1. Introduction
Nowadays, there was significant development in the field of intelligent big data (IBD) analysis where a multicore platform based on a large computing cluster was used. Despite the improvement, too much complex information is still being provided for a single institute or a computing center for processing.
Especially, the number of multimedia and user population will increase continuously and exponentially due to the rapid spread of smartphones and social networking sites.
The obese population is increasing rapidly in Korea due to the change of lifestyle and diet habits. According to the Ministry of Health and Welfare, the prevalence of obesity (over 19 years old, standardization) has increased from 26.0% in 1998 to 29.2% in 2001 and 31.7% in 2007. For the last seven years, it has remained at 31~32%. During the same period, obesity in men increased from 25.1% in 1998 to 36.2% in 2007—up by 11.1% in the past nine years—and remained at around 35~38%. Obesity in women remained at around 25% from 1998 to 2014 [
1].
Obesity can cause various complications, and it has become a social disease. Nonetheless, there are many obese patients who have no medical measures that are right for them. Although various online and offline obesity management services are emerging, they are not enough to attract the attention of users and have yet to be helpful in solving the problems.
The emergence of big data due to the spread of digital economy in the 21st century can provide a clue to solving some problems in our society and economy. One of the most valuable uses of big data is the health and fitness industry. The development of IT technology has given birth to a new phase of transformation in the medical field. Note, however, that the introduction of big data in the domestic medical industry has yet to be activated. It is still restricted in terms of actual use due to difficulties in the search and statistics of atypical data. Big data can produce very meaningful results depending on the collection and analysis method of a vast volume of data. The purpose of this study is to visualize big data using text mining and word clouds and to prepare measures, if any, of personalized health activities from more various perspectives.
The big data analysis can visualize a form by collected unstructured data fragments as a puzzle generates a picture by matching scattered pieces. It can show meaningful results depending on which algorithms or techniques it applies. Therefore, this study collected big data using crawling method, visualized big data using text mining and word cloud, and took a machine learning approach to prepare measures for personalized health activities in a variety of viewpoints.
Figure 1 shows bird’s-eye view of machine learning processing for automatic keyword extraction approach.
The research team led by Professor Dev Roy at the MIT Media Lab worked with six fact-checking organizations such as PolitiFact and factcheck.org to analyze 126,000 news articles that were categorized as real or fake in 2006–2017 and confirm that the dissemination speed of fake news overwhelmed real news. It published an article in
Science [
2]. Professor Roy and his research team used AI to collect the activity data of 3 million users who directly referred or shared the categorized news and analyzed the dissemination speed and the number of sharing on the network. The analysis result showed that the number of shared fake news was 70% higher than the real news. It meant that fake news spread much more widely than real news. The research team reported that the statistical physical analysis of comments to news showed that disgusting and amazing fake news is shared much faster than real news. The paper explained that “fake news with new and exciting features can be easily transmitted on the Internet and SNS” [
2]. Such studies of big data analysis can visualize a form by collected unstructured data fragments as a puzzle generates a picture by matching scattered pieces.
2. Related Works
Accordingly, the market for the big data is becoming larger over time and the data is being used in different areas of our daily lives and much information is shared by the general population. However, since the analysis of big data is very complicated and difficult that sometimes it is quite hard to recognize its meaning and direction, the visualization of big data has come into the picture. Recently, the big data analysis is shifting from SPSS/AMOS to R/TensorFlow.
Machine learning (ML) refers to studying various methods of achieving human-like learning ability through machines, and from the data analysis results, the program can learn about rules or new knowledge by extracting them automatically by itself. The techniques related to machine-learning remaining at the basic level is now becoming more sophisticated due to the emergence of new data mining techniques which can maximize their potential.
Recently, ML is one of the major areas of interest for the artificial intelligence systems, being at the intersection of informatics and statistics and closely related to the data science and knowledge discovery as well as the healthcare industry [
3,
4]. Especially, probabilistic ML is quite useful for the health informatics where most of the problem-solving process involves removing of uncertainties. The theoretical basis of the probabilistic ML was initially laid by Thomas Bayes (1701–1761) [
5]. The probabilistic inference holds a key position in artificial intelligence and statistical learning where the inverse probability allows one to infer unknown facts, deducing them from the available data and making predictions [
6,
7].
Meanwhile, the scale of big data is much larger than that of the data generated from the analog environment of the past, shorter in generation cycles, and not only the numerical data but the character and image data are included in the big data as well. Since the use of PC, internet, or mobile devices has become part of people’s daily routine, the volume of data left behind by them is increasing rapidly.
Along with the fact that the volume of big data has increased explosively, the types of data have been also diversified such that people’s behaviors, as well as their thoughts and opinions can be anticipated through positional information and SNS services. Many countries and companies are attempting to construct and utilize the big data system now.
Accordingly, the market for the big data is becoming larger over time and the data is being used in different areas of our daily lives and much information is shared by the general population. However, since the analysis of big data is very complicated and difficult that sometimes it is quite hard to recognize its meaning and direction, the visualization of big data has come into the picture [
8].
Wu et al. [
9] have argued that a large volume of data (big data) can be problematic when frequent itemset mining has been used for the following reasons: (1) spatial complexity: the algorithm may not be run as the system memory deal with a large input data as well as large intermediate results and output pattern; (2) time complexity: many existing approaches depend on an exhaustive search or a complicated data structure to obtain a frequent pattern but this is not suitable for big data. Thus, they proposed an iterative sampling-based frequent itemset mining that samples the subsets instead of processing entire dataset all together and then extracting the frequent itemsets from them.
Yang Luo et al. [
10] maintained that segmenting the Left Ventricle (LV) from the cardiac MRI image is essential when computing the clinical indices such as stroke volume, ejection fraction, etc. Thus, in this study, an automated LV segmenting method where the hierarchical extreme learning machine (H-ELM) is combined with a new location recognition method is proposed.
Ghadah Aldehim [
11] claimed that using all the data for the feature selection, which is becoming increasingly important in big data analysis and machine-learning, may lead to a selection bias while using the partial data could lead to an underestimation the relevant features under some conditions. Thus, a research on the method with which can decide a suitable method for a specific dataset in terms of reliability and effectiveness is being introduced in this study. Also, Tri Doan et al. [
12] maintained that selecting an appropriate categorization (classification) algorithm is a very important step in all the data mining procedures. The run-time is used to assess the efficiency of a categorization algorithm. In this study, a method that is helpful in finding an adequate algorithm in terms of efficiency has been studied by introducing a tool that estimates the run-time of a particular categorization algorithm used for a dataset based on the concept referred as meta-learning.
Meanwhile, Junhai et al. [
13] proposed an algorithm having a higher performance level (i.e, in G-mean) than other existing ensemble algorithms in terms of speed and scalability to effectively categorize the imbalanced data into two classes.
A number of research directions are recognized [
14,
15]. First, sentimental classification which classifies the contents in relation to the sentiments involving the opinion targets. Second, feature (aspect)-based opinion mining that analyzes the sentiment towards certain characteristics of an object. The examples of this can be found in [
16,
17]. Third, comparison-based opinion mining focuses on the text where similar objects are being compared [
18]. It is essential that the opinion mining methods are identified with three individual levels: document, sentence, or entity/aspect levels but most of the classification methods depend on identifying the opinion words or phrases involved. Also, their basic algorithms are categorized as (1) supervised learning of which can be found in [
19,
20]; (2) unsupervised learning as described in [
21]; (3) partially supervised learning illustrated in [
22]; and (4) other approaches using the algorithms that use some of the latent variable models such as hidden markov model (HMM) [
23], conditional random fields (CRF) [
24], latent semantic association (LSA) [
25], or pointwise mutual information (PMI) [
26]. For these varying techniques, a number of researchers had experimented them with a series of different algorithms and made comparisons [
27,
28,
29].
A few research works have clearly focused on Web 2.0. In that case, while many of research had dealt with weblogs [
30,
31,
32,
33] mainly investigating the correlation between blog posts and ‘real-life’ situations, a few other researchers evaluated the techniques used for the opinion mining targeting the context of weblogs such that the main trend in the mining technique has not been identified or suggested. Liu et al. made a comparison between varying linguistic features when classifying the blog sentiment [
34]. Some of the experimental studies were made with lexical and sentimental features using separate learning algorithms to identify the opinionated blogs [
35]. It is quite interesting that there are so little research has been conducted about the opinion mining in the field of “Discussion Forums” [
36,
37] whereas quite a number of researchers carried out their research focusing on the microblogs (for Twitter, especially) and published the papers on them [
38,
39,
40,
41,
42].
For the opinion mining of microblogs, the researchers primarily adopt the supervised or the semi-supervised learning technique for the microblogs. Contrary to the rapid spread of social network services led by Facebook and Twitters, the number of research concerning the opinion mining in the social networks is not enough [
43,
44]. Although there have been quite a number of research works published in the past decade concerning product reviews, it seems very little works for determining the most effective opinion mining technique were introduced. It is evident that most of the researchers are using the tex classification algorithms such as SVM, naïve Bayes, or a combination of different methods to enhance the reliability of opinion mining results but one of the most encouraging mining technique would be LDA [
45,
46]. The LDA-based model that identifies both aspects and sentiments together is proposed in [
47]. Such a model also described in [
48,
49] stands on the premise that entire words used in a sentence are relevant to a single topic. Gerald Petz introduced his research in the paper titled “Opinion Mining on Characteristics of User Generated Content and Their Impacts” [
50,
51,
52,
53,
54,
55,
56,
57,
58,
59].
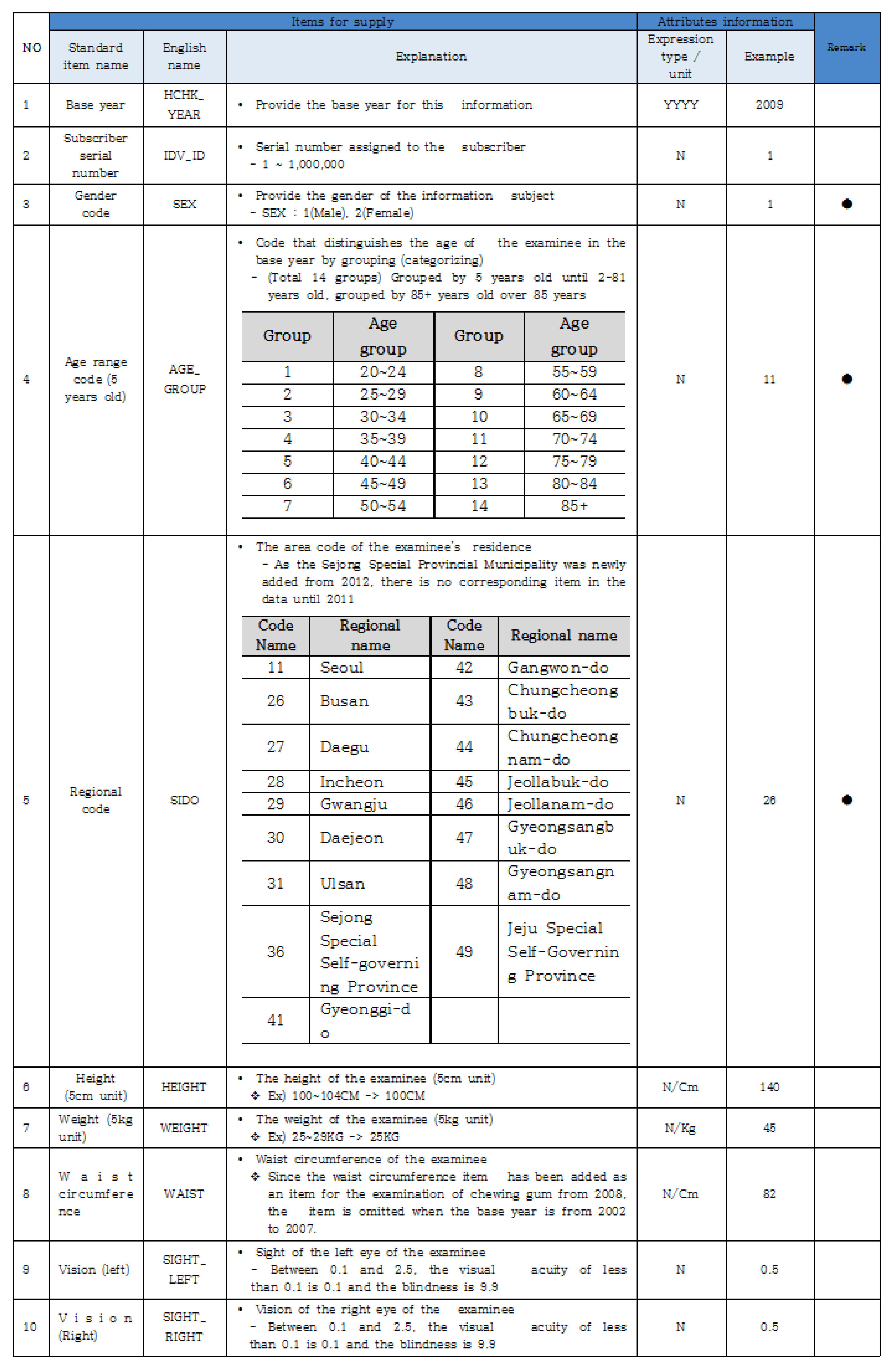
2.1. National Health Information Data
Among the data held by National Health Insurance Corporation according to the Korean Government 3.0 Policy, the national health information data is public data that is open to the public and which enjoys high demand from the private sector. National health information data are “medical history information” and “prescription medicine information and health examination information” of national health insurance subscribers accumulated by the corporation as the corporation serves the role of national health insurance data provider. In order to open safe data, the corporation excluded or masked personal information and sensitivity data, and the target date of data provided is from 2002 to 2016. It is planning to expand the target period continually in the future.
2.2. National Health Data Selection Criteria
Table 1 shows national health data selection criteria.
2.3. Excluding Personally Identifiable Information
Personal identification information (resident registration number, national health insurance subscriber number, etc.) and easily identifiable information (name, telephone number, address, photograph, etc.) are excluded from the national health information data.
2.4. Applying the Personal Information Non-Identifying Processing Technique
Data whose re-identification is possible is excluded from the opening through the prior filtering of identifiable information by combining with other information. The possibility of identification was excluded by applying the non-identifying processing technique suitable for individual items.
2.5. Health Checkup Information
Health checkup information is obtained by randomly selecting one million Korean national health insurance subscribers who had health checkups in the year; the basic information of the selected subscribers after the item selection process and the examination result information were then extracted. The data are organized by year, with one million data and 34 attributes per year.
Figure 2 shows survey of Korean national health information data.
3. A Big Data Analysis Method for Personalized Health Activities
3.1. Data Analysis
Aggregating data into a frequency table can show the overall characteristics better than raw data. However, a person who is weak in numbers may not get any meaningful idea from the table. Therefore, I use a graph called histogram to show the full data more intuitively. A histogram is a bar chart with the class interval of the frequency distribution table on the horizontal axis and the frequency on the vertical axis. I used R Studio because it was the most appropriate big data analysis tool for our data.
With R Studio, there were 542,321 men and 457,679 women in the total data of 1 million people in the “Health Examination Information Data Set”. First, the body information of males and females were checked, and each distribution was compared using histograms.
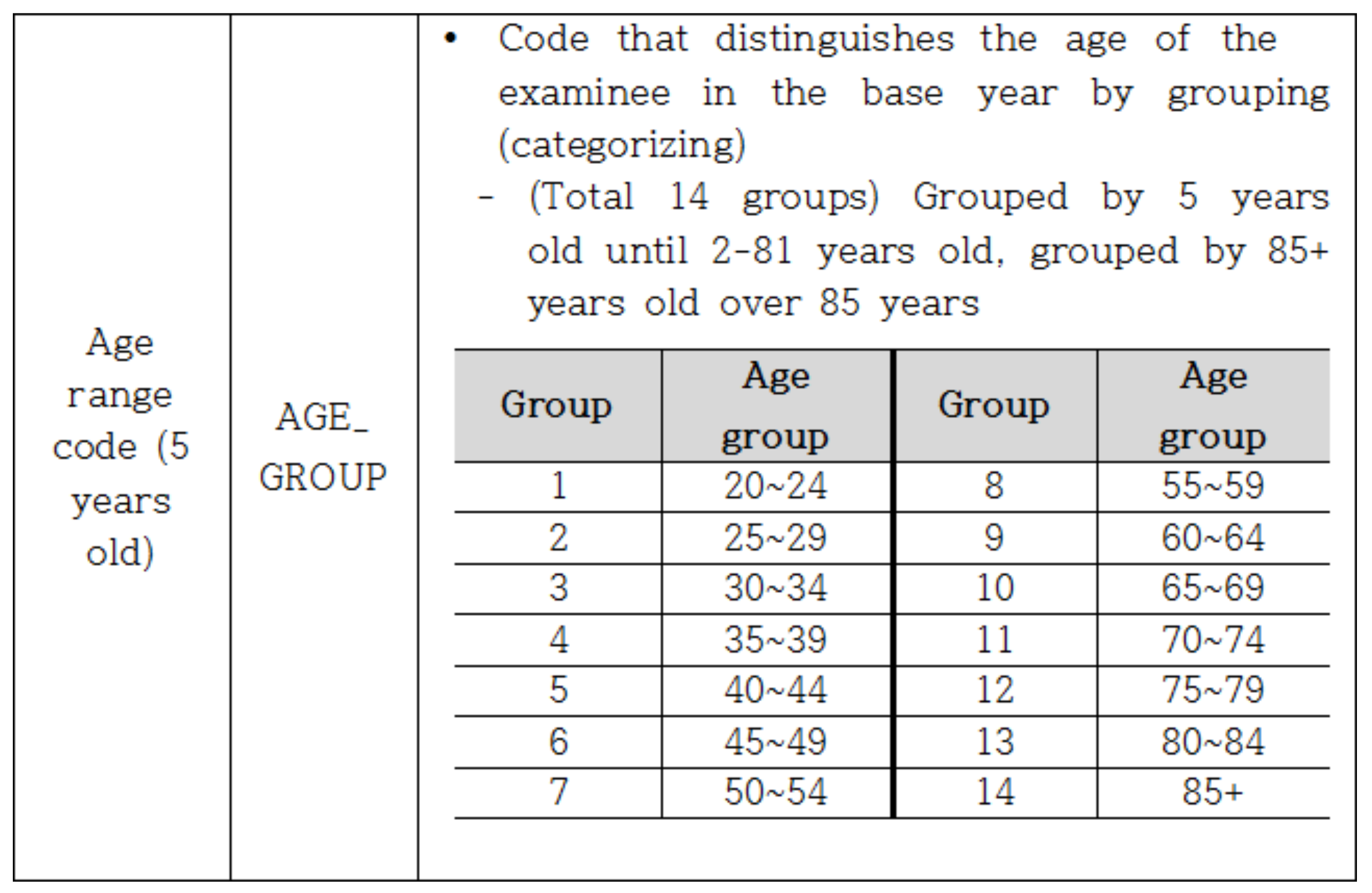
The health screening information data age group code is shown in
Figure 3. The age group codes of the national health information data set are grouped by age group (categorized by age 5). Therefore, by using the subset () function of R Studio, the data were categorized according to age. As a result, in the analysis of height by age, the data were collected by categorizing into 6 groups—20–24 years, 25–29 years, 30–34 years, 35–39 years, 40–44 years, and 45–49 years—and the mean and standard deviation of height were determined.
Table 2 shows data categorization by age and mean and standard deviation of height.
In the next place, the study compared the height of the whole age group according to gender by the histograms in
Figure 4. In males, height was most distributed at 165–170 (cm), with females’ height most distributed at 150~155 (cm). The histogram of females showed a symmetrical distribution of the population according to height, but the male histogram had a long tail to the left. To better understand the difference in height between male and female, the distribution of gender by combining histograms was analyzed. The distribution of male and female histograms according to height shows that the proportion of males increases with increasing height, whereas the proportion of females increases with decreasing height.
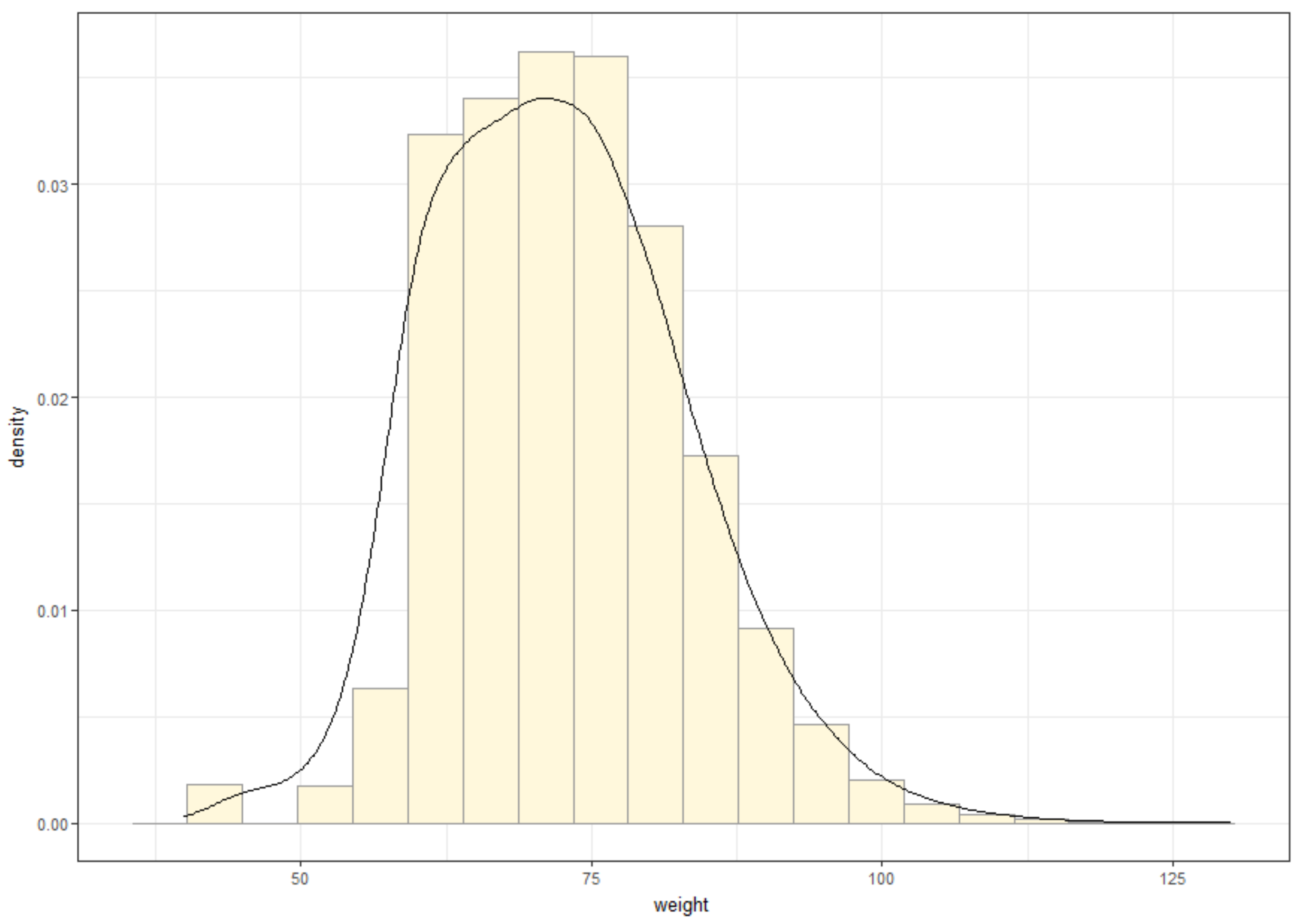
The results of big data analysis as shown as the histogram of weight in
Figure 5, indicate that the portion of males increased as the weight increased while the portion of females increased when the weight decreased. It shows the similar pattern as the height histogram depicting the difference of heights of males and females, and thus the analysis results were successfully visualized.
Next, a body mass index (BMI) column is added to the data set to check for obesity. The BMI value of each row is the weight (kg) divided by the square of height (m) (body weight (kg)/height (m2)). At this time, the classification of obesity by body index is defined as ‘underweight’ when BMI is less than 18.5, ‘normal’ when BMI is 18.5~22.9, and ‘overweight’ when BMI is 23~24.9. The distribution of BMI according to gender is as follows:
In this case, the obesity distribution can be seen as a kind of normal distribution as shown in
Figure 6. This analysis can be influenced by the difference in the observed number of obese. Therefore, the distribution of obesity (BMI ≥ 25) ≥ on body weight was analyzed. Also,
Table 3 shows data categorization by age and mean and standard deviation of height.
As a result, the obesity distribution graph according to body weight in
Figure 7 shows that the normal weight, overweight, and obesity appear evenly between 60 and 70 Kg in body weight, however, the proportion of obesity increased rapidly. The proportion of BMI for the total population of the dataset is shown below.
Figure 8 shows the distribution of obesity according to body weight.
Table 4 shows weight of the BMI in national health information data set.
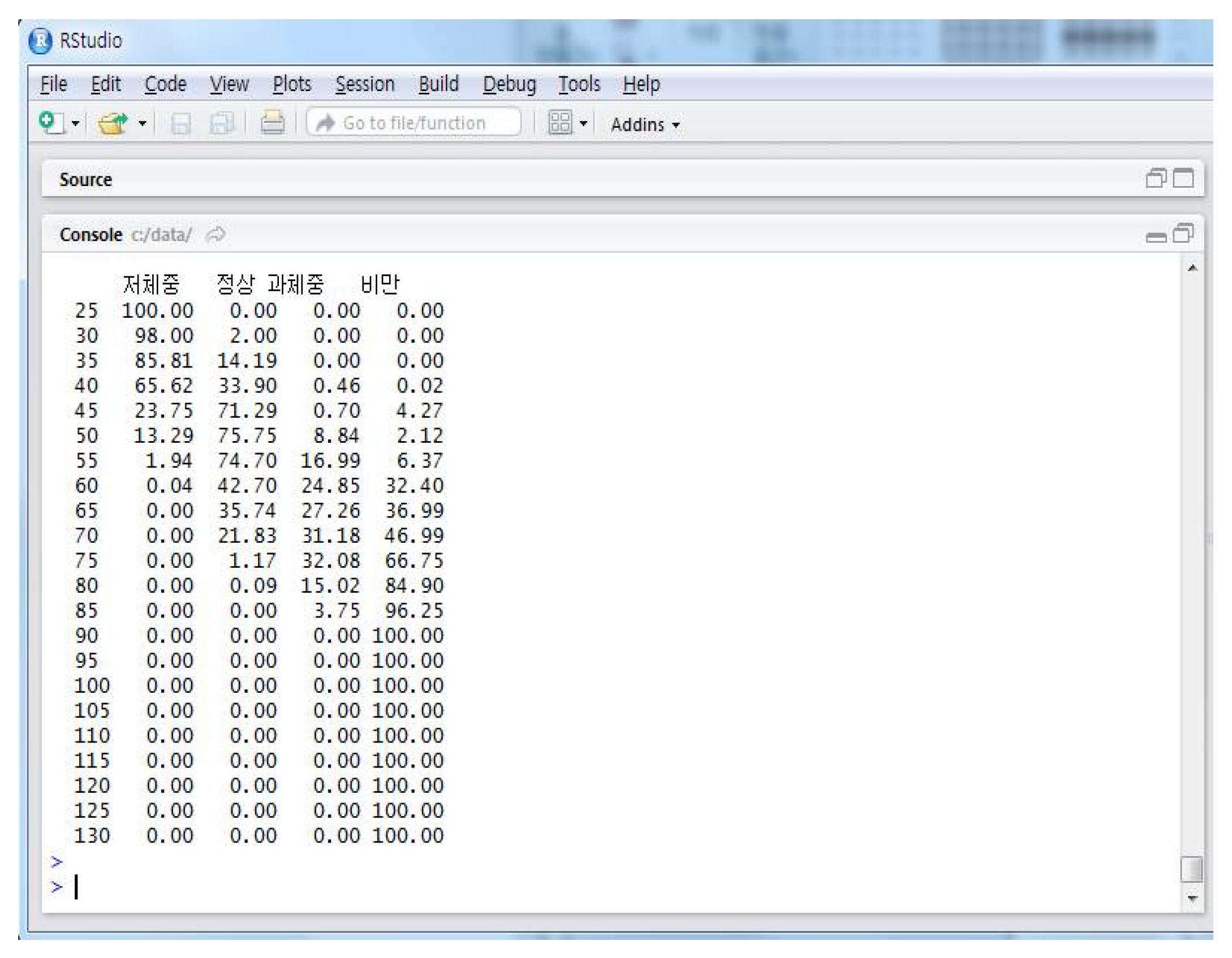
As shown in
Table 5, the big data analysis of the distribution of obesity according to body weight revealed that people with a body weight of 25–40 kg tended to be underweight while those with a body weight of 40–70 kg tended to be normal. The overweight people were evenly distributed up to 60–80 kg while 100% of people weighing more than 90 kg were obese. The obesity distribution graph according to weight as shown in
Figure 9 visualizes such change.
The next section is machine learning to create a suitable learning model through a large number of data of one million people and to discover useful information.
3.2. Machine Learning
Machine learning involves the study of various methods of implementing human-like learning abilities through a machine. It analyzes the given data and automatically extracts rules or new knowledge that can be learned from the analyzed results and aims to get the effect that the machine learns. Techniques related to machine learning have remained at the basic level, but they are becoming more feasible due to the emergence of a large number of big data that can maximize the potential of machine learning techniques.
In particular, the regression technique of machine learning differs from other machine learning techniques since there are a number of techniques that can be applied to a task beyond one algorithm. There are various techniques such as linear regression using one independent variable, multiple regression using two or more independent variables, and logistic regression used to model binary categorical results. The same basic principles apply to all regression techniques.
The “health checkup information data set” [
1] includes various health checkup results in addition to the obesity-related variables above. To investigate the effect of these variables on blood pressure, a regression technique that predicts the numerical data is used, and an appropriate model is created to analyze the correlation.
The basic installation of R Studio does not include machine learning. In order to use the machine learning algorithm implemented in R Studio, R Weka package, class package, and stats package were installed and analyzed using the ‘install.packages’ () function.
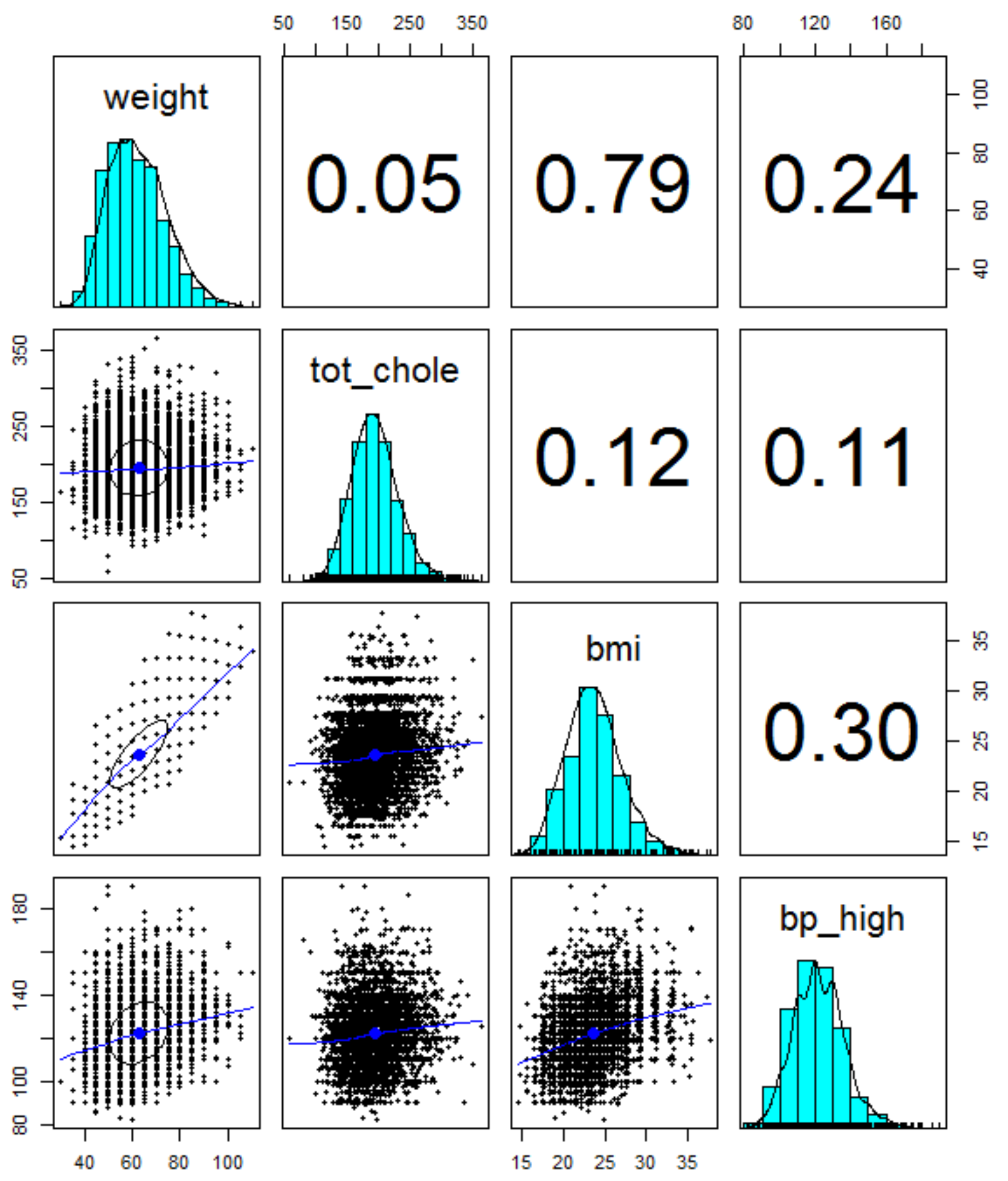
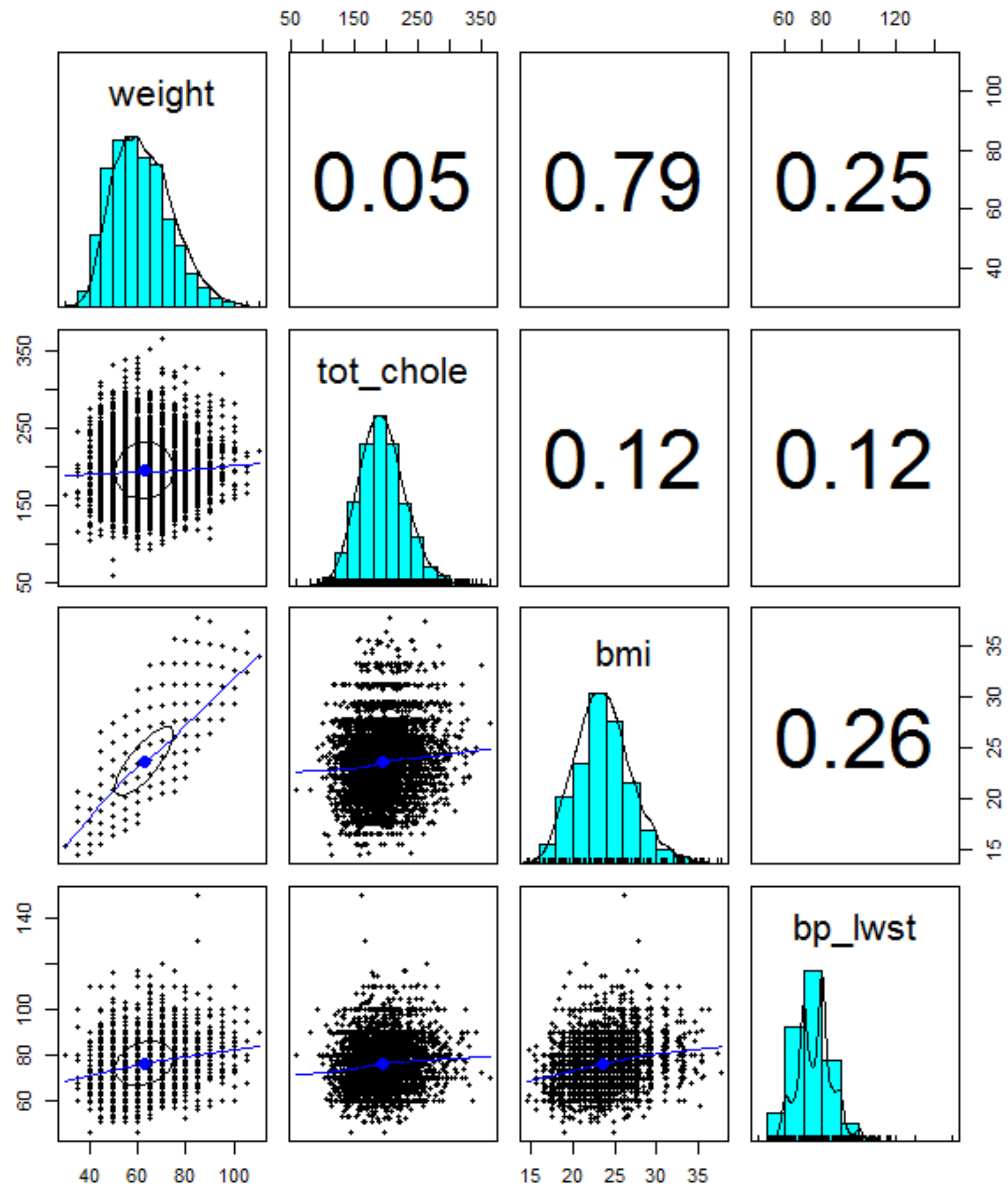
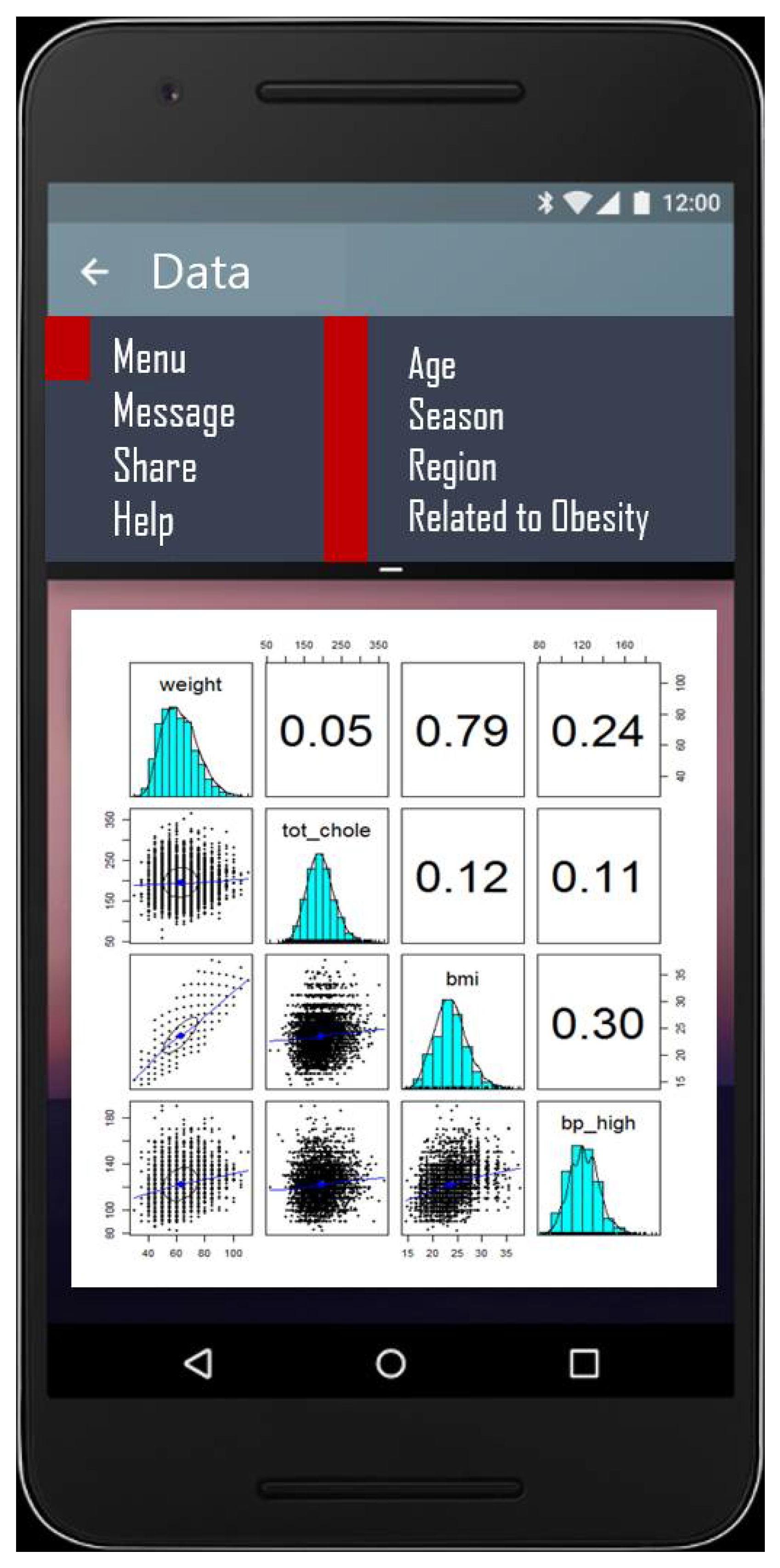
To apply machine learning to data, the library () function is used to load the package. Initially, a scatter matrix of “weight”, “total cholesterol”, “BMI”, “systolic blood pressure”, and “diastolic blood pressure” variables are created to visualize the relationship between major properties.
Here, the ellipse on the scatter chart shows how strong the correlation is with the correlation ellipse. “Weight” and “BMI” mean that the correlation is strong when they are extended to an ellipse. If the circle shape such as “weight” and “total cholesterol” is strong, it means weaker correlation. In the next place, “smoke” and “drink” are generated by using the ifelse () function to compare blood pressure according to smoking status and alcohol consumption.
Meanwhile, as shown in
Figure 10 and
Figure 11, the “systolic blood pressure (bp_high)” and linear regression model associated with ten variables are fitted. In this case, b_data is new data created by adding the variables required for a_data used in the preceding data analysis. After creating the model, enter the object name of the model to check the regression coefficient.
The estimated regression coefficient shown in
Figure 12 suggests how much bp_high (systolic blood pressure) increases for each attribute when the other attributes remain constant. Bp_high (systolic blood pressure) increases by 0.83 when age_group (age group code) is increased by 1 with other values held constant. The values of height, weight, blds, and tot_chole (total cholesterol) showed much lower values, indicating that blood pressure is very difficult to explain. bp_lwst (diastolic blood pressure) is similar to systolic blood pressure, and women have a mean blood pressure that is 0.98 point lower than men. Likewise, BMI (Body Mass Index), drink (drinking alcohol), and smoke (smoking) were more closely related compared with other variables. Next, the performance of the model is evaluated by the summary () command.
As shown in
Figure 13, the Residuals section provides summary statistics for the error. The maximum error of 111.895 indicates that the model has a difference of at least one predicted value in at least one example. The value of Multiple R-Squared indicates how well the model describes the value of the dependent variable. Like the correlation coefficient, if the value approaches 1.0, the model fully explains the data.
0.6015 as the value of R-Squared means that this ‘blood_model’ model can account for 60% of the dependent variable. A model with more attributes can provide higher values.
While the size of the error is part of the consideration, the regression model ‘blood_model’ has a value of 0.6015 and appears to work substantially well.
Next, this study analyzed not only the data analysis of the dataset but also the various keyword trends that have been publicized through the media in the meantime and examined the various problems and interest trends of national health to provide various kinds of personalized information.
3.3. Keyword Analysis Method
First, this study selected Naver News, an Internet newspaper, to analyze the field of interest in public health. To collect Internet news related to obesity over the last 1 year, the crawling technique was used, and the frequency of embedded words was analyzed. In addition, big data-based services such as Naver Trend and Google Trends showing the keyword trends in real time were used. As in the previous dataset analysis, web crawling for Internet news was done using statistical program R, and text mining was performed to find meaningful information of embedded words.
3.3.1. Text Mining
Text mining is a technique for extracting and processing important information such as the patterns, trends, and distributions of the text by analyzing the unstructured texts. With the recent availability of big data, interest in large-capacity text analysis technology has increased, and the importance of text mining technology is emphasized. Text mining basically expresses unstructured/semi-structured data as a simplified model.
While the purpose of a data mining is to draw useful and potential patterns from the structured data, text mining is the process of discovering new knowledge from a large unstructured textual group composed of natural language. In other words, text mining is a process of finding interesting and useful patterns from unstructured text finds new unknown knowledge or patterns with the resulting logic. Since most of the information I use is in the form of unstructured textual data, the automated analysis of textual documents in natural language is very important.
The method most commonly used in text mining is to generate a feature vector and find the new knowledge or patterns by applying various techniques such as the statistical method to the generated vector. These feature vectors extract keywords from the text and use them to categorize or summarize documents.
The text mining method combines various techniques such as the automatic classification (document clustering and text categorization), natural language processing, information extraction, and information retrieval. The automatic classification refers to a task of grouping objects with similar patterns by a classification algorithm. There are two types of automatic classification depending on the use of the preliminary classification system. The document clustering technique groups the documents having similar contents without the preliminary classification while the text categorization technique assigns the documents to the most suitable subject category classified in advance using the machine learning.
3.3.2. Word Cloud
As a technique of visualizing the key words mentioned in the study, Word cloud enables understanding intuitively the keywords and concepts of documents. For example, there is a technique that allows a word to be expressed at a glance as much as it is mentioned. It is mainly used to derive the characteristics of data when analyzing big data that deals with a huge amount of information. Big data analysis tool R Studio provides a variety of packages for crawling, text mining, and word cloud such as ‘KoNLP’, ‘wordcloud’, ‘XML’, ‘stringr’, ‘httr’, ‘rvest’, and ‘dplyr’. Data was collected through crawling after installing the necessary packages. Figure 15 shows an example of word cloud text image generated by big data analysis. The users can freely change the fonts, shapes, and sizes, and there is no copyright issue.
3.3.3. Web Crawling
Web crawling is a computer program work that explores the World Wide Web in an organized, automated manner. It is used to collect certain types of information on web pages by crawling the Web using R Studio’s library (httr), library (rvest), and library (dplyr) packages. After searching the news, the URL of the news web page is collected, including the URL of the news article in the web page. Then, words in the news articles are crawled to extract the text and to save. It is analyzed as shown in
Figure 14.
4. Big Data Analysis Result for Personalized Health Activities
First, the study hosted periodic searches on
Naver News Big Data in Korea to see the people’s interest in obesity by season. From 1 January 2013 to 1 March 2016, the search results were 655 pages with 6545 articles, and 500 of them were crawled. Likewise, the study categorized periods for other seasons and search for news and crawled. The number of web pages and the number of articles according to each period are shown in the table below. Files crawled during the period 1 January–1 March are referred to as ‘winter.txt’; files crawled from 2 March to 1 June are referred to as ‘spring.txt’, and files crawled from 2 June to 1 September are ‘summer.txt’. Finally, files crawled from 2 September to 1 December are referred to as ‘fall.txt’.
Table 6 shows number of web pages and articles in obesity search by
Naver News.
In the case of collected text files, words with “obesity” may include unnecessary words such as special characters and numbers as well as words with meaningful relationships. Therefore, the study used the gsup () function, which has a filtering function to remove characters and symbols deemed to be unnecessary during keyword extraction. The gsub () function has the function of changing the specified character or symbol to whatever character or space.
As shown in
Figure 15,
Figure 16 and
Figure 17, the filtered ‘winter.txt’ is shown in word cloud, and the frequency of each word is determined. Meanwhile, the five most frequently used words are selected and displayed as a graph and visualized during this period. The significance of each word is found and interpreted as follows:
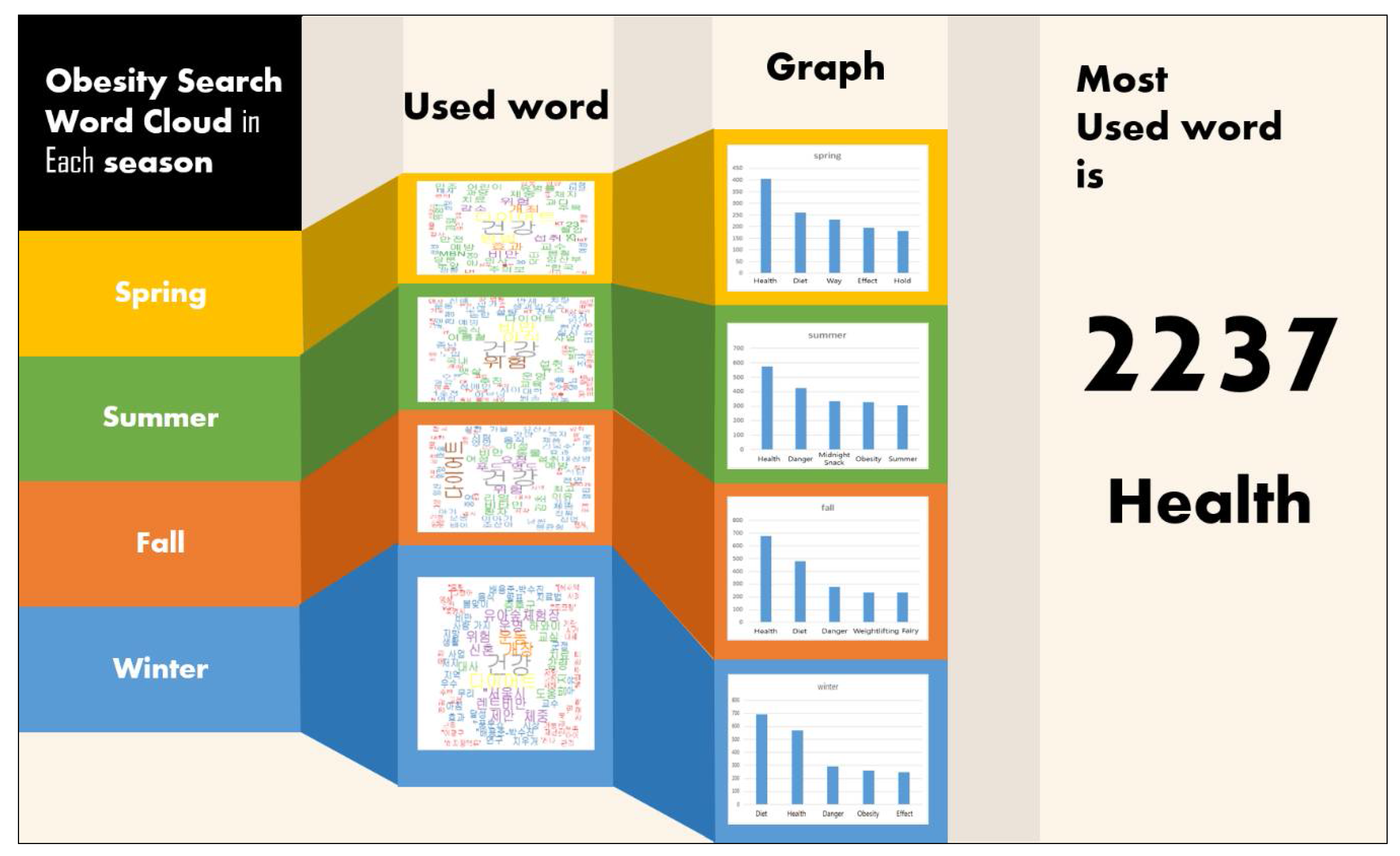
The most commonly used words related to obesity in winter were “diet”, “health”, “risk”, “obesity”, and “effect”. The analysis shows that obese people during this period are most interested in diet and health, and that they are also paying attention to the dangers of obesity. It was followed by the analysis of the crawled text file for another season.
As shown in
Figure 18 and
Figure 19, the most frequently used words related to “obesity” in spring were “health”, “diet”, “method”, “effect”, and “hosting” in order of frequency. There was no significant difference compared to the winter period, but people had more interest in health and diet methods and effects than the risk of obesity. In particular, the frequency of the word “hosting” increased, indicating that various events related to obesity were hosted. In fact, during this period, various events such as the “Healthy Living Practice Contest” hosted by the Korea Health Association, “Diet Recipe Contest” hosted by the obesity professional treatment center, and a “Health Lecture” held at the Northern Health Center were hosted.
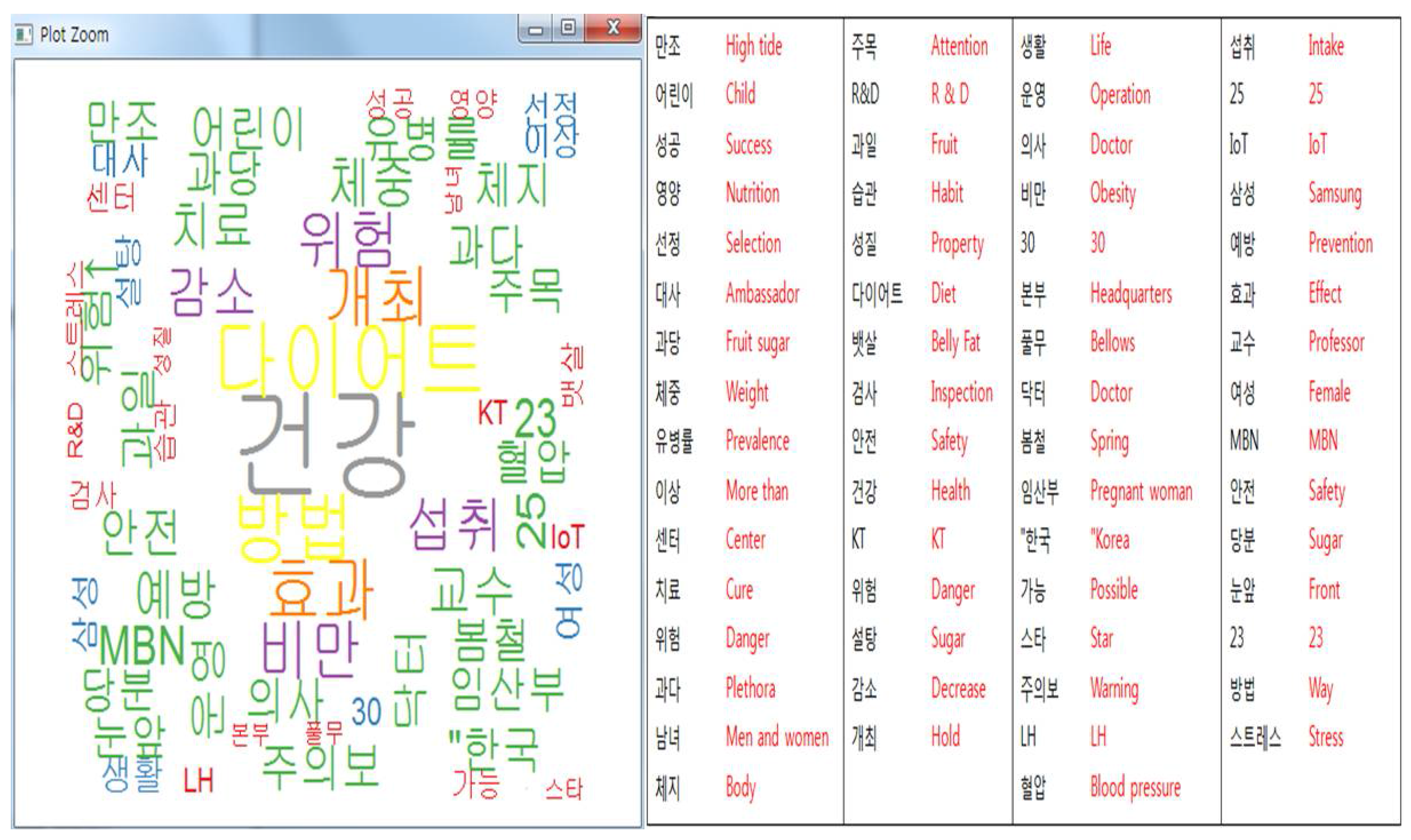
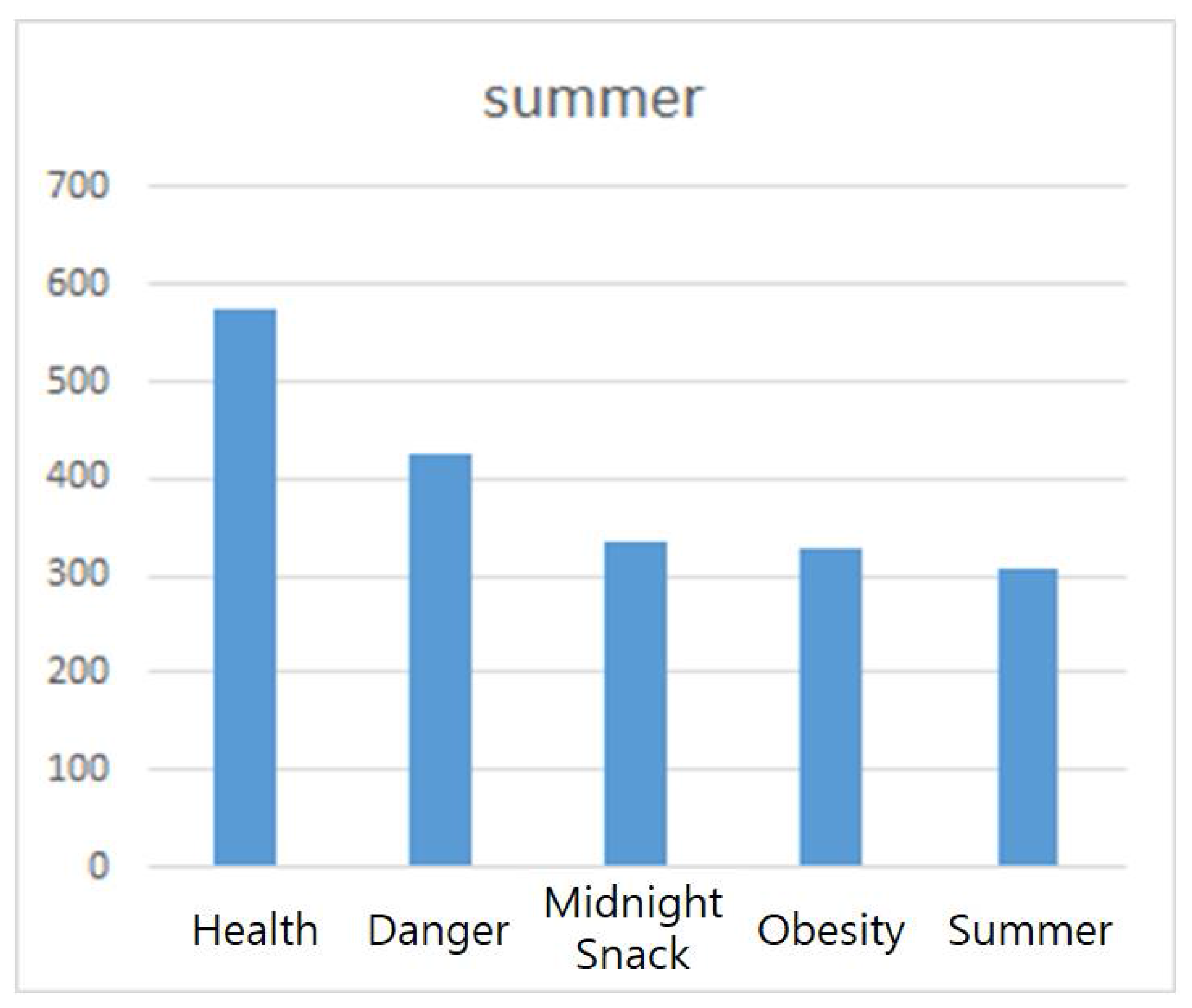
As shown in
Figure 20 and
Figure 21, the most commonly used words in summer were “health”, “risk”, “night snack”, “obesity”, and “summer”. During this period, interest in food and body shape is higher than in other seasons. It can be seen that they had more interest in diet habits for body fat management such as “summer”, “intake”, “food”, and “abdominal muscle”. In particular, due to the characteristics of the summer season, this result is attributable to the fact that the body shape was most noticeable and more prominent than in other seasons. In the next place, the study analyzed ‘fall.txt’, which crawled obesity news during the fall period.
As shown in
Figure 22 and
Figure 23, the three most frequently used words of “obesity news” in the fall period were “health”, “diet”, and “risk”, which did not show much difference compared to other seasons. Note, however, that the frequency of the two words “weight loss” and “fairy”, which have a low relationship with obesity, increased greatly. It is analyzed that “Kim Bok-joo, weightlifting fairy”, a drama aired during fall~winter 2016, has had great effect. It indicates that, in the crawling and word cloud processes, more caution is required regarding the filtering process that excludes unnecessary information. In addition to considering the exclusion of simple special characters, English alphabet, etc., it is also necessary to pay attention to the general public’s social interest.
In the next place, the study tried to visualize the change in the interest of the Korean people in obesity using the “biggest data-based service”, Google Trends, and check the relevant search terms to study the customized countermeasures according to obesity.
Meanwhile, as shown in
Figure 24, when we observe the graph of “obesity” change of interest of Google Trends over the last year, the interest was high in January and May compared to other periods but showed a sharp increase in December.
The influence of the drama as confirmed in the previous crawling process is analyzed to be large.
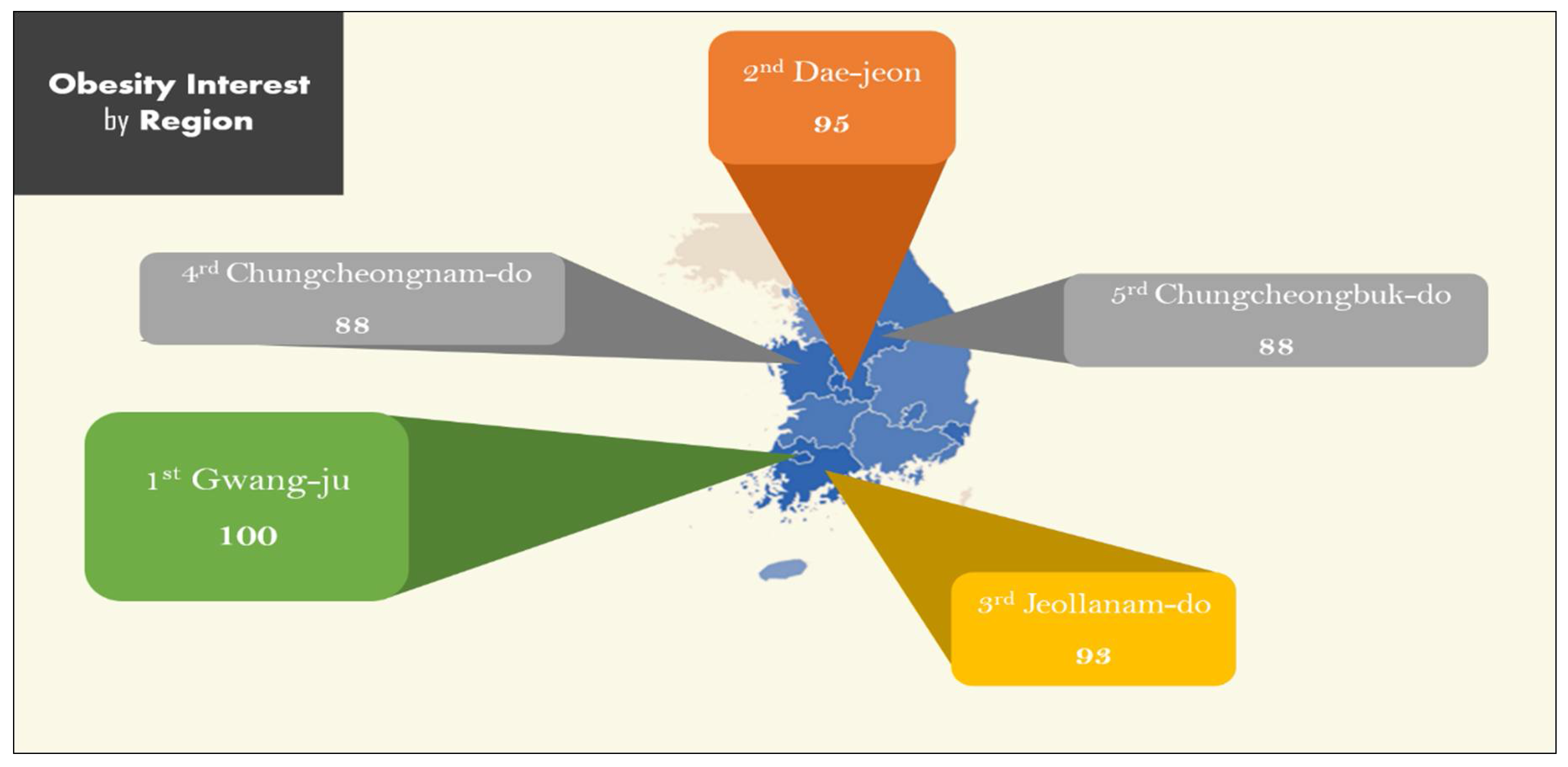
As shown in
Figure 25, Gwangju, Daejeon, and Jeollanam-do recorded 100, 95, and 93, respectively, indicating that they were most interested in obesity. Jeju Island recorded 45, which is the lowest. In this case, since the value of interest indicates the percentage of the total search words instead of the absolute search number, the residents of Jeju Island show that the interest in obesity is about half of that of Gwangju and Daejeon.
As shown in
Figure 26, interest was high in order of “lower body obesity”, “abdominal obesity”, “obesity clinic”, “childhood obesity”, and “high degree obesity”. Obese people are less concerned about the causes of obesity and are more likely to have obesity and abdominal obesity.
Next, this study analyzed crawl and word cloud for lower body obesity and abdominal obesity and customized measures. In Naver News, 126 pages and 1276 articles were formed as a result of the search for lower body obesity treatment, and 200 of them were crawled to generate a ‘lower.txt’ file. The search results for abdominal obesity treatment constituted 311 pages and 3120 articles, and 250 articles were crawled and stored as ‘ob.txt’.
As shown in
Figure 27,
Figure 28 and
Figure 29, words mostly related to lower body obesity treatment in
Naver News were diet, correction, and pelvis. For people with lower body obesity, exercise such as pelvic correction is helpful. In addition, considering the high frequency of the word “herbal”, oriental medicine such as herbal diet is considered effective. Besides, it seems that attention should be paid to words or complications that cause only lower incomes such as “swelling” and “pain”. Liposuction using injections is also mentioned as one of the treatment methods.
As shown in
Figure 30,
Figure 31 and
Figure 32, words most related to abdominal obesity treatment were health, diet, treatment, obesity, fat, and syndrome. The incidence of syndrome is higher than lower body obesity treatment, and it can be seen that various syndromes can be caused by abdominal obesity. As with lower body obesity treatment, abdominal obesity treatment is also considered to be highly effective in herbal diet, and caution is required because it can cause adult diseases such as diabetes and hypertension. Finally, this study searched the keyword “obesity” in the US search site
About.com and conducted a web crawl.
About.com is a US online information site founded in 1997, and it continues to operate to date. It has a lot of information in various fields such as food information and recipe, health, economy, and travel information since it has a long history of operation.
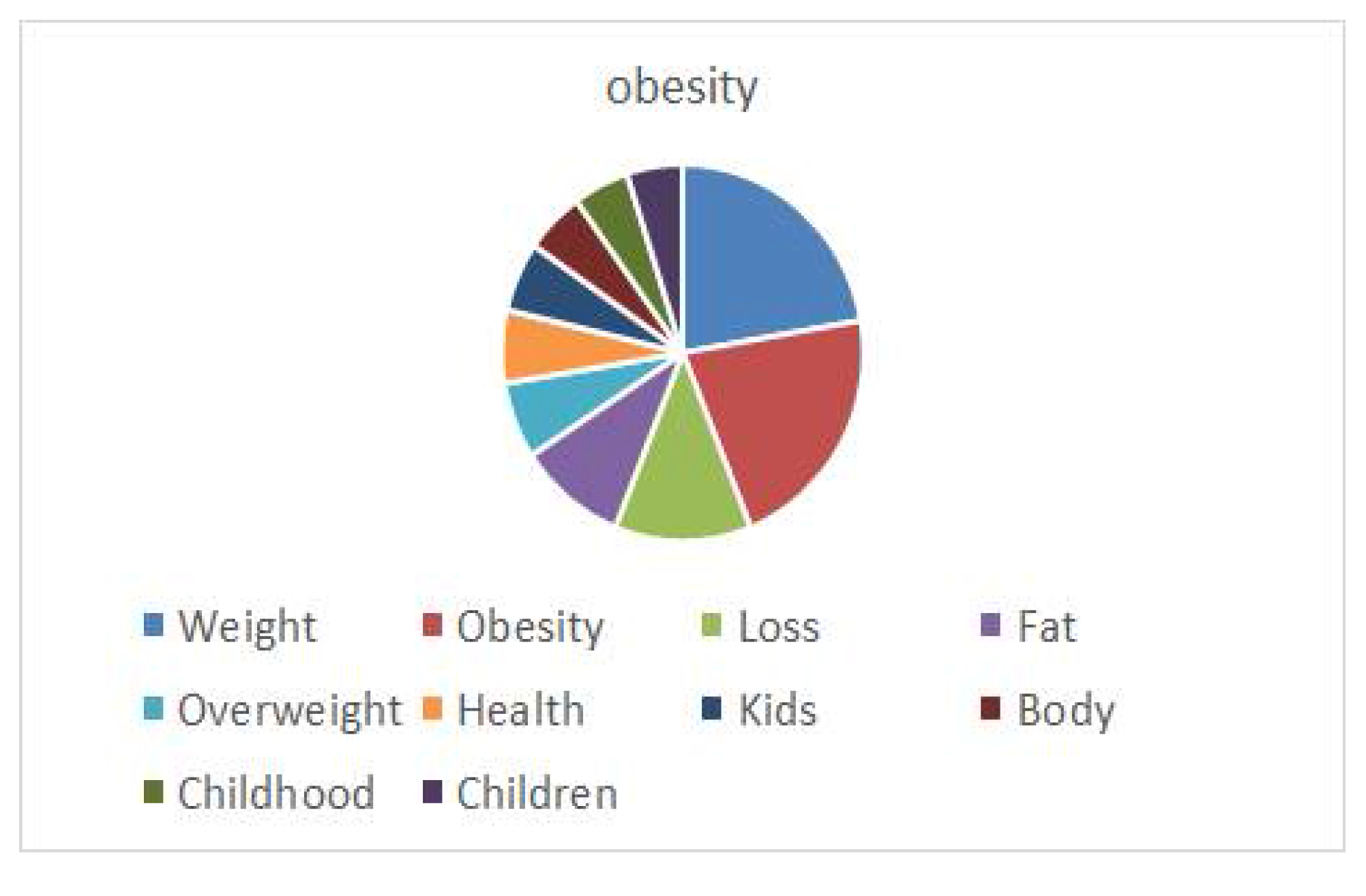
The search period for the news to crawl was 1 year from 1 January 2016 to 31 December 2016. Similar to previous data analysis, crawled words were extracted, filtered, and saved as ‘obesity.txt’ and visualized using word cloud. As shown in
Figure 33 and
Figure 34, the ten most commonly used words in the search results for “obesity” in
About.com are “Weight”, “Obesity”, “Loss”, “Fat”, “Overweight”, “Health”, “Kids”, “Body”, “Childhood”, and “Children”. Unlike Korea, in the US, the words “Kids”, “Childhood”, “Children”, and so on were used for words related to obesity. Since the US has a higher rate of childhood obesity than other countries, it focuses more on childhood life and diet habits related to obesity.
The analysis showed a wide range of seasonal factors according to spring, summer, fall, and winter. Its significance is that it completed visualization of the process of extracting the keywords appropriate for treatment of abdominal obesity and lower body obesity. In other words, this study collected big data by applying the machine learning and crawling methods to unstructured national health information data and search data of Naver News and Google and then visualized them using text mining and word cloud.
6. Conclusions and Future Work
In this paper, I analyzed the unstructured health data of one million Korean citizens using the datasets provided by the National Health Insurance Service using the machine learning and applied the text mining to the big data services such as Google Trends, Naver News, and About.com to analyzing the keyword big data for personalized health activities. It visualized the big data using text mining and word cloud. This study collected and analyzed the data concerning the interests related to obesity, change of interest on obesity, and treatment articles. The analysis showed a wide range of seasonal factors according to spring, summer, fall, and winter. Its significance is that it completed visualization of the process of extracting the keywords appropriate for treatment of abdominal obesity and lower body obesity.
As a result of analyzing the health examination information data set using the big data analysis tool R Studio, the distribution of obesity degree such as height and weight according to gender can be determined, including the obesity degree distribution according to body weight. Care should be taken when the weight exceeds 85 kg since the overweight and obese populations are high in that level. In addition to the various attributes used in this study, the health examination information data set contains more variables, so it is possible to analyze data from more diverse perspectives.
In the next place, data schematization such as crawling and word cloud can facilitate the analysis by clearly and concisely dividing the information. Nonetheless, careful attention is required because it can cause unintended and distorted results in the user’s data classification or at the schematization stage.
Meanwhile, seasonal obesity did not show a significant difference; the dramatic change in the interest rate of obesity in Google Trends in December is analyzed to have been influenced by the recent drama. The degree of interest in obesity by region was also significantly different. In particular, interest in obesity between Jeju residents and Gwangju and Daejeon residents had more than double the difference. Thus, future analysis on this issue would also have a significant effect on obesity. Abdominal obesity and lower body obesity were categorized as Naver News crawling, with lower body obesity showing that exercise such as pelvic correction was helpful and abdominal obesity showing a higher risk of obesity-related syndrome and adult disease. Herbal diet had an effect on both abdominal obesity and lower body obesity but higher frequency in the lower body obesity treatment.
The study included data collection and analysis of obesity-related areas of interest, changes in obesity interest, and treatment articles. It was a process of extracting keywords for the treatment of abdominal obesity and lower body obesity. Since each subject has different interests, interest level, and physical constitution, however, there is a need to select a variety of keywords suitable for the individual and perform big data analysis in order to prepare a countermeasure for more personalized treatment methods and health activities. Likewise, if big data is collected, processed, and analyzed using various techniques, it is expected to be able to prevent and treat various diseases including obesity.









































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}