


Bathymetric Modelling of High Mountain Tropical Lakes of Southern Ecuador

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
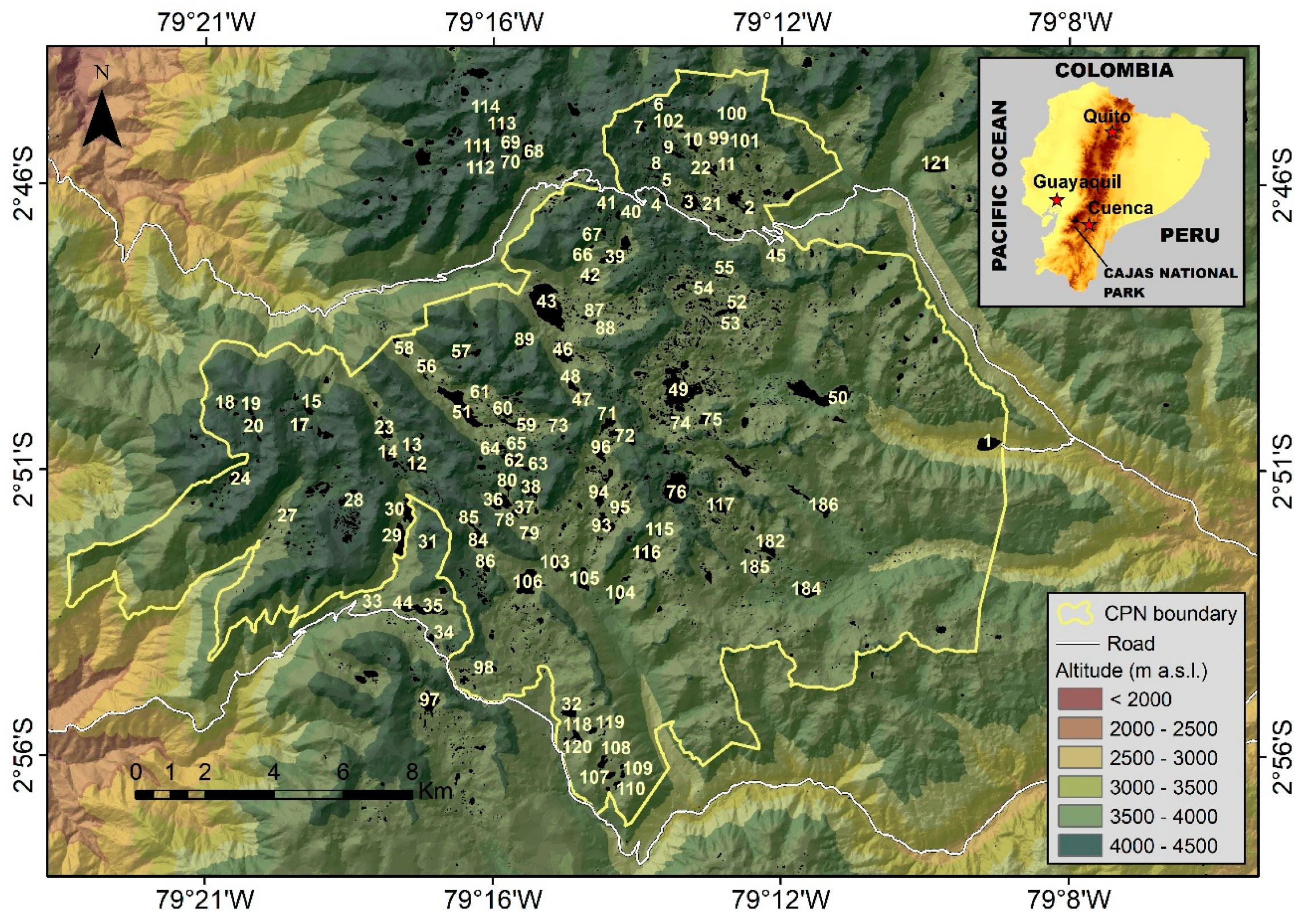
2.1. The Study Lakes
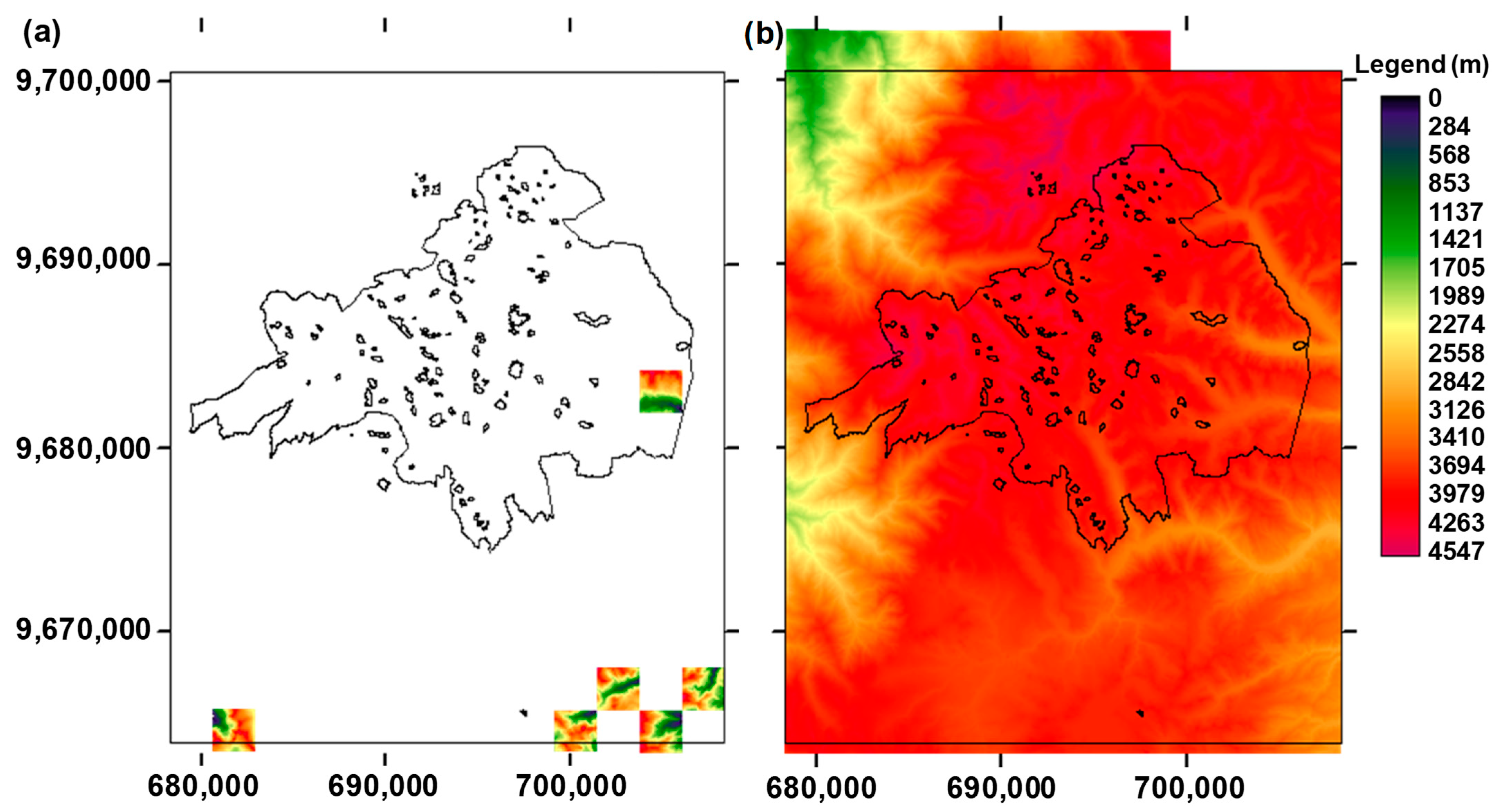
2.2. Digital Elevation Model (DEM) of the Study Site
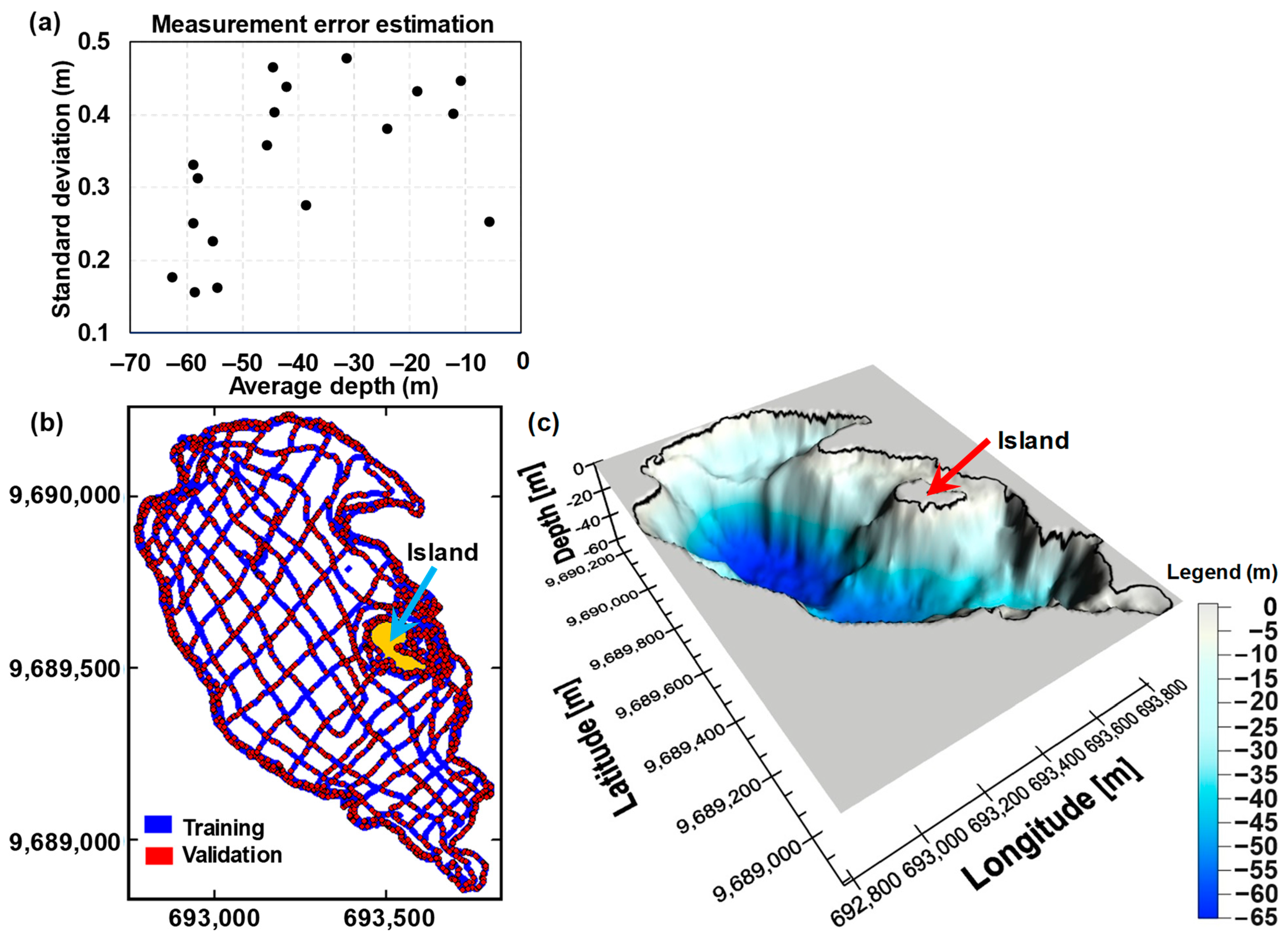
2.3. Bathymetric Surveying
2.4. Bathymetric Modelling
2.4.1. Splitting the Observations into Training and Evaluation Data Sets (Split-Sample Test)
2.4.2. Interpolation Methods
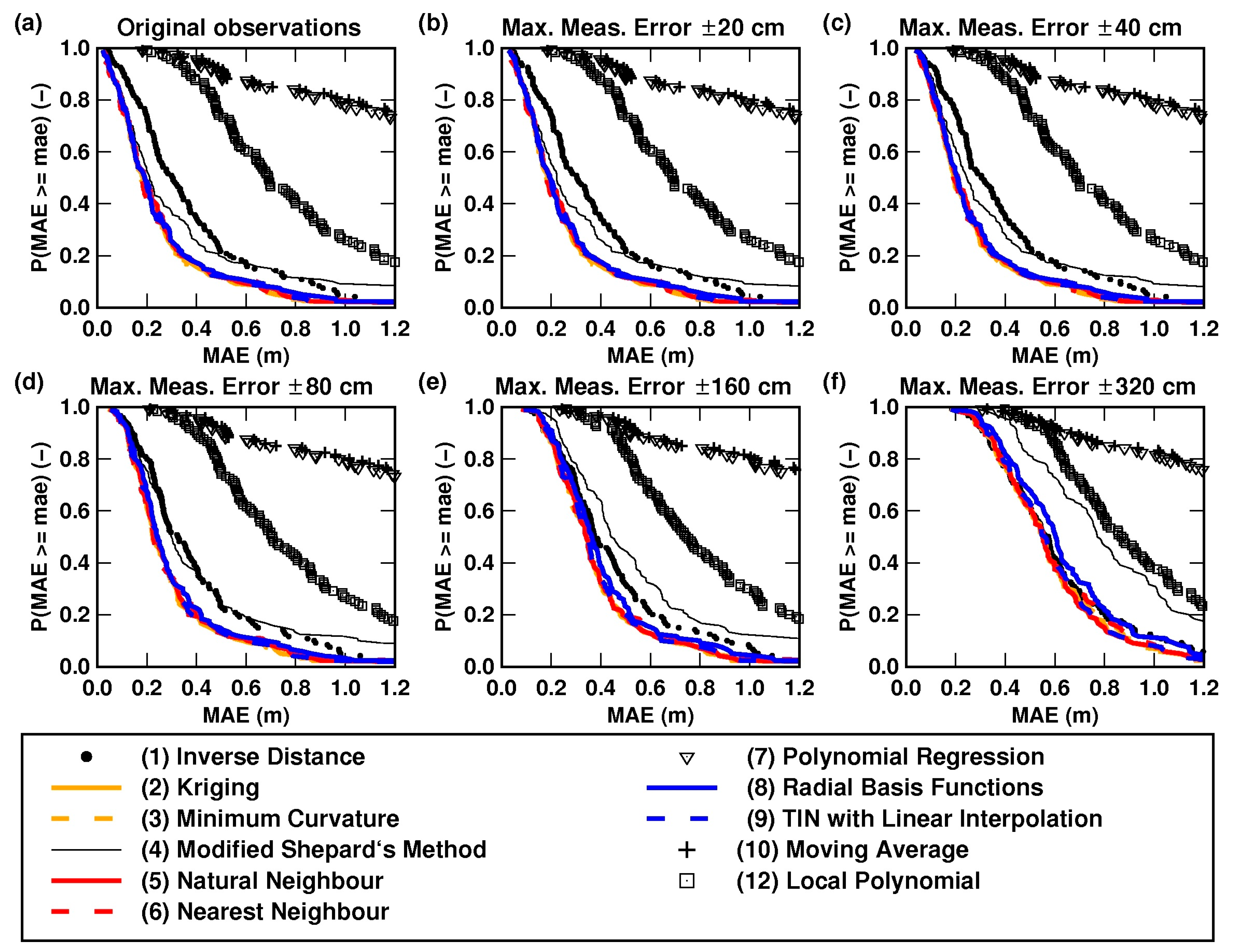
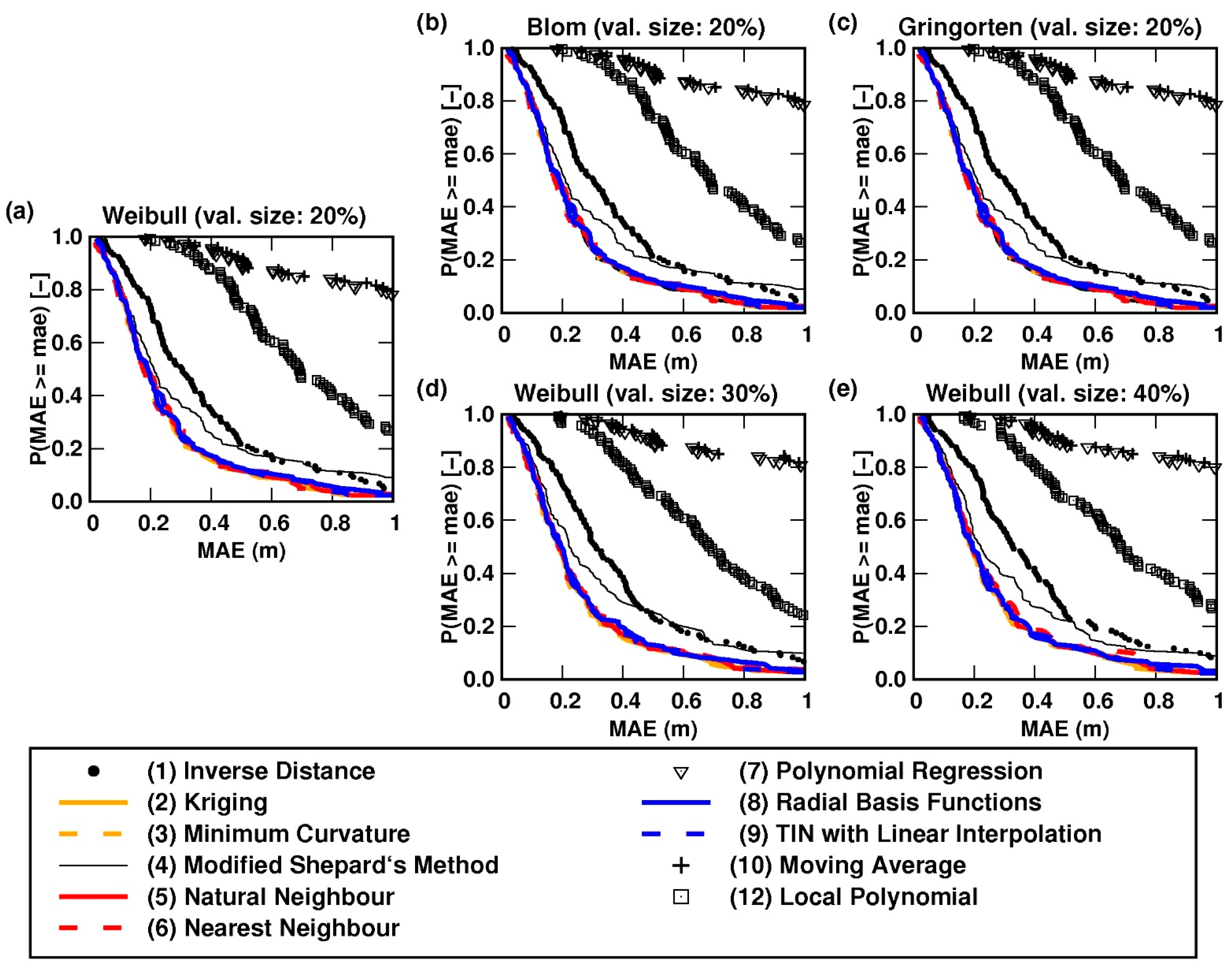
2.4.3. Assessing the Accuracy of Interpolation Methods
2.4.4. Sensitivity Analysis of the Effect of the Magnitude of Random Measurement Errors on the Accuracy of the Interpolation Methods
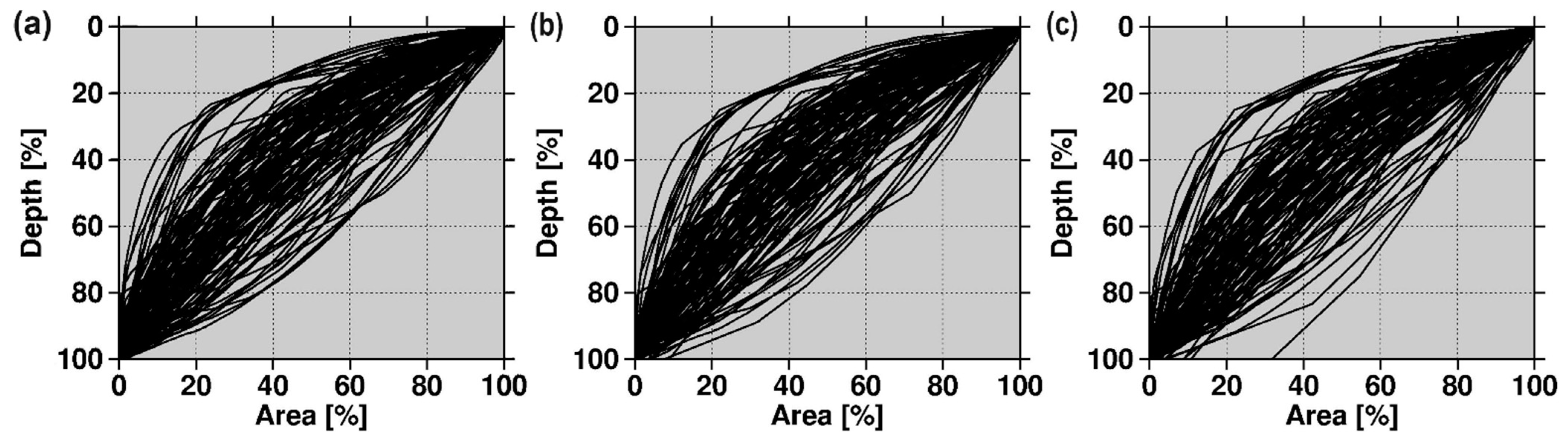
2.5. Inspecting the Hypsometric Properties of the Study Lakes
2.6. Incorporating the Lake Bathymetry into the Digital Elevation Model (DEM) of the Study Site
3. Results
3.1. Bathymetric Surveying
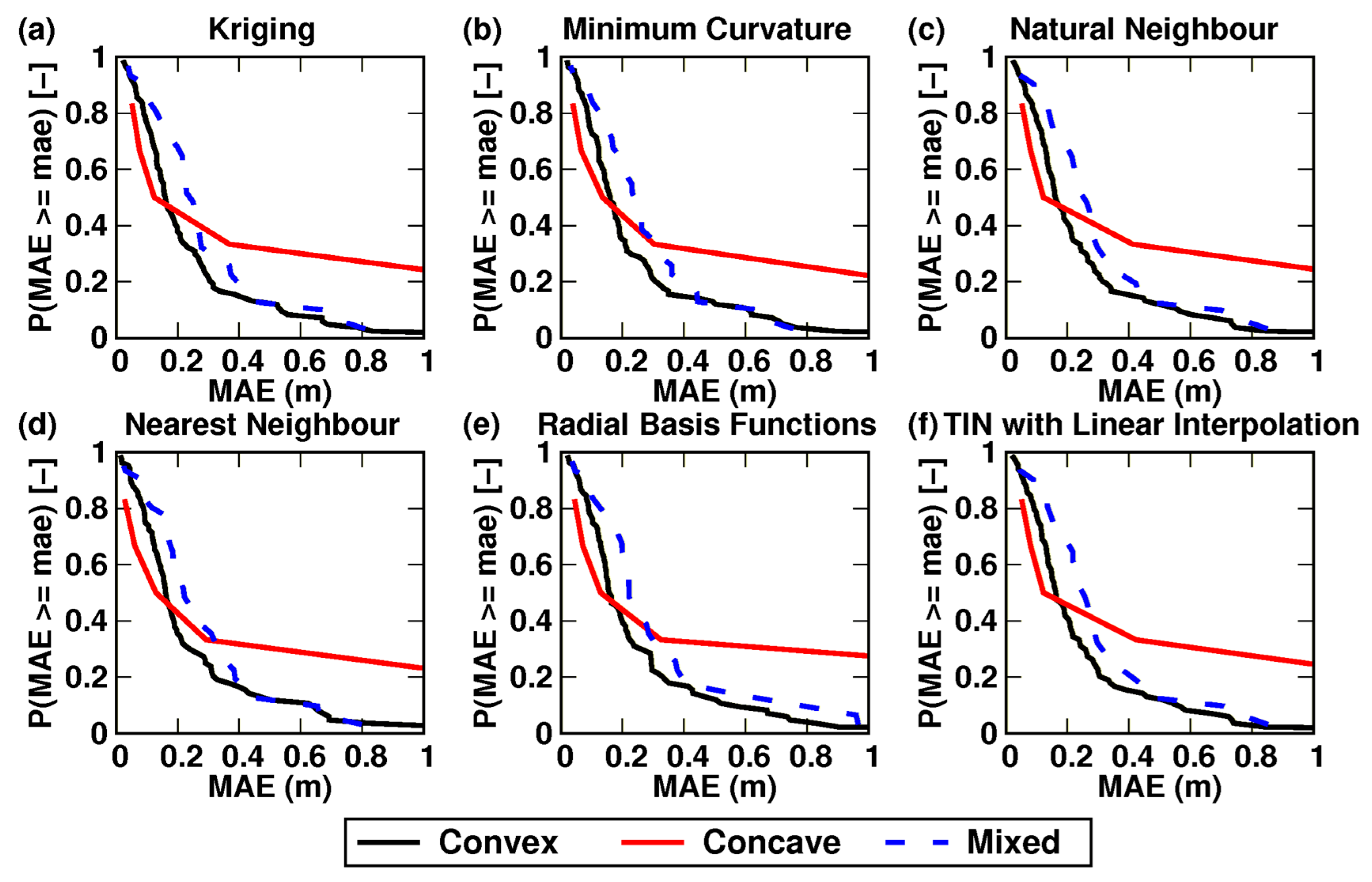
3.2. Bathymetric Modelling
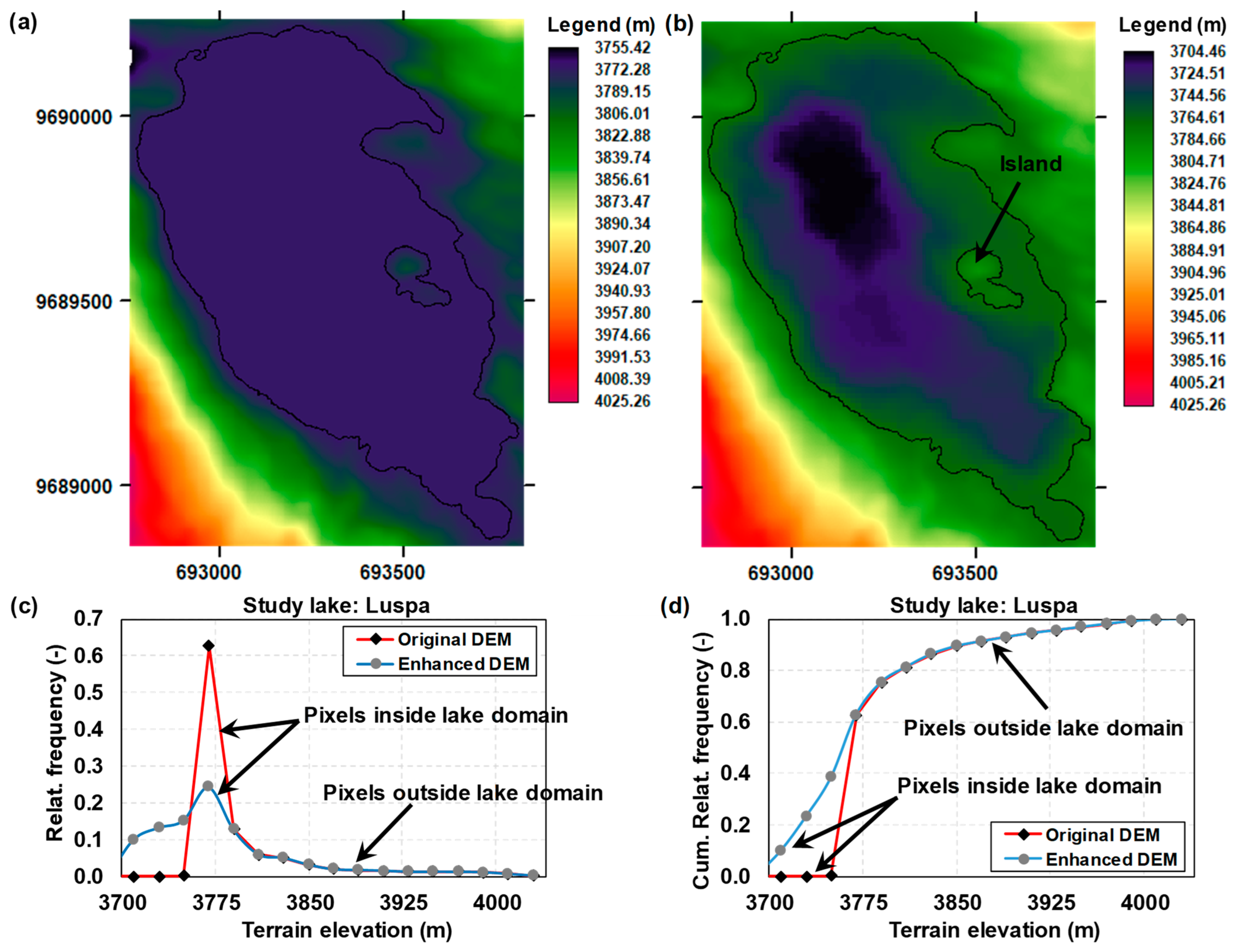
3.3. Inspecting the Hypsometric Properties of the Study Lakes
3.4. Incorporating the Lake Bathymetry into the Digital Elevation Model (DEM) of the Study Site
4. Discussion
4.1. Bathymetric Surveying
4.2. Bathymetric Modelling
4.3. Incorporating the Lake Bathymetry into the Digital Elevation Model (DEM) of the Study Site
4.4. Average Lake Form
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Viviroli, D.; Kummu, M.; Meybeck, M.; Kallio, M.; Wada, Y. Increasing dependence of lowland populations on mountain water resources. Nat. Sustain. 2020, 3, 917–928. [Google Scholar] [CrossRef]
- Grêt-Regamey, A.; Brunner, S.H.; Kienast, F. Mountain Ecosystem Services: Who Cares? Mt. Res. Dev. 2012, 32, S24–S34. [Google Scholar] [CrossRef]
- Mosquera, P.V.; Hampel, H.; Vázquez, R.F.; Alonso, M.; Catalan, J. Abundance and morphometry changes across the high-mountain lake-size gradient in the tropical Andes of Southern Ecuador. Water Resour. Res. 2017, 53, 7269–7280. [Google Scholar] [CrossRef]
- Mosquera, P.V.; Hampel, H.; Vázquez, R.F.; Catalan, J. Water chemistry variation in tropical high-mountain lakes on old volcanic bedrocks. Limnol. Oceanogr. 2022, 67, 1522–1536. [Google Scholar] [CrossRef]
- Giles, M.P.; Michelutti, N.; Grooms, C.; Smol, J.P. Long-term limnological changes in the Ecuadorian páramo: Comparing the ecological responses to climate warming of shallow waterbodies versus deep lakes. Freshw. Biol. 2018, 63, 1316–1325. [Google Scholar] [CrossRef]
- Michelutti, N.; Wolfe, A.P.; Cooke, C.A.; Hobbs, W.O.; Vuille, M.; Smol, J.P. Climate Change Forces New Ecological States in Tropical Andean Lakes. PLoS ONE 2015, 10, e0115338. [Google Scholar] [CrossRef] [PubMed]
- Catalán, J.; Donato Rondón, J.C. Perspectives for an integrated understanding of tropical and temperate high-mountain lakes. J. Limnol. 2016, 75, 215–234. [Google Scholar] [CrossRef]
- Woolway, R.I.; Kraemer, B.M.; Lenters, J.D.; Merchant, C.J.; O’Reilly, C.M.; Sharma, S. Global lake responses to climate change. Nat. Rev. Earth Environ. 2020, 1, 388–403. [Google Scholar] [CrossRef]
- Palomino-Ángel, S.; Vázquez, R.F.; Hampel, H.; Anaya, J.A.; Mosquera, P.V.; Lyon, S.W.; Jaramillo, F. Retrieval of Simultaneous Water-Level Changes in Small Lakes with InSAR. Geophys. Res. Lett. 2022, 49, e2021GL095950. [Google Scholar] [CrossRef]
- Luethje, M.; Mosquera, P.V.; Hampel, H.; Fritz, S.C.; Benito, X. Planktic diatom responses to spatiotemporal environmental variation in high-mountain tropical lakes. Freshw. Biol. 2024, 69, 387–402. [Google Scholar] [CrossRef]
- Prigent, C.; Papa, F.; Aires, F.; Jimenez, C.; Rossow, W.B.; Matthews, E. Changes in land surface water dynamics since the 1990s and relation to population pressure. Geophys. Res. Lett. 2012, 39, L08403. [Google Scholar] [CrossRef]
- Alcocer, J.; Oseguera, L.A.; Sánchez, G.; González, C.G.; Martínez, J.R.; González, R. Bathymetric and morphometric surveys of the Montebello Lakes, Chiapas. J. Limnol. 2016, 75, 56–65. [Google Scholar] [CrossRef]
- Håkanson, L. On Lake Form, Lake Volume and Lake Hypsographic Survey. Geogr. Annaler. Ser. A Phys. Geogr. 1977, 59, 1–30. [Google Scholar] [CrossRef]
- Håkanson, L. Optimization of lake hydrographic surveys. Water Resour. Res. 1978, 14, 545–560. [Google Scholar] [CrossRef]
- De Maisonneuve, C.B.; Eisele, S.; Forni, F.; Hamdi; Park, E.; Phua, M.; Putra, R. Bathymetric survey of lakes Maninjau and Diatas (West Sumatra), and lake Kerinci (Jambi). J. Phys. Conf. Ser. 2019, 1185, 012001. [Google Scholar] [CrossRef]
- Gonçalves, M.A.; Garcia, F.C.; Barroso, G.F. Morphometry and mixing regime of a tropical lake: Lake Nova (Southeastern Brazil). An. Acad. Bras. Ciências 2016, 88, 1341–1356. [Google Scholar] [CrossRef] [PubMed]
- Van Colen, W.; Portilla, K.; Oña, T.; Wyseure, G.; Goethals, P.; Velarde, E.; Muylaert, K. Limnology of the neotropical high elevation shallow lake Yahuarcocha (Ecuador) and challenges for managing eutrophication using biomanipulation. Limnologica 2017, 67, 37–44. [Google Scholar] [CrossRef]
- Gholamalifard, M.; Kutser, T.; Esmaili-Sari, A.; Abkar, A.A.; Naimi, B. Remotely Sensed Empirical Modeling of Bathymetry in the Southeastern Caspian Sea. Remote Sens. 2013, 5, 2746–2762. [Google Scholar] [CrossRef]
- Pope, A.; Scambos, T.A.; Moussavi, M.; Tedesco, M.; Willis, M.; Shean, D.; Grigsby, S. Estimating supraglacial lake depth in West Greenland using Landsat 8 and comparison with other multispectral methods. Cryosphere 2016, 10, 15–27. [Google Scholar] [CrossRef]
- Vázquez, R.F.; Feyen, J. Assessment of the effects of DEM gridding on the predictions of basin runoff using MIKE SHE and a modelling resolution of 600 m. J. Hydrol. 2007, 334, 73–87. [Google Scholar] [CrossRef]
- Vivoni, E.R.; Ivanov, V.Y.; Bras, R.L.; Entekhabi, D. On the effects of triangulated terrain resolution on distributed hydrologic model response. Hydrol. Process. 2005, 19, 2101–2122. [Google Scholar] [CrossRef]
- Guo, Q.; Li, W.; Yu, H.; Alvarez, O. Effects of Topographic Variability and Lidar Sampling Density on Several DEM Interpolation Methods. Photogramm. Eng. Remote Sens. 2010, 76, 701–712. [Google Scholar] [CrossRef]
- Chu, H.-J.; Wang, C.-K.; Huang, M.-L.; Lee, C.-C.; Liu, C.-Y.; Lin, C.-C. Effect of point density and interpolation of LiDAR-derived high-resolution DEMs on landscape scarp identification. GISci. Remote Sens. 2014, 51, 731–747. [Google Scholar] [CrossRef]
- Chen, C.; Bei, Y.; Li, Y.; Zhou, W. Effect of interpolation methods on quantifying terrain surface roughness under different data densities. Geomorphology 2022, 417, 108448. [Google Scholar] [CrossRef]
- Arun, P.V. A comparative analysis of different DEM interpolation methods. Egypt. J. Remote Sens. Space Sci. 2013, 16, 133–139. [Google Scholar] [CrossRef]
- Boke, A. Comparative Evaluation of Spatial Interpolation Methods for Estimation of Missing Meteorological Variables over Ethiopia. J. Water Resour. Prot. 2017, 9, 945–959. [Google Scholar] [CrossRef]
- Keskin, M.; Dogru, A.O.; Balcik, F.B.; Goksel, C.; Ulugtekin, N.; Sozen, S. Comparing Spatial Interpolation Methods for Mapping Meteorological Data in Turkey. In Energy Systems and Management; Springer: Cham, Switzerland, 2015; pp. 33–42. [Google Scholar]
- Declercq, F.A.N. Interpolation Methods for Scattered Sample Data: Accuracy, Spatial Patterns, Processing Time. Cartogr. Geogr. Inf. Syst. 1996, 23, 128–144. [Google Scholar] [CrossRef]
- Chiang, W.H. Processing Modflow, An Integrated Modeling Environment for the Simulation of Groundwater Flow, Transport and Reactive Processes. In Users Manual, Manuscript, Simcore Software; Simcore: Halifax, UK, 2012; p. 484. [Google Scholar]
- Holzbecher, E. Environmental Modeling Using MATLAB; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Hungerbühler, D.; Steinmann, M.; Winkler, W.; Seward, D.; Egüez, A.; Peterson, D.E.; Helg, U.; Hammer, C. Neogene stratigraphy and Andean geodynamics of southern Ecuador. Earth-Sci. Rev. 2002, 57, 75–124. [Google Scholar] [CrossRef]
- Hansen, B.C.S.; Rodbell, D.T.; Seltzer, G.O.; León, B.; Young, K.R.; Abbott, M. Late-glacial and Holocene vegetational history from two sites in the western Cordillera of southwestern Ecuador. Palaeogeogr. Palaeoclimatol. Palaeoecol. 2003, 194, 79–108. [Google Scholar] [CrossRef]
- Colinvaux, P.A.; Bush, M.B.; Steinitz-Kannan, M.; Miller, M.C. Glacial and Postglacial Pollen Records from the Ecuadorian Andes and Amazon. Quat. Res. 1997, 48, 69–78. [Google Scholar] [CrossRef]
- Ramsay, P.M.; Oxley, E.R.B. The growth form composition of plant communities in the ecuadorian páramos. Plant Ecol. 1997, 131, 173–192. [Google Scholar] [CrossRef]
- Alvites, C.; Battipaglia, G.; Santopuoli, G.; Hampel, H.; Vázquez, R.F.; Matteucci, G.; Tognetti, R.; De Micco, V. Dendrochronological analysis and growth patterns of Polylepis reticulata (Rosaceae) in the Ecuadorian Andes. IAWA J. 2019, 40, S331–S335. [Google Scholar] [CrossRef]
- Davis, J.C. Statistics and Data Analysis in Geology; John Wiley and Sons: New York, NY, USA, 2002; p. 638. [Google Scholar]
- Humminbird. Humminbird Operations Manual 1198c SI Combo; Humminbird: Eufaula, AL, USA, 2012; p. 207. [Google Scholar]
- Yang, C.-S.; Kao, S.-P.; Lee, F.-B.; Hung, P.-S. Twelve different interpolation methods: A case study of Surfer 8.0. In Proceedings of the XXth ISPRS Congress “Geo-Imagery Bridging Continents”, Istanbul, Turkey, 12–23 July 2004; pp. 778–785. [Google Scholar]
- Aykut, N.O.; Akpınar, B.; Aydın, Ö. Hydrographic data modeling methods for determining precise seafloor topography. Comput. Geosci. 2013, 17, 661–669. [Google Scholar] [CrossRef]
- Amante, C.J.; Eakins, B.W. Accuracy of Interpolated Bathymetry in Digital Elevation Models. J. Coast. Res. 2016, 76, 123–133. [Google Scholar] [CrossRef]
- Franke, R.; Nielson, G. Smooth interpolation of large sets of scattered data. Int. J. Numer. Methods Eng. 1980, 15, 1691–1704. [Google Scholar] [CrossRef]
- Renka, R.J. Algorithm 660: QSHEP2D: Quadratic Shepard Method for Bivariate Interpolation of Scattered Data. ACM Trans. Math. Softw. 1988, 14, 149–150. [Google Scholar] [CrossRef]
- Eldrandaly, K.A.; Abu-Zaid, M.S. Comparison of Six GIS-Based Spatial Interpolation Methods for Estimating Air Temperature in Western Saudi Arabia. J. Environ. Inform. 2011, 18, 38–45. [Google Scholar] [CrossRef]
- Merwade, V.M.; Maidment, D.R.; Goff, J.A. Anisotropic considerations while interpolating river channel bathymetry. J. Hydrol. 2006, 331, 731–741. [Google Scholar] [CrossRef]
- Li, L.; Nearing, M.A.; Nichols, M.H.; Polyakov, V.O.; Phillip Guertin, D.; Cavanaugh, M.L. The effects of DEM interpolation on quantifying soil surface roughness using terrestrial LiDAR. Soil Tillage Res. 2020, 198, 104520. [Google Scholar] [CrossRef]
- Pannatier, Y. VARIOWIN Software for Spatial Data Analysis in 2D; Springer: New York, NY, USA, 1996; p. 91. [Google Scholar]
- Erdogan, S. A comparision of interpolation methods for producing digital elevation models at the field scale. Earth Surf. Process. Landf. 2009, 34, 366–376. [Google Scholar] [CrossRef]
- Franke, R. Smooth interpolation of scattered data by local thin plate splines. Comput. Math. Appl. 1982, 8, 273–281. [Google Scholar] [CrossRef]
- Vázquez, R.F.; Brito, J.E.; Hampel, H.; Birkinshaw, S. Assessing the Performance of SHETRAN Simulating a Geologically Complex Catchment. Water 2022, 14, 3334. [Google Scholar] [CrossRef]
- Wei, C.; Zhao, Q.; Lu, Y.; Fu, D. Assessment of Empirical Algorithms for Shallow Water Bathymetry Using Multi-Spectral Imagery of Pearl River Delta Coast, China. Remote Sens. 2021, 13, 3123. [Google Scholar] [CrossRef]
- Hassan, M.H.; Nadaoka, K. Assessment of machine learning approaches for bathymetry mapping in shallow water environments using multispectral satellite images. Int. J. Geoinform. 2017, 13, 1–15. [Google Scholar]
- Hong, H.P.; Li, S.H. Plotting positions and approximating first two moments of order statistics for Gumbel distribution: Estimating quantiles of wind speed. Wind Struct. 2014, 19, 371–387. [Google Scholar] [CrossRef]
- Strahler, A.N. Hypsometric (Area-Altitude) Analysis of Erosional Topography. GSA Bull. 1952, 63, 1117–1142. [Google Scholar] [CrossRef]
- Langbein, W.B. Topographic Characteristics of Drainage Basins; 968C; United States Department of the Interior, Geological Survey: Reston, VA, USA, 1947; pp. 125–158.
- Franke, R. Scattered data interpolation: Tests of some methods. Math. Comput. 1982, 38, 181–200. [Google Scholar]
- Yamasaki, S.; Tabusa, T.; Iwasaki, S.; Hiramatsu, M. Acoustic water bottom investigation with a remotely operated watercraft survey system. Prog. Earth Planet. Sci. 2017, 4, 25. [Google Scholar] [CrossRef]
- Hatanaka, K.; Toda, M.; Wada, M. Data Analysis of a Low-Cost Bathymetry System Using Fishing Echo Sounders. In Proceedings of the OCEANS 2007, Vancouver, BC, Canada, 29 September–4 October 2007; pp. 1–6. [Google Scholar]
- Neupane, B.; Thakuri, S.; Gurung, N.; Aryal, A.; Bhandari, B.; Pathak, K. Lake Bathymetry, Morphometry and Hydrochemistry of Gosaikunda and Associated Lake. J. Tour. Himal. Adventures 2022, 4, 34–45. [Google Scholar] [CrossRef]
- Bongiovanni, C.; Stewart, H.A.; Jamieson, A.J. High-resolution multibeam sonar bathymetry of the deepest place in each ocean. Geosci. Data J. 2022, 9, 108–123. [Google Scholar] [CrossRef]
- Ernstsen, V.B.; Noormets, R.; Hebbeln, D.; Bartholomä, A.; Flemming, B.W. Precision of high-resolution multibeam echo sounding coupled with high-accuracy positioning in a shallow water coastal environment. Geo-Mar. Lett. 2006, 26, 141–149. [Google Scholar] [CrossRef]
- Aguilar, F.J.; Agüera, F.; Aguilar, M.A.; Carvajal, F. Effects of Terrain Morphology, Sampling Density, and Interpolation Methods on Grid DEM Accuracy. Photogramm. Eng. Remote Sens. 2005, 7, 805–816. [Google Scholar] [CrossRef]
- Liu, K.; Song, C.; Zhan, P.; Luo, S.; Fan, C. A Low-Cost Approach for Lake Volume Estimation on the Tibetan Plateau: Coupling the Lake Hypsometric Curve and Bottom Elevation. Front. Earth Sci. 2022, 10, 925944. [Google Scholar] [CrossRef]
- Paul, S.; Oppelstrup, J.; Thunvik, R.; Magero, J.M.; Ddumba Walakira, D.; Cvetkovic, V. Bathymetry Development and Flow Analyses Using Two-Dimensional Numerical Modeling Approach for Lake Victoria. Fluids 2019, 4, 182. [Google Scholar] [CrossRef]
- Martinsen, K.T.; Sand-Jensen, K.; Selvan, R. Predicting lake bathymetry from the topography of the surrounding terrain using deep learning. Limnol. Oceanogr. Methods 2023, 21, 625–636. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Vázquez, R.F.; Beven, K.; Feyen, J. GLUE based assessment on the overall predictions of a MIKE SHE application. Water Resour. Manag. 2009, 23, 1325–1349. [Google Scholar] [CrossRef]
- Julzarika, A.; Aditya, T.; Subaryono, S.; Harintaka, H.; Dewi, R.S.; Subehi, L. Integration of the latest Digital Terrain Model (DTM) with Synthetic Aperture Radar (SAR) Bathymetry. J. Degrad. Min. Lands Manag. 2021, 8, 2759–2768. [Google Scholar] [CrossRef]
- Kim, D.; Kim, J.; Wang, W.; Lee, H.; Kim, H.S. On Hypsometric Curve and Morphological Analysis of the Collapsed Irrigation Reservoirs. Water 2022, 14, 907. [Google Scholar] [CrossRef]
- Messager, M.L.; Lehner, B.; Grill, G.; Nedeva, I.; Schmitt, O. Estimating the volume and age of water stored in global lakes using a geo-statistical approach. Nat. Commun. 2016, 7, 13603. [Google Scholar] [CrossRef]
- Staehr, P.A.; Baastrup-Spohr, L.; Sand-Jensen, K.; Stedmon, C. Lake metabolism scales with lake morphometry and catchment conditions. Aquat. Sci. 2012, 74, 155–169. [Google Scholar] [CrossRef]
- Post, D.M.; Pace, M.L.; Hairston, N.G. Ecosystem size determines food-chain length in lakes. Nature 2000, 405, 1047–1049. [Google Scholar] [CrossRef] [PubMed]
- Dodson, S.I.; Arnott, S.E.; Cottingham, K.L. The Relationship In Lake Communities between Primary Productivity and Species Richness. Ecology 2000, 81, 2662–2679. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vázquez, R.F.; Mosquera, P.V.; Hampel, H. Bathymetric Modelling of High Mountain Tropical Lakes of Southern Ecuador. Water 2024, 16, 1142. https://doi.org/10.3390/w16081142
Vázquez RF, Mosquera PV, Hampel H. Bathymetric Modelling of High Mountain Tropical Lakes of Southern Ecuador. Water. 2024; 16(8):1142. https://doi.org/10.3390/w16081142
Chicago/Turabian StyleVázquez, Raúl F., Pablo V. Mosquera, and Henrietta Hampel. 2024. "Bathymetric Modelling of High Mountain Tropical Lakes of Southern Ecuador" Water 16, no. 8: 1142. https://doi.org/10.3390/w16081142
APA StyleVázquez, R. F., Mosquera, P. V., & Hampel, H. (2024). Bathymetric Modelling of High Mountain Tropical Lakes of Southern Ecuador. Water, 16(8), 1142. https://doi.org/10.3390/w16081142