
An Improved Method to Identify Built-Up Areas of Urban Agglomerations in Eastern and Western China Based on Multi-Source Data Fusion


Abstract
:1. Introduction
- (1)
- Urban agglomeration built-up area identification. The built-up area is identified from three dimensions: social economy, natural coverage, and traffic accessibility.
- (2)
- Delineation of the evaluation of recognition results. We conduct qualitative and quantitative assessments on the reliability in terms of consistency and integrity of built-up area delineation results.
- (3)
- Summary of the built-up area characteristics of urban agglomerations in different regions. Using spatial analysis techniques, we conduct a comparative analysis of representative urban agglomerations in eastern and western China.
- (1)
- Quantitative and comparative analysis of the development status of the Yangtze River Delta and Chengdu–Chongqing urban agglomerations has broadened the scope of the existing research and improved the lack of scientific data support for qualitative research on urban agglomerations’ development.
- (2)
- Three different technical routes were adopted to determine the built-up area boundaries of the Yangtze River Delta and Chengdu–Chongqing urban agglomeration from multiple perspectives, which improved the problem that a single index could not accurately reflect the internal heterogeneity of the urban edge.
- (3)
- Multi-source data fusion method is used to improve the accuracy of urban agglomeration built-up area identification.
2. Materials and Methods
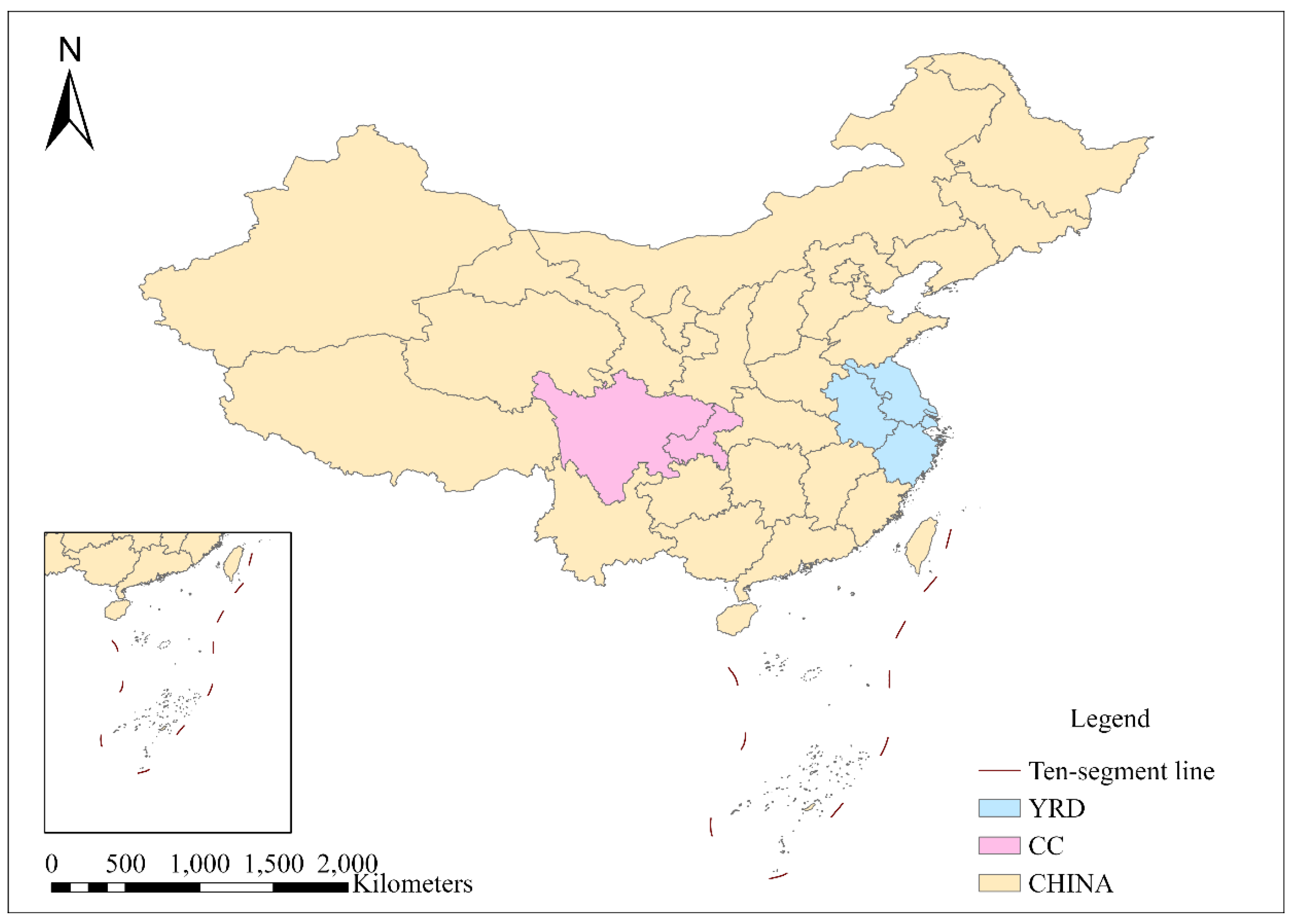
2.1. Study Area
2.2. Study Data
2.2.1. Land Use Data
2.2.2. Night-Time Light Data
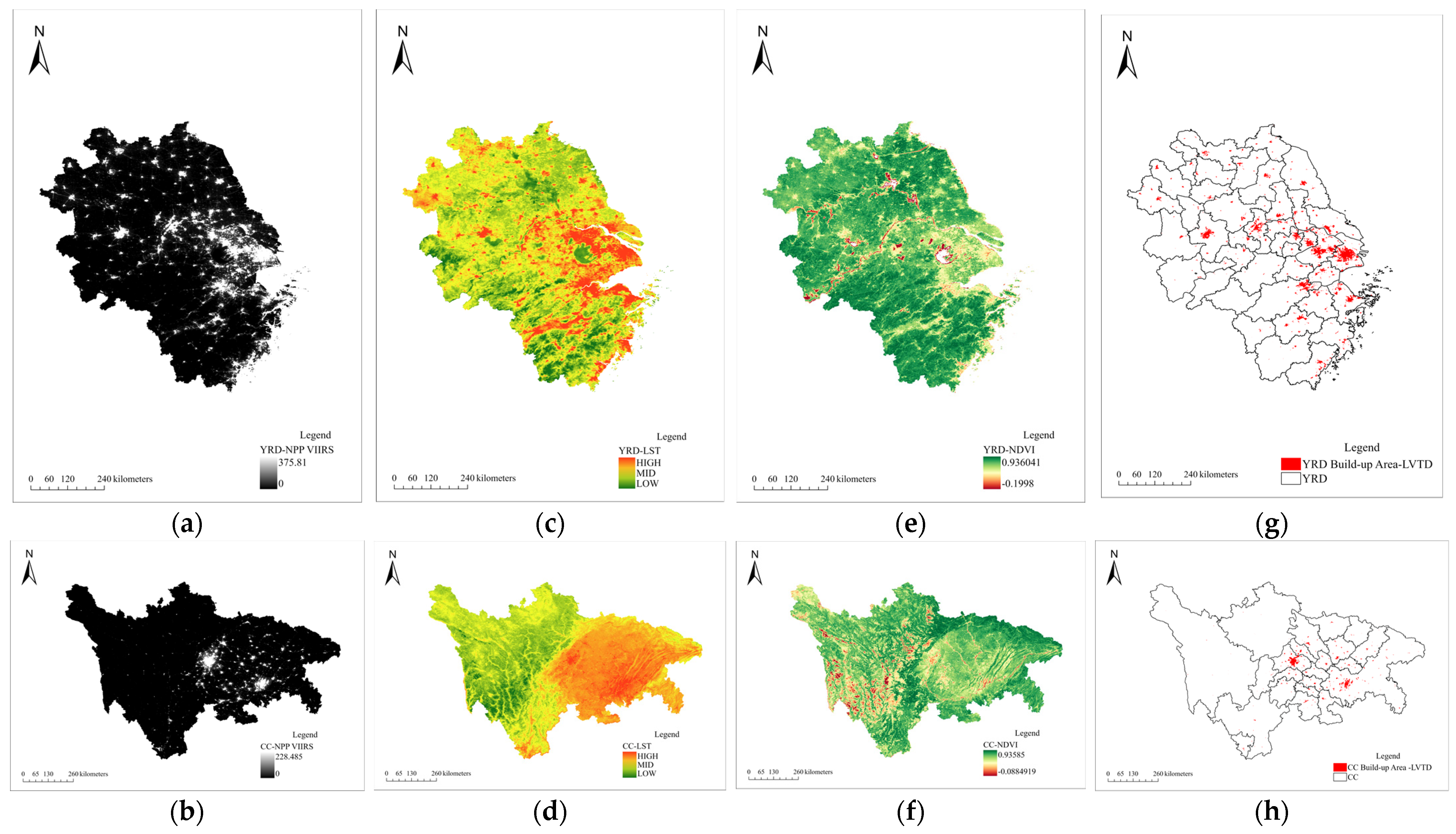
2.2.3. LST and NDVI Data
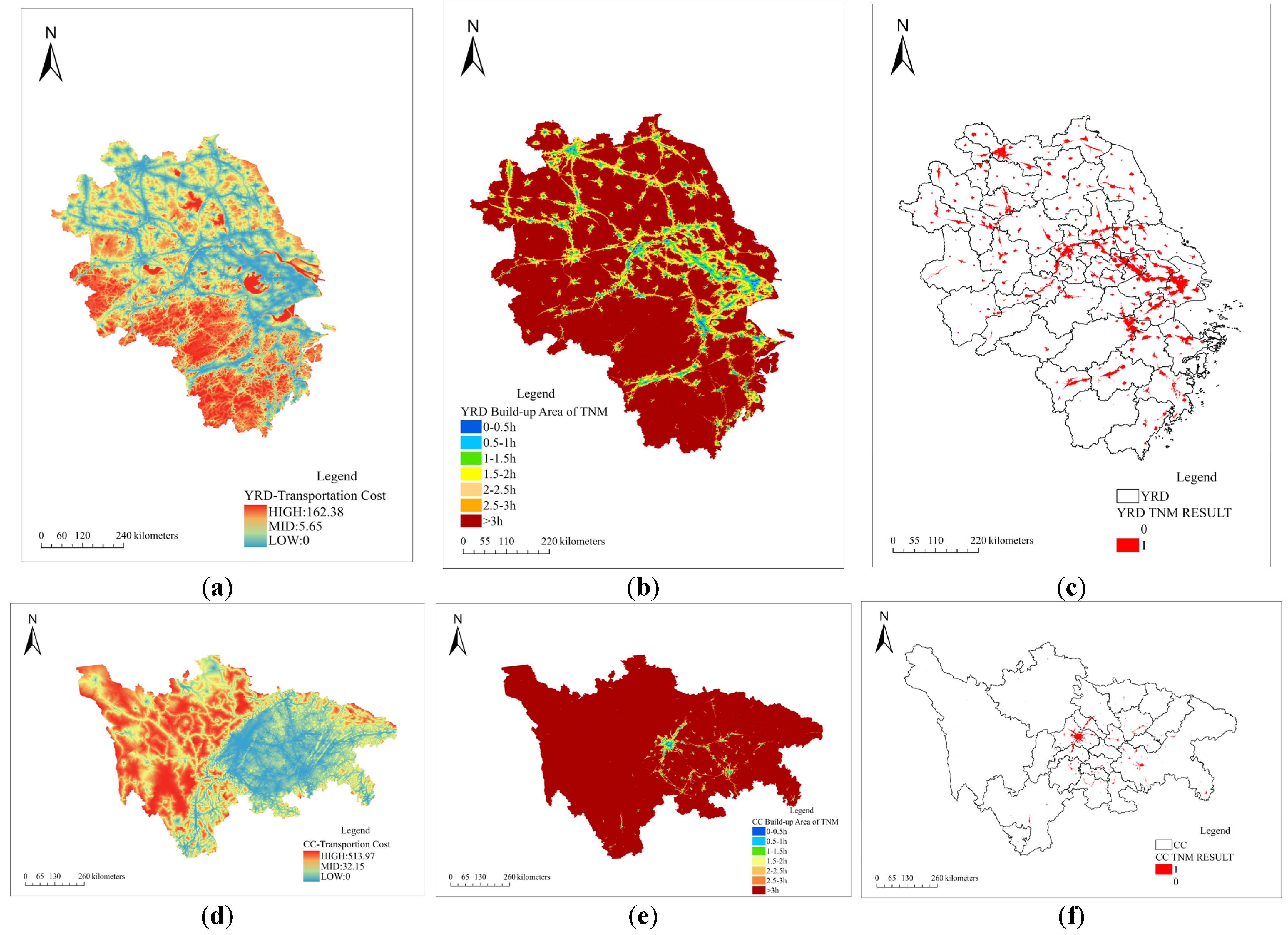
2.2.4. Road Network and POI Data
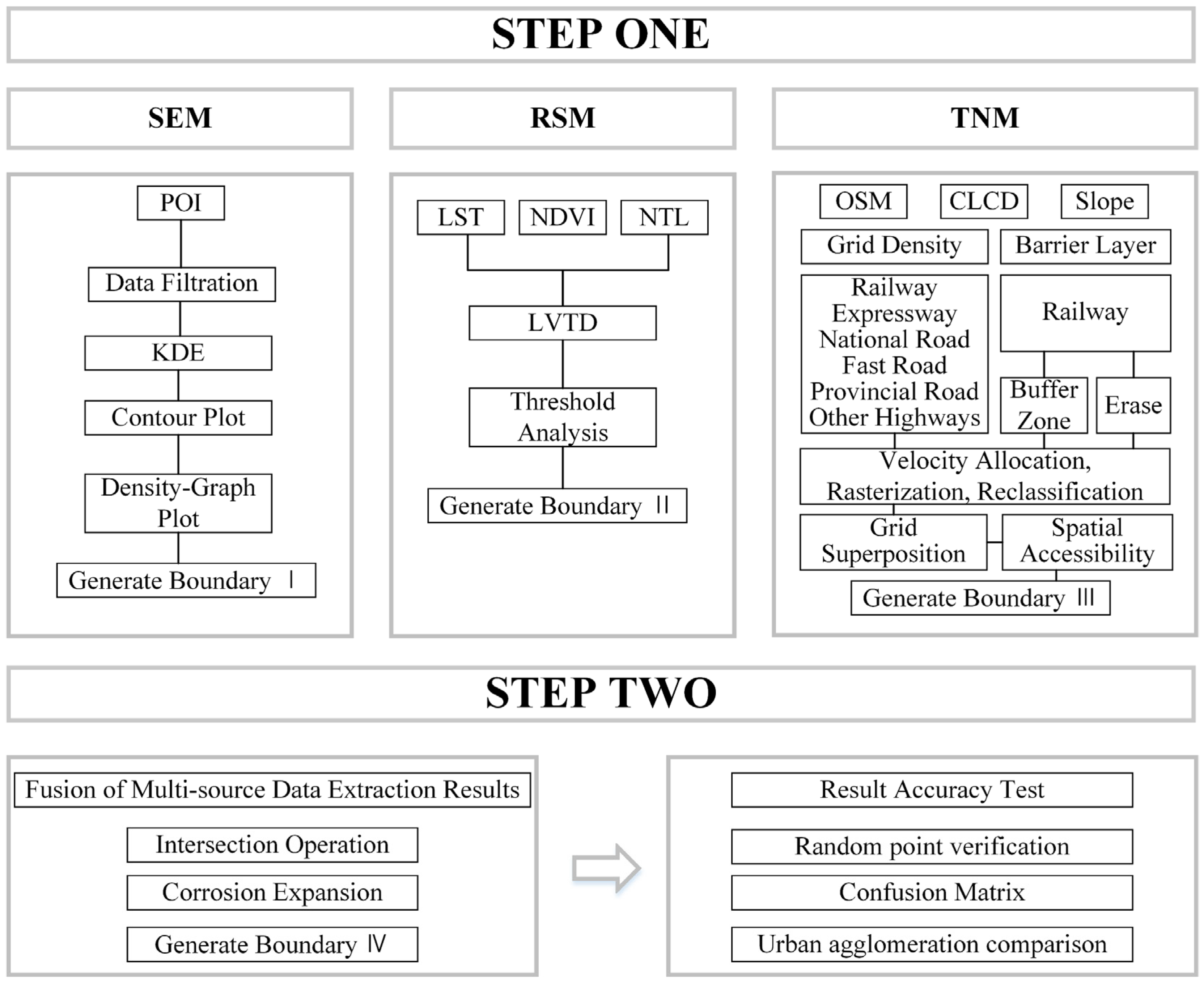
2.3. Method
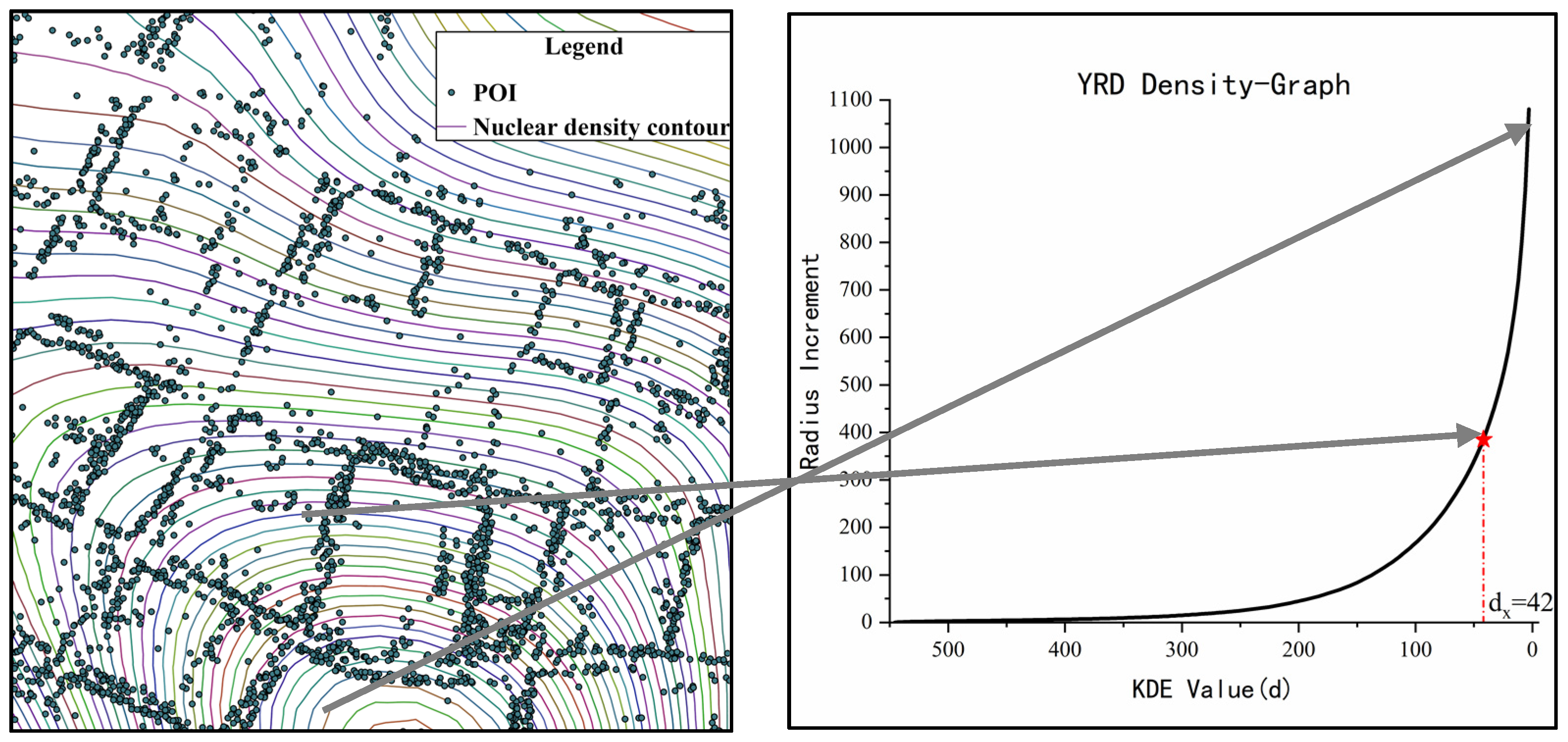
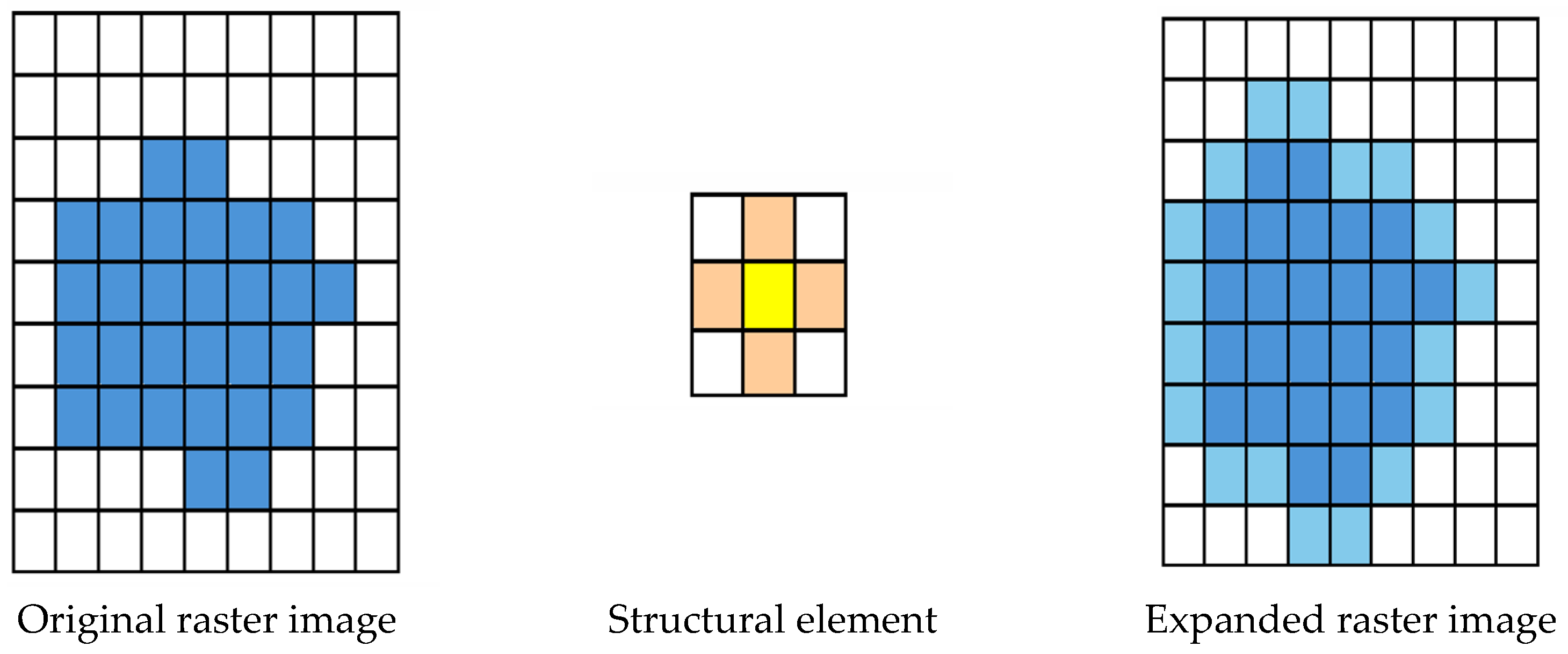
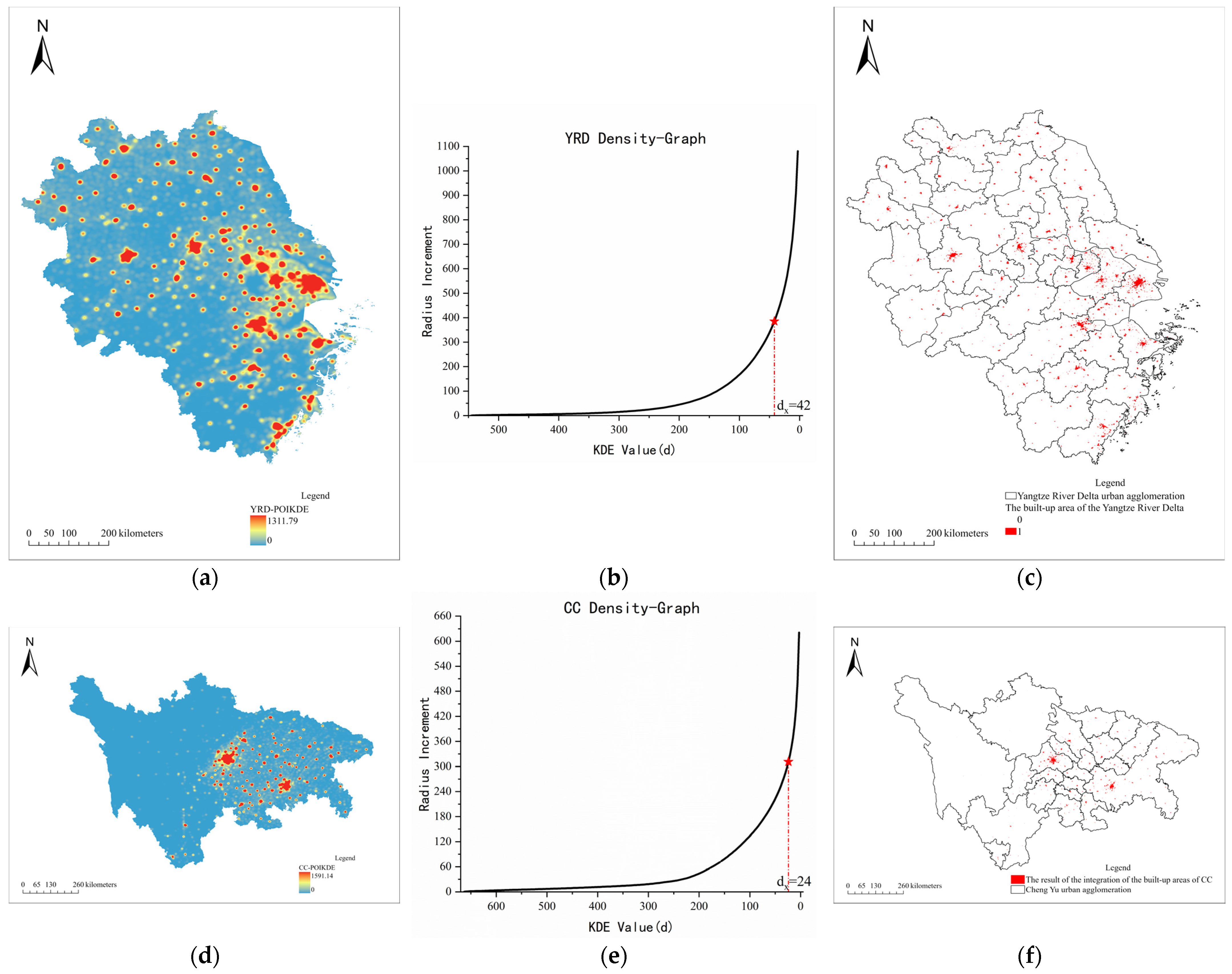
2.3.1. Recognition Method Based on POI (POIM)
2.3.2. Recognition Method Based on Remote Sensing Data (RSM)
2.3.3. Recognition Method Based on Traffic Road (TRM)
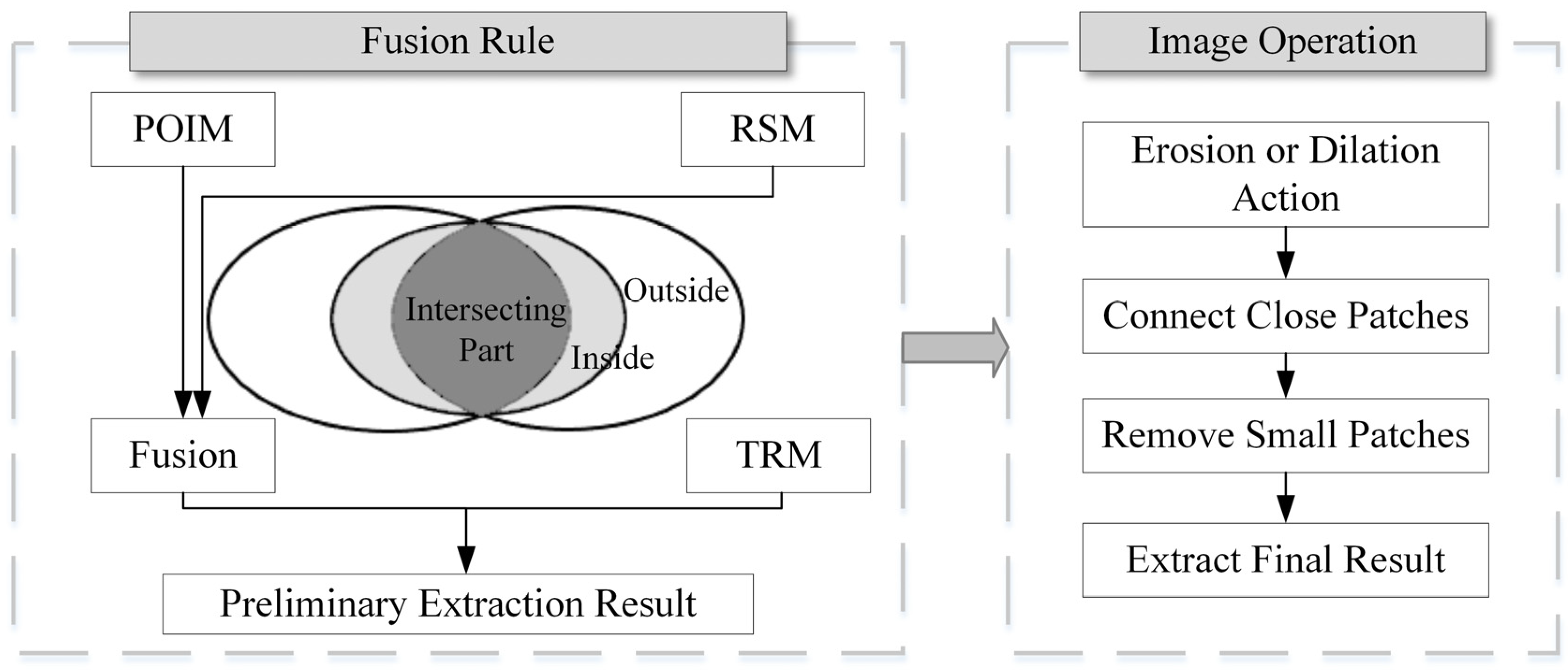
2.3.4. Fusion Method of Multi-Source Data Extraction Results
2.3.5. Accuracy Test Method
3. Results
3.1. Identification Result
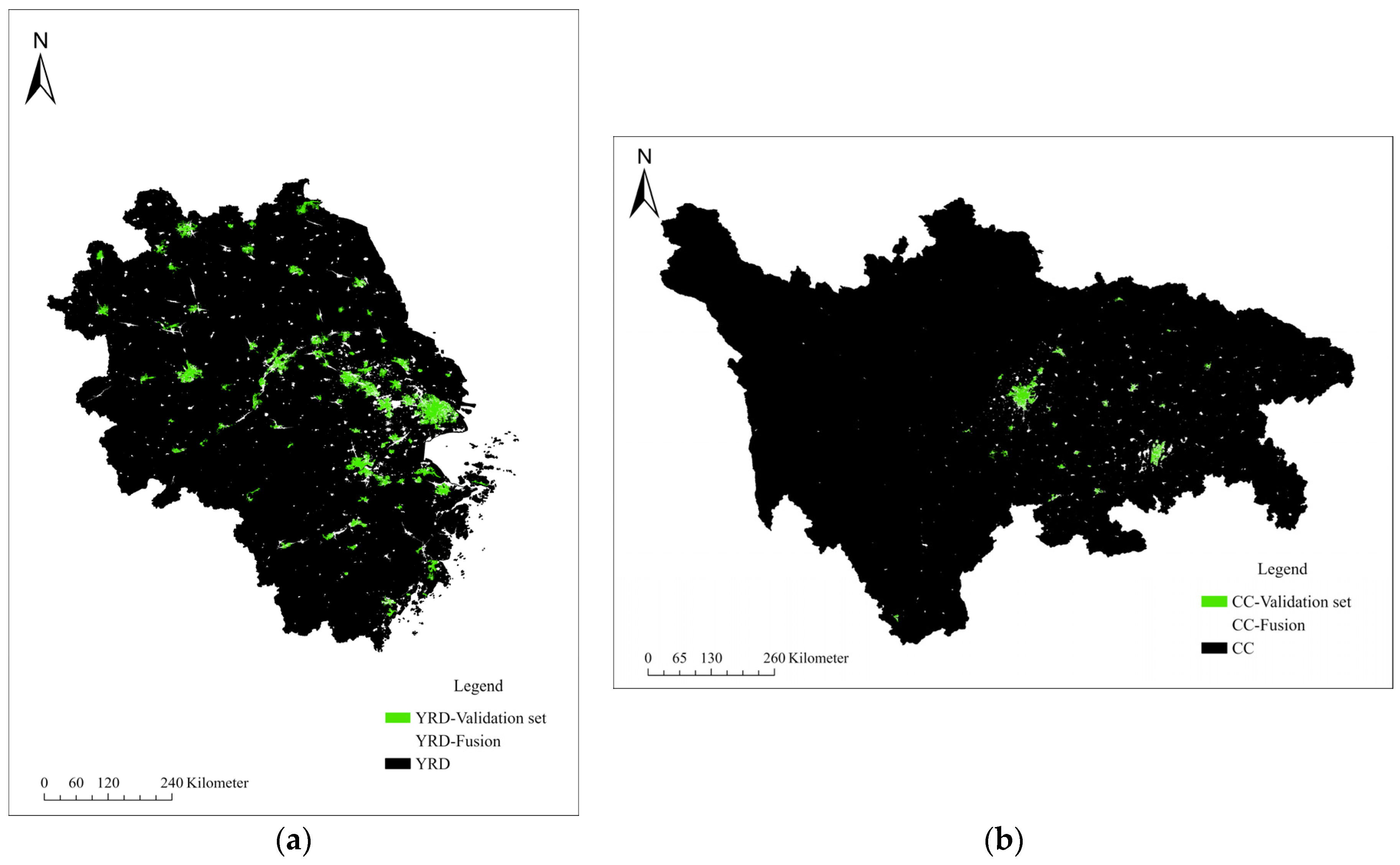
3.2. Fusion Result
4. Discussion
4.1. Comparison with Previous Studies
4.2. Contributions to the Urban Agglomerations in China
4.2.1. Planning Suggestions for the CC Urban Agglomeration
4.2.2. Planning Suggestions for the YRD Urban Agglomeration
4.2.3. Contributions to the Overall Planning in China
4.3. Limits and Prospects
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tan, M.; Lu, C. Distribution of China City Size Expressed by Urban Built-up Area. Acta Geogr. Sin. 2003, 58, 285–293. [Google Scholar]
- Fang, C. Progress and the future direction of research into urban agglomeration in China. Acta Geogr. Sin. 2014, 69, 1130–1144. [Google Scholar]
- Tan, M.; Li, X.; Lu, C. Analysis of the driving force of urban land expansion in China. Econ. Geogr. 2003, 23, 5. [Google Scholar] [CrossRef]
- Fang, C. The Basic Law of the Formation and Expansion in Urban Agglomerations. Geogr. Sci. 2019, 29, 1699–1712. [Google Scholar] [CrossRef]
- Mei, Z. Research on the delineation method of built-up area under territorial spatial planning. In Urban Planning Society of China. People’s City, Planning Empowerment—Proceedings of China Urban Planning Annual Conference; Urban Planning Society of China: Beijing, China, 2022; Volume 2023, p. 8. [Google Scholar]
- Shi, K.; Huang, C.; Yu, B.; Yin, B.; Huang, Y.; Wu, J. Evaluation of NPP-VIIRS Night-Time Light Composite Data for Extracting Built-up Urban Areas. Remote Sens. 2014, 5, 358–366. [Google Scholar] [CrossRef]
- Hu, T.; Huang, X.; Li, D.; Jin, S.; Yan, Q. Comprehensive evaluation of the urban built-up areas mapping ability from Luojia 1-01 nighttime light imagery over China. Acta Geod. Cartogr. Sin. 2023, 52, 432–442. [Google Scholar]
- Ascher, C.S.; Geddes, P. The Outlook Tower Association, E. Cities in Evolution. Land Econ. 1951, 27, 83–84. [Google Scholar] [CrossRef]
- O’Neill, P. Global city-regions: Trends, theory, policy. Area 2003, 35, 326–327. [Google Scholar] [CrossRef]
- Yu, Q.; Li, M.; Li, Q.; Wang, Y.; Chen, W. Economic agglomeration and emissions reduction: Does high agglomeration in China’s urban clusters lead to higher carbon intensity? Urban Clim. 2022, 43, 101174. [Google Scholar] [CrossRef]
- Denis, P.-Y. Hall, Peter (1984) The World Cities. London, Weidenfeld and Nicolson, Third Edition, 276 P. Cahiers Géographie Québec 2012, 29, 441. [Google Scholar] [CrossRef]
- Ning, Y.-M. Definition of Chinese Metropolitan Areas and Large Urban Agglomerations: Role of Large Urban Agglomerations in Regional Development. Sci. Geogr. Sin. 2011, 31, 257–263. [Google Scholar]
- Xu, Z.; Gao, X. A novel method for identifying the boundary of urban built-up areas with POI data. Acta Geogr. Sin. 2016, 71, 928–939. [Google Scholar]
- Bode, E. Delineating metropolitan areas using land prices. Reg. Sci. 2010, 48, 131–163. [Google Scholar] [CrossRef]
- Li, K.; Niu, X. Delineation of the Shanghai Megacity Region of China from a Commuting Perspective: Study Based on Cell Phone Network Data in the Yangtze River Delta. Urban Plan. Dev. 2021, 147, 04021022. [Google Scholar] [CrossRef]
- Bosker, M.; Park, J.; Roberts, M. Definition matters. Metropolitan areas and agglomeration economies in a large-developing country. Urban Econ. 2021, 125, 103275. [Google Scholar] [CrossRef]
- Zhen, F.; Cao, Y.; Qin, X.; Wang, B. Delineation of an urban agglomeration boundary based on Sina Weibo microblog ‘check-in’ data: A case study of the Yangtze River Delta. Cities 2017, 60, 180–191. [Google Scholar]
- Chen, J.; Zhuo, L.; Shi, P.; Toshiaki, I. The Study on Urbanization Process in China Based on DMSP/OLS Data: Development of a Light Index for Urbanization Level Estimation. J. Remote Sens. 2003, 3, 168–175. [Google Scholar]
- Mu, F.; Zhang, Z.; Chi, Y.; Liu, B.; Zhou, Q. Dynamic Monitoring of Built-up Area in Beijing during 1973–2005 Based on Multi-original Remote Sensed Images. J. Remote Sens. 2007, 2, 257–268. [Google Scholar]
- Lou, G.; Chen, Q.; He, K.; Zhou, Y.; Shi, Z. Using Nighttime Light Data and POI Big Data to Detect the Urban Centers of Hangzhou. Remote Sens. 2019, 11, 1821. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, P.; Shi, X. Industrial Agglomeration, Technological Innovation and High-quality Economic Development: Empirical Research based on China’s Five Major Urban Agglomerations. Reform 2022, 4, 68–87. [Google Scholar]
- Fang, C.; Zhou, C.; Wang, Z. Sustainable development strategy and priorities of spatially differentiated development of urban agglomerations along the Yangtze River Economic Belt. Prog. Geogr. 2015, 34, 1398–1408. [Google Scholar]
- Song, J.; Fang, C.; Song, D. Spatial Structure Stability of Urban Agglomerations in China. Acta Geogr. Sin. 2006, 61, 1311–1325. [Google Scholar]
- Yao, Z.; Tu, J.; Niu, H.; Ha, L.; Li, J. The Research on Urban Agglomeration Spatial Structure of Cheng-Yu Economic Zone. Econ. Geogr. 2017, 37, 82–89. [Google Scholar]
- Hu, S.; Tong, L.; Amy, E.F.; Liu, Y. Urban boundary extraction and sprawl analysis using Landsat images: A case study in Wuhan, China. Habitat Int. 2015, 47, 183–195. [Google Scholar] [CrossRef]
- Zhao, W.; Li, Q.; Li, B. Extracting hierarchical landmarks from urban POI data. J. Remote Sens. 2011, 15, 973–988. [Google Scholar]
- Li, F.; Yan, Q.; Zou, Y.; Liu, B. Extraction Accuracy of Urban Built-up Area Based on Nighttime Light Data and POI: A Case Study of Luojia 1-01 and NPP/VIIRS Nighttime Light Images. Geomat. Inf. Sci. Wuhan Univ. 2021, 46, 825–835. [Google Scholar]
- Luqman, M.; Rayner, P.J.; Gurney, K.R. Combining Measurements of Built-up Area, Nighttime Light, and Travel Time Distance for Detecting Changes in Urban Boundaries: Introducing the BUNTUS Algorithm. Remote Sens. 2019, 11, 2969. [Google Scholar] [CrossRef]
- Meng, Y.; Zhou, S.; Nie, Y.; Zeng, H.; Yu, J. Spatial Delimitation of the Urban-Rural Fringe Based on POI and Nighttime Light Data: A Case Study of Wuhan City. Geomat. Inf. Sci. Wuhan Univ. 2023. [Google Scholar] [CrossRef]
- Song, Y.; Jiao, L.; Liu, K.; Xu, G. Analysis of the Factors Affecting the Degree of Urban Expansion: Taking Wuhan City as an Example. Geomat. Inf. Sci. Wuhan Univ. 2021, 46, 417–426. [Google Scholar]
- Lin, M.; Shi, Y.; Chen, Y.; Yu, D.; He, Q.; Wang, L. A study on spatial-temporal features of construction land expansion in Changsha urban area. Geogr. Res. 2007, 26, 265–275. [Google Scholar]
- Yin, X.; Wei, H.; Li, Y. Identification and spatio-temporal variation of county towns’ built-up area of China based on impervious surface dataset. Geogr. Res. 2023, 42, 1492–1505. [Google Scholar]
- Tang, C.; Chen, J.; Xie, Y.; Tang, J.; Zhou, C. Integrated Identification and Spatial Differentiation Mechanism of Urban Built-up Area in Changsha-Zhuzhou-Xiangtan Urban Agglomeration Based on the Multi-source Big Data. Econ. Geogr. 2024, 44, 66–76. [Google Scholar]
- Santra, A.; Mitra, S.S.; Sinha, S.; Routh, S. Performance testing of selected spectral indices in automated extraction of impervious built-up surface features using Resourcesat LISS-III image. Arab. J. Geosci. 2020, 13, 1229. [Google Scholar] [CrossRef]
- Zhu, Y.; Yao, S. The research of urban special evolution of SuWan belt along the Changjiang River. Econ. Geogr. 1999, 19, 6. [Google Scholar]
- Chen, X.; Peng, J.; Liu, Y.; Chen, Y.; Li, T. Measuring spatial expansion and correlations of cities in Beijing-Tianjin-Hebei Urban Agglomeration using DMSP/OLS nighttime light data. Geogr. Res. 2018, 37, 898–909. [Google Scholar]
- Wang, H.; Hu, Z.; Li, F.; Zhou, Y. Research on the Spatial-Temporal Process of Urbanization in Chengdu-Chongqing Region based on Nighttime Light from 2000 to 2018. Remote Sens. Technol. Appl. 2022, 37, 897–907. [Google Scholar]
- Li, Q.; Zheng, B.; Xiong, Y. Spatio-Temporal Expansion of the Dongting Lake Eco-economic Zone Urban Agglomeration Based on Nighttime Light Remote Sensing Data. Econ. Geogr. 2021, 41, 92–102. [Google Scholar]
- Hong, J.; Li, X.; Wei, X.; Jiang, D.; Song, S. Spatial and Temporal Pattern of Urban Built-up Areas in the Yangtze River Economic Belt Based on Data Fusion. Resour. Environ. Yangtze Basin 2021, 30, 2325–2335. [Google Scholar]
- Zhao, P.; Jia, T.; Qin, K.; Shan, J.; Jiao, C. Statistical Analysis on the Evolution of OpenStreetMap Road Networks in Beijing. Phys. A Stat. Mech. Its Appl. 2015, 420, 59–72. [Google Scholar] [CrossRef]
- Yu, W.; Ai, T. The Visualization and Analysis of POI Features under Network Space Supported by Kernel Density Estimation. Acta Geod. Cartogr. Sin. 2015, 44, 82–90. [Google Scholar]
- Wang, G.; Wang, Y.; Li, Y.; Chen, T. Identification of Urban Clusters Based on Multisource Data—An Example of Three Major Urban Agglomerations in China. Land 2023, 12, 1058. [Google Scholar] [CrossRef]
- He, X.; Cao, T.; Zhou, C. Evaluation of Polycentric Spatial Structure in the Urban Agglomeration of the Pearl River Delta (PRD) Based on Multi-Source Big Data Fusion. Remote Sens. 2021, 13, 3639. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, Y. Built-up Areas Extraction Method of Urban Agglomeration in Southern Jiangsu Based on Nighttime Light Remote Sensing Image. Geospat. Inf. 2023, 21, 44–48. [Google Scholar]
- Liu, X.; Ning, X.; Wang, H.; Wang, C.; Zhang, H.; Meng, J. A Rapid and Automated Urban Boundary Extraction Method Based on Nighttime Light Data in China. Remote Sens. 2019, 11, 1126. [Google Scholar] [CrossRef]
- Zhou, Y.; Xie, B.; Zhao, H.; Chen, Y.; Pei, T.; Liu, S. Study on Spatial-temporal Pattern and Dynamic Evolution of City Scale at County Level in China Based on Night-time Light Data. Resour. Environ. Yangtze Basin 2019, 28, 250–260. [Google Scholar]
- Guan, D.; Yang, W.; Zhou, L.; Deng, Z.; Fan, X. Spatio-temporal characteristics and evolutionary trends of urban sprawl based on measuring the multi-dimensional indicators in the Yangtze River Basin, China. Geogr. Res. 2023, 42, 2940–2964. [Google Scholar]
- Ao, Y.; Wu, B.-L.; Bai, Z.-D.; Wang, X.F.; Chen, Z.X. Temporal-spatial Changes of Urban Built-up Area Expansion in Guangdong-Hong Kong-Macao Greater Bay Area, China Based on NPP-VIIRS-like Night Light Data. J. Earth Sci. Environ. 2022, 44, 513–523. [Google Scholar]
- GB/T 50280-98; Standard for Basic Terms of Urban Planning. Ministry of Construction of the People’s Republic of China. China Architecture & Building Press: Beijing, China, 1998.
- Zhang, Y.; Zheng, F.; Liu, Y.; Liu, Y.; Hu, H.; Xu, P. Extracting Urban Built-up Area Based on Impervious Surface Area and POI Data. Sci. Geogr. Sin. 2022, 42, 506–514. [Google Scholar]
- Tan, Y.; Xiong, S.; Li, Y. Automatic extraction of built-up areas from panchromatic and multispectral remote sensing images using double stream deep convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3988–4004. [Google Scholar] [CrossRef]
- Fang, C.; Zhang, G.; Xue, D. High-quality development of urban agglomerations in China and construction of science and technology collaborative innovation community. Acta Geogr. Sin. 2021, 76, 2898–2908. [Google Scholar]
- Lin, J.; Wu, K.; Yang, S. Spatial linkage networks and patterns of urban economic efficiency in the perspective of scaling law: A case study of Yangtze River Delta Urban Agglomeration. Acta Geogr. Sin. 2024, 79, 1391–1411. [Google Scholar]
- Fang, C. China’s Urban Agglomeration and Metropolitan Area Construction Under the New Development Pattern. Econ. Geogr. 2021, 41, 1–7. [Google Scholar]
- Pan, J.; Hu, Y. Measurement of the Efficiency of Coordinated Development of the Four Modernizations for Urban Agglomerations in China. China Popul. Resour. Environ. 2015, 25, 100–107. [Google Scholar]
- Feng, Z.; You, S.; You, Z. Spatial identification and structural characteristics of Chinese urban agglomerations based on traffic big data network. Geogr. Res. 2023, 42, 1729–1742. [Google Scholar]
- Bouzekri, S.; Lasbet, A.A.; Lachehab, A. A New Spectral Index for Extraction of Built-Up Area Using Landsat-8 Data. J. Indian Soc. Remote Sens. 2015, 43, 867–873. [Google Scholar] [CrossRef]
- Shahfahad Mourya, M.; Kumari, B.; Tayyab, M.; Paarcha, A.; Asif; Rahman, A. Indices based assessment of built-up density and urban expansion of fast growing Surat city using multi-temporal Landsat data sets. GeoJournal 2021, 86, 1607–1623. [Google Scholar] [CrossRef]
- Yin, D.; Yu, Q.; Shi, Y. Spatial Aggregation Within the Population and the Upgrading of Traditional Industries in the Great Lakes Megalopolis. J. Beijing Adm. Coll. 2022, 89–99. [Google Scholar]
- Fafchamps, M.; Shilpi, F. The evolution of built-up areas in Ghana since 1975. PLoS ONE 2021, 16, e0250847. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Road Network Type | Speed (km/h) | Speed Cost (min) | Barrier |
|---|---|---|---|
| Railway | 300 | 0.2 | Station |
| Highroad | 120 | 0.5 | / |
| National road, express road | 80 | 0.75 | |
| Provincial road | 60 | 1 | |
| Township road, county road | 40 | 1.5 | |
| Other roads | 30 | 2 |
| Type | POIM | RSM | TRM | Fusion | ||||
|---|---|---|---|---|---|---|---|---|
| TN | 2784 | 92.80% | 2776 | 92.53% | 2767 | 92.23% | 2776 | 92.53% |
| TP | 118 | 3.93% | 166 | 5.53% | 84 | 2.80% | 175 | 5.83% |
| FN | 94 | 3.13% | 46 | 1.53% | 128 | 4.27% | 37 | 1.23% |
| FP | 4 | 0.13% | 12 | 0.40% | 21 | 0.70% | 12 | 0.40% |
| TN | 6956 | 69.56% | 6935 | 69.35% | 6935 | 69.35% | 6932 | 69.32% |
| TP | 1625 | 16.25% | 2358 | 23.58% | 1263 | 12.63% | 2470 | 24.70% |
| FN | 1405 | 14.05% | 672 | 6.72% | 1767 | 17.67% | 560 | 5.60% |
| FP | 14 | 0.14% | 35 | 0.35% | 35 | 0.35% | 38 | 0.38% |
| Type | POIM | RSM | TRM | Fusion | ||||
|---|---|---|---|---|---|---|---|---|
| TN | 2565 | 85.50% | 2549 | 84.97% | 2483 | 82.77% | 2504 | 83.47% |
| TP | 175 | 5.83% | 237 | 7.90% | 184 | 6.13% | 273 | 9.10% |
| FN | 13 | 0.43% | 29 | 0.97% | 95 | 3.17% | 74 | 2.47% |
| FP | 247 | 8.23% | 185 | 6.17% | 238 | 7.93% | 149 | 4.97% |
| TN | 4787 | 47.87% | 4754 | 47.54% | 4746 | 47.46% | 4680 | 46.80% |
| TP | 2259 | 22.59% | 2906 | 29.06% | 1048 | 10.48% | 3363 | 33.63% |
| FN | 2920 | 29.20% | 2273 | 22.73% | 4131 | 41.31% | 1816 | 18.16% |
| FP | 34 | 0.34% | 67 | 0.67% | 75 | 0.75% | 141 | 1.41% |
| POIM | RSM | TRM | Fusion | |||||
|---|---|---|---|---|---|---|---|---|
| 3000 | 10,000 | 3000 | 10,000 | 3000 | 10,000 | 3000 | 10,000 | |
| OA | 96.7333% | 85.8100% | 98.0667% | 92.9300% | 95.0333% | 81.9800% | 98.3667% | 94.0200% |
| P | 96.7213% | 99.1458% | 93.2584% | 98.5374% | 80.0000% | 97.3035% | 93.5829% | 98.4848% |
| R | 55.6604% | 53.6304% | 78.3019% | 77.8218% | 39.6226% | 41.6832% | 82.5472% | 81.5182% |
| F1 | 0.7066 | 0.6961 | 0.8513 | 0.8696 | 0.5300 | 0.5836 | 0.8772 | 0.8920 |
| Kappa | 0.6906 | 0.6140 | 0.8410 | 0.8220 | 0.5069 | 0.4912 | 0.8685 | 0.8512 |
| POIM | RSM | TRM | Fusion | |||||
|---|---|---|---|---|---|---|---|---|
| 3000 | 10,000 | 3000 | 10,000 | 3000 | 10,000 | 3000 | 10,000 | |
| OA | 91.3333% | 70.4600% | 92.8667% | 76.6000% | 88.9000% | 57.9400% | 92.5667% | 80.4300% |
| P | 41.4692% | 98.5172% | 56.1611% | 97.7464% | 43.6019% | 93.3215% | 64.6919% | 95.9760% |
| R | 93.0851% | 43.6185% | 89.0977% | 56.1112% | 65.9498% | 20.2356% | 78.6744% | 64.9353% |
| F1 | 0.5738 | 0.6047 | 0.6890 | 0.7130 | 0.5250 | 0.3326 | 0.7100 | 0.7746 |
| Kappa | 0.5333 | 0.4204 | 0.6510 | 0.5387 | 0.4651 | 0.1815 | 0.6678 | 0.6127 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, X.; Yang, G.; Chen, S. An Improved Method to Identify Built-Up Areas of Urban Agglomerations in Eastern and Western China Based on Multi-Source Data Fusion. Land 2024, 13, 974. https://doi.org/10.3390/land13070974
Lu X, Yang G, Chen S. An Improved Method to Identify Built-Up Areas of Urban Agglomerations in Eastern and Western China Based on Multi-Source Data Fusion. Land. 2024; 13(7):974. https://doi.org/10.3390/land13070974
Chicago/Turabian StyleLu, Xiaoyi, Guang Yang, and Shijun Chen. 2024. "An Improved Method to Identify Built-Up Areas of Urban Agglomerations in Eastern and Western China Based on Multi-Source Data Fusion" Land 13, no. 7: 974. https://doi.org/10.3390/land13070974
APA StyleLu, X., Yang, G., & Chen, S. (2024). An Improved Method to Identify Built-Up Areas of Urban Agglomerations in Eastern and Western China Based on Multi-Source Data Fusion. Land, 13(7), 974. https://doi.org/10.3390/land13070974