New Underwater Image Enhancement Algorithm Based on Improved U-Net

Abstract
:1. Introduction

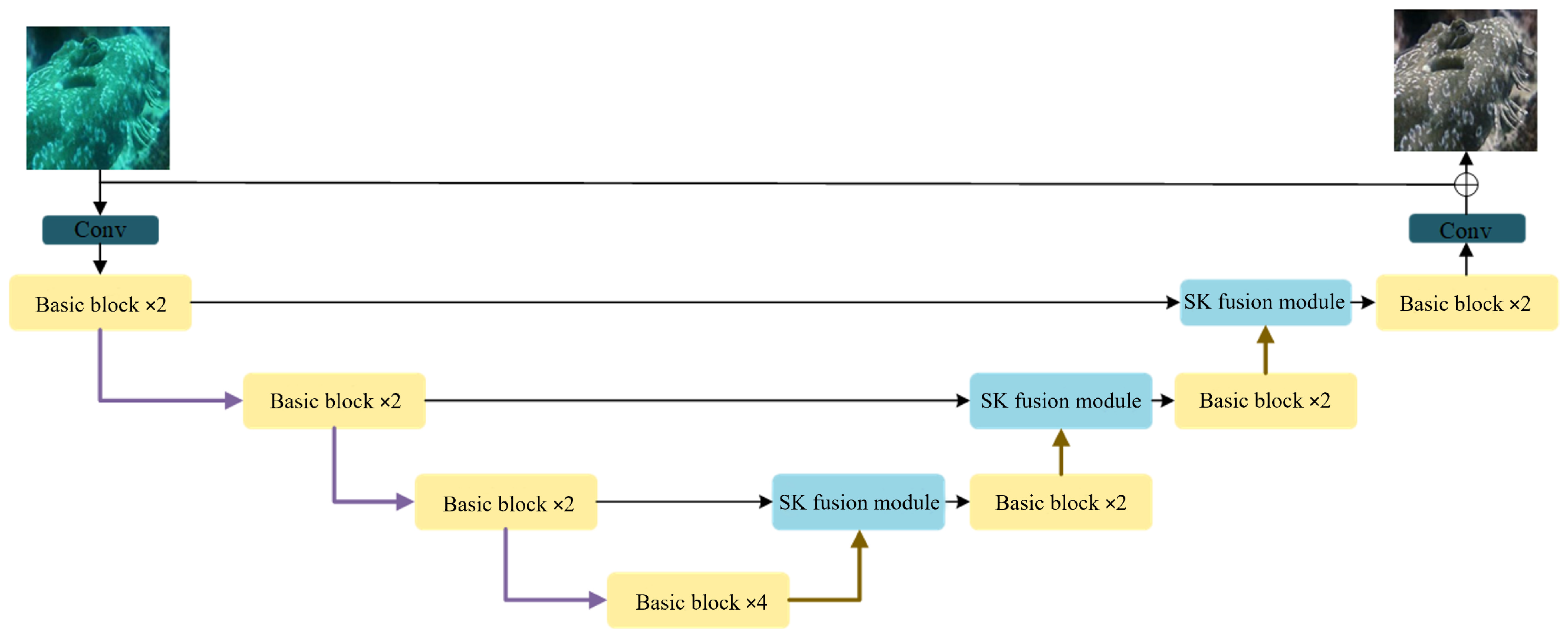
2. Network Architecture
2.1. General Overview of the Model
2.2. Basic Block
2.3. SK Fusion Module
2.4. Loss Functions
3. Experiments
3.1. Training Setup
3.2. Training Strategies
3.3. Reference Metrics
3.4. Comparison Test
4. Discussion
4.1. Basic Fast Internal Component Ablation Experiments
4.1.1. Normalization Method
4.1.2. Attention Mechanism
4.1.3. Activation Functions
4.2. SK Fusion Module
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Raveendran, S.; Patil, M.D.; Birajdar, G.K. Underwater image enhancement: A comprehensive review, recent trends, challenges and applications. Artif. Intell. Rev. 2021, 54, 5413–5467. [Google Scholar] [CrossRef]
- Moghimi, M.K.; Mohanna, F. Real-time underwater image enhancement: A systematic review. J. Real-Time Image Process. 2021, 18, 1509–1525. [Google Scholar] [CrossRef]
- Anwar, S.; Li, C. Diving deeper into underwater image enhancement: A survey. Signal Process. Image Commun. 2020, 89, 115978. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark hannel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341. [Google Scholar] [PubMed]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- Song, W.; Wang, Y.; Huang, D.; Tjondronegoro, D. A rapid scene depth estimation model based on underwater light attenuation prior for underwater image restoration. In Advances in Multimedia Information Processing–PCM 2018, Proceedings of the 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; Proceedings, Part I 19; Springer: Berlin/Heidelberg, Germany, 2018; pp. 678–688. [Google Scholar]
- Iqbal, K.; Salam, R.A.; Osman, A.; Talib, A.Z. Underwater Image Enhancement Using an Integrated Colour Model. IAENG Int. J. Comput. Sci. 2007, 34. [Google Scholar]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Sun, B.; Mei, Y.; Yan, N.; Chen, Y. UMGAN: Underwater image enhancement network for unpaired image-to-image translation. J. Mar. Sci. Eng. 2023, 11, 447. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Huang, Z.; Li, J.; Hua, Z.; Fan, L. Underwater image enhancement via adaptive group attention-based multiscale cascade transformer. IEEE Trans. Instrum. Meas. 2022, 71, 1–18. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef] [PubMed]
- Ba, J.L. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications (2017). arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wang, J.; Li, P.; Deng, J.; Du, Y.; Zhuang, J.; Liang, P.; Liu, P. CA-GAN: Class-condition attention GAN for underwater image enhancement. IEEE Access 2020, 8, 130719–130728. [Google Scholar] [CrossRef]
- Xue, L.; Zeng, X.; Jin, A. A novel deep-learning method with channel attention mechanism for underwater target recognition. Sensors 2022, 22, 5492. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple baselines for image restoration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 17–33. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 510–519. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NIQE | UCIQE | Param (M) | FLOPS (G) | PSNR | SSIM | |
|---|---|---|---|---|---|---|
| HE | 5.192 | 0.407 | - | - | 18.733 | 0.683 |
| UDCP | 4.927 | 0.411 | - | - | 18.852 | 0.695 |
| ULAP | 4.591 | 0.418 | - | - | 19.034 | 0.716 |
| ICM | 4.405 | 0.426 | - | - | 19.252 | 0.732 |
| CycleGan | 5.037 | 0.380 | 42.410 | 7.841 | 18.792 | 0.705 |
| UGan | 5.082 | 0.425 | 18.155 | 54.404 | 18.807 | 0.697 |
| FunIEGAN | 4.412 | 0.417 | 10.239 | 7.020 | 20.129 | 0.850 |
| UMGan | 4.618 | 0.440 | 38.745 | 13.149 | 19.239 | 0.764 |
| U-Net | 4.459 | 0.419 | 28.513 | 30.618 | 19.878 | 0.805 |
| Ours | 4.393 | 0.430 | 9.270 | 2.741 | 21.565 | 0.879 |
| BN | LN | Attention Mechanism | ReLU | GeLU | NIQE | UCIQE |
|---|---|---|---|---|---|---|
| ✓ | - | - | - | - | 4.414 | 0.426 |
| - | ✓ | - | - | - | 4.394 | 0.429 |
| - | ✓ | PA-CA | ✓ | - | 4.402 | 0.368 |
| - | ✓ | CA | ✓ | - | 4.399 | 0.432 |
| - | ✓ | SCA | ✓ | - | 4.395 | 0.429 |
| - | ✓ | PA-CA | - | ✓ | 4.403 | 0.432 |
| - | ✓ | CA | - | ✓ | 4.389 | 0.431 |
| - | ✓ | SCA | - | ✓ | 4.378 | 0.445 |
| BN | LN | Attention Mechanism | ReLU | GeLU | PSNR | SSIM |
|---|---|---|---|---|---|---|
| ✓ | - | - | - | - | 19.132 | 0.704 |
| - | ✓ | - | - | - | 20.024 | 0.792 |
| - | ✓ | PA-CA | ✓ | - | 20.560 | 0.850 |
| - | ✓ | CA | ✓ | - | 20.793 | 0.864 |
| - | ✓ | SCA | ✓ | - | 21.122 | 0.876 |
| - | ✓ | PA-CA | - | ✓ | 20.545 | 0.833 |
| - | ✓ | CA | - | ✓ | 21.253 | 0.882 |
| - | ✓ | SCA | - | ✓ | 21.337 | 0.887 |
| Method | NIQE | UCIQE |
|---|---|---|
| Tandem Splicing | 4.921 | 0.389 |
| Summation | 5.048 | 0.421 |
| SK Fusion Modules | 4.394 | 0.431 |
| Method | PSNR | SSIM |
|---|---|---|
| Tandem Splicing | 18.863 | 0.685 |
| Summation | 18.857 | 0.689 |
| SK Fusion Modules | 21.273 | 0.884 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, S.; Geng, Z.; Xie, Y.; Zhang, Z.; Yan, H.; Zhou, X.; Jin, H.; Fan, X. New Underwater Image Enhancement Algorithm Based on Improved U-Net. Water 2025, 17, 808. https://doi.org/10.3390/w17060808
Zhu S, Geng Z, Xie Y, Zhang Z, Yan H, Zhou X, Jin H, Fan X. New Underwater Image Enhancement Algorithm Based on Improved U-Net. Water. 2025; 17(6):808. https://doi.org/10.3390/w17060808
Chicago/Turabian StyleZhu, Sisi, Zaiming Geng, Yingjuan Xie, Zhuo Zhang, Hexiong Yan, Xuan Zhou, Hao Jin, and Xinnan Fan. 2025. "New Underwater Image Enhancement Algorithm Based on Improved U-Net" Water 17, no. 6: 808. https://doi.org/10.3390/w17060808
APA StyleZhu, S., Geng, Z., Xie, Y., Zhang, Z., Yan, H., Zhou, X., Jin, H., & Fan, X. (2025). New Underwater Image Enhancement Algorithm Based on Improved U-Net. Water, 17(6), 808. https://doi.org/10.3390/w17060808