
Research on Frequency Matching Correction Techniques for South China Precipitation Ensemble Forecast Based on the GRAPES Model

 , ,
, ,
Abstract
:1. Introduction
2. Data and Methods
2.1. Datasets
2.2. Correction Methods
2.3. Evaluation Methods
3. Comparative Analysis of Correction Experiment Cases
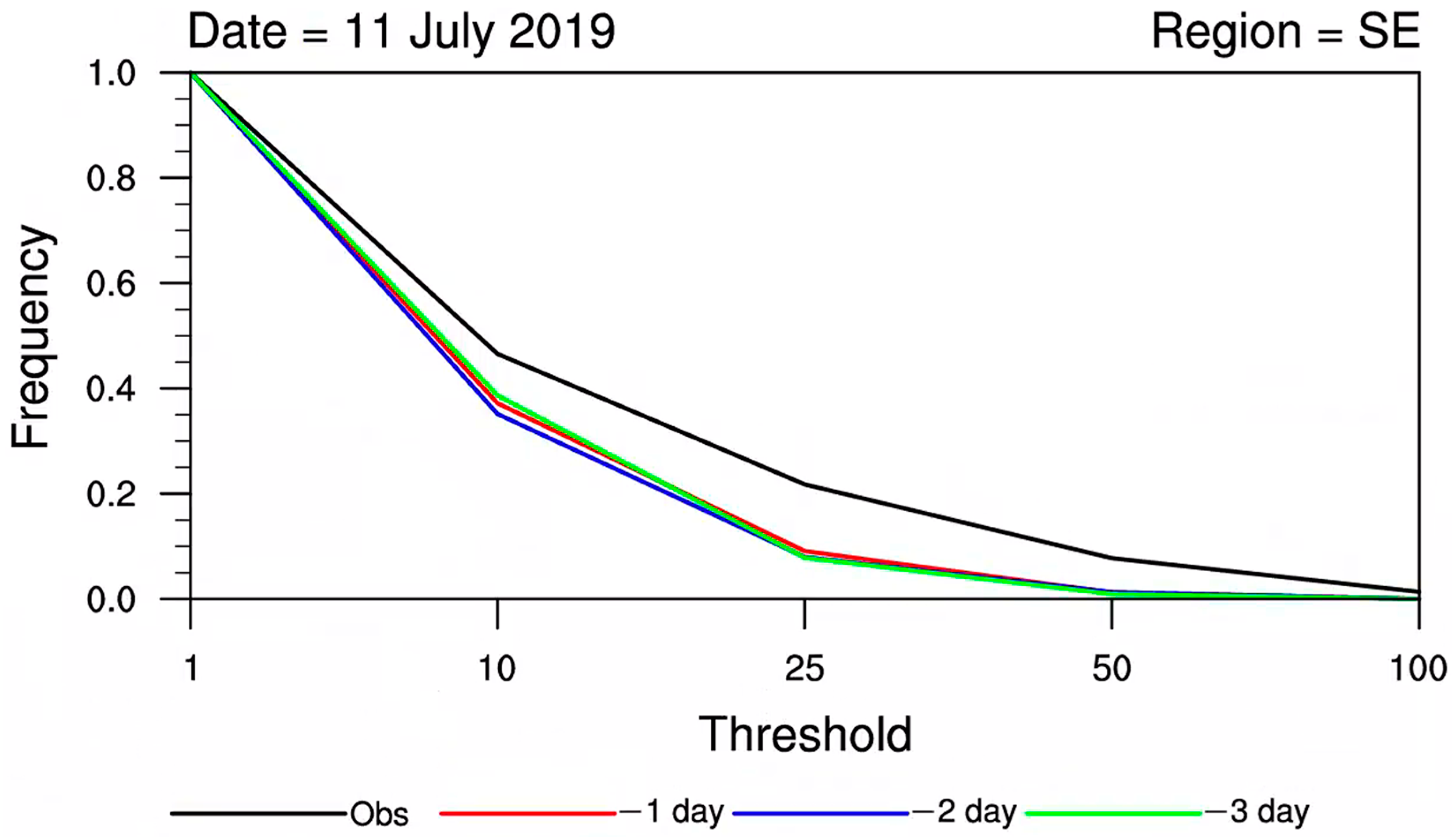
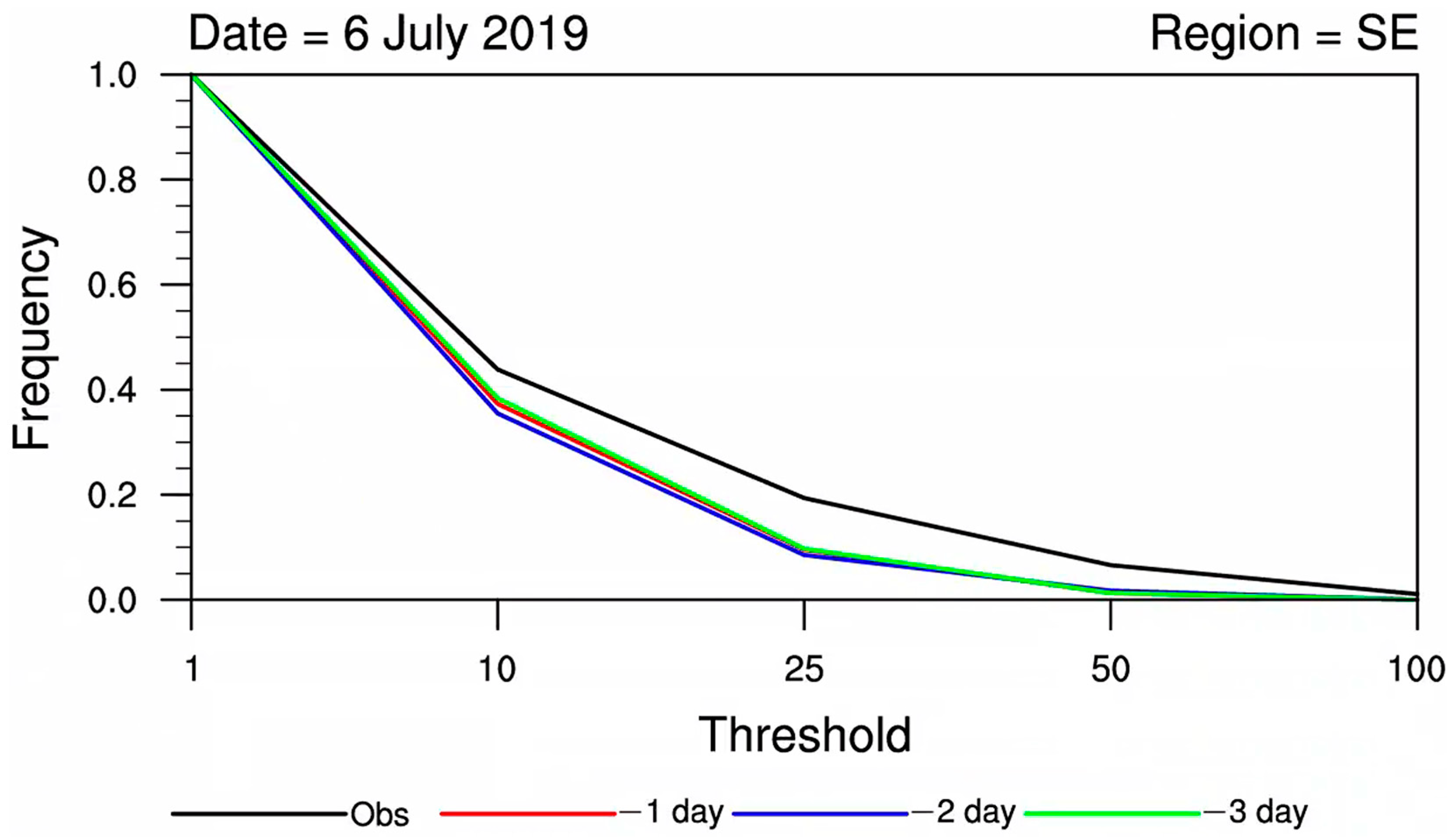
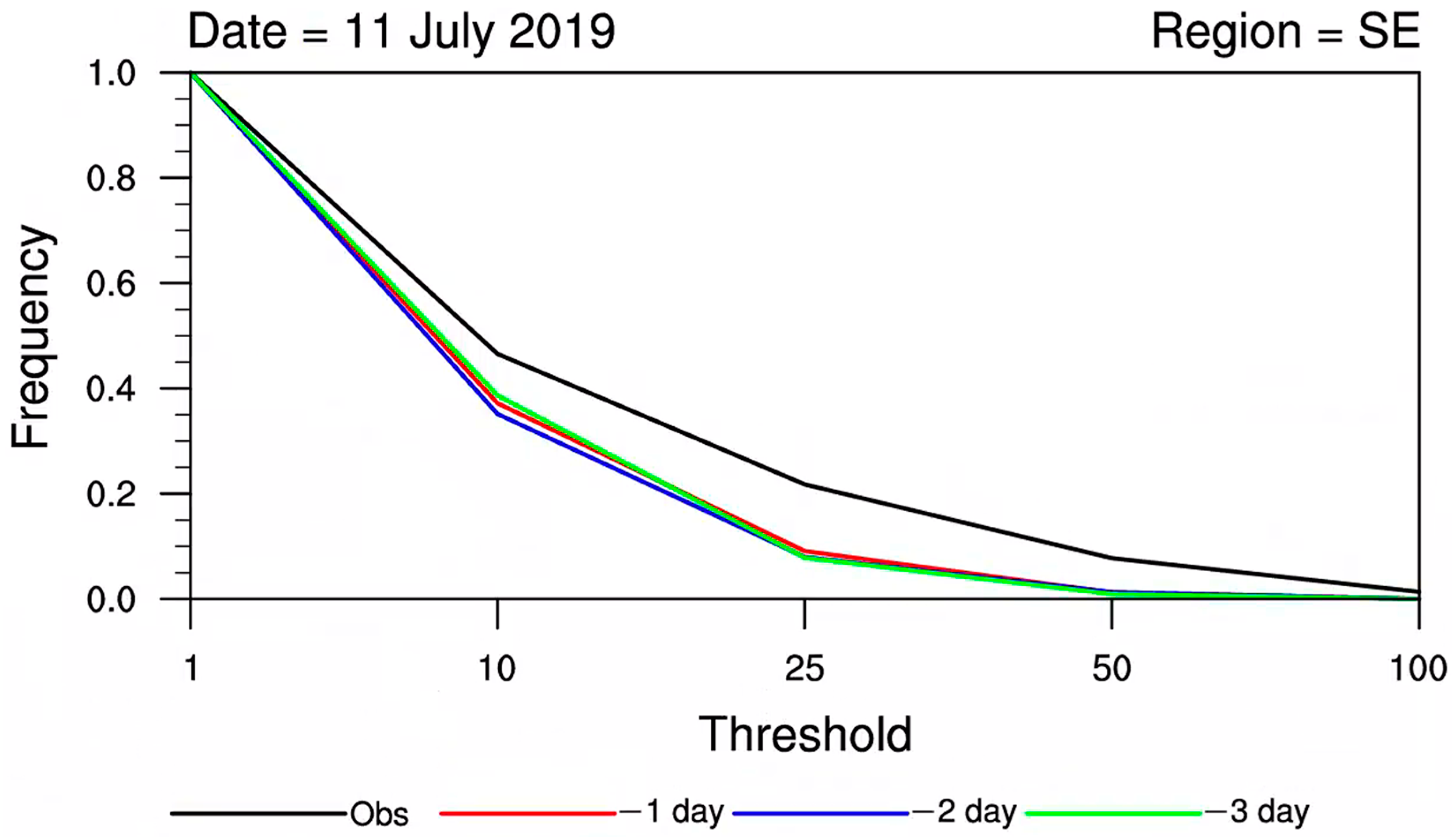
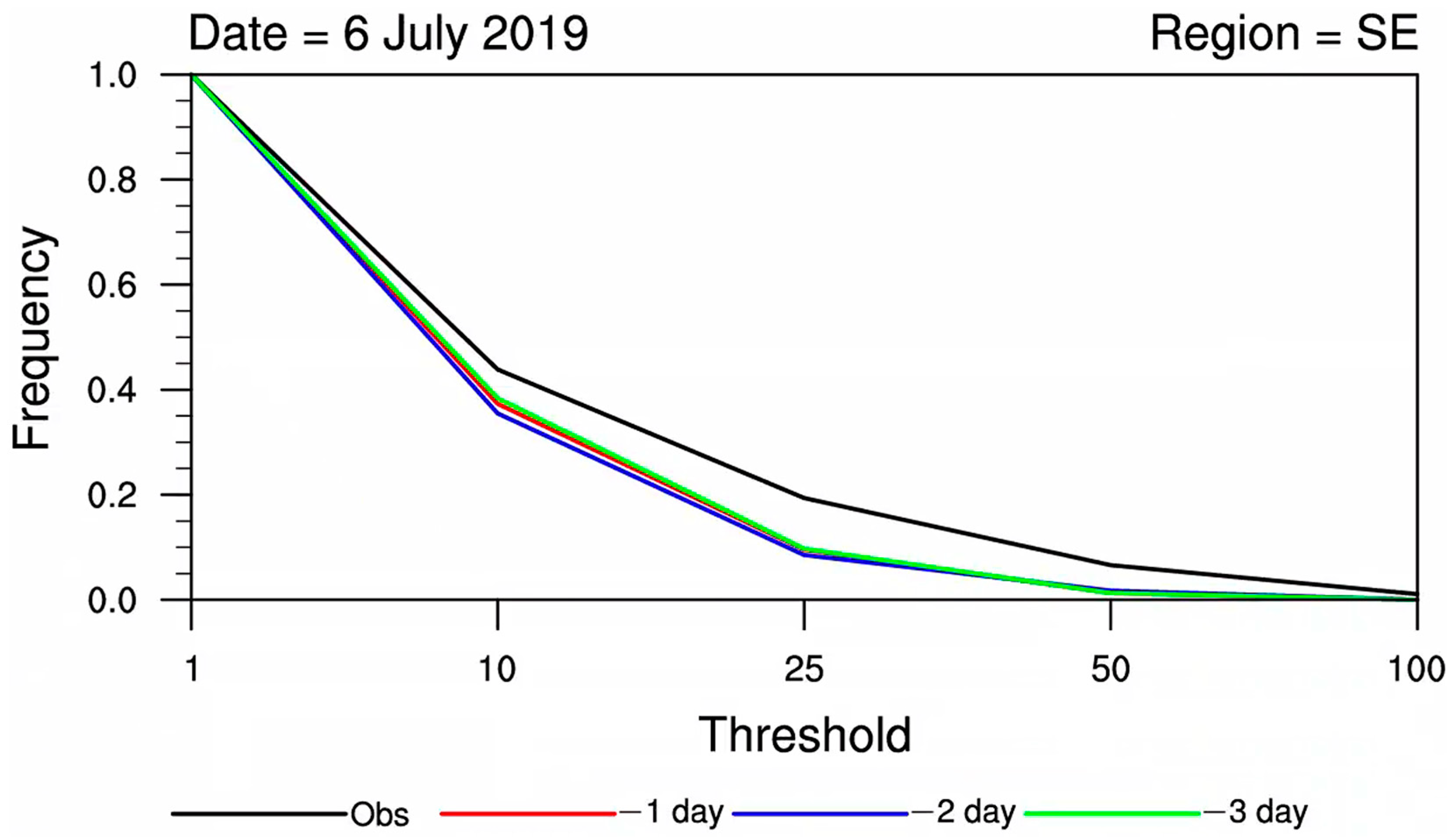
3.1. CDF Statistical Test Analysis
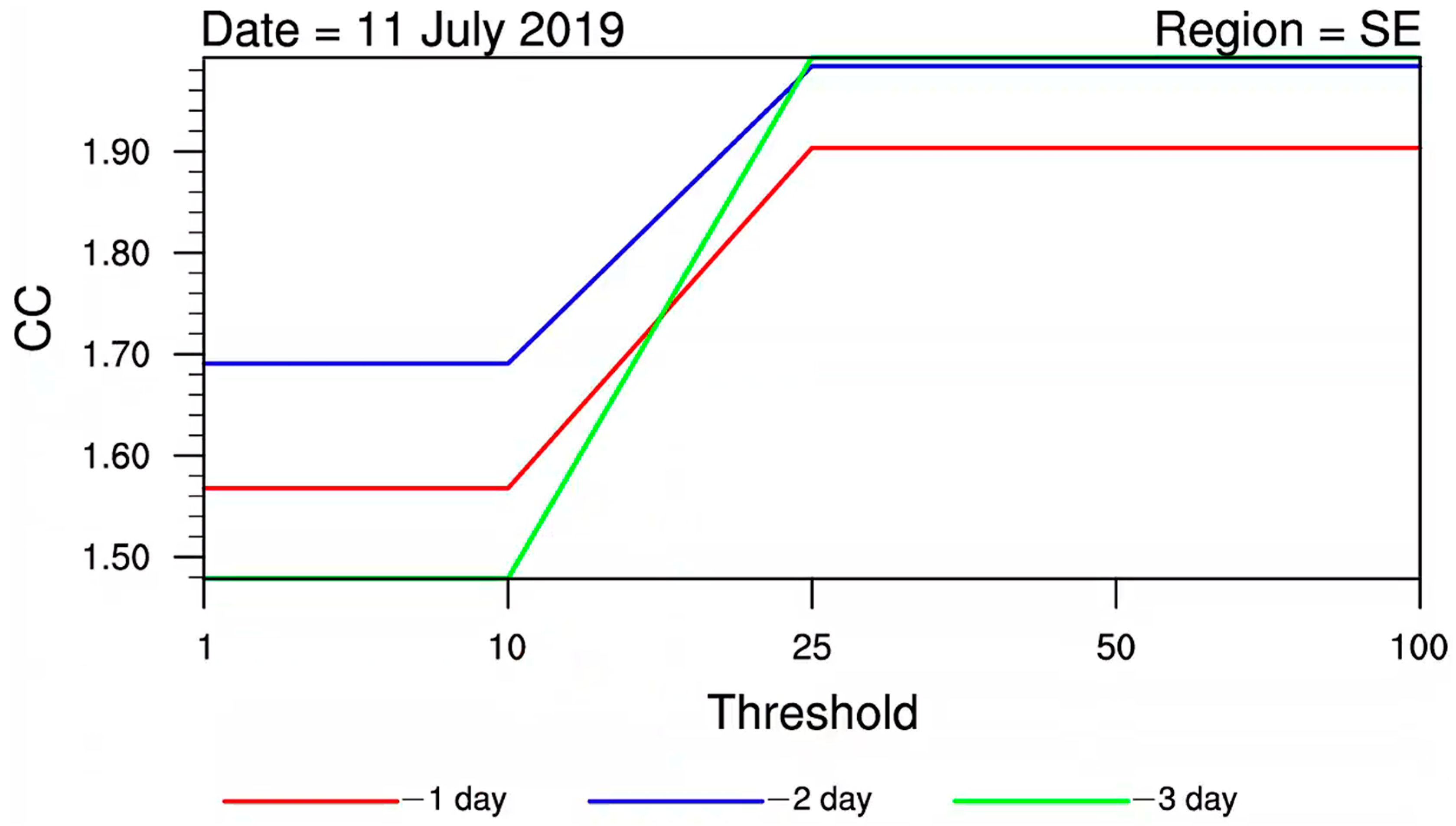
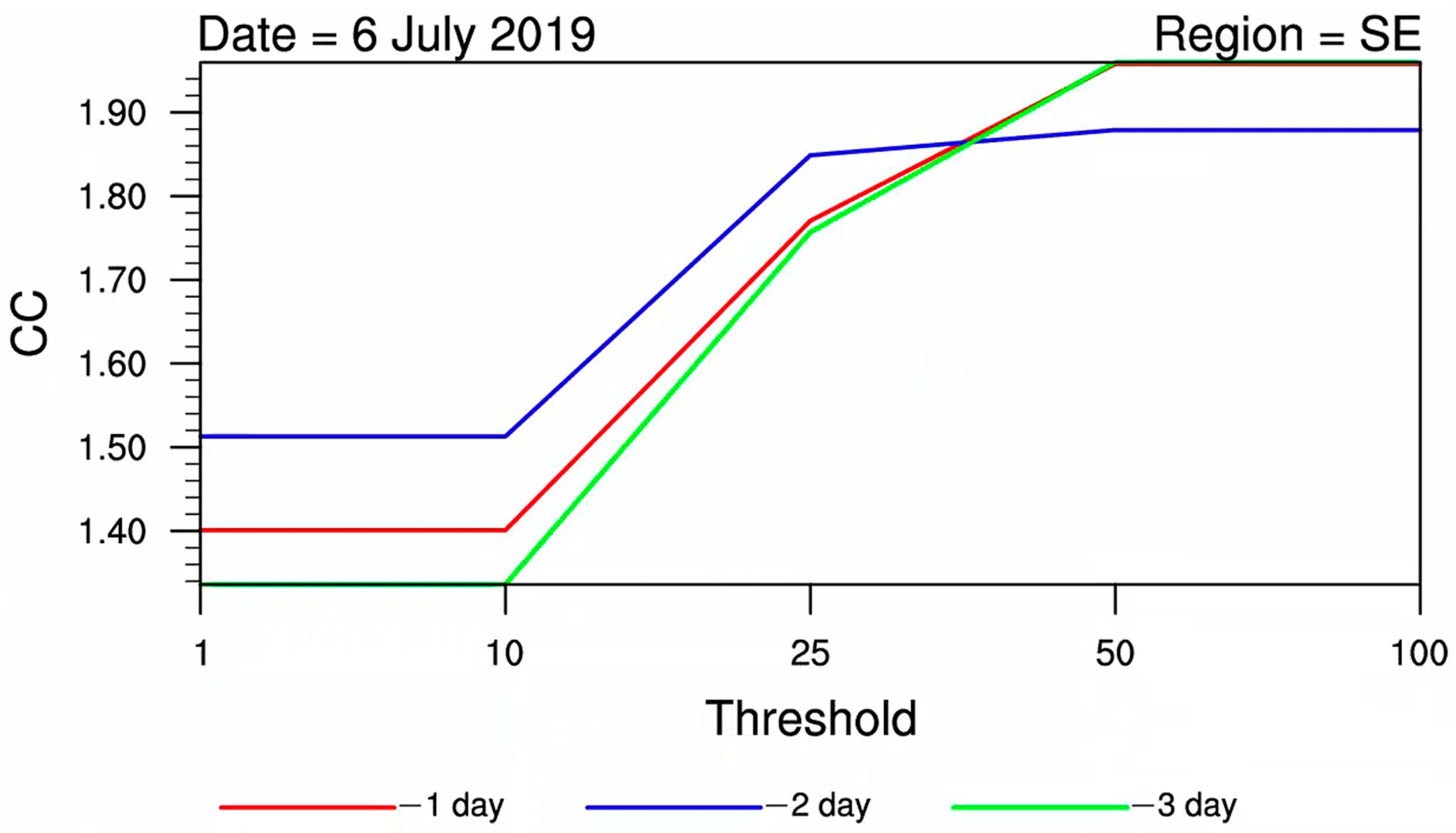
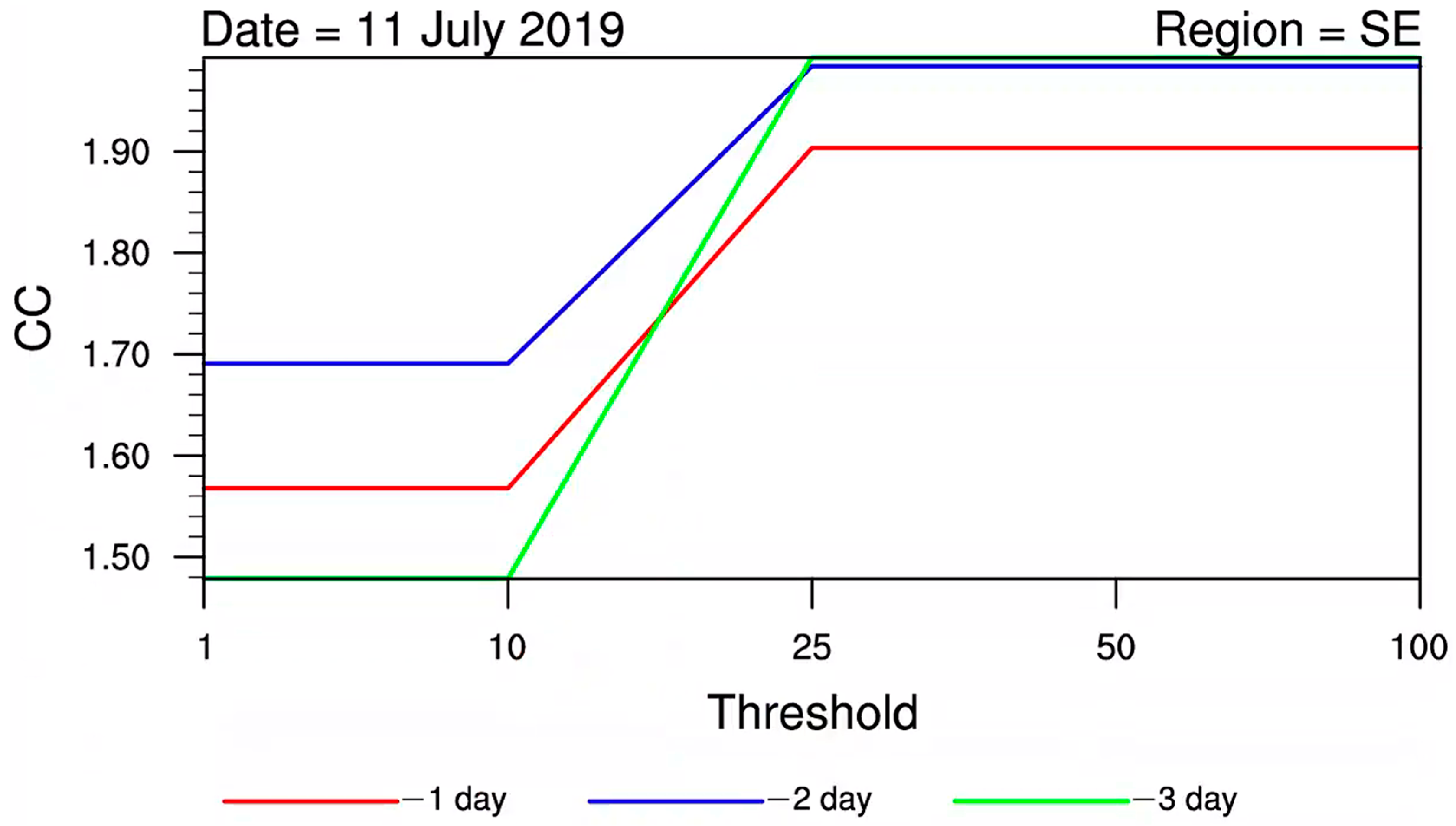
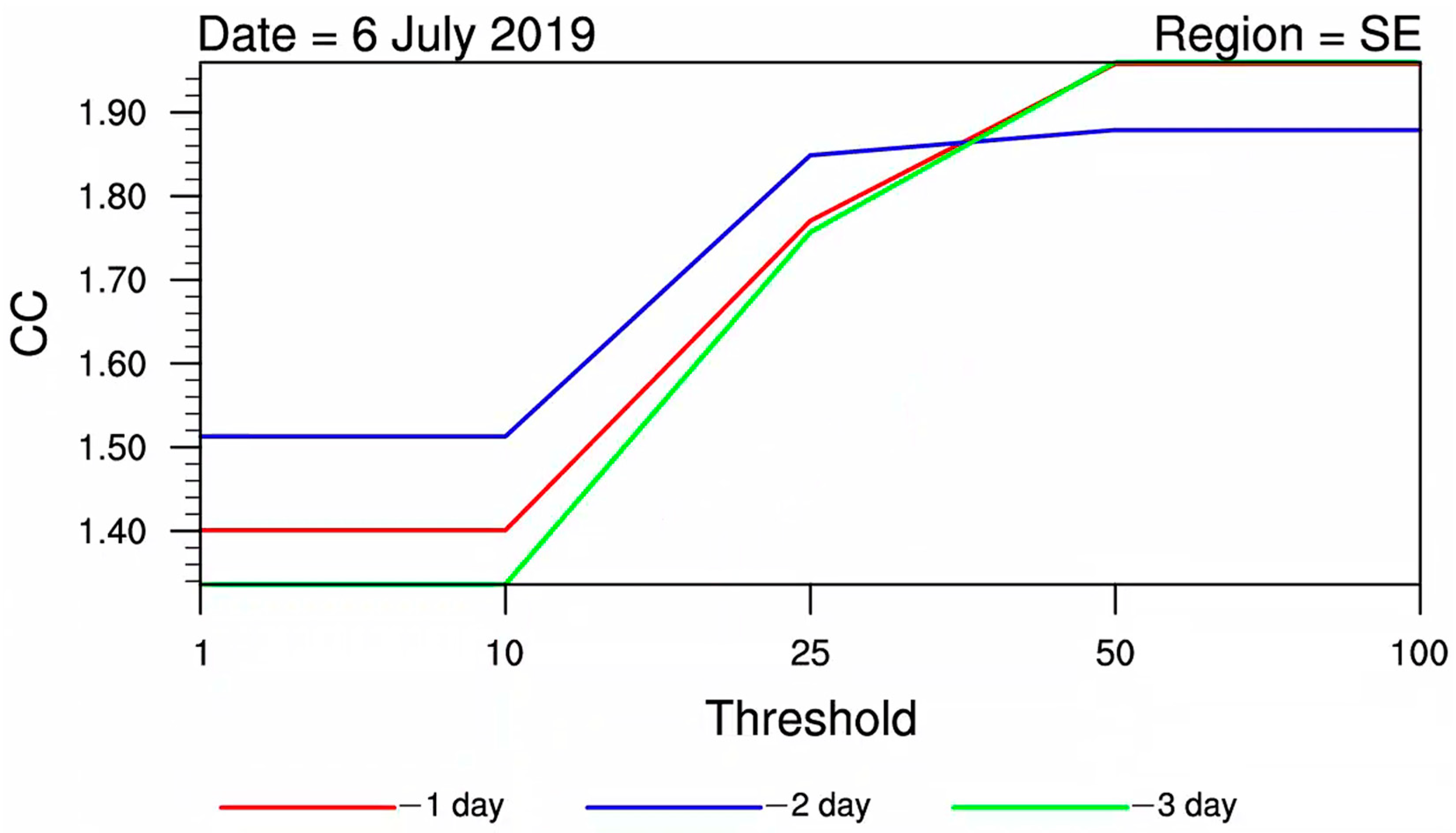
3.2. Correction Coefficient Analysis
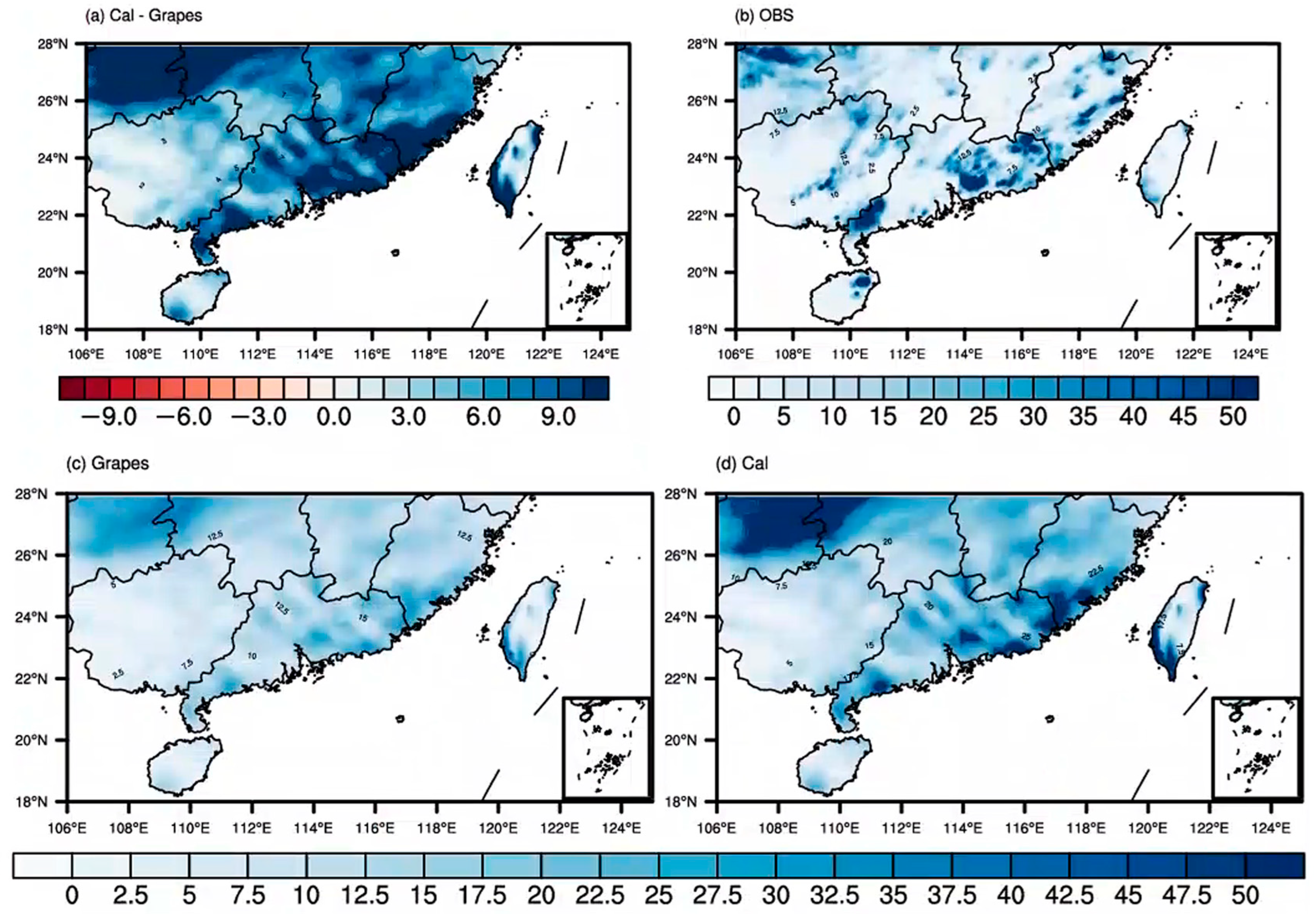
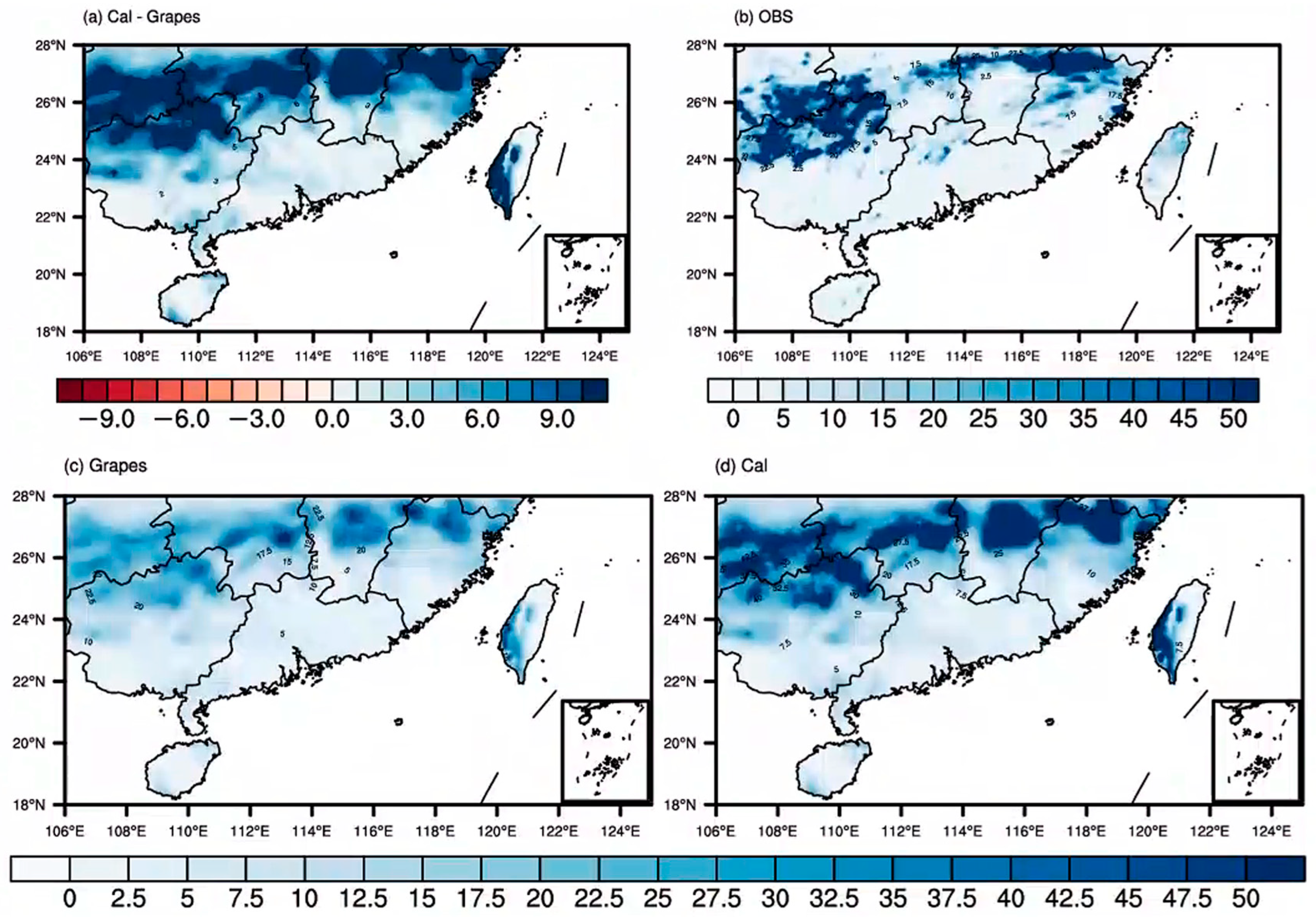
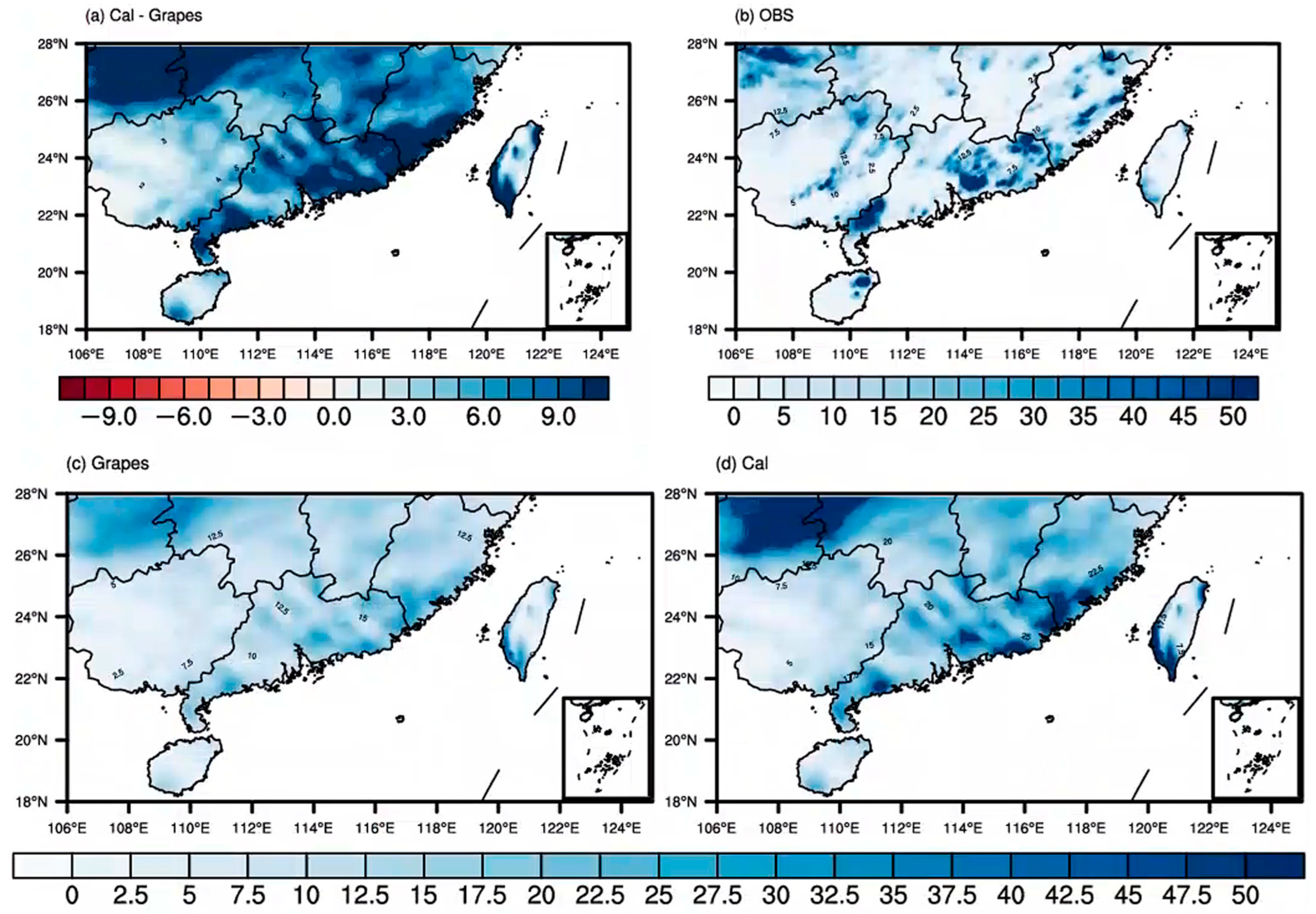
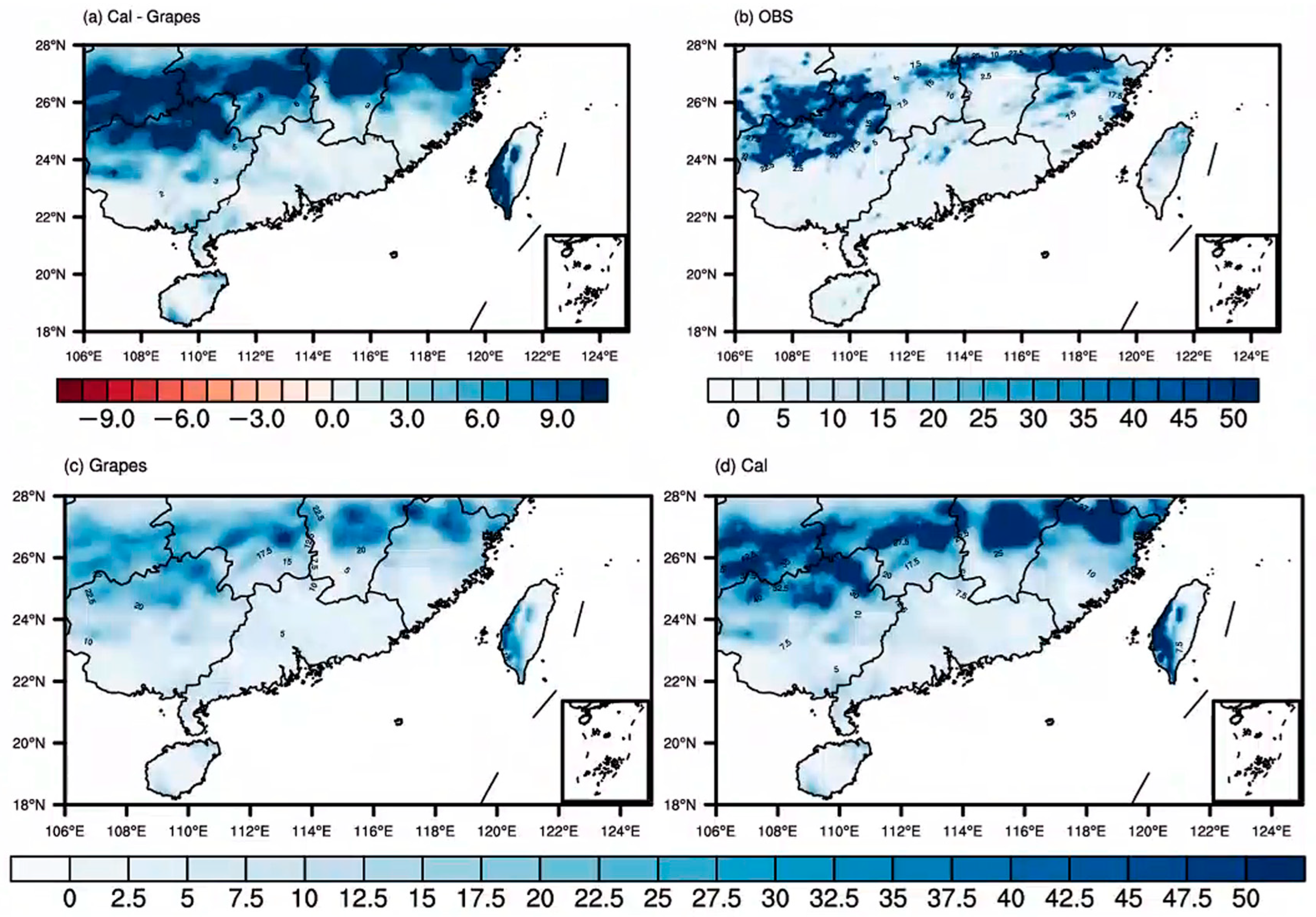
3.3. Comparative Analysis of Precipitation Distribution before and after Correction
4. Quantitative Comparison Analysis before and after Correction
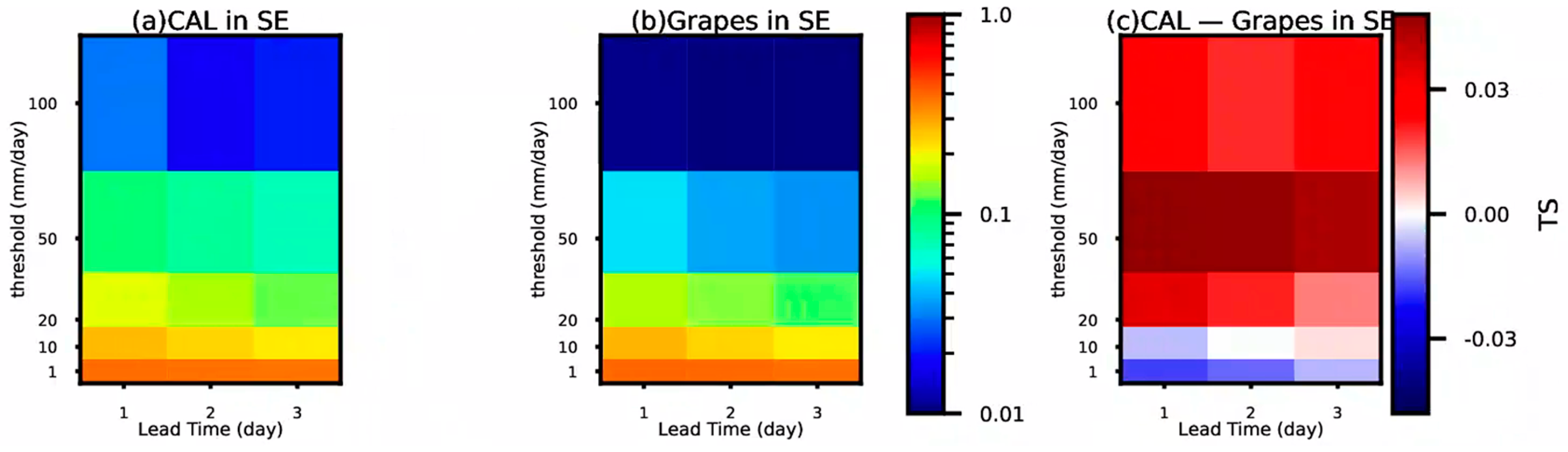
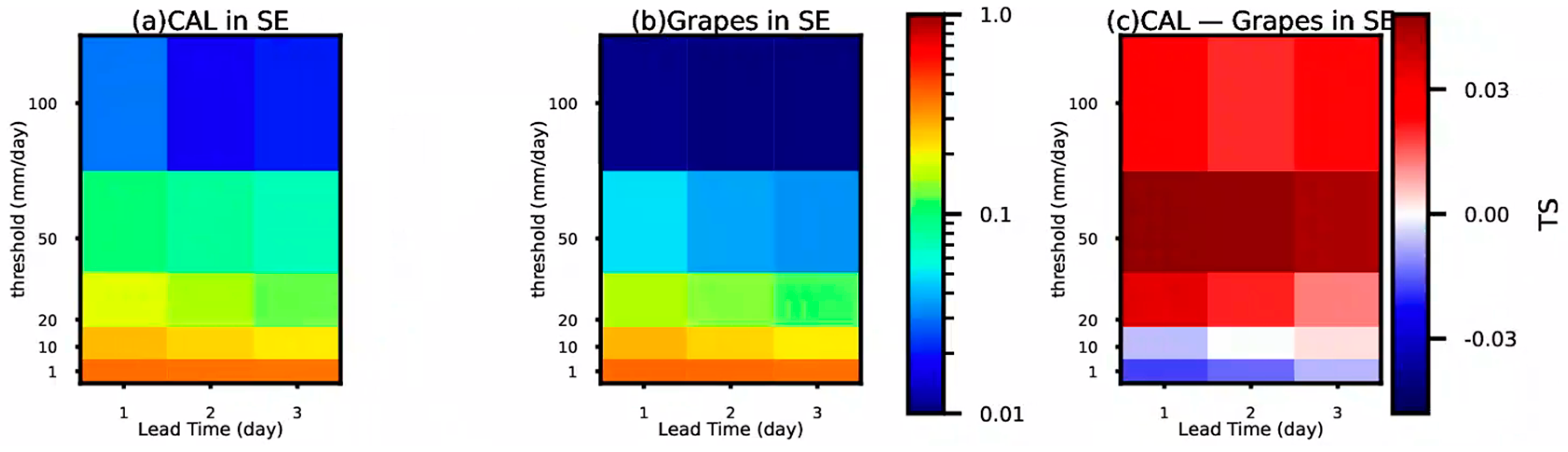
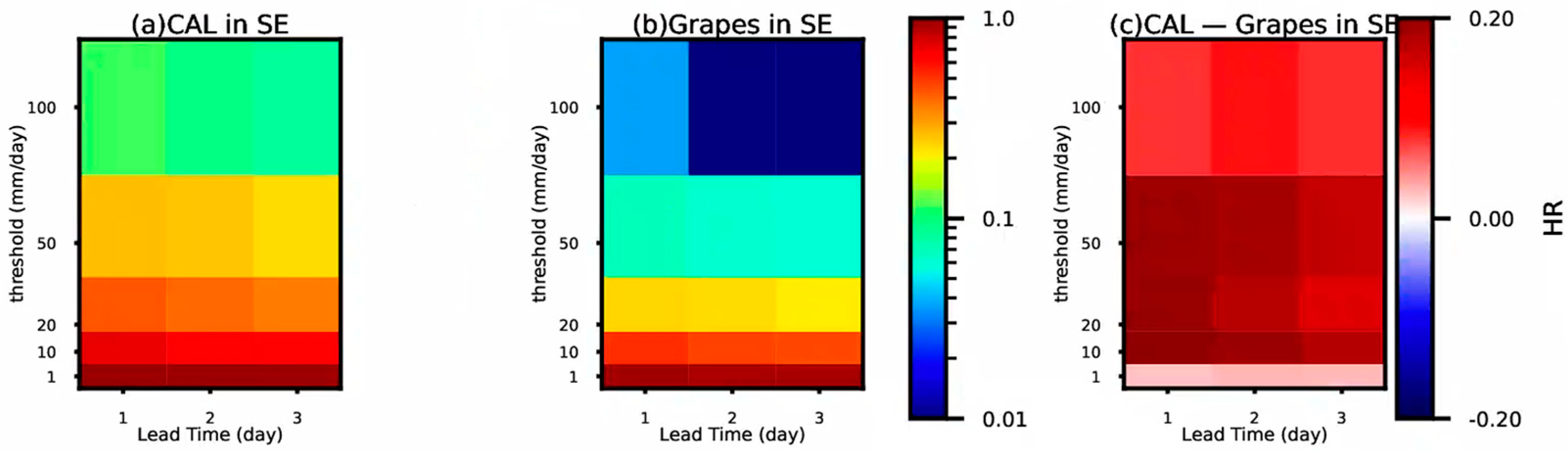
4.1. Comparative Analysis of TS Scores and Hit Rate
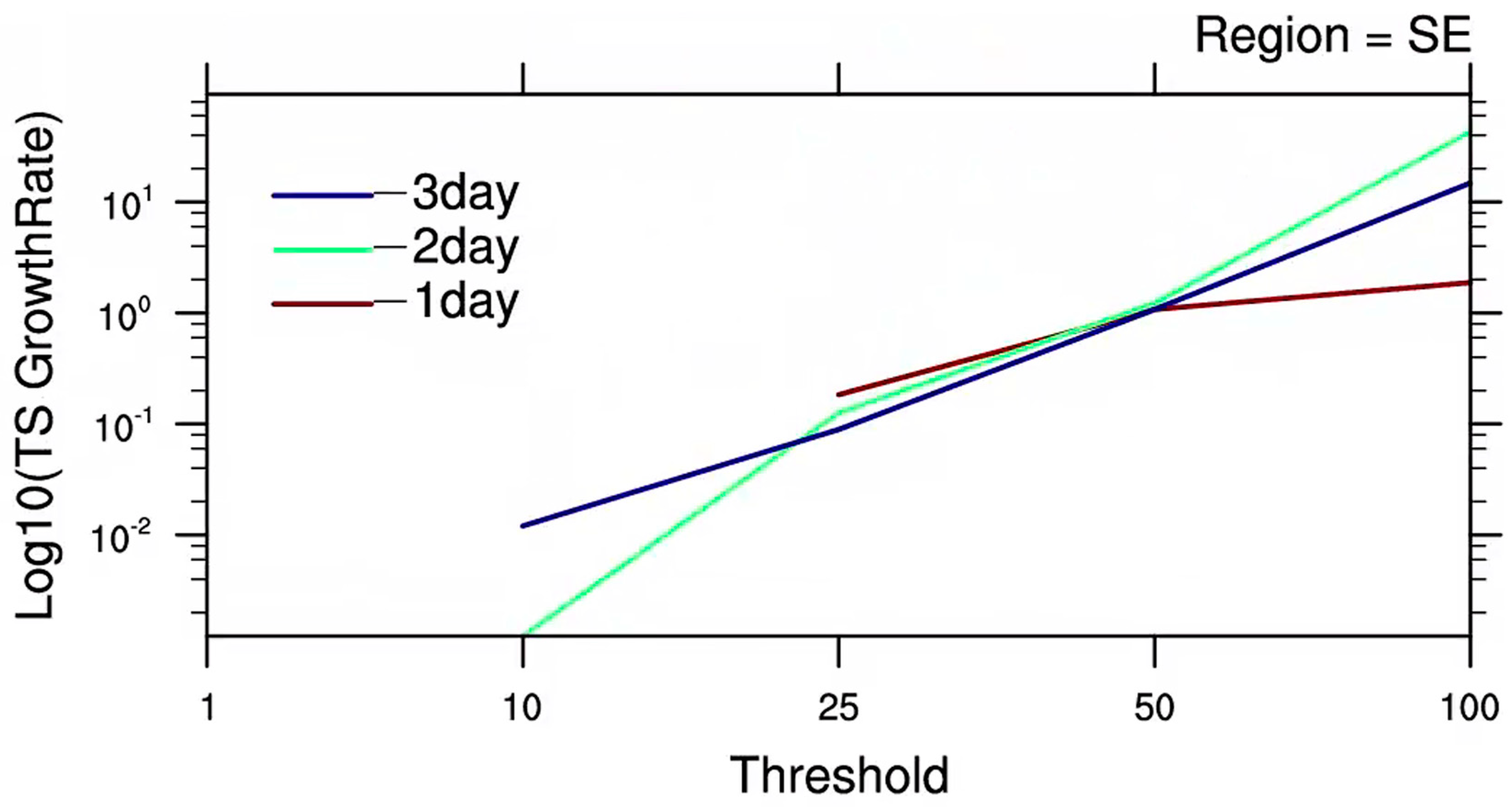
4.2. TS Score Growth Rate
5. Discussion and Conclusions
- (1)
- The model’s CDF curves exhibited deviations compared to observations, with the discrepancies becoming more pronounced with longer lead times. Therefore, the necessity for correction of model precipitation forecasts, especially for longer lead times, is apparent.
- (2)
- The CCs showed a gradually increasing trend with higher precipitation magnitudes, indicating that as the precipitation magnitude increases and the lead time extends, the necessity for correction becomes more significant.
- (3)
- Analysis of two precipitation cases in Southern China in July 2019 revealed through frequency matching correction that as precipitation magnitudes increase, the range of heavy rainfall expands. After frequency matching correction, the precipitation forecasts became more aligned with observations in terms of magnitude.
- (4)
- Statistical tests using TS scores demonstrated that frequency matching correction has a certain corrective effect on precipitation forecasts in Southern China overall, particularly for forecasts with longer lead times and higher precipitation magnitudes, where the correction effect was more pronounced.
- (5)
- Frequency matching correction showed a certain corrective effect for heavy rainfall and above magnitudes of precipitation. Additionally, for shorter lead times, the TS scores after correction were higher compared to before correction.
- (6)
- The necessity for frequency matching correction becomes more apparent for heavier precipitation events. Furthermore, the correction effect becomes more pronounced with longer lead times.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Du, J.; Kang, Z.M. A Survey on Forecasters’ View about Uncertainty in Weather Forecasts. Adv. Meteorol. Sci. Technol. 2014, 4, 58–67. [Google Scholar]
- Wei, M.Z.; Toth, Z.; Wobus, R.; Zhu, Y. Initial perturbations based on the ensemble transform (ET) technique in the NCEP global operational forecast system. Tellus A 2008, 60, 62–79. [Google Scholar] [CrossRef]
- Houtekamer, P.L.; Mitchell, H.L. Ensemble Kalman filtering. Q. J. R. Meteorol. Soc. 2005, 131, 3269–3289. [Google Scholar] [CrossRef]
- Houtekamer, P.L.; Charron, M.; Mitchell, H.L.; Pellerin, G. Status of the global EPS at environment Canada. In Proceedings of the ECMWF Workshop on Ensemble Prediction, Reading, UK, 7–9 November 2007; ECMWF: Reading, UK; pp. 57–68. [Google Scholar]
- Zhou, X.Q.; Zhu, Y.J.; Hou, D.C.; Kleist, D. A comparison of perturbations from an ensemble transform and an ensemble Kalman filter for the NCEP global ensemble forecast system. Weather Forecast. 2016, 31, 2057–2074. [Google Scholar] [CrossRef]
- Zhu, Y.J.; Li, W.; Zhou, X.Q.; Hou, M. Stochastic Representation of NCEP GEFS to Improve Sub-Seasonal Forecast; Springer Atmospheric Sciences; Springer: Singapore, 2019; pp. 317–328. [Google Scholar]
- Epstein, E.S. Stochastic dynamic prediction. Tellus 1969, 21, 739–759. [Google Scholar] [CrossRef]
- Leith, C.E. Theoretical skill of Monte Carlo forecasts. Mon. Weather. Rev. 1974, 102, 409–418. [Google Scholar] [CrossRef]
- Palmer, T.N.; Brankovic, C.; Richardson, D.S. A probability and decision-model analysis of PROVOST seasonal multi-model ensemble integrations. Q. J. R. Meteorol. Soc. 2000, 126, 2013–2033. [Google Scholar]
- Richardson, D.S. Skill and relative economic value of the EC-MWF ensemble prediction system. Q. J. R. Meteorol. Soc. 2000, 126, 649–668. [Google Scholar] [CrossRef]
- Wang, R.; Liang, Y.; Cai, H.; Zheng, J. Ability of the GRAPES Ensemble Forecast Product to Forecast Extreme Temperatures over the Tibetan Plateau. Atmosphere 2023, 14, 1625. [Google Scholar] [CrossRef]
- Ren, P.; Gao, L.; Zheng, J.; Cai, H. Key Factors of the Strong Cold Wave Event in the Winter of 2020/21 and Its Effects on the Predictability in CMA-GEPS. Atmosphere 2023, 14, 564. [Google Scholar] [CrossRef]
- Cai, H.; Zhao, Z.; Zheng, J.; Luo, W.; Li, H. Evaluation of the Dynamical–Statistical Downscaling Model for Extended Range Precipitation Forecasts in China. Atmosphere 2022, 13, 1663. [Google Scholar] [CrossRef]
- Zheng, J.; Ren, P.; Chen, B.; Zhang, X.; Cai, H.; Li, H. Research on a Clustering Forecasting Method for Short-Term Precipitation in Guangdong Based on the CMA-TRAMS Ensemble Model. Atmosphere 2023, 14, 1488. [Google Scholar] [CrossRef]
- Wu, M.; Luo, Y.; Chen, F.; Wong, W.K. Observed link of extreme hourly precipitation changes to urbanization over coastal South China. J. Appl. Meteor. Climatol. 2019, 58, 1799–1819. [Google Scholar] [CrossRef]
- Du, J.; Mullen, S.L.; Sanders, F. Short-range ensemble forecasting of quantitative precipitation. Mon. Weather. Rev. 1997, 125, 2427–2456. [Google Scholar] [CrossRef]
- Ebert, E.E. Ability of a poor man’s ensemble to predict the probability and distribution of precipitation. Mon. Weather. Rev. 2001, 129, 2461–2480. [Google Scholar] [CrossRef]
- Li, L.; Zhu, Y.J. The Establishment and Research of T213 Precipitation Calibration System. J. Appl. Met. Eorological. Sci. 2006, 17, 130–134. [Google Scholar]
- Li, J.; Du, J.; Chen, C.J. Introduction and Analysis to Frequency or Area Matching Method Applied to Precipitation Forecast Bias Correction. Meteorol. Mon. 2014, 40, 580–588. [Google Scholar]
- Li, J.; Du, J.; Chen, C.J. Applications of “Frequency-Matching” Method to Ensemble Precipitation Forecasts. Meteorol. Mon. 2015, 41, 674–684. [Google Scholar]
- Li, W.; Duan, Q.; Miao, C.; Ye, A.; Gong, W.; Di, Z. A review on statistical post processing methods for hydro meteorological ensemble forecasting. WIREs Water 2017, 4, e1246. [Google Scholar] [CrossRef]
- Duan, Q.; Pappenberger, F.; Wood, A.; Cloke, H.L.; Schaake, J.C. Hand-Book of Hydrometeorological Ensemble Forecasting; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Shahi, N.K.; Polcher, J.; Bastin, S.; Pennel, R.; Fita, L. Assessment of the spatio-temporal variability of the added value on precipitation of convection-permitting simulation over the Iberian Peninsula using the RegIPSL regional earth system model. Clim. Dyn. 2022, 59, 471–498. [Google Scholar] [CrossRef]
- Shahi, N.K.; Rai, S.; Sahai, A.K.; Abhilash, S. Intra-seasonal variability of the South Asian monsoon and its relationship with the Indo–Pacific sea-surface temperature in the NCEP CFSv2. Int. J. Climatol. 2018, 38, e28–e47. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Observation | Precipitation Occurs | No Precipitation | |
|---|---|---|---|
| Forecast | |||
| Precipitation Occurs | NA | NB | |
| No Precipitation | NC | ND | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, J.; Zheng, J.; Cai, H.; Zhao, X.; Yang, D.; Wang, L. Research on Frequency Matching Correction Techniques for South China Precipitation Ensemble Forecast Based on the GRAPES Model. Atmosphere 2024, 15, 466. https://doi.org/10.3390/atmos15040466
Dang J, Zheng J, Cai H, Zhao X, Yang D, Wang L. Research on Frequency Matching Correction Techniques for South China Precipitation Ensemble Forecast Based on the GRAPES Model. Atmosphere. 2024; 15(4):466. https://doi.org/10.3390/atmos15040466
Chicago/Turabian StyleDang, Jiantao, Jiawen Zheng, Hongke Cai, Xiaoping Zhao, Daoyong Yang, and Lianjie Wang. 2024. "Research on Frequency Matching Correction Techniques for South China Precipitation Ensemble Forecast Based on the GRAPES Model" Atmosphere 15, no. 4: 466. https://doi.org/10.3390/atmos15040466
APA StyleDang, J., Zheng, J., Cai, H., Zhao, X., Yang, D., & Wang, L. (2024). Research on Frequency Matching Correction Techniques for South China Precipitation Ensemble Forecast Based on the GRAPES Model. Atmosphere, 15(4), 466. https://doi.org/10.3390/atmos15040466