
A Stacking Ensemble Model of Various Machine Learning Models for Daily Runoff Forecasting

 ,
, 
Abstract
:1. Introduction
2. Methodology
2.1. Machine Learning Methods
2.1.1. Random Forest (RF)
2.1.2. Adaptive Boosting
2.1.3. Extreme Gradient Boosting (XGB)
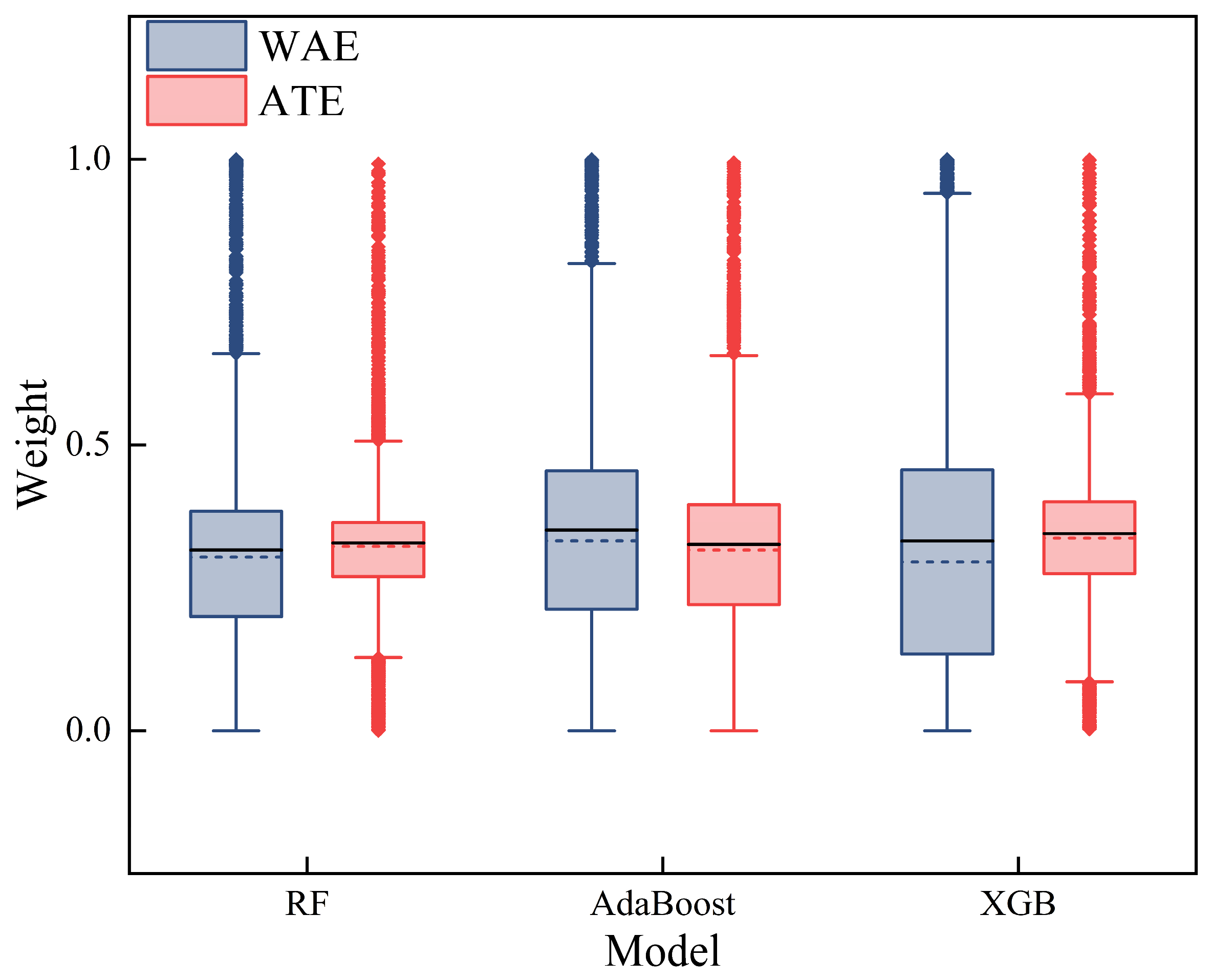
2.2. Proposed Stacking Ensemble Learning
| Algorithm 1 The iterative training process of the ATE model |
| Input: Training set D, Validation set D’, Attention-Based Stacking model. |
| Base models: Random Forest (RF), Adaptive Boosting (AdaBoost), Extreme Gradient Boosting (XGB) |
| Evaluation criteria: Nash–Sutcliffe Efficiency (NSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Pearson Correlation Coefficient (r) |
| 1: Initialize empty arrays F1 for predictions of base models on D’. |
| 2: Initialize empty array P for actual values in D’. |
| 3: For i = 1 to k do: |
| a. Split D into D_train and D_val for training and validation, respectively, using k-fold cross-validation. |
| b. Train base models on D_train. |
| c. For each instance j in D_val do: |
| i. Generate predictions pi1, pi2, pi3 using RF, AdaBoost, XGB, respectively. |
| ii. Append pi1, pi2, pi3 to F1 for instance j. |
| iii. Append actual value yj to P. |
| 4: Train Attention-Based Stacking model on F1 as input and P as target. |
| 5: Initialize empty arrays F2 and P2 for predictions of base models on D’ and actual values in D’, respectively. |
| 6: For each instance i in D’, perform: |
| a. Generate predictions pi1, pi2, pi3 using RF, AdaBoost, XGB, respectively. |
| b. Append pi1, pi2, pi3 to F2 for instance i. |
| c. Append actual value yi to P2. |
| 7: Generate predictions p using F2 and Attention-Based Stacking model. |
| 8: Calculate evaluation criteria NSE, RMSE, MAE, and r using p and P2. |
| 9: Repeat steps 3–8 for k-fold cross-validation and report average evaluation criteria. |
| 10: Train final Attention-Based Stacking model on D using all instances. |
| 11: Save the final model for future use. |
2.3. Hyper-Parameter Optimization
- Step 1:
- Define the objective function. Define an objective function with the hyper-parameters as inputs and the MSE as the model performance evaluation metric, and use k-fold cross-validation to calculate the generalization error for each set of hyper-parameters over k models, and apply its average as the output.
- Step 2:
- Define the hyper-parameter space. A preliminary determination of the search space of hyper-parameters was determined based on practical experiences of previous research.
- Step 3:
- Define the hyper-parameter optimization algorithm. The tree-structured Parzen estimator algorithm was chosen to search the hyper-parameter space.
- Step 4:
- Run hyper-parameter optimization. The ”fmin” function was chosen to run the hyper-parameter optimization and set the maximum number of iterations to 1000 to finally obtain the optimal hyper-parameters for the model.
2.4. Model Performance Evaluation
2.5. Significance Test for Model Performance Evaluation
- Step 1:
- The prediction results of N models on k folds are calculated. The prediction results in this study are assessed using the evaluation criteria of NSE, RMSE, MSE, and r.
- Step 2:
- For each fold, the tested models are ranked and given sequential values based on the merit of model performance of the prediction results.
- Step 3:
- Find the average (Ri) of N models ranked on all folds.
- Step 4:
- The Friedman test was used for comparison. The nonparametric Friedman statistic τχ2 is expressed as follows:
3. Case Study
3.1. Study Area
3.2. Data Sources
3.3. Data Preprocessing
4. Results
4.1. Comparison of Base Models
4.2. Comparison of Base Models and Ensemble Models
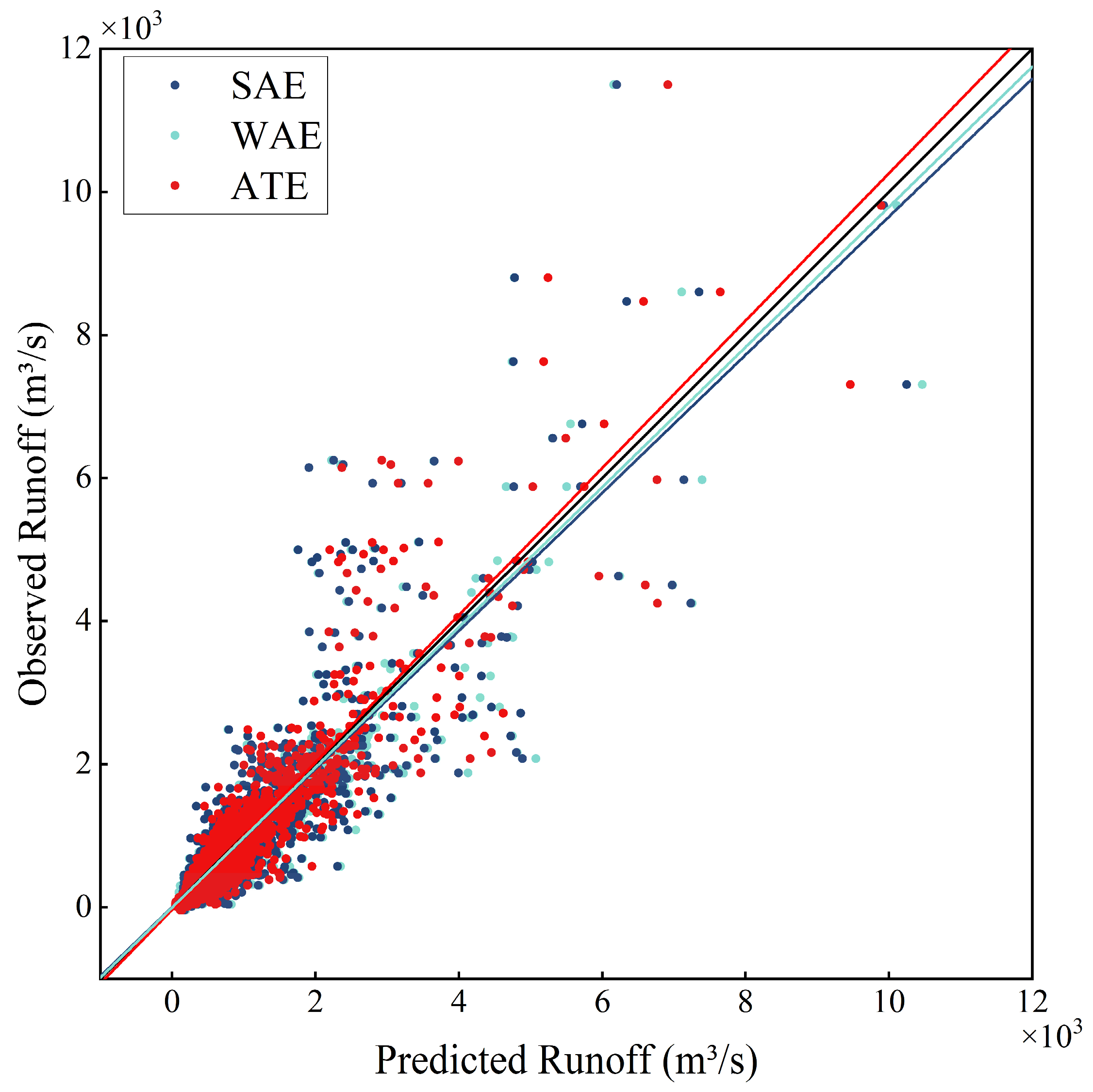
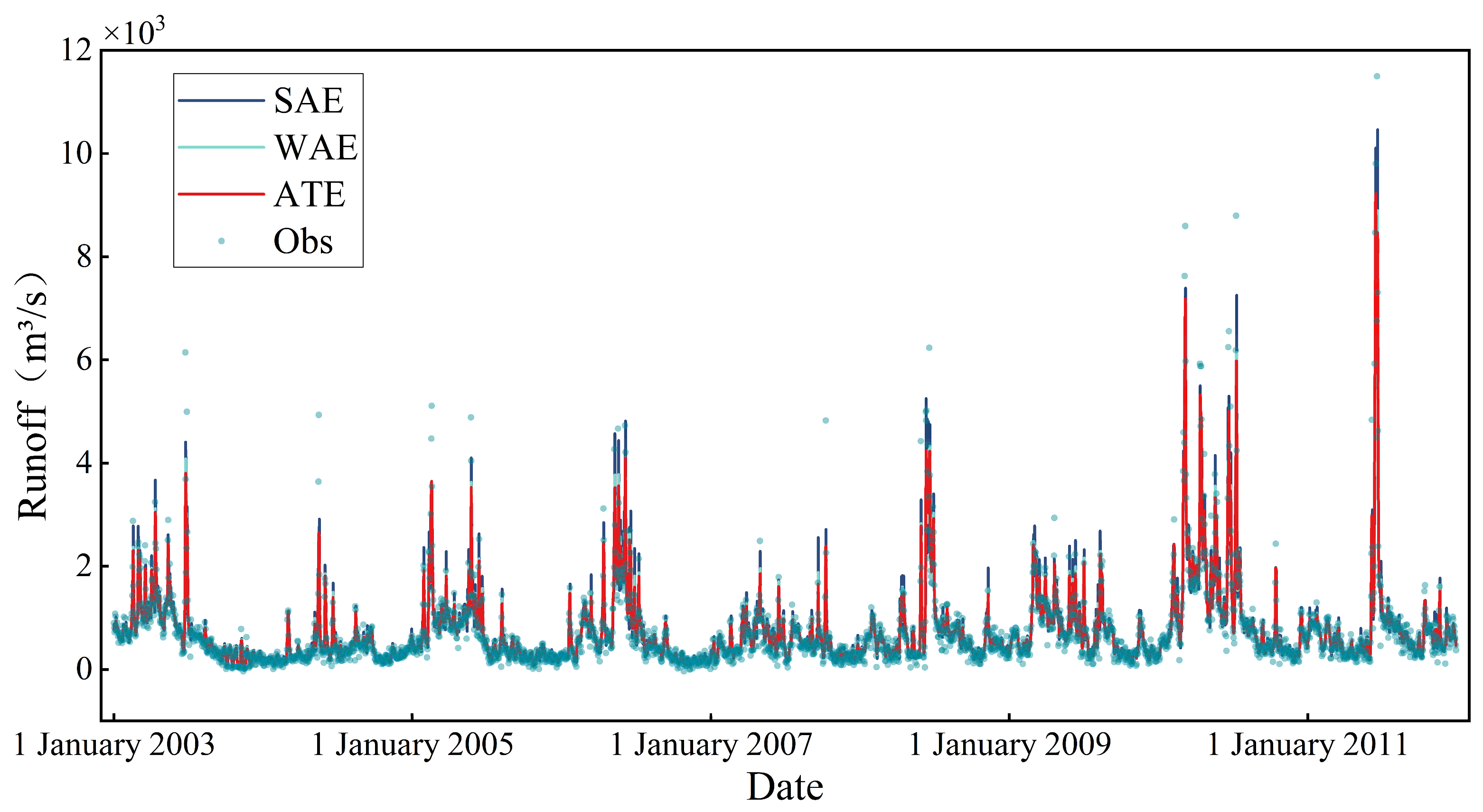
4.3. Comparison of Ensemble Models
4.4. Comparison of Model Performance in Significance Tests
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kratzert, F.; Klotz, D.; Herrnegger, M.; Sampson, A.K.; Hochreiter, S.; Nearing, G.S. Toward Improved Predictions in Ungauged Basins: Exploiting the Power of Machine Learning. Water Resour. Res. 2019, 55, 11344–11354. [Google Scholar] [CrossRef] [Green Version]
- Alfieri, L.; Burek, P.; Dutra, E.; Krzeminski, B.; Muraro, D.; Thielen, J.; Pappenberger, F. GloFAS—Global Ensemble Streamflow Forecasting and Flood Early Warning. Hydrol. Earth Syst. Sci. 2013, 17, 1161–1175. [Google Scholar] [CrossRef] [Green Version]
- Qin, P.; Xu, H.; Liu, M.; Du, L.; Xiao, C.; Liu, L.; Tarroja, B. Climate Change Impacts on Three Gorges Reservoir Impoundment and Hydropower Generation. J. Hydrol. 2020, 580, 123922. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, L.; Zhang, L.; Qin, S.; Liu, L.; Liu, P.; Liu, Y. Does Non-Stationarity Induced by Multiyear Drought Invalidate the Paired-Catchment Method? Hydrol. Earth Syst. Sci. 2022, 26, 6379–6397. [Google Scholar] [CrossRef]
- IPCC. Global Warming of 1.5 °C: IPCC Special Report on Impacts of Global Warming of 1.5 °C above Pre-Industrial Levels in Context of Strengthening Response to Climate Change, Sustainable Development, and Efforts to Eradicate Poverty, 1st ed.; Cambridge University Press: Cambridge, UK, 2022; ISBN 978-1-00-915794-0. [Google Scholar]
- Zhang, R.; Cheng, L.; Liu, P.; Huang, K.; Gong, Y.; Qin, S.; Liu, D. Effect of GCM Credibility on Water Resource System Robustness under Climate Change Based on Decision Scaling. Adv. Water Resour. 2021, 158, 104063. [Google Scholar] [CrossRef]
- Wang, W.-C.; Chau, K.-W.; Cheng, C.-T.; Qiu, L. A Comparison of Performance of Several Artificial Intelligence Methods for Forecasting Monthly Discharge Time Series. J. Hydrol. 2009, 374, 294–306. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Muhammad Adnan, R. Monthly Runoff Forecasting Based on LSTM–ALO Model. Stoch Env. Res Risk Assess 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- Yang, T.; Asanjan, A.A.; Welles, E.; Gao, X.; Sorooshian, S.; Liu, X. Developing Reservoir Monthly Inflow Forecasts Using Artificial Intelligence and Climate Phenomenon Information. Water Resour. Res. 2017, 53, 2786–2812. [Google Scholar] [CrossRef]
- Vázquez, R.F.; Feyen, J. Assessment of the Effects of DEM Gridding on the Predictions of Basin Runoff Using MIKE SHE and a Modelling Resolution of 600m. J. Hydrol. 2007, 334, 73–87. [Google Scholar] [CrossRef]
- Fang, Y.-H.; Zhang, X.; Corbari, C.; Mancini, M.; Niu, G.-Y.; Zeng, W. Improving the Xin’anjiang Hydrological Model Based on Mass–Energy Balance. Hydrol. Earth Syst. Sci. 2017, 21, 3359–3375. [Google Scholar] [CrossRef] [Green Version]
- Su, H.; Cheng, L.; Wu, Y.; Qin, S.; Liu, P.; Zhang, Q.; Cheng, S.; Li, Y. Extreme Storm Events Shift DOC Export from Transport-Limited to Source-Limited in a Typical Flash Flood Catchment. J. Hydrol. 2023, 620, 129377. [Google Scholar] [CrossRef]
- Wu, M.-C.; Lin, G.-F. The Very Short-Term Rainfall Forecasting for a Mountainous Watershed by Means of an Ensemble Numerical Weather Prediction System in Taiwan. J. Hydrol. 2017, 546, 60–70. [Google Scholar] [CrossRef]
- Mignot, E.; Li, X.; Dewals, B. Experimental Modelling of Urban Flooding: A Review. J. Hydrol. 2019, 568, 334–342. [Google Scholar] [CrossRef] [Green Version]
- Salas, J.D.; Tabios, G.Q.; Bartolini, P. Approaches to Multivariate Modeling of Water Resources Time Series. J. Am. Water Resour. Assoc. 1985, 21, 683–708. [Google Scholar] [CrossRef]
- Montanari, A.; Rosso, R.; Taqqu, M.S. Fractionally Differenced ARIMA Models Applied to Hydrologic Time Series: Identification, Estimation, and Simulation. Water Resour. Res. 1997, 33, 1035–1044. [Google Scholar] [CrossRef]
- Cheng, S.; Cheng, L.; Qin, S.; Zhang, L.; Liu, P.; Liu, L.; Xu, Z.; Wang, Q. Improved Understanding of How Catchment Properties Control Hydrological Partitioning Through Machine Learning. Water Resour. Res. 2022, 58, e2021WR031412. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Jaafar, O.; Deo, R.C.; Kisi, O.; Adamowski, J.; Quilty, J.; El-Shafie, A. Stream-Flow Forecasting Using Extreme Learning Machines: A Case Study in a Semi-Arid Region in Iraq. J. Hydrol. 2016, 542, 603–614. [Google Scholar] [CrossRef]
- Bray, M.; Han, D. Identification of Support Vector Machines for Runoff Modelling. J. Hydroinformatics 2004, 6, 265–280. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chang, F.-J.; Chen, P.-A.; Lu, Y.-R.; Huang, E.; Chang, K.-Y. Real-Time Multi-Step-Ahead Water Level Forecasting by Recurrent Neural Networks for Urban Flood Control. J. Hydrol. 2014, 517, 836–846. [Google Scholar] [CrossRef]
- Carlson, R.F.; MacCormick, A.J.A.; Watts, D.G. Application of Linear Random Models to Four Annual Streamflow Series. Water Resour. Res. 1970, 6, 1070–1078. [Google Scholar] [CrossRef]
- Burlando, P.; Rosso, R.; Cadavid, L.G.; Salas, J.D. Forecasting of Short-Term Rainfall Using ARMA Models. J. Hydrol. 1993, 144, 193–211. [Google Scholar] [CrossRef]
- Rahman, M.A.; Yunsheng, L.; Sultana, N. Analysis and Prediction of Rainfall Trends over Bangladesh Using Mann–Kendall, Spearman’s Rho Tests and ARIMA Model. Meteorol. Atmos. Phys. 2017, 129, 409–424. [Google Scholar] [CrossRef]
- Liu, S.; Xu, J.; Zhao, J.; Xie, X.; Zhang, W. Efficiency Enhancement of a Process-Based Rainfall–Runoff Model Using a New Modified AdaBoost.RT Technique. Appl. Soft Comput. 2014, 23, 521–529. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, G.; Hou, J.; Xie, J.; Lv, M.; Liu, F. Hybrid Forecasting Model for Non-Stationary Daily Runoff Series: A Case Study in the Han River Basin, China. J. Hydrol. 2019, 577, 123915. [Google Scholar] [CrossRef]
- Xiang, Z.; Yan, J.; Demir, I. A Rainfall-Runoff Model With LSTM-Based Sequence-to-Sequence Learning. Water Resour. Res. 2020, 56, e2019WR025326. [Google Scholar] [CrossRef]
- Chen, X.; Huang, J.; Han, Z.; Gao, H.; Liu, M.; Li, Z.; Liu, X.; Li, Q.; Qi, H.; Huang, Y. The Importance of Short Lag-Time in the Runoff Forecasting Model Based on Long Short-Term Memory. J. Hydrol. 2020, 589, 125359. [Google Scholar] [CrossRef]
- Renard, B.; Kavetski, D.; Kuczera, G.; Thyer, M.; Franks, S.W. Understanding Predictive Uncertainty in Hydrologic Modeling: The Challenge of Identifying Input and Structural Errors: Identifiability of Input and Structural Errors. Water Resour. Res. 2010, 46, W05521. [Google Scholar] [CrossRef]
- Liu, G.; Tang, Z.; Qin, H.; Liu, S.; Shen, Q.; Qu, Y.; Zhou, J. Short-Term Runoff Prediction Using Deep Learning Multi-Dimensional Ensemble Method. J. Hydrol. 2022, 609, 127762. [Google Scholar] [CrossRef]
- Baran, S.; Hemri, S.; El Ayari, M. Statistical Postprocessing of Water Level Forecasts Using Bayesian Model Averaging with Doubly Truncated Normal Components. Water Resour. Res. 2019, 55, 3997–4013. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Ren, L.; Xu, C.-Y.; Liu, S.; Yuan, F.; Yang, X. Quantifying Multi-Source Uncertainties in Multi-Model Predictions Using the Bayesian Model Averaging Scheme. Hydrol. Res. 2018, 49, 954–970. [Google Scholar] [CrossRef]
- Höge, M.; Guthke, A.; Nowak, W. The Hydrologist’s Guide to Bayesian Model Selection, Averaging and Combination. J. Hydrol. 2019, 572, 96–107. [Google Scholar] [CrossRef]
- Diks, C.G.H.; Vrugt, J.A. Comparison of Point Forecast Accuracy of Model Averaging Methods in Hydrologic Applications. Stoch Environ. Res. Risk. Assess 2010, 24, 809–820. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Trevor, B. A Stacking Ensemble Learning Framework for Annual River Ice Breakup Dates. J. Hydrol. 2018, 561, 636–650. [Google Scholar] [CrossRef]
- Ho, T.K. Random Decision Forests. In Proceedings of the Third International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; IEEE Computer Society: Washington, DC, USA, 1995; Volume 1, p. 278. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Loken, E.D.; Clark, A.J.; McGovern, A.; Flora, M.; Knopfmeier, K. Postprocessing Next-Day Ensemble Probabilistic Precipitation Forecasts Using Random Forests. Weather Forecast. 2019, 34, 2017–2044. [Google Scholar] [CrossRef]
- Yang, J.; Huang, X. The 30 m Annual Land Cover Dataset and Its Dynamics in China from 1990 to 2019. Earth Syst. Sci. Data 2021, 13, 3907–3925. [Google Scholar] [CrossRef]
- Towfiqul Islam, A.R.M.; Talukdar, S.; Mahato, S.; Kundu, S.; Eibek, K.U.; Pham, Q.B.; Kuriqi, A.; Linh, N.T.T. Flood Susceptibility Modelling Using Advanced Ensemble Machine Learning Models. Geosci. Front. 2021, 12, 101075. [Google Scholar] [CrossRef]
- Srivastava, R.; Tiwari, A.N.; Giri, V.K. Solar Radiation Forecasting Using MARS, CART, M5, and Random Forest Model: A Case Study for India. Heliyon 2019, 5, e02692. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Wu, C.; Zhong, H.; Li, Y.; Wang, L. Prediction of Undrained Shear Strength Using Extreme Gradient Boosting and Random Forest Based on Bayesian Optimization. Geosci. Front. 2021, 12, 469–477. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R. Experiments with a New Boosting Algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1996; pp. 148–156. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive Logistic Regression: A Statistical View of Boosting (With Discussion and a Rejoinder by the Authors). Ann. Statist. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; ACM: New York, NY, USA; pp. 785–794. [Google Scholar]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Lu, X.; Xiang, Y. Evaluation of SVM, ELM and Four Tree-Based Ensemble Models for Predicting Daily Reference Evapotranspiration Using Limited Meteorological Data in Different Climates of China. Agric. For. Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Jia, Y.; Jin, S.; Savi, P.; Gao, Y.; Tang, J.; Chen, Y.; Li, W. GNSS-R Soil Moisture Retrieval Based on a XGboost Machine Learning Aided Method: Performance and Validation. Remote Sens. 2019, 11, 1655. [Google Scholar] [CrossRef] [Green Version]
- Tahmassebi, A.; Wengert, G.J.; Helbich, T.H.; Bago-Horvath, Z.; Alaei, S.; Bartsch, R.; Dubsky, P.; Baltzer, P.; Clauser, P.; Kapetas, P.; et al. Impact of Machine Learning with Multiparametric Magnetic Resonance Imaging of the Breast for Early Prediction of Response to Neoadjuvant Chemotherapy and Survival Outcomes in Breast Cancer Patients. Investig. Radiol. 2019, 54, 110–117. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked Generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Zhou, Z.-H. Ensemble Learning. In Encyclopedia of Biometrics; Li, S.Z., Jain, A.K., Eds.; Springer US: Boston, MA, USA, 2015; pp. 411–416. ISBN 978-1-4899-7487-7. [Google Scholar]
- Ghahramani, Z. Probabilistic Machine Learning and Artificial Intelligence. Nature 2015, 521, 452–459. [Google Scholar] [CrossRef]
- Shang, Q.; Lin, C.; Yang, Z.; Bing, Q.; Zhou, X. A Hybrid Short-Term Traffic Flow Prediction Model Based on Singular Spectrum Analysis and Kernel Extreme Learning Machine. PLoS ONE 2016, 11, e0161259. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Xu, Y.-P.; Fu, G. Uncertainties in SWAT Extreme Flow Simulation under Climate Change. J. Hydrol. 2014, 515, 205–222. [Google Scholar] [CrossRef]
- Lichtendahl, K.C.; Grushka-Cockayne, Y.; Winkler, R.L. Is It Better to Average Probabilities or Quantiles? Manag. Sci. 2013, 59, 1594–1611. [Google Scholar] [CrossRef]
- Stock, J.H.; Watson, M.W. Combination Forecasts of Output Growth in a Seven-Country Data Set. J. Forecast. 2004, 23, 405–430. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.; Burnetas, A.; Langousis, A. Hydrological Post-Processing Using Stacked Generalization of Quantile Regression Algorithms: Large-Scale Application over CONUS. J. Hydrol. 2019, 577, 123957. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F.; de Marinis, G. Stacked Machine Learning Algorithms and Bidirectional Long Short-Term Memory Networks for Multi-Step Ahead Streamflow Forecasting: A Comparative Study. J. Hydrol. 2022, 613, 128431. [Google Scholar] [CrossRef]
- Gu, J.; Liu, S.; Zhou, Z.; Chalov, S.R.; Zhuang, Q. A Stacking Ensemble Learning Model for Monthly Rainfall Prediction in the Taihu Basin, China. Water 2022, 14, 492. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.; Langousis, A. Super Ensemble Learning for Daily Streamflow Forecasting: Large-Scale Demonstration and Comparison with Multiple Machine Learning Algorithms. Neural. Comput. Applic. 2021, 33, 3053–3068. [Google Scholar] [CrossRef]
- Kim, D.; Yu, H.; Lee, H.; Beighley, E.; Durand, M.; Alsdorf, D.E.; Hwang, E. Ensemble Learning Regression for Estimating River Discharges Using Satellite Altimetry Data: Central Congo River as a Test-Bed. Remote Sens. Environ. 2019, 221, 741–755. [Google Scholar] [CrossRef]
- Slater, L.J.; Villarini, G. Enhancing the Predictability of Seasonal Streamflow with a Statistical-Dynamical Approach. Geophys. Res. Lett. 2018, 45, 6504–6513. [Google Scholar] [CrossRef]
- Gibbs, M.S.; McInerney, D.; Humphrey, G.; Thyer, M.A.; Maier, H.R.; Dandy, G.C.; Kavetski, D. State Updating and Calibration Period Selection to Improve Dynamic Monthly Streamflow Forecasts for an Environmental Flow Management Application. Hydrol. Earth Syst. Sci. 2018, 22, 871–887. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Model Hyper-Parameters |
|---|---|
| Random Forest (RF) | n_estimators = 600 criterion = squared_error max_depth = None min_samples_split = 2 min_samples_leaf = 1 |
| Adaptive Boosting (AdaBoost) | n_estimators = 30 learning_rate = 0.08 base_estimator = DecisionTreeRegressor max_depth = None min_samples_split = 26 min_samples_leaf = 9 |
| Extreme Gradient Boosting (XGB) | n_estimators = 200 learning_rate = 0.02 subsample = 0.22 colsample_bytree = 0.96 |
| Period | Models | NSE | RMSE | MAE | r |
|---|---|---|---|---|---|
| Validation | RF | 0.690 (0.063) | 559.8 (111.3) | 267.6 (43.3) | 0.836 (0.030) |
| AdaBoost | 0.685 (0.066) | 564.2 (118.2) | 263.4 (45.7) | 0.834 (0.032) | |
| XGB | 0.704 (0.057) | 550.0 (121.9) | 265.3 (43.3) | 0.843 (0.031) | |
| Testing | RF | 0.757 (0.007) | 416.3 (6.4) | 204.4 (2.3) | 0.870 (0.003) |
| AdaBoost | 0.762 (0.014) | 411.7 (12.1) | 197.3 (2.4) | 0.872 (0.007) | |
| XGB | 0.767 (0.005) | 407.4 (4.0) | 205.5 (2.2) | 0.880 (0.003) |
| Models | NSE | RMSE | MAE | r |
|---|---|---|---|---|
| SAE | 0.766 | 408.0 | 199.3 | 0.876 |
| WAE | 0.779 | 397.0 | 181.5 | 0.883 |
| ATE | 0.845 | 331.9 | 147.6 | 0.920 |
| Models | Ranking (NSE) | Ranking (RMSE) | Ranking (MAE) | Ranking (r) |
|---|---|---|---|---|
| RF | 4.8 | 4.4 | 4.7 | 5.0 |
| AdaBoost | 5.2 | 4.7 | 3.4 | 5.3 |
| XGB | 3.3 | 3.8 | 5.1 | 3.3 |
| SAE | 3.7 | 4.0 | 3.8 | 3.9 |
| WAE | 2.9 | 2.7 | 2.8 | 2.4 |
| ATE | 1.1 | 1.4 | 1.2 | 1.1 |
| τχ2 | 30.80 | 21.83 | 28.80 | 36.69 |
| p | 1.03 × 10−5 | 5.64 × 10−4 | 2.54 × 10−5 | 6.92 × 10−7 |
| Models | ARD (NSE) | ARD (RMSE) | ARD (MAE) | ARD (r) |
|---|---|---|---|---|
| RF | 3.7 | 3.0 | 3.5 | 3.9 |
| AdaBoost | 4.1 | 3.3 | 2.2 | 4.2 |
| XGB | 2.2 | 2.4 | 3.9 | 2.2 |
| SAE | 2.6 | 2.6 | 2.6 | 2.8 |
| WAE | 1.8 | 1.3 | 1.6 | 1.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, M.; Hou, Q.; Qin, S.; Zhou, L.; Hua, D.; Wang, X.; Cheng, L. A Stacking Ensemble Model of Various Machine Learning Models for Daily Runoff Forecasting. Water 2023, 15, 1265. https://doi.org/10.3390/w15071265
Lu M, Hou Q, Qin S, Zhou L, Hua D, Wang X, Cheng L. A Stacking Ensemble Model of Various Machine Learning Models for Daily Runoff Forecasting. Water. 2023; 15(7):1265. https://doi.org/10.3390/w15071265
Chicago/Turabian StyleLu, Mingshen, Qinyao Hou, Shujing Qin, Lihao Zhou, Dong Hua, Xiaoxia Wang, and Lei Cheng. 2023. "A Stacking Ensemble Model of Various Machine Learning Models for Daily Runoff Forecasting" Water 15, no. 7: 1265. https://doi.org/10.3390/w15071265
APA StyleLu, M., Hou, Q., Qin, S., Zhou, L., Hua, D., Wang, X., & Cheng, L. (2023). A Stacking Ensemble Model of Various Machine Learning Models for Daily Runoff Forecasting. Water, 15(7), 1265. https://doi.org/10.3390/w15071265