1. Introduction
Water quality monitoring networks are essential for regulatory bodies including governments and policymakers for evaluating and managing water pollution. In the last fifty years, water quality monitoring networks of different spatial and temporal scales have been created by various environmental agencies and regulators in many countries [
1]. However, taking into account the increasing rate of human industrial activity and growth of the population, we must admit that the monitoring networks established decades ago may be insufficient to meet the demands imposed by the current trends in pollution. Moreover, the system should be not only efficient but also cost-effective. One of the topical issues that should be addressed is that an average concentration over the monitoring sites is sensitive to biases in the monitoring network. Though it may seem to be effective to create a well-distributed network of locations exclusively, the actual selection of points for water quality monitoring depends on several site-specific factors: what the locations of the existing wells, springs, and rivers are; how suitable these sources could be by for water sampling; whether they are accessible or not; what budget and time are available. Merging and improving older networks not infrequently may result in subsequent streamlining, rationalizing, and modifying their composition. Another approach to optimize current monitoring methodologies is harnessing new ecological monitoring data. This is especially useful for a water monitoring program on a regional scale. The aforementioned issues could be addressed using machine learning approaches and various optimization algorithms.
The approaches currently proposed to tackle the problem of optimizing water quality monitoring networks can be roughly classified into two categories: analytical methods and meta-heuristic algorithms. Among the former multi-criteria decision and multivariate statistical approaches seem to be most popular [
2,
3,
4]. Some studies suggest clustering of water quality data based on a dynamic algorithm for choosing optimal water sampling locations [
5]. The other one apply graph theory combined with a simulated annealing for optimized selection of river sampling sites [
6]. There is a research proposal to use Principal Component Analysis [
7] in order to find optimum monitoring positions and ultimately to reduce the monitoring costs.
Most studies focus on searching for and selecting an optimal position to install the equipment for observing large surface water bodies, such as rivers and lakes. Meanwhile, natural groundwater outlets, such as wells and springs, have yet received much less attention [
8], since they normally appear to be among the least damaged freshwaters in the investigated area [
9]. Additionally, at present, only few articles encompass the information about the integrated water quality index [
10].
The problem of finding the best subset of training samples to optimize an existing network of water quality assessment could be considered as a combinatorial optimization problem. The methods for solving such problems can be roughly divided into two groups: the exact methods and approximate ones [
11]. For solving NP-hard problems that are difficult to approach, metaheuristic algorithms are used [
12,
13]. However, these algorithms do not guarantee that an optimal solution would be found. Still they are widely used in practice as they allow users to obtain good solutions in reasonable time. Genetic algorithms also tend to be quite popular and are used for optimizing monitoring networks [
14,
15].
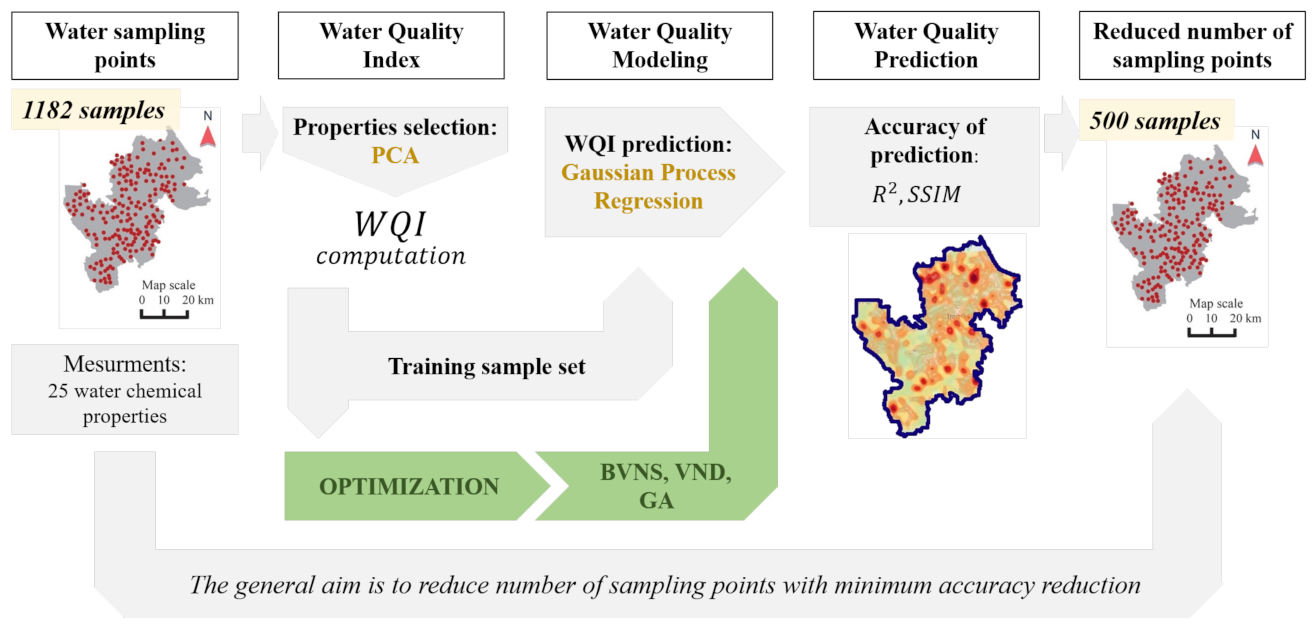
The present research aims to evaluate the effectiveness and robustness of genetic algorithms and compare them to variable neighborhood search family algorithms for solving problem of water quality assessment. We aimed to create an approach that would reduce the number of tested water-quality sites. One of the key feature of the proposed approach is that it allows user to find optimal sampling set of points capturing (i) the locations with the highest pollution rate and (ii) the locations representing the average regional level of pollution. To accomplish these goals, metaheuristic approaches were tested for optimization and multi-factors assessment of water quality monitoring in the New Moscow area. Namely, the dataset including 1182 samples from wells was analyzed. Our approach included five steps: selecting environmental factors, dividing the sampling grid, setting the initial stations, optimizing the sampling stations, and assessing reproducibility and efficiency of the proposed network.
2. Materials and Methods
2.1. Dataset for Case Study
Natural groundwater resources, such as springs, wells, and small rivers, are primary sources of fresh water in many countries, including Russia. They usually reflect human-made pollution sources, and environmental changes in soils and air [
9,
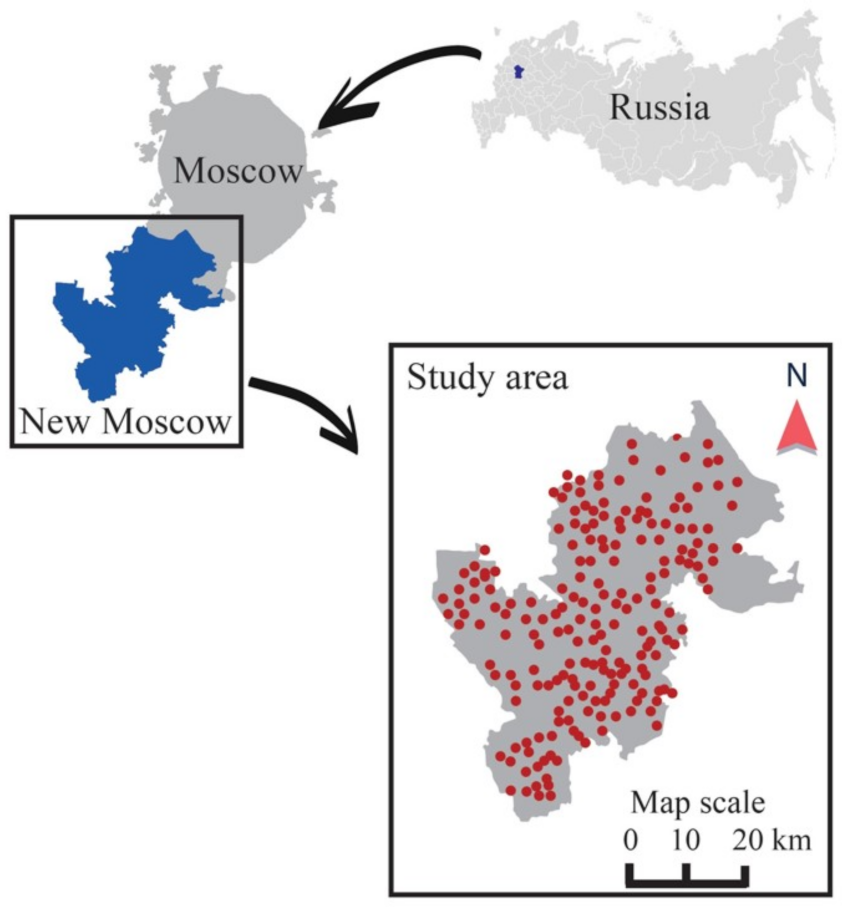
16]. To adjust the proposed approach, we used the dataset obtained in the course of the study by large-scale monitoring of small water bodies in New Moscow (see
Figure 1), which is now part of Moscow, Russia.
The New Moscow region was chosen to be the case study because of its unusually great abundance of monitoring sites. We should mention that not all researches can boast such a wide and various range of samples, which should definitely give rise to the need for methods that evaluate the urbanization trend (i.e., the overall change in concentration across the network of monitoring sites) in the absence of long-term monitoring sites.
This dataset under discussion includes three types of water sources: wells (1215 samples), springs (225 samples), small rivers (160 samples) monitored in 2017–2018—1600 samples in total [
17]. Wells were selected to be an object for the research since they comprise the largest part of the sample set, 1182 samples remained on the list after outliers have been excluded. The outliers were discarded based on DBSCAN clustering algorithm (this methodology was described in detail in [
18]). Each sample was evaluated according to 25 parameters of chemical properties. In order to use the model, we scaled all coordinates from 0 to 10. The Universal Transverse Mercator coordinate system [
19] was used to ensure a correct conversion of geographical coordinates. The conversion was carried out using the
utm library for python [
20].
2.2. Integral Water Quality Index
Water quality assessment is usually based on a large number of parameters, i.e., physical and chemical characteristics (25 items in our case). One of the challenging task was to integrate the measured parameters within a single meaningful composite value (Water Quality Index—WQI). WQI was supposed to be a function of the measured parameters and represent the water quality in the particular sampling point. Principal component analysis (PCA) has already been proposed as a means to aggregate all measurements into the final WQI without overestimating parameters [
21,
22]. In this study, we used the WQI geospatial modeling approach proposed by Shadrin et al. [
18]. This approach includes two steps: (i) calculating PCA-weighted WQI for each tested sample, (ii) applying Gaussian Process Regression (GPR) with optimal kernel structure search using Bayesian informational criteria in order to build a precise map of water quality distribution. It was successfully tested on a similar dataset and helped reveal the actual situation with water pollution.
A parameter selection work-flow for the further WQI construction, in brief, was as follows. According to previous study, from the whole data-set twenty-one parameters presented in water samples in significant concentrations were included in the PCA. From the output only components which corresponding eigenvalue was higher than or equal to 1 following Varimax rotation, and PCs that explained at least 5% of the observed data variation were considered for further calculations. Those parameters that were correlated with other significant parameters (correlation was more than 0.6) were eliminated if they had the smallest loadings among correlated parameters. After the above-mentioned data analysis procedures, only 12 parameters were left for constructing the water quality index.
Finally, water quality index was calculated using the following equation taken from the work [
18]:
The values of WQI were also scaled from 0 to 1. The general workflow of our research is presented on
Figure 2.
2.3. Optimization Algorithms
The optimization criteria for monitoring networks has certain limits. In the algorithms, the main priority was given to those sampling points which have the most diverse neighbors in terms of WQI values and which represented the regional average values. All algorithms are implemented in the Python programming language.
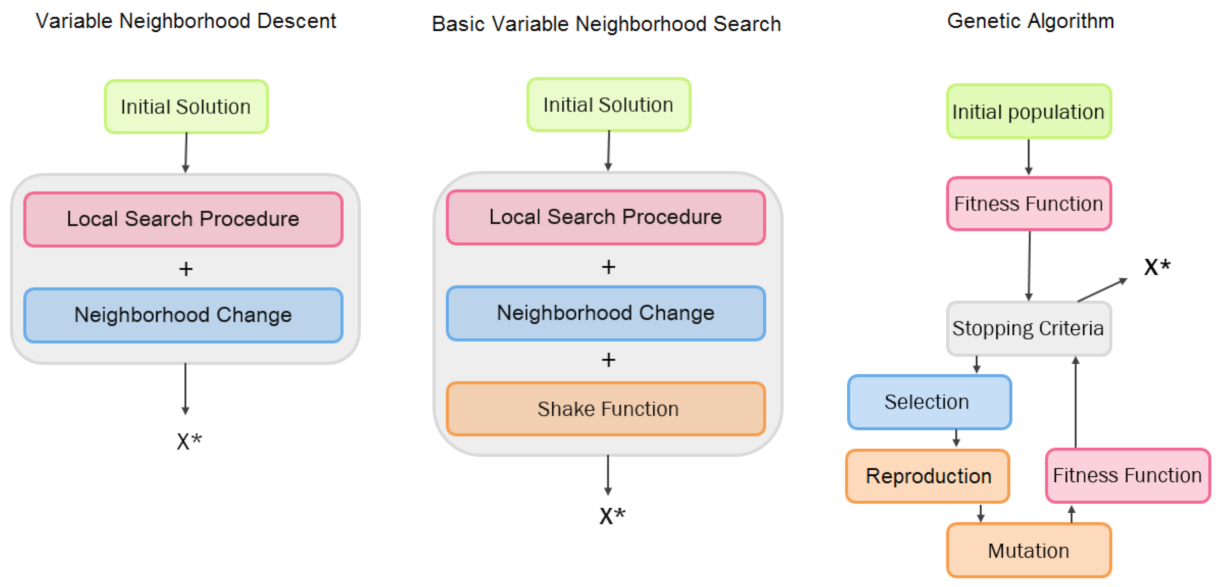
2.3.1. Variable Neighborhood Search Algorithms
Two algorithms from the Variable Neighborhood Search (VNS) family were applied to the following cases: Variable Neighborhood Descent (VND) and basic VNS proposed by Hansen and Mladenovic in 2003 [
23] and 2007 [
24], respectively. The main idea of these methods is to change the neighborhoods and apply the local search procedure. Since the performance of VNS depends significantly on the choice of a neighborhood at each iteration [
25], we used the neighborhood structure based on geographical similarity and k-mean clustering. The initial solution was randomly selected. It had to contain at least one point from each cluster and, at the same time, to exclude points from the similar area; as a result, the solution divided all points into clusters according to their coordinate.
One of the most popular algorithms of the VNS family is Variable Neighborhood Descent (VND). In order to apply this algorithm for solving the problem, system of neighborhoods and the initial solution had to be specified. In this algorithm the change of neighborhood was applied in a deterministic way. The proceeding search was performed using the selected neighborhood that had been obtained using the best improvement, which tended to be the most effective strategy. If an improved solution was obtained, all neighborhood structures on the list would become available for the next iteration. The procedure ended when every enlisted structure had been exhaustively explored, and no other improvement could achieved. The final solution is a local minimum with respect to all neighborhoods.
Algorithm Basic Variable Neighborhood Search (BVNS) is based on VND with an additional Shake function [
26]. The idea of the Shake function is to generate a new solution that will not be close that would significantly differ from the current solution, which allows the optimizer to get away from the local optima.
VNS and BVNS implemented as randomized versions of these algorithms by searching only in part of the neighbor points. In each experiment the algorithms explore of neighbors.
For each run of the VND algorithm, the change of neighborhoods is specified by a random sequence of numbers; as for the BVNS algorithm, the order is defined both at the beginning and after each shake. Randomization of algorithms helps to avoid the local optima and reduce the running time of algorithms, and at the same time increases the variance of solutions.
2.3.2. Genetic Algorithm
Genetic algorithm (GA), an evolutionary algorithm, was inspired by processes of biological evolution observed in the nature, such as crossover, mutation, and selection [
27,
28]. GA has been widely used for generating high-quality solutions to solve optimization problems. The procedure of GA has four parts: generating initial population, crossover operation, mutation operation, and selection (see
Figure 3). A typical genetic algorithm requires a genetic representation of the solution domain and a fitness function to evaluate it.
In the case with genetic algorithm the fitness function is considered to be an objective function. It is calculated in the same way as in VND and BVNS by maximizing
score (all details about
score and accuracy evaluation are discussed in
Section 2.6. The solution to the optimization problem is a binary vector of length N, where N is the whole training data size. In this vector, ones correspond to the points included in the new training sample set and zeros correspond to the remaining points. The initial population of solutions is chosen randomly in the same way as the start solution in VND and BVNS algorithms. The size of the initial population is regarded as an algorithm parameter. The fitness function decides which of the current population solutions should be included in the next population. In this case, the probability of choice depends on the place in the list of solutions sorted by the value of the fitness function.
Number N of the solutions to be selected in the following population is an algorithm parameter. Two or more parents are required for reproduction in genetic algorithms. At that, the offspring inherits features from both parents. In the algorithm, we used the strategy when both parents are randomly selected; thus, each individual in the population has an equal chance of being selected.
2.4. Baseline
Some preliminary actions are to be taken before the algorithms get compared; namely, it should be investigated whether they consider the problem in general terms or deal with it in greater detail. Obviously, the solutions obtained using optimization algorithms would outperform random sampling. Thus, we propose using the values of metrics for randomly selected solutions as a baseline.
2.5. Water Quality Prediction
To reconstruct spatial distribution of WQI, Gaussian Process Regression (GPR) was used [
29]. Gaussian process is determined by its mean
and covariance (kernel)
functions:
where
is a vector of input parameters. In this case,
x is a vector of coordinates, so
.
To solve the problem of reconstruction, the combination of the basic kernels was used [
29,
30]. Kernel hyper-parameter was obtained by using Bayesian Information Criteria (BIC) [
31] according to [
18], the selected kernels are represented by Equations (
3) and (
4) (see
Table 1 for the obtained coefficients). The regression model for predicting the water quality index was implemented by using the
GPy library for python [
32].
Radial Basis Function (RBF)
Usually, all data are divided into two parts; one is used for training and the other for testing, in order to measure the quality of model predictions. Such an approach required us to consider different subsets of the training sample set. The training and testing data were evenly spread across the area (
Figure 4a): the size of test data was 119 sample (10% of the whole dataset) (
Figure 4c) and that of training data was 1063 samples (90% of the total set) (
Figure 4b).
2.6. Optimization Problem Formulation and Accuracy Evaluation
To estimate the performance of the above-described algorithms, two statistical indices were used. The former is the coefficient of determination denoted
, which shows how well the observed outcomes would be replicated by the model, based on the proportion of total variation of the outcomes explained by the model [
33].
In terms of optimization theory, the considered problem can be written as follows.
Suppose we are given a set of points
and
with corresponding target vectors
and
and regression model
. We need to find a subset
which will maximize the following objective function on the test set
:
where
is prediction of
on
and
is a metric for measuring model prediction quality. The best possible value of
score is 1.0. The goal is to find subset of training sample set which maximizes
score on the test set, so summation only for points in test set
The second statistical metric is the structural similarity index measure, denoted SSIM. This index is usually used for comparing two images. Since in our study we display the predicted water quality index on a map, we can treat the predictions of the model trained on different data ( subsets of different sizes from training set) as pictures to compare them.
The structural similarity index is calculated for various windows of an image [
34]. For two windows
x and
y of typical size
:
where
is mean
x,
—mean
y,
—variance
x,
—variance
y,
—covariance,
and
,
L—dynamic range of pixels
,
and
. For identical images the SSIM value is equal to 1.0.
SSIM score is significantly more computationally expensive than score; thus, we did not use it as the objective function for the considered optimization problems. Still, we calculated the SSIM index for the best solutions that were found.
3. Results and Discussion
Figure 5 shows the result of comparing all algorithms. We plotted
score (a, b, c) and SSIM score (d, e, f) against the training sample size. Red lines on the graph correspond to the algorithms, while blue ones show the baseline, which contained 10 random solutions. The black line stands for the score on full training data.
We obtained 10 solutions by each algorithm using the same value of the parameter and plotted the confidence intervals. The baseline contains 10 random solutions. All the considered algorithms outperformed the baseline both by and ; BVNS showed the best results
Table 2 shows the best and average values of statistical characteristics for the considered algorithms obtained using the parameter search. The line “best perform n samples” in
Table 2 is the size of the training sample set. It is to be noted that that the problem under discussion and the implementation of BVNS algorithm appeared to get better solutions than others algorithms and had a smaller variance of values of the objective function. Moreover, the quality of prediction based on selected samples was higher than the quality of the prediction based on a full number of samples.
Figure 6 presenting spatial visualization of WQI prediction for water quality index predictions made using Gaussian Process Regression. In our case the sizes of training samples sets were 400, 500 and 700 sampling points. Noteworthily, predictions on 500 samples showed better results than predictions on 700 samples. The best performance was obtained by VND on 500 samples. We assume that the model finds specific patterns in the training data that described dependencies on the site better than the remaining data. This hypothesis requires further research in terms of multi-objective optimization.
The results show that all 3 algorithms managed to cope with the problem quite successfully. These algorithms helped to improve the quality of the prediction model from 0.73 to 0.9–0.93 of
score (
Table 2). Hence, the model can be claimed to be effective in finding in the training sample set some random patterns that have not described the data in general [
35]. Considering the structural similarity index, all algorithms also appeared to cope with a specified baseline. Moreover, the values of SSIM over 0.6 are considered as quite good for such an environmental problem.
All the abovementioned results were obtained by certain splitting data into train and test. The issue to be focused upon in the course of the study was whether the splitting data affect the solution of the optimization problem and what results we may face if all significant points would fall into the test sample. Normally, to estimate accuracy of the predictive model accuracy, the cross-validation procedure is used
Table A1. We used k-fold cross-validation (with k = 5, size of training part 80%, size of test part 20%). To estimate the values of the objective function on these splits, it is necessary to find a solution of the optimization problem
Based on the results of the greedy strategy, we would hypothesize that among the points, a certain subset of points mainly contributes to the quality of model predictions (e.g., this was the reason for a sharp jump of the
score in the value of size if the training set is 242 points, see
Figure 5). Having obtained this set, we observed no dramatic improvements in the objective function. When a lot of points were included in the training sample (over 800), the model found the patterns in the training data that do not describe the full data. The proposed hypothesis requires further investigation in terms of multi-objective optimization.
The dataset cross-validation process under discussion was found to affect insignificantly the search for the optimal subset of points if the points are uniformly distributed across the study area. Running time appeared to be the main factor that hampers the analysis of the implemented algorithms. Each calculation of the objective function required the regression model to be trained and tested. Since the algorithms are randomized to study the parameter space (as well as to search for the most suitable ones), the algorithms have to be run several times to obtain a sample of solutions for each parameter. Though the sample of 10 solutions does not seem large enough and sufficient, even such a sample does demonstrate the performance of the proposed algorithms.
The resultant approach can be further used to create effective systems for monitoring water quality in other geographical areas. To do so, firstly, an excessive number of measurements in a new area should be carried out; then, using the proposed optimization algorithms, the main points have to be determined at which water monitoring is required. At that, no modifying of the implemented algorithms are needed; users can only give the algorithms new data and get the results.
Moreover, the considered algorithms can be used in other monitoring problems, at which geographical coordinates of the points to be monitored and values of the necessary characteristics should be provided. Thus, to implement these algorithms, the prediction model has to be changed. All implemented algorithms accept the prediction model as an input parameter.
4. Conclusions
The considered algorithms (variable neighborhood descent, basic variable neighborhood search, genetic algorithm) make it possible to reduce the size of the training sample set. For instance, the number of points for monitoring water quality in the New Moscow area can be reduced by 500, which two times decreases the total cost of the analysis. The quality of prediction has initially reached 93%, which was later improved by 18% after the size of the training sample had been reduced. This may possibly be due to the model managed to detect some specific random patterns not describing the data in general. All the algorithms showed good results; the BVNS algorithm performed significantly better than others as regarded to the value of the objective function and its variance. Thus, it seems reasonable enough to use a combination of the algorithms to get better solutions. In addition, the implemented algorithms under investigation have been proved to be suitable for the optimization problem under consideration in similar monitoring cases.
The presented study provides a good starting point for discussion and further research. Future studies could investigate precisely the reasons why the fewer number of sampling points gives a better WQI prediction. Furthermore, an interesting topic for future work is considering the problem of water quality assessment as a multi-objective optimization problem. For example, score could be maximized simultaneously with minimization of sampling points number. In this case, a subset of sampling points could be considered not as a parameter of algorithm but as an input variable.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





