
A Data Assimilation Methodology to Analyze the Unsaturated Seepage of an Earth–Rockfill Dam Using Physics-Informed Neural Networks Based on Hybrid Constraints


Abstract
1. Introduction
2. Methods
2.1. Seepage-Governing Equation
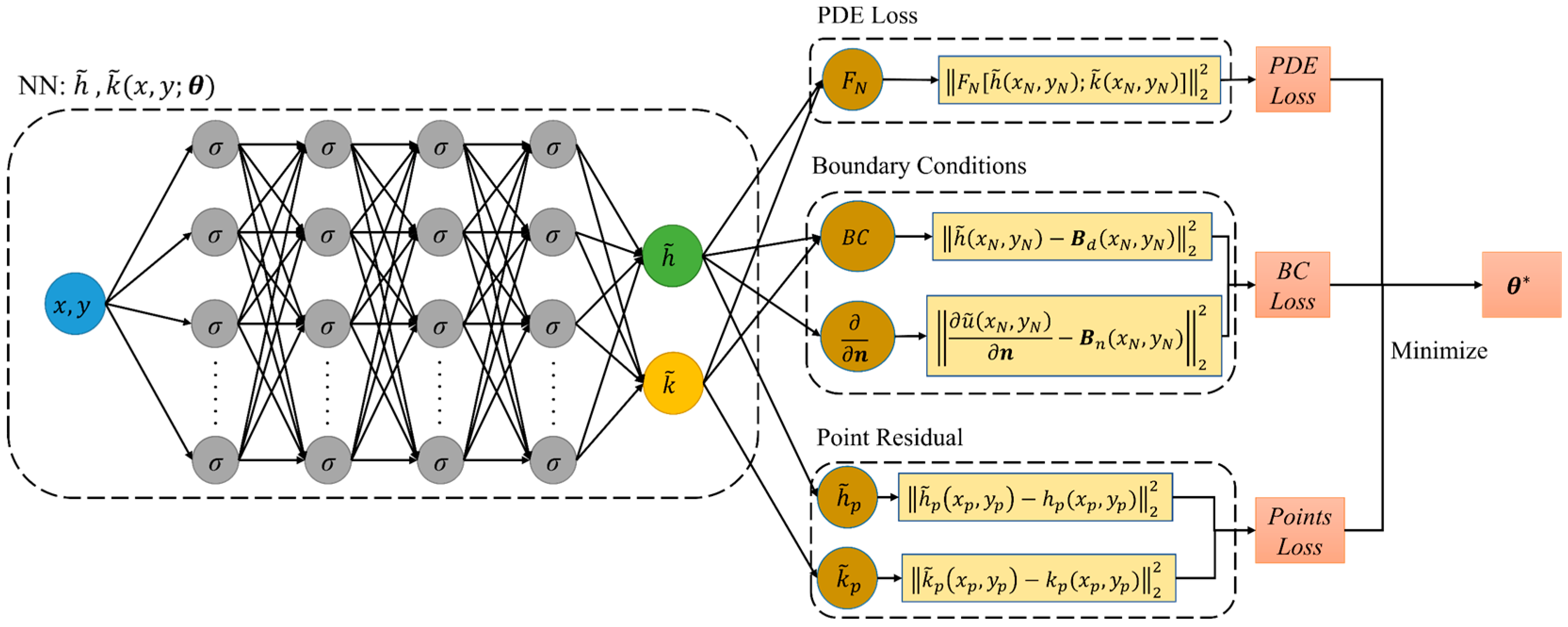
2.2. Neural Network Implementation
2.2.1. Structure of Neural Network
2.2.2. Loss Function
2.2.3. Automatic Differentiation
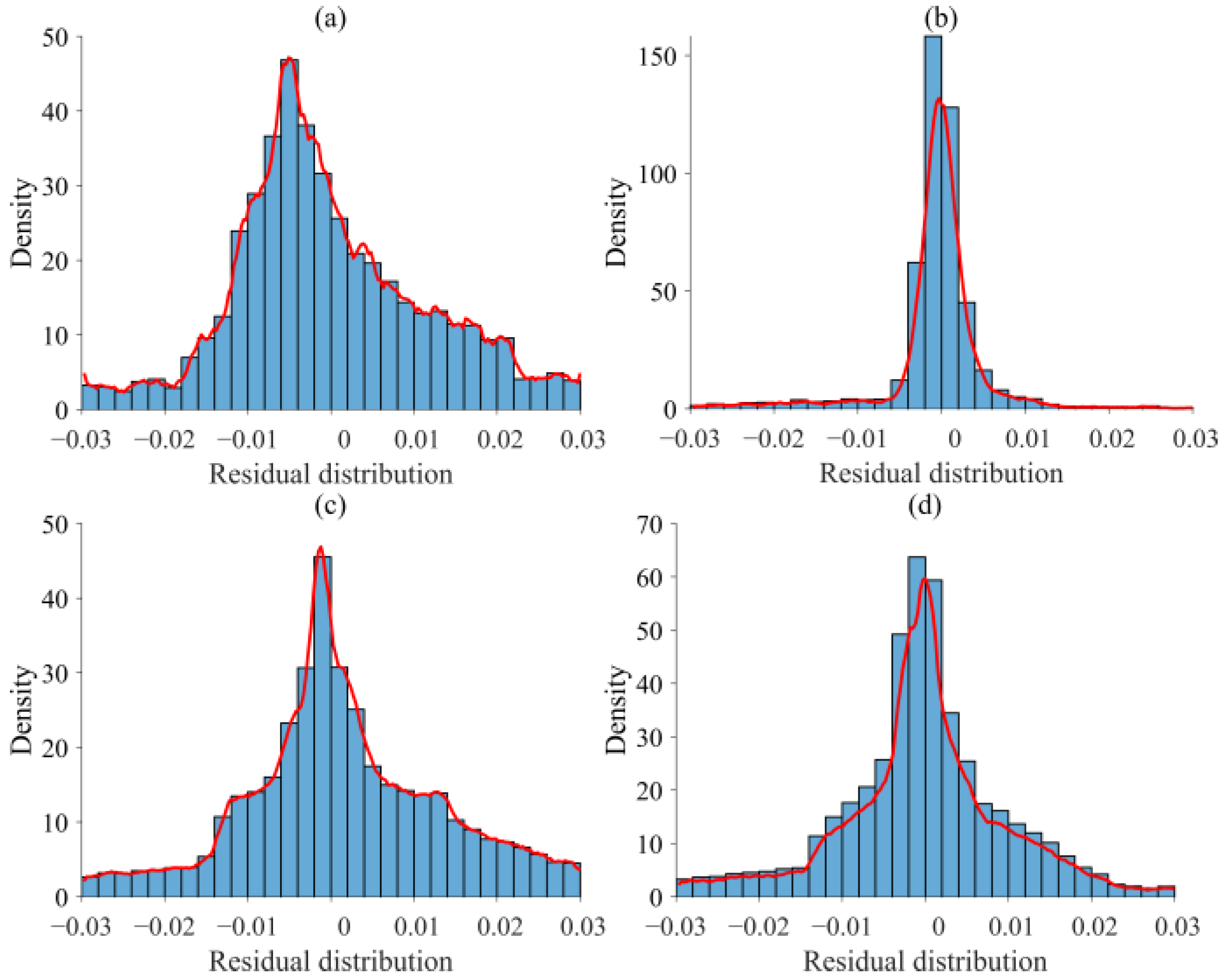
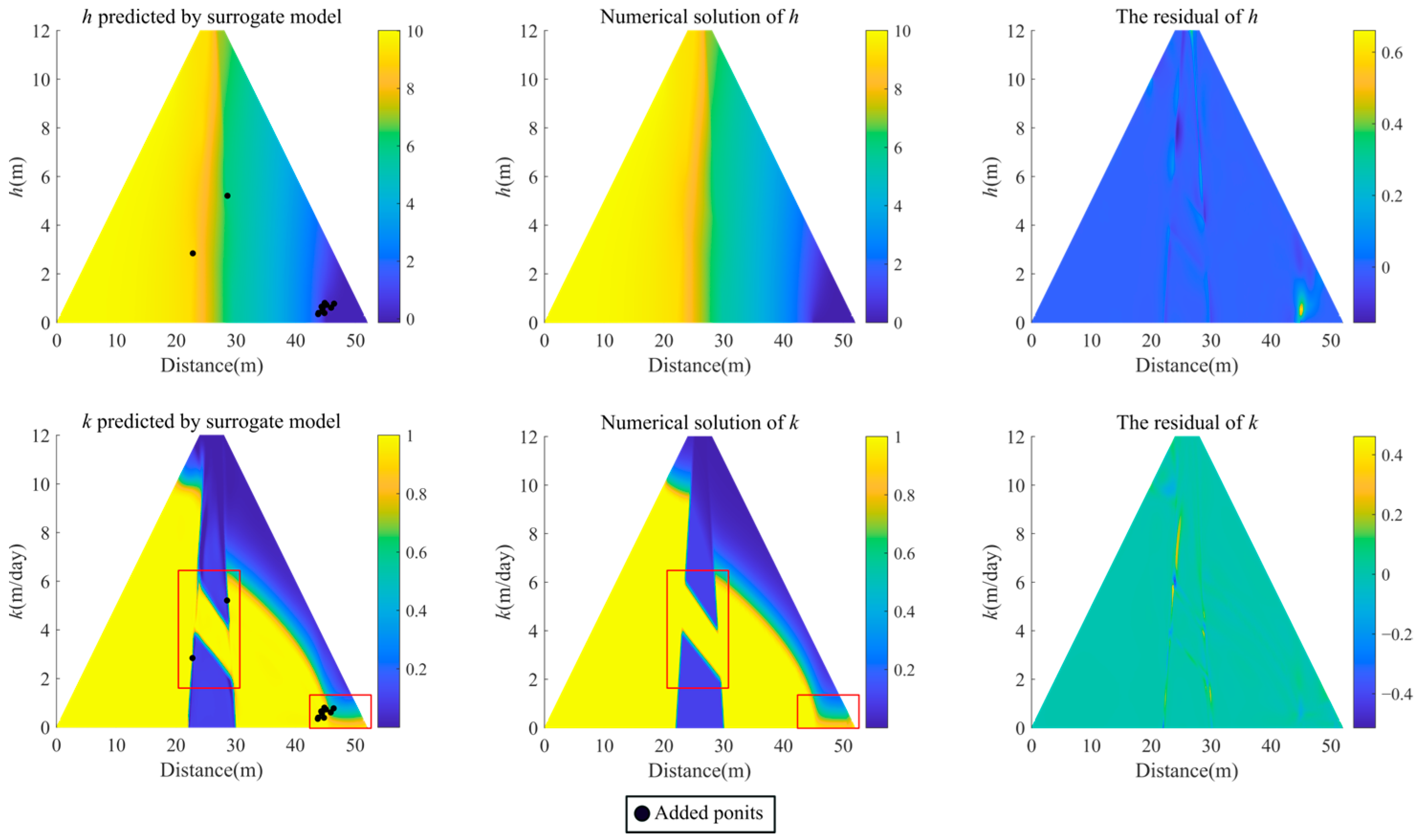
2.2.4. Residual-Based Adaptive Refinement
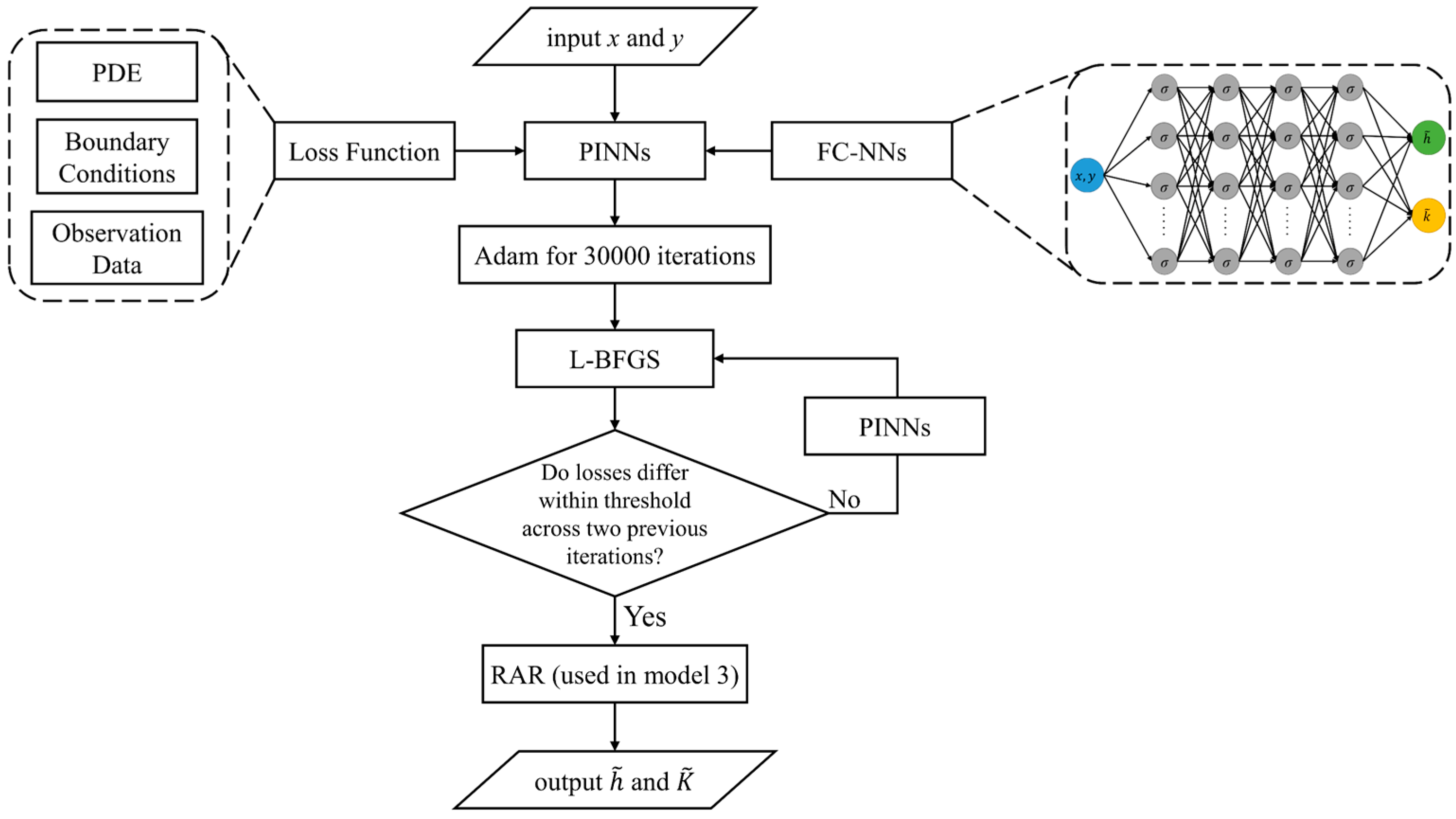
2.2.5. Workflow Process
- (i)
- Construct a PINN with the defined loss function (Equation (9)) and FC-NN. The inputs of the neural network are x and y, and the outputs are h and k.
- (ii)
- Initialize the network parameters (W and b) using the Glorot uniform.
- (iii)
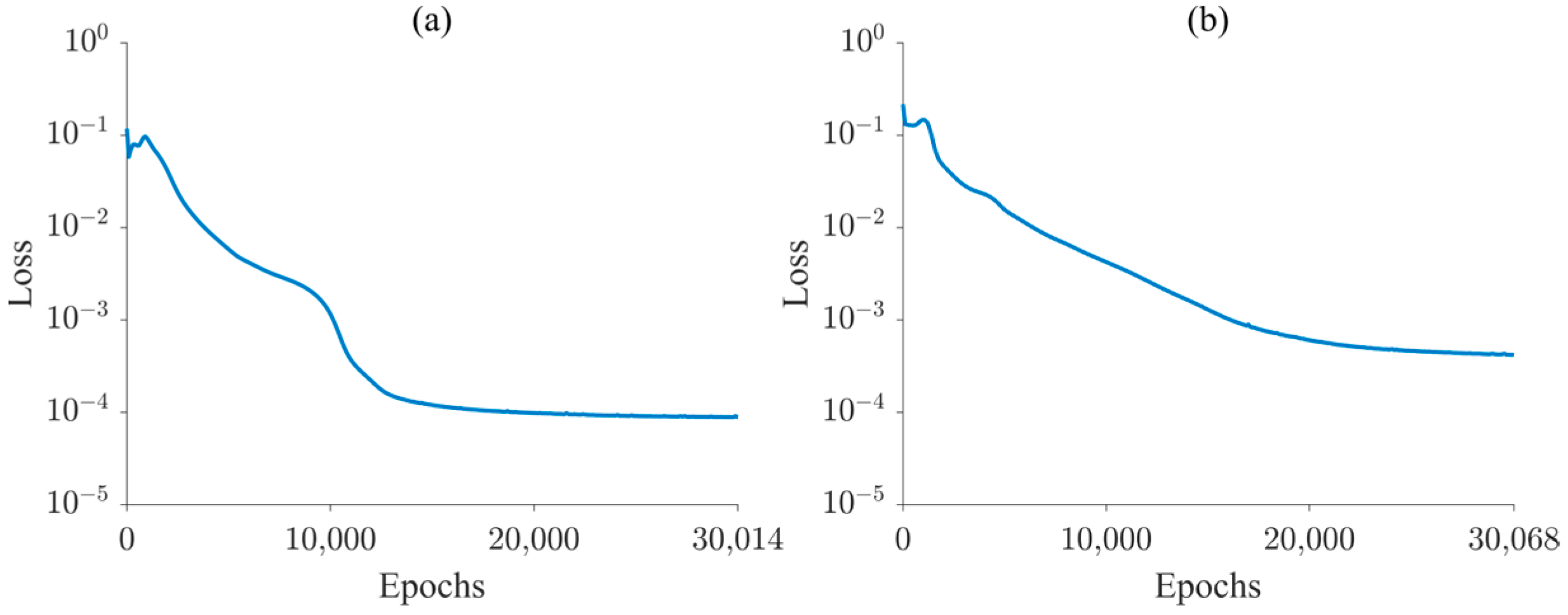
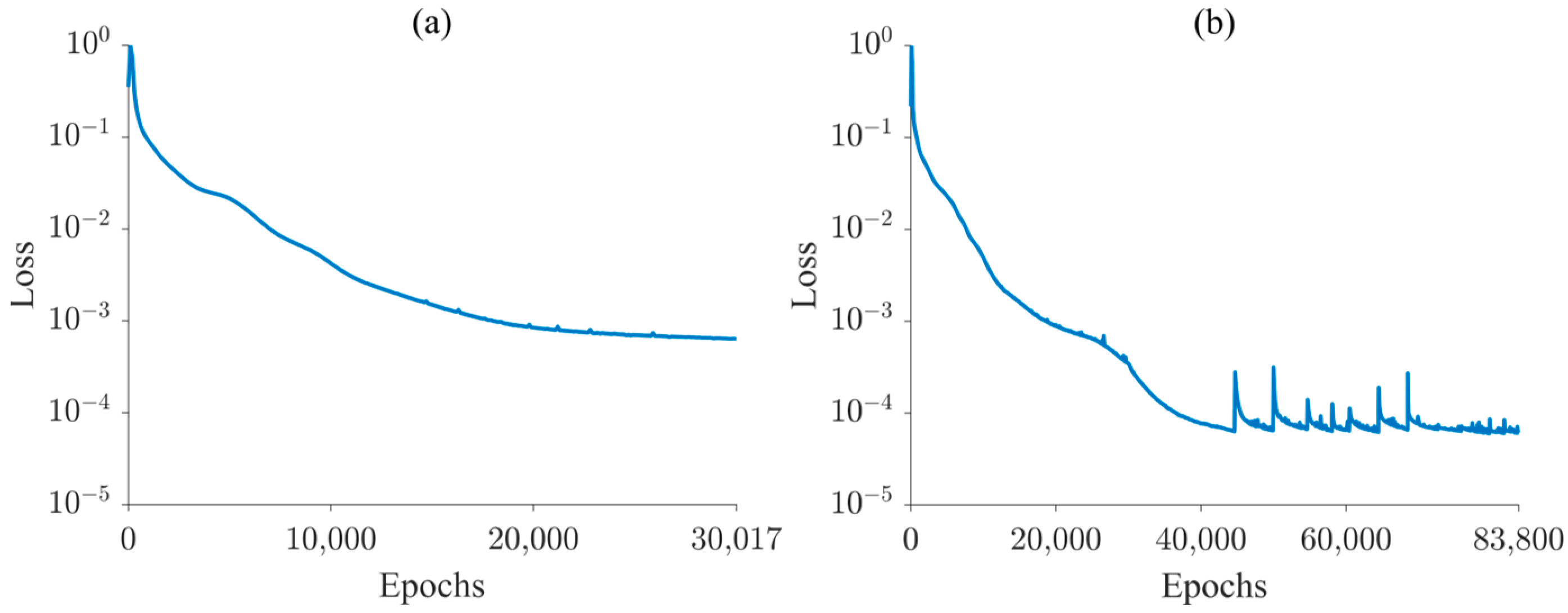
- Perform training using the Adam optimization algorithm for 30,000 epochs with a 0.0001 learning rate. Subsequently, switch to the L-BFGS optimization algorithm to continue training until the difference between the loss function values of two consecutive epochs falls below a specified tolerance.
- (iv)
- For the complex model in Section 3.3, apply the RAR method to further improve the accuracy of the calculations.
3. Numerical Experiments
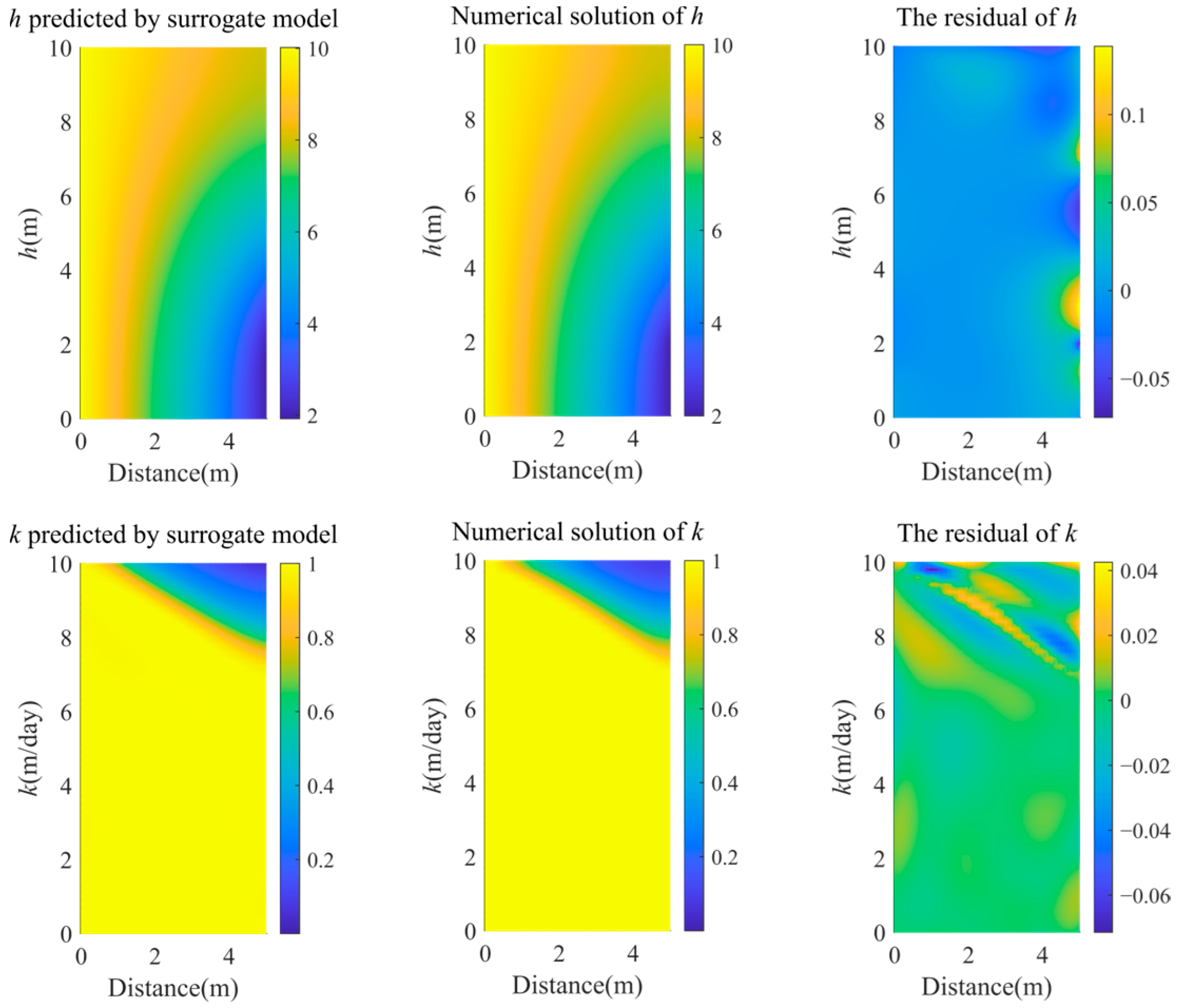
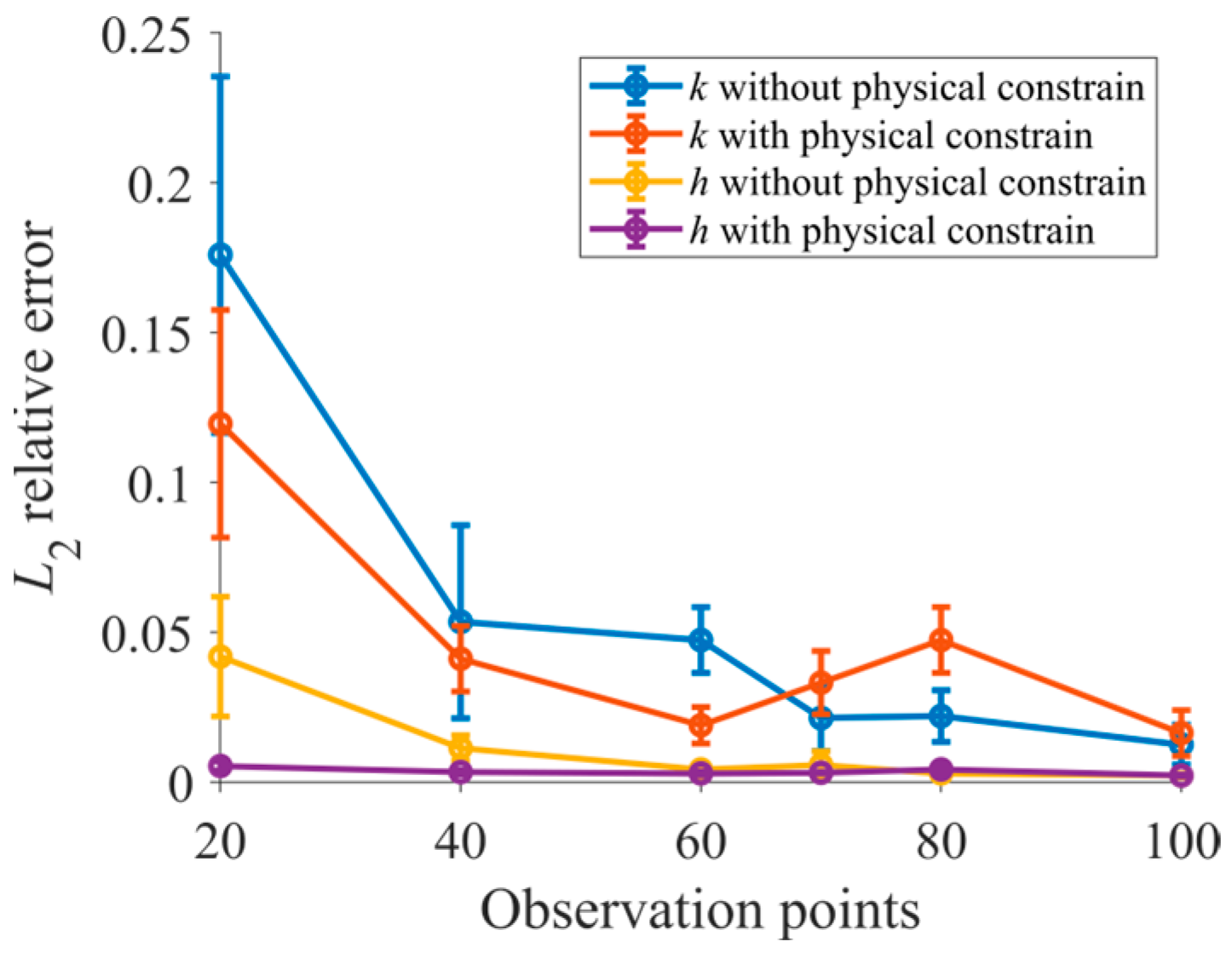
3.1. Homogeneous Rectangular Dam
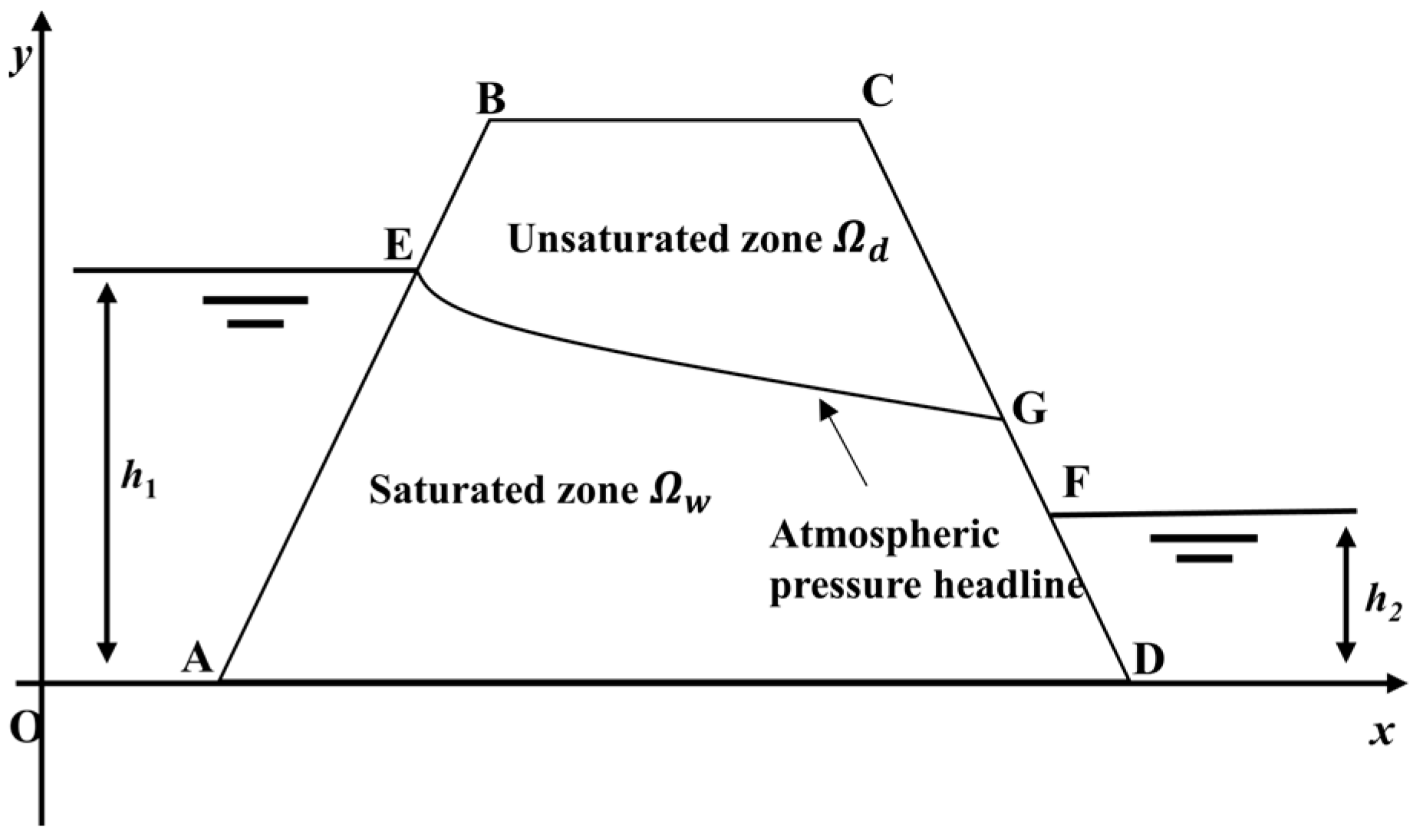
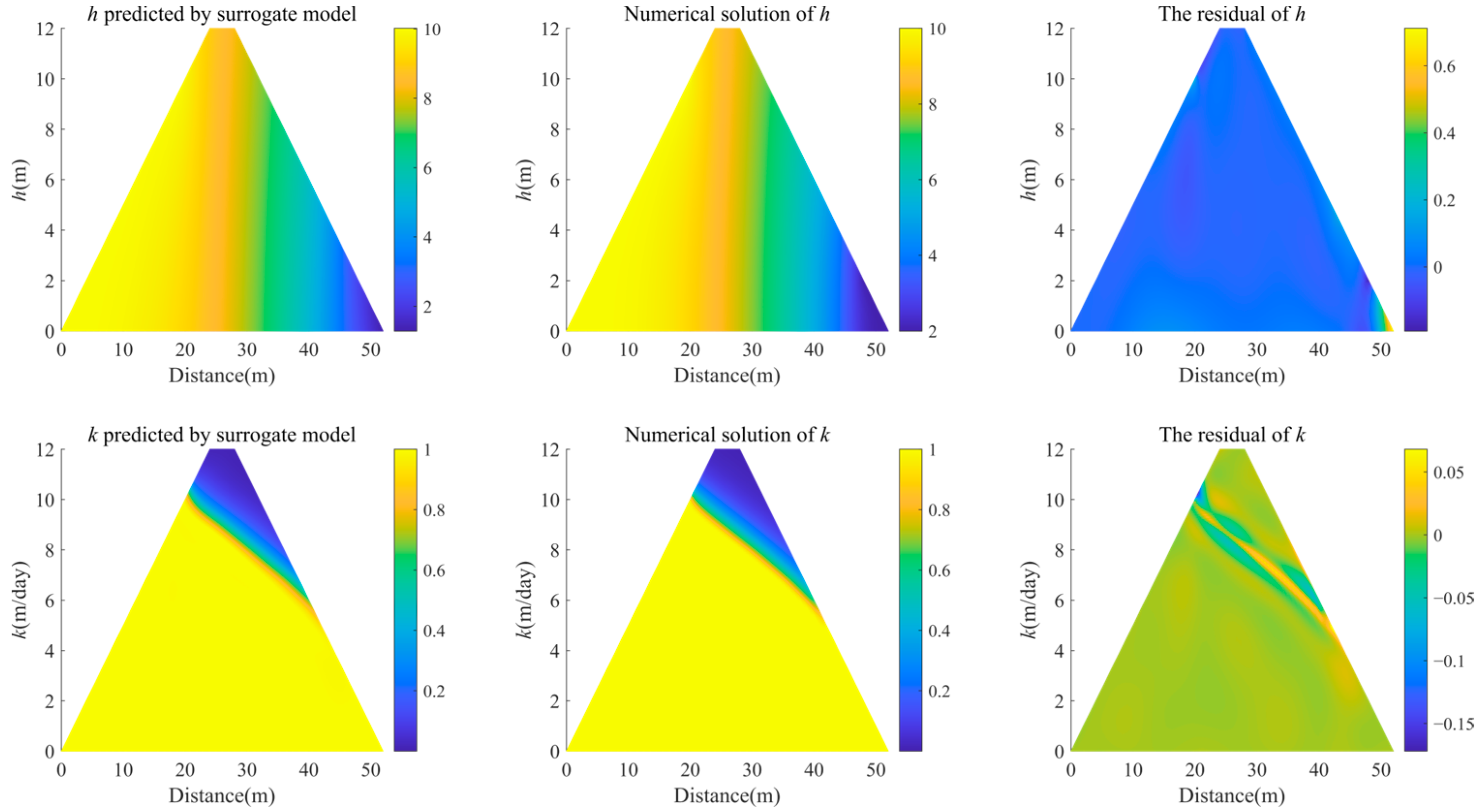
3.2. Trapezoidal Dam
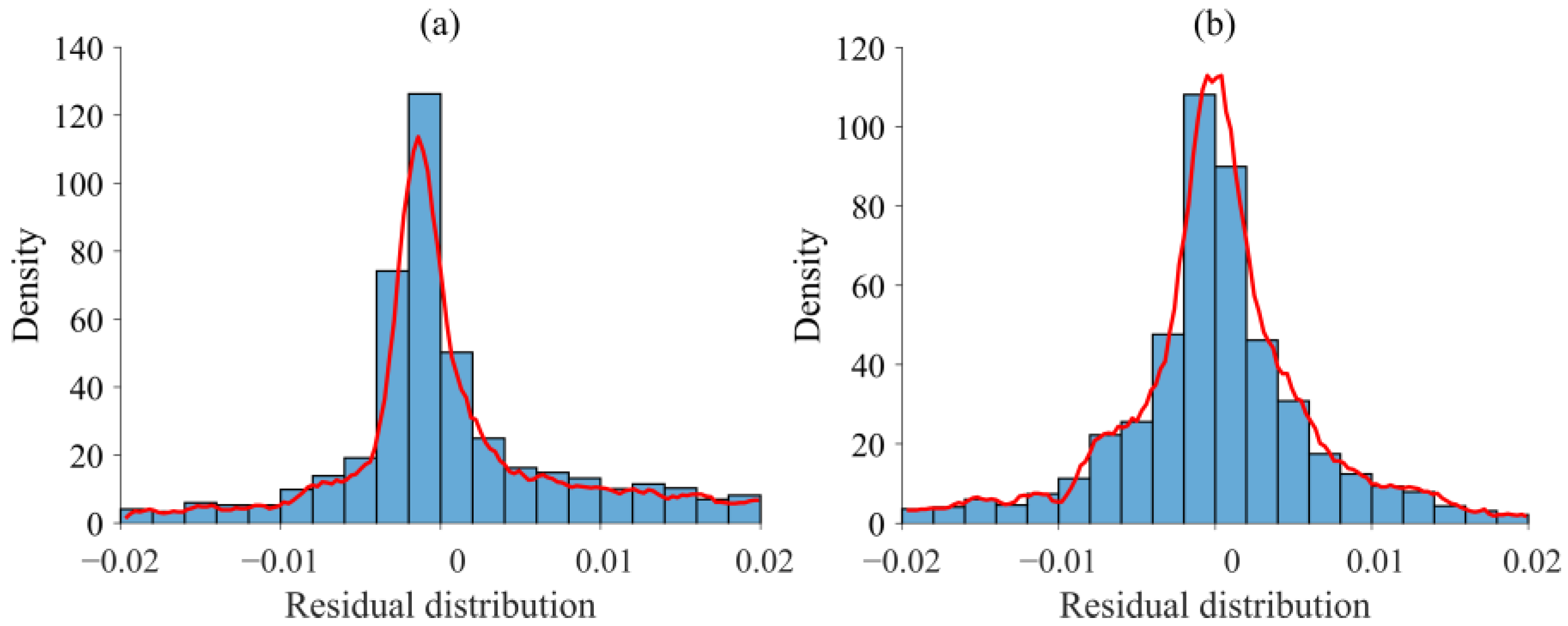
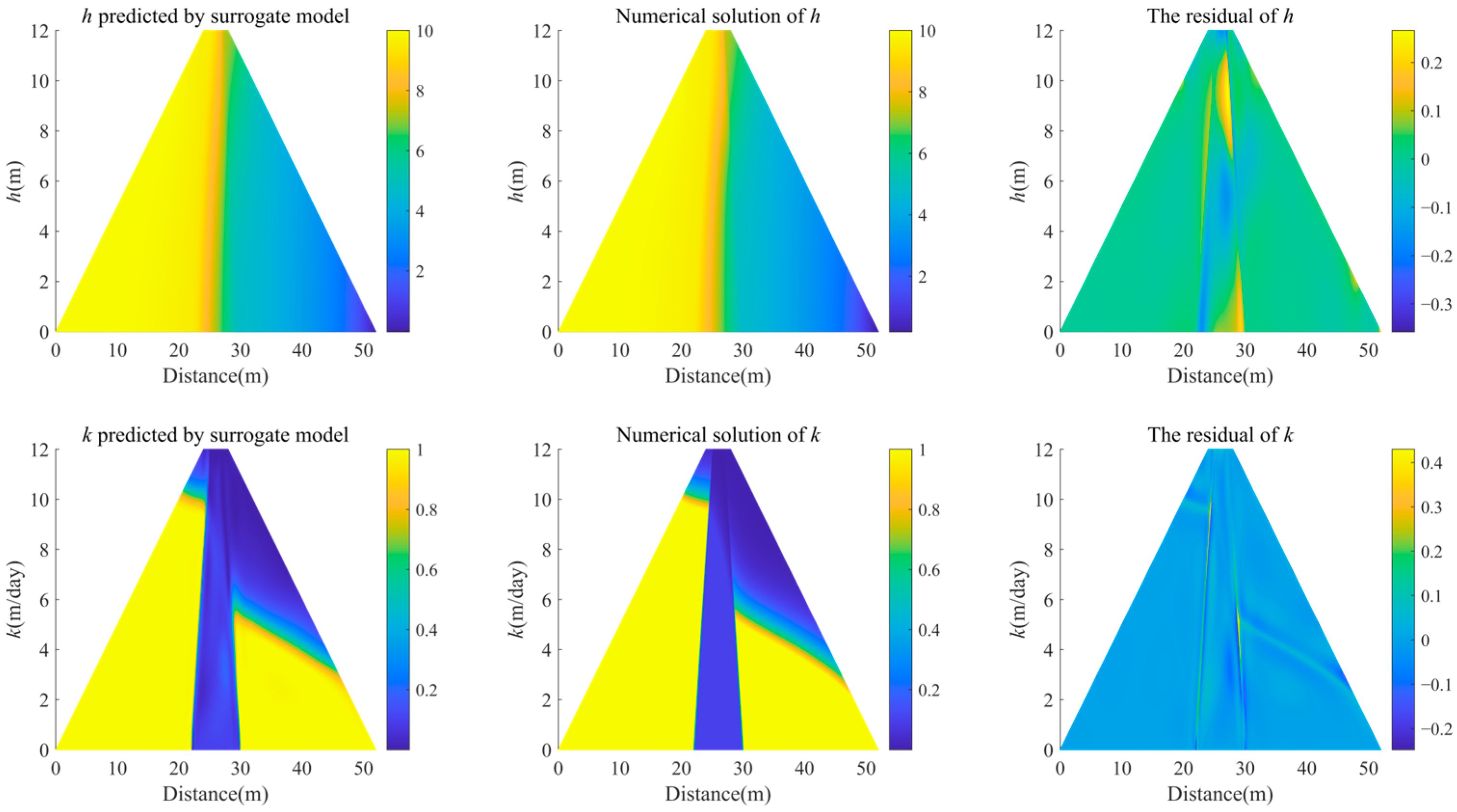
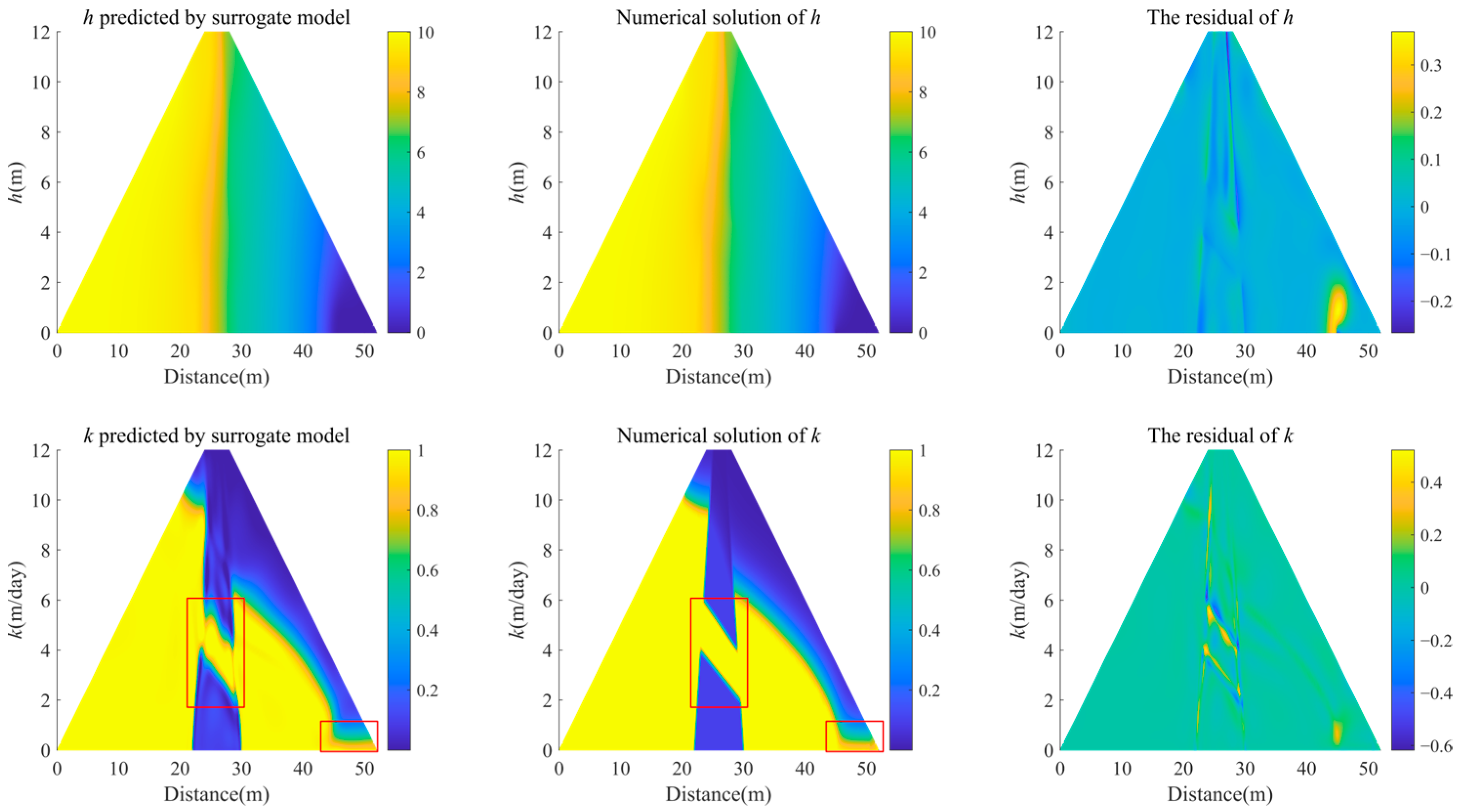
3.3. Hybrid model of trapezoidal dam
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, S.; He, Q.; Cao, J. Seepage simulation of high concrete-faced rockfill dams based on generalized equivalent continuum model. Water Sci. Eng. 2018, 11, 250–257. [Google Scholar] [CrossRef]
- Feng, R.; Fourtakas, G.; Rogers, B.D.; Lombardi, D. A general smoothed particle hydrodynamics (SPH) formulation for coupled liquid flow and solid deformation in porous media. Comput. Methods Appl. Mech. Eng. 2024, 419, 116581. [Google Scholar] [CrossRef]
- Yang, Y.; Sun, G.; Zheng, H. Modeling unconfined seepage flow in soil-rock mixtures using the numerical manifold method. Eng. Anal. 2019, 108, 60–70. [Google Scholar] [CrossRef]
- Zhang, J.; Zeng, L.; Chen, C.; Chen, D.; Wu, L. Efficient B ayesian experimental design for contaminant source identification. Water Resour. Res. 2015, 51, 576–598. [Google Scholar] [CrossRef]
- Hou, J.; Zhou, K.; Zhang, X.; Kang, X.; Xie, H. A review of closed-loop reservoir management. Pet. Sci. 2015, 12, 114–128. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. 1994, 99, 10143–10162. [Google Scholar] [CrossRef]
- Seo, M.G.; Kim, H.M. Effect of meteorological data assimilation using 3DVAR on high-resolution simulations of atmospheric CO2 concentrations in East Asia. Atmos. Pollut. Res. 2023, 14, 101759. [Google Scholar] [CrossRef]
- Musuuza, J.L.; Crochemore, L.; Pechlivanidis, I.G. Evaluation of earth observations and in situ data assimilation for seasonal hydrological forecasting. Water Resour. Res. 2023, 59, e2022WR033655. [Google Scholar] [CrossRef]
- Maschio, C.; Avansi, G.D.; Schiozer, D.J. Data Assimilation Using Principal Component Analysis and Artificial Neural Network. SPE Reserv. Eval. Eng. 2023, 26, 795–812. [Google Scholar] [CrossRef]
- Xu, Q.; Li, B.; McRoberts, R.E.; Li, Z.; Hou, Z. Harnessing data assimilation and spatial autocorrelation for forest inventory. Remote Sens. Environ. 2023, 288, 113488. [Google Scholar] [CrossRef]
- Beven, K.; Binley, A. The future of distributed models: Model calibration and uncertainty prediction. Hydrol. Process. 1992, 6, 279–298. [Google Scholar] [CrossRef]
- WK Hastings. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Yeh TC, J.; Liu, S. Hydraulic tomography: Development of a new aquifer test method. Water Resour. Res. 2000, 36, 2095–2105. [Google Scholar]
- Field, G.; Tavrisov, G.; Brown, C.; Harris, A.; Kreidl, O.P. Particle filters to estimate properties of confined aquifers. Water Resour. Manag. 2016, 30, 3175–3189. [Google Scholar] [CrossRef]
- Zheng, Q.; Xu, W.; Man, J.; Zeng, L.; Wu, L. A probabilistic collocation based iterative Kalman filter for landfill data assimilation. Adv. Water Resour. 2017, 109, 170–180. [Google Scholar] [CrossRef]
- Man, J.; Zheng, Q.; Wu, L.; Zeng, L. Adaptive multi-fidelity probabilistic collocation-based Kalman filter for subsurface flow data assimilation: Numerical modeling and real-world experiment. Stoch. Environ. Res. Risk Assess. 2020, 34, 1135–1146. [Google Scholar] [CrossRef]
- Golmohammadi, M.; Harati Nejad Torbati, A.H.; Lopez de Diego, S.; Obeid, L.; Picone, J. Automatic analysis of EEGs using big data and hybrid deep learning architectures. Front. Hum. Neurosci. 2019, 13, 76. [Google Scholar] [CrossRef] [PubMed]
- Hailesilassie, T. Rule extraction algorithm for deep neural networks: A review. arXiv 2016, arXiv:1610.05267. [Google Scholar]
- Zhang, J.; Li, C.; Jiang, W.; Wang, Z.; Zhang, L.; Wang, X. Deep-learning-enabled microwave-induced thermoacoustic tomography based on sparse data for breast cancer detection. IEEE Trans. Antennas Propag. 2022, 70, 6336–6348. [Google Scholar] [CrossRef]
- Mao, B.; Han, L.; Feng, Q.; Yin, Y. Subsurface velocity inversion from deep learning-based data assimilation. J. Appl. Geophys. 2019, 167, 172–179. [Google Scholar] [CrossRef]
- Tang, M.; Liu, Y.; Durlofsky, L.J. A deep-learning-based surrogate model for data assimilation in dynamic subsurface flow problems. J. Comput. Phys. 2020, 413, 109456. [Google Scholar] [CrossRef]
- Tang, M.; Liu, Y.; Durlofsky, L.J. Deep-learning-based surrogate flow modeling and geological parameterization for data assimilation in 3D subsurface flow. Comput. Methods Appl. Mech. Eng. 2021, 376, 113636. [Google Scholar] [CrossRef]
- Kang, X.; Kokkinaki, A.; Power, C.; Kitanidis, P.; Shi, X.; Duan, L.; Liu, T.; Wu, J. Integrating deep learning-based data assimilation and hydrogeophysical data for improved monitoring of DNAPL source zones during remediation. J. Hydrol. 2021, 601, 126655. [Google Scholar] [CrossRef]
- Sun, L.; Gao, H.; Pan, S.; Wang, J. Surrogate modeling for fluid flows based on physics-constrained deep learning without simulation data. Comput. Methods Appl. Mech. Eng. 2020, 361, 112732. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Chen, Y.; Lu, L.; Karniadakis, G.E.; Dal Negro, L. Physics-informed neural networks for inverse problems in nano-optics and metamaterials. Opt. Express. 2020, 28, 11618–11633. [Google Scholar] [CrossRef] [PubMed]
- Xue, L.; Dai, C.; Han, J.X.; Yang, M.; Liu, Y. Deep neural network model driven jointly by reservoir seepage physics and data. Pet. Geol. Recovery Effic. 2020, 29, 145–151. [Google Scholar]
- Tartakovsky, A.M.; Marrero, C.O.; Perdikaris, P.; Tartakovsky, G.D.; Barajas-Solano, D. Physics-informed deep neural networks for learning parameters and constitutive relationships in subsurface flow problems. Water Resour. Res. 2020, 56, e2019WR026731. [Google Scholar] [CrossRef]
- He, Q.; Barajas-Solano, D.; Tartakovsky, G.; Tartakovsky, A. Physics-informed neural networks for multiphysics data assimilation with application to subsurface transport. Adv. Water Resour. 2020, 141, 103610. [Google Scholar] [CrossRef]
- Zhang, S.; Lan, P.; Su, J.; Xiong, H. Simulation and parameter identification of groundwater flow model based on PINNs algorithms. Chin. J. Geotech. Eng. 2023, 45, 376–383. [Google Scholar]
- Depina, I.; Jain, S.; Mar Valsson, S.; Gotovac, H. Application of physics-informed neural networks to inverse problems in unsaturated groundwater flow. Georisk 2022, 16, 21–36. [Google Scholar] [CrossRef]
- Shadab, M.A.; Luo, D.; Hiatt, E.; Shen, Y.; Hesse, M.A. Investigating steady unconfined groundwater flow using Physics Informed Neural Networks. Adv. Water Resour. 2023, 177, 104445. [Google Scholar] [CrossRef]
- Yang, Y.; Gong, H.; Zhang, S.; Yang, Q.; Chen, Z.; He, Q.; Li, Q. A data-enabled physics-informed neural network with comprehensive numerical study on solving neutron diffusion eigenvalue problems. Ann. Nucl. Energy 2023, 183, 109656. [Google Scholar] [CrossRef]
- Lu, L.; Meng, X.; Mao, Z.; Karniadakis, G.E. DeepXDE: A deep learning library for solving differential equations. SIAM Rev. Soc. Ind. Appl. Math. 2021, 63, 208–228. [Google Scholar] [CrossRef]
- Lei, Y.; Dai, Q.; Zhang, B.; Zhou, W.; Yang, J. Saturated-unsaturated seepage simulation and hydrological dam models for quantifying the heterogeneity to hydrological state variables: Impacts of auxiliary structures and leakage anomalies. Int. J. Numer. Anal. Methods Geomech. 2023, 47, 2064–2084. [Google Scholar] [CrossRef]
- Richards, L.A. Capillary conduction of liquids through porous mediums. Physics 1931, 1, 318–333. [Google Scholar] [CrossRef]
- Van Genuchten, M.T. A closed-form equation for predicting the hydraulic conductivity of unsaturated soils. Soil Sci. Soc. Am. J. 1980, 44, 892–898. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res. 2018, 18, 1–43. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31th Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Workflow of the RAR Method |
|---|
| Step 1: Select a set of the initial points Γ and train the PINNs for a limited number of iterations. |
| Step 2: Calculate the mean PDE residual by the average of values at a set of randomly sampled points in area S. Step 3: Stop if the residual is within the threshold. Otherwise, add new points with the largest residual points in S to Γ, retrain the network, and go to Step 2. |
| L2 Relative Error of h | L2 Relative Error of k | |
|---|---|---|
| Adam | 0.0028 | 0.0391 |
| Adam, L-BFGS | 0.0029 | 0.0189 |
| L2 Relative Error of h | L2 Relative Error of k | |
|---|---|---|
| Adam, L-BFGS | 0.0052 | 0.0538 |
| Adam, L-BFGS, and RAR | 0.0040 | 0.0489 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Q.; Zhou, W.; He, R.; Yang, J.; Zhang, B.; Lei, Y. A Data Assimilation Methodology to Analyze the Unsaturated Seepage of an Earth–Rockfill Dam Using Physics-Informed Neural Networks Based on Hybrid Constraints. Water 2024, 16, 1041. https://doi.org/10.3390/w16071041
Dai Q, Zhou W, He R, Yang J, Zhang B, Lei Y. A Data Assimilation Methodology to Analyze the Unsaturated Seepage of an Earth–Rockfill Dam Using Physics-Informed Neural Networks Based on Hybrid Constraints. Water. 2024; 16(7):1041. https://doi.org/10.3390/w16071041
Chicago/Turabian StyleDai, Qianwei, Wei Zhou, Run He, Junsheng Yang, Bin Zhang, and Yi Lei. 2024. "A Data Assimilation Methodology to Analyze the Unsaturated Seepage of an Earth–Rockfill Dam Using Physics-Informed Neural Networks Based on Hybrid Constraints" Water 16, no. 7: 1041. https://doi.org/10.3390/w16071041
APA StyleDai, Q., Zhou, W., He, R., Yang, J., Zhang, B., & Lei, Y. (2024). A Data Assimilation Methodology to Analyze the Unsaturated Seepage of an Earth–Rockfill Dam Using Physics-Informed Neural Networks Based on Hybrid Constraints. Water, 16(7), 1041. https://doi.org/10.3390/w16071041