
A Handy Open-Source Application Based on Computer Vision and Machine Learning Algorithms to Count and Classify Microplastics




Abstract
:1. Introduction
2. Materials and Methods
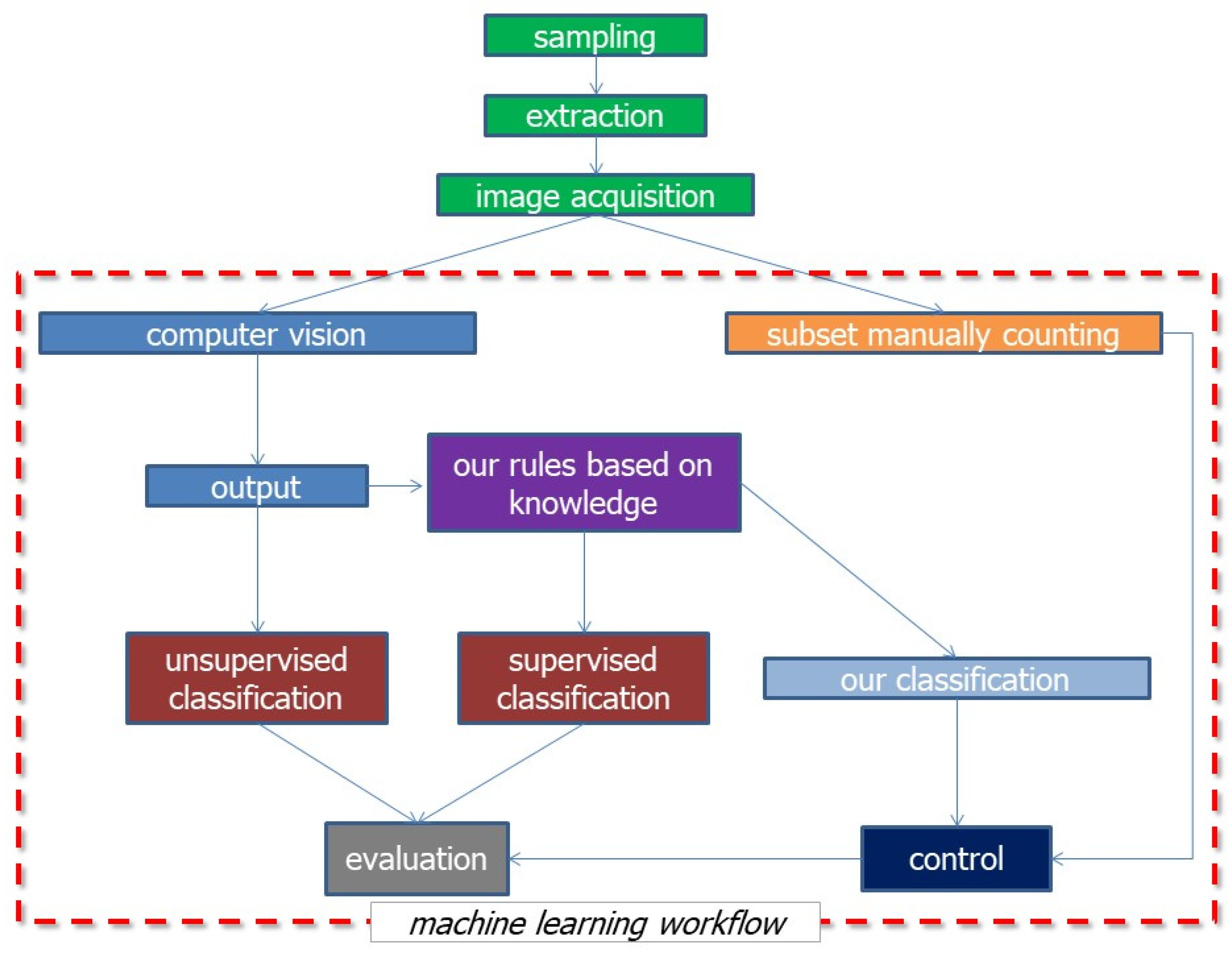
2.1. Overall Operative Workflow
2.2. Sampling and Extraction of MPs
2.3. Image Acquisition
2.4. Machine Learning Workflow
- Perimeter of the particle (in mm);
- Area of the particle (mm2);
- Area of the particle bounding box (mm2);
- Ratio between the area of the particle and its bounding box;
- Y and X axes of the particle bounding box (mm);
- Centroids of Y and X axes;
- Number of pixels of the bounding box;
- Mean pixel intensity;
- Number of bounding box pixels;
- Number of not null pixels for each bounding box (equivalent to each particle’s number of pixels).
- i.
- Pellets. This category corresponds to pre-production pellets, microbeads from personal care products and bead blasting, and other primary origin spheroids.
- ii.
- Fragments. Broken-down pieces of larger debris, such as plastic bottles.
- iii.
- Lines. Particles of fishing line and nets of longitudinal aspect with a thickness of about 1mm.
- iv.
- Fibres. Fibres from synthetic textiles of longitudinal aspect with a thickness <1 mm.
- i.
- <500 µm;
- ii.
- 500–1000 µm;
- iii.
- 1000–2000 µm;
- iv.
- 2000–5000 µm.
2.4.1. Supervised and Unsupervised Classification
Supervised Classification
- a training phase, during which we aimed to train a machine learning model on a set of data that we called “the training dataset” (we stratify the training data with a specific function provided);
- a test phase, during which we evaluated the learned (or finalised) machine learning model on a new set of never-before-seen data that we called “the test dataset”.
Unsupervised Classification
- the centre of each cluster is simply the arithmetic mean of all the points belonging to the cluster;
- each point in the cluster is closer to its centre than to other cluster centres.
2.4.2. Control Tests (Subset Manually Counting)
3. Results
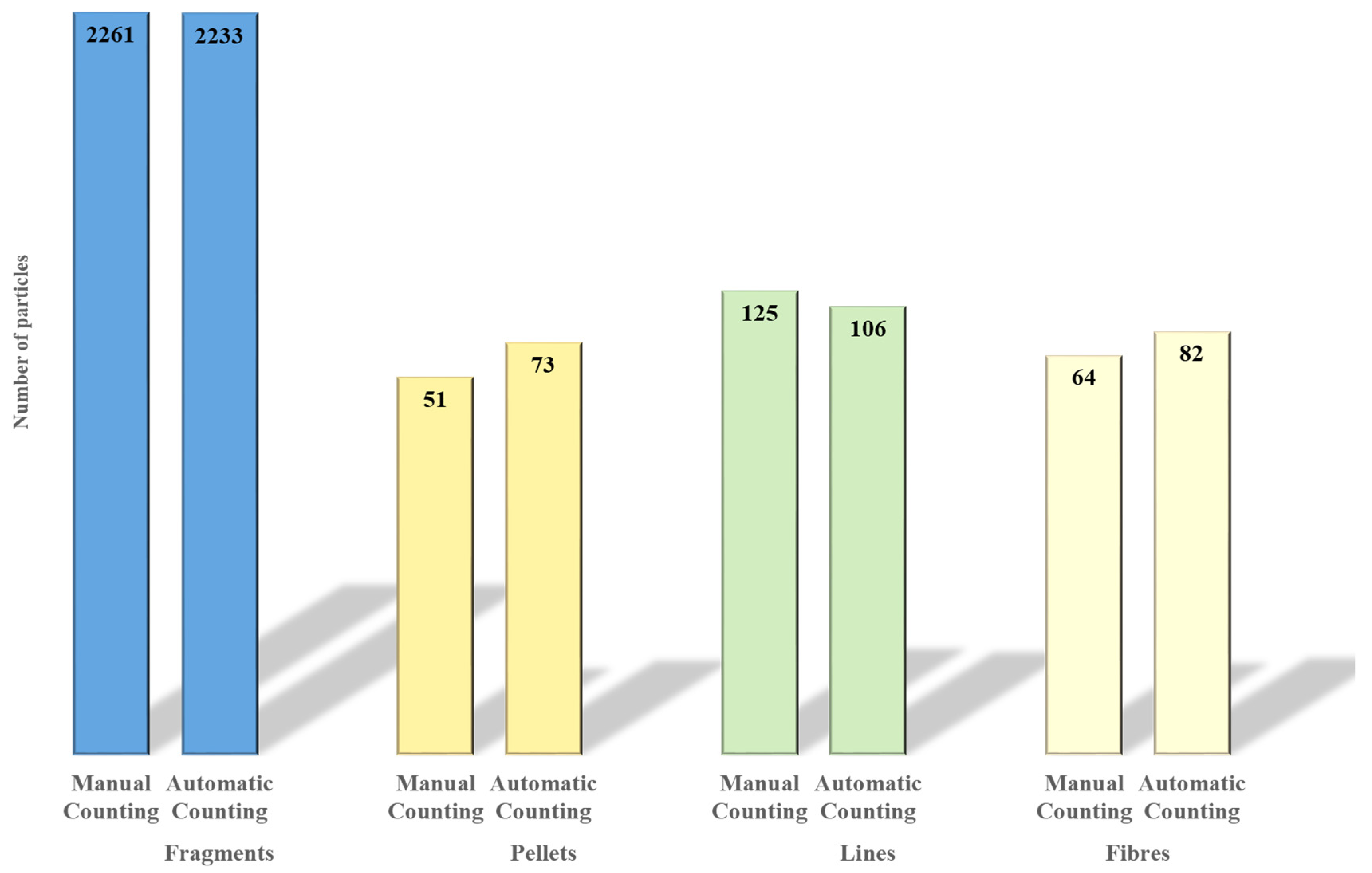
3.1. Manually Counting vs. Early Machine Learning
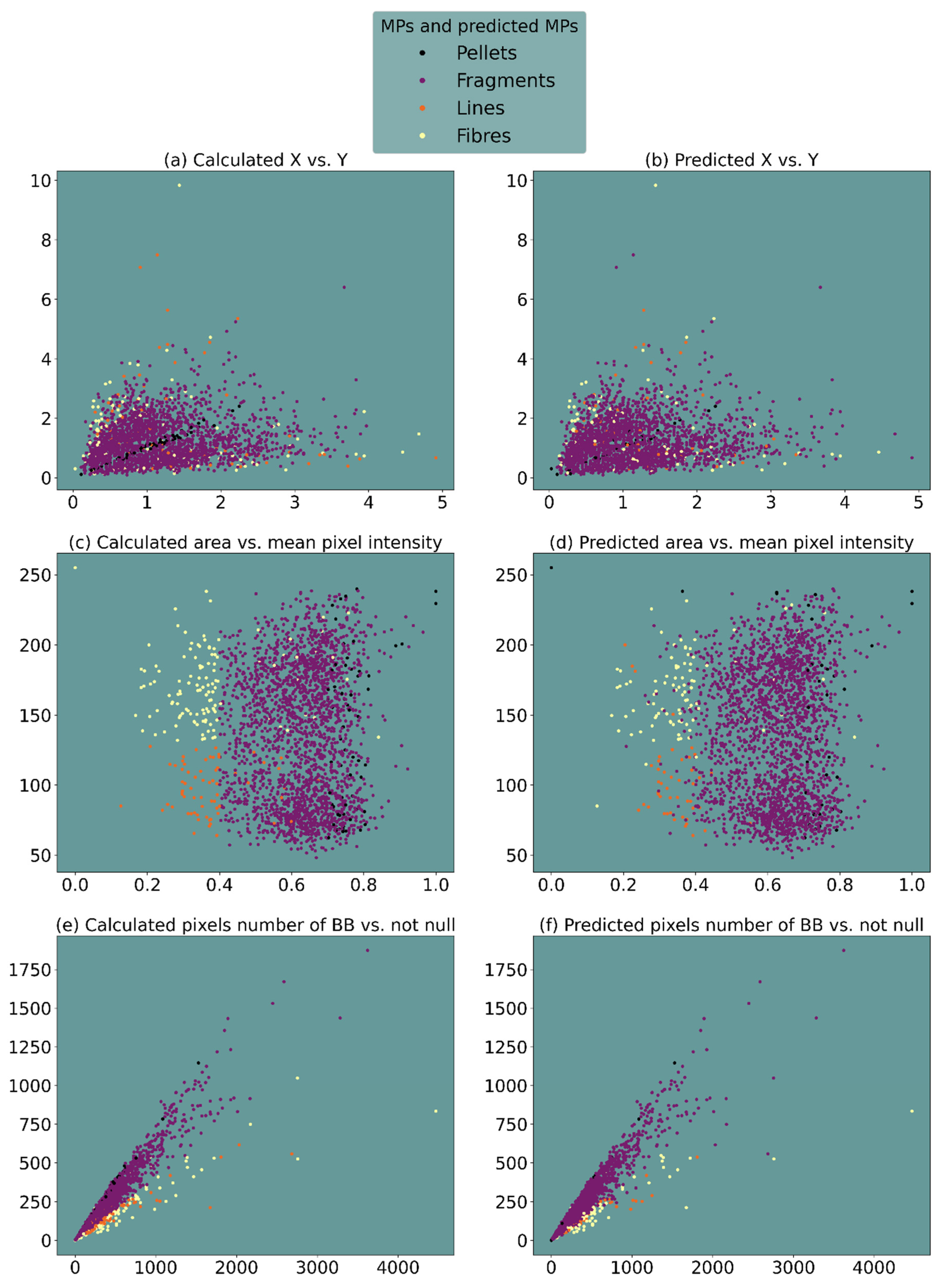
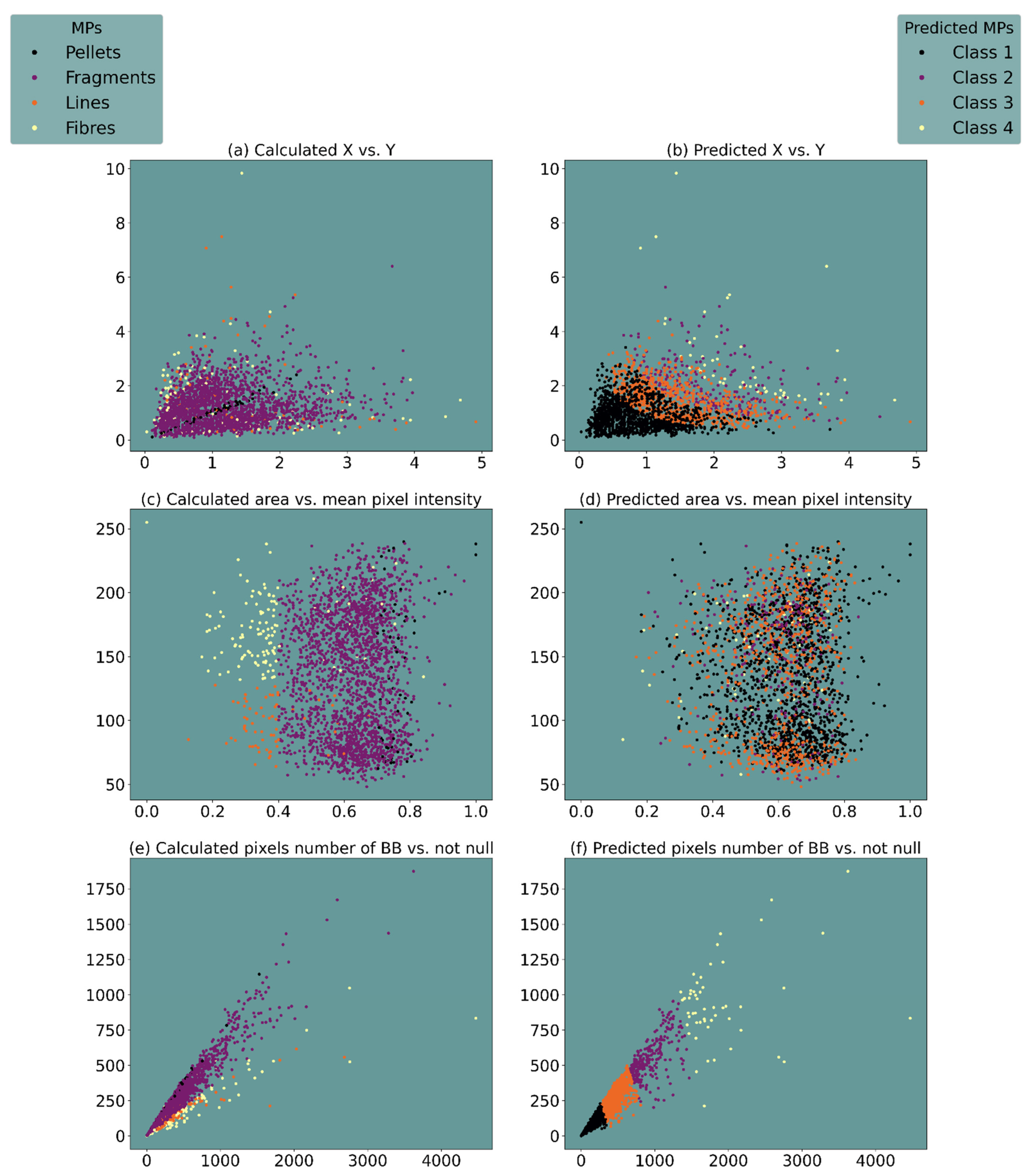
3.2. Supervised vs. Unsupervised Classification
3.2.1. Supervised Classification
3.2.2. Unsupervised Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Frias, J.P.G.L.; Nash, R. Microplastics: Finding a consensus on the definition. Mar. Pollut. Bull. 2019, 138, 145–147. [Google Scholar] [CrossRef]
- Stock, F.; Kochleus, C.; Bänsch-Baltruschat, B.; Brennholt, N.; Reifferscheid, G. Sampling techniques and preparation methods for microplastic analyses in the aquatic environment—A review. TrAC Trends Anal. Chem. 2019, 113, 84–92. [Google Scholar] [CrossRef]
- Law, K.L.; Thompson, R.C. Microplastics in the seas. Science 2014, 345, 144–145. [Google Scholar] [CrossRef]
- Thompson, R.C. Microplastics in the Marine Environment: Sources, Consequences and Solutions. In Marine Anthropogenic Litter; Bergmann, M., Gutow, L., Klages, M., Eds.; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Klein, S.; Dimzon, I.K.; Eubeler, J.; Knepper, T.P. Analysis, Occurrence, and Degradation of Microplastics in the Aqueous Environment. In Freshwater Microplastic; Wagner, M., Lambert, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
- Campanale, C.; Massarelli, C.; Bagnuolo, G.; Savino, I.; Uricchio, V.F. The problem of microplastics and regulatory strategies in Italy. In Plastics in the Aquatic Environment Stakeholders Role against Pollution; Stock, F., Reifferscheid, G., Brennholt, N., Kostianaia, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Li, J.; Liu, H.; Chen, J.P. Microplastics in freshwater systems: A review on occurrence, environmental effects, and methods for microplastics detection. Water Res. 2018, 137, 362–374. [Google Scholar] [CrossRef]
- Campanale, C.; Stock, F.; Massarelli, C.; Kochleus, C.; Bagnuolo, G.; Reifferscheid, G.; Uricchio, V.F. Microplastics and their possible sources: The example of Ofanto river in southeast Italy. Environ. Pollut. 2020, 258. [Google Scholar] [CrossRef] [PubMed]
- Chaczko, Z.; Wajs-Chaczko, P.; Tien, D.; Haidar, Y. Detection of Microplastics Using Machine Learning. In Proceedings of the International Conference on Machine Learning and Cybernetics (ICMLC), Kobe, Japan, 7–10 July 2019; pp. 1–8. [Google Scholar]
- Gonçalves, G.; Andriolo, U.; Gonçalves, L.; Sobrai, P.; Bessa, F. Quantifying Marine Macro Litter Abundance on a Sandy Beach Using Unmanned Aerial Systems and Object-Oriented Machine Learning Methods. Remote Sens. 2020, 12, 2599. [Google Scholar] [CrossRef]
- Lorenzo-Navarro, J.; Castrillón-Santana, M.; Gómez, M.; Herrera, A.; Marín-Reyes, P.A. Automatic counting and classification of microplastic particles. In Proceedings of the 7th International Conference on Pattern Recognition Applications and Methods, Funchal, Portugal, 16–18 January 2018; pp. 646–652. [Google Scholar]
- Lorenzo-Navarro, J.; Castrillon-Santana, M.; Santesarti, E.; De Marsico, M.; Martinez, I.; Raymond, E.; Gomez, M.; Herrera, A. SMACC: A System for Microplastics Automatic Counting and Classification. IEEE Access 2020, 8, 25249–25261. [Google Scholar] [CrossRef]
- Wegmayr, V.; Sahin, A.; Sæmundsson, B.; Buhmann, J.M. Instance Segmentation for the Quantification of Microplastic Fiber Images. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020. [Google Scholar]
- Pedrotti, M.L.; Petit, S.; Elineau, A.; Bruzaud, S.; Crebassa, J.-C.; Dumontet, B.; Martí, E.; Gorsky, G.; Cózar, A. Changes in the Floating Plastic Pollution of the Mediterranean Sea in Relation to the Distance to Land. PLoS ONE 2016, 11, e0161581. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, N.; Thibaul, D.; Galgani, F.; Paluselli, A.; Sempéré, R. Occurrence of microplastics in surface waters of the Gulf of Lion (NW Mediterranean Sea). Prog. Oceanogr. 2018, 163, 214–220. [Google Scholar] [CrossRef] [Green Version]
- Gorsky, G.; Ohman, M.D.; Picheral, M.; Gasparini, S.; Stemman, L.; Romagnan, B.; Cawood, A.; Pesant, S.; Garcia-Comas, C.; Prejger, F. Digital zooplankton image analysis using the ZooScan integrated system. J. Plankton Res. 2010, 32, 285–303. [Google Scholar] [CrossRef]
- Abramoff, M.; Magalhães, P.; Ram, S.J. Image Processing with ImageJ. Biophotonics Int. 2003, 11, 36–42. [Google Scholar]
- Schneider, C.A.; Rasband, W.S.; Eliceiri, K.W. NIH Image to ImageJ: 25 years of image analysis. Nat. Methods 2012, 9, 671–675. [Google Scholar] [CrossRef] [PubMed]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, in press. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kedzierski, M.; Falcou-Préfol, M.; Kerros, M.E.; Henry, M.; Pedrotti, M.L.; Bruzaud, S. A machine learning algorithm for high throughput identification of FTIR spectra: Application on microplastics collected in the Mediterranean Sea. Chemosphere 2019, 234, 242–251. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Beyeler, M. Machine Learning for OpenCV; Packt Publishing Ltd.: Bimingham, UK, 2017. [Google Scholar]
- Sebe, N.; Cohen, I.; Garg, A.; Huang, T.S. Machine Learning in Computer Vision; Springer: Dordrecht, The Netherlands; Berlin/Heidelberg, Germany; New York, NY, USA, 2005; ISBN 1402032749. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–407. [Google Scholar] [CrossRef] [Green Version]
- Michalski, R.S.; Carbonell, J.G.; Mitchell, T.M. (Eds.) Machine Learning: An Artificial Intelligence Approach; Morgan Kaufmann: Los Altos, CA, USA, 1986. [Google Scholar]
- Rowley, H.; Baluja, S.; Kanade, T. Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 23–38. [Google Scholar] [CrossRef]
- Pulli, K.; Baksheev, A.; Kornyakov, K.; Eruhimov, V. Realtime Computer Vision with OpenCV. Queue 2012, 10, 40–56. [Google Scholar] [CrossRef]
- Rosebrock, A. Pratical Python and OpenCV. An introductory, Example Driven Guide to Image Processing and Computer Vision, 3rd ed. ASIN B078QFL1NY. 2017. Available online: PyImageSearch.com (accessed on 15 June 2021).
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–168. [Google Scholar] [CrossRef]
- Hu, M.K. Visual Pattern Recognition by Moment Invariants. IRE Trans. Info. Theory 1962, 8, 179–187. [Google Scholar]
- Green, G. An essay on the application of mathematical analysis to the theories of electricity and magnetism. arXiv 1828, arXiv:0807.0088. [Google Scholar]
- Jurkat, W.B.; Nonnenmacher, D.J.F. The General Form of Green’s Theorem. Proc. Am. Math. Soc. 1990, 109. [Google Scholar] [CrossRef]
- Helm, P.A. Improving microplastics source apportionment: A role for microplastic morphology and taxonomy? Anal. Methods 2017, 9, 1328–1331. [Google Scholar] [CrossRef]
- Lusher, A.L.; Welden, N.; Sobral, P.; Cole, M. Sampling, isolating and identifying microplastics ingested by fish and invertebrates. Anal. Methods 2017, 9, 1346–1360. [Google Scholar] [CrossRef] [Green Version]
- Dyachenko, A.; Mitchell, J.; Arsem, N. Extraction and identification of microplastic particles from secondary wastewater treatment plant (WWTP) effluent. Anal. Methods 2017, 9, 1412–1418. [Google Scholar] [CrossRef]
- Hidalgo-Ruz, V.; Gutow, L.; Thompson, R.C.; Thiel, M. Microplastics in the Marine Environment: A Review of the Methods Used for Identification and Quantification. Environ. Sci. Technol. 2012, 46, 3060–3075. [Google Scholar] [CrossRef] [PubMed]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Naomi, S.A. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Belur, V. Nearest Neighbor (NN) Norms: NN Pattern Classification Techniques; IEEE Computer Society Press: Washington, DC, USA, 1991. [Google Scholar]
- Shakhnarovich, G.; Darrell, T.; Indyk, P. (Eds.) Nearest-Neighbour Methods in Learning and Vision; The MIT Press: Cambridge, MA, USA, 2005; ISBN 026219547X. [Google Scholar]
- Pedregosa, F.; Voroquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning (ICML), Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Flach, P.A.; Kull, M. Precision-Recall-Gain Curves: PR Analysis Done Right. In Proceedings of the 29th Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- GESAMP. Report and Studies No. 99. Guidelines for the Monitoring and Assessment of Plastic Litter in the Ocean; United Nations Environment Programme (UNEP): Nairobi, Kenya, 2019; ISSN 10204873. [Google Scholar]
- Quinn, G.P.; Keough, M.J. Experimental Design and Data Analysis for Biologists; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Turner, A.; Wallerstein, C.; Arnold, R. Identification, origin and characteristics of bio-bead microplastics from beaches in western Europe. Sci. Total Environ. 2019, 664, 938–947. [Google Scholar] [CrossRef] [PubMed]
- Boucher, J.; Friot, D. Primary Microplastics in the Oceans: A Global Evaluation of Sources; IUCN: Gland, Switzerland, 2017; p. 43. [Google Scholar]
- Zhu, Y.; Yeung, C.H.; Lam, E.Y. Digital holographic imaging and classification of microplastics using deep transfer learning. Appl. Opt. 2021, 60, 38–47. [Google Scholar] [CrossRef]
- Peršak, T.; Viltužnik, B.; Hernavs, J.; Klančnik, S. Vision-Based Sorting Systems for Transparent Plastic Granulate. Appl. Sci. 2020, 10, 4269. [Google Scholar] [CrossRef]
- Hufnagl, B.; Steiner, D.; Renner, E.; Löder, M.G.J.; Laforsch, C.; Lohninger, H. A methodology for the fast identification and monitoring of microplastics in environmental samples using random decision forest classifiers. Anal. Methods 2019, 11, 2277–2285. [Google Scholar] [CrossRef] [Green Version]
- Bagaev, A.; Mizyuk, A.; Khatmullina, L.; Isachenko, I.; Chubarenko, I. Anthropogenic fibres in the Baltic Sea water column: Field data, laboratory and numerical testing of their motion. Sci. Total Environ. 2017, 599, 560–571. [Google Scholar] [CrossRef]
- Barrows, A.P.W.; Cathey, S.E.; Petersen, C.W. Marine environment microfiber contamination: Global patterns and the diversity of microparticle origins. Environ. Pollut. 2018, 237, 275–284. [Google Scholar] [CrossRef] [Green Version]
- Suaria, G.; Achtypi, A.; Perold, V.; Lee, J.R.; Pierucci, A.; Bornman, T.G.; Aliani, S.; Ryan, P.G. Microfibers in oceanic surface waters: A global characterization. Sci. Adv. 2020, 6. [Google Scholar] [CrossRef] [PubMed]
- Ryan, P.G.; Suaria, G.; Perold, V.; Pierucci, A.; Bornman, T.G.; Aliani, S. Sampling microfibres at the sea surface: The effects of mesh size, sample volume and water depth. Environ. Pollut. 2019, 258. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample | Manual Counting | Automatic Counting | Dev st. % |
|---|---|---|---|
| 1 | 416 | 417 | 0.7 |
| 2 | 398 | 395 | 2.1 |
| 3 | 384 | 377 | 4.9 |
| 4 | 505 | 505 | 0.0 |
| 5 | 798 | 800 | 1.4 |
| Total | 2501 | 2494 | 4.9 |
| Sample | Fragment | Pellet | Line | Fibre | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n. | Manual Counting | Automatic Counting | Dev st. % | Manual Counting | Automatic Counting | Dev st. % | Manual Counting | Automatic Counting | Dev st. % | Manual Counting | Automatic Counting | Dev st. % |
| 1 | 382 | 372 | 12.7 | 9 | 12 | 2.1 | 4 | 12 | 5.7 | 21 | 29 | 5.7 |
| 2 | 348 | 346 | 1.4 | 5 | 9 | 2.8 | 10 | 0 | 7.1 | 35 | 40 | 3.5 |
| 3 | 337 | 333 | 2.8 | 5 | 8 | 2.1 | 42 | 26 | 11.3 | 0 | 2 | 1.4 |
| 4 | 462 | 454 | 5.7 | 6 | 12 | 4.2 | 37 | 38 | 0.7 | 0 | 0 | 0.0 |
| 5 | 732 | 728 | 2.8 | 26 | 32 | 4.2 | 32 | 29 | 2.1 | 8 | 11 | 2.1 |
| Total | 2261 | 2233 | 19.8 | 51 | 73 | 15.6 | 125 | 106 | 13.4 | 64 | 82 | 12.7 |
| Sample | Sizes of a Known Object | |
|---|---|---|
| n. | X (mm) | Y (mm) |
| 1 | 4.89 | 5.07 |
| 2 | 4.67 | 4.78 |
| 3 | 5.31 | 5.00 |
| 4 | 5.02 | 4.78 |
| 5 | 5.21 | 5.27 |
| 6 | 4.72 | 4.52 |
| 7 | 4.93 | 5.02 |
| 8 | 5.31 | 5.49 |
| 9 | 5.07 | 5.32 |
| 10 | 4.89 | 4.75 |
| 11 | 5.02 | 5.36 |
| 12 | 4.92 | 4.92 |
| 13 | 4.78 | 4.89 |
| 14 | 4.91 | 5.11 |
| 15 | 5.01 | 5.04 |
| 16 | 5.11 | 4.98 |
| 17 | 4.92 | 4.55 |
| 18 | 5.21 | 5.30 |
| 19 | 4.98 | 5.17 |
| 20 | 4.64 | 4.75 |
| 21 | 4.78 | 4.89 |
| 22 | 5.07 | 4.79 |
| 23 | 5.24 | 5.11 |
| 24 | 5.79 | 5.55 |
| 25 | 5.05 | 5.46 |
| 26 | 5.79 | 5.45 |
| 27 | 5.53 | 5.45 |
| 28 | 5.45 | 5.01 |
| Mean | 5.08 | 5.06 |
| Median | 5.02 | 5.03 |
| St. dev. | 0.30 | 0.30 |
| Max Value | 5.79 | 5.62 |
| Min Value | 4.64 | 4.52 |
| Training Data | Accuracy | Typology | Precision | Recall | F1 score | Support |
|---|---|---|---|---|---|---|
| 10% | 0.905 | Pellets | <0.01 | <0.01 | <0.01 | 60 |
| Fragments | 0.91 | 0.99 | 0.95 | 1990 | ||
| Lines | 0.67 | 0.17 | 0.27 | 60 | ||
| Fibres | 0.63 | 0.22 | 0.33 | 108 | ||
| 20% | 0.906 | Pellets | <0.01 | <0.01 | <0.01 | 53 |
| Fragments | 0.91 | 0.99 | 0.95 | 1769 | ||
| Lines | 0.74 | 0.26 | 0.38 | 54 | ||
| Fibres | 0.79 | 0.23 | 0.35 | 96 | ||
| 50% | 0.916 | Pellets | 0.14 | 0.03 | 0.05 | 33 |
| Fragments | 0.93 | 0.99 | 0.96 | 1105 | ||
| Lines | 0.59 | 0.29 | 0.39 | 34 | ||
| Fibres | 0.77 | 0.4 | 0.53 | 60 | ||
| 70% | 0.922 | Pellets | <0.01 | <0.01 | <0.01 | 20 |
| Fragments | 0.93 | 0.99 | 0.96 | 664 | ||
| Lines | 0.75 | 0.45 | 0.56 | 20 | ||
| Fibres | 0.78 | 0.5 | 0.61 | 36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Massarelli, C.; Campanale, C.; Uricchio, V.F. A Handy Open-Source Application Based on Computer Vision and Machine Learning Algorithms to Count and Classify Microplastics. Water 2021, 13, 2104. https://doi.org/10.3390/w13152104
Massarelli C, Campanale C, Uricchio VF. A Handy Open-Source Application Based on Computer Vision and Machine Learning Algorithms to Count and Classify Microplastics. Water. 2021; 13(15):2104. https://doi.org/10.3390/w13152104
Chicago/Turabian StyleMassarelli, Carmine, Claudia Campanale, and Vito Felice Uricchio. 2021. "A Handy Open-Source Application Based on Computer Vision and Machine Learning Algorithms to Count and Classify Microplastics" Water 13, no. 15: 2104. https://doi.org/10.3390/w13152104
APA StyleMassarelli, C., Campanale, C., & Uricchio, V. F. (2021). A Handy Open-Source Application Based on Computer Vision and Machine Learning Algorithms to Count and Classify Microplastics. Water, 13(15), 2104. https://doi.org/10.3390/w13152104