Applying Genetic Programming with Similar Bug Fix Information to Automatic Fault Repair


Abstract
:1. Introduction
- As developers’ workloads increase owing to many daily bugs, they may spend more time debugging to fix these. If an automatic fault repair technique is provided to fix bugs, program debugging time and cost can be reduced.
- Developers may make mistakes in debugging the program source code. As a result, they may generate incorrect program patches. Thus, if an automatic fault repair technique that generates the correct patch is provided, software quality will improve significantly.
- If bug reporters give descriptions with helpful information to developers such as stack trace and scenario reproduction, the developers can trace and fix the bugs easily. However, if the bug reports contain insufficient information [2], the developers may have difficulty debugging. Thus, it is expected that the automatic fault repair with similar bug fix information can effectively fix the bugs despite lacking descriptions.
- The bug fixing time and effort can be reduced as we support automatic fault repair.
- The quality of bug fixing can be improved as we utilize similar bug fix information with GP to generate program patches.
- We perform a small case of study using our model in IntroClass [11]. The result will likely generate a correct patch.
2. Background Knowledge
3. Related Work
- If we do not consider bug fix information, the buggy code cannot be fixed correctly by GP. In this paper, we first find the most similar buggy codes related to the new given buggy code in order to find the related fixed code. Thus, we can generate a program patch for the buggy program.
- If a bug pattern and template are adopted, the various bugs that do not exist in the proposed pattern will not be fixed. Thus, we utilized a buggy code and a related fixed code in order to fix various buggy codes.
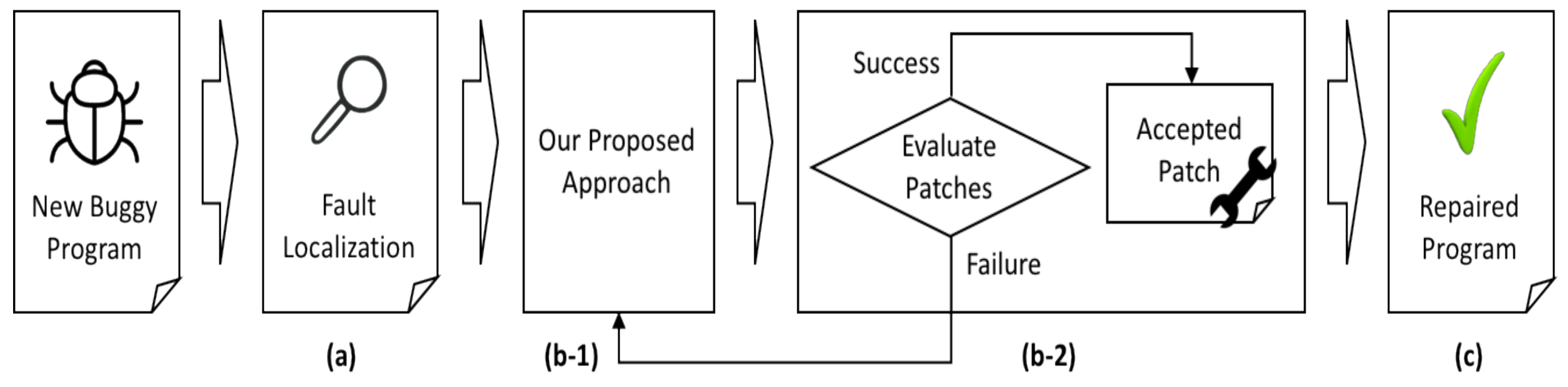
4. Applying Genetic Programming with Similar Bug Fix Information
4.1. Fault Localization
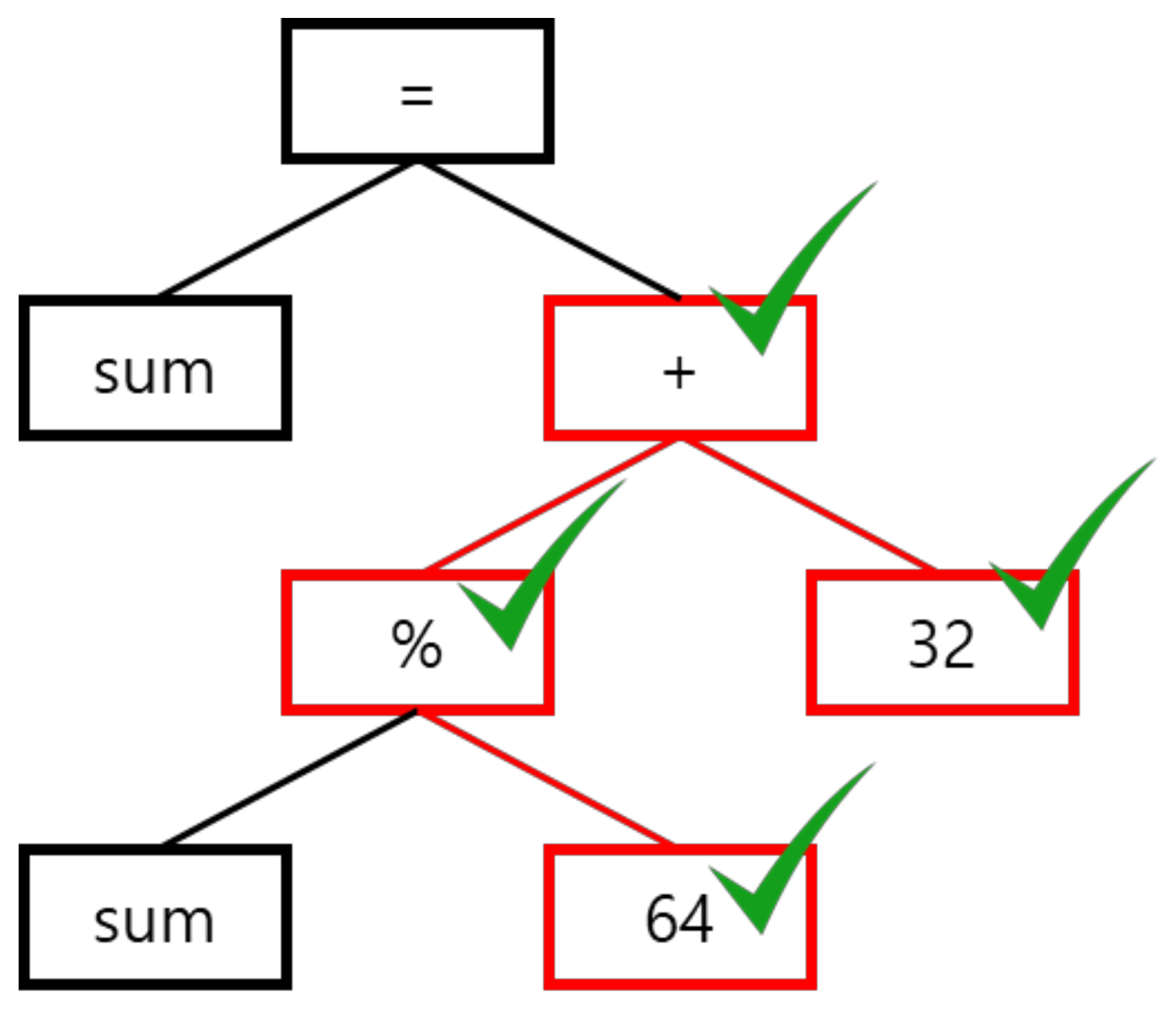
4.2. Converting Code to AST
- Target indicates the original buggy code and similar fixed buggy code.
- CodeLines are source code lines.
4.3. Applying GP
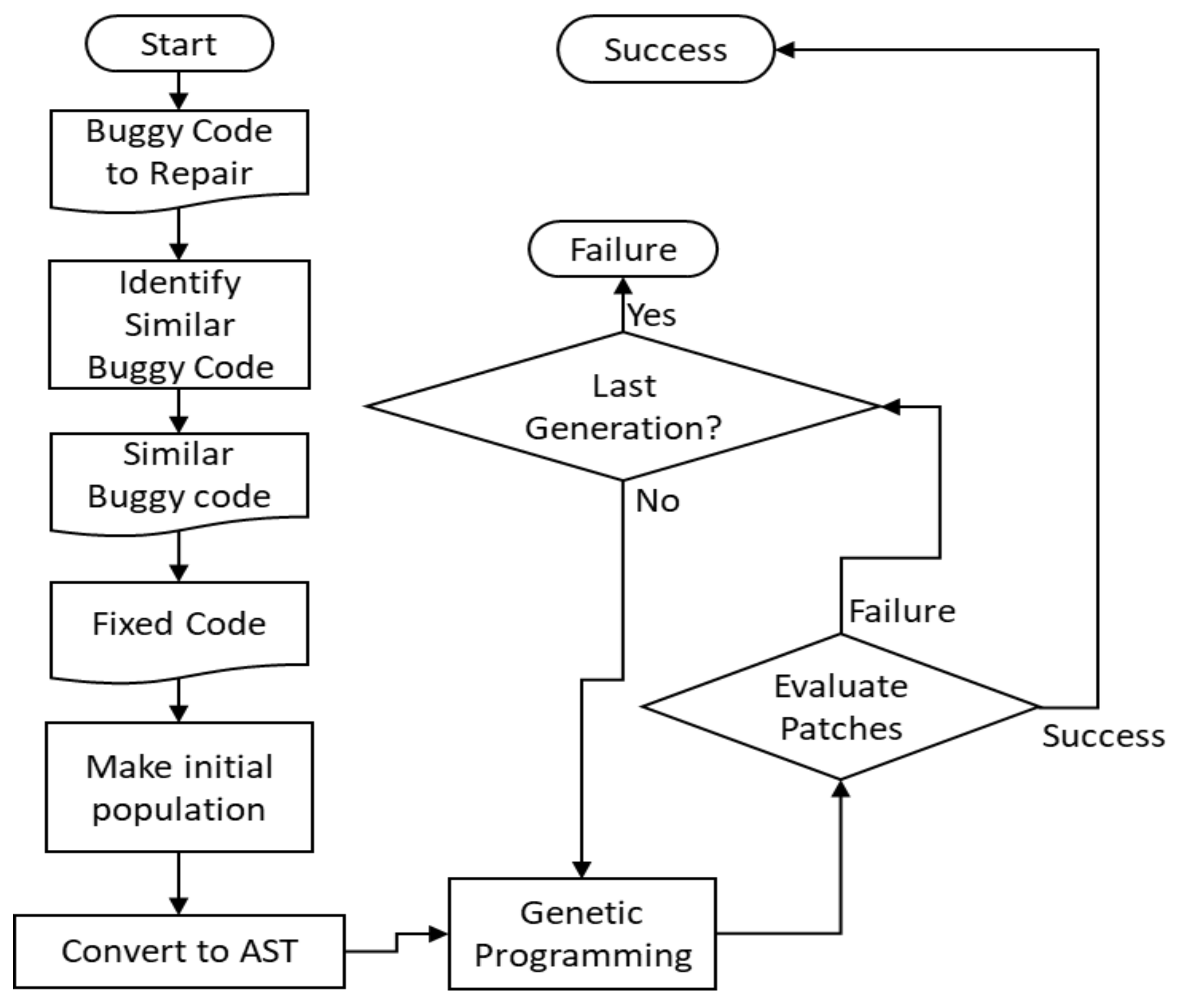
4.3.1. Making Initial Population
4.3.2. GP Operation
- Selection: Fitness normalizing process was applied to guarantee the probabilities for patches that have low fitness. To normalize fitness, we used the following process.
- We first sorted the candidate patches in the population in descending order from the previous generation using the fitness values. Then, we computed the difference between the largest and smallest fitness values. We divided the difference by the normalizing factor “n” and added the difference between the fitness value and the smallest fitness value in the generation to obtain the normalized fitness value. The smaller the value of the normalizing factor “n”, the greater the probability that a patch with a small fitness value will be selected. This normalized fitness value was used only for selection. The two ASTs from the current population were selected to construct two children using a roulette wheel selection operator with the normalized fitness value. According to roulette wheel selection, the patch that has the greater normalized fitness value will be selected with greater probability. Then, we used the two parent patches to generate two new children patches.
- Crossover: The crossover aims to exchange the sub-tree nodes in two ASTs. To do this, we first selected the changeable target nodes in each parent tree. We then constructed a set of target nodes from the buggy line to the nodes within “r” lines, including the lines above and below. The factor “r” refers to the range of the patch target code. After selecting the target nodes, we verified whether the two nodes can be exchanged with each other by tracing the parent’s node. Then, we exchanged the changeable nodes.
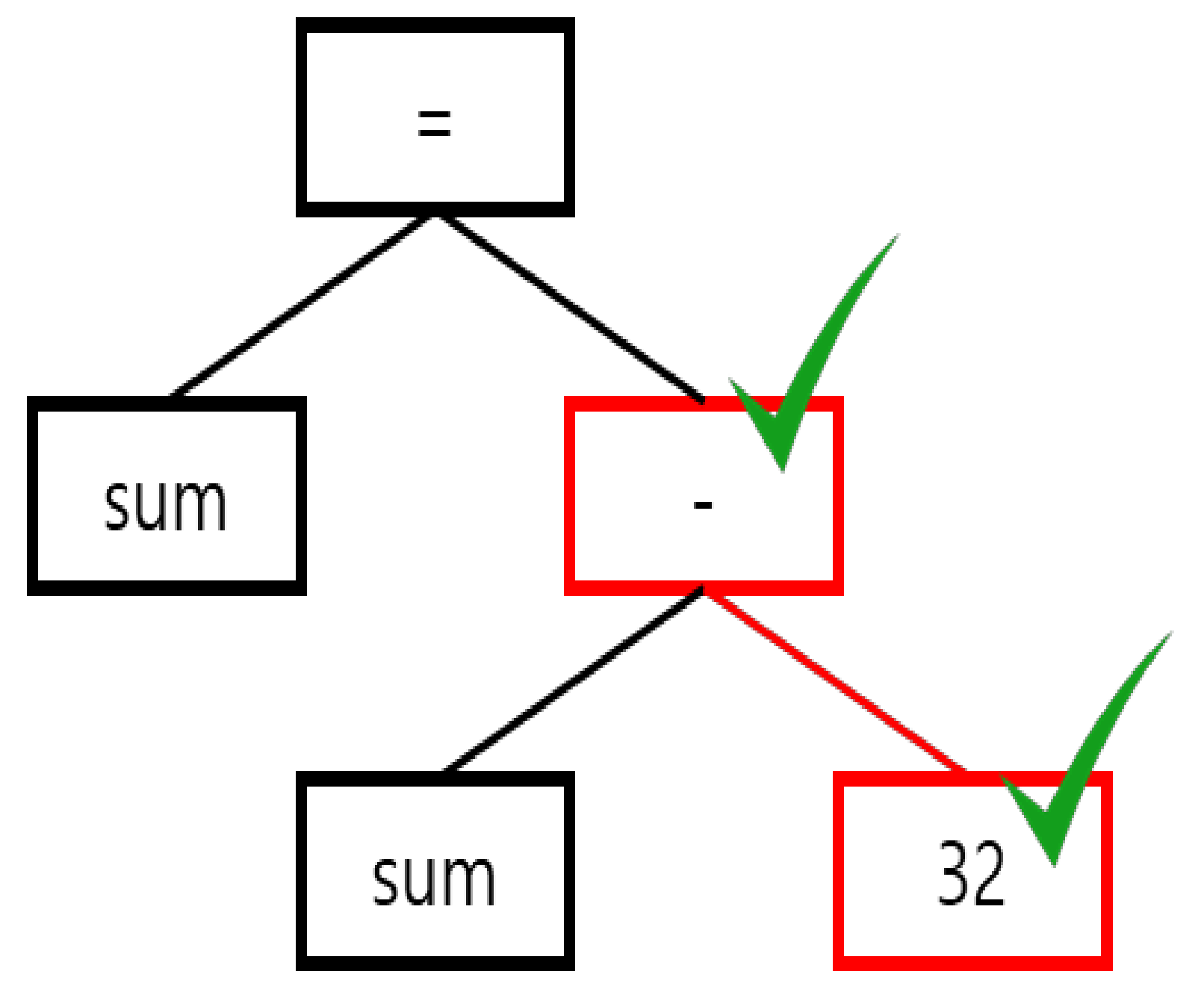
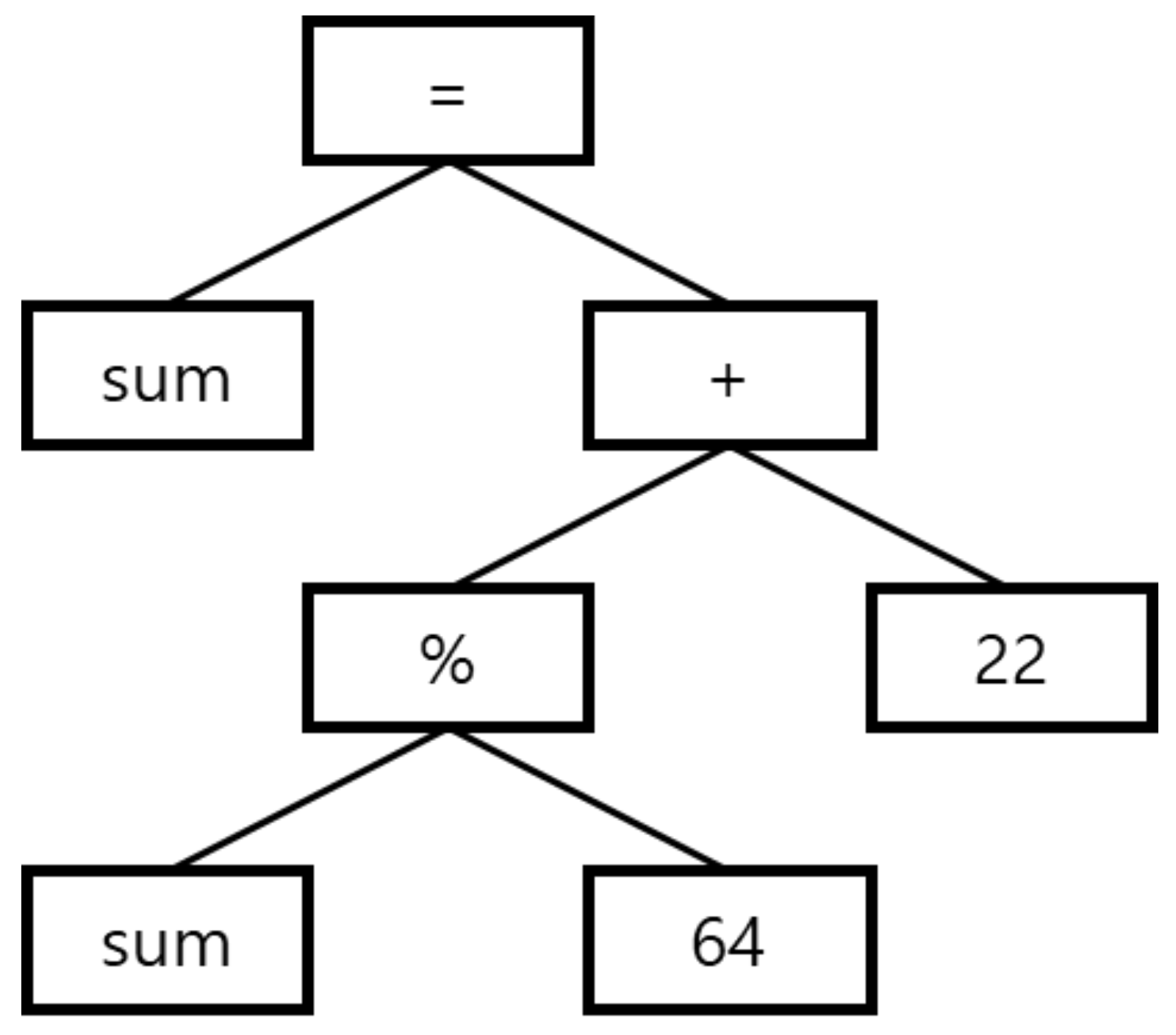
- Mutation: In this operation, the target node will be removed, added, or modified. The node was selected from the target set. The set is the same as the target set in the crossover, but the set can have different a code range, and the set is not dealt with as crossover target set. There are three sub-operations: deletion, addition, and modification. Deletion removes the target node from the AST. Addition inserts a copied node of its own tree. Modification changes the operator of the target node. When the modification is executed, an operator is selected from an operator list, except for the original operator. However, the mutation operator introduces variety into the population in a positive or negative way; thus, the operator is adjusted by a suitable probability parameter.
4.3.3. Fitness Function
- is a candidate program patch from the result of the GP operation.
- is the number of test cases passed among white box test cases from a given test suite. is the number of test cases passed among black box test cases from a given test suite.
- and are the total number of test cases in white box and black box, respectively.
5. Case Study
5.1. Similar Buggy Detection
5.2. AST Conversion
5.3. Applying GP
5.4. Fitness Function Computation
5.5. Adjusting Mutation Parameter
6. Discussion
6.1. Experiment Analysis
6.2. Threats to Validity
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yang, G.; Baek, S.; Lee, J.W.; Lee, B. Analyzing Emotion Words to Predict Severity of Software Bugs: A Case Study of Open Source Projects. In Proceedings of the Symposium on Applied Computing (SAC 2017), Marrakech, Morocco, 3–7 April 2017; pp. 1280–1287. [Google Scholar]
- Zimmermann, T.; Premraj, R.; Bettenburg, N.; Just, S.; Schroter, A.; Weiss, C. What Makes A Good Bug Report? IEEE Trans. Softw. Eng. 2010, 36, 618–643. [Google Scholar] [CrossRef]
- Le Goues, C.; Nguyen, T.; Forrest, S.; Weimer, W. Genprog: A Generic Method for Automatic Software Repair. IEEE Trans. Softw. Eng. 2012, 38, 54–72. [Google Scholar] [CrossRef]
- Kim, D.; Nam, J.; Song, J.; Kim, S. Automatic Patch Generation Learned from Human-written Patches. In Proceedings of the International Conference on Software Engineering (ICSE 2013), San Francisco, CA, USA, 18–26 May 2013; pp. 802–811. [Google Scholar]
- Qi, Y.; Mao, X.; Lei, Y.; Dai, Z.; Wang, C. The Strength of Random Search on Automated Program Repair. In Proceedings of the International Conference on Software Engineering (ICSE 2014), Hyderabad, India, 31 May–7 June 2014; pp. 254–265. [Google Scholar]
- Weimer, W.; Fry, Z.P.; Forrest, S. Leveraging Program Equivalence for Adaptive Program Repair: Models and First Results. In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE 2013), Silicon Valley, CA, USA, 11–15 November 2013; pp. 356–366. [Google Scholar]
- Samimi, H.; Schafer, M.; Artzi, S.; Millstein, T.; Tip, F.; Hendren, L. Automated Repair of HTML Generation Errors in PHP Applications using String Constraint Solving. In Proceedings of the International Conference on Software Engineering (ICSE 2012), Zurich, Switzerland, 2–9 June 2012; pp. 277–287. [Google Scholar]
- Son, S.; McKinley, K.S.; Shmatikov, V. Fix Me Up: Repairing Access-Control Bugs in Web Applications. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.307.1928 (accessed on 18 February 2018).
- Long, F.; Rinard, M. Automatic Patch Generation by Learning Correct Code. ACM SIGPLAN Not. 2016, 51, 298–312. [Google Scholar] [CrossRef]
- Long, F.; Rinard, M. Staged Program Repair with Condition Synthesis. In Proceedings of the Joint Meeting on Foundations of Software Engineering (FSE 2015), Bergamo, Italy, 30 August–4 September 2015; pp. 166–178. [Google Scholar]
- Le Goues, C.; Holtschulte, N.; Smith, E.K.; Brun, Y.; Devanbu, P.; Forrest, S.; Weimer, W. The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs. IEEE Trans. Softw. Eng. 2015, 41, 1236–1256. [Google Scholar] [CrossRef]
- Forrest, S. Genetic Algorithms: Principles of Natural Selection Applied to Computation. Science 1993, 261, 872–878. [Google Scholar] [CrossRef] [PubMed]
- Le Goues, C.; Dewey-Vogt, M.; Forrest, S.; Weimer, W. A Systematic Study of Automated Program Repair: Fixing 55 out of 105 Bugs for $8 each. In Proceedings of the International Conference on Software Engineering (ICSE 2012), Zurich, Switzerland, 2–9 June 2012; pp. 3–13. [Google Scholar]
- Nguyen, H.D.T.; Qi, D.; Roychoudhury, A.; Chandra, S. Semfix: Program Repair via Semantic Analysis. In Proceedings of the International Conference on Software Engineering (ICSE 2013), San Francisco, CA, USA, 18–26 May 2013; pp. 772–781. [Google Scholar]
- Yokoyama, H.; Higo, Y.; Hotta, K.; Ohta, T.; Okano, K.; Kusumoto, S. Toward Improving Ability to Repair Bugs Automatically: A Patch Candidate Location Mechanism using Code Similarity. In Proceedings of the ACM Symposium on Applied Computing (SAC 2016), Pisa, Italy, 4–8 April 2016; pp. 1364–1370. [Google Scholar]
- Qi, Y.; Mao, X.; Lei, Y. Efficient Automated Program Repair through Fault-recorded Testing Prioritization. In Proceedings of the International Conference on Software Maintenance (ICSM 2013), Eindhoven, The Netherlands, 22–28 September 2013; pp. 180–189. [Google Scholar]
- Guo, S.; Chen, R.; Li, H. Using Knowledge Transfer and Rough Set to Predict the Severity of Android Test Reports via Text Mining. Symmetry 2017, 9, 161. [Google Scholar] [CrossRef]
- Singh, J.; Singh, G.; Singh, R. Optimization of Sentiment Analysis using Machine Learning Classifiers. Human Centric Comp. Inf. Sci. 2017, 7, 32. [Google Scholar] [CrossRef]
- Souri, A.; Hosseini, R. A State-of-the-art Survey of Malware Detection Approaches using Data Mining Techniques. Human Centric Comp. Inf. Sci. 2018, 8, 3. [Google Scholar] [CrossRef]
- Sabharwal, S.; Aggarwal, M. Test Set Generation for Pairwise Testing using Genetic Algorithms. J. Inf. Proc. Syst. 2017, 13, 1089–1102. [Google Scholar]
- Youm, K.C.; Ahn, J.; Lee, E. Improved Bug Localization based on Code Change Histories and Bug Reports. Inf. Softw. Technol. 2017, 82, 177–192. [Google Scholar] [CrossRef]
- Lukins, S.K.; Kraft, N.A.; Etzkorn, L.H. Bug Localization using Latent Dirichlet Allocation. Inf. Softw. Technol. 2010, 52, 972–990. [Google Scholar] [CrossRef]
- Kamiya, T.; Kusumoto, S.; Inoue, K. CCFinder: A Multilinguistic Token-based Code Clone Detection System for Large Scale Source Code. IEEE Trans. Soft. Eng. 2002, 28, 654–670. [Google Scholar] [CrossRef]
- Nakatsu, N.; Kambayashi, Y.; Yajima, S. A Longest Common Subsequence Algorithm Suitable for Similar Text Strings. Acta Inf. 1982, 18, 171–179. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Evolutionary Algorithm | Metric |
|---|---|---|
| GenProg [3] | O | Basis of GP for Repairing |
| PAR [4] | X | Bug Fix Pattern Templates |
| AE [6] | X | Deterministic Algorithm |
| Prophet [9] | X | Machine Learning Algorithm |
| SemFix [14] | X | Component-based Synthesis |
| Yokoyama [15] | O | Code Similarity (Line based) |
| Our Approach | O | Bug Fix Information |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, G.; Jeong, Y.; Min, K.; Lee, J.-w.; Lee, B. Applying Genetic Programming with Similar Bug Fix Information to Automatic Fault Repair. Symmetry 2018, 10, 92. https://doi.org/10.3390/sym10040092
Yang G, Jeong Y, Min K, Lee J-w, Lee B. Applying Genetic Programming with Similar Bug Fix Information to Automatic Fault Repair. Symmetry. 2018; 10(4):92. https://doi.org/10.3390/sym10040092
Chicago/Turabian StyleYang, Geunseok, Youngjun Jeong, Kyeongsic Min, Jung-won Lee, and Byungjeong Lee. 2018. "Applying Genetic Programming with Similar Bug Fix Information to Automatic Fault Repair" Symmetry 10, no. 4: 92. https://doi.org/10.3390/sym10040092
APA StyleYang, G., Jeong, Y., Min, K., Lee, J.-w., & Lee, B. (2018). Applying Genetic Programming with Similar Bug Fix Information to Automatic Fault Repair. Symmetry, 10(4), 92. https://doi.org/10.3390/sym10040092