Clickbait Convolutional Neural Network


 ,
,  ,
,
Abstract
:1. Introduction
- We proposed a clickbait convolutional neural network (CBCNN) model for the clickbait-detection problem. To the best of our knowledge, this is the first attempt to optimize a CNN model in clickbait detection.
- We designed a new word-embedding structure in this work. The new word-embedding layer takes both overall and type-related word meanings into consideration.
- We proposed a new loss function to regulate the influence of type-related word meaning.
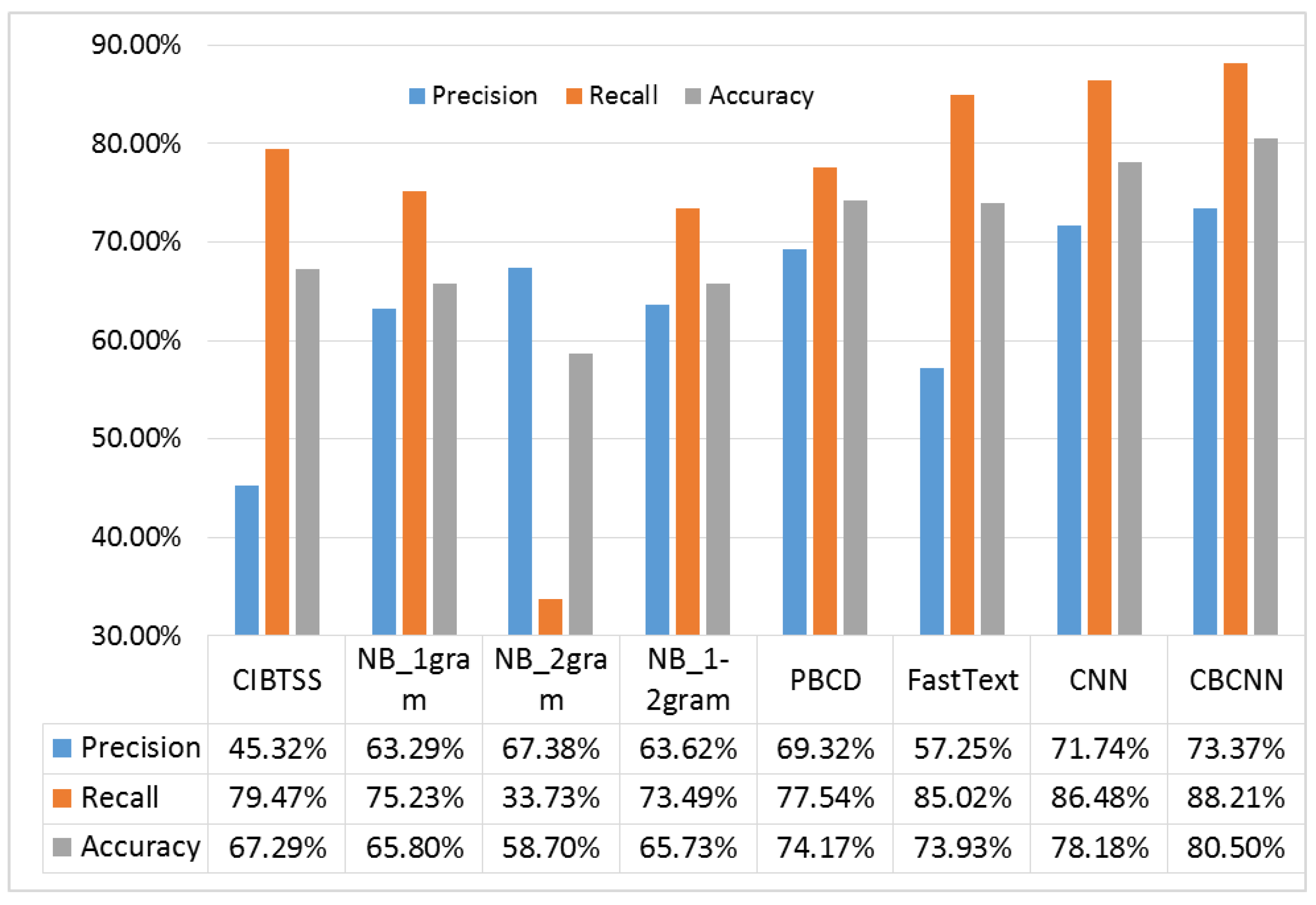
- We conducted extensive experiments, and the results show that the CBCNN model outperforms all the five baseline methods in terms of accuracy, precision and recall.
2. Related Work
2.1. Lexical Similarity Algorithms
2.2. Machine Learning Algorithms
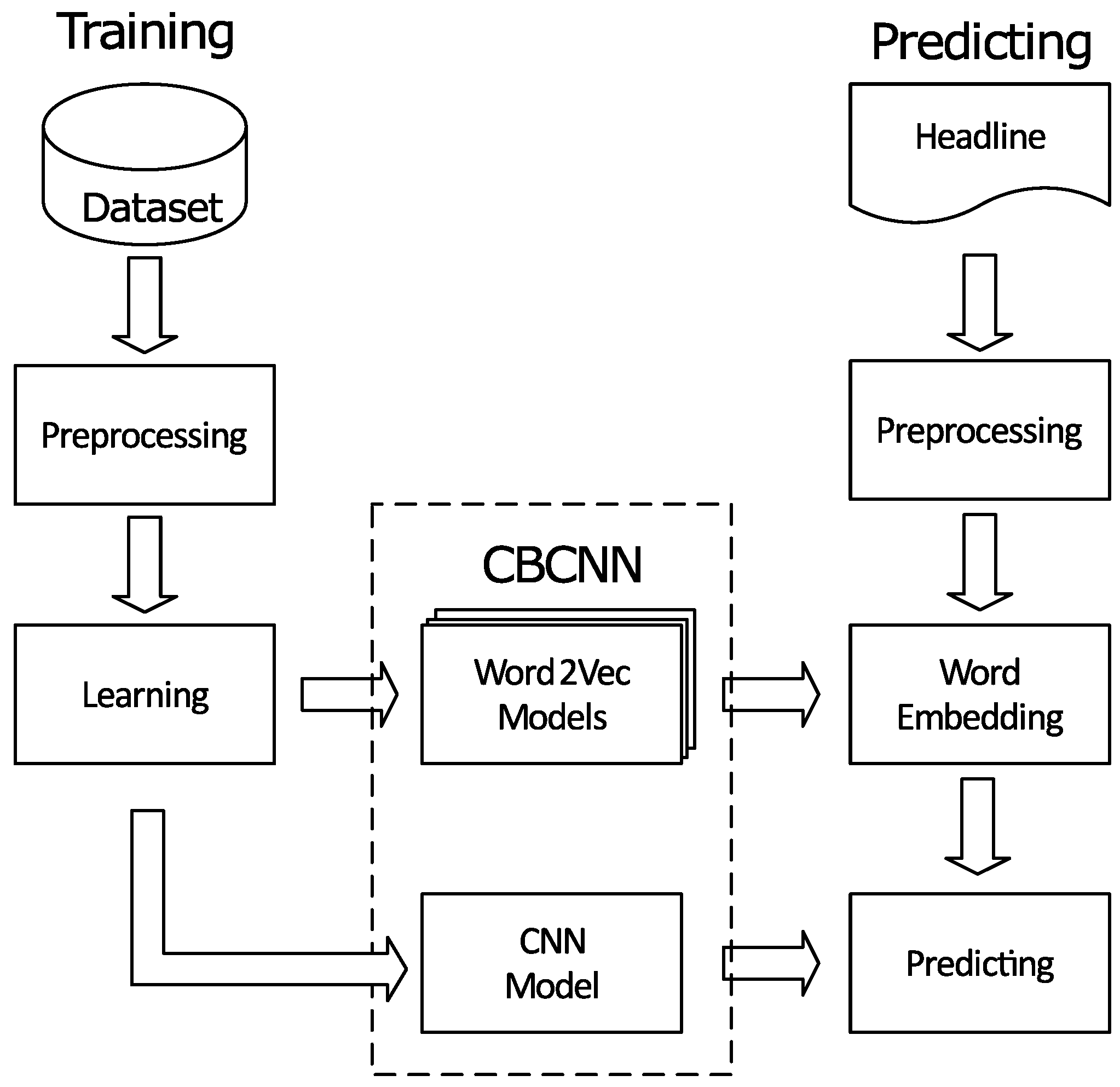
3. Methodology
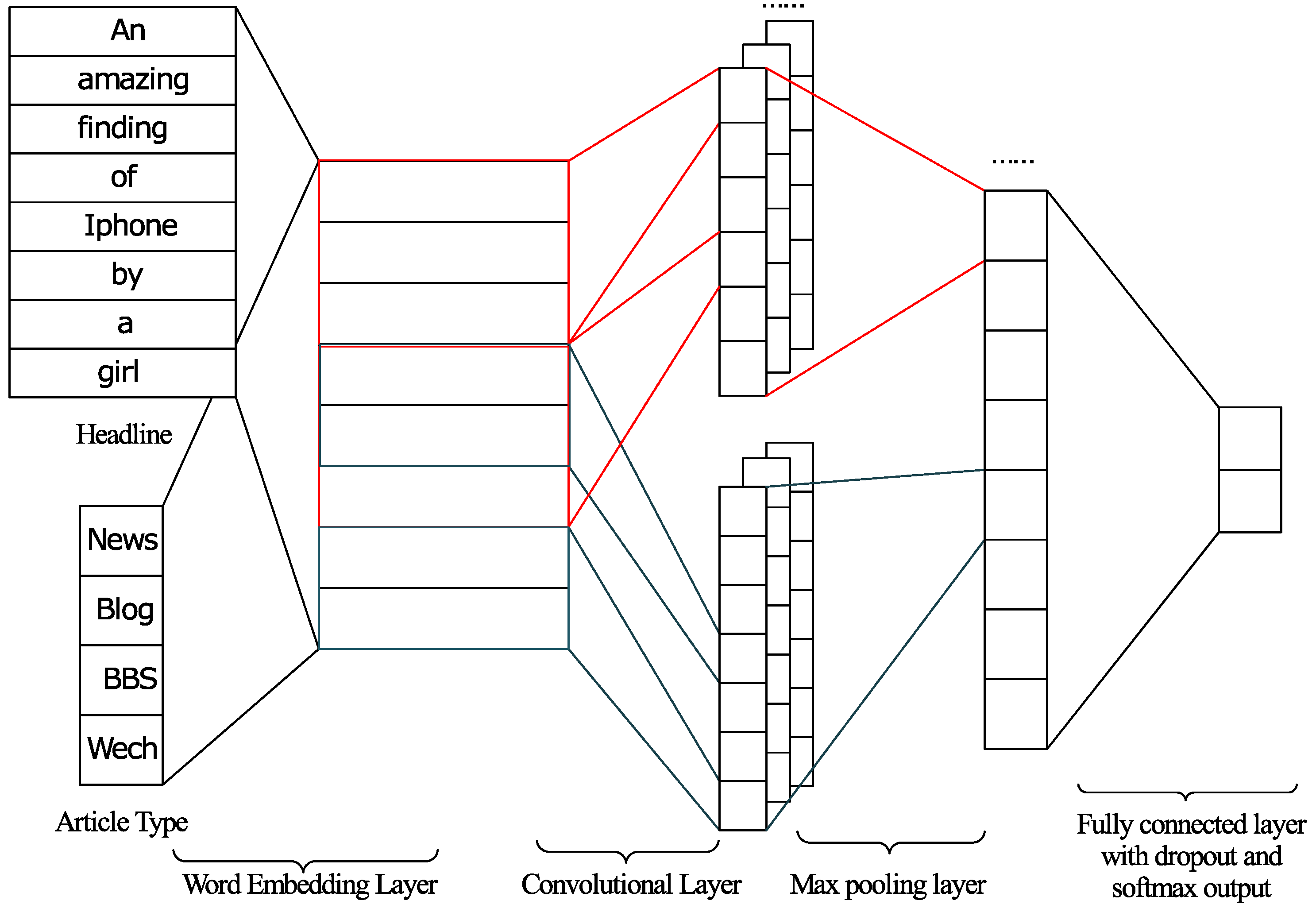
3.1. Word Embedding
3.2. Clickbait Convolutional Neural Network
4. Experiments and Discussions
4.1. Experiment Setup
- CIBTSS. Wang et al. [1] proposed a method detecting clickbait based on the lexical similarity between headline and content. Their method is named as CIBTSS.
- NB. The classic text classification method naive Bayes. We utilized unigrams and bigrams as the features of Bayes. The method that uses only unigrams is marked as , the method that uses only bigrams is named as , and the method that utilizes both unigrams and bigrams is marked as .
- PBCD. Biyani et al. [2] proposed series types of features for detecting clickbait, which is the latest machine learning-based method. Their features include unigram, bigram and a series of other newly defined features, such as the number of words, exclamatory marks and question marks. We named it as PBCD in this study.
- FastText. FastText [38] is a text-classification method similar to Word2Vec. Like Word2Vec, the sequence of words is considered in FastText. The learning algorithm of FastText is similar to the continuous bag-of-word (CBOW) model [39], which is a model learning distributed representations of words based on ordered words.
- TextCNN. TextCNN is evaluated by Agrawal [19]. As shown by Agrawal, the performance of TextCNN is the best among the five baselines.
4.2. Experimental Results
4.3. Discussion
- A number of clickbait articles tend to use similar words to attract users’ attention. Therefore, unigram-based machine learning algorithms figure out clickbait to a certain extent.
- Feature engineering is useful for clickbait detection, discarding the robustness problem.
- Word-sequence information helps machine learning algorithms to understand clickbait semantically.
- Various features are necessary for detecting clickbait, no matter if they had been extracted by feature engineering or by convolutional neural network means.
- The type-related features are important but undesirable when overvalued.
5. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Wang, Z.-C.; Weng, N.; Wang, Y. Research of Title Party News Identification Technology Based on Topic Sentence Similarity. New Technol. Lib. Inf. Serv. 2011, 11, 48–53. [Google Scholar] [CrossRef]
- Biyani, P.; Tsioutsiouliklis, K.; Blackmer, J. “8 Amazing secrets for getting more clicks”: Detecting clickbait in news streams using article informality. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Chakraborty, A.; Paranjape, B.; Kakarla, S.; Ganguly, N. Stop clickbait: Detecting and preventing clickbait in online news media. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, San Francisco, CA, USA, 18–21 August 2016; pp. 9–16. [Google Scholar]
- Potthast, M.; Köpsel, S.; Stein, B.; Hagen, M. Clickbait Detection. In Proceedings of the 38 European Conference on Information Retrieval, Padua, Italy, 20–23 March 2016. [Google Scholar]
- Chen, Y.; Conroy, N.J.; Rubin, V.L. Misleading online content: Recognizing clickbait as “False News”. In Proceedings of the ACM Workshop on Multimodal Deception Detection, Seattle, WA, USA, 9–13 November 2015; pp. 15–19. [Google Scholar]
- Abbasi, A.; Zhang, Z.; Zimbra, D.; Chen, H.; Nunamaker, J.F. Detecting fake websites: The contribution of statistical learning theory. Mis Q. 2010, 34, 435–461. [Google Scholar] [CrossRef]
- Abbasi, A.; Chen, H. A comparison of fraud cues and classification methods for fake escrow website detection. Inf. Technol. Manag. 2009, 10, 83–101. [Google Scholar] [CrossRef]
- Ntoulas, A.; Najork, M.; Manasse, M.; Fetterly, D. Detecting spam web pages through content analysis. In Proceedings of the World Wide Web Conference, Edinburgh, Scotland, 23–26 May 2006; pp. 83–92. [Google Scholar]
- Lahiri, S.; Mitra, P.; Lu, X. Informality judgment at sentence level and experiments with formality score. In CICLing 2011: Computational Linguistics and Intelligent Text Processing; Springer: Berlin/Heidelberg, Germany, 2011; pp. 446–457. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Haykin, S.; Kosko, B. GradientBased Learning Applied to Document Recognition; IEEE: New York, NY, USA, 2009; pp. 306–351. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. Eprint Arxiv, 2014; arXiv:1408.5882. [Google Scholar]
- Mikolov, T.; Le, Q.V.; Sutskever, I. Exploiting Similarities among Languages for Machine Translation. Comput. Sci. 2013. [Google Scholar] [CrossRef]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. Comput. Sci. 2014, 4, 1188–1196. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2015; pp. 1753–1762. [Google Scholar]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks. In Proceedings of the Association for Computational Linguistics, Beijing, China, 26–31 July 2015. [Google Scholar]
- He, H.; Gimpel, K.; Lin, J. Multi-Perspective Sentence Similarity Modeling with Convolutional Neural Networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portuga, 17–21 September 2015; pp. 1576–1586. [Google Scholar]
- Agrawal, A. Clickbait detection using deep learning. In Proceedings of the IEEE 2016 2nd International Conference on Next Generation Computing Technologies (NGCT), Dehradun, India, 14–16 October 2016; pp. 268–272. [Google Scholar]
- Gabrilovich, E.; Markovitch, S. Computing semantic relatedness using Wikipedia-based explicit semantic analysis. In Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; pp. 1606–1611. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.; Zemel, R.S.; Torralba, A.; Urtasun, R.; Fidler, S. Skip-Thought Vectors. Comput. Sci. 2015; arXiv:1506.06726. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2012, 12, 2825–2830. [Google Scholar]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating Continuous Distributions in Bayesian Classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Montréal, QC, Canada, 18–20 August 2013; pp. 338–345. [Google Scholar]
- Molek-Kozakowska, K. Coercive Metaphors in News Headlines a Cognitive-Pragmatic Approach. Brno Stud. Engl. 2014, 40, 149–173. [Google Scholar] [CrossRef]
- Cessie, S.L.; Houwelingen, J.C.V. Ridge Estimators in Logistic Regression. J. R. Stat. Soc. 1992, 41, 191–201. [Google Scholar] [CrossRef]
- Lewis, D.D. Naive (Bayes) at Forty: The Independence Assumption in Information Retrieval; Springer: Berlin/Heidelberg, Germany, 1998; pp. 1204–1206. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zheng, H.T.; Yao, X.; Jiang, Y.; Xia, S.T.; Xiao, X. Boost clickbait detection based on user behavior analysis. In APWeb-WAIM 2017: Web and Big Data; Springer: Cham, Switzerland, 2017; pp. 73–80. [Google Scholar]
- Anand, A.; Chakraborty, T.; Park, N. We used Neural Networks to detect clickbait: You won’t believe what happened Next! In ECIR 2017: Advances in Information Retrieval; Springer: Cham, Switzerland, 2017; pp. 541–547. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv, 2014; arXiv:1409.1259. [Google Scholar]
- Santos, C.D.; Zadrozny, B. Learning character-level representations for part-of-speech tagging. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Beijing, China, 21–26 June 2014; pp. 1818–1826. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On Loss Functions for Deep Neural Networks in Classification. Schedae Inform. 2016, 25, 49–59. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. Comput. Sci. 2012, 3, 212–223. [Google Scholar]
- Bouvrie, J.; Massachusetts Institute of Technology, Cambridge, MA, USA. Notes on Convolutional Neural Networks. Unpublished work. 2006. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. Comput. Sci. 2016; arXiv:1607.01759. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. Comput. Sci. 2013; arXiv:1301.3781. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| TextCNN | ||||||
|---|---|---|---|---|---|---|
| Precision | 69.21% | 71.32% | 73.37% | 72.59% | 71.74% | 71.74% |
| Recall | 81.34% | 84.31% | 88.21% | 87.35% | 86.48% | 86.48% |
| Accuracy | 74.16% | 77.54% | 80.5% | 79.84% | 78.18% | 78.18% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, H.-T.; Chen, J.-Y.; Yao, X.; Sangaiah, A.K.; Jiang, Y.; Zhao, C.-Z. Clickbait Convolutional Neural Network. Symmetry 2018, 10, 138. https://doi.org/10.3390/sym10050138
Zheng H-T, Chen J-Y, Yao X, Sangaiah AK, Jiang Y, Zhao C-Z. Clickbait Convolutional Neural Network. Symmetry. 2018; 10(5):138. https://doi.org/10.3390/sym10050138
Chicago/Turabian StyleZheng, Hai-Tao, Jin-Yuan Chen, Xin Yao, Arun Kumar Sangaiah, Yong Jiang, and Cong-Zhi Zhao. 2018. "Clickbait Convolutional Neural Network" Symmetry 10, no. 5: 138. https://doi.org/10.3390/sym10050138
APA StyleZheng, H.-T., Chen, J.-Y., Yao, X., Sangaiah, A. K., Jiang, Y., & Zhao, C.-Z. (2018). Clickbait Convolutional Neural Network. Symmetry, 10(5), 138. https://doi.org/10.3390/sym10050138