3D Capsule Hand Pose Estimation Network Based on Structural Relationship Information


Abstract
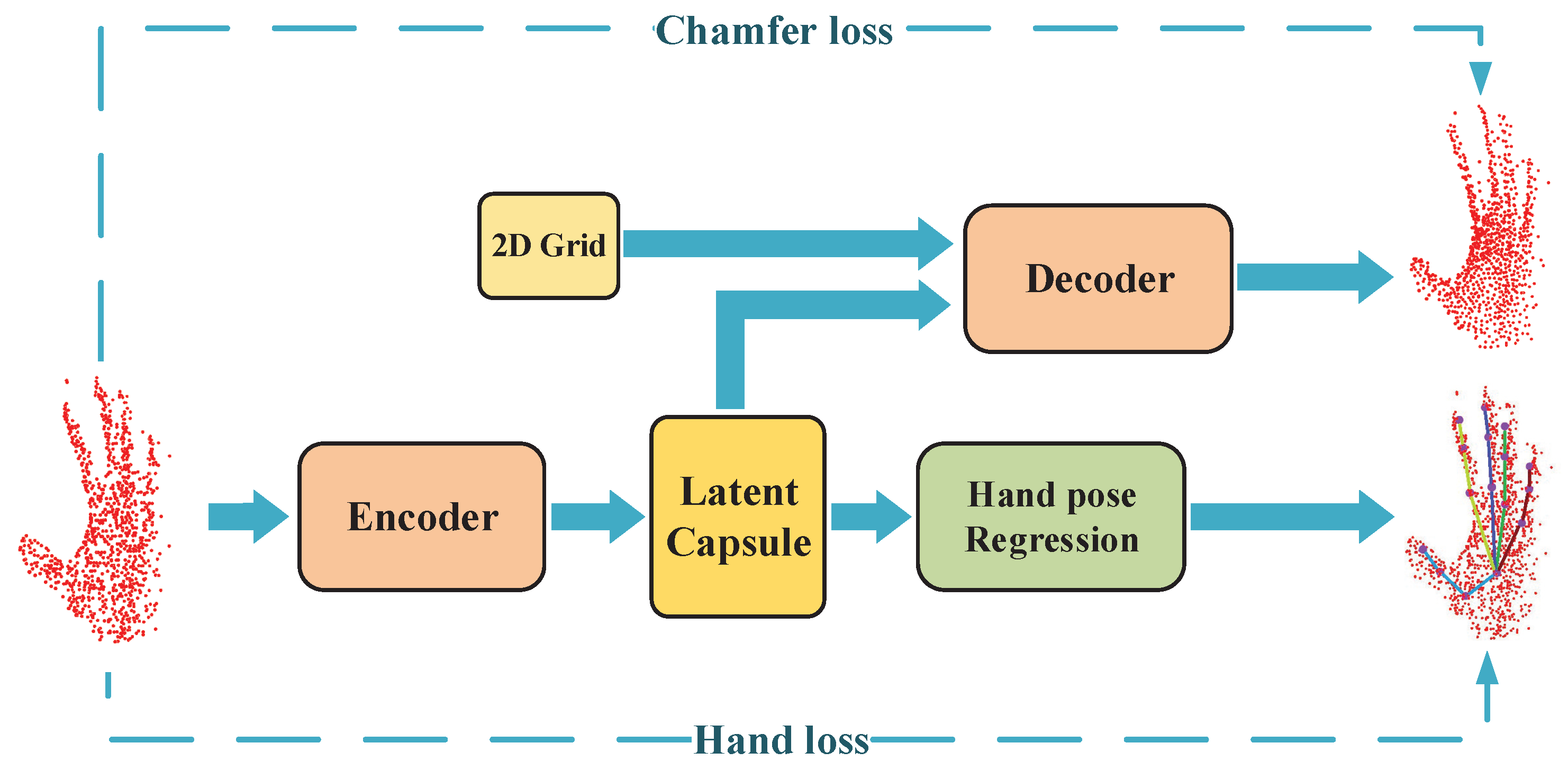
:1. Introduction
- (1)
- A capsule and dynamic routing based mechanism is first employed for hand pose estimation, which enable the network to learn the structural relationships among the local parts of the hand point cloud.
- (2)
- The hand feature is embedded into a lower-dimensional latent capsule, from which superior results can be obtained by a simple regressor.
- (3)
- An auto-encoder with a symmetric Chamfer distance metric is designed for hand feature optimization to acquire an effective latent capsule.
- (4)
- An end-to-end network is adopted to avoid extra transformation and a complicated intermediate modeling process for the hand point cloud, which reduces unnecessary 3D information loss and workload.
2. Related Work
2.1. Deeping Learning on Point Cloud
2.2. Hand Pose Estimation
3. Methodology
3.1. Hand Point Cloud Preprocessing
3.2. Capsule and Dynamic Routing
3.3. Hand Pose Estimation Network
4. Experiments
4.1. Datasets and Settings
4.2. Comparisons with State-of-the-Art Methods
4.3. Ablation Study
4.4. Runtime and Model Size
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Deng, Y.; Gao, F.; Chen, H. Angle Estimation for Knee Joint Movement Based on PCA-RELM Algorithm. Symmetry 2020, 12, 130. [Google Scholar] [CrossRef] [Green Version]
- Tang, D.; Jin Chang, H.; Tejani, A.; Kim, T.K. Latent regression forest: Structured estimation of 3d articulated hand posture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3786–3793. [Google Scholar]
- Sun, X.; Wei, Y.; Liang, S.; Tang, X.; Sun, J. Cascaded hand pose regression. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 824–832. [Google Scholar]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-time continuous pose recovery of human hands using convolutional networks. ACM Trans. Graph. (ToG) 2014, 33, 169. [Google Scholar] [CrossRef]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Robust 3d hand pose estimation in single depth images: From single-view cnn to multi-view cnns. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3593–3601. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. 3d convolutional neural networks for efficient and robust hand pose estimation from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1991–2000. [Google Scholar]
- Ge, L.; Cai, Y.; Weng, J.; Yuan, J. Hand pointnet: 3d hand pose estimation using point sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8417–8426. [Google Scholar]
- Chen, Y.; Tu, Z.; Ge, L.; Zhang, D.; Chen, R.; Yuan, J. So-handnet: Self-organizing network for 3d hand pose estimation with semi-supervised learning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6961–6970. [Google Scholar]
- Moon, G.; Yong Chang, J.; Mu Lee, K. V2v-posenet: Voxel-to-voxel prediction network for accurate 3d hand and human pose estimation from a single depth map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5079–5088. [Google Scholar]
- Chen, X.; Wang, G.; Zhang, C.; Kim, T.K.; Ji, X. Shpr-net: Deep semantic hand pose regression from point clouds. IEEE Access 2018, 6, 43425–43439. [Google Scholar] [CrossRef]
- Oberweger, M.; Lepetit, V. Deepprior++: Improving fast and accurate 3d hand pose estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 585–594. [Google Scholar]
- Chen, X.; Wang, G.; Guo, H.; Zhang, C. Pose guided structured region ensemble network for cascaded hand pose estimation. Neurocomputing 2020, 395, 138–149. [Google Scholar] [CrossRef] [Green Version]
- Poier, G.; Schinagl, D.; Bischof, H. Learning pose specific representations by predicting different views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 60–69. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Advances in Neural Information Processing Systems; 2017; pp. 3856–3866. Available online: http://papers.nips.cc/paper/6975-dynamic-routing-between-capsules (accessed on 2 October 2020).
- Zhao, Y.; Birdal, T.; Deng, H.; Tombari, F. 3D point capsule networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1009–1018. [Google Scholar]
- Zhang, D.; He, F.; Tu, Z.; Zou, L.; Chen, Y. Pointwise geometric and semantic learning network on 3D point clouds. Integr. Comput. Aided Eng. 2020, 27, 57–75. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- He, X.; Zhou, Y.; Zhou, Z.; Bai, S.; Bai, X. Triplet-center loss for multi-view 3d object retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1945–1954. [Google Scholar]
- Yu, T.; Meng, J.; Yuan, J. Multi-view harmonized bilinear network for 3d object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 186–194. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Prokudin, S.; Lassner, C.; Romero, J. Efficient learning on point clouds with basis point sets. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; 2017; pp. 5099–5108. Available online: http://papers.nips.cc/paper/7095-pointnet-deep-hierarchical-feature-learning-on-point-se (accessed on 2 October 2020).
- Liu, Y.; Fan, B.; Meng, G.; Lu, J.; Xiang, S.; Pan, C. Densepoint: Learning densely contextual representation for efficient point cloud processing. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 5239–5248. [Google Scholar]
- Liu, Y.; Fan, B.; Xiang, S.; Pan, C. Relation-shape convolutional neural network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 8895–8904. [Google Scholar]
- Li, J.; Chen, B.M.; Hee Lee, G. So-net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6411–6420. [Google Scholar]
- Mao, J.; Wang, X.; Li, H. Interpolated convolutional networks for 3d point cloud understanding. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1578–1587. [Google Scholar]
- Wang, W.; Yu, R.; Huang, Q.; Neumann, U. Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2569–2578. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. In Advances in Neural Information Processing Systems; 2018; pp. 820–830. Available online: http://papers.nips.cc/paper/7362-pointcnn-convolution-on-x-transformed-points (accessed on 2 October 2020).
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef] [Green Version]
- Keselman, L.; Iselin Woodfill, J.; Grunnet-Jepsen, A.; Bhowmik, A. Intel realsense stereoscopic depth cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar]
- Romero, J.; Tzionas, D.; Black, M.J. Embodied hands: Modeling and capturing hands and bodies together. ACM Trans. Graph. (ToG) 2017, 36, 245. [Google Scholar] [CrossRef] [Green Version]
- Tkach, A.; Tagliasacchi, A.; Remelli, E.; Pauly, M.; Fitzgibbon, A. Online generative model personalization for hand tracking. ACM Trans. Graph. (ToG) 2017, 36, 243. [Google Scholar] [CrossRef]
- Khamis, S.; Taylor, J.; Shotton, J.; Keskin, C.; Izadi, S.; Fitzgibbon, A. Learning an efficient model of hand shape variation from depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2540–2548. [Google Scholar]
- Remelli, E.; Tkach, A.; Tagliasacchi, A.; Pauly, M. Low-dimensionality calibration through local anisotropic scaling for robust hand model personalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2535–2543. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands deep in deep learning for hand pose estimation. arXiv 2015, arXiv:1502.06807. [Google Scholar]
- Deng, X.; Yang, S.; Zhang, Y.; Tan, P.; Chang, L.; Wang, H. Hand3d: Hand pose estimation using 3d neural network. arXiv 2017, arXiv:1704.02224. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Training a feedback loop for hand pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3316–3324. [Google Scholar]
- Sharp, T.; Keskin, C.; Robertson, D.; Taylor, J.; Shotton, J.; Kim, D.; Rhemann, C.; Leichter, I.; Vinnikov, A.; Wei, Y.; et al. Accurate, robust, and flexible real-time hand tracking. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 3633–3642. [Google Scholar]
- Ye, Q.; Yuan, S.; Kim, T.K. Spatial attention deep net with partial pso for hierarchical hybrid hand pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 346–361. [Google Scholar]
- Zhou, X.; Wan, Q.; Zhang, W.; Xue, X.; Wei, Y. Model-based deep hand pose estimation. arXiv 2016, arXiv:1606.06854. [Google Scholar]
- Choi, C.; Kim, S.; Ramani, K. Learning hand articulations by hallucinating heat distribution. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3104–3113. [Google Scholar]
- Zhang, D.; Zhang, Z.; Zou, L.; Xie, Z.; He, F.; Wu, Y.; Tu, Z. Part-based visual tracking with spatially regularized correlation filters. Vis. Comput. 2020, 36, 509–527. [Google Scholar] [CrossRef]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 206–215. [Google Scholar]
- Zhang, D.; He, F.; Han, S.; Zou, L.; Wu, Y.; Chen, Y. An efficient approach to directly compute the exact Hausdorff distance for 3D point sets. Integr. Comput. Aided Eng. 2017, 24, 261–277. [Google Scholar] [CrossRef] [Green Version]
- Wan, C.; Probst, T.; Van Gool, L.; Yao, A. Crossing nets: Combining gans and vaes with a shared latent space for hand pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 680–689. [Google Scholar]
- Zhou, Y.; Lu, J.; Du, K.; Lin, X.; Sun, Y.; Ma, X. Hbe: Hand branch ensemble network for real-time 3d hand pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 501–516. [Google Scholar]
- Wan, C.; Yao, A.; Van Gool, L. Hand pose estimation from local surface normals. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 554–569. [Google Scholar]
- Guo, H.; Wang, G.; Chen, X.; Zhang, C.; Qiao, F.; Yang, H. Region ensemble network: Improving convolutional network for hand pose estimation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4512–4516. [Google Scholar]
- Pan, Y.; He, F.; Yu, H. A novel enhanced collaborative autoencoder with knowledge distillation for top-N recommender systems. Neurocomputing 2019, 332, 137–148. [Google Scholar] [CrossRef]
- Zhang, D.; Luo, M.; He, F. Reconstructed similarity for faster GANs-based word translation to mitigate hubness. Neurocomputing 2019, 362, 83–93. [Google Scholar] [CrossRef]
- Sun, J.; Wang, M.; Zhao, X.; Zhang, D. Multi-View Pose Generator Based on Deep Learning for Monocular 3D Human Pose Estimation. Symmetry 2020, 12, 1116. [Google Scholar] [CrossRef]
- Guo, M.; Zhang, D.; Sun, J.; Wu, Y. Symmetry Encoder-Decoder Network with Attention Mechanism for Fast Video Object Segmentation. Symmetry 2019, 11, 1006. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; He, L.; Tu, Z.; Han, F.; Zhang, S.; Yang, B. Learning motion representation for real-time spatio-temporal action localization. Pattern Recognit. 2020, 103, 107312. [Google Scholar] [CrossRef]
- Liang, Y.; He, F.; Zeng, X. 3D mesh simplification with feature preservation based on Whale Optimization Algorithm and Differential Evolution. Integr. Comput. Aided Eng. 2020, 1–19, Preprint. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Mean Joint Error (mm) |
|---|---|
| Hierarchical [4] | 15.2 |
| Multi-view CNNs [6] | 13.1 |
| Crossing Nets [50] | 12.2 |
| 3D CNN [7] | 9.6 |
| DeepPrior++ [12] | 9.5 |
| Capsule-HandNet (Ours) | 8.85 |
| V2V [10] | 6.3 |
| Method | Mean Joint Error (mm) |
|---|---|
| LRF [3] | 12.6 |
| DeepModel [45] | 11.6 |
| DeepPrior [40] | 10.4 |
| Crossing Nets [50] | 10.2 |
| Hierarchical [4] | 9.9 |
| LSN [52] | 8.2 |
| DeepPrior++ [12] | 8.1 |
| So-HandNet [9] | 7.7 |
| REN [53] | 7.6 |
| Capsule-HandNet (Ours) | 7.49 |
| Method | Component | MSRA | ICVL | |
|---|---|---|---|---|
| Feature Combined | Dynamic Routing | |||
| (a) | 13.50 (mm) | 9.85 (mm) | ||
| (b) | ✔ | 10.37 (mm) | 8.42 (mm) | |
| (c) | ✔ | 13.12 (mm) | 9.78 (mm) | |
| (d) | ✔ | ✔ | 8.85 (mm) | 7.49 (mm) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Ma, S.; Zhang, D.; Sun, J. 3D Capsule Hand Pose Estimation Network Based on Structural Relationship Information. Symmetry 2020, 12, 1636. https://doi.org/10.3390/sym12101636
Wu Y, Ma S, Zhang D, Sun J. 3D Capsule Hand Pose Estimation Network Based on Structural Relationship Information. Symmetry. 2020; 12(10):1636. https://doi.org/10.3390/sym12101636
Chicago/Turabian StyleWu, Yiqi, Shichao Ma, Dejun Zhang, and Jun Sun. 2020. "3D Capsule Hand Pose Estimation Network Based on Structural Relationship Information" Symmetry 12, no. 10: 1636. https://doi.org/10.3390/sym12101636