
RLNformer: A Rainfall Levels Nowcasting Model Based on Conv1D_Transformer for the Northern Xinjiang Area of China


Abstract
:1. Introduction
- (1)
- Innovatively, we chose data from six ground meteorological stations in the northern Xinjiang area instead of radar images as the dataset for rainfall nowcasting. The accuracy of ground meteorological station data is higher on a smaller scale, ensuring the precision of the training data.
- (2)
- The preprocessed dataset can provide a reference for future research. In this paper, comprehensive preprocessing was conducted on the raw data, with a particular focus on complex feature construction. This increased the diversity of the data, improved its quality, and ensured data consistency. The dataset can serve as a foundation for future studies on rainfall nowcasting in the same area, allowing for further analysis and research based on this groundwork.
- (2)
- The RLNformer model suitable for rainfall nowcasting was constructed. The RLNformer model overcomes the drawbacks of using RNN models for rainfall nowcasting, and its included residual structure mitigates the gradient vanishing or exploding issues present in RNN models to a certain extent. Furthermore, the RLNformer model employs Conv1D to replace the word-embedding layer of the transformer, enabling it to fully capture the complex relationships between temporal features. This allows the attention mechanism to extract the context information of the input data more effectively, enhancing predictive performance. This structure resolves the issues of the inability to process inputs in parallel and difficulties at capturing long-term contextual dependencies, which are present in RNN-based rainfall nowcasting models. Lastly, the original transformer’s normalization layer is placed before the multi-head attention, ensuring that the extracted features have an appropriate scale, which enhances the model’s stability. The prediction results of the model on two datasets indicate that transformer-based models are equally suitable for rainfall nowcasting tasks.
2. Study Area and Data Preprocessing
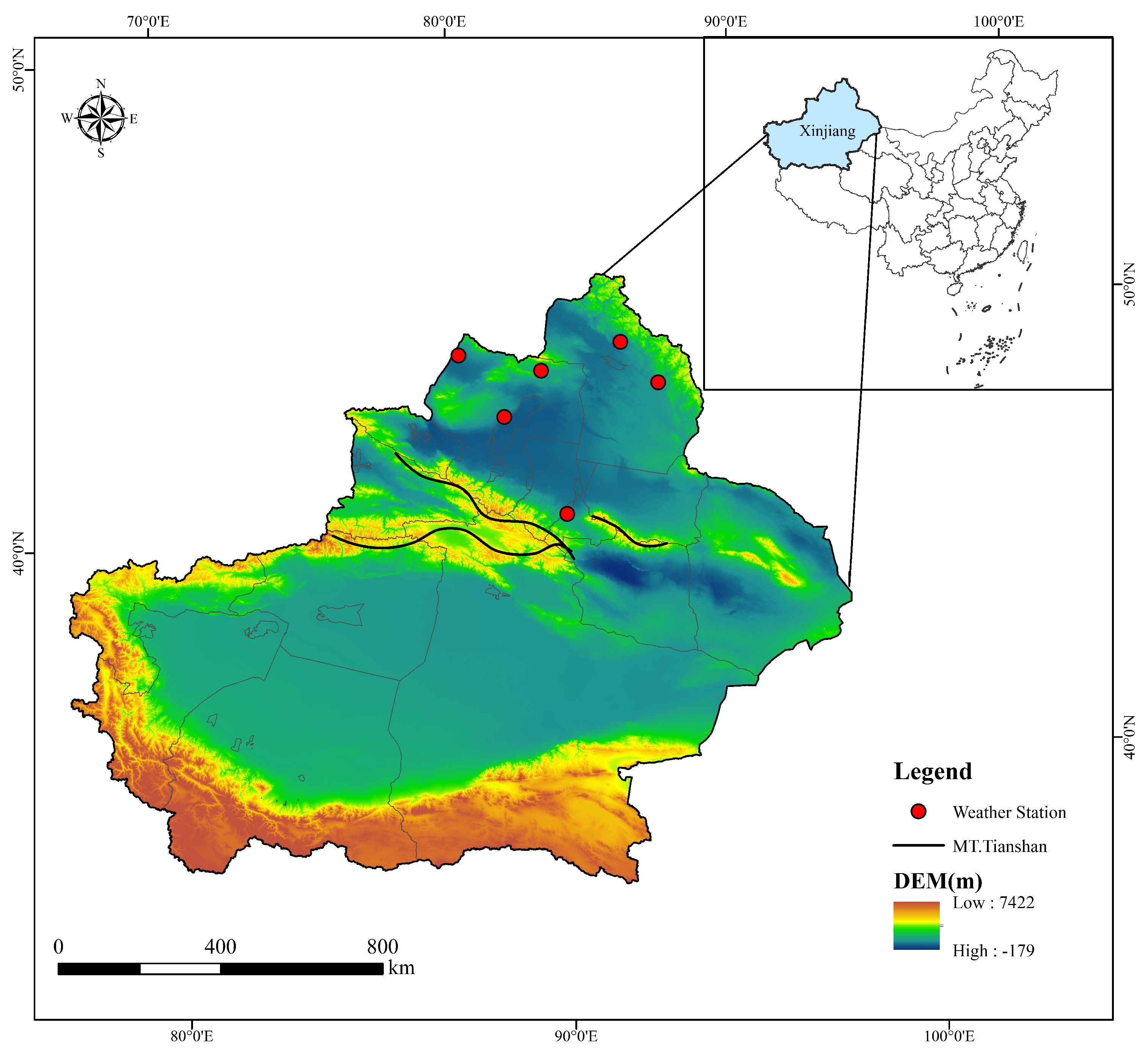
2.1. Study Area
2.2. Original Data
2.3. Data Preprocessing
2.3.1. Data Cleaning
2.3.2. Outliers and Missing Values Handling
2.3.3. Feature Construction
- Time features. Precipitation shows different trends in different time periods of the year. Time features can help researchers understand the rainfall pattern in the target area, and the model can also capture changes in precipitation over time, thereby improving prediction performance. This paper uses the date feature Date as an index and splits it into four features, namely, Year, Month, Day, and Time, which, respectively, represent the year, month, day, and hour of the record.
- STL decomposition features. Meteorological data are essentially time series data and have a certain periodicity. STL decomposition [35] can decompose time series data more precisely, that is, decompose time series data into three parts: trend, season, and residual. This can hep one to better understand and analyze the trend, periodicity, and randomness of time series data and enable better prediction and modeling. Therefore, STL decomposition is performed on features related to air temperature, air pressure, relative humidity, wind speed, and precipitation.
- Variation features. Variables such as air pressure, temperature, and humidity generally change during a period of time before rainfall occurs. Therefore, first-order variation features and second-order variation features are introduced for each meteorological feature.
- Interaction features. Precipitation is the result of the interaction of meteorological features, and the interaction between features should be taken into account, for example, the values of temperature and relative humidity are multiplied to obtain another feature.
- Difference features. Using the difference between two features as a new feature can reflect the changes between feature values, allowing the model to better capture the fluctuations in the data.
2.3.4. Data Normalization
2.3.5. Rainfall Levels Division
2.3.6. Feature Selection
3. Materials and Methods
3.1. Conv1D
3.2. Transformer
3.3. Rainfall Levels Nowcasting Model
4. Experimental Setup
4.1. Experimental Environment
4.2. Experimental Data
4.3. Experimental Process
- (1)
- Data preprocessing. The entire preprocessing process is described in Section 2.3.
- (2)
- Dataset division. The process of dividing the North Xinjiang and India public datasets is described in Section 4.2.
- (3)
- Model training and prediction. During the training phase, the loss function was set to cross-entropy loss and Adam was used as the optimizer. The maximum iteration of the model was set to 1000. The validation set was used to prevent overfitting during the training process. The model stops training when the validation loss does not decrease for 20 consecutive epochs or reaches the maximum number of iterations. The detailed hyperparameters of the model are shown in Table 5. During the prediction phase, the trained model is used to predict the test set.
- (4)
- Model evaluation. Various evaluation metrics are used to comprehensively evaluate the prediction performance of the model and increase the robustness of the model performance. The evaluation metrics used in this paper are shown in Section 5.1.
4.4. Benchmark Models for Experiment
5. Results and Discussion
5.1. Evaluation Metrics
- (1)
- Accuracywhere total represents the total number of samples.
- (2)
- PrecisionPrecision refers to the proportion of correctly predicted positive samples to all samples predicted as positive by the classifier. Precision is a statistic that focuses on the classifier’s judgment of positive class data.
- (3)
- RecallRecall refers to the proportion of correctly predicted positive samples to the actual number of positive samples. Recall is also a statistic that focuses on the actual positive class samples. In practical applications, precision and recall affect each other, and each evaluates a different aspect of the model. To be able to consider both indicators comprehensively, the score (weighted harmonic mean of precision and recall) is used to evaluate the model’s predicted results.
- (4)
- scoreFrom Equation (14), it can be seen that the score takes into account both precision and recall, making it a more comprehensive evaluation metric. The score ranges from 0 to 1, with higher values indicating better model performance.
5.2. Analysis of the Prediction Results of the RLNformer Model
5.3. Ablation Experiment
5.4. Comparison Analysis with the Benchmark Models
6. Conclusions
- (1)
- Innovatively, we chose ground meteorological station data for rainfall nowcasting. This deviates from the traditional approach of using radar images or satellite cloud images for rainfall nowcasting, ensuring the data quality for small-scale rainfall prediction.
- (2)
- We performed complex preprocessing on the raw data. Multiple features were constructed, including time features, STL decomposition features, variation features, interaction features, and difference features, to enhance the diversity of the data. Based on the rainfall characteristics in the northern Xinjiang area, we defined the prediction task as rainfall nowcasting levels prediction and divided it into corresponding rainfall levels.
- (3)
- The transformer structure was improved and named RLNformer. Replacing the word-embedding layer with a Conv1D layer effectively captures deep relationships between features, allowing the multi-head attention mechanism to better extract contextual information from time series. Placing the normalization layer before the multi-head attention mechanism and the feed-forward layer ensures that the extracted features are more standardized, thereby ensuring the stability of the model. The introduction of RLNformer not only overcomes the drawbacks of RNN models but also demonstrates the suitability of transformer-based models for rainfall nowcasting tasks.
- (4)
- The experimental results were analyzed and compared in detail. Multiple evaluation metrics were selected to assess the prediction results, and ablation experiments were conducted. The model was compared with benchmark models that are highly authoritative in the field. The experimental results indicate that the model has very high prediction accuracy for various categories of samples in the Northern Xinjiang region, surpassing all benchmark models. When the experimental conditions were kept unchanged, the model also demonstrated the best prediction performance on an Indian public dataset, indicating the good generalization ability of the proposed model.
- (1)
- In future work, we plan to apply functional data analysis to rainfall time series, visualizing features such as the trends, periodicity, and seasonality of the rainfall time series data. This will allow for a better analysis of the rainfall data and implement measures to further enhance forecasting performance.
- (2)
- The datasets used in this paper have imbalanced samples in each category; although the model structure can capture the imbalanced samples to some extent, the model’s processing ability is limited. In future work, the imbalanced sample problem can be addressed in the preprocessing process to improve the model’s prediction performance.
- (3)
- The formation process of rainfall is extremely complex, and using a single piece of meteorological data for prediction cannot allow the model to fully learn the complex patterns of rainfall. In future work, it is suggested to consider using multiple sources of meteorological data together for rainfall prediction.
- (4)
- Some of the hyperparameters in the model are manually tuned, and in future work, it is suggested to apply advanced hyperparameter optimization methods to search a wider range of hyperparameters and select better combinations of hyperparameters.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Crown, M.D. Validation of the NOAA Space Weather Prediction Center’s solar flare forecasting look-up table and forecaster-issued probabilities. Space Weather 2012, 10. [Google Scholar] [CrossRef]
- Ryu, S.; Lyu, G.; Do, Y.; Lee, G. Improved rainfall nowcasting using Burgers’ equation. J. Hydrol. 2020, 581, 124140. [Google Scholar] [CrossRef]
- Nizar, S.; Thomas, J.; Jainet, P.; Sudheer, K. A Novel Technique for Nowcasting Extreme Rainfall Events using Early Microphysical Signatures of Cloud Development. Authorea Prepr. 2022, 61, 62. [Google Scholar]
- Zhu, J.; Dai, J. A rain-type adaptive optical flow method and its application in tropical cyclone rainfall nowcasting. Front. Earth Sci. 2022, 16, 248–264. [Google Scholar] [CrossRef]
- De Luca, D.L.; Capparelli, G. Rainfall nowcasting model for early warning systems applied to a case over Central Italy. Nat. Hazards 2022, 112, 501–520. [Google Scholar] [CrossRef]
- Dwivedi, D.; Shrivastava, P. Rainfall probability distribution and forecasting monthly rainfall of Navsari using ARIMA model. Indian J. Agric. Res. 2022, 56, 47–56. [Google Scholar] [CrossRef]
- Ray, S.N.; Bose, S.; Chattopadhyay, S. A Markov chain approach to the predictability of surface temperature over the northeastern part of India. Theor. Appl. Climatol. 2021, 143, 861–868. [Google Scholar] [CrossRef]
- Islam, F.; Imteaz, M.A. A Novel Hybrid Approach for Predicting Western Australia’s Seasonal Rainfall Variability. Water Resour. Manag. 2022, 36, 3649–3672. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, Y.; Yao, W.; Yao, Y. Hourly rainfall forecasting model using supervised learning algorithm. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–9. [Google Scholar] [CrossRef]
- Song, L.; Schicker, I.; Papazek, P.; Kann, A.; Bica, B.; Wang, Y.; Chen, M. Machine Learning Approach to Summer Precipitation Nowcasting over the Eastern Alps. Meteorol. Z. 2020, 29, 289–305. [Google Scholar] [CrossRef]
- Maliyeckel, M.B.; Sai, B.C.; Naveen, J. A comparative study of lgbm-svr hybrid machine learning model for rainfall prediction. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–7. [Google Scholar]
- Diez-Sierra, J.; Del Jesus, M. Long-term rainfall prediction using atmospheric synoptic patterns in semi-arid climates with statistical and machine learning methods. J. Hydrol. 2020, 586, 124789. [Google Scholar] [CrossRef]
- Appiah-Badu, N.K.A.; Missah, Y.M.; Amekudzi, L.K.; Ussiph, N.; Frimpong, T.; Ahene, E. Rainfall prediction using machine learning algorithms for the various ecological zones of Ghana. IEEE Access 2021, 10, 5069–5082. [Google Scholar] [CrossRef]
- Pirone, D.; Cimorelli, L.; Del Giudice, G.; Pianese, D. Short-term rainfall forecasting using cumulative precipitation fields from station data: A probabilistic machine learning approach. J. Hydrol. 2023, 617, 128949. [Google Scholar] [CrossRef]
- Raval, M.; Sivashanmugam, P.; Pham, V.; Gohel, H.; Kaushik, A.; Wan, Y. Automated predictive analytics tool for rainfall forecasting. Sci. Rep. 2021, 11, 17704. [Google Scholar] [CrossRef] [PubMed]
- Adaryani, F.R.; Mousavi, S.J.; Jafari, F. Short-term rainfall forecasting using machine learning-based approaches of PSO-SVR, LSTM and CNN. J. Hydrol. 2022, 614, 128463. [Google Scholar] [CrossRef]
- Rahman, A.u.; Abbas, S.; Gollapalli, M.; Ahmed, R.; Aftab, S.; Ahmad, M.; Khan, M.A.; Mosavi, A. Rainfall prediction system using machine learning fusion for smart cities. Sensors 2022, 22, 3504. [Google Scholar] [CrossRef]
- Amini, A.; Dolatshahi, M.; Kerachian, R. Adaptive precipitation nowcasting using deep learning and ensemble modeling. J. Hydrol. 2022, 612, 128197. [Google Scholar] [CrossRef]
- Khaniani, A.S.; Motieyan, H.; Mohammadi, A. Rainfall forecasting based on GPS PWV together with meteorological parameters using neural network models. J. Atmos. Sol. Terr. Phys. 2021, 214, 105533. [Google Scholar] [CrossRef]
- Li, H.; Wang, X.; Zhang, K.; Wu, S.; Xu, Y.; Liu, Y.; Qiu, C.; Zhang, J.; Fu, E.; Li, L. A neural network-based approach for the detection of heavy precipitation using GNSS observations and surface meteorological data. J. Atmos. Sol. Terr. Phys. 2021, 225, 105763. [Google Scholar] [CrossRef]
- Bhimavarapu, U. IRF-LSTM: Enhanced regularization function in LSTM to predict the rainfall. Neural Comput. Appl. 2022, 34, 20165–20177. [Google Scholar] [CrossRef]
- Fernández, J.G.; Mehrkanoon, S. Broad-UNet: Multi-scale feature learning for nowcasting tasks. Neural Netw. 2021, 144, 419–427. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Cao, W.; Li, W. Surface and high-altitude combined rainfall forecasting using convolutional neural network. Peer Peer Netw. Appl. 2021, 14, 1765–1777. [Google Scholar] [CrossRef]
- Khan, M.I.; Maity, R. Hybrid deep learning approach for multi-step-ahead daily rainfall prediction using GCM simulations. IEEE Access 2020, 8, 52774–52784. [Google Scholar] [CrossRef]
- Zhang, C.J.; Zeng, J.; Wang, H.Y.; Ma, L.M.; Chu, H. Correction model for rainfall forecasts using the LSTM with multiple meteorological factors. Meteorol. Appl. 2020, 27, e1852. [Google Scholar] [CrossRef]
- Yan, J.; Xu, T.; Yu, Y.; Xu, H. Rainfall forecasting model based on the tabnet model. Water 2021, 13, 1272. [Google Scholar] [CrossRef]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Woo, G.; Liu, C.; Sahoo, D.; Kumar, A.; Hoi, S. Etsformer: Exponential smoothing transformers for time-series forecasting. arXiv 2022, arXiv:2202.01381. [Google Scholar]
- Wang, H.; Peng, J.; Huang, F.; Wang, J.; Chen, J.; Xiao, Y. Micn: Multi-scale local and global context modeling for long-term series forecasting. In Proceedings of the Eleventh International Conference on Learning Representations; 2022. Available online: https://openreview.net/pdf?id=zt53IDUR1U (accessed on 30 August 2023).
- Wu, H.; Hu, T.; Liu, Y.; Zhou, H.; Wang, J.; Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis. arXiv 2022, arXiv:2210.02186. [Google Scholar]
- Liu, M.; Qin, H.; Cao, R.; Deng, S. Short-Term Load Forecasting Based on Improved TCN and DenseNet. IEEE Access 2022, 10, 115945–115957. [Google Scholar] [CrossRef]
- Tang, X.; Chen, H.; Xiang, W.; Yang, J.; Zou, M. Short-term load forecasting using channel and temporal attention based temporal convolutional network. Electr. Power Syst. Res. 2022, 205, 107761. [Google Scholar] [CrossRef]
- Hua, H.; Liu, M.; Li, Y.; Deng, S.; Wang, Q. An ensemble framework for short-term load forecasting based on parallel CNN and GRU with improved ResNet. Electr. Power Syst. Res. 2023, 216, 109057. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, Y.; Li, W.; Li, F.; Xin, Q. Ecological responses to climate change and human activities in the arid and semi-arid regions of Xinjiang in China. Remote Sens. 2022, 14, 3911. [Google Scholar] [CrossRef]
- He, R.; Zhang, L.; Chew, A.W.Z. Modeling and predicting rainfall time series using seasonal-trend decomposition and machine learning. Knowl. Based Syst. 2022, 251, 109125. [Google Scholar] [CrossRef]
- Li, W.; Gao, X.; Hao, Z.; Sun, R. Using deep learning for precipitation forecasting based on spatio-temporal information: A case study. Clim. Dyn. 2022, 58, 443–457. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; McVean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed]
- Hu, K.; Guo, X.; Gong, X.; Wang, X.; Liang, J.; Li, D. Air quality prediction using spatio-temporal deep learning. Atmos. Pollut. Res. 2022, 13, 101543. [Google Scholar] [CrossRef]
- Soni, S.; Chouhan, S.S.; Rathore, S.S. TextConvoNet: A convolutional neural network based architecture for text classification. Appl. Intell. 2023, 53, 14249–14268. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 356–366. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Y.; Wu, H.; Wang, J.; Long, M. Non-stationary transformers: Exploring the stationarity in time series forecasting. Adv. Neural Inf. Process. Syst. 2022, 35, 9881–9893. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence; 2021; Volume 35, pp. 11106–11115. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/17325 (accessed on 29 August 2023).
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
- Gorishniy, Y.; Rubachev, I.; Khrulkov, V.; Babenko, A. Revisiting deep learning models for tabular data. Adv. Neural Inf. Process. Syst. 2021, 34, 18932–18943. [Google Scholar]
- Grinsztajn, L.; Oyallon, E.; Varoquaux, G. Why do tree-based models still outperform deep learning on typical tabular data? Adv. Neural Inf. Process. Syst. 2022, 35, 507–520. [Google Scholar]
- Arik, S.Ö.; Pfister, T. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 6679–6687. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are transformers effective for time series forecasting? In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37. pp. 11121–11128. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station No. | Latitude (°) | Longitude (°) | Altitude (m) |
|---|---|---|---|
| 51076 | 47.73 | 88.08 | 735.3 |
| 51087 | 46.98 | 89.52 | 807.5 |
| 51133 | 46.73 | 83.00 | 534.9 |
| 51156 | 46.78 | 85.72 | 1322.1 |
| 51243 | 45.62 | 84.85 | 450.3 |
| 51463 | 43.78 | 87.37 | 935.0 |
| Number | Feature | Description | Unit |
|---|---|---|---|
| 1 | Date | Date of record | / |
| 2 | T | Temperature 2 m above ground | ℃ |
| 3 | Po | Horizontal atmospheric pressure | mmHg |
| 4 | P | Mean sea level pressure | mmHg |
| 5 | Pa | The change of atmospheric pressure within 3 h before observation | mmHg |
| 6 | U | Relative humidity at 2 m above the ground | % |
| 7 | DD | The wind direction 10–12 m above the ground within 10 min before observation | / |
| 8 | Ff | The wind speed 10–12 m above the ground within 10 min before observation | m/s |
| 9 | ff10 | The maximum gust 10–12 m above the ground within 10 min before observation | m/s |
| 10 | N | The maximum gust 10–12 m above the ground between the two observations | m/s |
| 11 | N | Total cloud cover | / |
| 12 | Tn | Minimum air temperature | ℃ |
| 13 | Tx | Maximum air temperature | ℃ |
| 14 | H | The height of the lowest cloud | m |
| 15 | VV | Horizontal visibility | km |
| 16 | Td | Dew point temperature at 2 m above ground | ℃ |
| 17 | RRR | Precipitation within 3 h | mm |
| 18 | Tg | The lowest temperature of soil surface at night | ℃ |
| Rainfall Level | No Rain | Light Rain | Moderate Rain | Heavy Rain and Above |
|---|---|---|---|---|
| Precipitation amount in 3 h (mm) | 0 | (0, 5] | (5, 10] | (10, ) |
| Dataset | Time Range | Training Set Size | Validation Set Size | Testing Set Size |
|---|---|---|---|---|
| Northern Xinjiang | 1 April 2020–31 July 2023 | [29,127, 8, 80] | [3638, 8, 80] | [3646, 8, 80] |
| India | 1 June 2016–30 November 2019 | [36,888, 8, 80] | [4608, 8, 80] | [4616, 8, 80] |
| Hyperparameters | Value |
|---|---|
| Loss function | Cross entropy loss function |
| Optimizer | Adam |
| Maximum number of training | 1000 |
| The patience of the early stopping mechanism | 20 |
| Batch size | 64 |
| Learning rate | 0.001 |
| Number of heads for multi-head attention | 4 |
| The number of encoder layers | 4 |
| Benchmark Model | Structure of Input Data | Hyperparameter Settings |
|---|---|---|
| MLP | [N, C] | seq_len = 1, learning_rate = 0.001 |
| ResNet | [N, L, C] | seq_len = 8, learning_rate = 0.001 |
| XGBoost | [N, C] | n_estimators = 1000, learning_rate = 0.3 |
| Random Forest | [N, C] | n_estimators = 1000 |
| TabNet | [N, C] | n_steps = 5, optimizer_params = dict(lr = 0.1) |
| Autoformer | [N, L, C] | seq_len = 8, learning_rate = 0.001 |
| DLinear | [N, L, C] | seq_len = 8, learning_rate = 0.001 |
| Predicted Value | |||||
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | ||
| True value | 0 | ||||
| 1 | |||||
| 2 | |||||
| 3 | |||||
| Dataset | Rainfall Level | No Conv1D | Change Position of Norm Layer | RLNformer (Ours) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F | Precision | Recall | F | Precision | Recall | F | ||||
| Northern Xinjiang | 0 | 0.898 | 1.000 | 0.947 | 0.964 | 0.993 | 0.978 | 0.970 | 0.992 | 0.981 | ||
| 1 | 0.000 | 0.000 | 0.000 | 0.906 | 0.656 | 0.761 | 0.897 | 0.716 | 0.796 | |||
| 2 | 0.000 | 0.000 | 0.000 | 0.818 | 0.643 | 0.720 | 0.846 | 0.786 | 0.815 | |||
| 3 | 0.000 | 0.000 | 0.000 | 0.500 | 0.750 | 0.600 | 1.000 | 0.750 | 0.857 | |||
| India | 0 | 0.656 | 1.000 | 0.792 | 0.925 | 0.955 | 0.940 | 0.937 | 0.943 | 0.940 | ||
| 1 | 0.000 | 0.000 | 0.000 | 0.833 | 0.796 | 0.814 | 0.812 | 0.846 | 0.829 | |||
| 2 | 0.000 | 0.000 | 0.000 | 0.451 | 0.433 | 0.442 | 0.553 | 0.347 | 0.426 | |||
| 3 | 0.000 | 0.000 | 0.000 | 1.000 | 0.032 | 0.063 | 0.909 | 0.323 | 0.476 | |||
| Model | Index | Northern Xinjiang | India | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | |||
| MLP | Precision | 0.976 | 0.808 | 0.750 | 0.750 | 0.930 | 0.767 | 0.000 | 0.667 | |
| Recall | 0.981 | 0.776 | 0.643 | 0.750 | 0.934 | 0.857 | 0.000 | 0.171 | ||
| 0.979 | 0.791 | 0.692 | 0.750 | 0.932 | 0.809 | 0.000 | 0.000 | |||
| ResNet | Precision | 0.968 | 0.859 | 0.333 | 0.333 | 0.940 | 0.768 | 0.333 | 0.222 | |
| Recall | 0.989 | 0.676 | 0.286 | 0.750 | 0.934 | 0.872 | 0.007 | 0.061 | ||
| 0.979 | 0.757 | 0.308 | 0.462 | 0.937 | 0.817 | 0.013 | 0.095 | |||
| XGBoost | Precision | 0.972 | 0.834 | 0.600 | 0.750 | 0.917 | 0.792 | 0.472 | 0.000 | |
| Recall | 0.985 | 0.727 | 0.643 | 0.750 | 0.944 | 0.809 | 0.214 | 0.000 | ||
| 0.979 | 0.777 | 0.621 | 0.750 | 0.930 | 0.801 | 0.294 | 0.000 | |||
| Random Forest | Precision | 0.976 | 0.810 | 0.750 | 0.750 | 0.928 | 0.792 | 0.546 | 0.000 | |
| Recall | 0.981 | 0.776 | 0.643 | 0.750 | 0.942 | 0.836 | 0.226 | 0.000 | ||
| 0.979 | 0.793 | 0.692 | 0.750 | 0.935 | 0.813 | 0.320 | 0.000 | |||
| TabNet | Precision | 0.977 | 0.751 | 0.000 | 0.000 | 0.866 | 0.791 | 0.000 | 0.000 | |
| Recall | 0.977 | 0.790 | 0.000 | 0.000 | 0.949 | 0.740 | 0.000 | 0.000 | ||
| 0.977 | 0.770 | 0.000 | 0.000 | 0.906 | 0.764 | 0.000 | 0.000 | |||
| Autoformer | Precision | 0.969 | 0.832 | 0.500 | 0.750 | 0.822 | 0.714 | 0.64 | 0.000 | |
| Recall | 0.986 | 0.688 | 0.571 | 0.750 | 0.919 | 0.588 | 0.271 | 0.000 | ||
| 0.977 | 0.753 | 0.533 | 0.750 | 0.868 | 0.640 | 0.349 | 0.000 | |||
| DLinear | Precision | 0.974 | 0.831 | 0.818 | 0.750 | 0.918 | 0.784 | 0.537 | 1.000 | |
| Recall | 0.984 | 0.753 | 0.643 | 0.750 | 0.941 | 0.821 | 0.142 | 0.030 | ||
| 0.979 | 0.790 | 0.720 | 0.750 | 0.929 | 0.802 | 0.225 | 0.059 | |||
| RLNformer (Ours) | Precision | 0.970 | 0.897 | 0.846 | 1.000 | 0.937 | 0.812 | 0.553 | 0.909 | |
| Recall | 0.992 | 0.716 | 0.786 | 0.750 | 0.943 | 0.846 | 0.347 | 0.323 | ||
| 0.981 | 0.796 | 0.815 | 0.857 | 0.940 | 0.829 | 0.426 | 0.476 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Liu, S.; Chen, J. RLNformer: A Rainfall Levels Nowcasting Model Based on Conv1D_Transformer for the Northern Xinjiang Area of China. Water 2023, 15, 3650. https://doi.org/10.3390/w15203650
Liu Y, Liu S, Chen J. RLNformer: A Rainfall Levels Nowcasting Model Based on Conv1D_Transformer for the Northern Xinjiang Area of China. Water. 2023; 15(20):3650. https://doi.org/10.3390/w15203650
Chicago/Turabian StyleLiu, Yulong, Shuxian Liu, and Juepu Chen. 2023. "RLNformer: A Rainfall Levels Nowcasting Model Based on Conv1D_Transformer for the Northern Xinjiang Area of China" Water 15, no. 20: 3650. https://doi.org/10.3390/w15203650
APA StyleLiu, Y., Liu, S., & Chen, J. (2023). RLNformer: A Rainfall Levels Nowcasting Model Based on Conv1D_Transformer for the Northern Xinjiang Area of China. Water, 15(20), 3650. https://doi.org/10.3390/w15203650