3.3. Review of CNN, a Deep Learning Technique
DL is a kind of Artificial Neural Network (ANN) model which is designed to solve learning tasks by imitating the human biological neural network. ANN became popular after 2006 when Hinton and Salakhutdinov [
33] proposed the concept of “deep learning,” an architecture with many more layers than ANN. Since then, deep learning became very popular, especially in pattern recognition and image classification [
30]. One of the significant components in deep learning is Convolutional Neural Network (CNN), which can extract features, i.e., variables, directly from pixel-based images. CNN is an ANN-based network that is mainly used for processing natural images with three RGB channels, and it significantly outperforms all other data mining techniques [
34]. To be specific, CNN can be viewed as a two-dimensional (2D) version of ANN, where the one-dimensional hidden layer is replaced by multiple 2D layers. In addition to the astonishing accuracy in image object classification, CNN is successfully applied in extreme weather prediction [
35].
Liu et al. [
35] built a CNN model to classify three extreme types of weather, TCs, atmospheric rivers, and weather fronts based on the CAM5.1 historical run, ERA-interim reanalysis, 20-century reanalysis, and NCEP-NCAR reanalysis data. The overall accuracy achieves more than 88%, and the TC detection rate reaches 98%.
Although regular CNN achieves excellent accuracy in tasks such as image classification, CNN cannot handle problems with temporal information involved. Tran et al. [
36] proposed a 3D CNN aiming at handling video analysis problems by adding another temporal dimension to CNN.
Another important structure of deep learning is the auto-encoder network, which is “a type of ANN that is trained to attempt to copy its input to its output. Internally, it has a hidden layer that describes a code used to represent the input. The network may be viewed as consisting of two parts: an encoder represents a feature extracted process and a decoder that produces an input reconstruction” [
37]. An auto-encoder is used for dimension reduction when the original data space dimension is too large and is also used for classification and prediction [
38].
Racah et al. [
39] proposed an auto-encoder CNN architecture for a semi-supervised classification on extreme weather. Since there are a large number of unlabeled extreme weather images, and to expand the training dataset, Racah et al. employed a bounding box technique to recognize the location of extreme weather, and the classification is based on those data. Although the classification performance of Racah et al. [
39] still needs improvement, it reveals that there are many promises to consider deep learning techniques in the weather community.
3.4. Implementation Details of CNN for the ERA-Interim Filtering (Readers Familiar with CNN Procedure Could Read the Figures on Major Structures Only without Going through the Technical Details of CNN)
For the COR-SHIPS and LLE-SHIPS models, the features from the current time to 18 h before are included for the RI prediction. The same temporal coverage is chosen here and therefore, each instance has 14 (variable) × 4 (−18 h, −12 h, −6 h, 0 h) × 37 (pressure level) × 33 (zonal dimension) × 33 (meridional dimension) dimensions (values). In our implementation, each variable is handled individually, and therefore, a 3D CNN is used to extract features from each individual variable. The 37 pressure levels are viewed as 37 channels, similar to RGB channels of videos, with the gridded data at each pressure level as an image, and the temporal coverage as the image sequence of a video.
In a 2D convolutional layer, the same learnable filter is applied to each group of nearby pixels to extract features. The filter is defined as a
p ×
q (
p and
q are integers) size rectangle that can be convolved through the entire input array with
m ×
n dimensions. The dot product is computed between the filter weights and the input, and producing an (
m −
p + 1) × (
n −
q + 1) output array after scanning assuming a stride of 1.
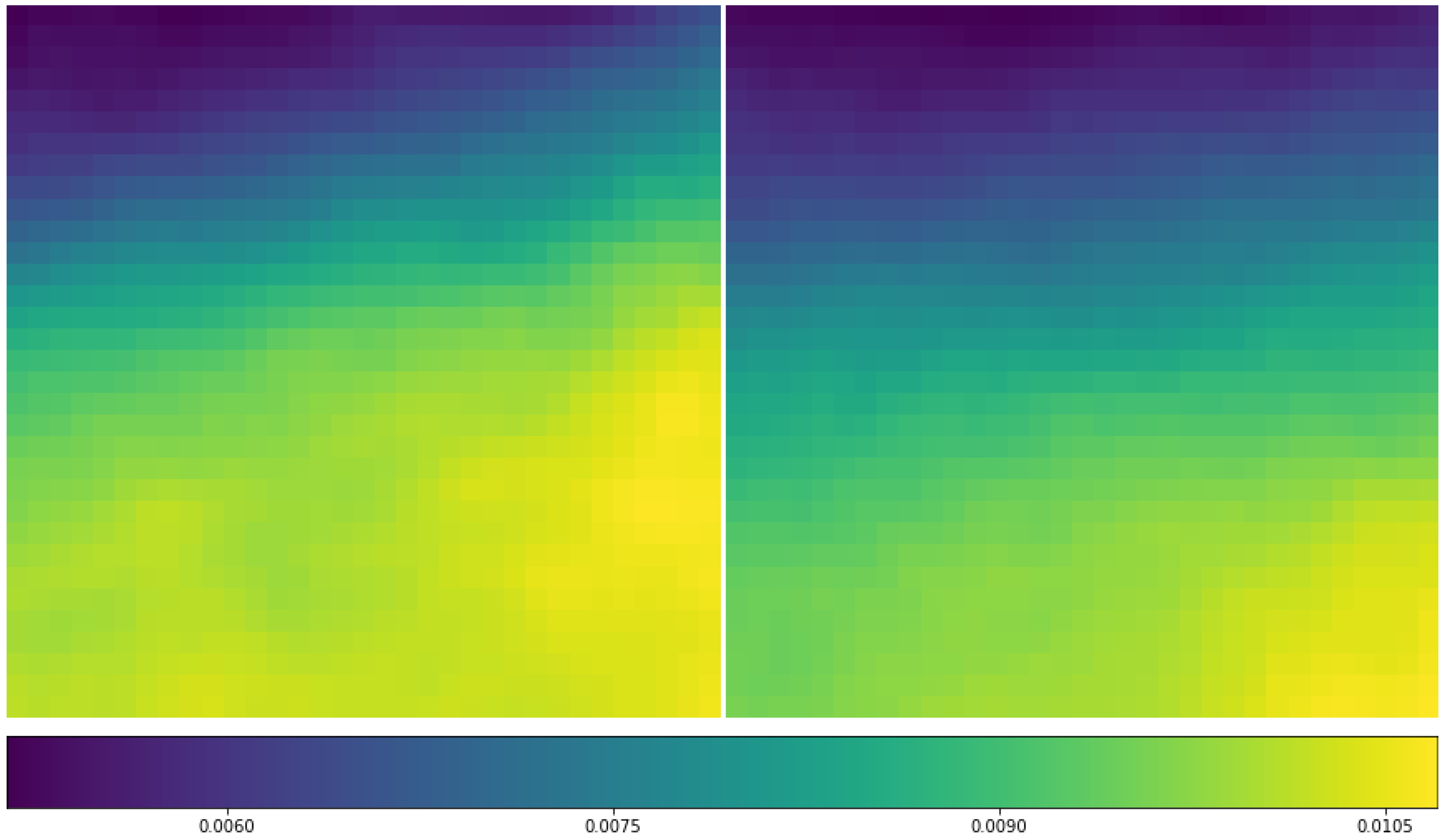
Figure 1 displays an example of the convolution operation. A 3 × 3 filter is convolved through a 4 × 4 array and output a 2 × 2 array with values calculated by the dot product of the sliding filter and the original data value. If the input array has more than one channel, as in a natural image with RGB channels, there will be the 3rd dimension (depth) added to the previous two-dimension filer, and the output array will still be two-dimension with value summing over the depth dimensions.
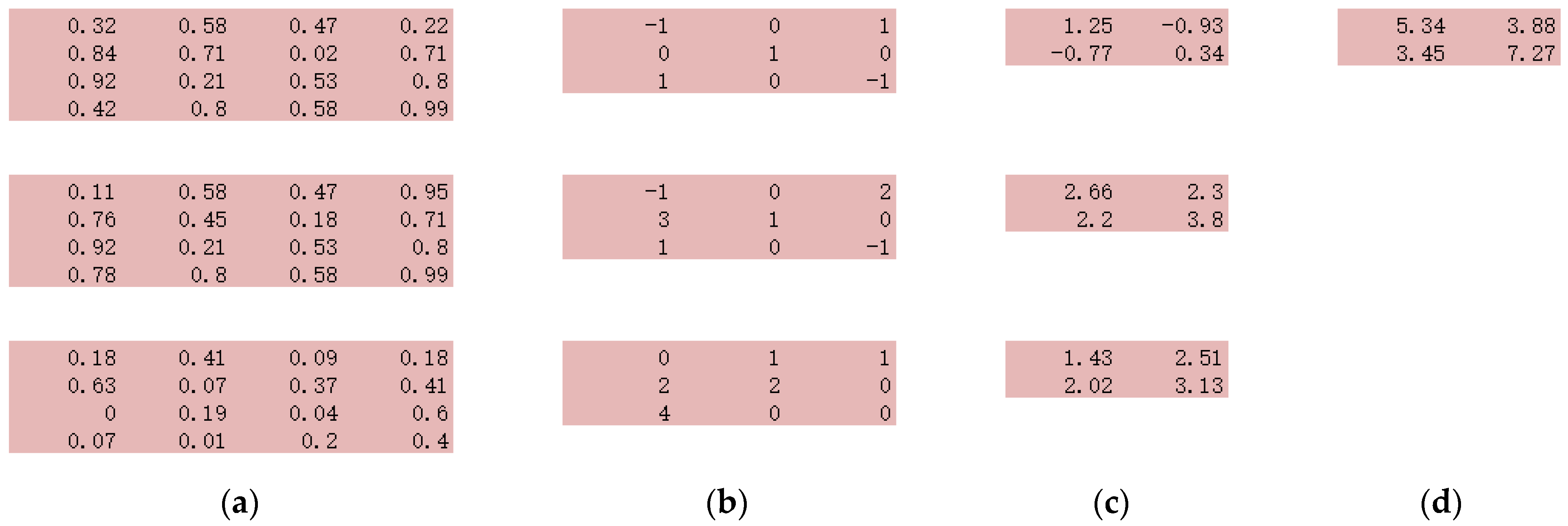
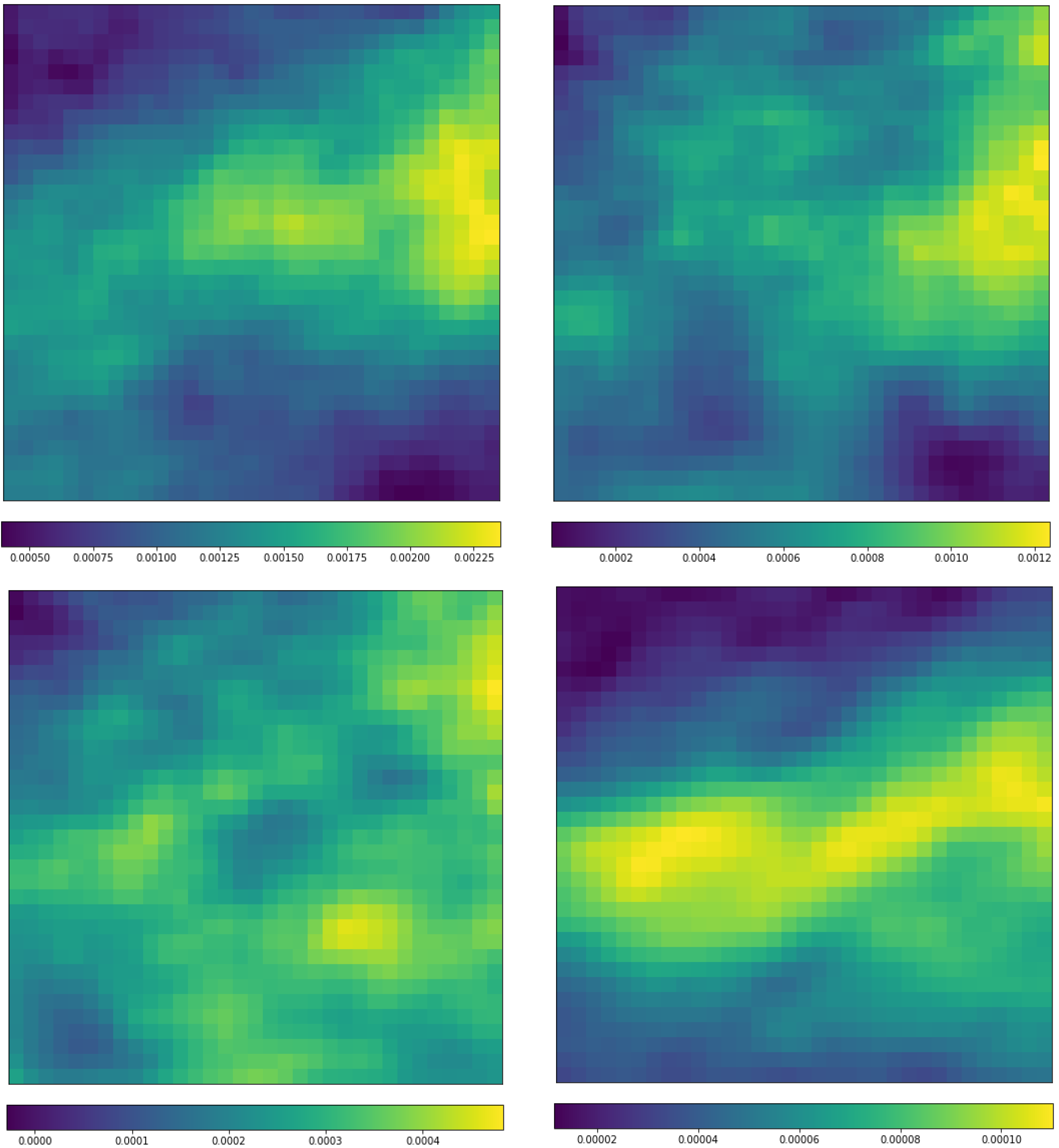
Figure 2 shows a multi-channel example with a 4 × 4 image with three channels (
Figure 2a). Three-dimension filters (
Figure 2b) are designed, each one is applied to the corresponding channel, and the result will be 3 × 2 ×2 outputs (
Figure 2c). Then these three outputs will be simply summed up together, leading to one 2 × 2 output (
Figure 2d).
When the input is 3D arrays, the 3D filter, and its convolving operation are the same as that of 2D except that an additional dimension is added.
The above-described convolution procedure only extracts linear information, and for obtaining nonlinear information, an activation layer is introduced after each convolutional layer. Rectified Linear Units (ReLU) is the most commonly used activation function that maps negative values to 0, and keeps the positive values, respectively. This function will not affect the size of the data arrays and will be used in this work.
A pooling layer is usually applied after the convolution and activation transformation to reduce the input’s dimension in order to avoid overfitting, and unlike convolution, there is no overlap in pooling operations for each pooling layer. Max pooling is the most widely used pooling method, which selects the maximum value among all covered values as the output value.
There are various types of deep learning models, and the most appropriate model for converting the gridded data into features for mining purposes is the auto-encoder network. Each auto-encoder network is composed of multiple deep learning layers, which is divided into two parts: an encoder represents a feature extraction process from the input and a decoder that reconstructs the input.
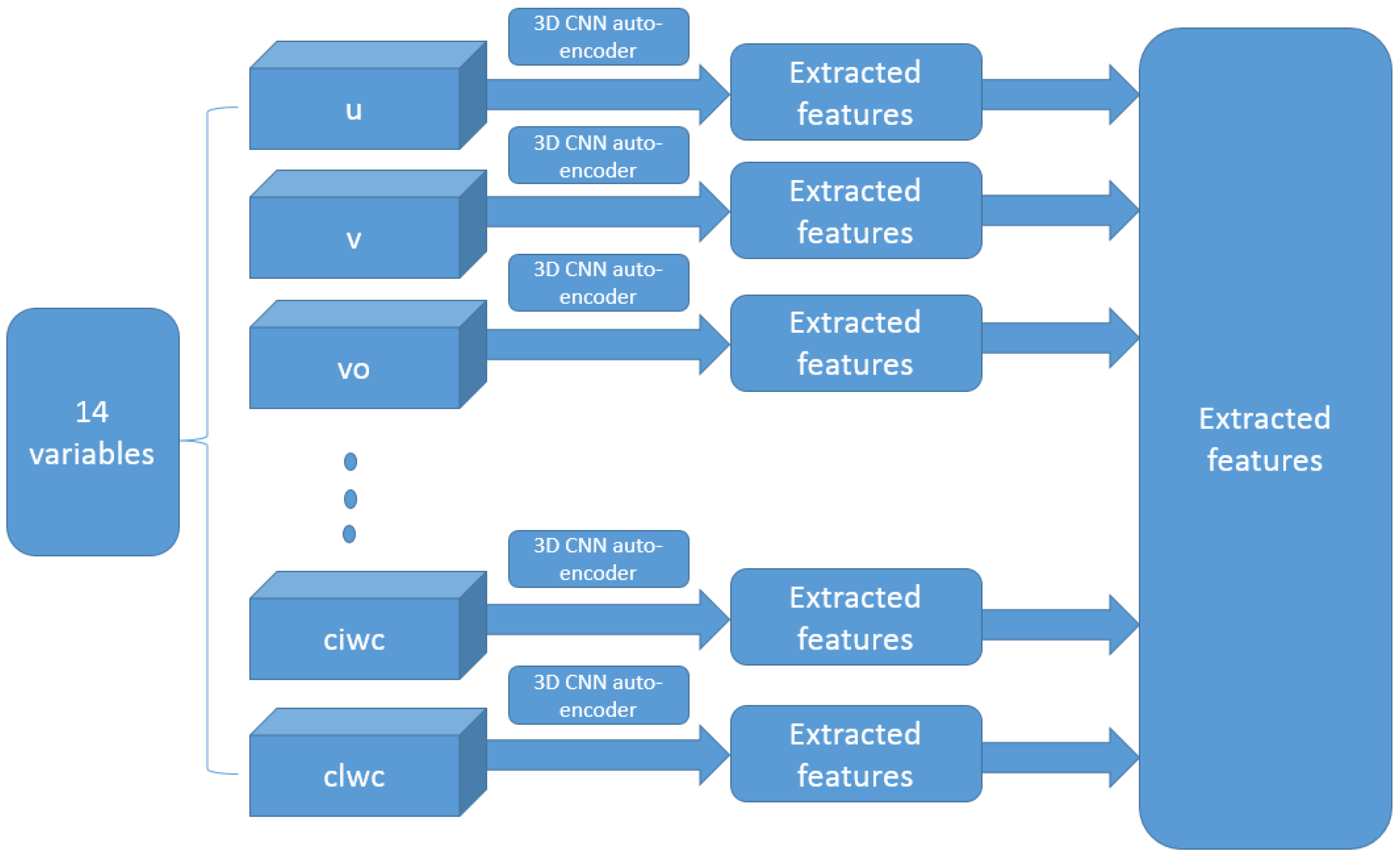
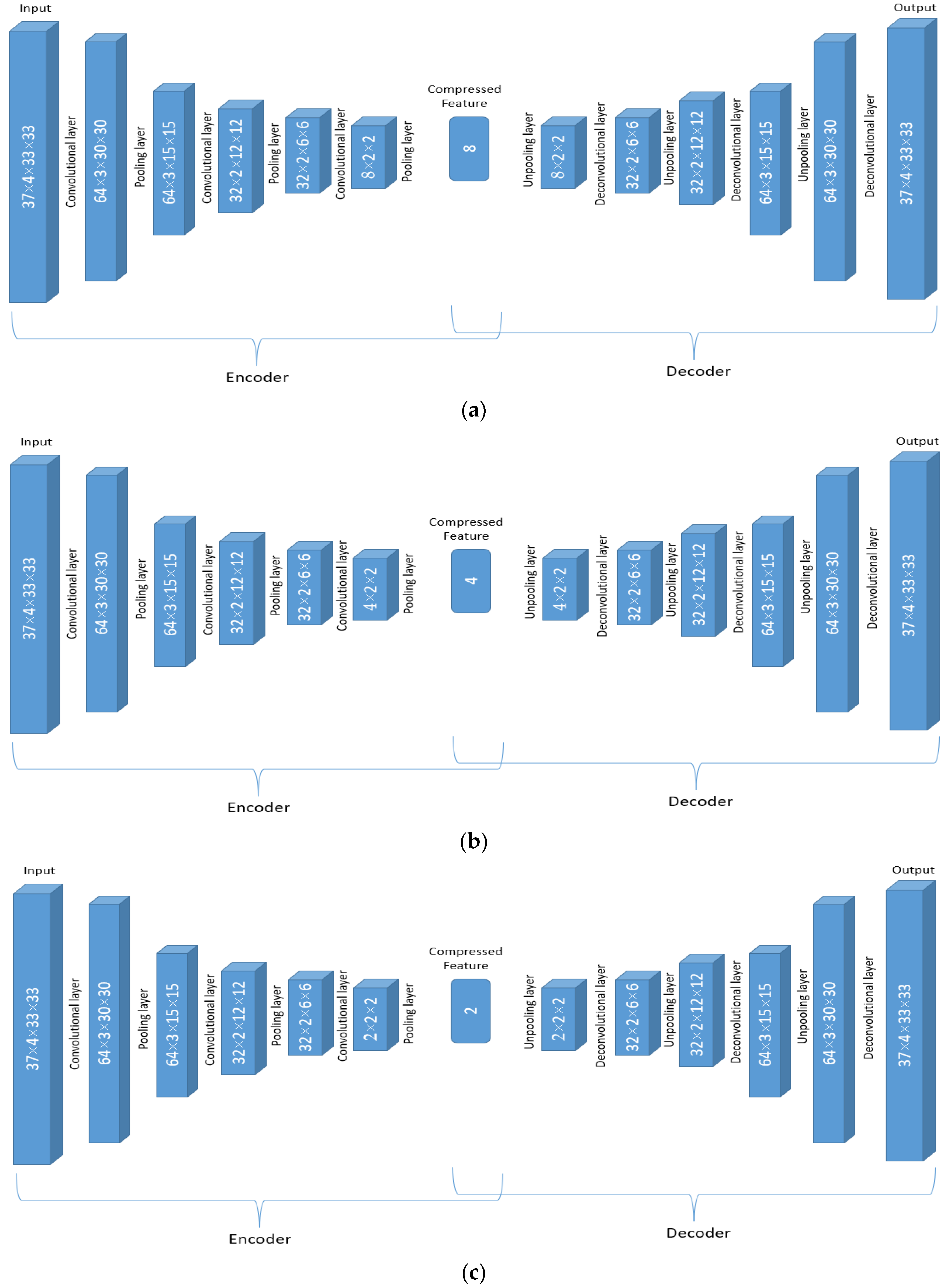
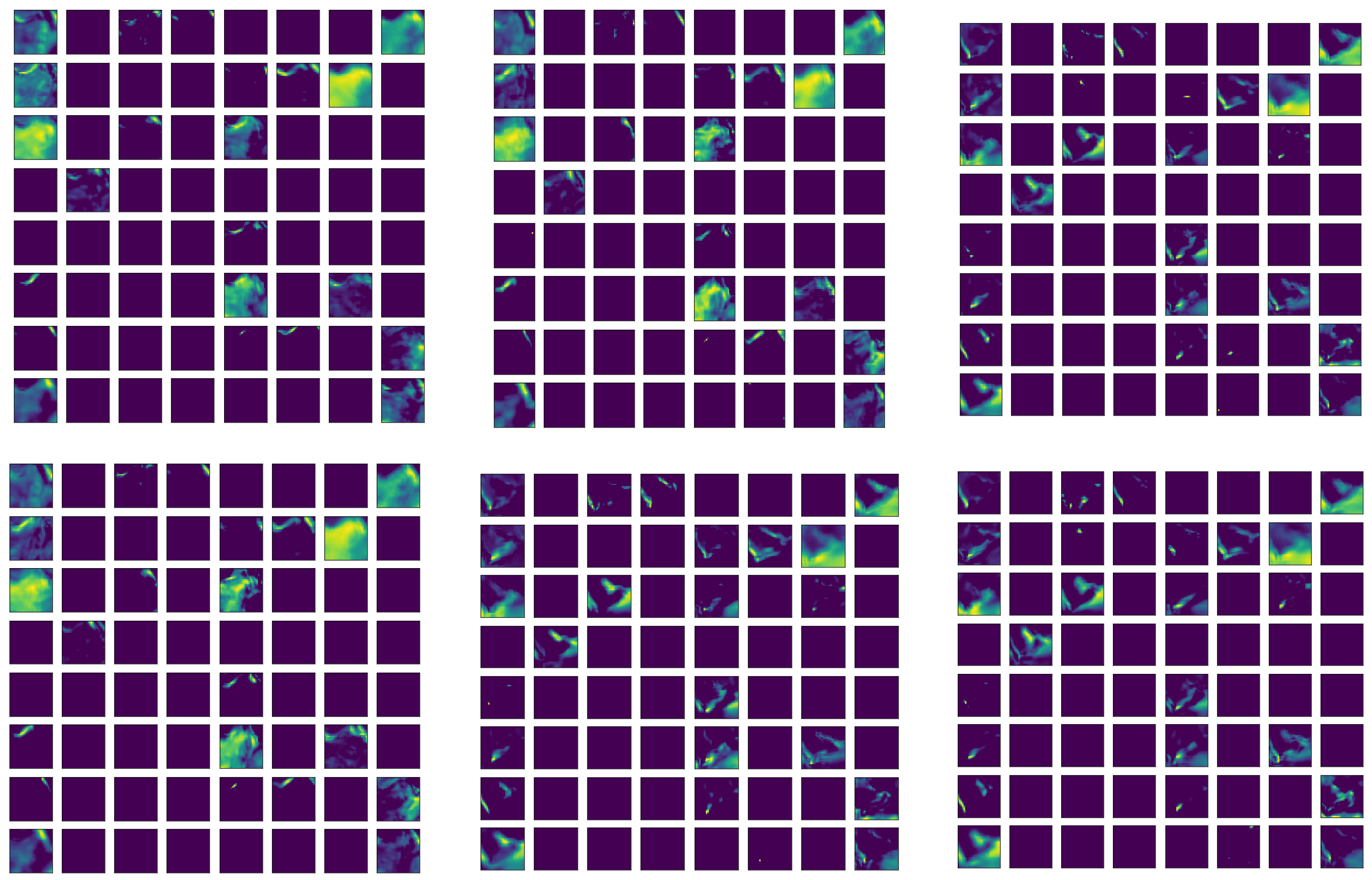
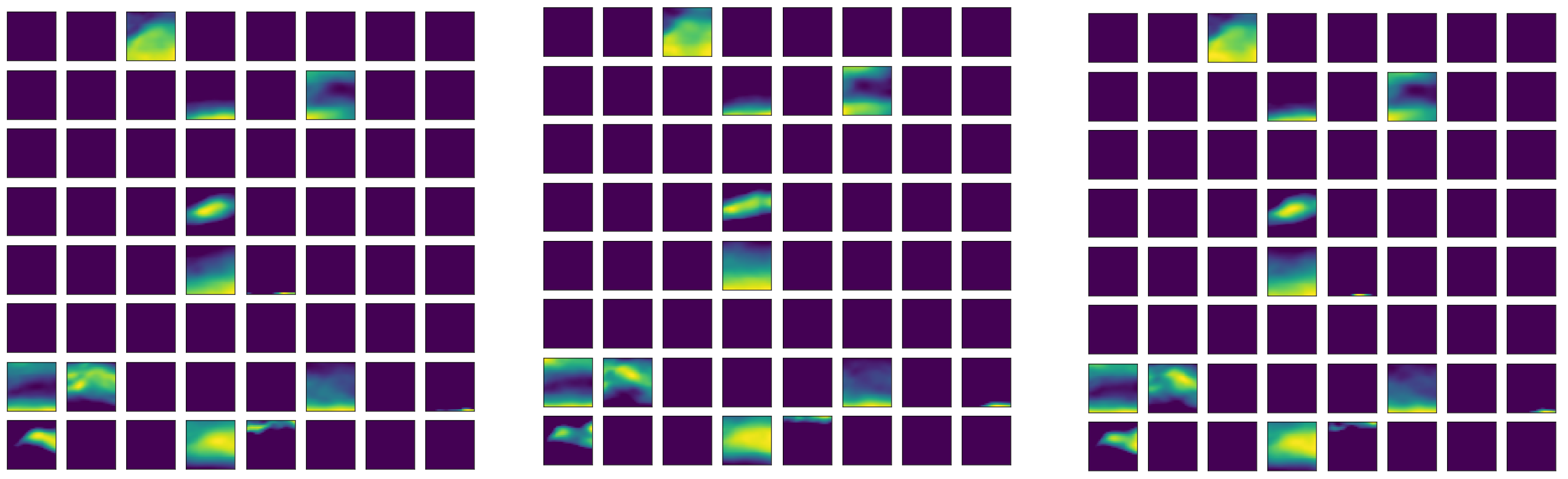
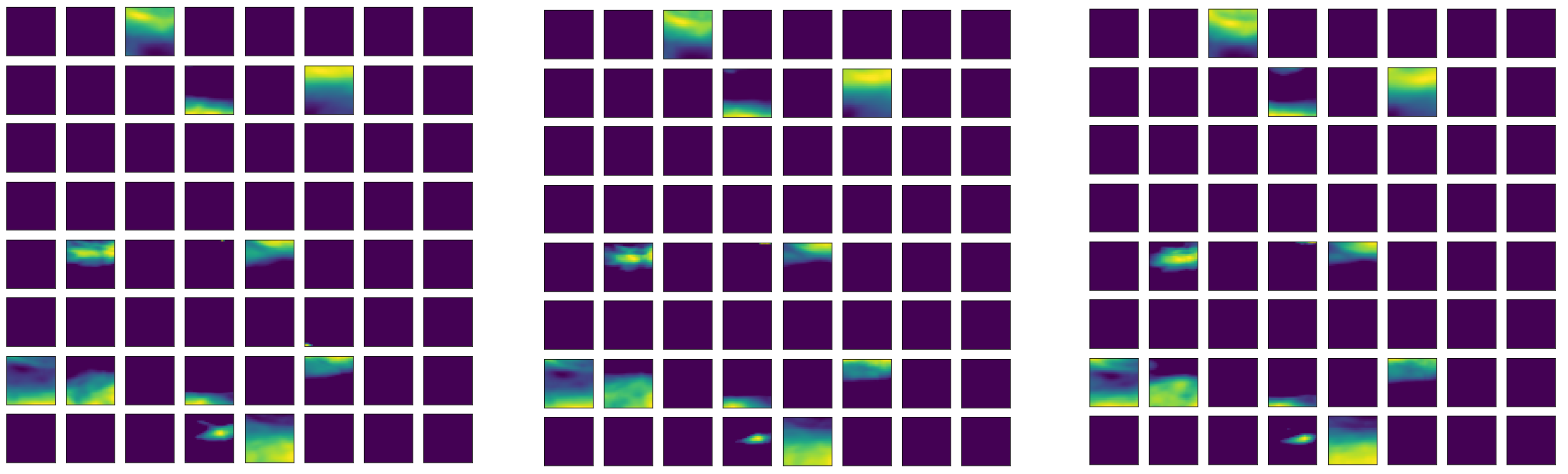
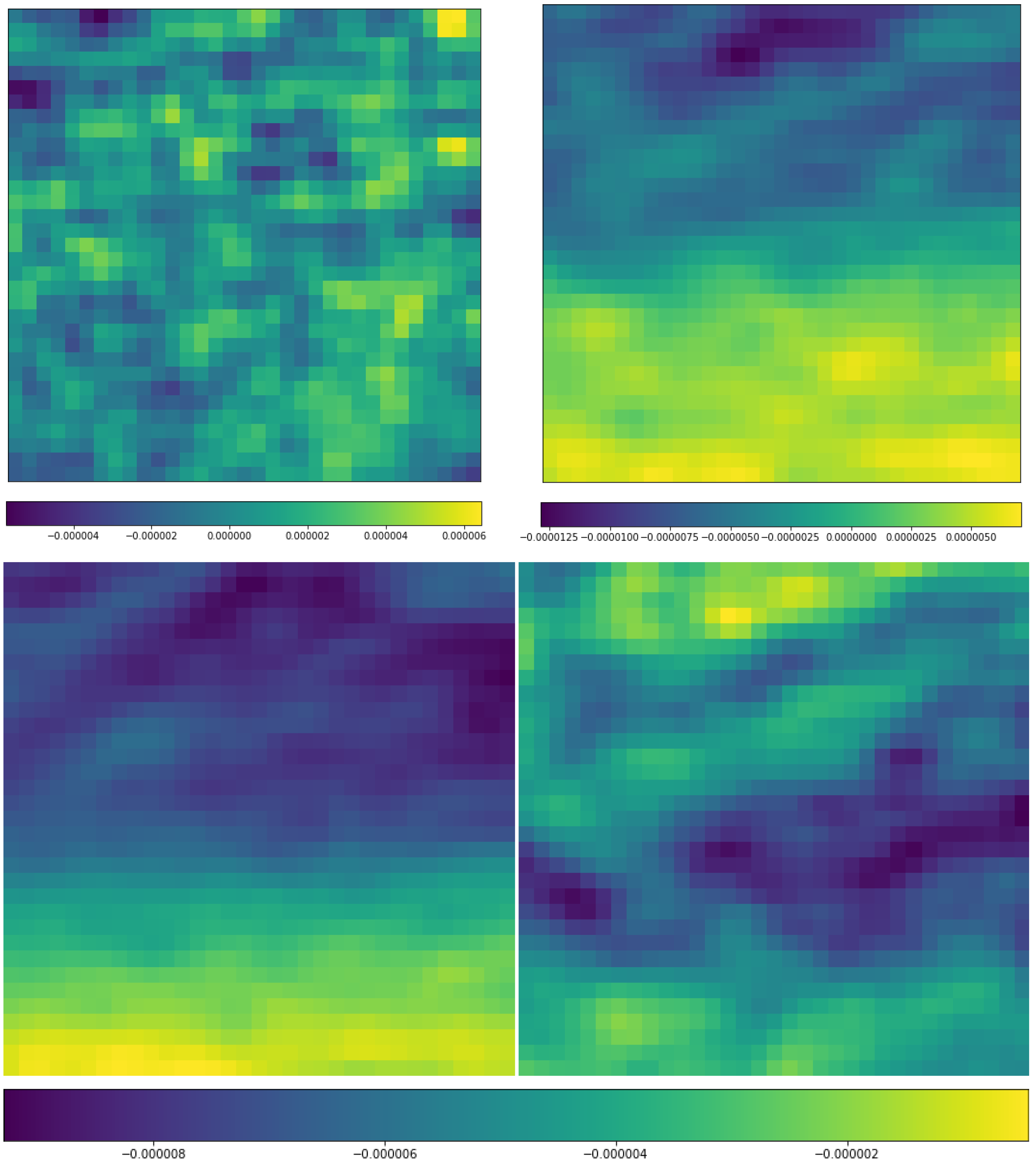
With the 14 × 4 × 37 × 33 × 33-dimensional ERA-Interim data, a more efficient auto-encoder network is a 3D Conv-auto-encoder. That is an auto-encoder with a group of 3D convolutional, activation (ReLU), and pooling layers. In each 3D convolutional layer, there are multiple 3D convolutional filters with learnable weights with an additional channel dimension on the input channels. Moreover, the 14 variables in ERA-Interim data are treated differently than the usual spatial or temporal dimension, and therefore, 14 different 3D Conv-auto-encoders are adopted to handle the ERA-Interim data.
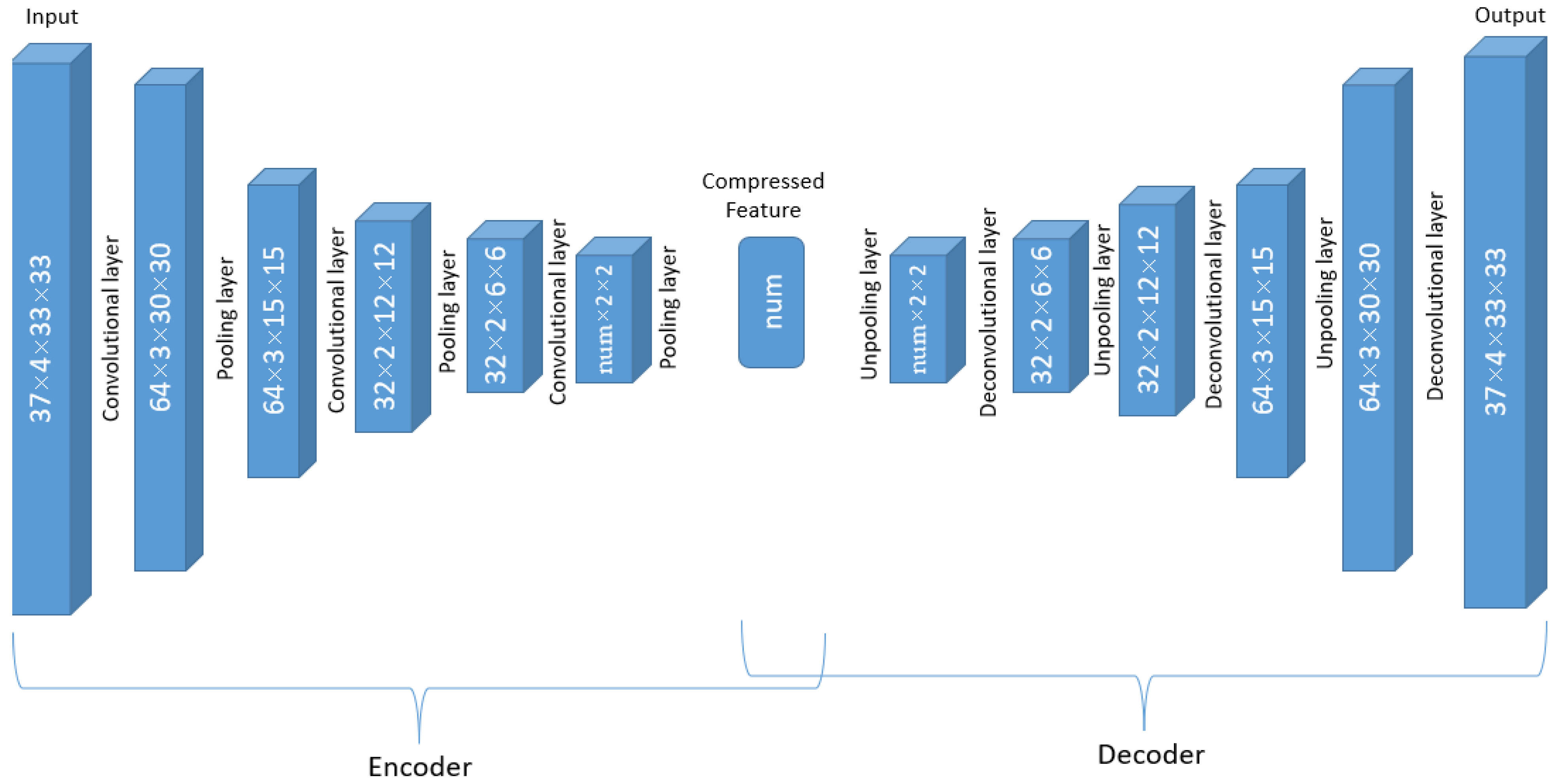
To be specific, the input of the encoder are observations with the dimension of 37 × 4 × 33 × 33, with pressure level (37) as its channel. There are 14 such auto-encoder networks. The network working on a single variable is elaborated below in detail, and the dimension changes in the data are displayed in
Figure 3.
The first convolution layer is with 64 different 37 (channel) × 2 × 4 × 4 filters and converts the 37 × 4 × 33 × 33 array for one variable to 64 3 × 30 × 30 arrays. In other words, a 37 × 2 × 4 × 4 filter is applied, and the results are summed up in the channel dimension (37), and therefore the vertical pressure layer dimension number is reduced to 1. This procedure is repeated 64 times with different convolution weights. Therefore, after the first convolution layer, the original 37 × 4 × 33 × 33 array becomes 64 3 × 30 × 30 arrays. The activation applied after each filter in the convolution layer does not change the array size and therefore is not shown in
Figure 3. After the convolution layer, A 1 × 2 × 2 pooling layer converts the 64 arrays with dimension 3 × 30 × 30 to 64 arrays with dimension 3 × 15 × 15.
The second convolution layer has 32 different filters with dimensions 64 × 2 × 4 × 4, and in this layer, the new dimension due to 64 different filters in the previous layer is considered to be “channels” and the filtered arrays will be summed over the channel dimension. As a result, each of the 32 filters converts the 64 × 3 × 15 × 15 array to 1 array with reduced dimensions 2 × 12 × 12 with the same operation as that of the first convolution layer, and finally, there are 32 such arrays. The same 1 × 2 × 2 pooling layer is then applied to the 32 2 × 12 × 12 arrays, and that results in 32 2 × 6 × 6 arrays. Similar to the previous two convolutional layers, the third convolution layer has num different convolution filters 32 × 2 × 5 × 5, and the dimension of 32 is treated as the channel again. The result after this filtering process is num arrays of dimension 1 × 2 × 2, where the num is a to-be-determined hyperparameter. Finally, the last 1 × 2 × 2 pooling layers will compress the arrays into num scalar features.
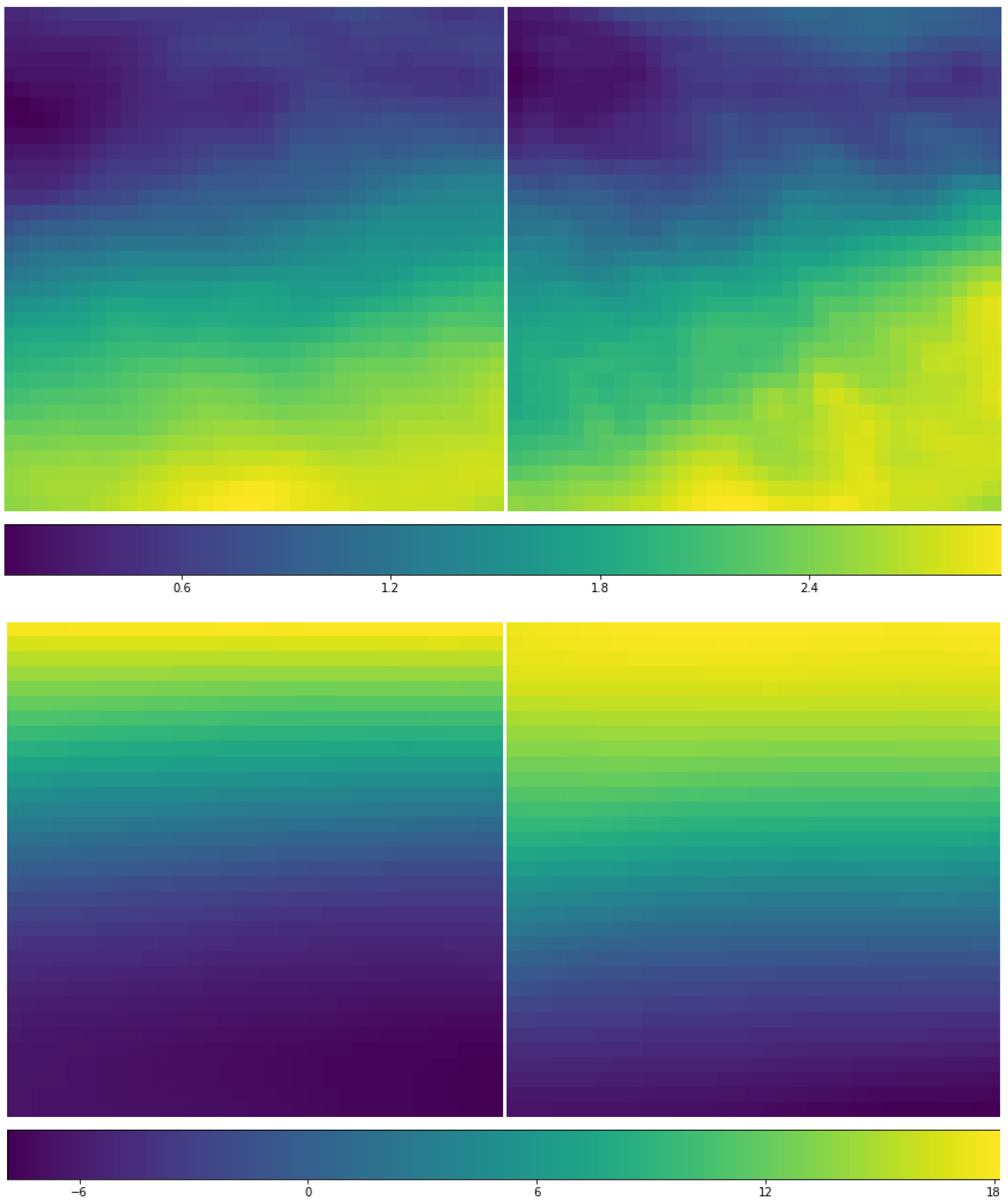
The decoder is the reverse of the encoder using the deconvolutional and unpooling layers in DeConvNet network [
40,
41,
42] to reconstruct the convolutional networks, i.e., reverse the convolution and the pooling operations. More details about DeConvNet could be found in Zeiler et al. [
40,
41,
42].
The network is trained through the backpropagation, where the mean square error [
43] is used as the loss function, and Adam optimizer [
44] is used as the optimizer to update the filter weights through backpropagation.
Fourteen separated networks with the same structure displayed in
Figure 4 are trained separately for 14 different ERA-Interim variables. The compressed features from each of the networks are merged with filtered SHIPS variables and together used as the input of the GMM-SMOTE [
27,
28].



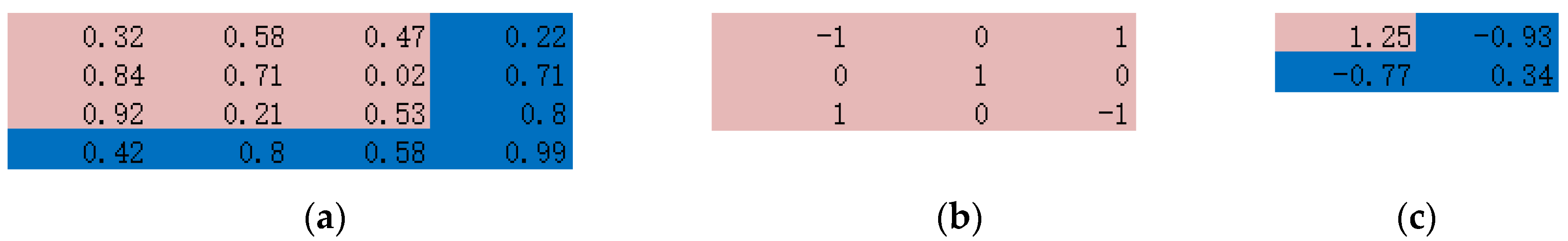{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













