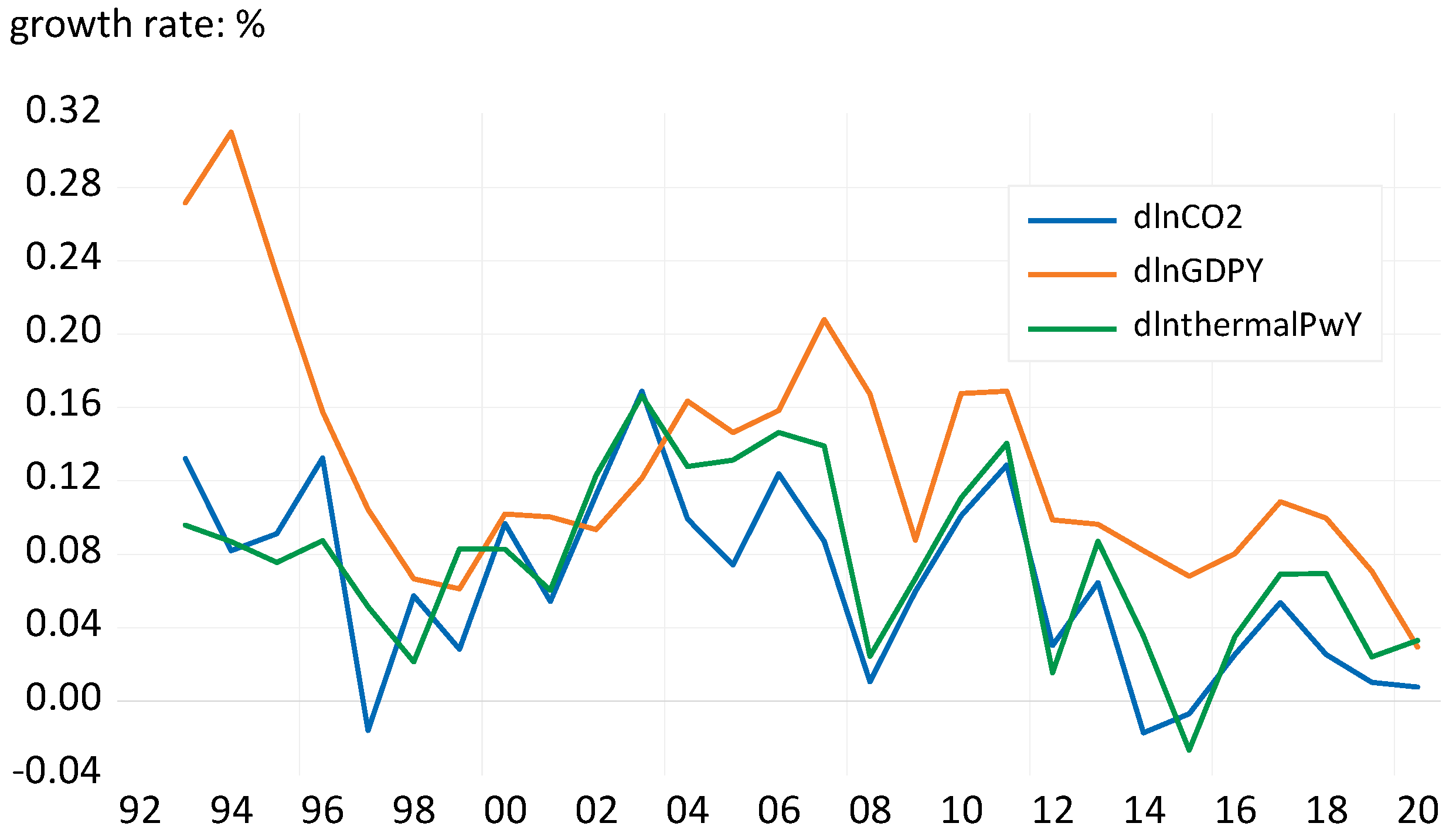
| dlnCO2 | Growth rate of CO2 emissions by the power industry | 28 | −0.01735 | 0.16883 | 0.06484 | 0.05032 |
| dlnGDPY | Yearly GDP growth rate | 28 | 0.02944 | 0.30999 | 0.12931 | 0.06559 |
| dlnthermalPwY | Yearly growth rate of electricity from thermal power stations | 28 | −0.02669 | 0.16638 | 0.07719 | 0.04709 |
| dlnGDPQ | Quarterly GDP growth rate | 115 | −0.010157 | 0.09889 | 0.03302 | 0.02301 |
| dlnthermalPwM | Monthly growth rate of electricity from thermal power stations | 347 | −0.018903 | 0.18882 | 0.00668 | 0.04262 |
| Symbol | ADF Testing | p-Value | Result |
|---|---|---|---|
| dlnCO2 | −4.125755 | 0.0161 | Stationary ** |
| dlnGDPY | −1.810576 | 0.0674 | Stationary * |
| dlnthermalPwY | −3.062216 | 0.0418 | Stationary ** |
| dlnGDPQ | −4.241424 | 0.0009 | Stationary *** |
| dlnthermalPwM | −19.30022 | 0.0000 | Stationary *** |
| Model | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| ARDL | MIDAS | ||||
| Variable | dlnGDPY | dlnthermalPwY | dlnGDPQ | dlnthermalPwM | dlnGDPQ dlnthermalPwM |
| RMSE | 0.050012 | 0.055784 | 0.041391 | 0.041428 | 0.037131 |
| MAPE | 286.7752 | 270.9444 | 259.2398 | 269.2595 | 197.0581 |
| MAE | 0.045379 | 0.04354 | 0.034088 | 0.03489 | 0.030401 |
| Lag | ARDL(5,1) | ARDL(5,4) | K1 = 2 | K2 = 18 | K1 = 13, K2 = 26 |
| Variable | Models | ||||
|---|---|---|---|---|---|
| ARDL | MIDAS | ||||
| 1 | 2 | 3 | 4 | 5 | |
| dlnCO2 (−1) | −0.491435 (0.357392) | −0.683536 ** (0.171498) | — | — | |
| dlnGDPY | 1.145907 ** (0.485071) | — | — | — | |
| dlnGDPY (−1) | −0.444184 (0.407048) | — | — | — | |
| dlnthermalPwY | — | 0.581409 *** (0.071905) | — | — | |
| dlnthermalPwY (−1) | — | 0.691681 ** (0.168351) | — | — | |
| dlnGDPQ | — | — | 2.931045 ** (2.825309) | — | 0.365510 (0.300701) |
| dlnthermalPwM | — | — | 0.543143 *** (0.179435) | 0.722755 ** (0.227343) | |
| Intercept | 0.117435 ** (0.040799) | 0.08185 ** (0.012126) | 0.027616 (0.022987) | 0.025505 (0.017184) | 0.008504 (0.033976) |
| AIC | −3.450208 | −6.778780 | −3.433334 | −3.783747 | −4.082098 |
| R-squared | 0.629634 | 0.991101 | 0.312447 | 0.515689 | 0.731822 |
| Steps | Year of 2021 (Mt CO2/Year) | Year of 2022 (Mt CO2/Year) |
|---|---|---|
| h = 0 | 5166.04 | — |
| h = 1 | 5069.03 | — |
| h = 2 | 5072.39 | — |
| h = 3 | 5187.45 | — |
| h = 4 | 5225.81 | 5201.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Liao, M. Prediction of Carbon Emissions in China’s Power Industry Based on the Mixed-Data Sampling (MIDAS) Regression Model. Atmosphere 2022, 13, 423. https://doi.org/10.3390/atmos13030423
Xu X, Liao M. Prediction of Carbon Emissions in China’s Power Industry Based on the Mixed-Data Sampling (MIDAS) Regression Model. Atmosphere. 2022; 13(3):423. https://doi.org/10.3390/atmos13030423
Chicago/Turabian StyleXu, Xiaoxiang, and Mingqiu Liao. 2022. "Prediction of Carbon Emissions in China’s Power Industry Based on the Mixed-Data Sampling (MIDAS) Regression Model" Atmosphere 13, no. 3: 423. https://doi.org/10.3390/atmos13030423
APA StyleXu, X., & Liao, M. (2022). Prediction of Carbon Emissions in China’s Power Industry Based on the Mixed-Data Sampling (MIDAS) Regression Model. Atmosphere, 13(3), 423. https://doi.org/10.3390/atmos13030423