1. Introduction
With the continuous development of the Internet and manufacturing industries, high-tech products, such as computers and smart electronic devices, are being used extensively in daily life and manufacturing research. The chassis is one of the key components of these mechanical and electronic devices. On the outside, assembled parts are fixed to the chassis by nuts, and they are connected to circuit wires on the inside.
Figure 1 shows an image of a general-purpose computer chassis, which facilitates power-switching and signal input and output through various assembly components, thereby realizing communication and control functions.
The chassis is the key protection structure of electronic equipment, data communication equipment, and information technology equipment. Therefore, the quality of the chassis assembly directly affects the use of the product, and it is necessary to test and analyze its quality. Accordingly, it is necessary to identify the position of the actual assembly, obtain assembly position information, and analyze the quality according to the assembly standard. However, it is difficult to perform the inspection task efficiently and with high quality using the traditional manual detection method because the assembly parts of the chassis have many features and complicated configurations. It is thus essential to develop new detection methods. At present, various detection methods for assembly and electronic components have been proposed. These methods can be divided into two categories: reference image detection and non-reference image detection [
1].
In reference image detection methods, the image to be detected is compared with a reference image. As such, it is necessary to specify a standard reference image, through which the degree of similarity between the detected object and the standard is obtained [
2]. For this purpose, the histogram and template matching algorithms are mainly implemented. The former is used to calculate the image histogram and normalize it based on simple vector similarity versus an image similarity metric. Zeng et al. proposed a method based on a sector descriptor to effectively improve the accuracy of blasthole defect recognition by dividing the gradient histogram [
3]. Tahir et al. extracted the directional gradient feature histogram from the University of Bremen to form a feature vector for solving the problem of unclear boundary of image noise area [
4]. As the histogram is the probability distribution of the gray value of the reaction image and there is no image space position information, it is prone to large amounts of information loss. The template matching algorithm locates the position of a particular object in the image and then identifies the object. Kumar et al. [
5] proposed a detection algorithm for image enhancement and standard template generation to automatically detect reference matching defects; the detection time of the algorithm is as short as 14 ms. Kim et al. used a feature matching defect detection method to determine the corresponding relationship between feature sets to detect faults [
6]. Huang et al. proposed a standard machine assembly quality machine vision method based on One Versus Rest One Versus Rest (OVR-SVM) and realized the assembly quality evaluation of standard components based on the support vector machine by using the One Versus Rest (OVR) strategy [
7]. Srisaila et al. proposed utilizing the connection component and template matching technology to solve the problems of image blur and uneven brightness, and complete image segmentation and matching tasks [
8]. The template matching algorithm is simple, and highly effective detection can be achieved under ideal conditions, but it is difficult to obtain better detection effects using it in cases of rotation or size change of the matching target in the original image.
The non-reference image detection approach extracts image features and performs detection according to detection criteria or rules without reference images. Minaee S et al. realized image foreground and background separation through image signal decomposition and achieved good segmentation effect for some pictures with prominent foreground, with segmentation algorithm precision up to 95% [
9,
10]. However, it is suitable for image segmentation with a prominent foreground. Deep learning is a typical method for non-reference image detection, in which training is performed layer by layer through unsupervised learning methods and then optimization is performed using a supervised backpropagation algorithm [
11,
12]. Therefore, multiple model structures with deep learning have been widely used in image detection. Semantic segmentation network in deep learning has been widely used in image detection. Badrinarayanan V et al. designed a semantic segmentation network based on VGG to solve the problem of semantic segmentation of images recognized by autonomous driving or intelligent robots, but its classification effect still cannot be applied in practice [
13]. Romera-paredes B et al. proposed a case segmentation model based on recursive neural network, which can realize the case segmentation of blocked images in sequence and solve the segmentation problem of blocked images [
14]. Because the deep learning method exhibits strong data fitting ability and has the learning advantage of simulating the human brain structure, by applying the deep learning method to practical detection, such as automatic driving, better and rapid detection results can be obtained. However, errors may still occur owing to the low sample set limit of the specific test object [
15,
16,
17].
In recent years, the cascade network of researchers has achieved better results [
18]. For example, existing approaches [
19,
20,
21,
22,
23,
24,
25,
26,
27,
28] have been proposed to use the cascade network method. The method is easy to define and combined with the deep learning method, such as R-CNN. Aiming at the limitations of the neural network in the detection of a class of objects, expert prior knowledge [
20] and information system [
21] are added to solve the problem of small data set samples, and at the same time to improve the classification accuracy of detection objects under the condition of small training data set, so as to reduce the detection error rate caused by classification errors.
Deep learning can be used to extract multi-layer features of detected objects in an image, and adapt to the detection in different environments, such as diverse backgrounds and complex illumination. With these advantages, it is widely used in image recognition and detection. However, to the best of our knowledge, the application of deep learning to chassis assembly inspection has not yet been investigated. In order to find a simpler and more effective detection and identification method, this paper proposes the adoption of a non-reference method. By transforming the chassis image into a pixel prediction mask based on an example segmentation of deep learning, detection and identification of each component of the chassis are realized, in order to solve the detection problem caused by the limited sample set, we adopt cascade network and join the standard dictionary (SD) network pixel information divided and output according to the example is used for positioning, and the outer shape of the chassis and the size of the component are determined.
The main contributions of this paper are as follows:
(1) A (SD) Mask regional CNN (R-CNN) based component instance segmentation method is proposed to handle assembly quality inspection tasks. Compared with other methods, the detection results are obtained more quickly and accurately under complex illumination conditions and backgrounds.
(2) The proposed method solves the problem of chassis assembly parts being prone to misdetection due to the numerous parts and complex types. Furthermore, the component mask can be quickly and accurately acquired, and the component category and assembly quality information obtained. Next an SD is built according to the identification of the chassis model and the authentication SD selected to achieve chassis assembly detection and identification.
(3) Cascade architecture [
18] was used to connect the SD with Mask R-CNN, achieving better detection results under the condition of limited sample sets.
The remainder of this paper is organized as follows:
Section 2 introduces the Mask R-CNN component instance segmentation method, SD Mask R-CNN model, and Mask R-CNN based component instance segmentation and positioning.
Section 3 describes the chassis detection method.
Section 4 outlines the multiple sets of experiments conducted and analyzes the results obtained. Finally,
Section 5 presents concluding remarks.
2. Background of the Proposed Method
In this study, Mask R-CNN was first introduced into the basic framework of Faster R-CNN to achieve pixel-level segmentation. Then, the SD corresponding to the chassis model was built, and the SD Mask R-CNN model established. Finally, the instance segmentation method was implemented. This method incorporates the full convolutional network (FCN) and region of interest align (ROIAlign) techniques to achieve accurate segmentation of the chassis image and processing of corresponding pixel values [
29].
2.1. SD Mask R-CNN Model
Mask R-CNN, developed by Kaiming et al. [
30], is an extension of Faster R-CNN. For each proposal box of Faster R-CNN, FCN is used for semantic segmentation, and the segmentation task is performed simultaneously with positioning and classification tasks [
29,
31,
32]. Faster R-CNN is used to input an entire picture into CNN, and it performs detection by extracting the feature frame candidate frame convolution, classification, and regression adjustment position.
Figure 2 shows a flowchart of Faster R-CNN. ResNet-101+FPN is used as the feature extraction network to achieve the highest state-of-the-art effect, and ROIAlign is used to solve the misalignment problem. A Mask R-CNN pre-training network is well adapted to multi-class object detection, converges to the ideal state faster, and achieves image instance segmentation. The special structure of CNN local weight sharing has unique advantages in image processing; in particular, images of multi-dimensional input vectors can be directly input into the network to avoid the complexity of data reconstruction in the feature extraction and classification process [
33,
34,
35,
36]. Therefore, Mask R-CNN is used to extract and classify the chassis components to implement instance segmentation. More details on Mask R-CNN can be found in [
30].
Mask R-CNN is a general framework for object instance segmentation that accurately detects objects in an image while generating a segmentation mask for each instance. It consists mainly of two modules: a convolution backbone architecture for feature extraction on the entire image and an upper layer network for border recognition (classification and regression) and mask prediction, which is applied to each region of interest (ROI). Because Mask R-CNN can complete image instance segmentation and find and classify objects, each type of component can be re-identified and the spatial position information of each object can be obtained. However, only identification of the detection object is realized, and the detection and identification cannot be directly completed according to the instance division information. There are many types of chassis components, and the same type of components have the same shape. According to the characteristics of the assembly standard of each model, we can judge the information by constructing the SD corresponding to the chassis model.
After the image of the chassis to be detected is input, the CNN is first used for feature extraction. For each anchor point, nine bounding boxes are generated according to different sizes (128, 256, 512 pixels) and different aspect ratios (1:1, 0.5:1, 1:0.5). Simultaneously, a full CNN is used to distinguish and initially locate multiple ROIs. Then, through size transformation, it enters the full CNN and Mask structure. The full CNN completes the boundary regression and classification task, and Mask completes the pixel-level instance segmentation task. Subsequently, the class information is used to identify the chassis model, find the corresponding dictionary, and finally the dictionary is used to realize identification of the chassis assembly parts.
During the overall detection process, the input feature vector is defined, where x,y,w,h are the coordinates of the center point of the feature map and the width and height, respectively. The predicted bounding box feature vector is
Then, the loss function can be expressed as follows:
where
is the correctly calibrated ground truth,
is the learning parameter, and
is the input feature vector.
Following classification, border selection, and mask calculation, the multitasking loss function is defined as follows:
where
is the classification loss,
is the frame loss, and
is the mask loss.
2.2. Instance Segmentation
In general, target segmentation refers to semantic segmentation. Semantic segmentation has a long history of development and significant progress has been made. Furthermore, many scholars are currently conducting research in this area. Semantic segmentation and instance segmentation are used to segment the input image, and instance segmentation is a small field that is independent of the target segmentation domain. The instance segmentation requires finer segmentation of similar objects on the basis of semantic segmentation [
37,
38,
39]. The instance segmentation algorithm can be used to perform more precise classification tasks for chassis assembly parts that may be similar, such as USB2.0 and USB3.0, audio input, and output interfaces, thus achieving accurate identification.
2.2.1. Full Convolutional Networks
A full convolutional network (FCN) is a hierarchical structure that can generate features through pixel-to-pixel training. It is one of the most advanced techniques for segmentation. The advantage is to build an FCN that accepts image inputs of any size and generates outputs of the corresponding size through effective reasoning and learning [
29]. An FCN consists of upsample, skip layer, and convolution sections, and classifies the image at the pixel level. It can accept input images of any size and uses the deconvolution layer to upsample the last convolutional feature map to restore it to the same size as the input image, thus producing a prediction for each pixel. At the same time, the spatial information in the original input image is preserved, and the feature map of the upper and lower parity is finally subjected to pixel classification.
2.2.2. Region of Interest Align
Region of interest align (ROIAlign) is proposed to solve the problem of large pixel errors in ROI Pooling candidate frame boundary quantization and cell boundary quantization. To achieve instance segmentation, the impact of errors on the target must be reduced. Therefore, properly constructing the mask branch is critical to achieving good results. ROI Pooling uses the rounding method to quantize twice, resulting in a more severe deviation of the candidate area, while ROIAlign can preserve the precise spatial position. First, ROIAlign can increase the mask accuracy to 10% to 50%, showing a greater advantage in more stringent position measurements. Second, decoupling masks and class predictions are critical. In the absence of inter-class competition, predicting binary masks independently for each class depends on the network ROI classification branch to predict the class [
30].
Following feature extraction of the chassis image, the quantization operation is cancelled, and the image value on the pixel with coordinates of floating point numbers is obtained using the bilinear interpolation method, thereby converting the entire feature aggregation process into a continuous operation.
Figure 3 shows an example of the ROIAlign calculation of the chassis components. Input a 1200 by 900 image with a 175 by 75 bounding box (USB2.0). After the image is extracted through the trunk network, the stride of the feature map is 48. So, both the image and the bounding box are 1/48 of the length of the input. Eight hundred is exactly divisible by 32 into 25. but when dividing 900 by 48 you get 18.75, which is not going to be quantified. Both the chassis image and the feature map, as well as the ROI feature map, use the bilinear interpolation method to reduce the error [
31].
3. Proposed Method
According to the algorithm described in
Section 2, a chassis assembly detection and identification method based on deep learning component instance segmentation is proposed.
Figure 4 shows a flowchart of the proposed chassis assembly detection and identification method. First, Mask R-CNN extracts the chassis image features. The extracted feature is composed of a set of multi-dimensional multivariate vectors, which represent attributes in the chassis image: component classification result, ROI spatial position information, frame offset, and mask information.
Table 1 shows a list of vectors obtained by chassis image feature extraction.
The component classification structure is represented by the corresponding reference numerals; ROI spatial position information is represented by the upper left corner and the lower right corner vertical and horizontal coordinates of the rectangular frame; the border offset is represented by the offset value of the real box and the anchor; the mask information is represented by a Boolean array whose corresponding polygon value is valid. Then, according to the classification information, the corresponding assembly rule is selected by using the SD. Because misassembly and leak assembly of the assembly components randomly occur and are unpredictable, the identification cannot be directly performed using the detected image. The number and types of assembly of components in the image can be obtained through case segmentation, but it cannot guide whether there is wrong assembly or missing assembly, and cascade network is an effective method for deep learning implementation [
18]. Therefore, each component of the chassis is accurately identified through a practical SD, and leakage of the assembly is confirmed according to the number of component classification results. If the chassis model is not detected or model does not exist in the SD, it is returned for re-detection. Finally, the quality of the chassis is analyzed by the identification result.
Figure 4 shows a flowchart of the detection and identification methods for chassis assembly.
3.1. Mask R-CNN Based Components Instance Segmentation
As mentioned earlier, in the first step of the method, Mask R-CNN performs convolution and vectorization of the chassis image and extracts the anchor point in the form of a vector, and then performs feature extraction, full convolution, classification, regression, mask, etc., as in the previous one.
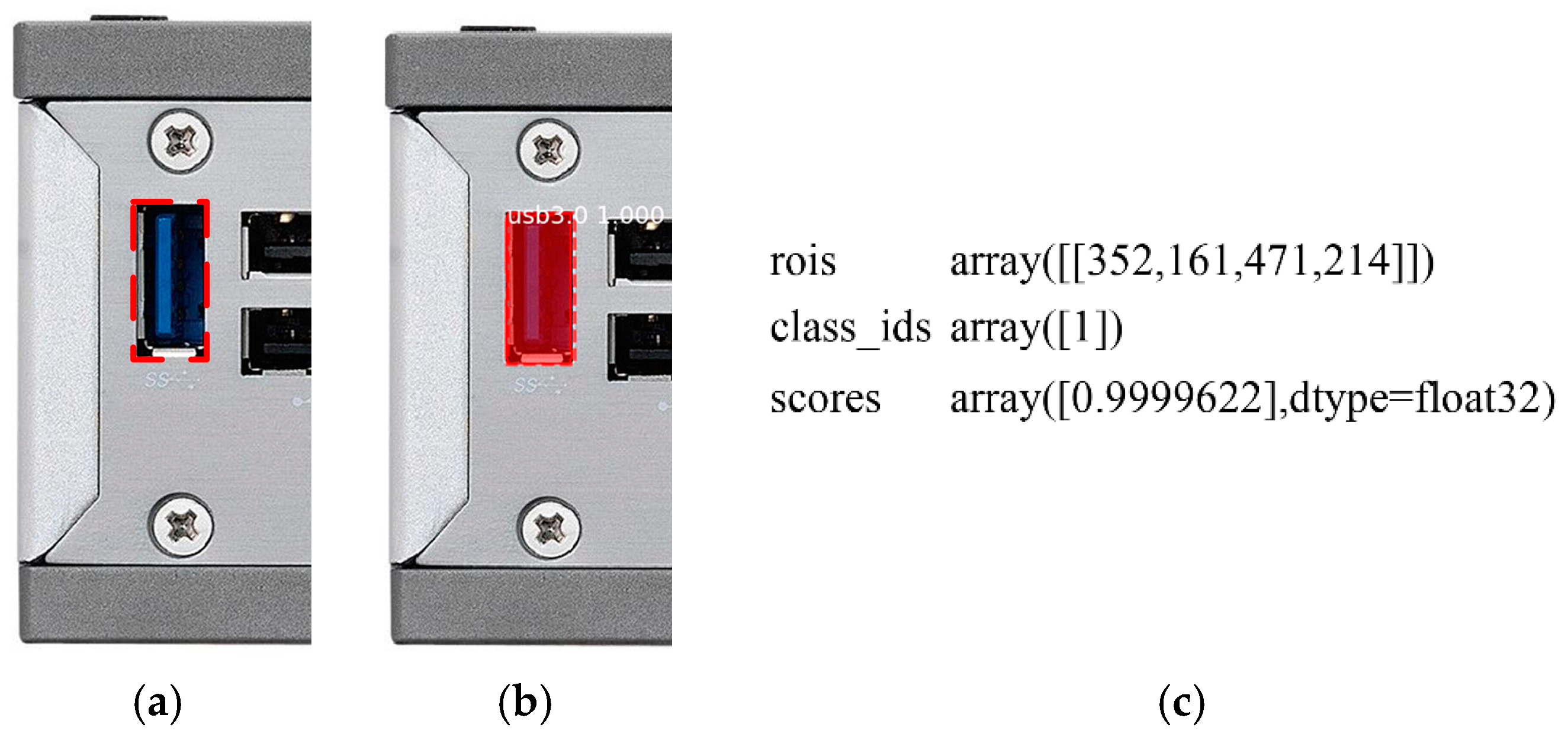
Figure 5 shows the positioning example of USB3.0 instance segmentation.
Figure 5a is an example of the component USB3.0 that needs to be positioned in the original chassis assembly image, and the area within the dotted line is the positioning information to be obtained.
Figure 5b is an example of the feature extraction diagram of the chassis detection component USB3.0; ROI positioning information is extracted after the instance is segmented.
Figure 5c shows ROI positioning information of USB3.0, including the coordinates of the upper left corner
and the coordinates of the lower right corner
. The ROI geometric center is defined as the component positioning point
and solved using Equation (4).
Through the above step, instance segmentation of each component is completed, and the classification result and frame offset are output.
Figure 6 shows an example based on Mask R-CNN instance segmentation, where
Figure 6a is an example of the original chassis assembly image. The area inside the dotted line is the model to be tested and the assembly parts;
Figure 6b is the chassis assembly detection feature extraction map. From
Figure 6b, it can be seen that USB2.0, USB3.0, NP and other components can be detected and perfect semantic segmentation Instance segmentation of each component is realized and the component name is accurately obtained.
3.2. SD Construction Method and Detection Cethod
The chassis component information extracted in the previous section is used to perform authentication, which is a technique for automatically extracting information to be authenticated using deep learning methods.
Table 2 shows an example of SD storage. First, the SD, which includes the chassis model, chassis size, number of assembly parts, name of each component, and corresponding assembly location, should be established. The chassis size is the length of the upper left corner and the lower right corner of the chassis; the assembly position of each component is represented by the spatial distance from the geometric center to the geometric center of the chassis. SD has a three-level structure: the first level is the chassis model; the second level is the chassis size, the number of assembled components, and the name of each component; the third level is the corresponding assembly position of each component.
SD can be found through the keyword, that is, the chassis model is defined as the Keywords: The corresponding information of SD can be obtained through the chassis model, and the positioning of the component name can be obtained to determine whether it is correctly assembled.
Figure 7 is the implementation process of SD:
As the angle between the chassis and industrial camera cannot be guaranteed in actual shooting, an identification method capable of adapting to rotation and translation is proposed. The proposed method satisfies the positional arbitrariness of the chassis image.
Figure 8 is an example of shooting at any angle. Because the translation and rotation of the same shooting plane does not cause a change in the size of the space of the chassis during shooting, only the rotation different from the shooting plane needs to be considered.
In order to facilitate the calculation, the rotation can be regarded as rotating around a certain point. By constructing a circle to simplify the calculation process, the actual position of the industrial camera shooting chassis can be mapped to the shooting plane. Then the rotation angle
can be expressed by Equation (5):
where
is
-class chassis;
and
are the coordinates of the upper left corner and lower right corner of the chassis in the image when the front is photographed;
and
are the coordinates of the upper left corner and lower right corner of the chassis in the image during actual shooting.
Then, the chassis image is detected by Mask R-CNN. The process has been described in detail in the previous section. In order to realize the chassis assembly identification, each component assembly needs to be identified. Therefore, the chassis image detection feature vector list information with the SD is used for identification according to the chassis model, and the component identification result is obtained by using the feature of the chassis image extraction in
Figure 6 and SD of
Table 2.
Defining the chassis geometry center as the component assembly reference point, the true assembly space distance between each component and the chassis is obtained:
According to Equations (4) and (5), Equation (6) is reduced to
Then, according to SD, each component is identified. If the component space distance is within the standard distance, the assembly is correct; otherwise, the assembly error is identified using Equation (8):
Finally, the chassis assembly test results are obtained as shown in Equation (9):















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}