1. Introduction
As an important part of the national infrastructure, the water conservancy project is vital to the sustainable development of agricultural production, urban water supply, ecological environment protection, and other fields. The water conservancy dam is a crucial structure in water conservancy projects, and its safety is directly related to the national economic construction, improvements in the lives of the people, and the protection of the ecological environment. In recent years, with the rapid development of national water conservancies, higher requirements have been put forward for dam quality monitoring. In rockfill material dam projects, the construction quality of the rockfill material for dam building is the most important aspect of the overall dam quality control. The quality of the rockfill material in dams directly affects the safety of the construction and operation of the project, and it is crucial to the long-term development of water conservancy. The main factor affecting the quality of rockfill material dams is the compaction quality, and the main control index of compaction quality is the density of the rockfill material. Therefore, an appropriate scientific method to study and control the density of rockfill material is needed. For rockfill material dams, the main indicators of dam construction quality include density, particle gradation, and permeability characteristics. The focus in the current construction is to monitor these data quickly and accurately by developing effective methods. It is crucial to monitor these data to control the compaction quality and the safety of the dam. Therefore, in the field of water conservancy engineering, the continuous improvement of the methods for monitoring the quality of dam construction, effective control, and the monitoring of dam quality indicators through scientific methods are important ensure the safe operation of water conservancy projects.
In the past, permeability characteristic and permeability coefficient studies of dams were mainly carried out in laboratories or in the field. The field tests mainly included the trail pit seepage test and drilling grouting test, while the laboratory tests mainly included the constant head permeability test and the model seepage test. However, field tests have some disadvantages, such as their time-consuming processes, small monitoring range, and low monitoring efficiency. For their part, laboratory tests also have certain limitations. The actual working conditions may not be accurately reflected and the permeability coefficient data might not be obtained promptly [
1]. Some scholars have proposed empirical formulae for estimating the permeability coefficient, including the Terzaghi [
2] formula:
and Kozeny’s formula:
where
e is the pore ratio,
n is the porosity, and
dm is the effective particle size of each corresponding formula.
However, the use of empirical formulae to estimate the permeability coefficients of rockfill materials is often inconsistent with the actual situation because these empirical formulae cannot comprehensively take into account the influence of various factors. , Thus, empirical formulae have a limited scope of application [
3]. The coefficient of permeability of coarse-grained soil is affected by many factors, such as the dry density [
4], particle shape [
5,
6], fine content [
7,
8], coefficient of uniformity [
9,
10], and pore ratio [
11,
12]. Chapuis [
13] proposed a new equation to predict the saturated hydraulic conductivity of sand and gravel using the effective diameter and void ratio, finding that the new equation predictions were usually between 0.5 and 2.0 times the measured value for the considered data using the values of
d10 and
e. Koohmishi [
14] conducted a laboratory test on a coarse aggregate to evaluate the effect of gradation and compaction on permeability and found that gradation is the property that most affects permeability. Dolzyk et al. [
15] proposed a relationship between the void ratio, the coefficient of uniformity, and the effective size and the coefficient of permeability.
Due to the development of artificial intelligence, some scholars began to use artificial neural network methods to predict the permeability coefficient [
16,
17,
18,
19]. Yilmaz et al. [
20] predicted the permeability coefficients of coarse-grained soils by using neural networks and compared and analyzed different prediction models, which provided a new methodology and approach for obtaining the permeability coefficients of soils. Zhang et al. [
21] developed a predictive equation of the permeability characteristics of soil using gene expression programming (GEP) and conducted a sensitivity analysis, including the effective size (
d10), mean grain size (
d50), and void ratio (
e). Al Khalifah et al. [
22] used two machine learning techniques to predict the permeability of carbonate rock and compared them with seven conventional methods, finding that machine learning performed better than all the conventional empirical methods, especially neural networks.
The factors influencing the permeability coefficient are complex in rockfill material. The neural network model has more input parameters, and less research has been conducted on predicting permeability coefficients with convolutional neural network (CNN) models. In recent years, with the development of machine learning technology, CNNs have gradually received increasing attention. With their special architecture and powerful feature analysis and processing ability, CNNs can more easily handle multi-dimensional data, such as the particle gradation and permeability coefficient, in the field of rockfill materials, and they extract the features of these materials for fitting predictions to improve the accuracy. Therefore, in this paper, a CNN was used to build a machine learning model, and a BP neural network was also built to make contrastive analysis. In addition, the applicability of the CNN in the prediction of the permeability coefficient of rockfill material was verified through a laboratory permeability test.
2. CNN Predictive Models
CNNs are well known for their excellent feature extraction capabilities in image processing, but they are equally suitable for processing other types of data, including one-dimensional data. Even though our data are one-dimensional, there are still local correlations and structural features. CNNs are able to capture these features efficiently and are effective tools for working with one-dimensional sequential data. CNNs are able to extract important local patterns and global structure from the data, which makes the model’s representation of the data more efficient and accurate.
2.1. Basic Principle of Convolutional Neural Network
The CNN is a kind of deep feed-forward neural network with local connection, weight sharing, and other characteristics. As one of the representative algorithms of machine learning, it is good at dealing with images, especially image recognition and other related machine learning problems, and it can also be used in data regression prediction. CNNs have representational learning capabilities and are able to classify input information according to its hierarchical structure in a translation-invariant way, allowing both supervised and unsupervised learning [
23]. Compared with traditional neural networks, CNNs have the following advantages. They can automatically learn the features in the data instead of designing the features manually, which makes them more efficient and flexible in dealing with large-scale data. In addition, CNNs can capture local features in data and extract more abstract and important features through pooling operations. Moreover, CNNs can construct deep networks by stacking multiple convolutional and fully connected layers to further improve performance.
2.2. CNN-Model Structure
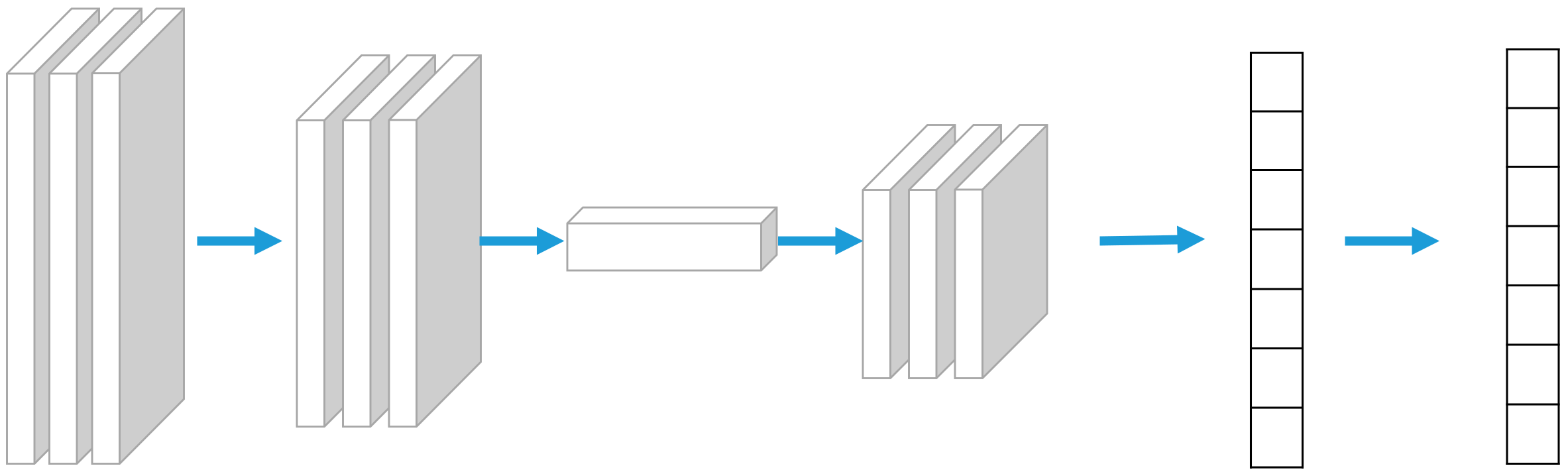
The CNN is divided into a 3-layer structure: input layer, hidden layer, and output layer. The input layer is responsible for importing data. The hidden layer includes convolutional layer, pooling layer, and fully connected layer. The convolutional layer uses convolutional operations to extract features from the input data. It consists of multiple convolution kernels and each convolution kernel detects features of the input data, such as edges and texture. The convolution operation is computed on the input data by sliding filters to generate a feature map as input to the next layer. The pooling layer is responsible for down-sampling the feature map output from the convolutional layer to reduce the computation by retaining the maximum and average values in the region. The pooling layer helps to reduce the size of the feature map while retaining the key features. The fully connected layer is usually located at the end of the network and its nodes are connected to all the nodes in the previous layer. The fully connected layer transforms the features extracted from the pooling layer into the final output by combining and learning the features and producing the final output. The output layer is responsible for receiving signals from the fully connected layer and generating the output predicted by the model [
24]. Therefore, to make the model fit the dataset better and improve the prediction accuracy, the convolutional layer–pooling layer–convolutional layer structure is designed so that the model is convolved once, pooled, and then convolved again to make the model obtain more features for fitting learning. The structure is shown in
Figure 1.
2.3. Model Construction
For the permeability-coefficient-prediction task, the input data are a one-dimensional array containing permeability-related features, including gradation, inhomogeneity coefficients, pore ratios, and curvature coefficients, as well as the permeability coefficient. In this paper, MATLAB-R2022a is used to construct a CNN [
25]. The specific steps are as follows:
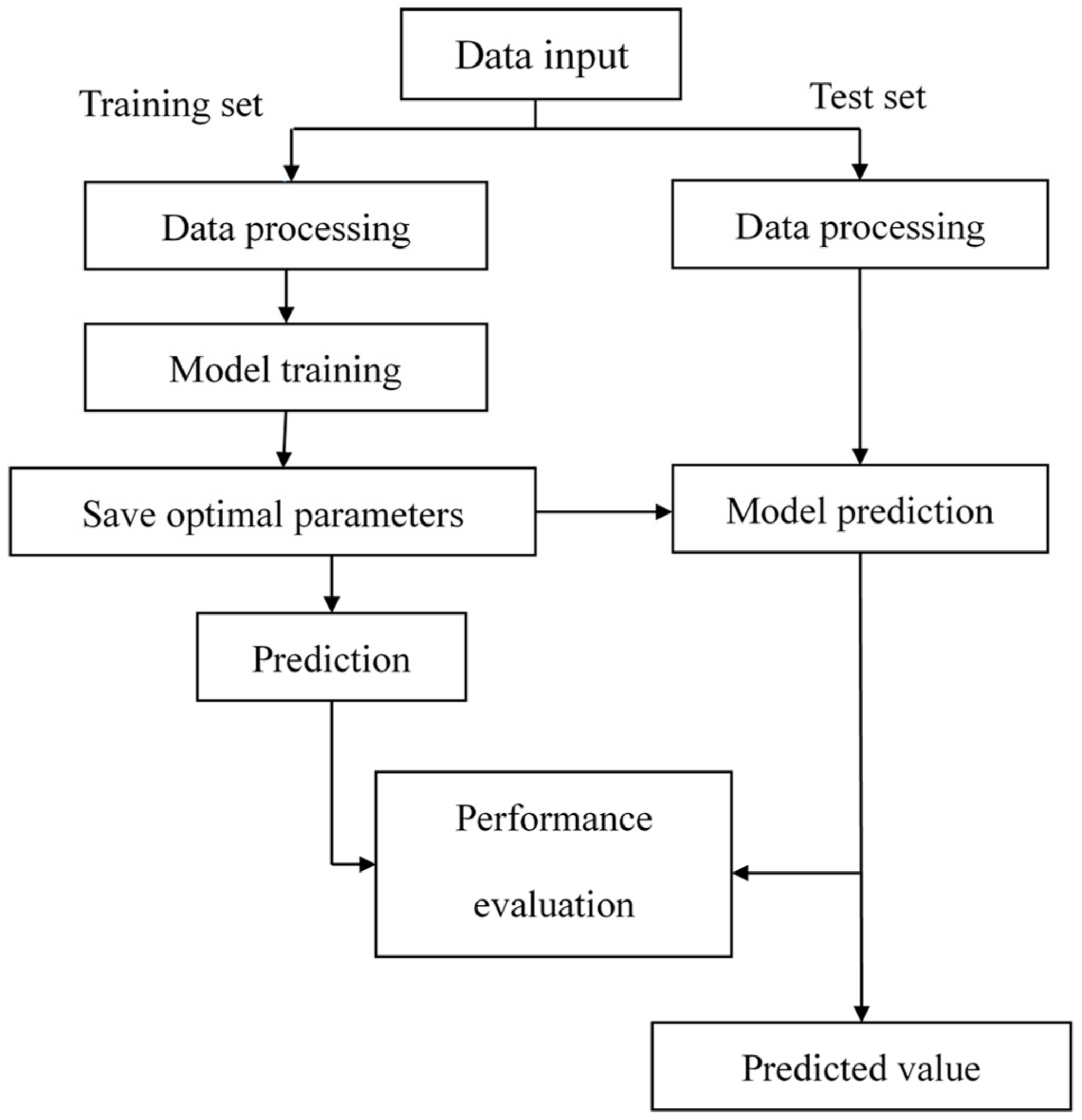
(1) Data input. The dataset was imported in the form of an Excel table and divided into the training set and test set.
(2) Data preprocessing. To ensure that the dataset allows the model to identify and learn features, it is necessary to preprocess the input data, and the specific steps include normalization and data tiling. Normalization is used to change all the data to the (0, 1) interval, using the function
mapminmax. Data tiling is used because the CNN is mainly used for image processing; the images are generally in three dimensions, and they need to be converted to one dimension to ensure that the dimensionality of the data and the dimensionality of the input layer of the model are consistent. The following is the
mapminmax function:
where
is the original data,
and
are the minimum and maximum values of the original data, respectively,
and
are the minimum and maximum values of the target range, respectively, and
is the normalized data.
(3) The network structure construction, building convolutional, pooling, and fully connected layers. First, the neural network’s input layer is created using the
imageInputLayer function, and the input-data dimension is set to [13, 1, 1], which corresponds to
d10~
d100,
e,
Cu, and
Cc, respectively. Next, the convolution layer is constructed using the
Convolution2D function, and the size of the convolution kernel is 3 × 1. The pooling layer is constructed by the
MaxPooling2D function, setting the pooling window to [2, 1] and the step size to [1, 1]. After the pooling layer, the same convolutional layer with the same convolutional kernel is set, and the size of feature map is adjusted to 32. The
Dropout function is used to introduce the regularization technique, and the parameter size of the
L2Regularization function is set to 0.01, in order to reduce the risk of overfitting and the effect of multicollinearity of the input features. Finally, the
fullyConnectedLayer and
Regression functions are used to construct the fully connected layer and the regression layer, respectively. The
Activation function between layers uses the
ReLU function to improve the nonlinear fitting ability of the model in the following form:
(4) Model training hyperparameter settings. Suitable parameters would allow better model fitting, less training time, and better prediction accuracy. The maximum number of model training is set to 1200. The number of samples per training is 30. The initial learning rate is 0.01, and the learning rate’s decrease factor is 0.5. The
SGDM function is chosen as the optimization function, which serves to minimize the loss function by calculating the gradient of each parameter and updating the parameters using momentum, which can help the neural network to converge to the optimal solution more quickly while reducing the oscillations when the parameters are updated. Its expression function is as follows:
where
and
are the model parameters before and after updating, respectively,
is the parameter gradient,
is the learning rate,
and
are the momentum before and after updating, respectively, and
is the momentum parameter, which takes a value between 0 and 1.
(5) Data output. In the permeability coefficient prediction task, the output is a continuous value that represents the predicted result of the permeability coefficient. Since the permeability coefficient of the input dataset is a value that has already been processed in the data preprocessing, the output can be directly used for the estimation of the permeability coefficient. In the subsequent prediction process, we only need to input the relevant parameters to obtain the predicted value of the permeability coefficient.
The CNN prediction model flowchart is shown in
Figure 2.
3. Data Acquisition and Processing
There are some factors that affect the permeability coefficient significantly, including the gradation, pore ratio, coefficient of uniformity, and coefficient of curvature. For rockfill material, the size and distribution of particles may directly affect the velocity of the permeability of water. Gradation reflects the particle distribution of the rockfill material. The coefficient of uniformity measures the degree of dispersion in the particle size of the rockfill material. The highly inhomogeneous stones create larger penetration paths, which affect permeability. The coefficient of curvature characterizes the shapes of the particles. The pore ratio reflects the volume of pores in the soil, which relates to the water-flow area of the rockfill material and also affects permeability.
Some scholars, through experimental research, put forward their own empirical formulae to predict the coefficient of permeability of soil, such as Hazen’s formula,
, and Sauerbrey’s [
26] formula,
, as well as Terzaghi’s formula and Kozeny’s formula, mentioned above, through which it can be concluded that the coefficient of permeability is a function of the parameters of the particle gradation, porosity, pore ratio, and so on, and it is possible to estimate the coefficient of permeability from these parameters. It can be concluded that the above parameters have a greater influence on the permeability coefficient and play a major controlling role in the prediction of the permeability coefficient. At the same time, the above parameters are easy to measure and obtain, which satisfies the purpose of the non-destructive and rapid measurement of the permeability coefficients of heap stone materials proposed in this paper.
Therefore, the neural network CNN model mainly learns the dataset, refines and analyzes the features between each datum and establishes a fitting relationship, so as to achieve the purpose of prediction. In this paper, by using the full feature particle size, Cc, Cu, and e as the input parameters and the permeability coefficient as the output parameter, a fitting relationship is established for the prediction of the permeability coefficient of heap rock material.
3.1. Data Acquisition and Processing
The determination process of the permeability coefficient of rockfill material samples using laboratory tests is cumbersome and the data format is difficult to unify. The data on the permeability coefficients of rockfill material and coarse-grained soil samples were obtained from the literature, scientific journals, academic papers, or research reports in relevant fields. The permeability coefficients of the samples were selected to be in the range of 10−3~10−1 cm/s to ensure the applicability of the dataset to the rockfill materials due to the large permeability coefficients of rockfill materials. The particle-size range of the selected samples was between 5 mm and 60 mm, which is a typical range for large particle sizes. The permeability characteristics of the selected samples were similar to those of the rockfill material, which met the requirements of model training.
The original data for the dataset were provided by Ding et al. [
27]. Based on the original data, the samples with permeability coefficients on the order of 10
−4 cm/s were removed. The coefficient of uniformity
Cu and the coefficient of curvature
Cc were added to the dataset. The gradation, the pore ratio, the
Cu, and the
Cc were taken as the input features of the model and the permeability coefficients were taken as the output features. The collated dataset is shown in
Table 1.
3.2. Model Performance Evaluation
In this paper, the root mean square error (
RMSE), coefficient of determination (
R2), and mean absolute error (
MAE) are used as the evaluation indexes to assess the performance of the model. The
RMSE is an index to assess the difference between predicted values and test values. A smaller
RMSE indicates that the difference between the predictions and the observations is smaller, meaning a better model performance. Its expression is as follows:
R2 is used to measure how well the model explains the total variance. It represents the proportion of the total variance explained by the model and takes a value between 0 and 1. A larger
R2 indicates that the model explains the variability of the test data better and that the model fit is better. Its expression is as follows:
The
MAE is the average of the absolute errors between the predicted and the test values. A smaller
MAE value indicates a smaller absolute error in the model prediction, meaning better model performance. Its expression is:
where
and
are the test and predicted values of the permeability coefficient, respectively,
m is the total number of samples, and
is the mean of the test values.
4. Model Training and Results Analysis
Building the BP neural network model and the random forest model and comparing them with the CNN model allows us to assess the performance of the CNN model with respect to the BP model in the permeability coefficient prediction task. This comparison helps us to understand the advantages of the CNN model.
4.1. Construction of the BP Model
The full name of the BP neural network is the backpropagation neural network, which is a multilayer feed-forward network trained according to the error-backpropagation algorithm. The BP neural network model is a classical neural network model that has been widely used in a variety of prediction and classification tasks. It has a multilayer structure and a backpropagation algorithm to model and learn complex nonlinear relationships. It consists of input, hidden, and output layers. The construction of the BP neural network can be achieved by the self-contained toolbox in MATLAB-R2022a [
28]. The specific construction steps are as follows:
(1) Data normalization and sample division.
(2) Define input, hidden, and output layers. The number of hidden layers is determined by the empirical formula (where is the number of neurons in the hidden layer, m is the number of neurons in the input layer, n is the number of neurons in the output layer, and a is a constant between 0 and 10).
(3) Define the network training function and parameter settings. The activation function is a sigmoid function, the number of iterations is set to 1000, the learning rate is 0.01, and the error threshold is 1 × 10−6.
(4) Training model and performance evaluation.
The BP model’s hyperparameter settings are shown in
Table 2.
4.2. Analysis of Training Results
The collected dataset was used in the model training. During the training process, the hyperparameters needed to be adjusted according to the training effect to improve the prediction accuracy. Furthermore, to verify the prediction performance of the model, the CNN model was compared to the traditional BP model and the error of each model was calculated. The training effect is shown in
Figure 3 and
Figure 4, and the evaluation index of each model is shown in
Table 3.
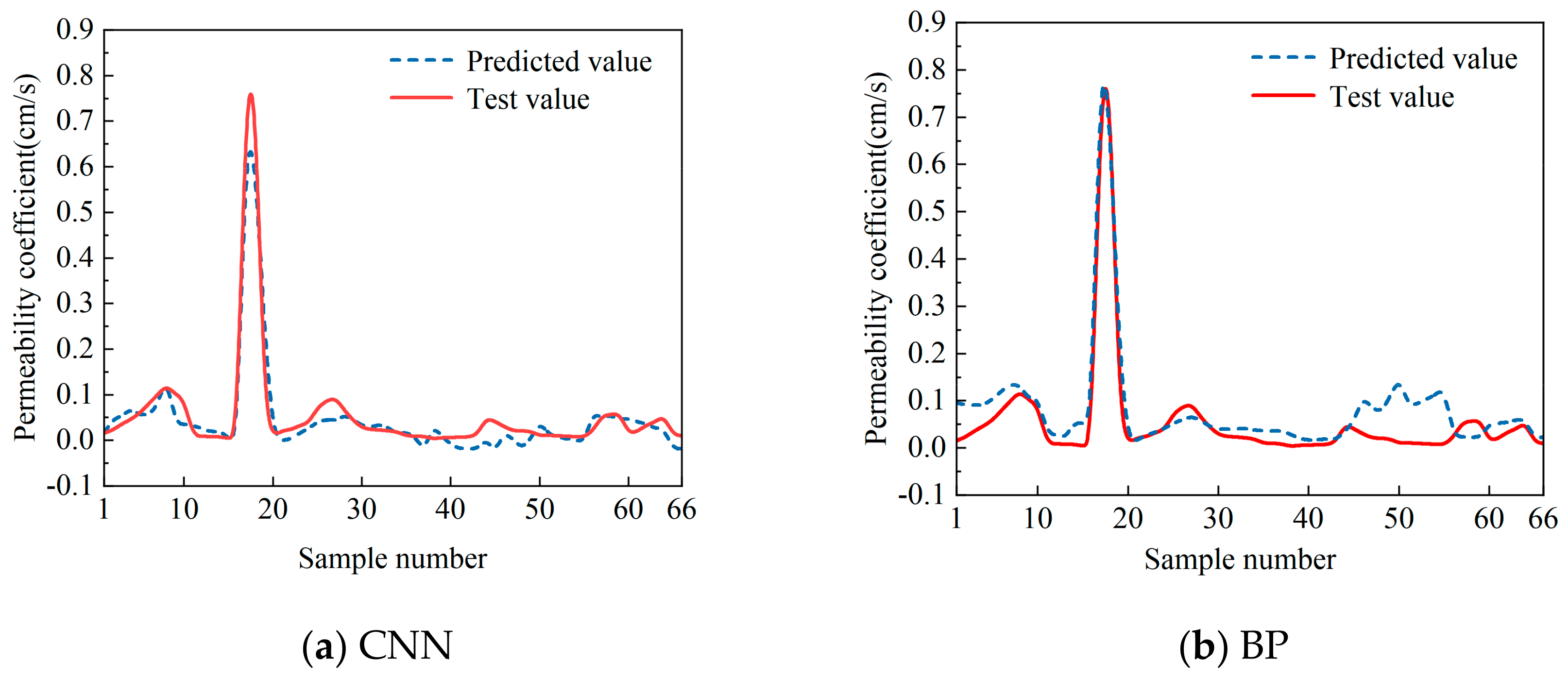
As can be seen in
Figure 3, the CNN model and the BP model both perform well on the training set. However, the predicted values of the BP model fluctuate greatly, and the predicted values of some samples deviate from the test values significantly. On the other hand, the predicted values of the CNN model are closer to the test values, and the trends are also consistent with the test values. Therefore, the CNN model fits the dataset better.
As can be seen in
Figure 4, the predicted values of the CNN model are closer to the test values than those of the BP model, with less fluctuation in the curve and a more stable trend, indicating that the CNN model has higher prediction accuracy and better model performance. In addition, the CNN model has a better prediction effect when the test value of the sample permeability coefficient is about 0.1 cm/s or less, but the prediction accuracy is lower when the permeability coefficient is larger. The main reason for this is the small number of datasets (76 groups). The permeability coefficients of the dataset samples are concentrated around the order of 1 × 10
−2 cm/s. The number of samples above 0.1 cm/s is small, providing insufficient data for the CNN model. Even on the dataset with only 76 sets of samples, the CNN model has good results, showing the powerful learning and fitting ability of the CNN, which also performs well in regression problems.
In
Table 3, the evaluation indexes of the CNN model and BP model are compared and analyzed. For
RMSE, the CNN model’s training set decreases by 65.6% and the testing set decreases by 59.62% compared with the BP model. For
R2, the CNN model improves the training set by 21.56% and the testing set by 22.61% compared with the BP model. For
MAE, the CNN model decreases the training set by 35.71% and the testing set by 29.05% compared with the BP model. Thus, it seems that the convolutional and pooling layers in the CNN model contribute to improving the ability to extract the feature information of the data, which significantly improves the prediction performance and verifies the model’s applicability in the prediction of the permeability coefficients of rockfill materials.
The model’s prediction accuracy was tested using non-participating training data. The comparison of the predicted values and test values is shown in
Table 4. It can be seen that the maximum relative error between the CNN model’s predicted values and the test values is 7.83% and that the average relative error is 4.77%, indicating that the predicted values are closer to the test values.
4.3. Model Effectiveness Evaluation
To validate the performance of the CNN model and the BP model, the mainstream machine learning evaluation method of K-fold cross-validation is used. The steps of K-fold cross-validation are as follows: first, the original dataset is divided into K subsets of similar size, and next, K iterations are performed. In each iteration, one of the subsets is used as the test set and the remaining K-1 subsets are used as the training set. Next, the training set is used to train the model and the performance of the model is evaluated on the corresponding test set. The performance-evaluation results obtained from K iterations are averaged as the final performance-evaluation results.
In this study, the dataset was divided into seven subsets, one subset was used as the test set each time, and the results of the seven subsets were obtained as shown in
Table 5, which shows that the CNN model performs well on each validation subset and that the model is sufficiently reliable.
5. Validation of Permeability Test
To validate the generalization performance of the CNN model, a constant head permeability test was conducted to verify the prediction accuracy of the model [
29]. In the normal head infiltration test, since the infiltration head remains stable, the pore structure of the soil body is more uniform after it is compacted by equal compaction work, and no turbulence occurs during the test; the soil body can be described as having laminar flow, and its infiltration coefficient can be calculated by applying Darcy’s formula.
5.1. Permeability Test Design
The permeameter sample gradation adopted the reduced scale of the field gradation of the rockfill dam. The samples were formulated to ensure good gradation, which is controlled by the coefficient of uniformity and the coefficient of curvature. Furthermore, the large particles greater than 60 mm in size were excluded, and the particle-size range was 2–60 mm. The rockfill permeameter was used in the test as shown in
Figure 5. The diameter of the specimen bucket was 300 mm. The test was conducted with a water temperature of 20 °C as the standard temperature, and the permeability coefficient was measured at this standard temperature.
The specific steps of the permeability test are as follows:
(1) Instrument installation. The water pipe was connected and the water was filled from the bottom of the instrument until the water level was slightly above the orifice plate and the water supply was stopped. Samples were taken and the air-dried water contents of the samples were measured. The temperature (T) during the test was recorded.
(2) The samples were filled into the specimen buckets in layers and lightly tamped with a wooden hammer. After filling, the height from the top of the specimen to the top of the bucket was measured and the net height of the specimen was calculated. The mass of the filled samples was calculated by measuring the mass of the remaining samples. A buffer layer of gravel approximately 2 cm thick was placed over the top of the specimen. The water supply was slightly opened until the water level rose to the overflow hole, and then the water supply was stopped.
(3) After a few minutes, the water level in each piezometer was checked to ensure that it was flush with the overflow hole. The water supply was started to allow water to be injected into the specimen bucket. During the test, the water supply should be adjusted to allow the supply water slightly more than the overflow water. The overflow pipe should always have water overflow to maintain a constant water level.
(4) After the water level of the piezometer tube has been stabilized, the water level of the piezometer tube should be recorded and the difference in water level between each piezometer tube should be calculated. The volume of infiltration water in a certain period (t) was taken with a graduated cylinder, and the measurement should be repeated according to the regulations.
The permeability coefficient of the constant head permeability test should be calculated according to the following formula:
where
KT is the permeability coefficient of the specimen at the target water temperature (
T) (cm/s),
Q is the volume of infiltration water in a certain period (
t), in seconds (cm
3),
L is the seepage diameter (cm), the height between the centers of the two pressure holes,
A is the cross-sectional area of the specimen (cm
2),
t is the time (s),
H1,
H2 is the difference between the water levels (cm),
K20 is the permeability coefficient of the specimen at the standard water temperature (20 °C) (cm/s),
is the coefficient of the dynamic viscosity of the water at the target water temperature (
T) (1 × 10
−6 kPa·s), and
is the coefficient of the dynamic viscosity of water under the standard water temperature (20 °C) (1 × 10
−6 kPa·s).
5.2. Permeability Test Results
The permeability test results of the samples are shown in
Table 6.
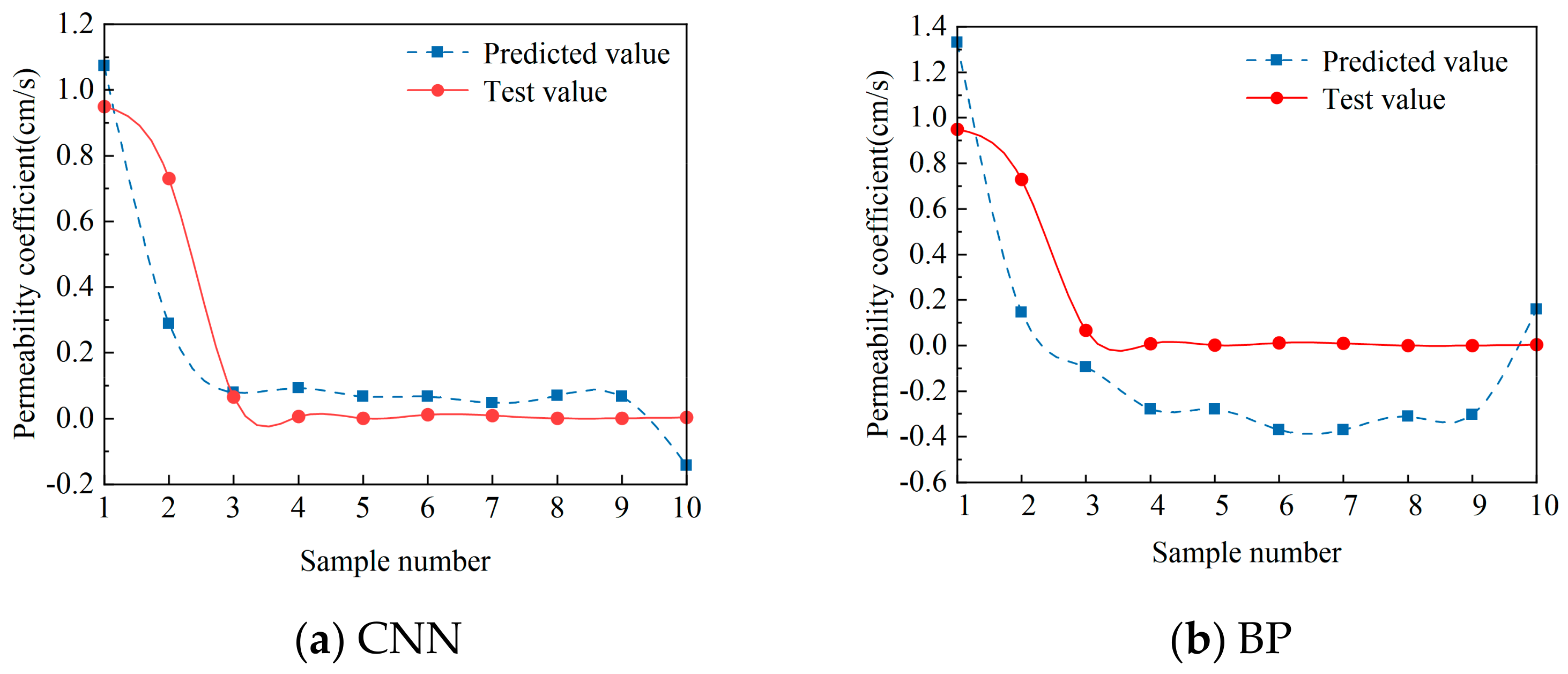
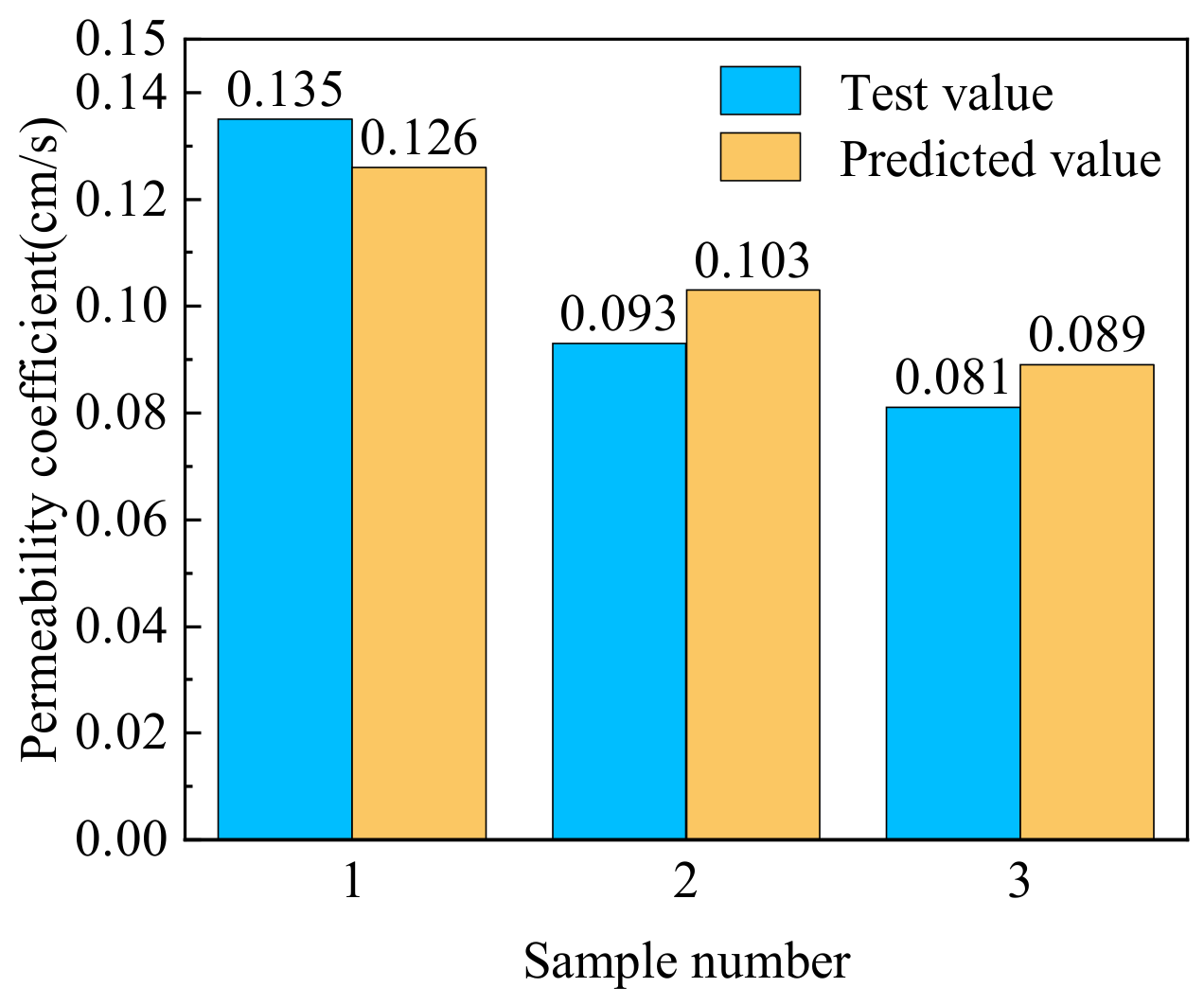
The comparison of the test values and the predicted values is shown in
Table 7 and
Figure 6. The complexity of the infiltration path of the rockfill material is related to many factors, such as the compactness, gradation, pore ratio, coefficient of uniformity, etc. Therefore, some error exists between the predicted permeability coefficient obtained with the CNN model and the test values. From
Table 7 and
Figure 6, it can be seen that the difference between the predicted values of the CNN model and the test values of the permeability test is not large and that the relative error is small, which meets the general needs of rough estimation in engineering. Therefore, the CNN model is applicable when evaluate the permeability coefficient of rockfill material.
6. Conclusions
With the popularization of machine learning technology, the application of neural networks in engineering practice has received increasing attention. In this paper, the CNN was used to establish a machine learning model to predict the permeability coefficient of rockfill material, and the following conclusions were obtained:
(1) Compared with the traditional BP neural network, CNNs can learn to obtain more data features through their special convolution and pooling structures. Therefore, they have higher accuracy in regression prediction.
(2) For the prediction of the permeability coefficient of rockfill material, the gradation, coefficient of uniformity, coefficient of curvature, and pore ratio were used as the input features and the permeability coefficient was used as the output feature to build a dataset, which achieved better results.
(3) The laboratory permeability test was conducted to demonstrate that the CNN model has good generalization performance.
Author Contributions
Conceptualization, Q.Y., C.W. and S.L.; Methodology, Q.Y.; Software, X.D.; Formal analysis, J.Z.; Investigation, X.D., C.W. and S.L.; Resources, Q.Y., J.Z. and S.L.; Writing—original draft, Z.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Yulong Kashgar Special Scientific Research Project (YLKS-SW-2022-016).
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
Qigui Yang was employed by Changjiang Institute of Survey, Planning, Design and Research Co., Ltd.; National Dam Safety Research Center. Jianqing Zhang was employed by Changjiang Institute of Survey, Planning, Design and Research Co., Ltd.; National Dam Safety Research Center; Changjiang Geophysical Exploration and Testing Co., Ltd. Xing Dai and Shuyang Lu were employed by China Gezhouba Group Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Eggleston, J.; Rojstaczer, S. The value of grain-size hydraulic conductivity estimates: Comparison with high resolution in-situ field hydraulic conductivity. Geophys. Res. Lett. 2001, 28, 4255–4258. [Google Scholar] [CrossRef]
- Zhu, C.H.; Liu, J.M.; Wang, Z.H. Study on the influence of particle level matching on permeability coefficient of coarse-grained soil. People’s Yellow River 2005, 12, 79–81. (In Chinese) [Google Scholar]
- Chapuis, R.P. Predicting the saturated hydraulic conductivity of soils: A review. Bull. Eng. Geol. Environ. 2012, 71, 401–434. [Google Scholar] [CrossRef]
- Zhou, W.H.; Yuen, K.V.; Tan, F. Estimation of soil–water characteristic curve and relative permeability for granular soils with different initial dry densities. Eng. Geol. 2014, 179, 1–9. [Google Scholar] [CrossRef]
- Göktepe, A.B.; Sezer, A. Effect of particle shape on density and permeability of sands. Proc. Inst. Civ. Eng. Geotech. Eng. 2010, 163, 307–320. [Google Scholar] [CrossRef]
- Ghabchi, R.; Zaman, M.; Kazmee, H.; Singh, D. Effect of shape parameters and gradation on laboratory-measured permeability of aggregate bases. Int. J. Geomech. 2015, 15, 04014070. [Google Scholar] [CrossRef]
- Seghir, A.; Benamar, A.; Wang, H. Effects of fine particles on the suffusion of cohesionless soils. Exp. Model. Transp. Porous Media 2014, 103, 233–247. [Google Scholar] [CrossRef]
- Sato, M.; Kuwano, R. Suffusion and clogging by one-dimensional seepage tests on cohesive soil. Soils Found. 2015, 55, 1427–1440. [Google Scholar] [CrossRef]
- Tillmann, A.; Englert, A.; Nyari, Z.; Fejes, I.; Vanderborght, J.; Vereecken, H. Characterization of subsoil heterogeneity, estimation of grain size distribution and hydraulic conductivity at the Krauthausen test site using cone penetration test. J. Contam. Hydrol. 2008, 95, 57–75. [Google Scholar] [CrossRef]
- Wang, J.J.; Qiu, Z.F. Anisotropic hydraulic conductivity and critical hydraulic gradient of a crushed sandstone–mudstone particle mixture. Mar. Georesour. Geotechnol. 2017, 35, 89–97. [Google Scholar] [CrossRef]
- Neithalath, N.; Sumanasooriya, M.S.; Deo, O. Characterizing pore volume, sizes, and connectivity in pervious concretes for permeability prediction. Mater. Charact. 2010, 61, 802–813. [Google Scholar] [CrossRef]
- Koohmishi, M.; Azarhoosh, A. Assessment of permeability of granular drainage layer considering particle size and air void distribution. Constr. Build. Mater. 2021, 270, 121373. [Google Scholar] [CrossRef]
- Chapuis, R.P. Predicting the saturated hydraulic conductivity of sand and gravel using effective diameter and void ratio. Can. Geotech. J. 2004, 41, 787–795. [Google Scholar] [CrossRef]
- Koohmishi, M. Hydraulic conductivity and water level in the reservoir layer of porous pavement considering gradation of aggregate and compaction level. Constr. Build. Mater. 2019, 203, 27–44. [Google Scholar] [CrossRef]
- Dolzyk, K.; Chmielewska, I. Predicting the coefficient of permeability of non-plastic soils. Soil Mech. Found. Eng. 2014, 51, 213–218. [Google Scholar] [CrossRef]
- Wrzesiński, G.; Markiewicz, A. Prediction of permeability coefficient k in sandy soils using ANN. Sustainability 2022, 14, 6736. [Google Scholar] [CrossRef]
- Pham, B.T.; Ly, H.B.; Al-Ansari, N.; Ho, L.S. A comparison of Gaussian process and M5P for prediction of soil permeability coefficient. Sci. Program. 2021, 2021, 3625289. [Google Scholar] [CrossRef]
- Tran, V.Q. Predicting and investigating the permeability coefficient of soil with aided single machine learning algorithm. Complexity 2022, 2022, 8089428. [Google Scholar] [CrossRef]
- Ahmad, M.; Keawsawasvong, S.; Bin Ibrahim, M.R.; Waseem, M.; Kashyzadeh, K.R.; Sabri, M.M.S. Novel approach to predicting soil permeability coefficient using Gaussian process regression. Sustainability 2022, 14, 8781. [Google Scholar] [CrossRef]
- Yilmaz, I.; Marschalko, M.; Bednarik, M.; Kaynar, O.; Fojtova, L. Neural computing models for prediction of permeability coefficient of coarse-grained soils. Neural Comput. Appl. 2012, 21, 957–968. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, S. Coefficient of permeability prediction of soils using gene expression programming. Eng. Appl. Artif. Intell. 2024, 128, 107504. [Google Scholar] [CrossRef]
- Al Khalifah, H.; Glover, P.W.J.; Lorinczi, P. Permeability prediction and diagenesis in tight carbonates using machine learning techniques. Mar. Pet. Geol. 2020, 112, 104096. [Google Scholar] [CrossRef]
- Dongare, A.D.; Kharde, R.R.; Kachare, A.D. Introduction to artificial neural network. Int. J. Eng. Innov. Technol. IJEIT 2012, 2, 189–194. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Vedaldi, A.; Lenc, K. Matconvnet: Convolutional neural networks for MATLAB. In Proceedings of the 23rd ACM International Conference on Multimedia, ACM, New York, NY, USA, 29 October–3 November 2015; pp. 689–692. [Google Scholar]
- Sauerbrey, I.I. On the problem and determination of the permeability coefficient. Proc. VNIIG 1932, 3–5, 115–145. (In Russian) [Google Scholar]
- Ding, Y.; Rao, Y.K.; Ni, Q.; Xu, W.N.; Liu, D.X.; Zhang, H. Effect of particle composition and pore ratio on permeability coefficient of coarse-grained soil. Hydrogeol. Eng. Geol. 2019, 46, 108–116. (In Chinese) [Google Scholar]
- Liu, L.; Chen, J.; Xu, L. Realization and application research of BP neural network based on MATLAB. In Proceedings of the 2008 International Seminar on Future BioMedical Information Engineering, Wuhan, China, 18 December 2008; pp. 130–133. [Google Scholar]
- Sandoval, G.F.; Galobardes, I.; Teixeira, R.S.; Toralles, B.M. Comparison between the falling head and the constant head permeability tests to assess the permeability coefficient of sustainable pervious concretes. Case Stud. Constr. Mater. 2017, 7, 317–328. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}