
Validation of Machine Learning Models for Structural Dam Behaviour Interpretation and Prediction




Abstract
:1. Introduction
- The adequate selection of input variables.
- The possibilities and limitations of their interpretation for identifying the effects of the external variables.
- The required size of the available monitoring data for model fitting.
- The methods for handling missing values.
- The selection of training and predicted sets.
- The procedure for reliably evaluating model accuracy and defining warning thresholds from model predictions.
2. State of Art: Machine Learning Models for Dam Behaviour Interpretation and Prediction
2.1. Overview about Machine Learning
2.2. Formulation by Separation of the Reversible and Irreversible Effects: The HST and HTT Approaches
- (i)
- The analysed effects refer to a period in the life of a dam for which there are no relevant structural changes.
- (ii)
- The effects of the normal structural behaviour for normal operating conditions can be represented by two parts: a part of elastic nature (reversible and instantaneous, resulting from the variations of the hydrostatic pressure and the temperature) and another part of the inelastic nature (irreversible) such as a time function.
- (iii)
- The effects of the hydrostatic pressure, temperature, and time changes can be evaluated separately.
2.3. Machine Learning Models Used for the Dam Behaviour Interpretation and Prediction
- Each tree is created from a bootstrapped sample of the training set, in which some the samples are included, some are excluded, and others are duplicated.
- Only a random subsample of the inputs is taken for creating each split of each tree.
- The tree models in the ensemble are simple, i.e., with just a few branches.
- Each tree is fitted on a random subset of the original training set.
- The residual of the previous ensemble is considered as the objective function for fitting each tree. As a result, the model prediction is computed as the sum of outputs from all trees (instead of the average, as for RF).
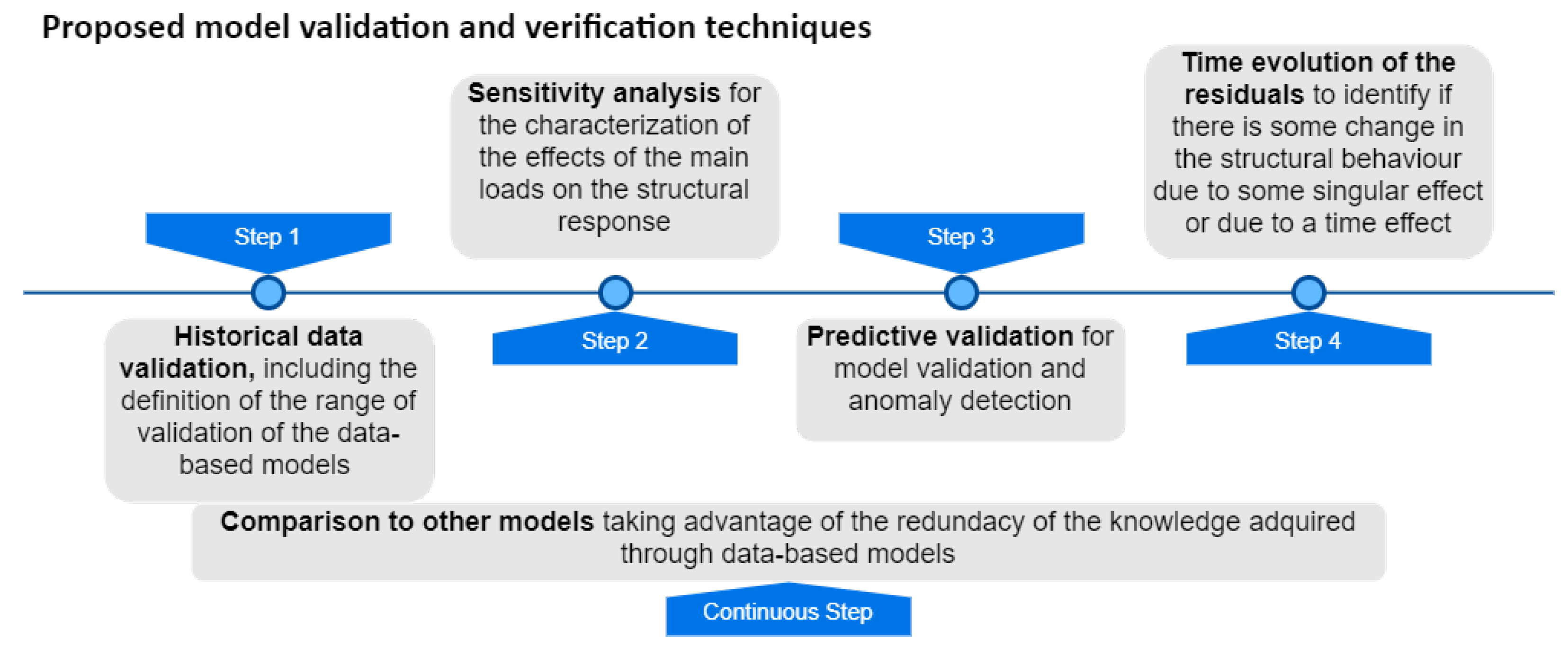
3. Methodology Proposed for Model Validation and Verification
- Model verification is “ensuring that the computer program of the computerized model and its implementation are correct”.
- Model validation is a “substantiation that a computerized model within its domain of applicability possesses a satisfactory range of accuracy consistent with the intended application of the model”.
- Model accreditation is determining if a model satisfies specified model accreditation criteria according to a specified process.
- Model credibility is the concern with developing in (potential) users the confidence they require to use a model and in the information derived from that model.
- (i)
- The problem entity is the system (real) composed of the reservoir, the dam and its foundation.
- (ii)
- The conceptual model is the mathematical/logical/verbal representation of the problem entity developed for a particular study, usually the analysis and interpretation of the observed structural dam’s behaviour (based on recorded data).
- (iii)
- The computerized model is the conceptual model implemented on a computer. In this case, machine learning was adopted for the development of the model simulation. A critical aspect of this topic is that the person who develops the ML model (as a programmer or as a software user) must have a strong knowledge of how machine learning techniques work and be familiarized with the programming language or with the software in use.
- (iv)
- The conceptual model validation is defined as determining that the theories and assumptions underlying the conceptual model are correct and that the model representation of the problem entity is “reasonable” for the intended purpose of the model. For example, dam engineers usually perform this validation through the following questions: Is the horizontal displacement of the dam body increasing with the increase of hydrostatic water effect? Is the displacement downstream or upstream? Is the range of displacements higher near the crest? Is the structural response due to the air temperature variations similar to a sinusoidal shape with an annual period? Can the effects of the hydrostatic pressure, temperature, and time changes be evaluated separately?
- (v)
- Computerized model verification is defined as assuring that the computer programming and implementation of the conceptual model are correct. In the case of data-based models used in dam engineering, this is performed through the knowledge of the functioning, the field of application and the range of validity of the machine learning methods. The computerized model is developed and tested to verify if the conceptual model is well simulated using a “training set” of data from the reservoir-dam-foundation system (problem entity). For the computerized model verification, two types of verifications can be performed: (i) the first regarding the verification of the programming code (if a home-made software is used) or regarding parameters and to the learning method adopted in each case, and (ii) the second regarding the verification of the conceptual model must be supported by a specialist with a strong knowledge about the dam’s behaviour.
- (vi)
- Operational validation is defined as determining that the model output behaviour has sufficient accuracy for the intended purpose over the domain of the intended applicability. This is usually achieved through the knowledge of the performance indicators of the data-based models developed. In some cases, a new set of data from the reservoir-dam-foundation system is used to validate the model.
- (vii)
- Data validity is defined as ensuring that the data necessary for model building, evaluation and testing, and conducting the model experiments to solve the problem are adequate and correct. This is an important task usually performed through the quality control of monitoring data—e.g., repeatability and reproducibility studies [46], comparison between manual and automated measurements [47], the metrological verification of the measuring devices [48], training of the operators, and through the quantification of the measurement uncertainties in dam monitoring systems.
4. Case Study
4.1. The Salamonde Dam
4.2. The Analysed Data
4.3. The ML Models Developed
- SVR model: a Gaussian RBF kernel with an -insensitive loss function was adopted and several values of (0.05, 0.1, 0.5), C (1, 10, 20) and (0.1, 0.2, 0.3, 0.4) were tested on 2/3 of the training data, and their accuracy evaluated on the remaining 1/3. The best combination of parameters were = 0.1, C = 10 and = 0.3.
- NN model: Every neuron in the network is fully connected with each neuron of the next layer. A logistic transfer function was chosen as the activation function for the hidden layer and the linear function for the output layer. Parameter calibration was used for the NN model to select the number of neurons in the hidden layers: models with 3, 4 and 5 neurons were tested. To find out the optimum result, 15 initializations of random weights and a maximum of 1500 iterations were performed for each NN architecture. A cross-validation technique was adopted to select the best NN: 65% of the training set was used for training, 20% of the training set was used to choose the NN with better performance and 15% of the training set was used to check the performance of the NN model.
- RF model: Default parameters were used for the RF model, i.e., 500 trees and one input variable randomly taken for each split.
- BRT model: Default parameters of the gbm package [62] were applied, with 300 trees in the final model.
5. Results and Discussion
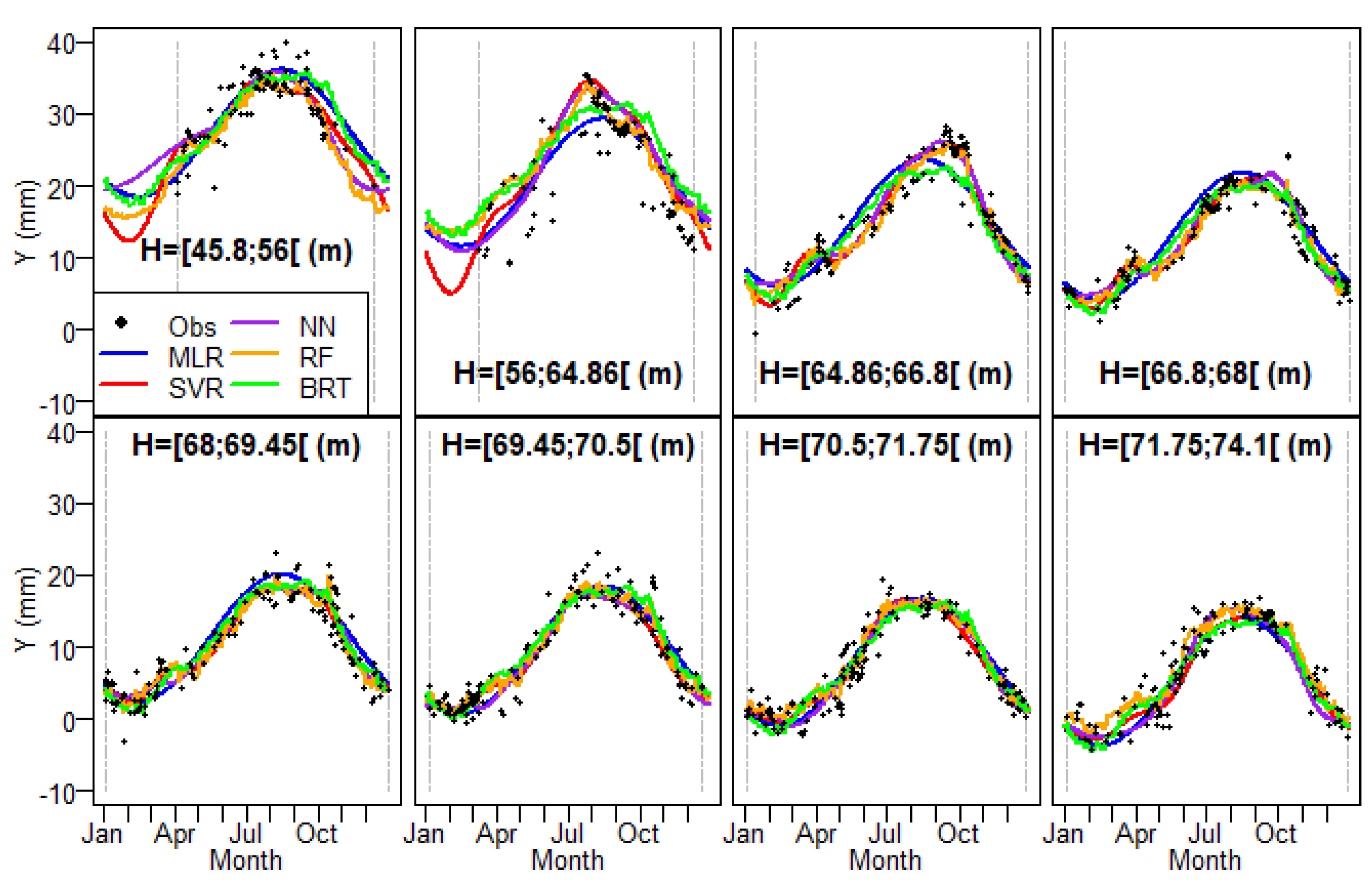
5.1. Step 1: Historical Data Validation
5.2. Step 2: Sensitivity Analysis
5.2.1. Effect of Water Level
5.2.2. Effect of Temperature
5.3. Step 3: Predictive Validation
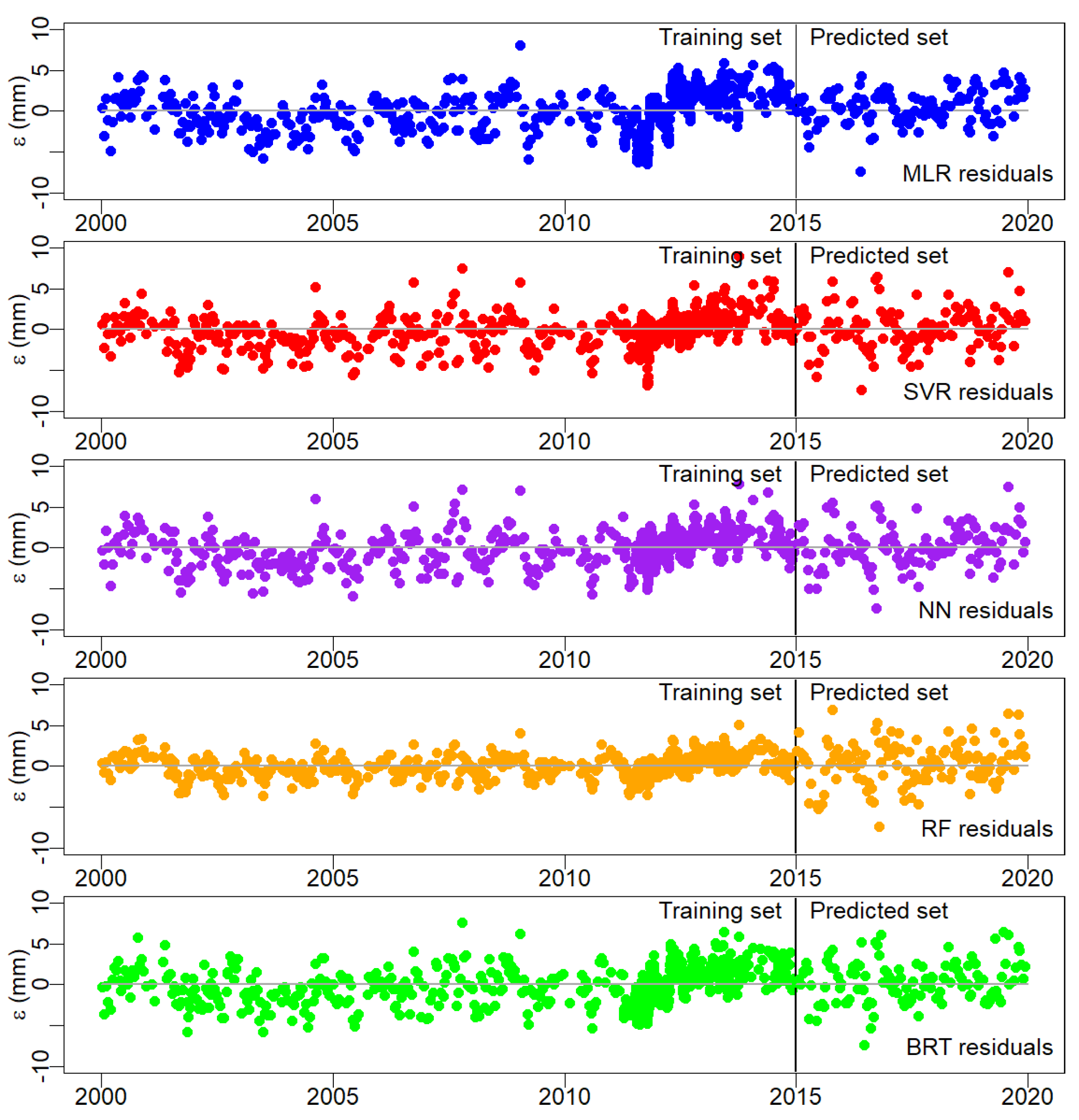
5.4. Step 4: Time Evolution of Residuals
5.5. Step 5: Comparison to Other Models
6. Conclusions and Final Remarks
- Dams are made of, and founded on, materials whose properties change with time, so each data-based model has a limited lifetime (from a couple of months until several years) and a regular update of the parameters of the models based on “new data” is recommended. However, the model updating must be performed with data representing the typical (and acceptable) dam behaviour.
- Good data quality is necessary to obtain good ML models, but an adequate learning process is also necessary. The performance of the ML models is a consequence of the quality of data (directly related to the measurements uncertainties or even errors from the measuring process) and the suitability of the ML techniques adopted for the intended purpose (e.g., analysis and interpretation of the dam behaviour).
- ML models showed to be able to learn the pattern behaviour of the data (sometimes unseen from the users of the data). Some ML techniques are too prone to overfitting. However, an adequate generalization capacity can be achieved if a suitable learning strategy is adopted.
- Day-to-day dam safety activities based on data-based models are usually split into two parts: model development and operation. Each part uses different data (from the same source) recorded along time: the training and the prediction sets. However, these two sets are recorded measurements. So, regarding the historical data validation, two strategies can be performed: (i) use a part of the training set to validate the behaviour of the model or, in other words, to verify the adequacy and the generalization capacity of the model, and (ii) to use the own prediction set for this purpose (as usually verified in MLR because the shape of the terms adopted is well known in this field).
- To perform predictive validation is a routine activity of dam engineers. This process of forecast the structural response (based on known inputs) and compare to the observed response is fundamental to identify possible measurement errors or some change of the dam behaviour pattern observed before (namely on the training set) in order to draw conclusions regarding the safety state of the dam.
- The water level and the temperature variations are two important loads to be considered in the study of the dam behaviour, and their effect on horizontal displacements in concrete dams is well known. For this reason, performing sensitivity analysis in the model regarding these two loads is relevant to the model validation process. This is more important because one premise of the approach (adopted in this work) is that the effects of the hydrostatic pressure, temperature, and time changes can be evaluated separately.
- The knowledge about the evolution of the residuals over time can provide beneficial information about how the reservoir-dam-foundation system changes. The properties of this system change over time. However, a slow time dependency variation is expected in most dams in normal exploitation. Evidence of trends may be, for example, related to changes in concrete proprieties due to alkalis-silica reactions.
- Using more than one predictive model and comparing the results is strongly recommended. This can also be useful if some of the models are based on the FEM, particularly when complex behaviour is observed or when the interpretation of the model suggests some potential anomaly.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- ICOLD. Surveillance: Basic Elements in a Dam Safety Process; Bulletin Number 138; International Commission on Large Dams: Paris, France, 2009. [Google Scholar]
- RSB. Regulation for the Safety of Dams; Decree-Law number 21/2018 of March 28; RSB: Porto, Portugal, 2018. (In Portuguese) [Google Scholar]
- Lombardi, G. Advanced data interpretation for diagnosis of concrete dams. In Structural Safety Assessment of Dams; CISM: Udine, Italy, 2004. [Google Scholar]
- Salazar, F.; Toledo, M.A.; Oñate, E.; Morán, R. An empirical comparison of machine learning techniques for dam behaviour modelling. Struct. Saf. 2015, 56, 9–17. [Google Scholar] [CrossRef] [Green Version]
- Swiss Committee on Dams. Methods of analysis for the prediction and the verification of dam behaviour. In Proceedings of the 21st Congress of the International Commission on Large Dams, Montreal, Switzerland, 16–20 June 2003. [Google Scholar]
- Leger, P.; Leclerc, M. Hydrostatic, Temperature, Time-Displacement Model for Concrete Dams. J. Eng. Mech. 2007, 133, 267–277. [Google Scholar] [CrossRef]
- Mata, J. Interpretation of concrete dam behaviour with artificial neural network and multiple linear regression models. Eng. Struct. 2011, 33, 903–910. [Google Scholar] [CrossRef]
- Simon, A.; Royer, M.; Mauris, F.; Fabre, J. Analysis and Interpretation of Dam Measurements using Artificial Neural Networks. In Proceedings of the 9th ICOLD European Club Symposium, Venice, Italy, 10–12 April 2013. [Google Scholar]
- Ranković, V.; Grujović, N.; Divac, D.; Milivojević, N. Predicting piezometric water level in dams via artificial neural networks. Neural Comput. Appl. 2014, 24, 1115–1121. [Google Scholar] [CrossRef]
- Granrut, M.; Simon, A.; Dias, D. Artificial neural networks for the interpretation of piezometric levels at the rock-concrete interface of arch dams. Eng. Struct. 2019, 178, 616–634. [Google Scholar] [CrossRef]
- Rico, J.; Barateiro, J.; Mata, J.; Antunes, A.; Cardoso, E. Applying Advanced Data Analytics and Machine Learning to Enhance the Safety Control of Dams. In Machine Learning Paradigms: Applications of Learning and Analytics in Intelligent Systems 1; Tsihrintzis, G.A., Virvou, M., Sakkopoulos, E., Jain, L.C., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 315–350. [Google Scholar]
- Li, M.; Wang, J. An Empirical Comparison of Multiple Linear Regression and Artificial Neural Network for Concrete Dam Deformation Modelling. Math. Probl. Eng. 2019, 2019, 7620948. [Google Scholar] [CrossRef] [Green Version]
- Ren, Q.; Li, M.; Li, H.; Shen, Y. A novel deep learning prediction model for concrete dam displacements using interpretable mixed attention mechanism. Adv. Eng. Inform. 2021, 50, 101407. [Google Scholar] [CrossRef]
- Chen, S.; Gu, C.; Lin, C.; Wang, Y.; Hariri-Ardebili, M.A. Prediction, monitoring, and interpretation of dam leakage flow via adaptative kernel extreme learning machine. Measurement 2020, 166, 108161. [Google Scholar] [CrossRef]
- Kang, F.; Li, J.; Zhao, S.; Wang, Y. Structural health monitoring of concrete dams using long-term air temperature for thermal effect simulation. Eng. Struct. 2019, 180, 642–653. [Google Scholar] [CrossRef]
- Qu, X.; Yang, J.; Chang, M. A Deep Learning Model for Concrete Dam Deformation Prediction Based on RS-LSTM. J. Sens. 2019, 2019, 4581672. [Google Scholar] [CrossRef]
- Ranković, V.; Grujović, N.; Divac, D.; Milivojević, N. Development of support vector regression identification model for prediction of dam structural behaviour. Struct. Saf. 2014, 48, 142–149. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.A.; Pourkamali-Anaraki, F. Support vector machine based reliability analysis of concrete dams. Soil Dyn. Earthq. Eng. 2018, 104, 276–295. [Google Scholar] [CrossRef]
- Dai, B.; Gu, C.; Zhao, E.; Qin, X. Statistical model optimized random forest regression model for concrete dam deformation monitoring. Struct. Control Health Monit. 2018, 25, e2170. [Google Scholar] [CrossRef]
- Salazar, F.; Toledo, M.A.; Oñate, E.; Suárez, B. Interpretation of dam deformation and leakage with boosted regression trees. Eng. Struct. 2016, 119, 230–251. [Google Scholar] [CrossRef] [Green Version]
- Salazar, F.; Morán, R.; Toledo, M.Á.; Oñate, E. Data-Based Models for the Prediction of Dam Behaviour: A Review and Some Methodological Considerations. Arch. Comput. Methods Eng. 2017, 24, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Sargent, R. Verification and validation of simulation models. In Proceedings of the 2010 Winter Simulation Conference, Baltimore, MD, USA, 5–8 December 2010. [Google Scholar]
- Schweinsberg, M.; Feldman, M.; Staub, N.; van den Akker, O.R.; van Aert, R.C.M.; van Assen, M.A.L.M.; Liu, Y.; Althoff, T.; Heer, J.; Kale, A.; et al. Same data, different conclusions: Radical dispersion in empirical results when independent analysts operationalize and test the same hypothesis. Organ. Behav. Hum. Decis. Process. 2021, 165, 228–249. [Google Scholar] [CrossRef]
- Childers, C.P.; Maggard-Gibbons, M. Same data, opposite results? A call to improve surgical database research. JAMA Surg. 2020, 156, 219–220. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, T.M. Machine Learning; McGraw Hill: Burr Ridge, IL, USA, 1997; Volume 45, pp. 870–877. [Google Scholar]
- Mata, J.; Leitao, N.S.; de Castro, A.T.; da Costa, J.S. Construction of decision rules for early detection of a developing concrete arch dam failure scenario. A discriminant approach. Comput. Struct. 2014, 142, 45–53. [Google Scholar] [CrossRef] [Green Version]
- Salazar, F.; Conde, A.; Vicente, D.J. Identification of Dam behaviour by Means of Machine Learning Classification Models. In Lecture Notes in Civil Engineering, Proceedings of the ICOLD International Benchmark Workshop on Numerical Analysis of Dams, ICOLD-BW, Milan, Italy, 9–11 September 2019; Springer: Cham, Switzerland, 2019; Volume 91, pp. 851–862. [Google Scholar]
- Willm, G.; Beaujoint, N. Les méthodes de surveillance des barrages au service de la production hydraulique d’Electricité de France-Problèmes ancients et solutions nouvelles. In Proceedings of the 9th ICOLD Congres, Istanbul, Turkey, 4–8 September 1967; Volume III, pp. 529–550. (In French). [Google Scholar]
- Montgomery, D.C.; Runger, G.C. Applied Statistics and Probability for Engineers; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1994. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 4th ed.; Prentice Hall: Hoboken, NJ, USA, 1998. [Google Scholar]
- Kutner, M.H.; Nachtsheim, C.J.; Neter, J.; Li, W. Applied Linear Statistical Models, 5th ed.; McGraw-Hill Higher Education: New York, NY, USA, 2004. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Firedman, J. The Elements of Statistical Learning-Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Stojanovic, B.; Milivojevic, M.; Milivojevic, N.; Antonijevic, D. A self-tuning system for dam behaviour modeling based on evolving artificial neural networks. Adv. Eng. Softw. 2016, 97, 85–95. [Google Scholar] [CrossRef]
- Kao, C.Y.; Loh, C.H. Monitoring of long-term static deformation data of Fei-Tsui arch dam using artificial neural network-based approaches. Struct. Control Health Monit. 2013, 20, 282–303. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Díaz-Uriarte, R.; Alvarez de Andrés, S. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 20. [Google Scholar] [CrossRef] [Green Version]
- Moguerza, J.M.; Muñoz, A. Support vector machines with applications. Stat. Sci. 2006, 21, 322–336. [Google Scholar] [CrossRef] [Green Version]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Fisher, W.D.; Camp, T.K.; Krzhizhanovskaya, V.V. Anomaly detection in earth dam and levee passive seismic data using support vector machines and automatic feature selection. J. Comput. Sci. 2017, 20, 143–153. [Google Scholar] [CrossRef]
- Cheng, L.; Zheng, D. Two online dam safety monitoring models based on the process of extracting environmental effect. Adv. Eng. Softw. 2013, 57, 48–56. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.A.; Salazar, F. Engaging soft computing in material and modeling uncertainty quantification of dam engineering problems. Soft Comput. 2020, 24, 11583–11604. [Google Scholar] [CrossRef]
- Friedman, J. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Leathwick, J.; Elith, J.; Francis, M.; Hastie, T.; Taylor, P. Variation in demersal fish species richness in the oceans surrounding New Zealand: An analysis using boosted regression trees. Mar. Ecol. Prog. Ser. 2006, 321, 267–281. [Google Scholar] [CrossRef] [Green Version]
- Mata, J.; Tavares de Castro, A.; Sá da Costa, J. Quality control of dam monitoring measurements. In Proceedings of the 8th ICOLD European Club Symposium, Graz, Austria, 22–23 September 2010. [Google Scholar]
- Mata, J.; Martins, L.; Tavares de Castro, A.; Ribeiro, A. Statistical quality control method for automated water flow measurements in concrete dam foundation drainage systems. In Proceedings of the 18th International Flow Measurement Conference, Lisbon, Portugal, 26–28 June 2019. [Google Scholar]
- Mata, J.; Martins, L.; Ribeiro, A.; Tavares de Castro, A.; Serra, C. Contributions of applied metrology for concrete dam monitoring. In Proceedings of the Hydropower’15, ICOLD, Stavanger, Norway, 14–19 June 2015. [Google Scholar]
- Sun, X.Y.; Newham, L.T.H.; Croke, B.F.W.; Norton, J.P. Three complementary methods for sensitivity analysis of a water quality model. Environ. Model. Softw. 2012, 37, 19–29. [Google Scholar] [CrossRef]
- Song, X.; Zhang, J.; Zhan, C.; Xuan, Y.; Ye, M.; Xu, C. Global sensitivity analysis in hydrological modeling: Review of concepts, methods, theoretical framework, and applications. J. Hydrol. 2015, 523, 739–757. [Google Scholar] [CrossRef] [Green Version]
- Borgonovo, E.; Plischke, E. Sensitivity analysis: A review of recent advances. Eur. J. Oper. Res. 2016, 248, 869–887. [Google Scholar] [CrossRef]
- Pianosi, F.; Beven, K.; Freer, J.; Hall, J.W.; Rougier, J.; Stephenson, D.B.; Wagener, T. Sensitivity analysis of environmental models: A systematic review with practical workflow. Environ. Model. Softw. 2016, 79, 214–232. [Google Scholar] [CrossRef]
- Pang, Z.; O’Neill, Z.; Li, Y.; Niu, F. The role of sensitivity analysis in the building performance analysis: A critical review. Energy Build. 2020, 209, 142–149. [Google Scholar] [CrossRef]
- Douglas-Smith, D.; Iwanaga, T.; Croke, B.F.W.; Jakeman, A.J. Certain trends in uncertainty and sensitivity analysis: An overview of software tools and techniques. Environ. Model. Softw. 2020, 124, 142–149. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- RStudio Team. RStudio: Integrated Development Environment for R; R Studio, Inc.: Boston, MA, USA, 2019. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 0-387-95457-0. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Therneau, T.; Atkinson, B. rpart: Recursive Partitioning and Regression Trees; R Package Version 4.1-15; R Foundation for Statistical Computing: Vienna, Austria, 2019. [Google Scholar]
- Peters, A.; Hothorn, T. ipred: Improved Predictors; R Package Version 0.9-11; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Slowikowski, K. ggrepel: Automatically Position Non-Overlapping Text Labels with ‘ggplot2’; R Package Version 0.9.1; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Greenwell, B.; Boehmke, B.; Cunningham, J. gbm: Generalized Boosted Regression Models; R Package Version 2.1.8; CRAN: Vienna, Austria, 2020. [Google Scholar]
- Muralha, A.; Couto, L.; Oliveira, M.; Dias da Silva, J.; Alvarez, T.; Sardinha, R. Salamonde dam complementary spillway. Design, Hydraulic model and ongoing works. In Proceedings of the Dam World Conference, Lisbon, Portugal, 21–25 April 2015. [Google Scholar]
- Cortez, P.; Embrechts, M. Using sensitivity analysis and visualization techniques to open black box data mining models. Inf. Sci. 2013, 225, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Guo, X.; Baroth, J.; Dias, D.; Simon, A. An analytical model for the monitoring of pore water pressure inside embankment dams. Eng. Struct. 2018, 160, 356–365. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relevant Publications | ||
|---|---|---|
| Algorithm | Theory and Fundamentals | Practical Implementation |
| Neural networks | [35] | [7,8] |
| Support Vector Machines | [38,39] | [18,40,41] |
| Random Forests | [36] | [19,42] |
| Boosted Regression Trees | [43,44] | [20,45] |
| Validation Technique | Description |
|---|---|
| Historical data validation | Part of the data is used to build the model, and the remaining data are used to determine (test) whether the model reproduces the behaviour of the system. |
| Sensitivity analysis | The values of the input variables are changed and the effect on the model output is analyzed, which should resemble the observed behaviour of the real system. This technique can be used qualitatively—directions only of outputs—and quantitatively—both directions and (precise) magnitudes of outputs. |
| Predictive validation | The model is used to generate predictions of the behaviour of the system, which are later compared to the observed response to identify anomalies and draw conclusions regarding the safety state of the dam. The data may come from an operational system or be obtained by conducting experiments on the system, e.g., field tests. |
| Comparison to other models | This action is transversal and is performed for all three previous processes, i.e., results of different models in terms of historical data validation, sensitivity analysis, and predictive validation are compared and discussed. |
| Time evolution of the residuals | This action allows to easily identify if there are singularities on the observed behaviour or sometrend (such as a change of the observed pattern) over time. |
| Radial displ. (mm) | Water Height (m) | ||||
|---|---|---|---|---|---|
| Training Set | Predicted Set | Training Set | Predicted Set | ||
| Mean | (mm) | 14.49 | 9.90 | 66.16 | 69.09 |
| Max | (mm) | 39.9 | 26.9 | 74.1 | 73.46 |
| Min | (mm) | −4.1 | −3.5 | 45.8 | 62.64 |
| (mm) | 10.58 | 7.69 | 6.60 | 2.60 | |
| MLR | SVR | NN | RF | BRT | ||
|---|---|---|---|---|---|---|
| mean() | (mm) | 0.00 | 0.07 | 0.02 | −0.01 | 0.02 |
| mean() | (mm) | 2.12 | 1.33 | 1.51 | 0.84 | 1.81 |
| MAPE | (%) | 42.78 | 34.41 | 34.33 | 25.86 | 47.45 |
| (mm) | 8.02 | 8.90 | 7.81 | 5.04 | 7.51 | |
| (mm) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| RMSE | (mm) | 2.60 | 1.88 | 1.97 | 1.15 | 2.22 |
| MLR | SVR | NN | RF | BRT | ||
|---|---|---|---|---|---|---|
| mean() | (mm) | −0.61 | −0.25 | −0.29 | −0.47 | −0.52 |
| mean() | (mm) | 1.66 | 1.84 | 1.85 | 1.99 | 1.92 |
| MAPE | (%) | 38.41 | 34.85 | 37.26 | 46.88 | 58.21 |
| (mm) | 4.69 | 7.05 | 7.44 | 6.92 | 6.47 | |
| (mm) | 0.00 | 0.01 | 0.01 | 0.00 | 0.02 | |
| RMSE | (mm) | 2.02 | 2.39 | 2.40 | 2.51 | 2.42 |
| Time Series | Standard Deviation (mm) | |
|---|---|---|
| Training Set | Predicted Set | |
| Observations | 10.58 | 7.69 |
| MLR | 10.25 | 7.86 |
| SVR | 10.43 | 7.9 |
| NN | 10.45 | 7.97 |
| BRT | 10.35 | 8.12 |
| RF | 10.19 | 7.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mata, J.; Salazar, F.; Barateiro, J.; Antunes, A. Validation of Machine Learning Models for Structural Dam Behaviour Interpretation and Prediction. Water 2021, 13, 2717. https://doi.org/10.3390/w13192717
Mata J, Salazar F, Barateiro J, Antunes A. Validation of Machine Learning Models for Structural Dam Behaviour Interpretation and Prediction. Water. 2021; 13(19):2717. https://doi.org/10.3390/w13192717
Chicago/Turabian StyleMata, Juan, Fernando Salazar, José Barateiro, and António Antunes. 2021. "Validation of Machine Learning Models for Structural Dam Behaviour Interpretation and Prediction" Water 13, no. 19: 2717. https://doi.org/10.3390/w13192717
APA StyleMata, J., Salazar, F., Barateiro, J., & Antunes, A. (2021). Validation of Machine Learning Models for Structural Dam Behaviour Interpretation and Prediction. Water, 13(19), 2717. https://doi.org/10.3390/w13192717