
Advancing Digital Image-Based Recognition of Soil Water Content: A Case Study in Bailu Highland, Shaanxi Province, China

 , , ,
, , ,
Abstract
:1. Introduction
- 1.
- There is a need for more effective image-based SWC recognition regression methods. Previous studies have primarily utilized simple traditional machine learning models such as linear models [31], polynomial models [25], exponential models [34], and basic deep learning models [29,33]. However, research has shown that the response of soil image information to changes in SWC is not a straightforward relationship [13,31]. Simple models can lead to poor accuracy and stability in recognition, failing to meet application demands. Therefore, more effective regression models are needed to learn the complex patterns and feature representations in soil images, enhancing the accuracy and stability of SWC recognition regression.
- 2.
- The high demand for computational resources has increased the threshold for application, limiting the potential for widespread use. Previous research has primarily focused on selecting useful input variables, such as mean and variance in the statistical color space of soil images [30,31,32,33]. However, selecting variables to represent the entire image may lead to the loss of valuable information within the image. As a viable alternative, many current studies choose to input all pixels of the entire image into the model without variable selection [32,33]. However, the computational and time costs for handling large amounts of data increase the usage threshold, requiring more expensive computational resources. This poses a challenge in resource-constrained environments. One way to address this issue is to develop more efficient algorithms and technologies to reduce computational and time costs, thus lowering the application threshold and increasing the potential for widespread use.
- 3.
- Highly redundant spatial information in soil images. Highly redundant spatial information exists in traditional natural images [35,36]. However, soil images mainly consist of a significantly larger proportion of soil regions and a smaller proportion of non-soil areas (porous areas, mineral composition areas), where the redundant spatial information between these regions is more pronounced and highly similar compared to natural images. Yet, research on reducing the spatial redundancy in soil images to prevent the model from merely focusing on the low-level statistical distribution of images and truly understanding soil image characteristics is very limited.
- 1.
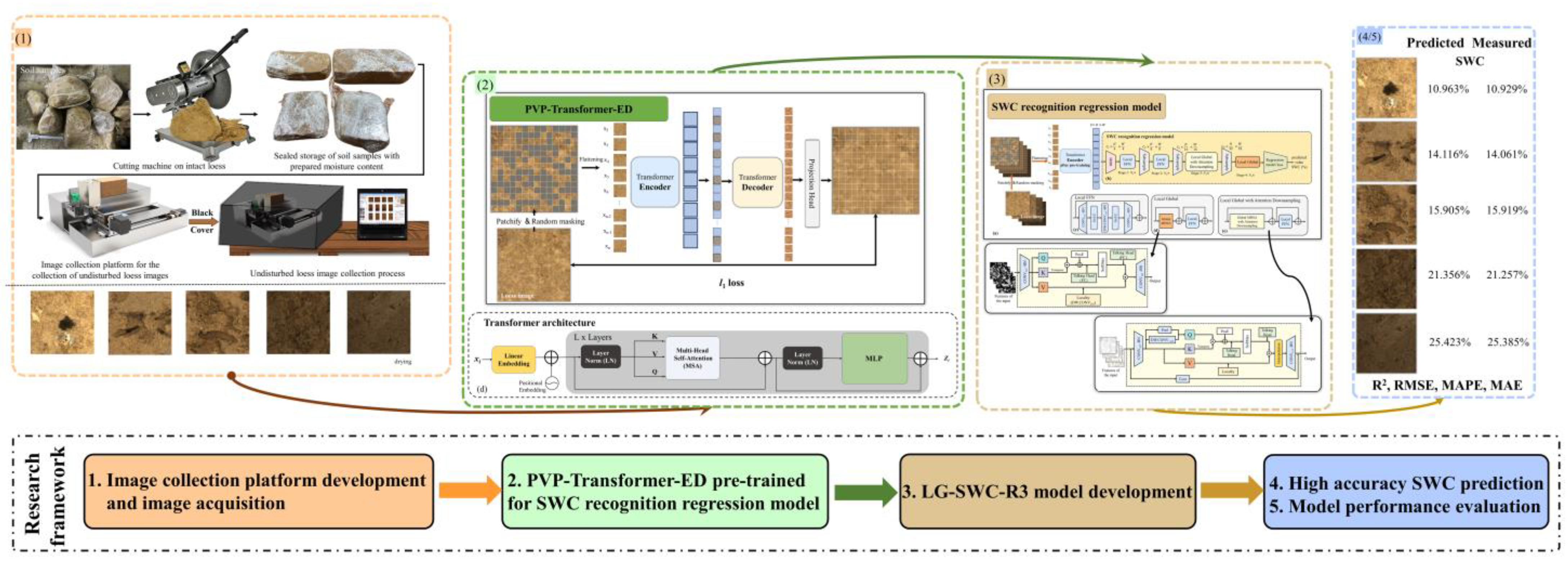
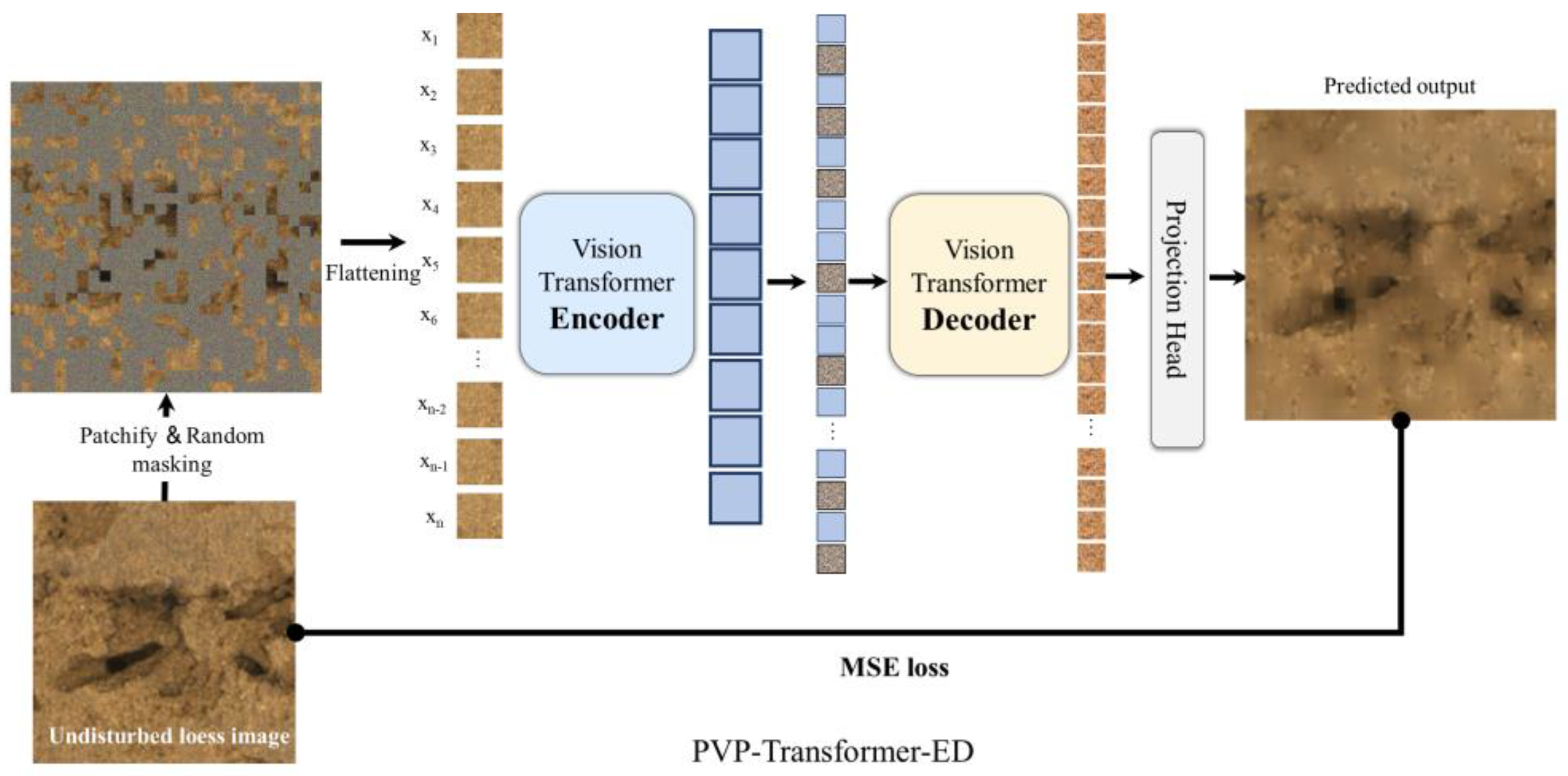
- To reduce the demand for computational resources, we designed the PVP-Transformer-ED from the perspective of reducing spatial redundancy in soil images. Its aim is to randomly mask patches from the input image, reconstruct missing patches in pixel space to learn more complex patterns and feature representations in soil images, and then fine-tune the pretrained PVP-Transformer-ED on the regression model. It enables the SWC model to identify SWC with minimal input patches, reducing the recognition time by 50% or more. Additionally, it helps reduce memory consumption, thus providing the potential to extend the PVP-Transformer-ED to more complex large models and enhance generalization.
- 2.
- We designed the LG-SWC-R3 model based on the concept of local information and global perception to effectively capture the intricate relationship between SWC and image features. Experimental results have demonstrated that this model outperforms the aforementioned SWC recognition models across different evaluation metrics.
- 3.
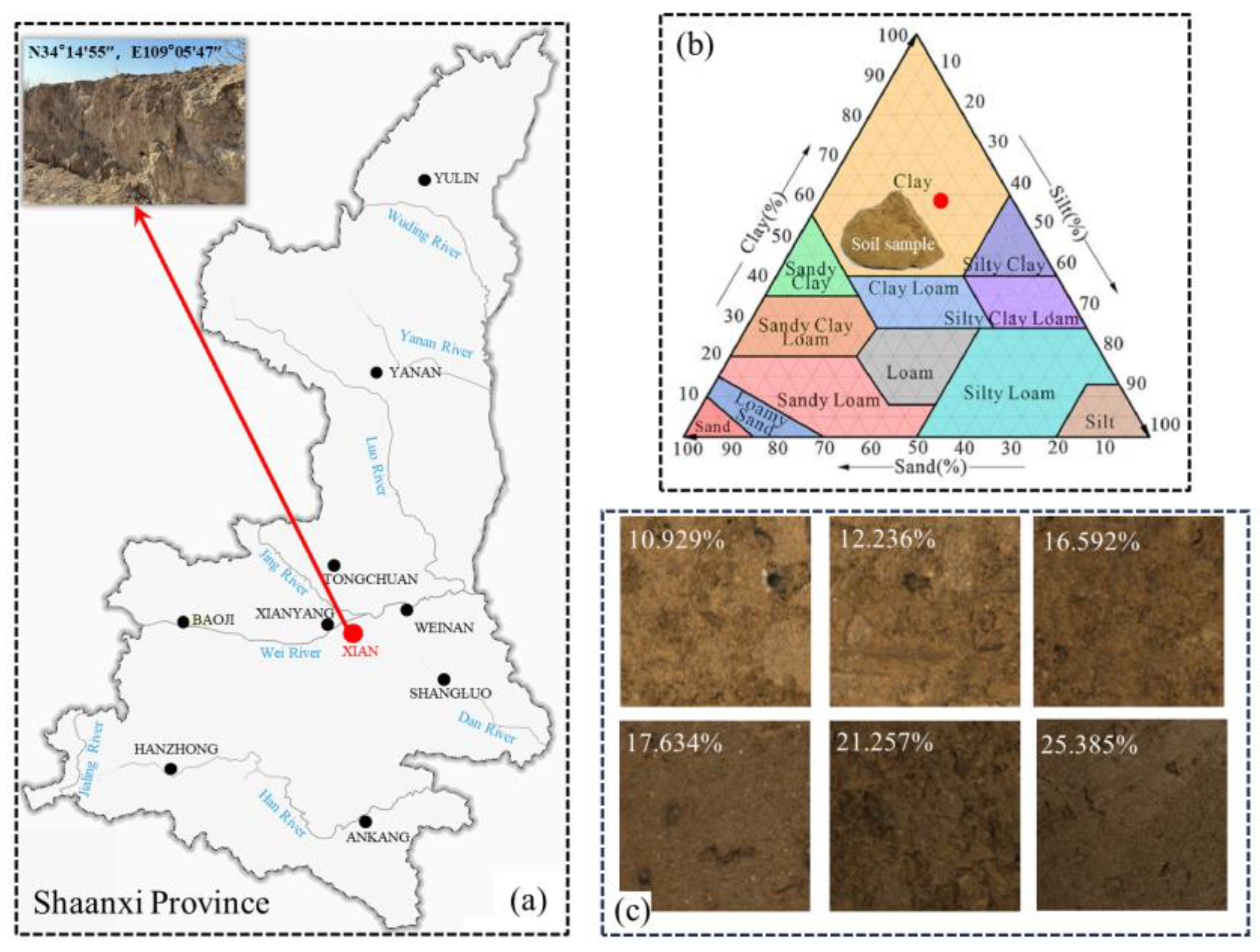
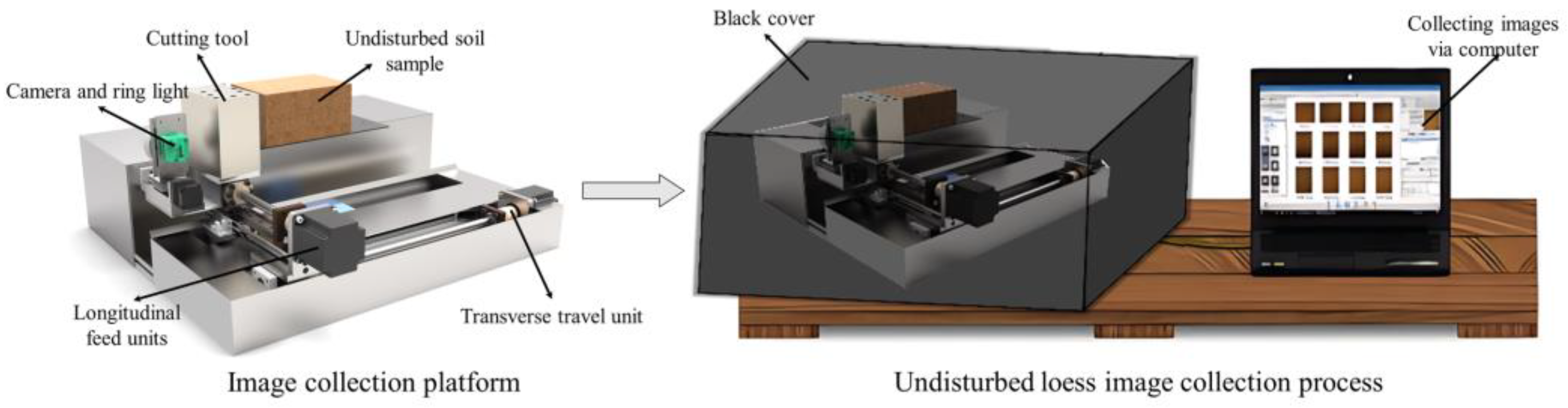
- We developed an automatic image acquisition platform for constructing the undisturbed loess dataset and established the Bailu highland soil dataset based on this platform. This hardware and dataset support pave the way for future research endeavors.
2. Materials and Methods
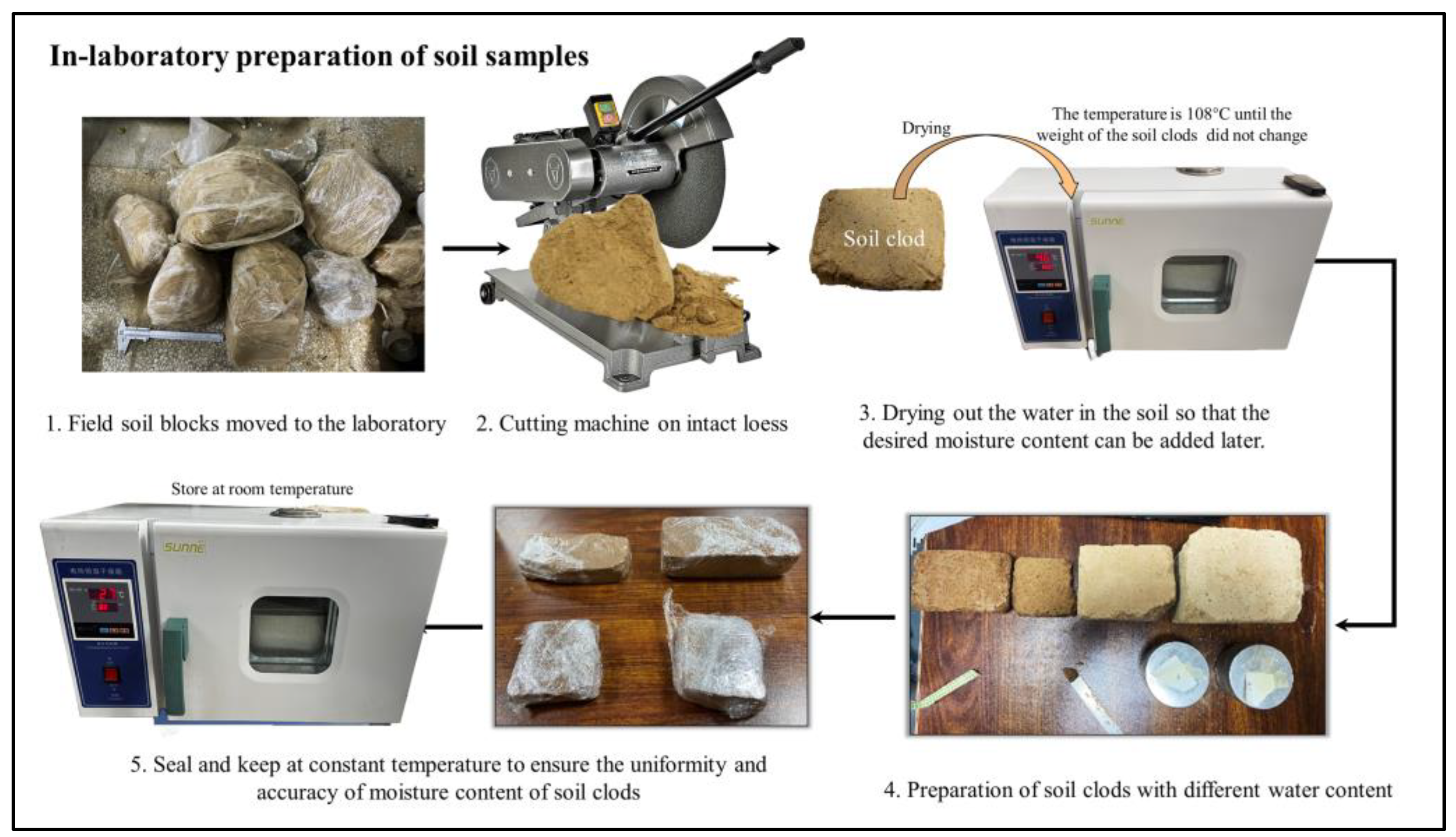
2.1. Soil Sampling and Preparation
2.2. Automatic Soil Image Collection Platform
2.3. PVP-Transformer-ED
2.3.1. Masking Strategies
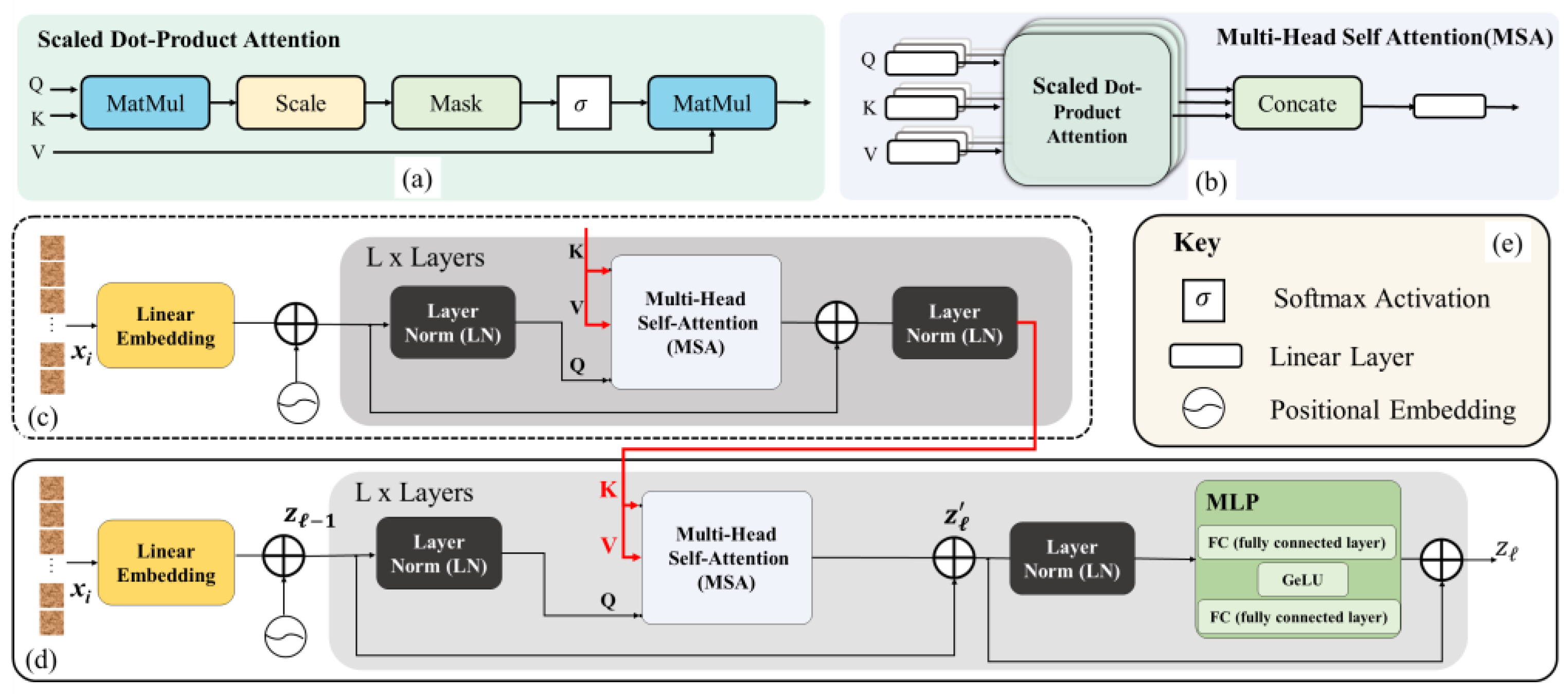
2.3.2. Encoder
2.3.3. Decoder
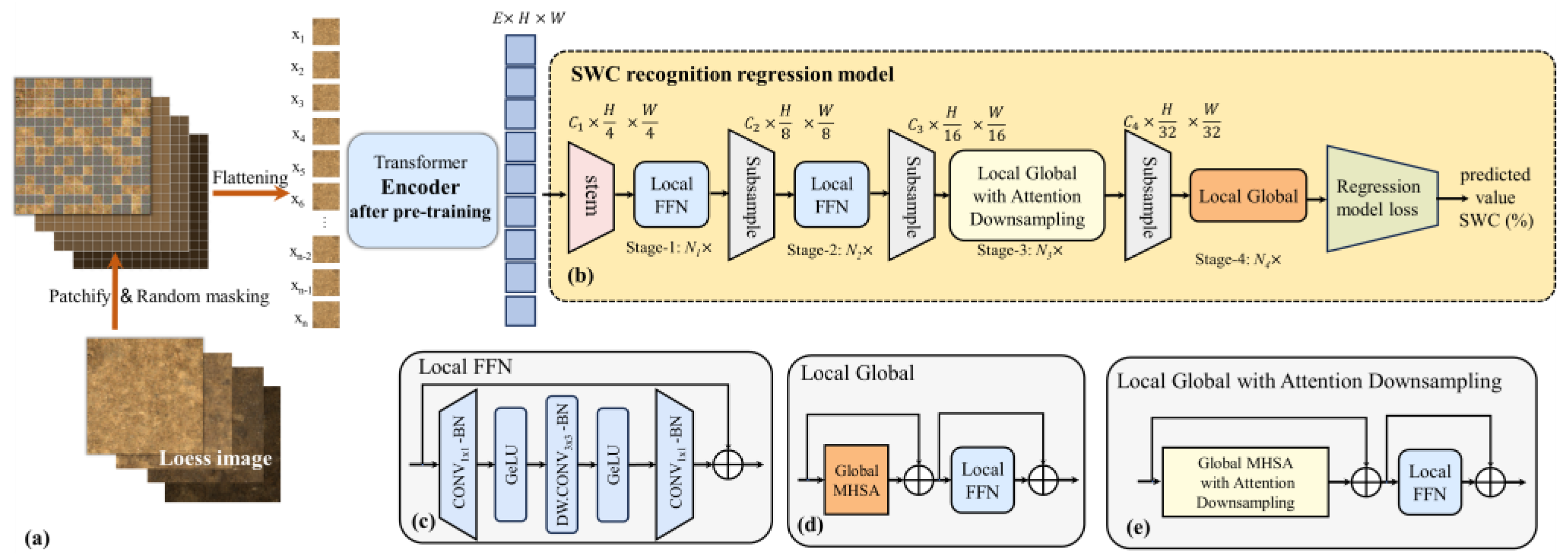
2.4. Local Global SWC Recognition Regression Model (LG-SWC-R3 Model)
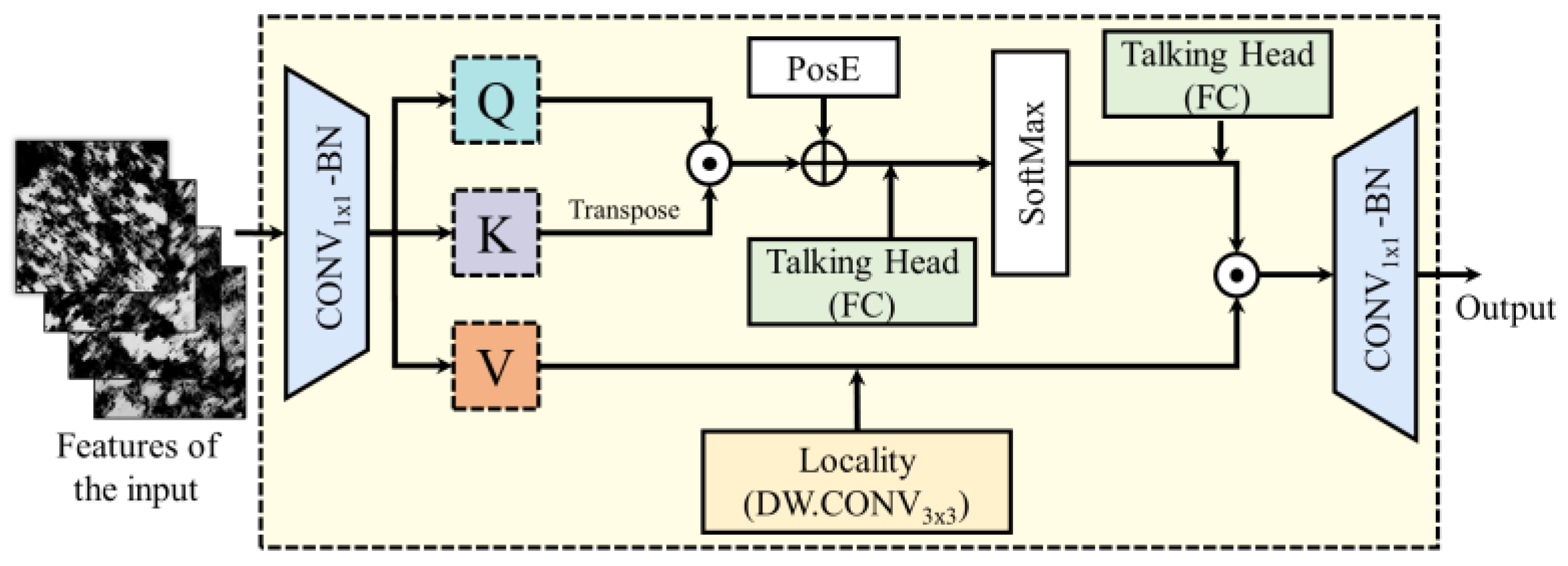
2.4.1. Global MHSA Block
2.4.2. Global MHSA Block with Global–Local Attention Downsampling Strategy
2.5. Model Performance Evaluation Metrics
2.6. Implementation Settings
3. Experimental Results and Discussion
3.1. Performance Comparison of Different Models
3.2. Performance Analysis of Different Models
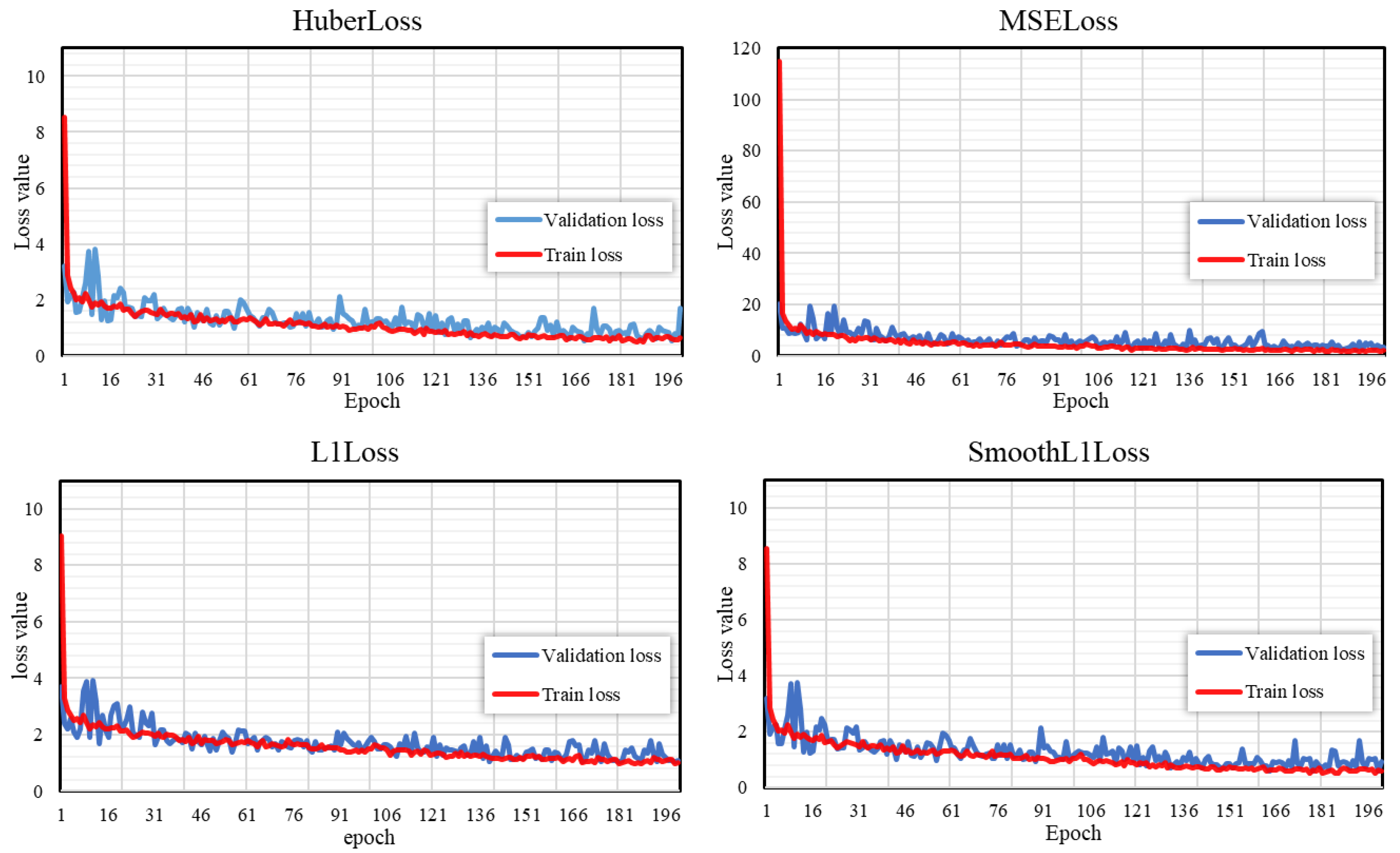
3.3. Comparison of Different Loss Functions
3.4. Stability Analysis of PVP-Transformer-ED
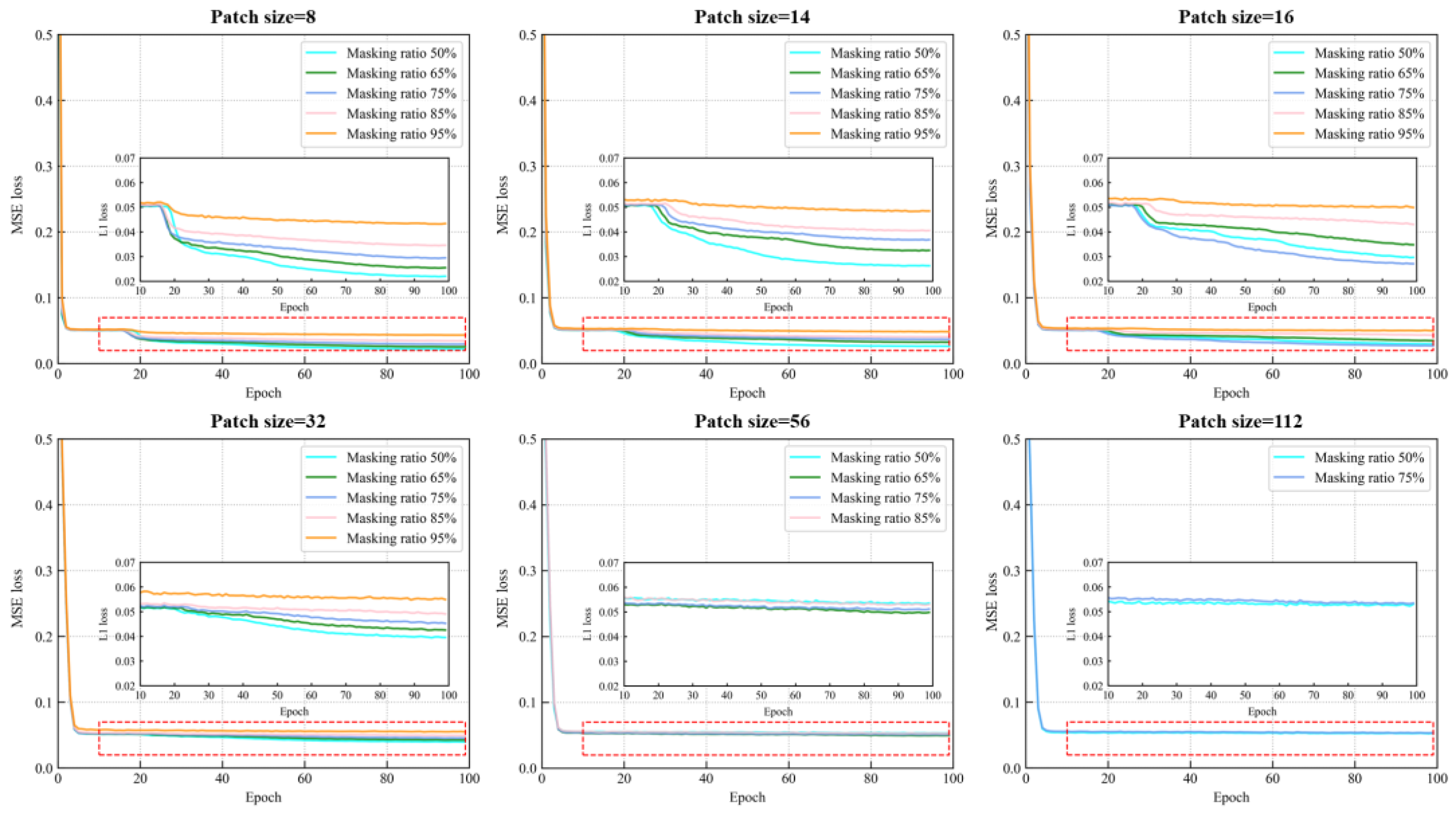
3.5. Masking Strategy
3.6. Visualization of PVP-Transformer-ED Restoration
3.7. Visualization and Analysis of the Iterative Process of PVP-Transformer-ED
4. Conclusions
- 1.
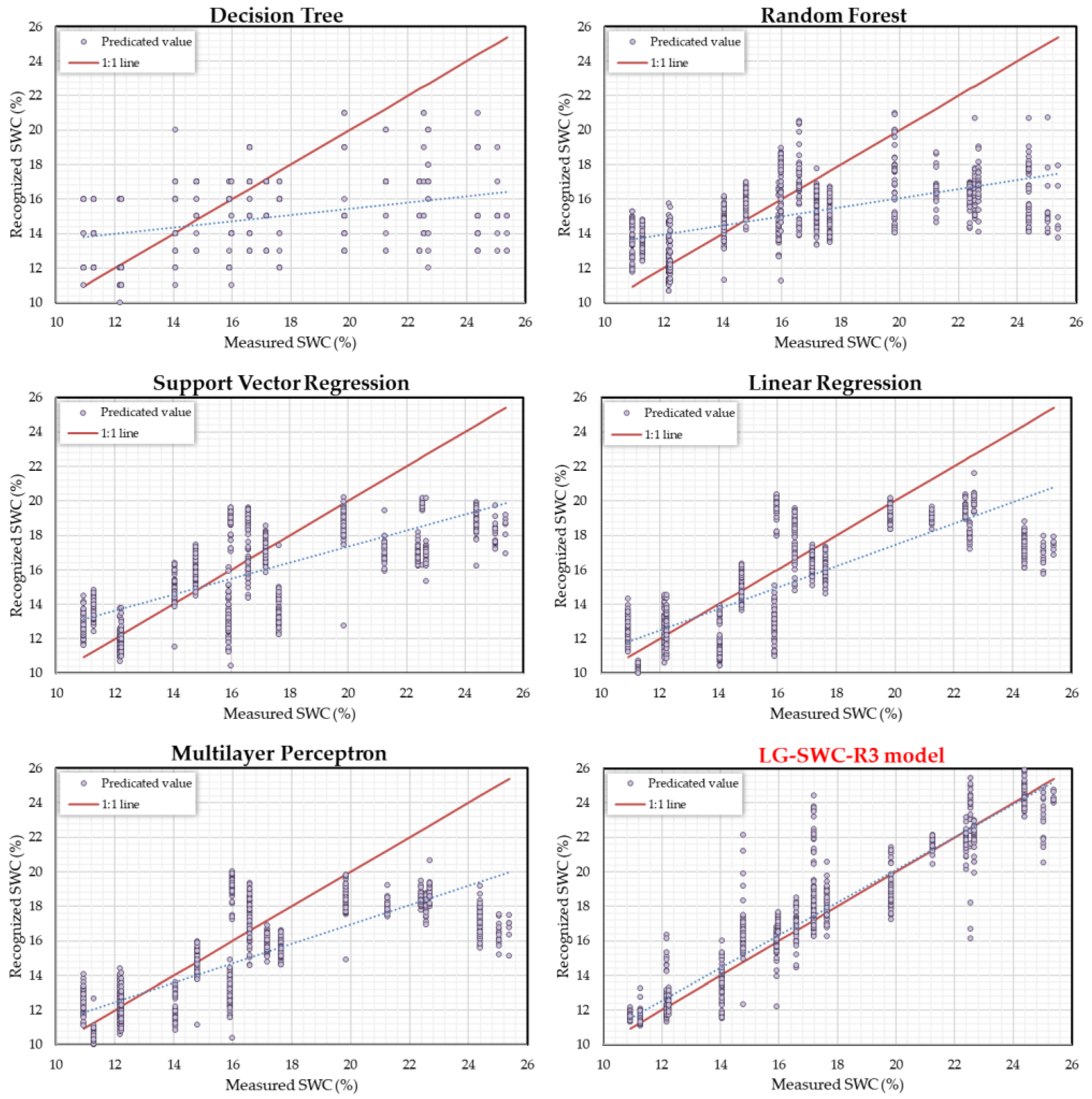
- Evaluation of various SWC models revealed significant constraints with traditional machine learning models and highlighted the superior stability and satisfactory accuracy of the LG-SWC-R3 model. Visualizing the scatter plots in Section 3.2 further elucidated the performance differences among the models. While all models effectively captured moisture content changes in soil images, Decision Tree and Random Forest exhibited notable deviations from actual values. Additionally, Support Vector Regression, Linear Regression, and Multilayer Perceptron displayed a tendency to underestimate images with the SWC exceeding 20%. In contrast, the LG-SWC-R3 model demonstrated robustness in identifying images with both high and low SWC levels.
- 2.
- Our pre-trained PVP-Transformer-ED can effectively restore the original soil image by predicting it from a limited number of unmasked patches. The core principle of PVP-Transformer-ED is its adeptness in computing and rectifying the relational attributes among input patches. In this regard, it operates by encoding a subset of randomly chosen patches to distill features and comprehend the image. This approach is suited for soil images, which typically possess heightened information redundancy owing to the pronounced local interconnections among pixels.
- 3.
- Restoring visible sparse patches as the input serves a dual purpose: it not only diminishes spatial redundancy and alleviates the pre-training computational burden but also compels the architecture to transcend mere dependence on low-level statistical image distributions. This, in turn, necessitates a deeper and genuine comprehension of the image content. Remarkably, variations in hyperparameters like patch size and masked ratio imbue the model with a more “imaginative” capacity, facilitating the recognition of nuanced changes in pore and crack size and location within soil images. This enhanced perceptiveness aids the encoder in acquiring more versatile and generalizable representations.
- 4.
- Fine-tuning the model after pre-training the PVP-Transformer-ED may slightly impact SWC recognition compared to recognizing the entire image. However, this impact remains within an acceptable range and offers substantial time and computational savings exceeding 50%. Such efficiency gains are particularly beneficial for applications in environments with limited computational resources and holds significant value for further deployment and utilization.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- White, R.E. Principles and Practice of Soil Science: The Soil as a Natural Resource; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Hossain, M.; Lamb, D.; Lockwood, P.; Frazier, P. EM38 for volumetric soil water content estimation in the root-zone of deep vertosol soils. Comput. Electron. Agric. 2010, 74, 100–109. [Google Scholar] [CrossRef]
- Dobriyal, P.; Qureshi, A.; Badola, R.; Hussain, S.A. A review of the methods available for estimating soil moisture and its implications for water resource management. J. Hydrol. 2012, 458, 110–117. [Google Scholar] [CrossRef]
- Chen, S.; Lou, F.; Tuo, Y.; Tan, S.; Peng, K.; Zhang, S.; Wang, Q. Prediction of Soil Water Content Based on Hyperspectral Reflectance Combined with Competitive Adaptive Reweighted Sampling and Random Frog Feature Extraction and the Back-Propagation Artificial Neural Network Method. Water 2023, 15, 2726. [Google Scholar] [CrossRef]
- Chakraborty, D.; Nagarajan, S.; Aggarwal, P.; Gupta, V.; Tomar, R.; Garg, R.; Sahoo, R.; Sarkar, A.; Chopra, U.K.; Sarma, K.S. Effect of mulching on soil and plant water status, and the growth and yield of wheat (Triticum aestivum L.) in a semi-arid environment. Agric. Water Manag. 2008, 95, 1323–1334. [Google Scholar] [CrossRef]
- Coppola, A.; Dragonetti, G.; Sengouga, A.; Lamaddalena, N.; Comegna, A.; Basile, A.; Noviello, N.; Nardella, L. Identifying optimal irrigation water needs at district scale by using a physically based agro-hydrological model. Water 2019, 11, 841. [Google Scholar] [CrossRef]
- Rahardjo, H.; Kim, Y.; Satyanaga, A. Role of unsaturated soil mechanics in geotechnical engineering. Int. J. Geo-Eng. 2019, 10, 8. [Google Scholar] [CrossRef]
- Gens, A. Soil–environment interactions in geotechnical engineering. Géotechnique 2010, 60, 3–74. [Google Scholar] [CrossRef]
- Al-Rawas, A.A. State-of-the-art-review of collapsible soils. Sultan Qaboos Univ. J. Sci. [SQUJS] 2000, 5, 115–135. [Google Scholar] [CrossRef]
- Negro, A., Jr.; Karlsrud, K.; Srithar, S.; Ervin, M.; Vorster, E. Prediction, monitoring and evaluation of performance of geotechnical structures. In Proceedings of the 17th International Conference on Soil Mechanics and Geotechnical Engineering (Volumes 1, 2, 3 and 4), Alexandria, Egypt, 5–9 October 2009; pp. 2930–3005. [Google Scholar]
- Marino, P.; Peres, D.J.; Cancelliere, A.; Greco, R.; Bogaard, T.A. Soil moisture information can improve shallow landslide forecasting using the hydrometeorological threshold approach. Landslides 2020, 17, 2041–2054. [Google Scholar] [CrossRef]
- Furtak, K.; Wolińska, A. The impact of extreme weather events as a consequence of climate change on the soil moisture and on the quality of the soil environment and agriculture—A review. Catena 2023, 231, 107378. [Google Scholar] [CrossRef]
- Liu, G.; Tian, S.; Xu, G.; Zhang, C.; Cai, M. Combination of effective color information and machine learning for rapid prediction of soil water content. J. Rock Mech. Geotech. Eng. 2023, 15, 2441–2457. [Google Scholar] [CrossRef]
- Walker, J.P.; Willgoose, G.R.; Kalma, J.D. In situ measurement of soil moisture: A comparison of techniques. J. Hydrol. 2004, 293, 85–99. [Google Scholar] [CrossRef]
- Yin, Z.; Lei, T.; Yan, Q.; Chen, Z.; Dong, Y. A near-infrared reflectance sensor for soil surface moisture measurement. Comput. Electron. Agric. 2013, 99, 101–107. [Google Scholar] [CrossRef]
- Su, S.L.; Singh, D.N.; Baghini, M.S. A critical review of soil moisture measurement. Measurement 2014, 54, 92–105. [Google Scholar] [CrossRef]
- Lakshmi, V. Remote sensing of soil moisture. Int. Sch. Res. Not. 2013, 2013, 424178. [Google Scholar] [CrossRef]
- Peng, J.; Shen, Z.; Zhang, W.; Song, W. Deep-Learning-Enhanced CT Image Analysis for Predicting Hydraulic Conductivity of Coarse-Grained Soils. Water 2023, 15, 2623. [Google Scholar] [CrossRef]
- Snapir, B.; Hobbs, S.; Waine, T. Roughness measurements over an agricultural soil surface with Structure from Motion. ISPRS J. Photogramm. Remote Sens. 2014, 96, 210–223. [Google Scholar] [CrossRef]
- Wang, D.; Si, Y.; Shu, Z.; Wu, A.; Wu, Y.; Li, Y. An image-based soil type classification method considering the impact of image acquisition distance factor. J. Soils Sediments 2023, 23, 2216–2233. [Google Scholar] [CrossRef]
- Swetha, R.; Bende, P.; Singh, K.; Gorthi, S.; Biswas, A.; Li, B.; Weindorf, D.C.; Chakraborty, S. Predicting soil texture from smartphone-captured digital images and an application. Geoderma 2020, 376, 114562. [Google Scholar] [CrossRef]
- Pires, L.F.; Cássaro, F.A.M.; Bacchi, O.O.S.; Reichardt, K. Non-destructive image analysis of soil surface porosity and bulk density dynamics. Radiat. Phys. Chem. 2011, 80, 561–566. [Google Scholar] [CrossRef]
- Shi, T.; Cui, L.; Wang, J.; Fei, T.; Chen, Y.; Wu, G. Comparison of multivariate methods for estimating soil total nitrogen with visible/near-infrared spectroscopy. Plant Soil 2013, 366, 363–375. [Google Scholar] [CrossRef]
- Meng, C.; Yang, W.; Bai, Y.; Li, H.; Zhang, H.; Li, M. Research of soil surface image occlusion removal and inpainting based on GAN used for estimation of farmland soil moisture content. Comput. Electron. Agric. 2023, 212, 108155. [Google Scholar] [CrossRef]
- Gadi, V.K.; Garg, A.; Manogaran, I.P.; Sekharan, S.; Zhu, H.-H. Understanding soil surface water content using light reflection theory: A novel color analysis technique considering variability in light intensity. J. Test. Eval. 2020, 48, 4053–4066. [Google Scholar] [CrossRef]
- Parera, F.; Pinyol, N.M.; Alonso, E.E. Massive, continuous, and non-invasive surface measurement of degree of saturation by shortwave infrared images. Can. Geotech. J. 2021, 58, 749–762. [Google Scholar] [CrossRef]
- Liu, W.; Baret, F.; Gu, X.; Tong, Q.; Zheng, L.; Zhang, B. Relating soil surface moisture to reflectance. Remote Sens. Environ. 2002, 81, 238–246. [Google Scholar] [CrossRef]
- Maltese, A.; Minacapilli, M.; Cammalleri, C.; Ciraolo, G.; D’Asaro, F. A thermal inertia model for soil water content retrieval using thermal and multispectral images. In Proceedings of the Remote Sensing for Agriculture, Ecosystems, and Hydrology XII, Toulouse, France, 22 October 2010; pp. 273–280. [Google Scholar]
- Zanetti, S.S.; Cecilio, R.A.; Alves, E.G.; Silva, V.H.; Sousa, E.F. Estimation of the moisture content of tropical soils using colour images and artificial neural networks. Catena 2015, 135, 100–106. [Google Scholar] [CrossRef]
- Persson, M. Estimating surface soil moisture from soil color using image analysis. Vadose Zone J. 2005, 4, 1119–1122. [Google Scholar] [CrossRef]
- Dos Santos, J.F.; Silva, H.R.; Pinto, F.A.; Assis, I.R.D. Use of digital images to estimate soil moisture. Rev. Bras. Eng. Agrícola Ambient. 2016, 20, 1051–1056. [Google Scholar] [CrossRef]
- Taneja, P.; Vasava, H.B.; Fathololoumi, S.; Daggupati, P.; Biswas, A. Predicting soil organic matter and soil moisture content from digital camera images: Comparison of regression and machine learning approaches. Can. J. Soil Sci. 2022, 102, 767–784. [Google Scholar] [CrossRef]
- Kim, D.; Kim, T.; Jeon, J.; Son, Y. Convolutional Neural Network-Based Soil Water Content and Density Prediction Model for Agricultural Land Using Soil Surface Images. Appl. Sci. 2023, 13, 2936. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, Y.; Shao, M. Using soil surface gray level to determine surface soil water content. Sci. China Earth Sci. 2010, 53, 1527–1532. [Google Scholar] [CrossRef]
- Hosseini, R.; Sinz, F.; Bethge, M. Lower bounds on the redundancy of natural images. Vis. Res. 2010, 50, 2213–2222. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Bruzzone, L.; Zhao, H.; Tan, Y.; Guan, R. Superpixel-based unsupervised band selection for classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7230–7245. [Google Scholar] [CrossRef]
- Peng, J.; Wang, Q.; Zhuang, J.; Leng, Y.; Fan, Z.; Wang, S. Triggered factors and motion simulation of “9-17” baqiao catastrophic landslide. J. Eng. Geol. 2015, 23, 747–754. [Google Scholar] [CrossRef]
- Moreno-Maroto, J.M.; Alonso-Azcarate, J. Evaluation of the USDA soil texture triangle through Atterberg limits and an alternative classification system. Appl. Clay Sci. 2022, 229, 106689. [Google Scholar] [CrossRef]
- Fao, W. World reference base for soil resources. International soil classification system for naming soils and creating legends for soil maps. World Soil Resour. Rep. 2014, 106, 12–21. [Google Scholar]
- Hajjar, C.S.; Hajjar, C.; Esta, M.; Chamoun, Y.G. Machine learning methods for soil moisture prediction in vineyards using digital images. In Proceedings of the E3S Web of Conferences, Tallinn, Estonia, 6–9 September 2020; p. 02004. [Google Scholar]
- Xu, J.J.; Zhang, H.; Tang, C.S.; Cheng, Q.; Tian, B.G.; Liu, B.; Shi, B. Automatic soil crack recognition under uneven illumination condition with the application of artificial intelligence. Eng. Geol. 2022, 296, 106495. [Google Scholar] [CrossRef]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9653–9663. [Google Scholar]
- Li, Y.; Hu, J.; Wen, Y.; Evangelidis, G.; Salahi, K.; Wang, Y.; Tulyakov, S.; Ren, J. Rethinking vision transformers for mobilenet size and speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 16889–16900. [Google Scholar]
- Cai, H.; Gan, C.; Han, S. Efficientvit: Enhanced linear attention for high-resolution low-computation visual recognition. arXiv 2022, arXiv:2205.14756. [Google Scholar] [CrossRef]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, J.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. Efficientformer: Vision transformers at mobilenet speed. Adv. Neural Inf. Process. Syst. 2022, 35, 12934–12949. [Google Scholar] [CrossRef]
- Gong, C.; Wang, D.; Li, M.; Chen, X.; Yan, Z.; Tian, Y.; Chandra, V. Nasvit: Neural architecture search for efficient vision transformers with gradient conflict aware supernet training. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Voita, E.; Talbot, D.; Moiseev, F.; Sennrich, R.; Titov, I. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv 2019, arXiv:1905.09418. [Google Scholar] [CrossRef]
- Shazeer, N.; Lan, Z.; Cheng, Y.; Ding, N.; Hou, L. Talking-heads attention. arXiv 2020, arXiv:2003.02436. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. Levit: A vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2021; pp. 12259–12269. [Google Scholar]
- Liu, J.; Huang, X.; Song, G.; Li, H.; Liu, Y. Uninet: Unified architecture search with convolution, transformer, and mlp. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 33–49. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sakti, M.; Ariyanto, D. Estimating soil moisture content using red-green-blue imagery from digital camera. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Langkawi, Malaysia, 4–5 December 2018; p. 012004. [Google Scholar]
- Taneja, P.; Vasava, H.K.; Daggupati, P.; Biswas, A. Multi-algorithm comparison to predict soil organic matter and soil moisture content from cell phone images. Geoderma 2021, 385, 114863. [Google Scholar] [CrossRef]
- Aitkenhead, M.J.; Poggio, L.; Wardell-Johnson, D.; Coull, M.C.; Rivington, M.; Black, H.; Yacob, G.; Boke, S.; Habte, M. Estimating soil properties from smartphone imagery in Ethiopia. Comput. Electron. Agric. 2020, 171, 105322. [Google Scholar] [CrossRef]
- Döpper, V.; Rocha, A.D.; Berger, K.; Gränzig, T.; Verrelst, J.; Kleinschmit, B.; Förster, M. Estimating soil moisture content under grassland with hyperspectral data using radiative transfer modelling and machine learning. Int. J. Appl. Earth Obs. Geoinf. 2022, 110, 102817. [Google Scholar] [CrossRef]
- Yu, J.; Tang, S.; Li, Z.; Zheng, W.; Wang, L.; Wong, A.; Xu, L. A deep learning approach for multi-depth soil water content prediction in summer maize growth period. IEEE Access 2020, 8, 199097–199110. [Google Scholar] [CrossRef]
- Hossain, M.R.H.; Kabir, M.A. Machine Learning Techniques for Estimating Soil Moisture from Smartphone Captured Images. Agriculture 2023, 13, 574. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Fang, L.; Zhan, X.; Yin, J.; Liu, J.; Schull, M.; Walker, J.P.; Wen, J.; Cosh, M.H.; Lakhankar, T.; Collins, C.H. An intercomparison study of algorithms for downscaling SMAP radiometer soil moisture retrievals. J. Hydrometeorol. 2020, 21, 1761–1775. [Google Scholar] [CrossRef]
- GB/T 50123-2019; China national standards: Standard for geotechnical testing method. Standardization Administration of China, Ministry of Water Resources, China Planning Press: Beijing, China, 2019. (In Chinese)
- Han, X.; Papyan, V.; Donoho, D.L. Neural collapse under mse loss: Proximity to and dynamics on the central path. arXiv 2021, arXiv:2106.02073. [Google Scholar] [CrossRef]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A comprehensive survey of loss functions in machine learning. Ann. Data Sci. 2020, 9, 5500. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Sites | Soil Texture | Soil Type | Sand (%) | Slit (%) | Clay (%) | Organic Carbon (OC) (g·kg−1) | Nitrogen (N) (g·kg−1) | Phosphorous (P) (g·kg−1) |
|---|---|---|---|---|---|---|---|---|
| Bailu highland | Clay | Calcisols | 11.7 | 30.6 | 57.7 | 9.3 | 1.7 | 0.6 |
| SWC Recognition Model | R2 | RMSE (%) | MAPE | MAE (%) |
|---|---|---|---|---|
| Decision Tree [31] | 0.352 | 4.201 | 0.206 | 3.020 |
| Random Forest [66] | 0.559 | 3.657 | 0.156 | 2.745 |
| Support Vector Regression [63] | 0.717 | 2.968 | 0.141 | 2.379 |
| Linear Regression [40] | 0.769 | 2.882 | 0.127 | 2.169 |
| Multilayer Perceptron [29] | 0.770 | 3.004 | 0.126 | 2.243 |
| LG-SWC-R3 model | 0.950 | 1.351 | 0.054 | 0.886 |
| Loss Function | R2 | RMSE (%) | MAPE | MAE (%) |
|---|---|---|---|---|
| HuberLoss | 0.949 | 1.382 | 0.052 | 0.847 |
| L1Loss | 0.953 | 1.261 | 0.049 | 0.820 |
| MSELoss | 0.932 | 1.563 | 0.064 | 1.034 |
| SmoothL1Loss | 0.950 | 1.351 | 0.054 | 0.886 |
| Model | Masked Patch Size | Masking Ration | R2 | RMSE | MAPE | MAE |
|---|---|---|---|---|---|---|
| Baseline | × | × | 0.950 | 1.351 | 0.054 | 0.886 |
| 8 | 0.5 | 0.942 | 1.409 | 0.050 | 0.838 | |
| 0.65 | 0.917 | 1.588 | 0.067 | 1.042 | ||
| 0.75 | 0.903 | 1.784 | 0.062 | 1.029 | ||
| 0.85 | 0.922 | 1.745 | 0.071 | 1.123 | ||
| 0.95 | 0.832 | 2.302 | 0.092 | 1.546 | ||
| 14 | 0.5 | 0.927 | 1.571 | 0.058 | 0.961 | |
| 0.65 | 0.922 | 1.605 | 0.059 | 1.013 | ||
| 0.75 | 0.896 | 1.840 | 0.066 | 1.138 | ||
| 0.85 | 0.912 | 1.841 | 0.078 | 1.262 | ||
| 0.95 | 0.862 | 2.104 | 0.086 | 1.413 | ||
| 16 | 0.5 | 0.930 | 1.540 | 0.061 | 0.987 | |
| 0.65 | 0.929 | 1.558 | 0.059 | 0.983 | ||
| PVP-Transformer-ED | 0.75 | 0.938 | 1.543 | 0.062 | 1.002 | |
| 0.85 | 0.896 | 1.848 | 0.063 | 1.109 | ||
| 0.95 | 0.876 | 2.045 | 0.081 | 1.377 | ||
| 32 | 0.5 | 0.925 | 1.578 | 0.056 | 0.944 | |
| 0.65 | 0.913 | 1.725 | 0.062 | 1.081 | ||
| 0.75 | 0.900 | 1.819 | 0.064 | 1.115 | ||
| 0.85 | 0.855 | 2.185 | 0.072 | 1.261 | ||
| 0.95 | 0.839 | 2.249 | 0.093 | 1.535 | ||
| 56 | 0.5 | 0.931 | 1.577 | 0.057 | 0.916 | |
| 0.65 | 0.909 | 1.745 | 0.062 | 1.026 | ||
| 0.75 | 0.890 | 1.936 | 0.071 | 1.164 | ||
| 0.85 | 0.882 | 1.969 | 0.076 | 1.294 | ||
| 112 | 0.5 | 0.931 | 1.555 | 0.061 | 0.982 | |
| 0.75 | 0.884 | 1.934 | 0.072 | 1.216 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhang, H.; Lan, H.; Li, Y.; Liu, H.; Sun, D.; Wang, E.; Dong, Z. Advancing Digital Image-Based Recognition of Soil Water Content: A Case Study in Bailu Highland, Shaanxi Province, China. Water 2024, 16, 1133. https://doi.org/10.3390/w16081133
Zhang Y, Zhang H, Lan H, Li Y, Liu H, Sun D, Wang E, Dong Z. Advancing Digital Image-Based Recognition of Soil Water Content: A Case Study in Bailu Highland, Shaanxi Province, China. Water. 2024; 16(8):1133. https://doi.org/10.3390/w16081133
Chicago/Turabian StyleZhang, Yaozhong, Han Zhang, Hengxing Lan, Yunchuang Li, Honggang Liu, Dexin Sun, Erhao Wang, and Zhonghong Dong. 2024. "Advancing Digital Image-Based Recognition of Soil Water Content: A Case Study in Bailu Highland, Shaanxi Province, China" Water 16, no. 8: 1133. https://doi.org/10.3390/w16081133
APA StyleZhang, Y., Zhang, H., Lan, H., Li, Y., Liu, H., Sun, D., Wang, E., & Dong, Z. (2024). Advancing Digital Image-Based Recognition of Soil Water Content: A Case Study in Bailu Highland, Shaanxi Province, China. Water, 16(8), 1133. https://doi.org/10.3390/w16081133