1. Introduction
Evapotranspiration is an important factor in the hydrological cycle and is used in water resource management for irrigation [
1,
2], drought estimation and monitoring [
3,
4,
5], and in estimation of crop production [
6,
7]. Evapotranspiration (ET) could be defined as the amount of water that is transferred from the Earth’s surface to the atmosphere, and it plays a significant role in the world’s ecosystem that is related to water, energy, and carbon cycles [
8,
9]. ET is affected by different factors, including precipitation, temperature, relative humidity, wind speed, and solar radiation [
10]. In addition, there is a common consent that terrestrial ET around the world has been changed as a result of climate change and human activity in the last decades [
11,
12,
13,
14,
15]. Therefore, in order to calculate terrestrial ET, it is necessary to recognize the roles of water management, the hydrological cycle, and the impact of climate change [
16,
17].
Reference evapotranspiration (ET
0) can be estimated using different methods and approaches, including statistical or empirical methods, remote-sensing methods, and physical model-based methods [
11]. In the first method, ET
0 is estimated using flux tower observations [
18,
19], while in the second method, ET
0 is calculated using the integration of remote-sensing data with experimental observations [
20,
21], the surface energy balance equation [
22,
23], Penman–Monteith or Priestley–Taylor equations [
24,
25,
26], and data assimilation methods [
27,
28,
29]. In the third method, ET
0 is estimated using a physical model alone or integrated with data-simulation algorithms [
30,
31,
32]. Although several studies have used these methods globally, the daily estimation of ET
0 using these methods comes with some uncertainty [
33]. Relative variation between the observed and estimated values was found to range from 14% to 44% [
34,
35]. On the other hand, Lysimeters provide more precise measurements of ET values, and many researchers estimate ET by employing the measurements of Lysimeters [
36,
37]. Unfortunately, the use of Lysimeters has some drawbacks such as the cost of installation and maintenance, in addition to environmental impacts. Additionally, the restricted number of Lysimeters impedes the observation of ET at specific locations [
38]. Based on the above, the development of new adequate methods to estimate reference evapotranspiration (ET
0) with more accuracy and low cost is important and necessary.
In the last decades, the use of machine learning (ML) has received more attention in the field of water resource management around the world, including ET
0 estimation. ML has been applied to estimate the parameters of hydrology [
39,
40,
41,
42,
43,
44,
45], hydraulics [
46,
47,
48,
49], and water quality by many researchers [
42,
50,
51,
52,
53]. Several previous studies have reported the capability of ML techniques in estimating ET
0 [
54]. A comparative study using two ML techniques, namely generalized regression neural networks (GRNN) and radial basis function neural networks (RBFNN), in addition to empirical methods for ET
0 estimation in Algeria, is presented in [
55]. It concluded that for ET
0 estimation, the results obtained from the use of GRNN are better than those obtained from using the RBF. Another ML model, which is the support vector machine (SVM) model, was developed for ET
0 estimation in [
56] using limited climatic data. They used different parameters such as maximum and minimum temperature, wind speed, and solar radiation with several input combinations. The results acknowledged that the SVM is useful for ET
0 estimation with acceptable accuracy. A comparison between an artificial neural network (ANN) with empirical approaches to estimate ET
0 using the daily meterological data has also been conducted [
57]. It used two types of ANN with three empirical approaches that included Priestley–Taylor, Makkink, Hargreaves, and mass transfer. In [
58], different machine learning techniques were used for ET
0 estimation with more actual and precise limited meteorological variables. The results generalized the relation between the various meteorological parameters. Moreover, the performance of ten ML techniques was evaluated in [
59]. It used three statistical indices that included RMSE, R
2, and bias to evaluate the modeling results. In [
60], a deep neural network (DNN) model was developed for ET
0 estimation using four meteorological stations in Turkey. In that study, the results of DNN were compared with results of ANN. The study revealed that the output of DNN was more accurate compared to that of ANN. In [
61], eight ML techniques were evaluated in estimating ET
0 using temperature data only. Additionally, the results were compared with the Hargreaves–Samani equation (a temperature-based equation). It was concluded that the accuracy of the developed models varied with various scenarios. Five machine learning models to predict daily ET
0 across ten meteorological stations in China were developed in [
62]. The results from comparison showed that the CAT model outperformed the other models. The overall findings of the previous studies indicate that the use of soft computing techniques for modeling the evaporation process is very promising, and further studies incorporating these techniques are recommended [
63].
In this research, seven scenarios with different climate variables were evaluated by employing four regression-based ML techniques. To the best of the authors’ knowledge, these regression-based ML methods have not been previously compared in estimating ET0 in a semi-arid region.
2. Materials and Methods
2.1. Study Area
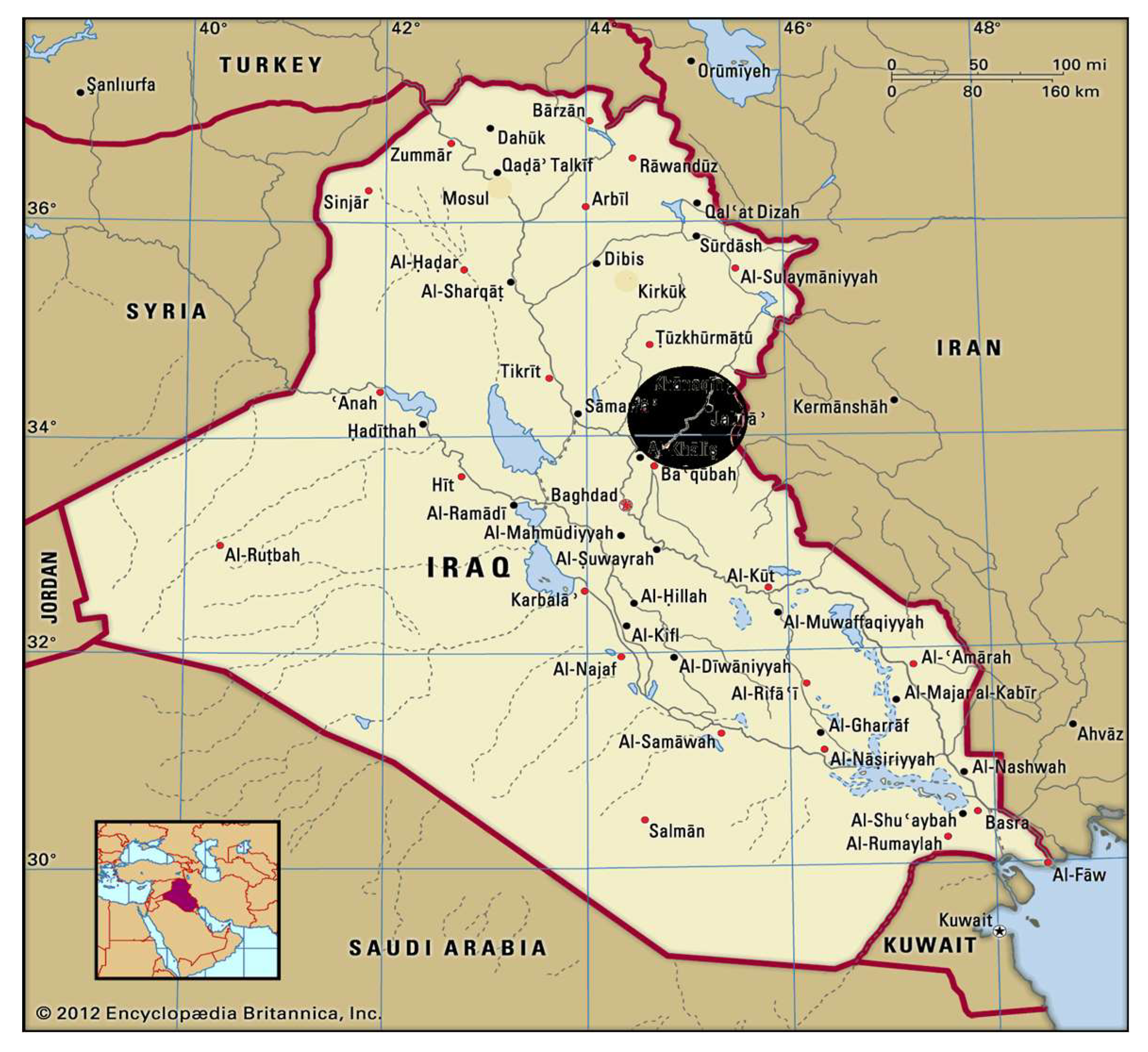
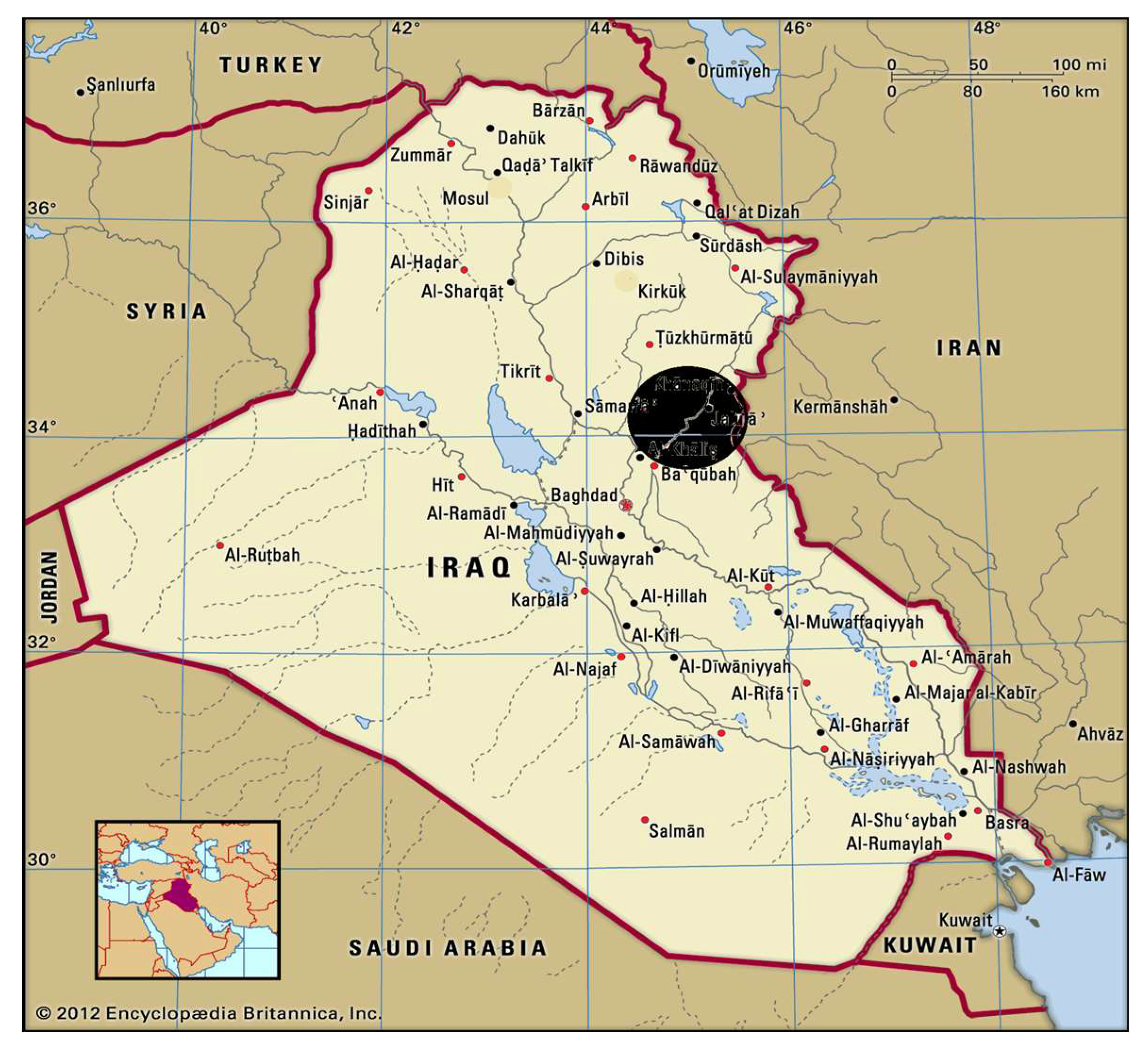
The catchment area of the Diyala River is at the eastern border of Iraq towards Iran. The northern part of it (within Iran) is mostly of mountainous character, with about 3000 m height. The Hemren Basin, a large catchment area located in the northeast of Iraq within the Diyala governorate, extends between (33°53′13.00″ to 35°25′41.61″ Northern latitude) and (44°30′47.68″ to 45°48′39.59″ Eastern longitude) inside Iraqi land, and it is located about 120 km northeast of Baghdad, the capital city in Iraq (
Figure 1).
The relief of study area is characterized with topographic differences, their elevation ranges vary from 225 to 900 m above M.S.L. Therefore, the area was divided into three main regions. The length of the Diyala River within the catchment area is about 150 km, with an average gradient of 1 m per kilometer. Meanwhile, the Alwand River, which is the main tributary on the left side of the Diyala River, has a gradient of 2 m/km. It drains an area of 3974 km2, and without the part in Iranian land, the area is 1974 km2. The Narin River, which is the largest tributary on the right side, has a small gradient with a catchment area of 2344 km2, and empties into the Diyala River near Hemren Mountains. Moreover, the downstream part of the catchment area, located between Derbendi Khan and Hemren, has lower altitudes and gradients.
2.2. Employed Data
In the present study, the capability of four regression-based machine learning methods, SVM, RF, BoT and BaT, was investigated for ET
0 estimation. Seven input scenarios were considered in this study using six climatic parameters, namely solar radiation (SR), wind speed (WS), relative humidity (RH), and maximum, mean, and minimum air temperatures (T
max, T
min, T
mean) as model inputs. The data were collected daily from five stations in Iraq, namely Mandali, Kalar, Iran–Iraq Border, Qarah-Tapah, and Adhim stations.
Table 1 shows the statistical properties of the meteorological stations. The daily climate data during the period of 1979–2014 were collected from the study area and used for model development.
2.3. Machine Learning Models
This section briefly explains the input combinations and machine leaning methods used in this study. ET mainly depends on temperature and other climate variables as stated by previous studies. The idea in this study was creating some scenarios including temperature as the first variable and then combining it with other variables to select which scenario was the best for predicting ET0.
Support Vector Machines (SVM) are widely recognized as powerful machine learning (ML) models that yield valuable outcomes in both classification and regression problems. The SVM methodology employs structural risk minimization during the training process, which results in several effective features for simulating complex problems [
46]. These features include the sparse presentation of solutions, good generalization ability, and the ability to avoid trapping in local minima. It is worth noting that the term Support Vector Regression (SVR) is commonly used for regression-based problems.
In this method, the input vector
x is transformed into a higher-dimensional space through nonlinear mapping, where linear regression is applied to the input vector. Considering a solution space with
x as the independent vector and
y as the dependent vector variables for the dataset having
N number of data pairs, the linear regression function can be written as:
where
φ(
x) represents a non-linear function that maps the low input space to the high output space;
w represents the weights vector, while
b denotes the threshold.
Unlike the SVR model, the other three ML models, RF, BaT, and BoT, are based on the concepts of decision and regression tree models that employ ensemble learning techniques. Decision tree learning is a supervised learning approach that is used to solve both classification and regression problems. Examples include Classification and Regression Tree (CART) models. In a decision tree model such as CART, each decision node in the tree represents a test on some input variables. Ensemble learning is a prosperous ML paradigm that merges a group of learners, rather than relying on a solitary learner, to forecast unfamiliar target attributes. It has been proven that using ensemble learning can improve the simulating and predicting results of individual models [
64]. In this respect, two types of ensemble learning methodologies, namely bagging (here for the Bat and RF models) and boosting (here for the BoT model), are applied.
As indicated by [
65], the BoT model incorporates important advantages of tree-based methods and has unique features. Its performance is based on an ensemble for training new samples. On the other hand, the bagging technique, also known as bootstrap aggregated, is an early ensemble method, which has numerous trees designed to improve the stability and accuracy of models. In the BaT, multiple independent decision trees can be constructed simultaneously on different segments of the training samples by utilizing distinct subsets of accessible characteristics.
Random forests are one of the most popular machine learning algorithms. They are so successful because they provide in general good predictive performance, low over-fitting, and easy interpretability. This interpretability is given by the fact that it is straightforward to derive the importance of each variable on tree decision. In other words, it is easy to compute how much each variable is contributing to the decision. The RF model acts similar to the BaT by constructing different decision trees. However, it uses a classification methodology for combining multiple trees to arrive at a conclusive outcome using the voting technique. Consequently, the RF classifier exhibits a robust ability to generalize. The RF can be considered as a specified type of the Bootstrap model. In each stage, the system has two subdivisions as unconnected segments to reduce the mean squared error values.
Feature selection through the random forest (RF) is categorized as an embedded method. Embedded methods encompass the advantages of both filter and wrapper techniques, as they rely on algorithms with built-in feature selection capabilities. Embedded methods offer several advantages, including:
High accuracy: They yield precise results.
Improved generalization: They enhance the model’s ability to apply learned patterns to new data.
Interpretability: They provide insights into the significance of selected features.
Random forest comprises multiple decision trees, each constructed using a random subset of observations and a random subset of features from the dataset. This means that not every tree processes all the features or observations. This design ensures that the trees are uncorrelated, reducing the risk of overfitting. Each tree is essentially a sequence of binary questions based on individual or combined features. At each node (corresponding to each question), the tree partitions the dataset into two groups, each containing observations that are more similar to each other and dissimilar to those in the other group. Consequently, the importance of each feature is determined by how “pure” each of these partitioned groups becomes.
2.4. Evaluation of Models’ Performance
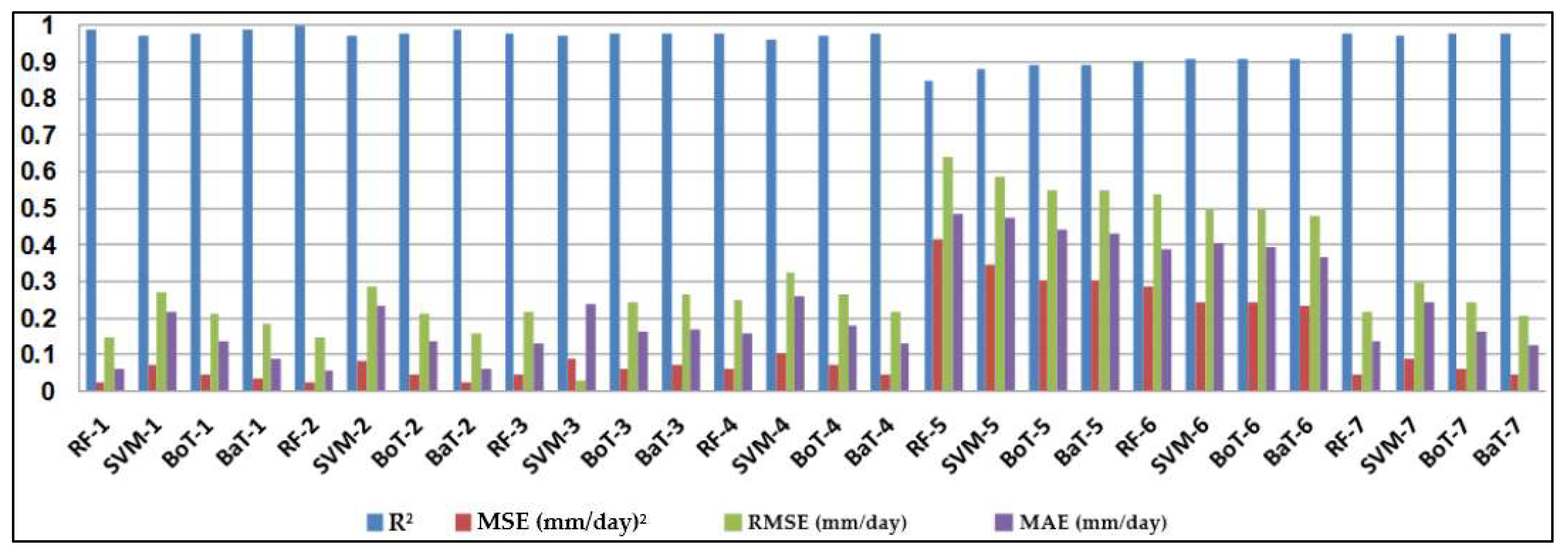
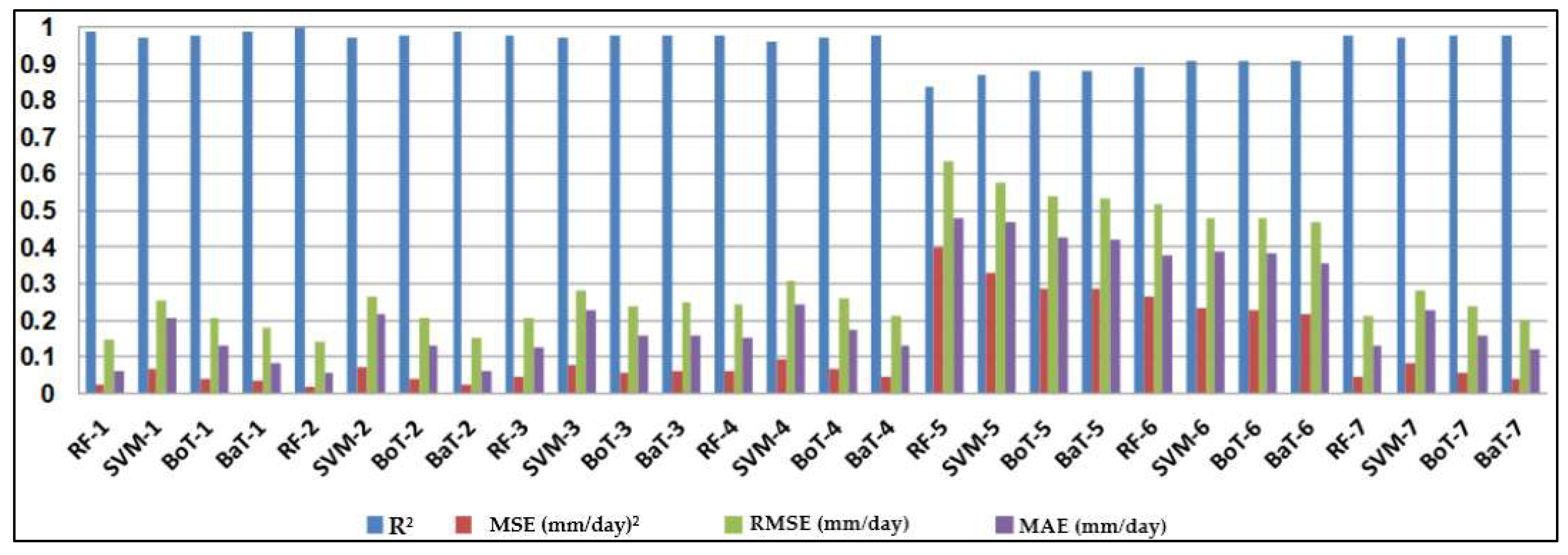
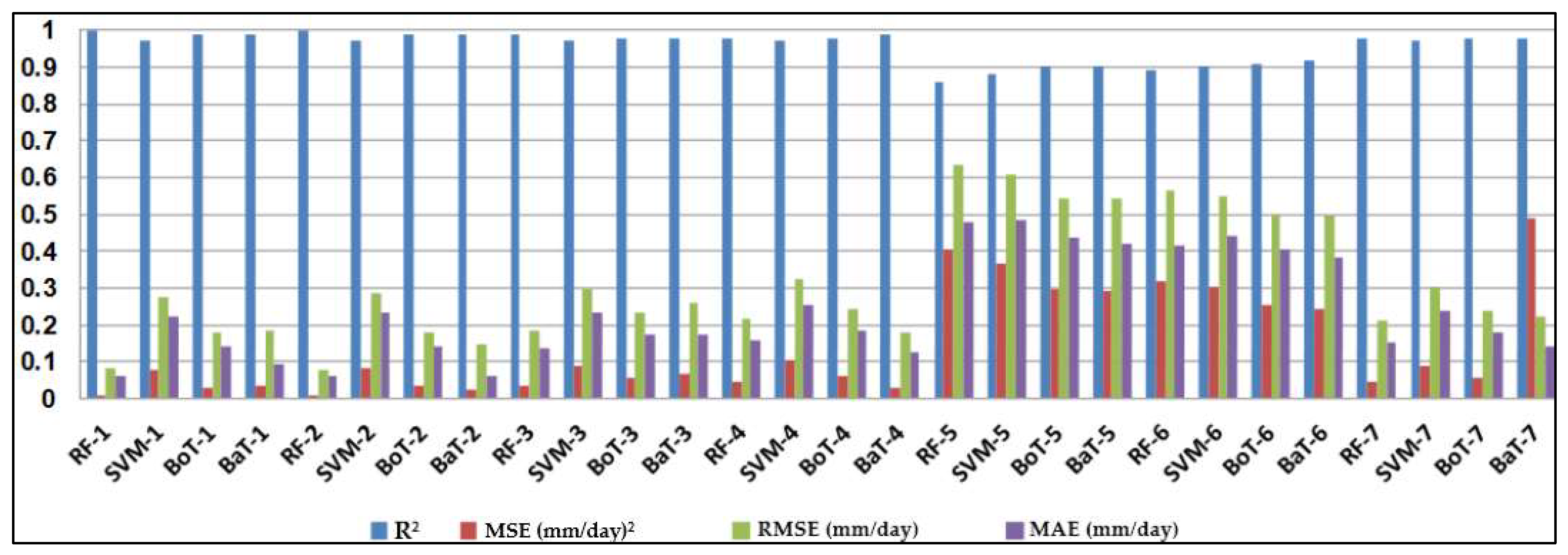
The most important step in using machine-learning models is evaluating their accuracy. Performance evaluation of the four soft computing models was conducted based on regression analysis using four statistical indices, namely mean absolute error (MAE), root mean square error (RMSE), mean square error (MSE), and coefficient of determination (R2).
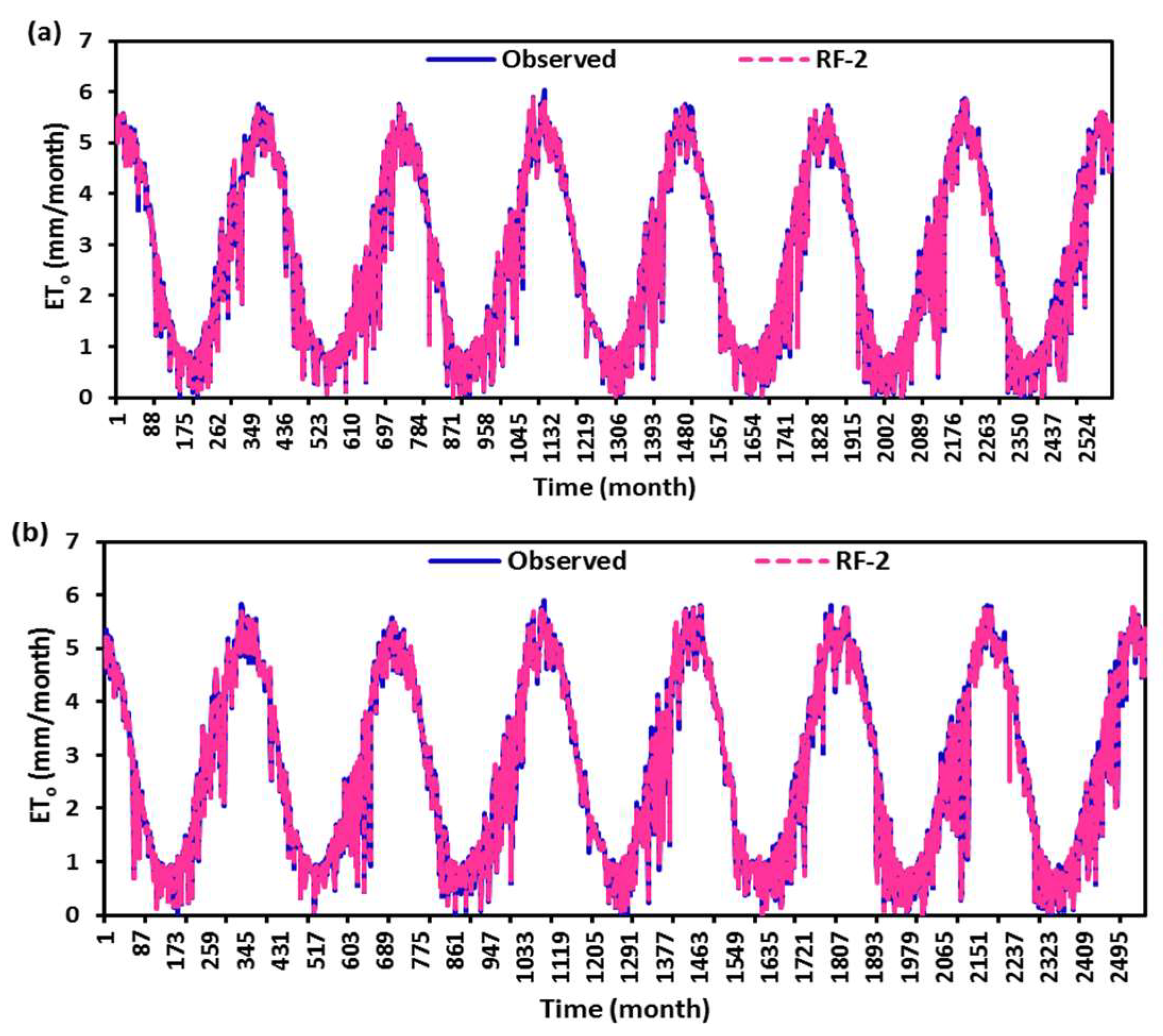
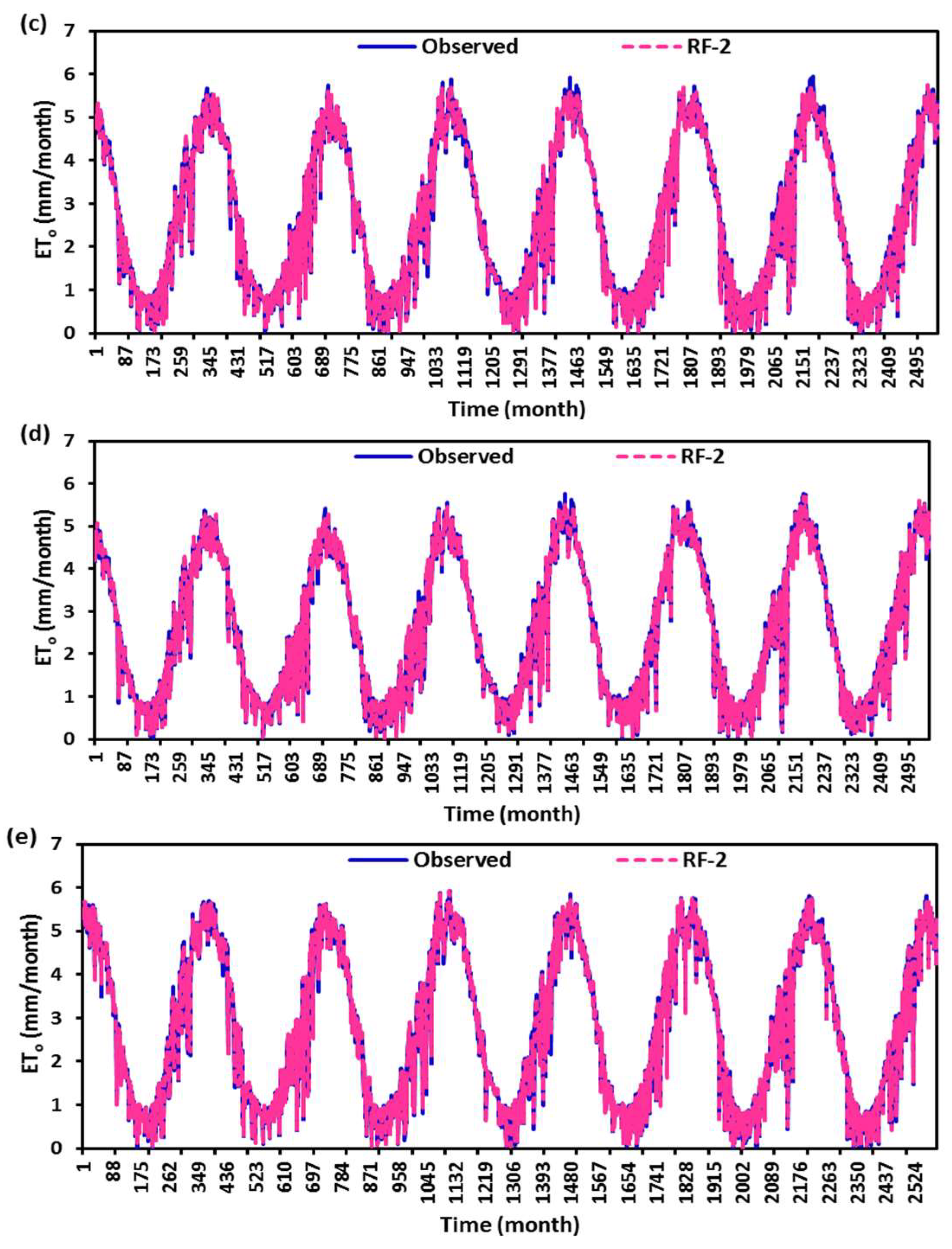
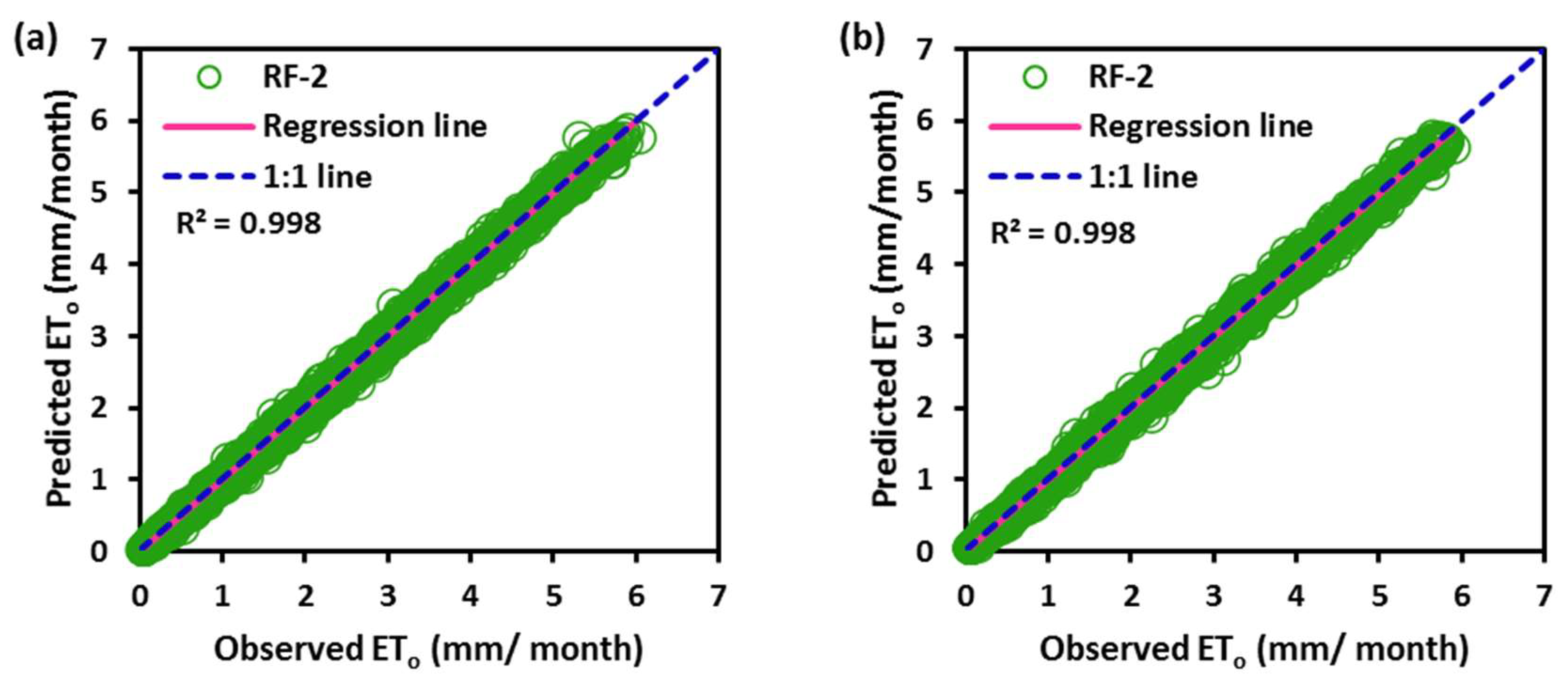
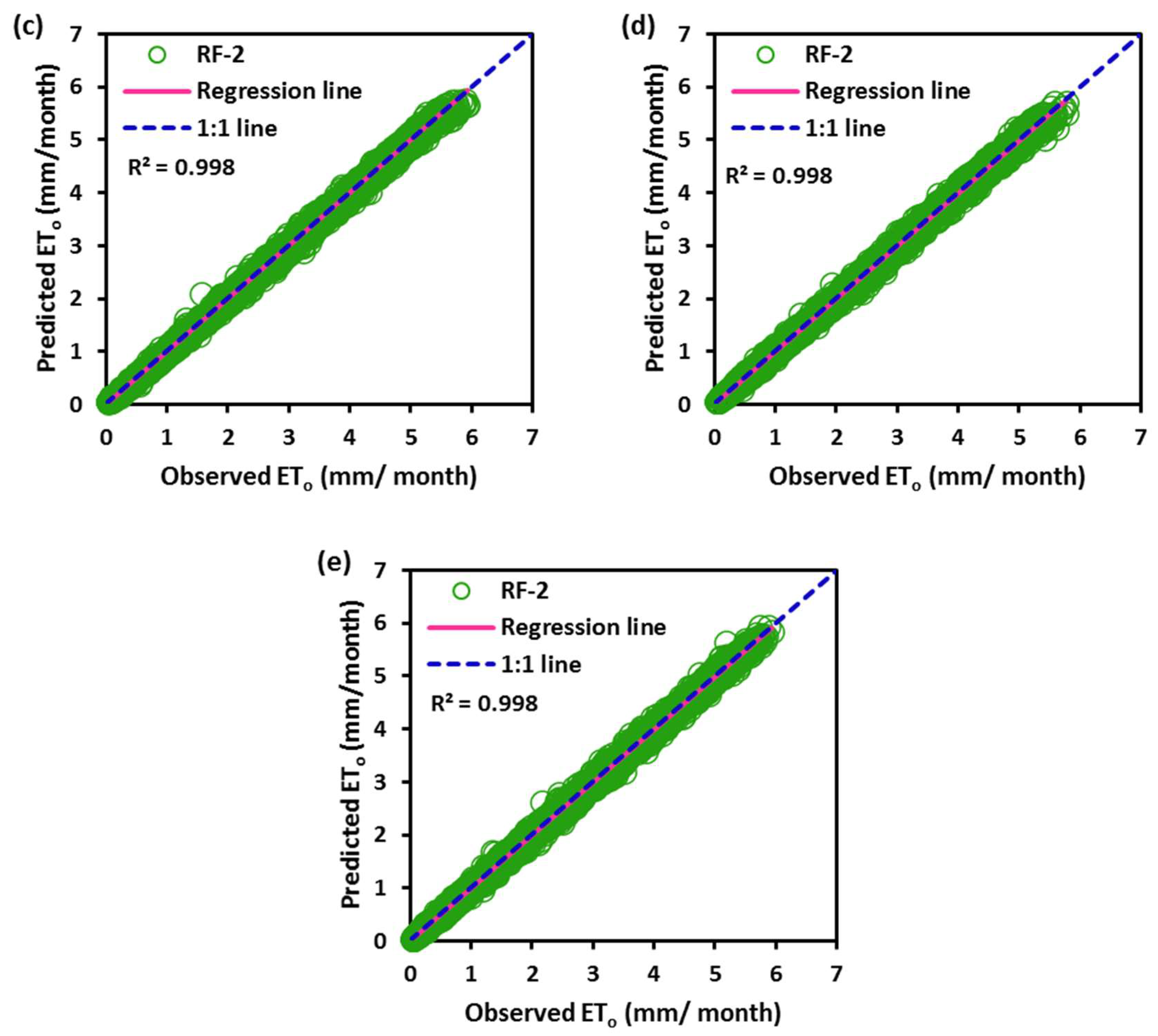
4. Discussion
Evapotranspiration plays a significant role in the hydrological cycle and finds applications in water resource management, including irrigation, as well as in the assessment and surveillance of drought conditions [
69,
70,
71,
72,
73,
74,
75,
76]. Four different regression-based machine learning methods were compared for modeling daily reference evapotranspiration (ET0) for a semi-arid region (the Hemren catchment basin in Iraq). The comparison statistics indicated that the random forest method with Tmax, Tmin, Tmean, and SR inputs performed superior to the other methods in estimating the daily ET
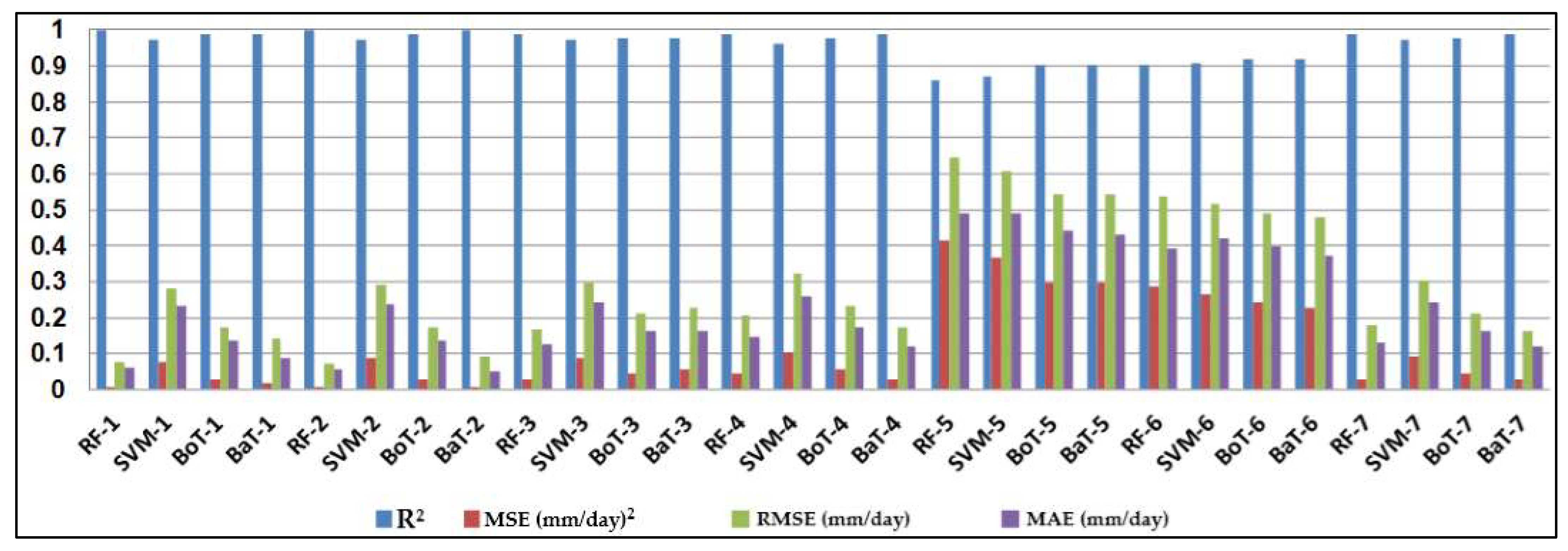
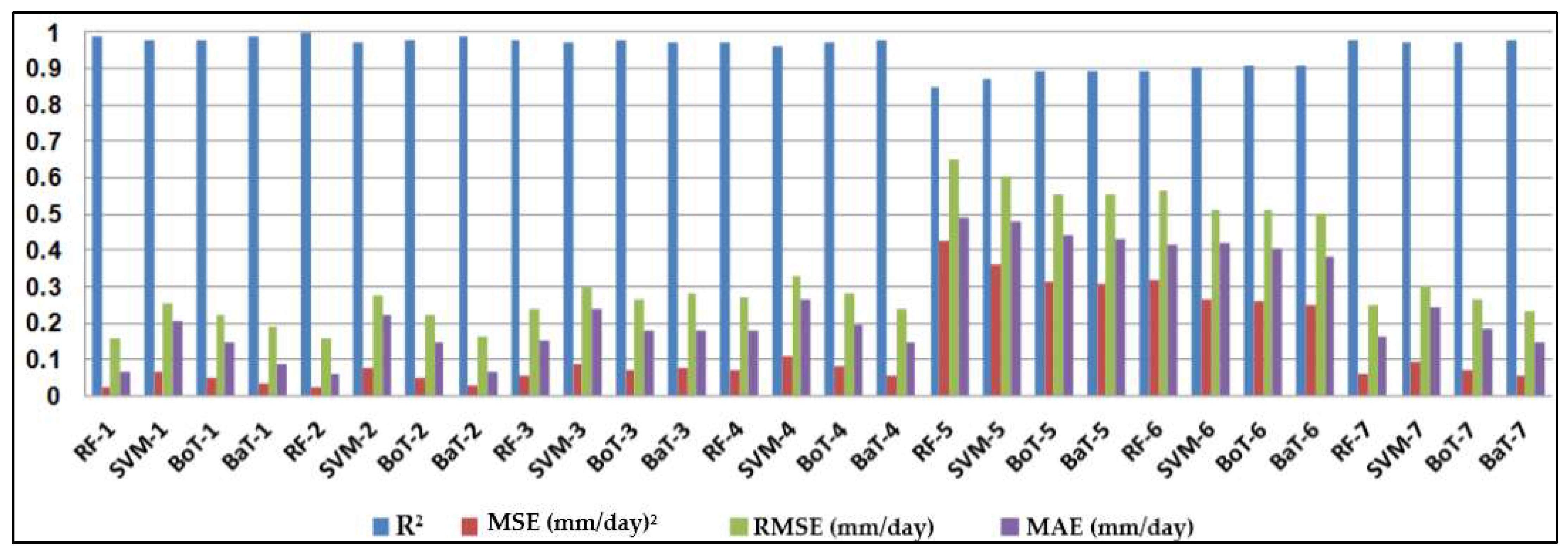
0 at all stations, while the SVM had the worst accuracy. Random forest (RF) is a popular machine-learning algorithm known for its strong predictive performance, minimal overfitting, and ease of interpretability. RF constructs multiple decision trees and combines them using a voting mechanism, resulting in robust generalization capabilities. One key feature of RF is its use of embedded methods for feature selection, which combines the strengths of filter and wrapper methods. Embedded methods are known for their high accuracy, excellent generalization, and interpretability. RF builds multiple decision trees, each using a random subset of data observations and features. This ensures that the trees are uncorrelated and less prone to overfitting. Each tree consists of a series of questions based on features, with each question dividing the data into two groups based on their similarity, ultimately determining the importance of each feature. In summary, RF is a powerful machine learning algorithm valued for its predictive abilities, robustness, and interpretability, making it a popular choice in various applications.
In [
55], ET
0 estimation was carried out using radial based artificial neural networks (RBNNs) and generalized regression artificial neural networks (GRNNs). The inputs for this estimation included daily mean relative humidity, sunshine duration, maximum and minimum air temperatures, mean air temperature, and wind speed. The study yielded the best R
2 values of 0.868 and 0.889 for the RBNN and GRNN, respectively. Granata and Nunno [
77] adopted two deep learning methods, NARX and LSTM, to model ET
0. They experimented with various input combinations, including solar radiation, mean air temperature, sensible heat flux, relative humidity, and lagged ET
0 values. The results showed R
2 values of 0.687 and 0.837 as the best performance achieved by the LSTM and NARX models, respectively. The table data in
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 clearly demonstrate that the proposed methods achieved remarkable success in modeling ET
0.
5. Conclusions
In this study, the applicability of four different regression-based machine learning methods in estimating ET0 was investigated. Climatic data from five stations located in a semi-arid region of Iraq was used as inputs to the models. According to comparison statistics (R2, MSE, RMSE, and MAE) and graphical inspection, the random forest model offered the best ET0 estimates in all stations, while the SVM provided the worst accuracy. Employing various combinations of climatic inputs revealed that the models with Tmax, Tmin, Tmean, and SR inputs produced the best estimations. The best random forest model with Tmax, Tmin, Tmean, and SR improved the estimation accuracy of the SVM, BoT, and BaT models by 94%, 83%, and 38% for Qarah-Tapah, by 68%, 50%, and 8% for Mandali, by 73%, 49%, and 8% for Kalar, by 72%, 51%, and 9% for Iran–Iraq Border, and by 93%, 81%, and 73% for Adhim with respect to RMSE in the test period, respectively. The outcomes of the study recommend random forest for estimating ET0 in a semi-arid region. The study used data from one region, and more data can be used to assess the regression-based machine learning methods in future studies. The regression-based methods considered in this study may be compared with more complex machine learning methods.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}