We performed an empirical study to evaluate the proposed reviewer recommendation approach. In this section, we first introduce in
Section 5.1 the subject projects used to perform the empirical study. In
Section 5.2, we describe the collected data from the subject projects. In
Section 5.3, we describe the implementation details of the proposed approach. We also introduce existing reviewer recommendation approaches used for comparison with the proposed approach in
Section 5.4. In
Section 5.5, we present the evaluation metric used for evaluating the reviewer recommendation performance. In
Section 5.6, we report and discuss the results of the empirical study. Lastly, we present threats to the validity of this study in
Section 5.7.
5.6. Results & Discussion
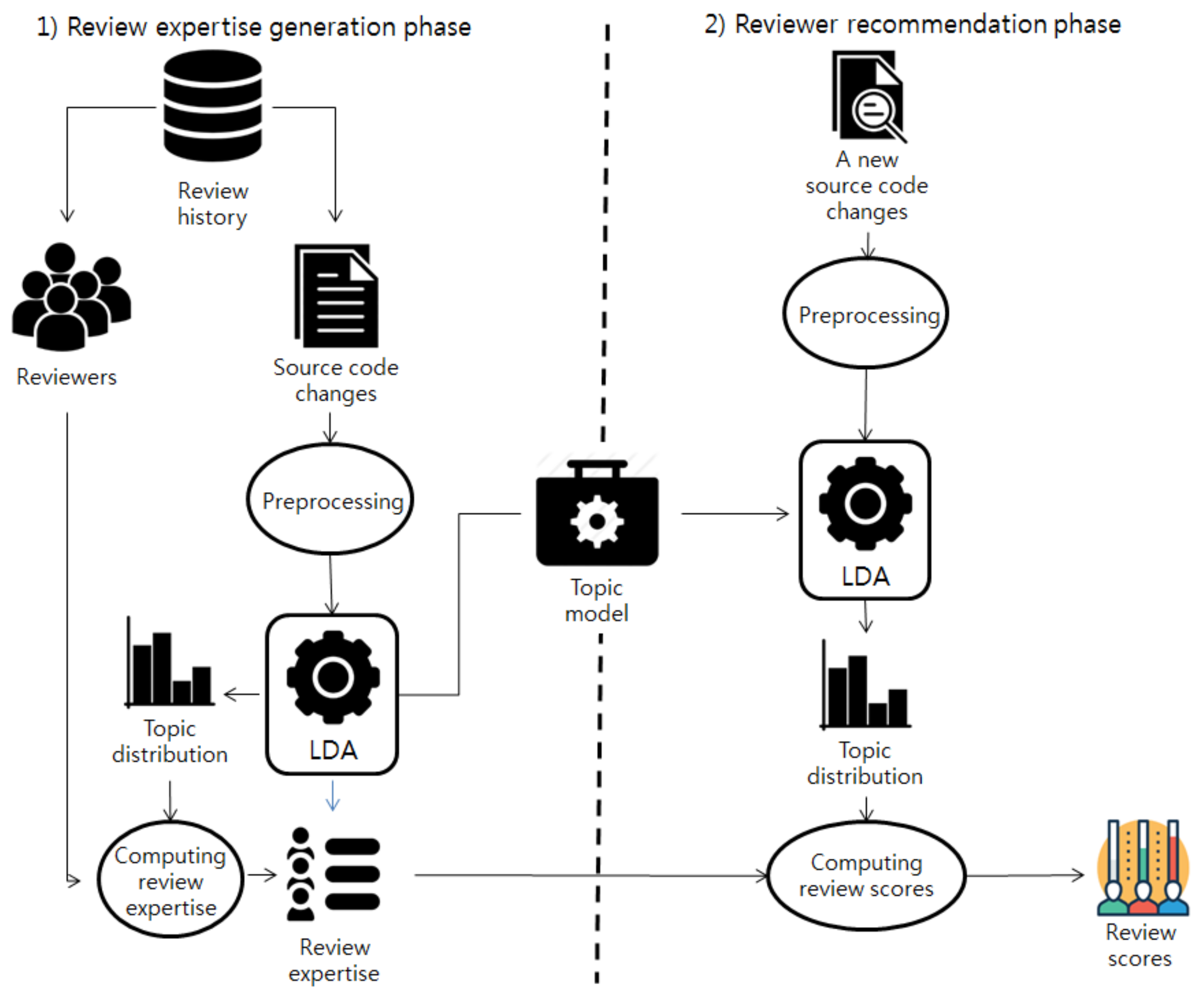
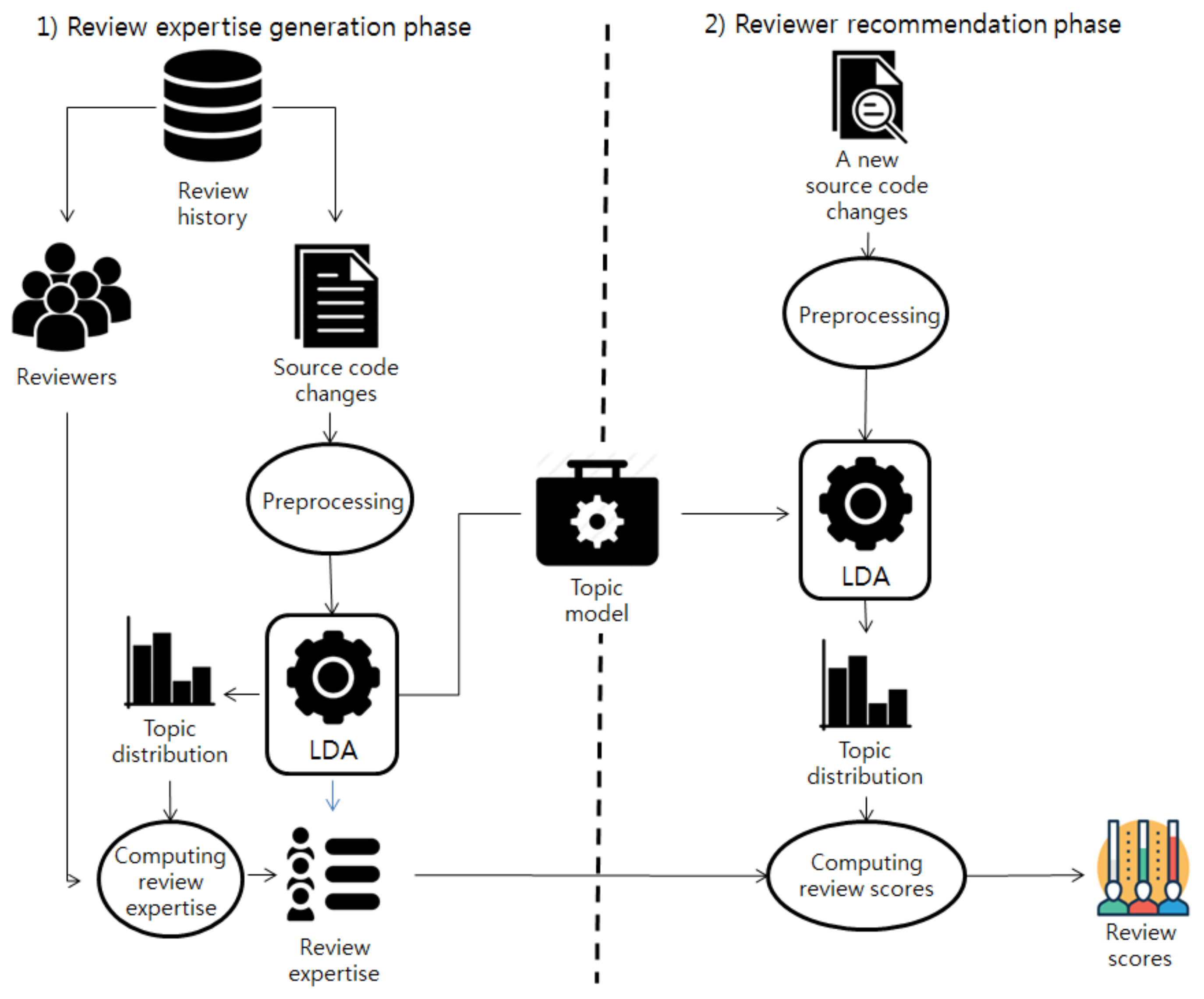
In this subsection, we report the results of the empirical evaluation. For each subject project, we ran the proposed approach, cHRev, and REVFINDER. The three reviewer recommendation approaches all require a training dataset to compute the review scores of the developers. We split the collected review history data in each subject project into a training dataset and an evaluation dataset. We used the review history data from 1 May 2016 to 31 June 2016 as a training dataset and data from 1 July 2016 to 31 October 2016 as the evaluation dataset.
Table 5 shows the number of review data in the training data and the evaluation data.
In this evaluation, we ran the proposed approach by setting K, alpha, and beta to 20, 5.0, and 0.01, respectively. The value of the parameter K is sensitive when analyzing topics of a software project because values that are too large or too small hinder exact topic generation [
24]. Hence, according to [
24], we set the value of K to 20. The values of alpha and beta were set as 5.0 and 0.01, which are default values in MALLET, respectively.
For each subject project, we evaluated the performances of the proposed approach, cHRev, and REVFINDER.
Table 6 shows the results of the top-N accuracy of the approaches in the subject projects. For each subject project, when performing the top-10 recommendations, the proposed approach achieved 0.72, 0.71, 0.60, 0.75, and 0.39 of the top-10 accuracy, whereas cHRev and REVFINDER achieved 0.71, 0.58, 0.56, 0.56, and 0.31 and 0.65, 0.68, 0.62, 0.71, and 0.33 of the top-10 accuracy, respectively. The proposed approach obtained better top-10 accuracy than cHRev and REVFINDER, except for the
xbmc project. On average, the proposed approach obtained 10% better top-10 accuracy than cHRev and obtained 4% better top-10 accuracy than REVFINDER.
Furthermore, we present the following null hypotheses to evaluate the improvement of the recommendation result of the proposed approach compared with cHRev and REVFINDER.
: There is no statistically significant difference between the results of the proposed approach and cHRev.
: There is a statistically significant difference between the results of the proposed approach and cHRev.
: There is no statistically significant difference between the results of the proposed approach and REVFINDER.
: There is a statistically significant difference between the results of the proposed approach and REVFINDER.
We used t.test function in R (
https://www.r-project.org/) package to perform the student’s
t-test with the results of the top-10 accuracy of the recommendation approaches.
Table 7 shows the
t-values and
p-values obtained with the Student’s
t-test. With 95% confidence, we reject
in rails, node, and tensorflow and also reject
in bitcoin, node, and tensorflow. The results show that the proposed approach has improved performance compared to cHRev in rails, node, and tensorflow and compared to cHRev and REVFINDER in bitcoin, node, and tensorflow.
In the bitcoin project, there was extremely little difference in the top-10 accuracy between the proposed approach and cHRev. However, in the results of the top-3 accuracy, cHRev obtained the most superior performance and the proposed approach obtained the second best performance, followed by REVFINDER. The differences of the top-3 accuracy of the proposed approach and REVFIDNER with cHRev are 27% and 37%, respectively. To understand why cHRev could obtain the most superior performance, we manually investigated the recommendation results in the bitcoin project. For the recommendation results, we compared the top-3 lists of cHRev and the proposed approach and confirmed that actual reviewers who have extremely little review history were involved only in the top-3 lists of cHRev. In general, the developers who have much more review history should be recommended more than those having less review history because the developers have reviewing experiences in multiple source files. The proposed approach and REVFINDER are basically designed to assign a high review score to such developers. Therefore, the developers who have little review history are mostly located with low ranks on the recommendation list by the proposed approach and REVFINDER. This caused the proposed approach and REVFINDER to have lower top-5 recommendation accuracy than cHRev. However, the proposed approach and REVFINDER outperformed cHRev in other projects.
Overall, the proposed approach showed improved performance compared to REVFINDER in the subject projects. To check out the advantage of the proposed approach in reviewer recommendation and the reason that the proposed approach could obtain better recommendation performance than REVFINDER, we also investigated the recommendation results of the proposed approach and REVFINDER in the bitcoin project. We found that REVFINDER had a limitation in recommending the correct reviewers for the source file “src/main.cpp”. In the bitcoin project, the source file is one of the most often changed and reviewed source files. The source file was changed 134 times and reviewed by 40 developers from 1 May 2016 to 31 June 2016. It is difficult to select some appropriate reviewers among the developers with only their review expertise of the file path similarity or review count because most of the developers have a similar review experience for the source file. On the other hand, the proposed approach can complement such a limitation by considering the review expertise of the developers for the topic distribution of the source code change of the source file. In the actually performed recommendation by the proposed approach for the commit fe6f4056bb1e2be4b0fd84bb1752141b8bef38, which contained the source code change of the source file “src/main.cpp”, an actual reviewer to the commit was precisely recommended within the top-5 according to his review expertise on the topic distribution of the source code change of the source file. The recommended reviewer indeed had high review expertise of the dominant topic of the source code change of the source file “src/main.cpp”.
In this empirical study, we showed that it is effective to consider the information of topics of source code changes reviewed by developers in reviewer recommendation. The results showed that the file path similarity and review count based reviewer recommendation approaches have limitations in recommending some reviewers. We believe that the proposed approach can complement the limitations of cHRev and REVFINDER and can improve the code review process of a software project.





{kind=link}
{kind=link}
{kind=link}