Integration of a Parsimonious Hydrological Model with Recurrent Neural Networks for Improved Streamflow Forecasting




Abstract
:1. Introduction
2. Materials and Methods
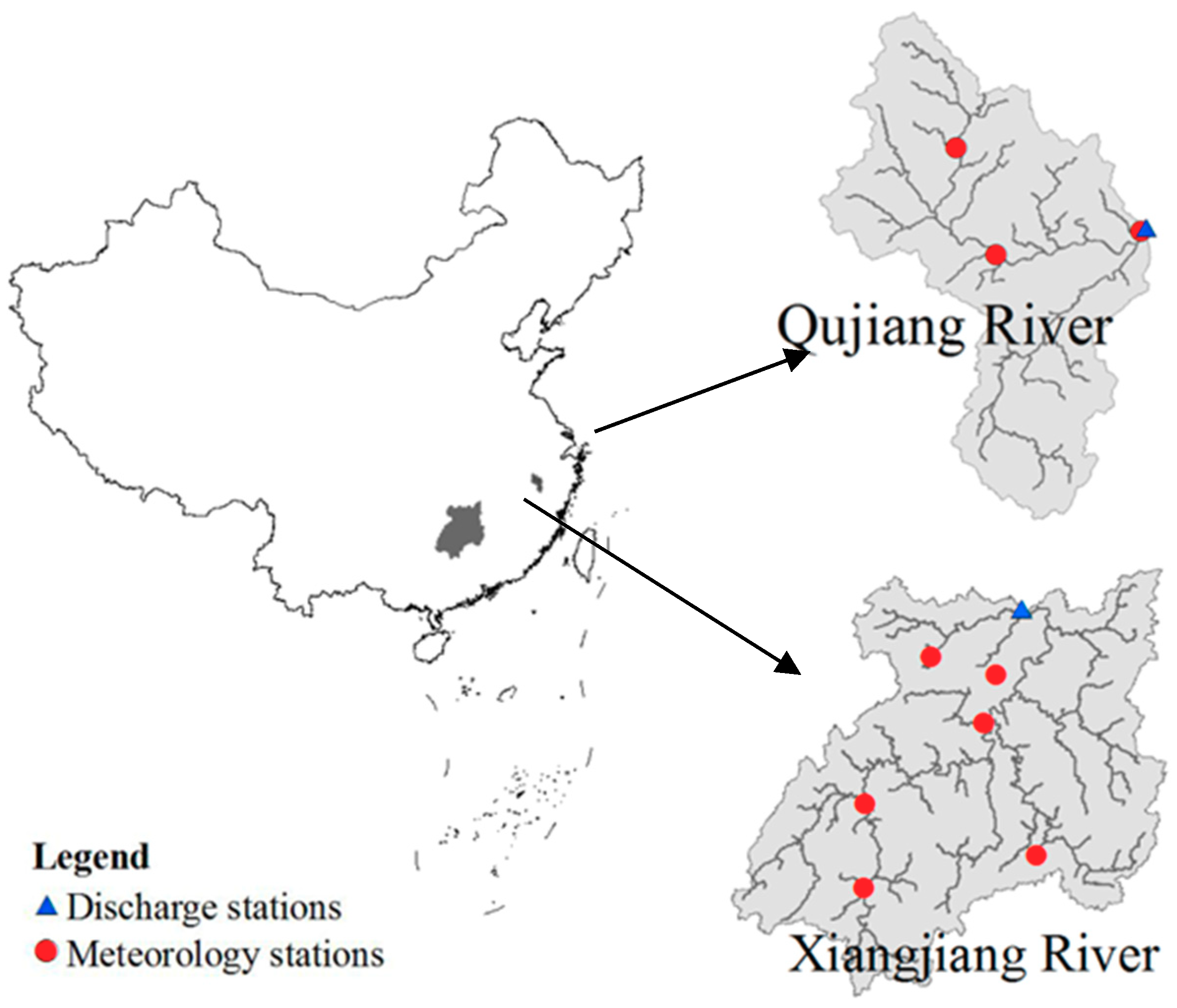
2.1. Data and Study Area
2.2. GR4J Model
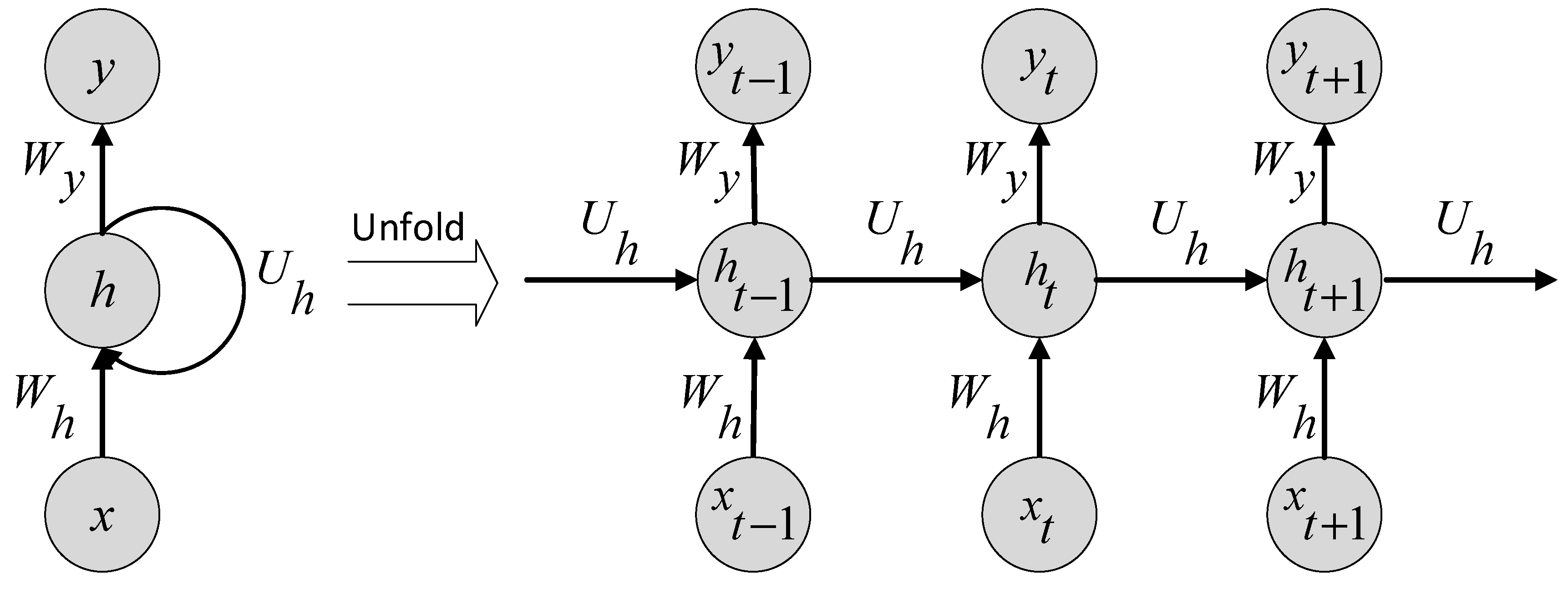
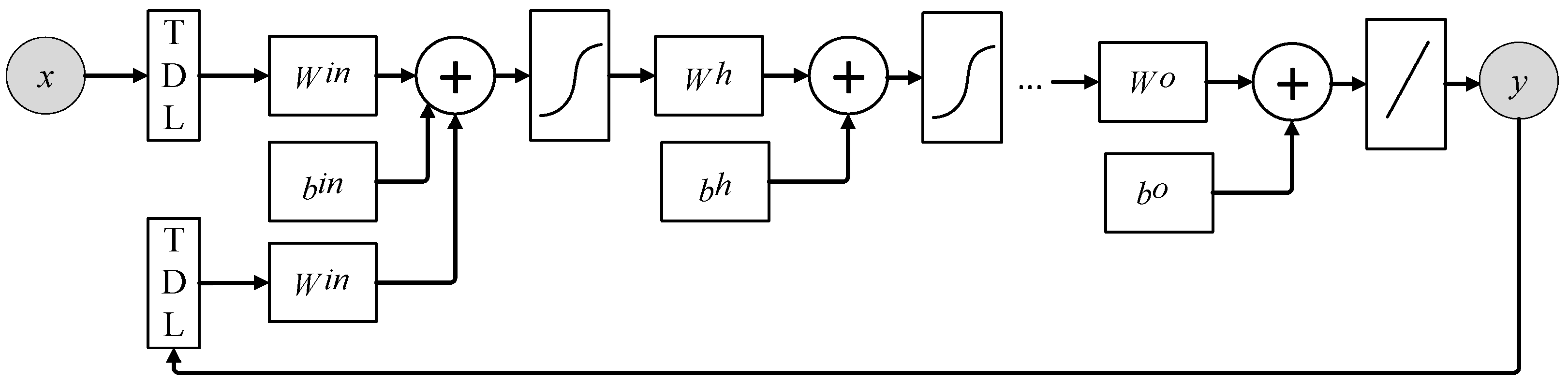
2.3. Elman Recurrent Neural Network
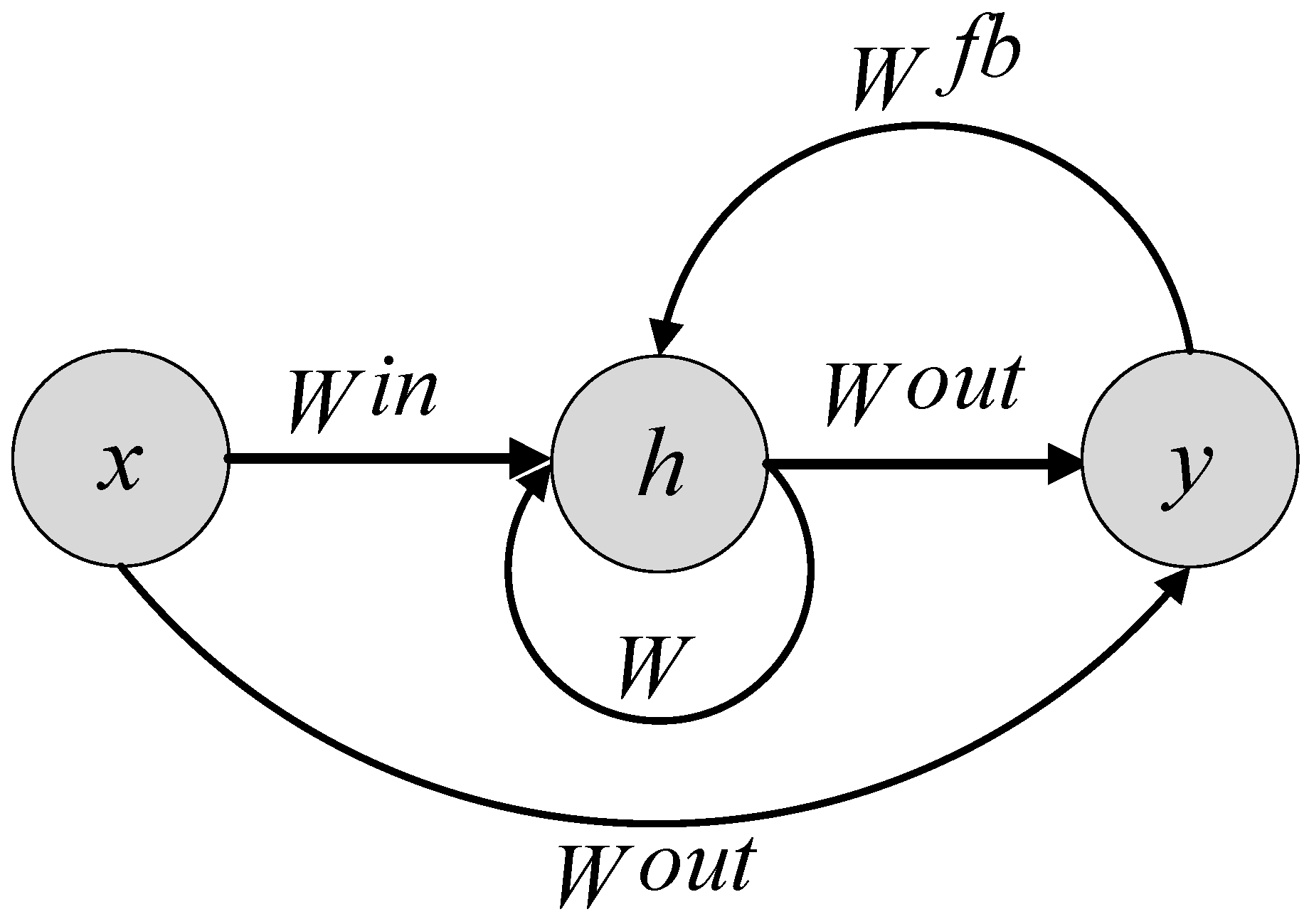
2.4. Echo State Network
2.5. Nonlinear Autoregressive Exogenous Inputs Neural Network
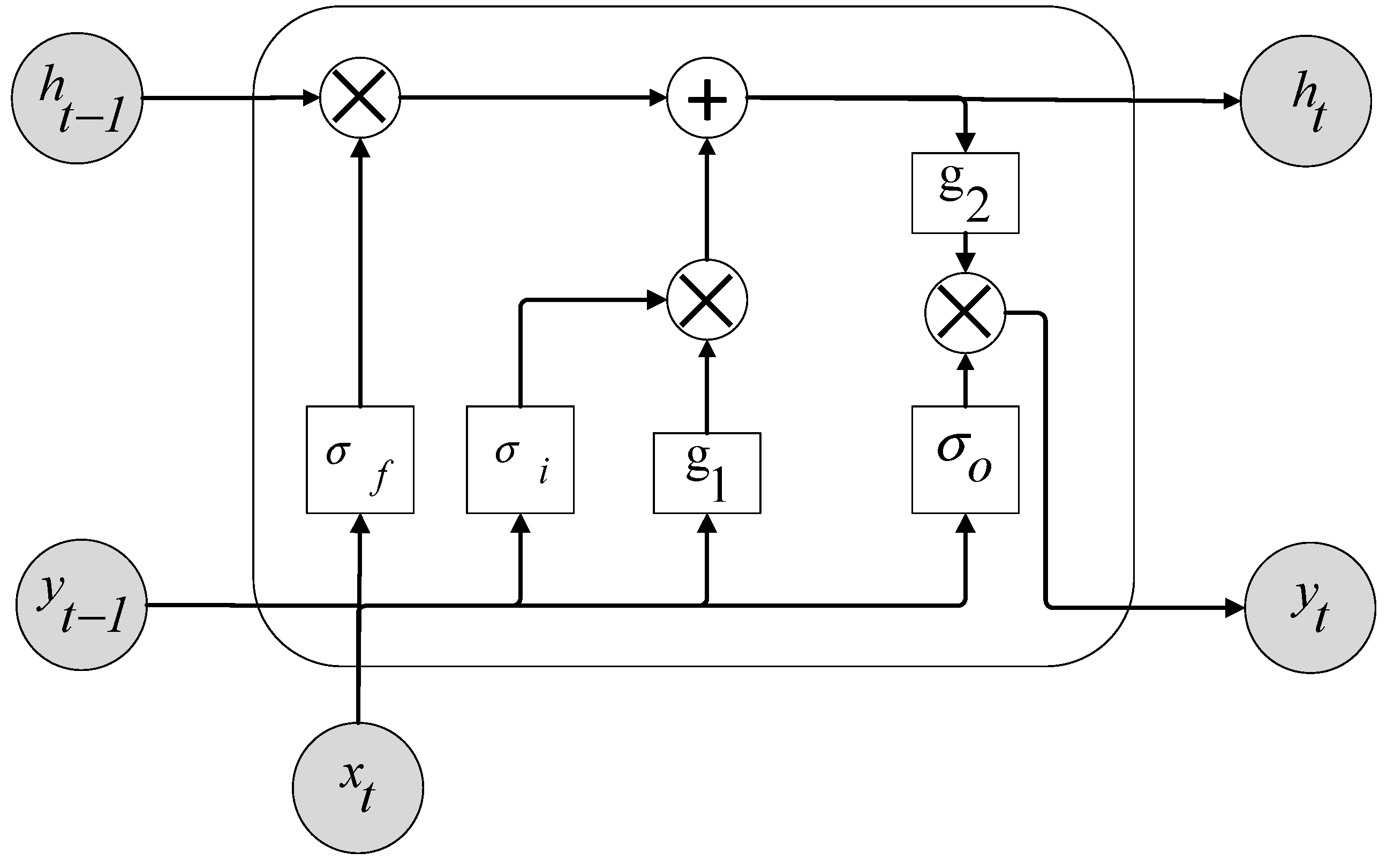
2.6. Long Short-Term Memory
2.7. Measurement of Performance
2.8. Quantification of Uncertainty
- (1)
- 10,000 parameter sets are generated from the uniform distribution with upper and lower boundaries for each parameter. Previous studies involving an application of the GR4J model are used as references for the boundaries. The ranges of the parameters (Table 1) cover most reasonable values [34,53,54].
- (2)
- Definition of the likelihood function and choosing the threshold value for the behavioral parameter sets. NSE is used as the likelihood function. The threshold is defined as 0.7 [54], which means that parameter sets with an efficiency <0.7 are rejected.
- (3)
- Calculation of the posterior likelihood distribution based on the prior distribution and likelihood.
- (4)
- Estimation of the uncertainty range. Outcomes that fall between the fifth and 95th percentiles are used to calculate the uncertainty ranges.
3. Results
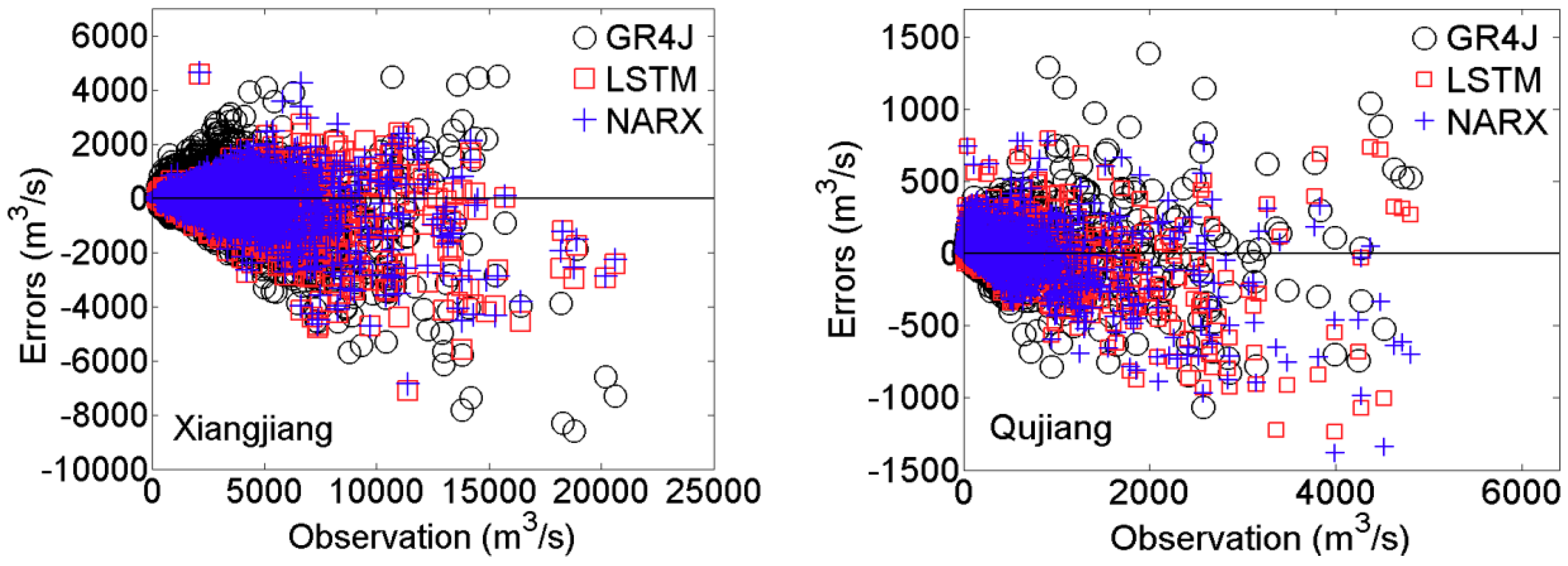
3.1. Model Evaluation and Error Diagnostics
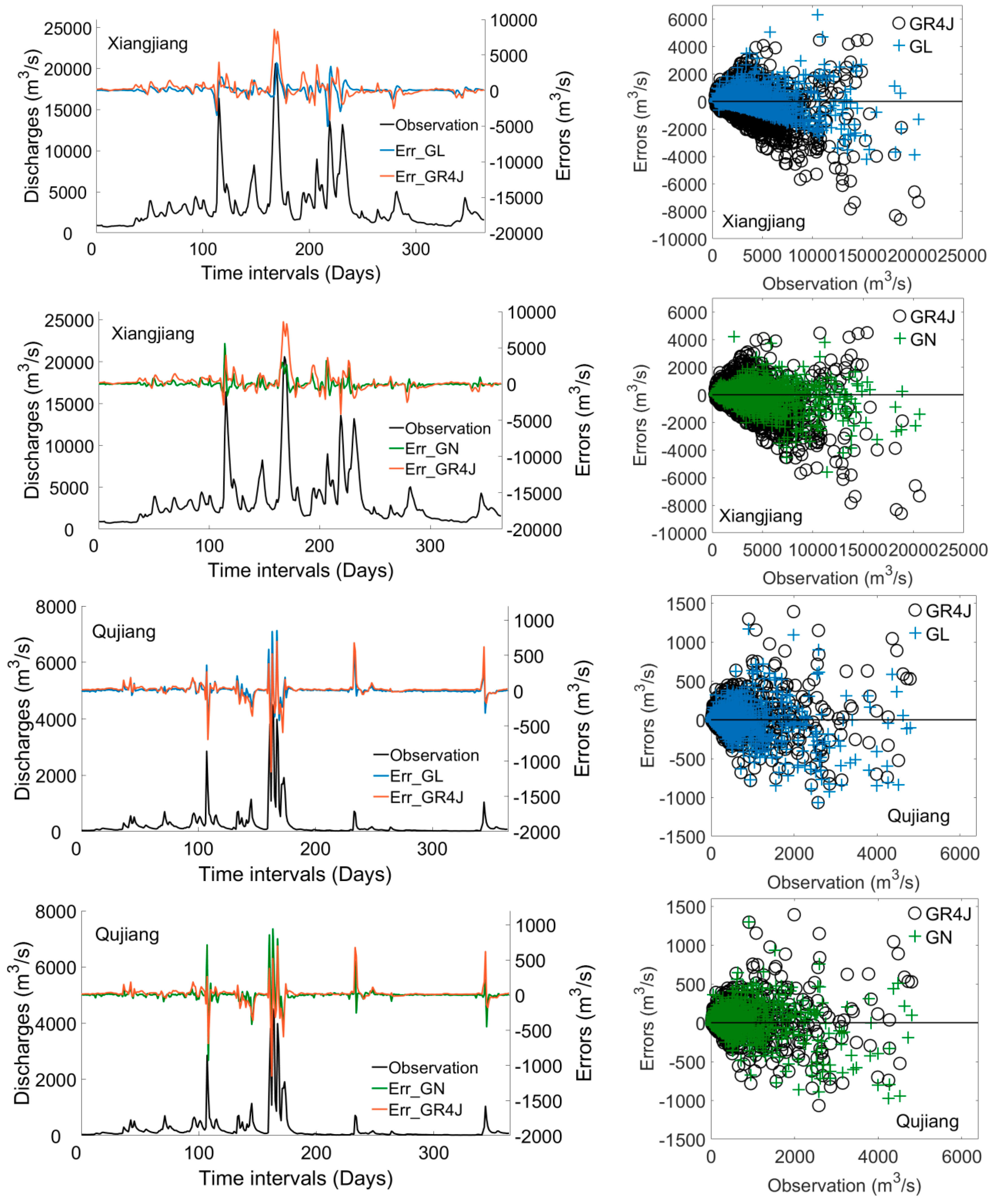
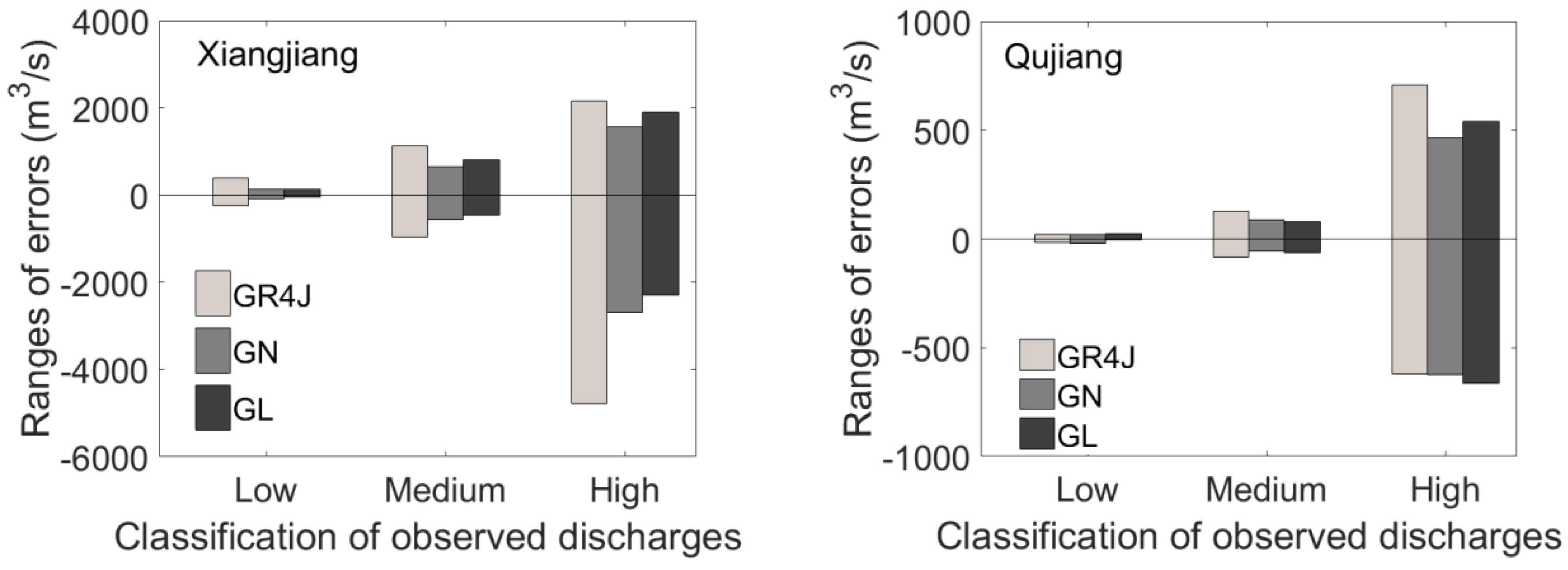
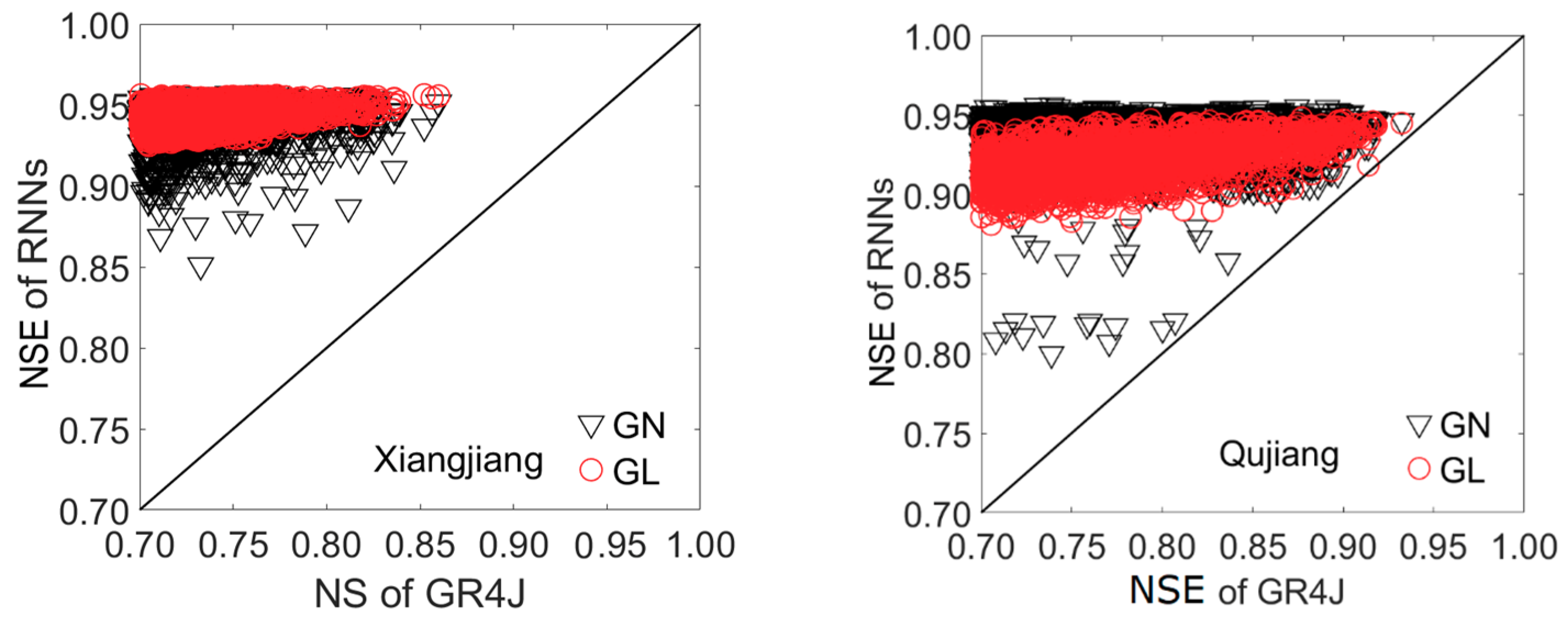
3.2. Integration of GR4J with RNNs
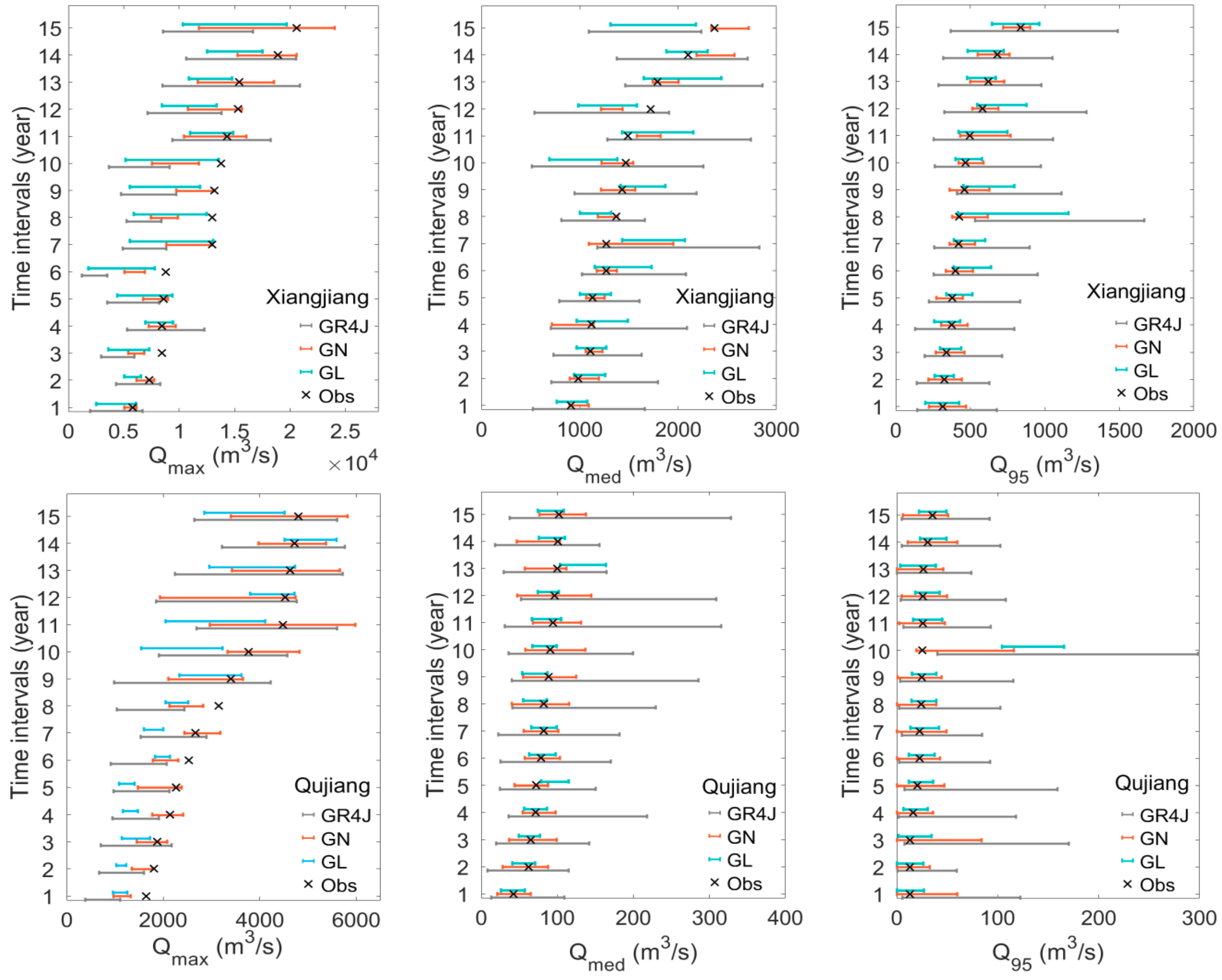
3.3. Uncertainty in the Integrated Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A




References
- Beven, K. So how much of your error is epistemic? Lessons from Japan and Italy. Hydrol. Process. 2013, 27, 1677–1680. [Google Scholar] [CrossRef]
- Beven, K. Facets of uncertainty: Epistemic uncertainty, non-stationarity, likelihood, hypothesis testing, and communication. Int. Assoc. Sci. Hydrol. Bull. 2016, 61, 1652–1665. [Google Scholar] [CrossRef]
- Fraedrich, K.; Morison, R.; Leslie, L.M. Improved tropical cyclone track predictions using error recycling. Meteorol. Atmos. Phys. 2000, 74, 51–56. [Google Scholar] [CrossRef]
- Xiong, L.; O’Connor, K. Comparison of four updating models for real-time river flow forecasting. Int. Assoc. Sci. Hydrol. Bull. 2002, 47, 621–639. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Zhang, Y.; Zhou, J.; Singh, V.P.; Guo, S.; Zhang, J. Real-time error correction method combined with combination flood forecasting technique for improving the accuracy of flood forecasting. J. Hydrol. 2015, 521, 157–169. [Google Scholar] [CrossRef]
- Yen, H.; Wang, X.; Fontane, D.G.; Harmel, R.D.; Arabi, M. A framework for propagation of uncertainty contributed by parameterization, input data, model structure, and calibration/validation data in watershed modeling. Environ. Model. Softw. 2014, 54, 211–221. [Google Scholar] [CrossRef]
- Whitfield, P.H.; Wang, J.Y.; Cannon, A.J. Modelling future streamflow extremes—Floods and low flows in Georgia Basin, British Columbia. Can. Water Resour. J. 2003, 28, 633–656. [Google Scholar] [CrossRef]
- Collet, L.; Beevers, L.; Prudhomme, C. Assessing the impact of climate change and extreme value uncertainty to extreme flows across Great Britain. Water 2017, 9, 103. [Google Scholar] [CrossRef]
- Marshall, L.; Nott, D.; Sharma, A. A comparative study of Markov chain Monte Carlo methods for conceptual rainfall-runoff modeling. Water Resour. Res. 2004, 40, 183–188. [Google Scholar] [CrossRef]
- Raje, D.; Krishnan, R. Bayesian parameter uncertainty modeling in a macroscale hydrologic model and its impact on Indian river basin hydrology under climate change. Water Resour. Res. 2012, 48, 2838–2844. [Google Scholar] [CrossRef]
- Yang, J.; Reichert, P.; Abbaspour, K.C. Bayesian uncertainty analysis in distributed hydrologic modeling: A case study in the Thur River basin (Switzerland). Water Resour. Res. 2007, 43, 145–151. [Google Scholar] [CrossRef]
- Beven, K.; Binley, A. The future of distributed models: Model calibration and uncertainty prediction. Hydrol. Process. 1992, 6, 279–298. [Google Scholar] [CrossRef]
- McMichael, C.E.; Hope, A.S.; Loaiciga, H.A. Distributed hydrological modeling in California semi-arid shrublands: MIKESHE model calibration and uncertainty estimation. J. Hydrol. 2006, 317, 307–324. [Google Scholar] [CrossRef]
- Mirzaei, M.; Galavi, H.; Faghih, M.; Huang, Y.F.; Lee, T.S.; El-Shafie, A. Model calibration and uncertainty analysis of runoff in the Zayanderood River basin using Generalized Likelihood Uncertainty Estimation (GLUE) method. J. Water Supply Res. Technol. 2013, 62, 309–320. [Google Scholar] [CrossRef]
- Rigon, R.; Bertoldi, G.; Over, T.M. GEOtop: A distributed hydrological model with coupled water and energy budgets. J. Hydrometeorol. 2006, 7, 371–388. [Google Scholar] [CrossRef]
- Güntner, A. Improvement of global hydrological models using GRACE data. Surv. Geophys. 2008, 29, 375–397. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, W.; Hu, Y.; Cui, W. Improving the Distributed Hydrological Model Performance in Upper Huai River basin: Using streamflow observations to update the basin states via the Ensemble Kalman Filter. Adv. Meteorol. 2016, 2016, 4921616. [Google Scholar] [CrossRef]
- Paturel, J.E.; Mahé, G.; Diello, P.; Barbier, B.; Dezetter, A.; Dieulin, C.; Karambiri, H.; Yacouba, H.; Maiga, A. Using land cover changes and demographic data to improve hydrological modeling in the Sahel. Hydrol. Process. 2016, 31, 811–824. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.J.; Lien, H.C.; Chang, C.H.; Shen, J.C. Real-time correction of water stage forecast during rainstorm events using combination of forecast errors. Stoch. Env. Res. Risk Assess. 2012, 26, 519–531. [Google Scholar] [CrossRef]
- Hsu, K.; Gupta, H.V.; Sorooshian, S. Artificial neural network modeling of the rainfall-runoff process. Water Resour. Res. 1995, 31, 2517–2530. [Google Scholar] [CrossRef]
- Lee, J.; Kim, C.-G.; Lee, J.; Kim, N.; Kim, H. Application of artificial neural networks to rainfall forecasting in the Geum River basin, Korea. Water 2018, 10, 1448. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W.; Li, Y.S. River stage prediction based on a distributed support vector regression. J. Hydrol. 2008, 358, 96–111. [Google Scholar] [CrossRef] [Green Version]
- Belayneh, A.; Adamowski, J.; Khalil, B.; Ozga-Zielinski, B. Long-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet neural network and wavelet support vector regression models. J. Hydrol. 2014, 508, 418–429. [Google Scholar] [CrossRef]
- Humphrey, G.B.; Gibbs, M.S.; Dandy, G.C.; Maier, H.R. A hybrid approach to monthly streamflow forecasting: Integrating hydrological model outputs into a Bayesian artificial neural network. J. Hydrol. 2016, 540, 623–640. [Google Scholar] [CrossRef]
- Shiau, J.T.; Hsu, H.T. Suitability of ANN-Based Daily Streamflow extension models: A case study of Gaoping River basin, Taiwan. Water Resour. Manag. 2016, 30, 1499–1513. [Google Scholar] [CrossRef]
- Sahoo, S.; Russo, T.A.; Elliott, J.; Foster, I. Machine learning algorithms for modeling groundwater level changes in agricultural regions of the U.S. Water Resour. Res. 2017, 53, 3878–3895. [Google Scholar] [CrossRef]
- Chang, F.J.; Lo, Y.C.; Chen, P.A.; Chang, L.C.; Shieh, M.C. Multi-Step-Ahead Reservoir Inflow Forecasting by Artificial Intelligence Techniques; Springer International Publishing: Cham, Switzerland, 2015; pp. 235–249. [Google Scholar]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. Computer Science. arXiv, 2015; arXiv:1506.00019. [Google Scholar]
- Jiang, C.; Chen, S.; Chen, Y.; Zhang, B.; Feng, Z.; Zhou, H.; Bo, Y. A MEMS IMU De-Noising method using long short term memory recurrent neural networks (LSTM-RNN). Sensors 2018, 18, 3470. [Google Scholar] [CrossRef] [PubMed]
- Chang, F.J.; Chen, P.A.; Lu, Y.R.; Huang, E.; Chang, K.Y. Real-time multi-step-ahead water level forecasting by recurrent neural networks for urban flood control. J. Hydrol. 2014, 517, 836–846. [Google Scholar] [CrossRef]
- Chen, P.A.; Chang, L.C.; Chang, F.J. Reinforced recurrent neural networks for multi-step-ahead flood forecasts. J. Hydrol. 2013, 497, 71–79. [Google Scholar] [CrossRef]
- Shen, H.Y.; Chang, L.C. Online multistep-ahead inundation depth forecasts by recurrent NARX networks. Hydrol. Earth Syst. Sci. 2013, 17, 935–945. [Google Scholar] [CrossRef] [Green Version]
- Liang, C.; Li, H.; Lei, M.; Du, Q. Dongting Lake Water Level Forecast and Its Relationship with the Three Gorges Dam Based on a Long Short-Term Memory Network. Water 2018, 10, 1389. [Google Scholar]
- Perrin, C.; Michel, C.; Andréassian, V. Improvement of a parsimonious model for streamflow simulation. J. Hydrol. 2003, 279, 275–289. [Google Scholar] [CrossRef]
- Thyer, M.; Renard, B.; Kavetski, D.; Kuczera, G.; Franks, S.W.; Srikanthan, S. Critical evaluation of parameter consistency and predictive uncertainty in hydrological modeling: A case study using Bayesian total error analysis. Water Resour. Res. 2009, 45, 1211–1236. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Demuth, H.; Beale, M. Neural Network Toolbox for Use with MATLAB. User’s Guide Version 4. 2002. Available online: http://www.image.ece.ntua.gr/courses_static/nn/matlab/nnet.pdf (accessed on 13 November 2018).
- Jaeger, H. Adaptive Nonlinear System Identification with Echo State Networks. In Proceedings of the NIPS’02 15th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002; pp. 609–616. [Google Scholar]
- Jaeger, H.; Lukosevicius, M.; Popovici, D.; Siewert, U. Optimization and applications of echo state networks with leaky-integrator neurons. Neural Netw. 2007, 20, 335–352. [Google Scholar] [CrossRef] [PubMed]
- Leontaritis, I.J.; Billings, S.A. Input-output parametric models for non-linear systems Part I: Deterministic non-linear systems. Int. J. Control 1985, 41, 303–328. [Google Scholar] [CrossRef]
- Horne, B.G. An experimental comparison of recurrent neural networks. Adv. Neural Inf. Process. Syst. 1995, 7, 697–704. [Google Scholar]
- Menezes, J.; Maria, P.; Barreto, G.A. Long-term time series prediction with the NARX network: An empirical evaluation. Neurocomputing 2008, 71, 3335–3343. [Google Scholar] [CrossRef]
- Marquardt, D.W. An algorithm for least-squares estimation of nonlinear parameters. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar]
- Dipietro, R.; Rupprecht, C.; Navab, N.; Hager, G.D. Analyzing and Exploiting NARX recurrent neural networks for long-term dependencies. arXiv, 2017; arXiv:1702.07805. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F. Long Short-Term Memory in Recurrent Neural Networks; University of Hannover: Hannover, Germany, 2001. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.A.; Cummins, F.A. Learning to forget: Continual prediction with LSTM. In Proceedings of the Ninth International Conference on Artificial Neural Networks, ICANN 99, Edinburgh, UK, 7–10 September 1999; p. 2451. [Google Scholar]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Lindholm, G.; Ratnaweera, H. Use long short-term memory to enhance Internet of Things for combined sewer overflow monitoring. J. Hydrol. 2018, 556, 409–418. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall-Runoff modelling using Long-Short-Term-Memory (LSTM) networks. Hydrol. Earth Syst. Sci. Discuss. 2018. [Google Scholar] [CrossRef]
- Beven, K. A manifesto for the equifinality thesis. J. Hydrol. 2006, 320, 18–36. [Google Scholar] [CrossRef] [Green Version]
- Shin, M.J.; Kim, C.S. Assessment of the suitability of rainfall-runoff models by coupling performance statistics and sensitivity analysis. Hydrol. Res. 2017. [Google Scholar] [CrossRef]
- Tian, Y.; Xu, Y.P.; Booij, M.J.; Wang, G. Uncertainty in future high flows in Qiantang River Basin, China. J. Hydrometeorol. 2015, 16, 363–380. [Google Scholar] [CrossRef]
- Jaeger, H. The Echo State Approach to Analysing and Training Recurrent Neural Networks; GMD Report 148; German National Research Center for Information Technology: Bonn, Germany, 2001. [Google Scholar]
- Diaconescu, E. The use of NARX neural networks to predict chaotic time series. WSEAS Trans. Comp. Res. 2008, 3, 182–191. [Google Scholar]
- Lin, T.; Horne, B.G.; Tiňo, P.; Giles, C.L. Learning long-term dependencies in NARX recurrent neural networks. IEEE Trans. Neural Netw. 1996, 7, 1329–1338. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Description | Minimum | Maximum | Unit |
|---|---|---|---|---|
| X1 | Capacity of the production reservoir | 10 | 2000 | mm |
| X2 | Groundwater exchange coefficient | −8 | 6 | mm |
| X3 | One day capacity of the routing reservoir | 10 | 500 | mm |
| X4 | Time base of the unit hydrograph | 0 | 4 | d |
| Gauge Stations | Models | Calibration | Validation | ||||
|---|---|---|---|---|---|---|---|
| NSE | RMSE (m3/s) | MAPE | NSE | RMSE (m3/s) | MAPE | ||
| Xiangjiang | GR4J | 0.860 | 724 | 0.223 | 0.869 | 837 | 0.189 |
| ERNN | 0.381 | 1522 | 0.672 | 0.450 | 1725 | 0.470 | |
| ESN | 0.745 | 970 | 0.428 | 0.780 | 1088 | 0.360 | |
| NARX | 0.936 | 489 | 0.103 | 0.934 | 595 | 0.096 | |
| LSTM | 0.933 | 500 | 0.091 | 0.932 | 608 | 0.086 | |
| Qujiang | GR4J | 0.933 | 90 | 0.281 | 0.936 | 122 | 0.336 |
| ERNN | 0.664 | 201 | 1.349 | 0.713 | 259 | 1.320 | |
| ESN | 0.889 | 116 | 0.683 | 0.906 | 148 | 0.663 | |
| NARX | 0.933 | 89 | 0.243 | 0.938 | 120 | 0.241 | |
| LSTM | 0.929 | 92 | 0.336 | 0.946 | 112 | 0.348 | |
| Gauge Stations | Models | Calibration | Validation | ||||
|---|---|---|---|---|---|---|---|
| NSE | RMSE | MAPE | NSE | RMSE | MAPE | ||
| Xiangjiang | GR4J | 0.860 | 724 | 0.223 | 0.869 | 837 | 0.189 |
| GL | 0.954 | 414 | 0.098 | 0.952 | 510 | 0.098 | |
| GN | 0.954 | 414 | 0.098 | 0.957 | 480 | 0.085 | |
| Qujiang | GR4J | 0.933 | 90 | 0.281 | 0.936 | 122 | 0.336 |
| GL | 0.942 | 83 | 0.210 | 0.954 | 104 | 0.221 | |
| GN | 0.942 | 83 | 0.210 | 0.955 | 102 | 0.181 | |
| River Basin | Criteria | Qmax | Qmed | Q95 | |||
|---|---|---|---|---|---|---|---|
| Uncertainty Interval | Cover Ratio | Uncertainty Interval | Cover Ratio | Uncertainty Interval | Cover Ratio | ||
| Xiangjiang | GR4J | 5950 | 0.40 | 1250 | 0.93 | 725 | 0.93 |
| GN | 3975 | 0.60 | 315 | 0.80 | 215 | 1.00 | |
| GL | 5200 | 0.33 | 525 | 0.67 | 265 | 1.00 | |
| Qujiang | GR4J | 1990 | 0.60 | 175 | 1.00 | 115 | 0.93 |
| GN | 1325 | 0.73 | 60 | 1.00 | 50 | 1.00 | |
| GL | 890 | 0.27 | 35 | 0.80 | 30 | 0.93 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Xu, Y.-P.; Yang, Z.; Wang, G.; Zhu, Q. Integration of a Parsimonious Hydrological Model with Recurrent Neural Networks for Improved Streamflow Forecasting. Water 2018, 10, 1655. https://doi.org/10.3390/w10111655
Tian Y, Xu Y-P, Yang Z, Wang G, Zhu Q. Integration of a Parsimonious Hydrological Model with Recurrent Neural Networks for Improved Streamflow Forecasting. Water. 2018; 10(11):1655. https://doi.org/10.3390/w10111655
Chicago/Turabian StyleTian, Ye, Yue-Ping Xu, Zongliang Yang, Guoqing Wang, and Qian Zhu. 2018. "Integration of a Parsimonious Hydrological Model with Recurrent Neural Networks for Improved Streamflow Forecasting" Water 10, no. 11: 1655. https://doi.org/10.3390/w10111655
APA StyleTian, Y., Xu, Y.-P., Yang, Z., Wang, G., & Zhu, Q. (2018). Integration of a Parsimonious Hydrological Model with Recurrent Neural Networks for Improved Streamflow Forecasting. Water, 10(11), 1655. https://doi.org/10.3390/w10111655