1. Introduction
Accurate and timely precipitation forecasting is of great significance for daily life and production planning, providing early warnings for flood and drought disasters, fllod and drought prevention and control management, etc. However, rainfall is the result of the interaction of multi-scale atmospheric systems and is affected by various environmental factors such as heat, flow fields, and topography [
1]. Therefore, precipitation nowcasting is extremely challenging. Although the northern Xinjiang area of China, located in arid and semi-arid areas, experiences scarce rainfall, it has been subject to frequent extreme rainfall events due to factors such as global warming. As a result, people’s lives and property are under certain threats. Therefore, accurate and timely rainfall prediction in this region is crucial for human life and production activities.
Rainfall forecasting can be divided into nowcasting, short-term forecasting, and medium and long-term forecasting, according to the length of the forecast time. Due to long-term development, the forecasting capabilities of medium and long-term forecasting have been significantly improved, but the development of nowcasting and short-term forecasting is obviously insufficient and has major shortcomings. In addition, with the development of the economy, precipitation nowcasting has fallen into line more with people’s needs. In order to further improve the accuracy and stability of precipitation prediction, various methods have been proposed. At present, precipitation prediction methods are mainly divided into data extrapolation methods, traditional statistical methods, machine learning methods, and deep learning methods. Data extrapolation techniques primarily utilize satellite cloud images and meteorological radar detection data to conduct rainfall forecasting. Ryu et al. [
2] obtained an initial vector field through a variational echo tracking algorithm and then updated the vector field by solving the Burgers equation. Nizar et al. [
3] extracted feature values from the relationship graphs generated from the cloud top temperatures and effective radii of cloud particles obtained from satellite images at different times and used logistic regression to find the probability relationship between these feature values and extreme rainfall events in measured rainfall, enabling the prediction of extreme rainfall events more than 6 hours in advance. Zhu et al. [
4] proposed a rain-type adaptive pyramid Kanade–Lucas-Tomasi (A-PKLT) optical flow method for radar echo extrapolation, which divides the rainfall into six types, addressing the difficulty of the PKLT optical flow algorithm in calculating motion vectors in mixed-type rainfall. Methods based on data extrapolation have advantages such as low computational load, fast calculation speed, and the ability to meet real-time forecasting needs, but they do not consider the nonlinear processes of large-scale aerodynamics and thermodynamics, making it difficult to describe complex rainfall processes. For statistical models, traditional time series methods have been widely used and studied, including autoregressive (AR), moving average (MA), and autoregressive integrated moving average (ARIMA). De Luca et al. [
5] proposed a hybrid model PRAISE-MET based on stochastic models and numerical weather prediction models, characterized by its advantage in improving rainfall forecasting at the basin scale. D.K. Dwivedi et al. [
6] used the method of moments to obtain the probability distribution of monthly rainfall and used the ARIMA model to predict rainfall, which had a minimum root mean square value, and found that the residuals were not relevant. Ray et al. [
7] proposed a surface temperature prediction framework using the two-state Markov chain method and the autoregressive method and found that there is a strong correlation between surface temperature and rainfall. Islam et al. [
8] used a new hybrid GEP-ARIMAX model to predict rainfall at 12 rainfall stations in Western Australia. Compared with traditional linear and nonlinear models, this model has good rainfall forecasting capabilities. The above studies are based on historical rainfall series prediction, which has the advantages of small calculation amount, simple linear prediction, and high accuracy. However, under strong convective weather conditions, short-term rainfall changes rapidly, and traditional statistical methods have limited accuracy in precipitation nowcasting.
With the development of computer technology, machine learning methods have become an excellent prediction tool, bringing unprecedented opportunities to advance predictions, and can be used for precipitation forecasting. Zhao et al. [
9] proposed an hourly rainfall forecasting model (HRF) based on a supervised learning algorithm, compared it with similar work in previous studies, and found that the proposed HRF model has impressive performance in terms of temporal resolution and prediction accuracy. Song et al. [
10] proposed a new machine-learning-based model for summer hourly precipitation forecasting in the Eastern Alps, demonstrating that machine learning methods are a promising approach for precipitation forecasting. Maliyeckel et al. [
11] used the LightGBM and SVM integrated model to make predictions using the preprocessed dataset. Compared with a single model, the root mean square error of the hybrid model was the smallest and the rainfall prediction results were more accurate. Diez-Sierra et al. [
12] evaluated the performance of eight statistical and machine learning methods for long-term daily rainfall prediction in a semi-arid climate region and found that the performance of most machine learning models is very sensitive to hyperparameters and the performance of neural networks is optimal. Appiah-Badu et al. [
13] used multiple machine learning methods to predict rainfall in different ecological zones in Ghana and found that random forest, extreme gradient boosting, and multi-layer perceptron performed well, while K-NN performed the worst. Pirone et al. [
14] conducted probabilistic rainfall nowcasting for 19 meteorological stations in southern Italy, ranging from 30 min to 6 h in 10-min intervals. They found that the use of temporal and spatial information allowed the model to predict short-term rainfall amounts using only current measurements as input. Raval et al. [
15] developed an optimized neural network for comparison with machine learning methods and found that both traditional machine learning models and neural network-based machine learning models can accurately predict rainfall. Adaryani et al. [
16] improved the performance of rainfall prediction methods based on PSO-SVR and LSTM by 3–15% and 2–10%, respectively. Rahman et al. [
17] proposed a new smart city real-time rainfall prediction system using machine learning fusion technology, making the prediction results better than other models. Although the machine learning model can effectively fit the implicit nonlinear relationship between historical data and external factors, there are still some shortcomings, such as local optimum, dependence on manual parameter adjustment, and being prone to over-fitting.
In recent years, deep learning has demonstrated extraordinary capabilities and huge potential in many different fields, making breakthroughs in the fields of computer vision, speech recognition, and natural language processing. New technological innovation brings both challenges and opportunities to the development of weather forecasting technology. Deep learning provides new methods for meteorological problems that are difficult to solve based on shallow neural networks. Amini et al. [
18] developed several deep neural networks (DNNs) for rainfall nowcasting with a lead time of 5 min. They integrated the predictions from these DNNs with the forecasts from some numerical weather prediction models using three ensemble methods, thereby enhancing the prediction accuracy. Khaniani et al. [
19] used MLP and nonlinear autoregressive (NARX) with exogenous inputs to predict precipitation in Tehran, respectively, and the NARX model showed better performance than MLP in both non-rainfall and rainfall event prediction. Li et al. [
20] developed a neural network method with seven meteorological variables as input data based on the backpropagation (BP) algorithm to detect heavy precipitation, which was superior to existing models. Bhimavarapu et al. [
21] proposed an enhanced regularization function to predict rainfall to reduce bias, and the performance of the proposed IRF-LSTM surpassed the state-of-the-art methods. Fernández et al. [
22] proposed a novel architecture, Broad-Unet, based on the core UNet model. This model learns more complex patterns by combining multi-scale features. Compared to the core UNet model, it not only has fewer parameters but also boasts higher prediction accuracy. Zhang et al. [
23] proposed a combined surface and upper-altitude rainfall forecasting model (ACRF) and tested it on 92 weather stations in China and found that ACRF outperformed existing methods in terms of threat score and MSE. Khan et al. [
24] confirmed that the Conv1D-MLP hybrid model is more effective at capturing the complex relationship between causal variables and daily variation in rainfall. Zhang et al. [
25] used the K-means clustering method to divide the samples into four types, and each type was modeled by LSTM separately, which reduced the root mean square error by 0.65 and improved the threat scores of light rain and heavy rain. Yan et al. [
26] proposed a rainfall forecasting model based on TabNet, using 5-year meteorological data from 26 stations in the Beijing–Tianjin–Hebei region to verify that the proposed rainfall forecasting model has good forecasting performance. Due to differences in region and climate, although the above research has achieved relatively ideal results, it is not necessarily applicable to the research tasks of this paper. Since meteorological data comprise a collection of data arranged in chronological order, they can be regarded as time series data. Time series data are characterized by time dependence. Numerous time series models [
27,
28,
29,
30] based on deep learning have been developed for time series prediction. The characteristic of these time series models is that they can capture the long-term dependence of the sequence and improve prediction performance. Time series models have been widely used in fields such as short-term load forecasting [
31,
32,
33], but their applications in the meteorological field are relatively rare.
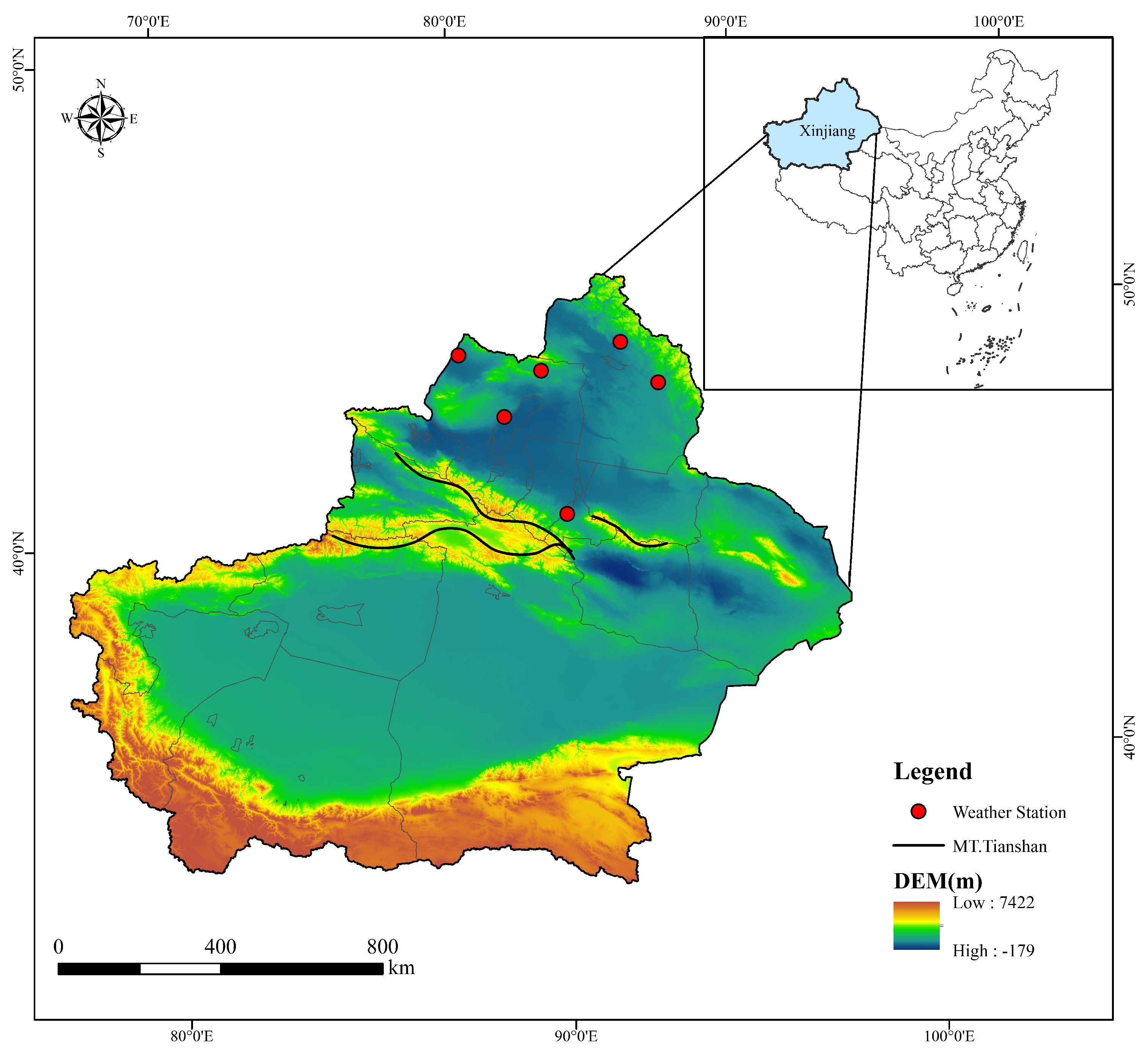
Currently, data used for rainfall nowcasting primarily consist of satellite cloud images and radar images due to their advantages of wide coverage, real-time updates, and high spatio-temporal resolution. However, when compared to data from ground meteorological stations, they have limitations such as accuracy being affected by terrain, significant estimation errors, and inability to capture small-scale precipitation variations. Moreover, deep learning models currently used for rainfall nowcasting predominantly involve recurrent neural networks (RNN) and their variants, as well as hybrid models combining convolutional neural networks (CNN) and RNN. Nevertheless, RNNs have drawbacks like susceptibility to gradient vanishing or exploding; inability to parallelize computations, leading to lower operational efficiency; and challenges at capturing long-term contextual relationships. While the transformer and its variants have effectively addressed the limitations of RNNs, they have mainly been used to solve long-term dependency issues and have not been widely adopted in the domain of rainfall nowcasting. Therefore, inspired by the limitations of satellite cloud images and radar images, as well as the extensive application of the transformer in various domains, this paper selects six meteorological stations in the northern Xinjiang area as the study area. We integrate CNN and the transformer to construct a rainfall nowcasting model based on Conv1D_Transformer, named RLNformer.
The contributions of this study are as follows:
- (1)
Innovatively, we chose data from six ground meteorological stations in the northern Xinjiang area instead of radar images as the dataset for rainfall nowcasting. The accuracy of ground meteorological station data is higher on a smaller scale, ensuring the precision of the training data.
- (2)
The preprocessed dataset can provide a reference for future research. In this paper, comprehensive preprocessing was conducted on the raw data, with a particular focus on complex feature construction. This increased the diversity of the data, improved its quality, and ensured data consistency. The dataset can serve as a foundation for future studies on rainfall nowcasting in the same area, allowing for further analysis and research based on this groundwork.
- (2)
The RLNformer model suitable for rainfall nowcasting was constructed. The RLNformer model overcomes the drawbacks of using RNN models for rainfall nowcasting, and its included residual structure mitigates the gradient vanishing or exploding issues present in RNN models to a certain extent. Furthermore, the RLNformer model employs Conv1D to replace the word-embedding layer of the transformer, enabling it to fully capture the complex relationships between temporal features. This allows the attention mechanism to extract the context information of the input data more effectively, enhancing predictive performance. This structure resolves the issues of the inability to process inputs in parallel and difficulties at capturing long-term contextual dependencies, which are present in RNN-based rainfall nowcasting models. Lastly, the original transformer’s normalization layer is placed before the multi-head attention, ensuring that the extracted features have an appropriate scale, which enhances the model’s stability. The prediction results of the model on two datasets indicate that transformer-based models are equally suitable for rainfall nowcasting tasks.
5. Results and Discussion
5.1. Evaluation Metrics
This study is a four-class classification problem, and the dataset has imbalanced samples in each class. Therefore, considering the characteristics of the prediction task and dataset, four metrics were selected to evaluate the performance of the model, all of which were calculated based on the confusion matrix. The multi-class confusion matrix is shown in
Table 7.
In a multi-class confusion matrix, represents the number of correctly predicted samples and represents the number of incorrectly predicted samples, where j is the predicted class label and i is the actual class label, .
- (1)
Accuracy
where total represents the total number of samples.
- (2)
Precision refers to the proportion of correctly predicted positive samples to all samples predicted as positive by the classifier. Precision is a statistic that focuses on the classifier’s judgment of positive class data.
- (3)
Recall refers to the proportion of correctly predicted positive samples to the actual number of positive samples. Recall is also a statistic that focuses on the actual positive class samples. In practical applications, precision and recall affect each other, and each evaluates a different aspect of the model. To be able to consider both indicators comprehensively, the score (weighted harmonic mean of precision and recall) is used to evaluate the model’s predicted results.
- (4)
From Equation (
14), it can be seen that the
score takes into account both precision and recall, making it a more comprehensive evaluation metric. The
score ranges from 0 to 1, with higher values indicating better model performance.
5.2. Analysis of the Prediction Results of the RLNformer Model
After training the RLNformer model using two different datasets, the respective test sets were predicted, and the resulting confusion matrices are shown in
Figure 7 and
Figure 8.
From
Figure 7, it can be seen that the RLNformer model accurately predicted most of the samples in the Northern Xinjiang dataset. Even in the case of imbalanced sample sizes in each class, the model was able to learn the complex relationships between minority class samples and labels, improving the prediction performance for minority classes without sacrificing the accuracy of majority class predictions. The prediction results on the Northern Xinjiang dataset demonstrate that the proposed RLNformer model has excellent prediction performance.
The results in
Figure 8 indicate that the predictive results of the RLNformer model proposed in this paper for the “no rain” and “light rain” categories in the Indian public dataset are relatively ideal, while the number of incorrectly predicted samples for the “moderate rain” and ”heavy rain and above” categories is greater than the number of correctly predicted samples. This is because the rainfall pattern in India is more complex than that in northern Xinjiang.
Although the model’s predictive performance on the Indian dataset is lower than that on the northern Xinjiang dataset, it still has a certain accuracy in predicting minority classes, which proves that the RLNformer model structure has the ability to capture complex relationships between features, indicating that it has certain generalization and robustness capabilities.
5.3. Ablation Experiment
The RLNformer replaces the word-embedding layer of the original transformer with a Conv1D layer and places the normalization layer before the multi-head attention and feed-forward layers. The ablation experiments were conducted by replacing the Conv1D layer in the model with the word-embedding layer and placing the normalization layer after the multi-head attention and feed-forward layers, and the performance of the model was observed. The results of the RLNformer model and the ablation experiment are shown in
Table 8.
From the ablation experiment results, it can be found that after replacing the word-embedding layer with the Conv1D layer, the model shows the same trend when predicting both datasets, that is, it can only predict the “no rain” category and cannot predict the rainfall of other categories. This is because the word-embedding layer cannot extract the interaction information between features of the time series data, and the extracted irrelevant information is fed into the multi-head attention mechanism, which also fails to capture the contextual information of the time series data, resulting in the model’s inability to predict samples of other categories. After changing the position of the normalization layer, the model’s predictions for both datasets become unstable. In the prediction of the Northern Xinjiang dataset, the values of the evaluation metrics for the “no rain” and “light rain” categories are similar to the predictions of the proposed model in this paper, while the predictive performance for the “moderate rain” and “heavy rain and above” categories is noticeably lower than that of the RLNformer model proposed in this paper. In the prediction of the Indian public dataset, although the recall rate and score for the “moderate rain” category are better than those of the RLNformer model, the predictive performance for the other three categories, especially the “heavy rain and above” category, is not as good as the RLNformer model. The reason for this result is that changing the position of the normalization layer makes the model unstable, leading to a decrease in the overall predictive performance of the model.
From the ablation experiment results, it can be concluded that the Conv1D layer plays a crucial role in extracting the feature relationships of the time series data, while the normalization layer makes the extracted feature matrix more normalized, improving the stability of the model. Both are indispensable, and their combined effect significantly enhances the predictive performance of the model for samples of different categories.
5.4. Comparison Analysis with the Benchmark Models
The benchmark models were trained using the Northern Xinjiang and India datasets, respectively, in
Section 4.4 and compared with the proposed model in this paper. The accuracy and training time of each model on the two datasets are shown in
Figure 9 and
Figure 10, respectively.
From
Figure 9, it can be seen that on the Northern Xinjiang dataset, the accuracy of the benchmark models is similar to that of the RLNformer model, with all exceeding 0.95, while there is a significant difference in training time consumption among the models. From
Figure 10, it can be seen that on the India dataset, except for the TabNet and Autoformer models, which have an accuracy lower than 0.8, the accuracy of the other baseline models is similar to that of the RLNformer model, above 0.87, while there is a significant difference in training time consumption among the models. Overall, the accuracy and training time indicators of the models show the same trend on both datasets. In terms of accuracy, compared to all baseline models, the RLNformer model has the highest accuracy on both datasets, with values of 0.964 and 0.890, respectively. In terms of training time consumption, the two tree models have the shortest training time on both datasets, followed by the Autoformer and DLinear models, while the RLNformer model’s training time consumption is at a moderate level.
If the prediction performance of the model is measured only from the two indicators of accuracy and time consumption, then the advantages of the two tree models are very obvious. However, accuracy cannot fully reflect the performance of the model in the case of class imbalance. In the case of sample class imbalance, if the number of samples in one class is much larger than that in other classes, the model may tend to classify most of the samples into that class, resulting in high accuracy. But this does not mean that the model has good predictive performance on other classes, and it may even be unable to make accurate predictions for minority classes. Therefore, further comparison of the precision, recall, and
score of each model is needed to comprehensively evaluate the predictive performance of each model on each class. The average evaluation indicators of each benchmark model and the RLNformer model on each class on the two datasets are shown in
Figure 11 and
Figure 12, and detailed results can be found in
Table 9.
The results in
Figure 11 and
Figure 12 show that the RLNformer model has the highest average precision, recall, and
score on the Northern Xinjiang dataset compared to the other benchmark models. Although its average precision on the Indian public dataset is slightly lower than the DLinear model, considering the overall evaluation metrics and training time consumption, its predictive performance is superior to other benchmark models. In contrast, the TabNet model exhibits the worst predictive performance on both datasets, while the MLP, XGBoost, Random Forest, and DLinear models show certain advantages in predicting both datasets.
From
Table 9, it is clear to see the prediction performance of each model on each class of samples in the two datasets, and the bold and italicized values represent the optimal values for each corresponding metric of the class. From the results, it can be seen that the optimal values for both datasets are concentrated on the RLNformer model. The RLNformer model demonstrates the best predictive performance on both datasets. For the Northern Xinjiang dataset, the TabNet model has an accuracy of 0 for predicting categories of “moderate rain” and “heavy rain and above”, which is the worst in terms of predictive performance. The precision and recall of ResNet for predicting the “moderate rain” are both low, indicating that the model predicts a large number of samples from other categories as “moderate rain” and also predicts “moderate rain” samples as other categories. Although the other models have a certain level of accuracy in predicting minority categories, their performance is not as good as the RLNformer model. For the Indian public dataset, the MLP model is unable to predict the “moderate rain” category. The XGBoost, random forest, and Autoformer models are unable to predict the “heavy rain and above” category, and the TabNet model is unable to predict two minority categories. Although the DLinear model achieves a precision of 1 for predicting the “heavy rain and above” category, the recall for this category is very low, only 0.03. The precision and recall of ResNet for predicting the two minority categories are both low, and the predictions for the minority categories are almost ineffective.
The experimental results show that the RLNformer model is able to extract complex relationships between features and learn contextual information of time series through multi-head attention mechanism, making it very suitable for time series classification problems. Its predictive performance on the two datasets surpasses the tree, MLP, ResNet, and transformer-based time series models, which are considered as benchmarks in this field, providing an excellent solution for rainfall prediction research in northern Xinjiang area.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}