1. Introduction
With the rapid development of the Internet of Things (IoT) technology, many IoT devices have emerged, and various IoT applications such as environmental monitoring, precise agriculture, smart health care, smart families, and intelligent manufacturing have been developed. With the incorporation of big data technology and IoT applications, increasing numbers of sensors are being deployed, and the amount of data that is transmitted is increasing. Designing a system to effectively support IoT applications face lots of challenges.
For IoT applications that deploy a large number of sensors to monitor changes in environmental parameters, the sensor data are characterized in terms of the periodic and continuous generation and the large amount of data transmitted. For example, as air pollution is becoming severe, a large number of sensors have been deployed to monitor air quality. These sensors detect the value of PM2.5 for each area over a long time and periodically transmit the sensor data to the server for storage. In order to obtain more accurate values, more and more sensors are deployed, so the amount of data generated and transmitted is getting higher. Since the sensing period is short, data are generated faster, and more storage space is required over time.
On the other hand, service providers usually allow users to observe real-time changes in air quality using a Web browser. To process the growing number of sensors and their generated sensor data and provide stable Web services simultaneously, the system requires more servers to receive and process sensor data. The system must also have a fault tolerance mechanism to ensure that data are not lost and the system is highly available.
To address growing service demands, most enterprises base on the concept of symmetry of architecture and quantities in system design and use server cluster technology to construct their systems. Traditionally, server clusters use multiple physical servers to provide services and employ effective load-balancing mechanisms to distribute the load over servers. Servers can be added into or remove from the cluster on demand. This allows a high degree of scalability, excellent reliability, and high efficiency. With the maturity of computer hardware and virtualization technology, administrators can maintain and deploy systems more conveniently and efficiently [
1,
2]. Hence, enterprises and organizations use virtualization technology to deploy their systems. Physical server clusters are thus transformed into virtualized server clusters. Besides, virtual machines (VMs) on a physical server are independent, so administrators can construct VMs that provide a variety of services on a server to meet the diverse service needs of users and make full use of system resources.
Tenants can construct individual server clusters or rent VMs from cloud providers, such as Google Cloud Platform (GCP) [
3], Amazon Web Services (AWS) [
4] and Microsoft Azure [
5], in line with their demand for computing resources. In order to increase the reliability and performance of services, a group of VMs can be created, and load-balancing services implemented by providers are used to distribute the workload between physical server groups.
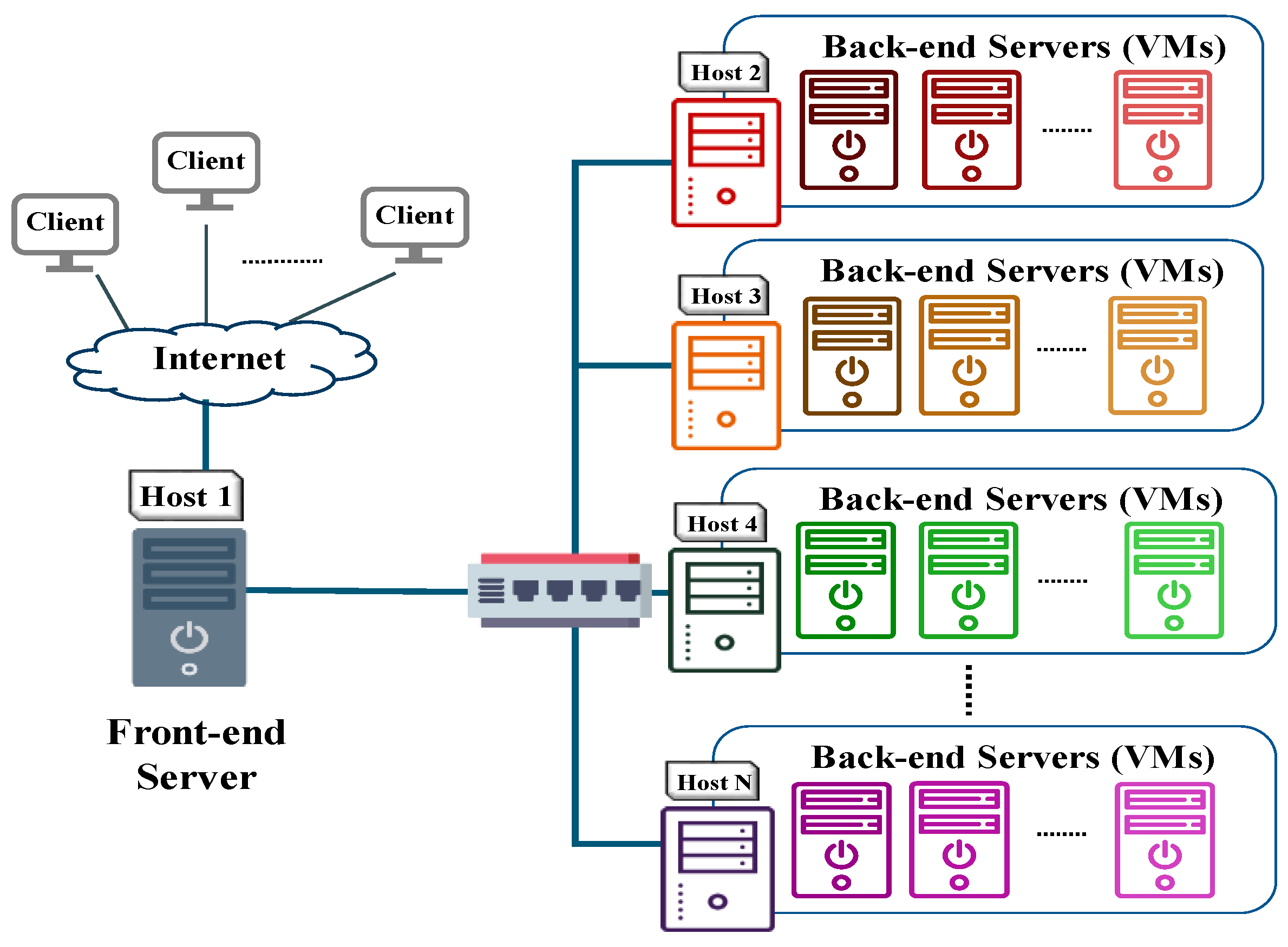
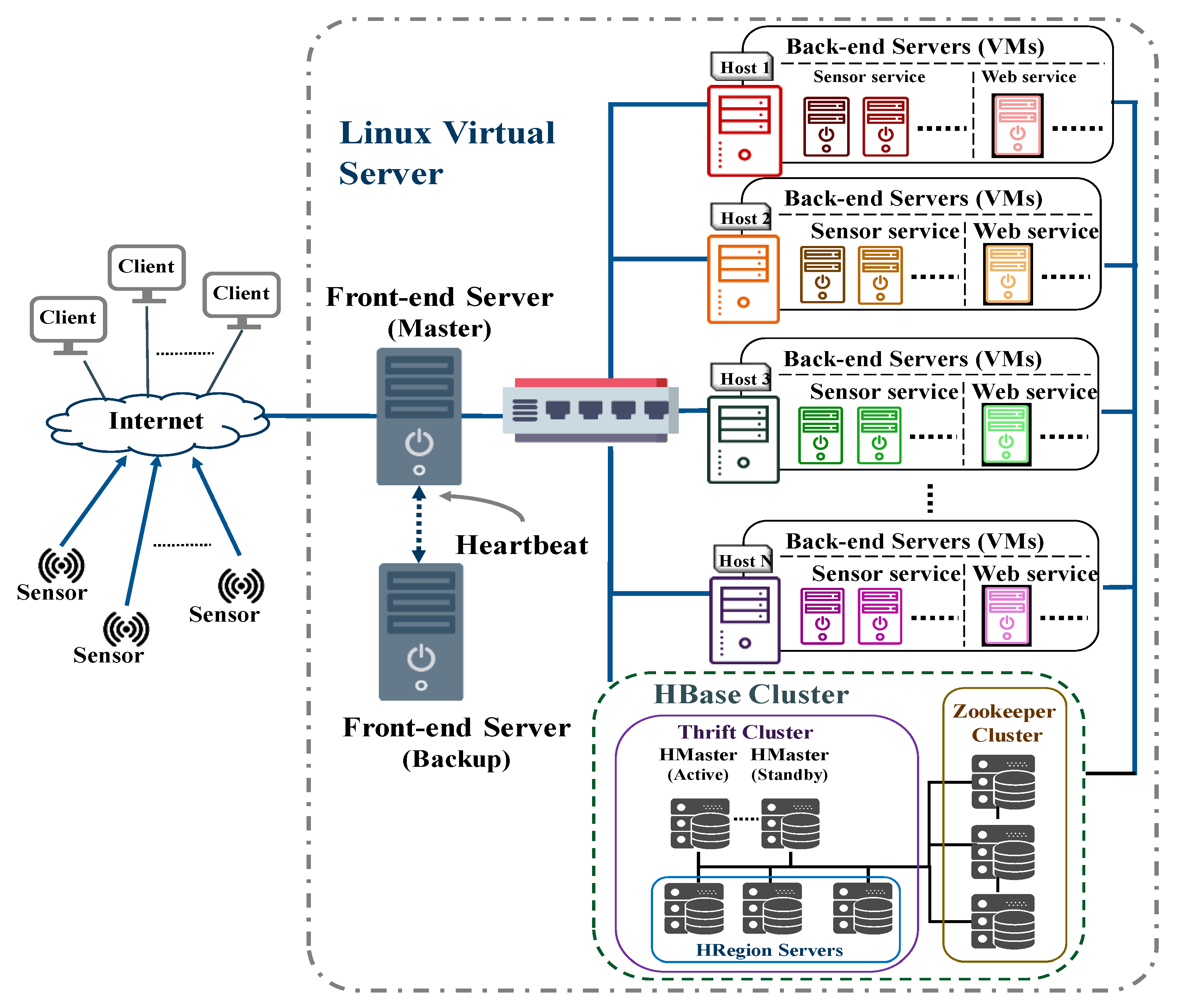
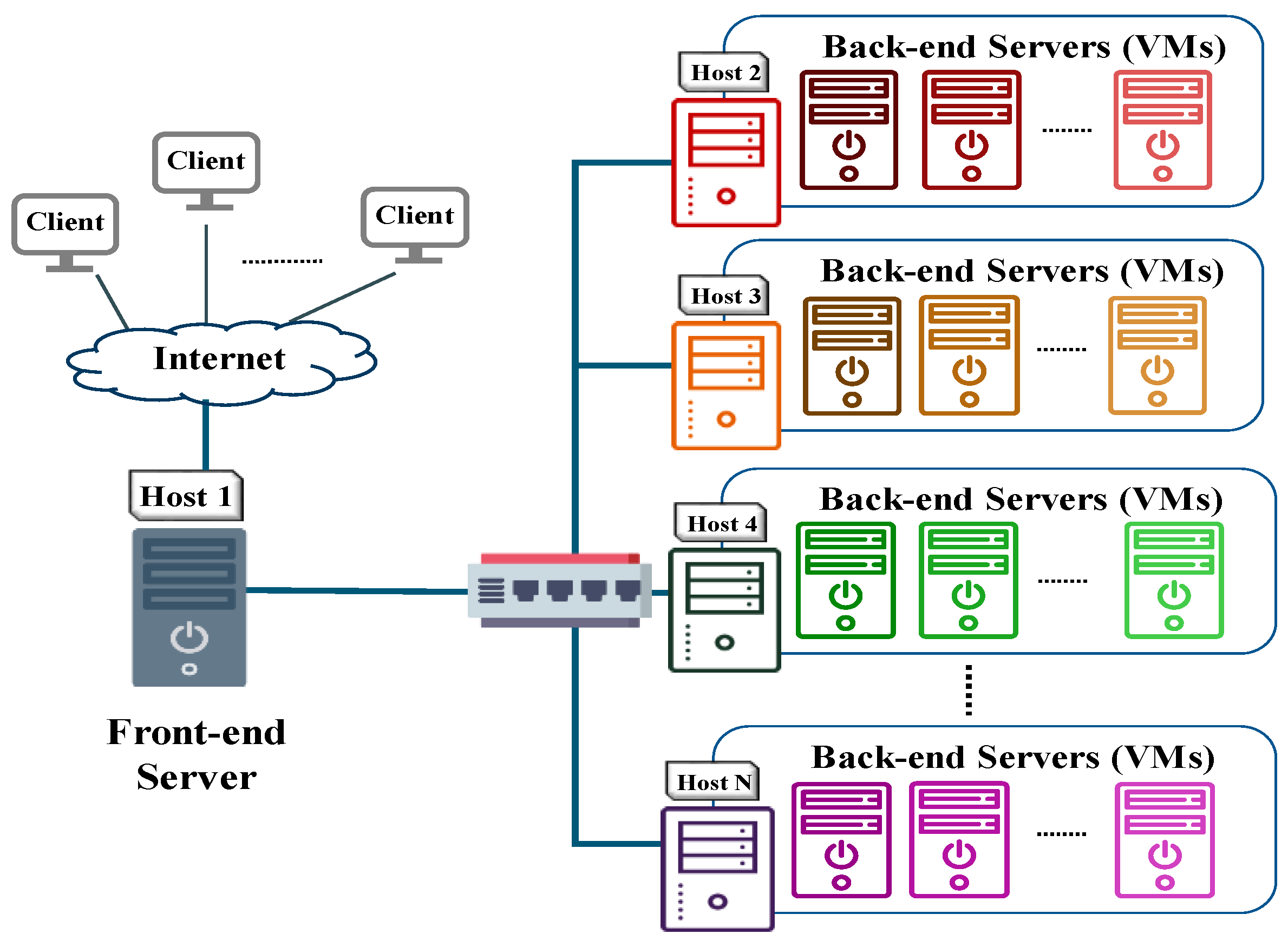
To avoid the constraints of cloud providers and reduce security concerns about data leakage, this study designs and implements a server cluster for IoT applications. To efficiently meet the ever-increasing service demands, the system architecture should allow a high degree of scalability, high performance, and high availability for providing IoT-generated data repositories and Web services. This study describes our experience in adopting the open-source software to develop our server cluster system. The Linux Virtual Server (LVS) [
6,
7] and the Kernel-based Virtual Machine (KVM) [
8] technologies are used to deploy a VM cluster named VM-based Cluster Providing Hybrid Service (VMC/H). LVS and KVM technologies are adopted since they are directly supported in the Linux kernel. Being operated at the kernel layer, they are shown to have excellent performance in the related studies [
1,
2,
7]. It consists of a front-end server, also called a load balancer for dispatching requests, and several back-end servers to provide services. On each host of the VMC/H cluster, several VMs are constructed as back-end servers to provide sensor services and provide Web services to users that allow sensor data to be browsed. In order to achieve high availability, a standby front-end server is additionally set up and serves as a backup. If the primary front-end server fails, the backup server continues to provide system service. Besides, the Hadoop Distributed File System (HDFS) [
9] and distributed NoSQL database HBase [
10] are used to establish a storage cluster to process and store a large amount of sensor data, which mainly takes advantage of their features of high performance and high availability.
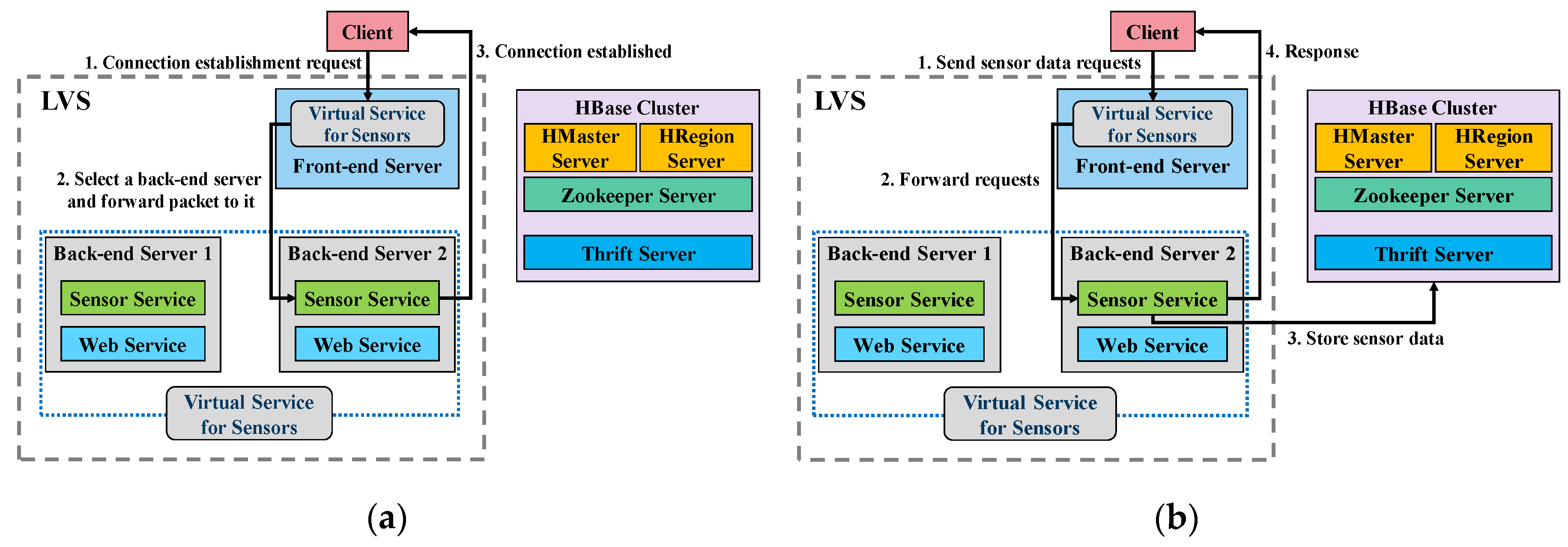
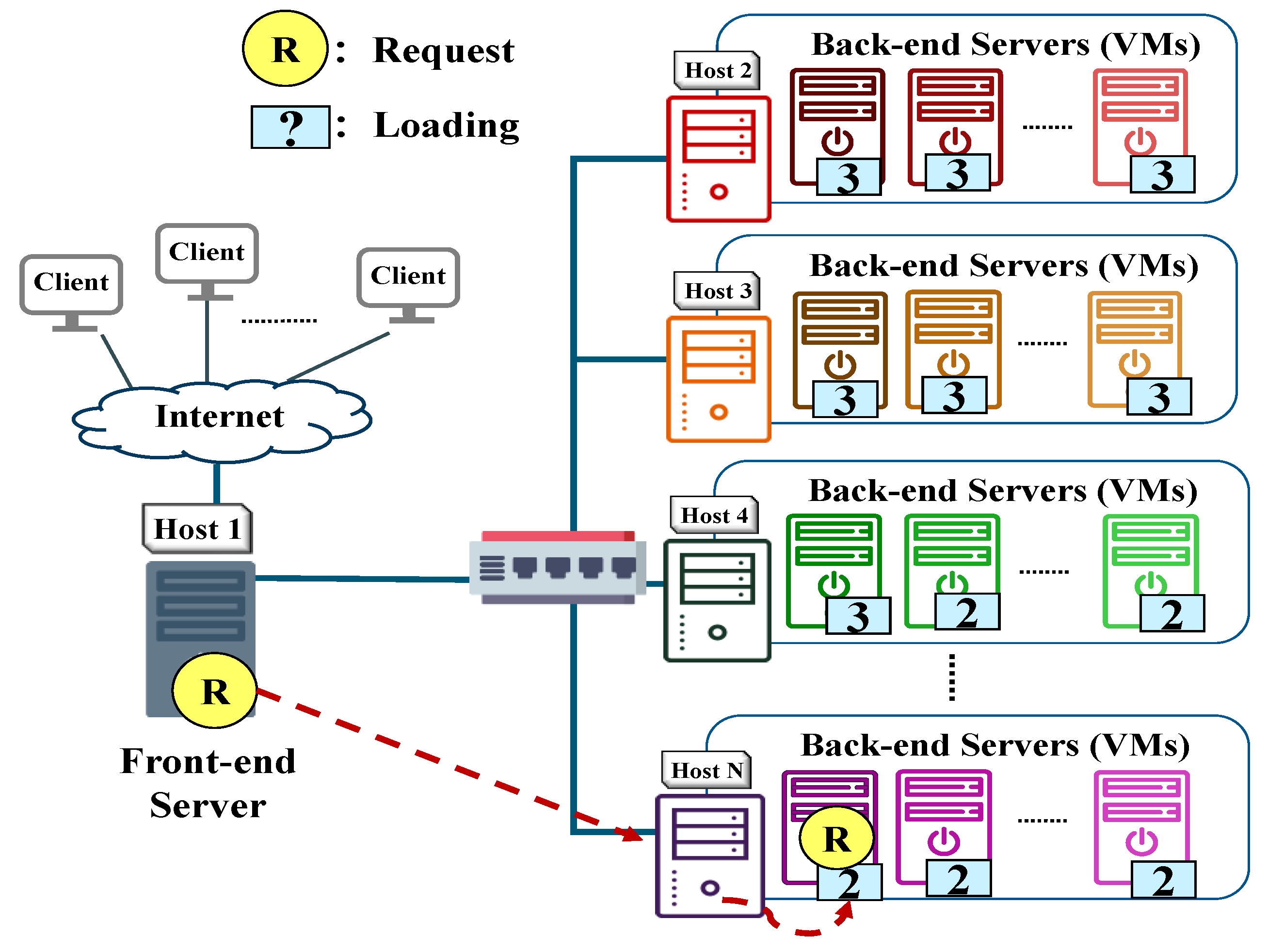
Though several open-source software is integrated and used to construct a server cluster system, nevertheless, to meet the high-performance needs, the load-balancing issue should be addressed for the VM-based server cluster because it significantly affects the use of system resources. Current load distribution algorithms provided in the LVS cluster, such as Weighted Round-Robin (WRR) [
7] and Weighted Least Connection (WLC) [
7], are not appropriate to be used for virtual server clusters that provide different types of services on the same physical server group. Two factors must be taken into account. The first one is the difference between physical machines and VMs. The other one is the aggregate loads of different services provided by the server clusters. Otherwise, even VMs are load-balanced, physical machines may not be.
In this study, we further explore efficient load distribution strategies for VM-based server clusters. These virtual server clusters are constructed on the same physical server group but provide different types of services. We have designed and implemented a new load distribution strategy called VM-based Weighted Least Connections for Hybrid Service (VMWLC/H). It not only considers the difference between physical and virtual machines but also the aggregate load of different services provided by the server clusters to prevent a load imbalance between physical servers.
We further perform experiments to explore the difference between the overall system performance for the proposed VMC/H using multiple lower-cost physical servers and a single physical server with higher capability. The experimental results show that these VMC/H clusters with the VMWLC/H load distribution strategy provide scalable and reliable data storage and efficiently provide sensor services and Web browsing services simultaneously. The VMC/H system constructed using multiple physical servers performs better than the VMC/H system constructed using a single powerful physical server. Besides, the proposed VMWLC/H helps balance the load over servers and increase performance.
The contribution of this work is as follows. First, to efficiently support IoT applications that provide hybrid services such as web service and sensor data storage, we have utilized several open-source software to construct our VM cluster. We have further improved them to achieve the VMC/H system’s key properties regarding scalability, fault tolerance, high performance, and virtualization. Second, we have designed and implemented a new load distribution strategy VMWLC/H for VM-based server clusters that provide hybrid services. It considers the difference between physical and virtual machines and the aggregate load of hybrid services on servers to prevent a load imbalance between physical servers. Besides, to demonstrate the effectiveness of the proposed VMC/H system for IoT applications and the VMWLC/H for load balancing, they are practically implemented and use air quality monitoring as an application.
The remainder of this paper is organized as follows.
Section 2 describes the technology background and related work.
Section 3 describes the design and implementation of the proposed system, including the proposed VMC/H virtual server cluster and the proposed load-balancing algorithm, to provide hybrid services in the same virtual server cluster.
Section 4 describes the experimental environment and presents experimental results. Finally,
Section 5 concludes.
4. Performance Evaluation
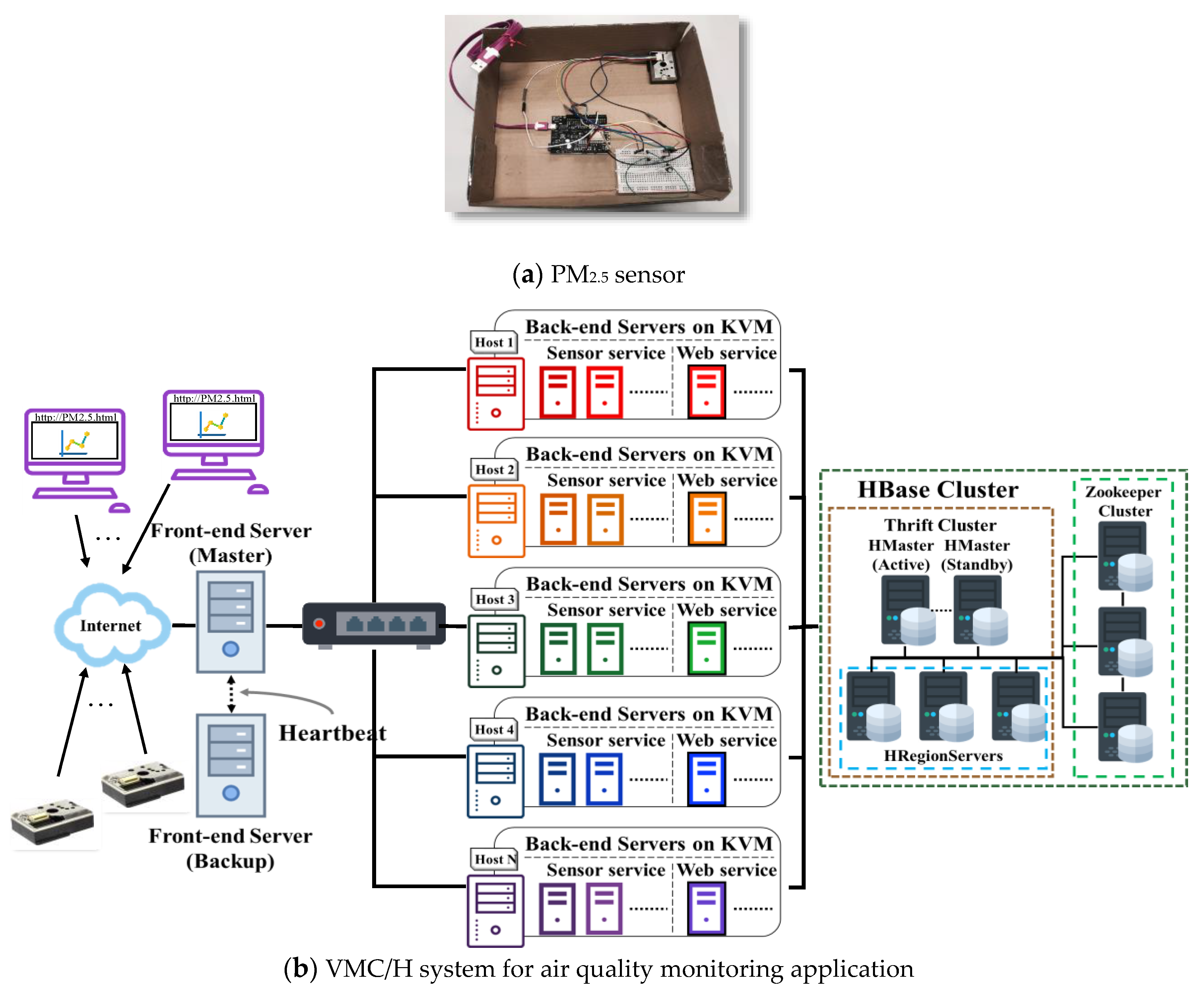
To demonstrate the effectiveness of the proposed VMC/H system for IoT applications and the VMWLC/H for load balancing, they are practically implemented and use the air quality monitoring as an application in the experiment, as shown in
Figure 12. Two services are provided, including sensor service to collect and store sensor data and Web service for browsing stored sensor data. A set of PM
2.5 sensors with wireless network connection was constructed for testing. A GP2Y1014AU0F dust sensor [
27] with a WeMos D1 R2 development board [
28] was used to build a PM
2.5 sensor, as shown in
Figure 12a. Sensor programs were then developed, in which the sensor sends detected data periodically to the sensor service server in VMC/H. When the data are sent, the state of the connection with the sensor service server is confirmed. If the connection is lost, it is re-established, and the system then continues to detect and send sensor data.
To evaluate the performance, the VMC/H system was implemented with various load-balancing strategies, such as WLC, VMWLC, and VMWLC/H. Two groups of LVS virtual services are implemented in the VMC/H system. As presented in
Section 3.1, one provides sensor services, and the other provides Web services for browsing stored sensor data. We further construct two virtual server clusters that are similar in cost and system performance. This performance evaluation serves as a reference for developers when developing their systems.
Section 4.1 describes the experimental environment, and
Section 4.2 describes the experimental settings. The time that is required to perform failover is measured and presented in
Section 4.3.
Section 4.4,
Section 4.5 and
Section 4.6 show the performance evaluation of VMC/H systems that provide sensor services, Web services, and hybrid services.
4.1. Experimental Environment
Figure 13 shows the experimental environment. Two sets of hardware devices with similar cost and system performance were used to construct VMC/H systems. LVS cluster A is constructed using multiple low-cost computers and is labeled VMC/H(M), as shown in
Figure 2. The other LVS cluster B uses a Dell R730 [
29] server with better performance and is labeled VMC/H(S), as shown in
Figure 6. Two computers with the same specification were used to construct the FEs to provide the fault tolerance feature. In LVS cluster A and LVS cluster B, 20 VMs are deployed as BEs. 15 VMs are configured to provide sensor services, and the other 5 VMs offer Web services. Five clients are used, and these run the benchmark software Siege [
30] to send Web requests to the VMC/H system. They also execute the sensor simulation program that we wrote to send sensor data to the VMC/H system. The software and hardware specifications are shown in
Table 1,
Table 2 and
Table 3.
When constructing the HBase cluster for data storage, we consider the efficiency of data access. 5 VMs were constructed on an ASUS TS500-E8-PS4 server [
31]. Two of these were constructed as HMaster servers, and the other three were constructed as Zookeeper servers. The HRegion servers are mainly responsible for data storage, so they are constructed on three physical servers, instead of VMs on one physical server, to increase the speed at which data are accessed.
The operating system is Ubuntu 16.04 server edition, and LVS clustering software is IPVS [
6]. We modify the core of the IPVS kernel module to implement the front-end server with VMWLC/H. Each VM is constructed using Kernel-based Virtual Machine (KVM) [
8] technology. The Hadoop [
9] and HBase [
10] are used to provide sensor data storage.
4.2. Experimental Settings
To evaluate the performance impact of different load distribution algorithms, four VMC/H systems implemented with different load distribution algorithms were measured. As shown in
Table 4, one executes WLC in VMC/H(S) systems constructed using a single physical server. VMWLC and VMWLC/H are not used because they target systems with multiple physical servers.
To evaluate the performance of VMC/H systems when providing different types of services, three different experimental workloads, including sensor requests only, Web requests only, and hybrid requests, are used in the experiments, as shown in
Table 5. To serve only a single type of service, VMC/H(M) systems constructed using multiple physical servers execute VMWLC [
2] or WLC [
7]. VMWLC/H is used only for the VMC/H(M) that provides hybrid services.
To perform a stress test for various sensor connections, a large number of PM
2.5 sensors must be deployed. We then use Java and HBase Client API to write a multi-threaded sensor program that simulates various sensors to send sensor data to the server for storage periodically. The sensor program and sensor data format refer to the air pollutant miniature sensor system [
32]. When the sensor data are received, the sensor service server stores it in the HBase cluster. The time between when all sensor service servers write the received sensor data to the HBase cluster and when all the sensor data are stored in it was recorded.
Table 6 shows the sensor data format stored in the HBase.
To avoid the server’s memory cache affecting the performance evaluation, all machines were restarted before each experiment was started. Each test was conducted five times, and the average value is used to calculate the performance.
4.3. Measurement of Failover Time
This experiment verifies the fault tolerance feature for the system. It tests whether the proposed VMC/H system allows the system to recover and continue to provide services when the FE fails. This experiment uses a test time of 60 s after the sensor is turned on. The master FE is turned off at the 30th second, and the sensor is turned off at the 60th second. During the test, the sensor data per second sent by the sensor was measured on the server-side. The experimental results are shown in
Figure 14. When the FE fails, the backup server recovers the system and continues to provide services in 13 s. This indicates that the backup FE successfully replaces the master, and the system successfully continues to provide services even if the master FE fails.
4.4. Performance Evaluation for VMC/H Systems Providing Sensor Services
This section presents the evaluation of performance and scalability for the VMC/H system that provides sensor services. The system performance under various amounts of sensor connections and the scalability under various amounts of VMs and physical servers are measured.
4.4.1. Performance Evaluation for Various Numbers of Sensor Connections
In this experiment, five clients are used to simulate 150, 250, 350, and 450 sensors that send sensor data at the same time. The test time is 5 min. During this time, sensors send data every 5 s; therefore, a total of 9000, 15,000, 21,000, and 27,000 sensor data are sent to the sensor service server.
The experimental results are shown in
Figure 15. The average data write latency for VMC/H(S) is 261.67 s, about twice as long as that for VMC/H(M). The load is too high for a single physical server, so the VM-based sensor servers running on it have significantly reduced performance. Among them, the VMC/H(M) system using VMWLC obtains the best performance. This shows that using multiple physical servers to provide services can achieve much better performance. Using VMWLC that differentiates physical servers from virtual servers helps maintain load balance between servers, which can further increase performance. However, as the number of sensors increases more than the VMC/H systems can offer, the time delay of writing data increases significantly. Since VMC/H(S) uses only a single server, it has an upper bound for the performance limit. In contrast, VMC/H(M) can further increase performance by adding more physical servers, as shown in the scalability test for various numbers of physical servers in
Section 4.4.3.
4.4.2. Scalability Test for Various Numbers of VMs
We have designed four test cases for the scalability test, as shown in
Table 7, to determine how many sensors this VMC/H system can support and the stability of the VMC/H system for different numbers of VMs. The delay time for the sensor data to be written to the HBase cluster was measured.
Figure 16 shows the experimental result for different numbers of VMs.
The result shows that a VM can support 15 sensors in test case 1 and without time delay of writing data. When the number of sensors increases to 75 and 5 VMs are deployed in test case 2, each sensor’s data can still be processed in real time. The VMC/H(S) system begins to experience a delay in writing data in test case 3, whereas the VMC/H(M) systems begins to experience a delay in writing data in test case 4. Their delay time is much shorter than that of the VMC/H(S).
As the number of sensors is increased, the load on VMC systems increases as well. Because only one physical server in the VMC/H(S) runs all VMs and the physical server is heavily loaded, so the entire system performance is reduced. In the VMC/H(M), since five physical servers share the load, so its performance is better than VMC/H(S) even under heavy load (i.e., test cases 3 and 4). Besides, all the data from each sensor is processed in real time in test cases 1–3.
Although increasing the number of VMs helps serve more amounts of sensors, the time delay of writing data increases as more amounts of sensors are deployed. When large amounts of sensors are deployed, adding more physical servers helps reduce the time delay, as shown in
Section 4.4.3, which transforms VMC/H(S) to VMC/H(M).
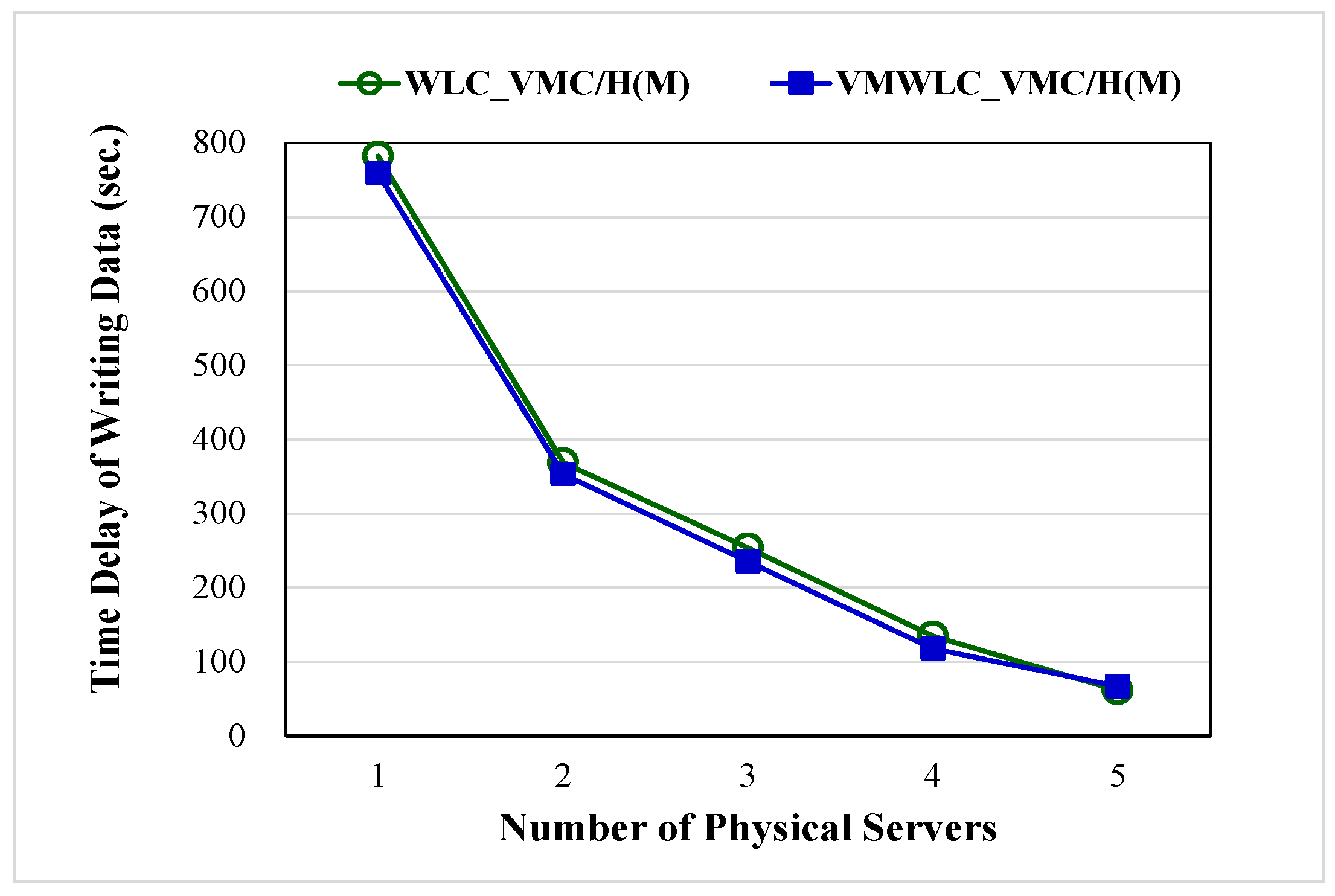
4.4.3. Scalability Test for Various Numbers of Physical Servers
A scalability test was performed for the VMC/H(M) system that is constructed using different numbers of physical servers to determine how the delay time in writing data changes with the number of physical servers. In this experiment, 3 VMs that provide sensor services were established on each physical server, and five clients were used to simulate 225 sensors to send sensor data to the server simultaneously. The test ran for 5 min. Sensor data were sent every 5 s, and a total of 13,500 sensor data were sent to the sensor service server.
Figure 17 shows the experimental results that no matter which load-balancing algorithm is used, VMC/H(M) reduces the latency for writing data by adding physical servers. Adding every additional physical server in the server cluster reduces the delay time for writing data by an average of 45.0–46.4%. These data serve as a reference for administrators to extrapolate the effect when expanding the system to serve more sensors.
4.5. Performance Evaluation for Providing Web Services
To test the website performance for servers, a dynamic Web page that accesses the latest sensor data every 5 s was established on servers. A total of 9000 pieces of data from 150 sensors were pre-created in the HBase cluster. When users query real-time sensor data using a Web browser, they query the latest sensor data of 150 sensors from the 9000 data and display them on the Web page. Five clients ran Siege [
30], which simulates a total of 500 users requesting the Web service. We test three scenarios: clients sent 5000, 7500, and 10,000 Web requests for the test. The throughput was measured.
Figure 18 shows that when clients send 10,000 requests, VMC/H(M) outperforms VMC/H(S) by 41.4–55.2% in terms of throughput. VMWLC performs 9.8% better than WLC. The performance data of VMC/H systems providing Web services is similar to that of VMC/H systems providing sensor services, as shown in
Section 4.4.1. VMC/H(S) is constructed using a single physical server. When too many requests are received, the physical server is overloaded, and the bandwidth of the network interface is limited, so the overall system performs poorly. VMC/H(M) using multiple physical servers to share the load and using VMWLC that balances the loads between physical servers and virtual servers has the best performance.
4.6. Performance Evaluation for VMC/H Systems Providing Hybrid Services
The proposed VMWLC/H algorithm is mainly designed for a virtual server cluster that provides hybrid services, such as the proposed VMC/H system that simultaneously provides sensor services and Web browsing services. In this experiment, five clients are used to simulate 225 sensors that send sensor data, and they run Siege [
30] that simulates a total of 5000 users requesting Web service at the same time. We tested three scenarios; the tests last for 5, 10, and 15 min. During these periods, sensors send data every 5 s, so a total of 13,500, 27,000, and 40,500 sensor data are sent to the sensor service server. The longer the test period, the more sensor data are received and stored in the HBase cluster, which affects the performance of querying sensor data through the Web browsing service.
The experimental results for VMC/H systems that use different load-balancing algorithms are shown in
Figure 19. Among them, VMC/H(M) with VMWLC/H has the best performance. For VMC/H(M) system, VMWLC/H performs 3.6–9.1% better than VMWLC and 8.2–26.3% better than WLC. Furthermore, the VMC/H(M) system that uses VMWLC/H performs 35.3–62.8% better than VMC/H(S) system that uses WLC.
These results show that VMC/H(M) is more effective than VMC/H(S) because constructing all the VMs on a single physical server in VMC/H(S) results in an excessive load on the overall system. The proposed VMWLC/H algorithm considers the aggregate loads of all BEs even though they provide different services on the same physical server. Therefore, loads can be distributed to physical servers in a more balanced way. Since the overall server load is more balanced, system performance is increased.
5. Conclusions
For IoT devices and applications such as air quality monitoring that send data periodically and continuously for a long period, the system should be highly scalable and highly available to meet the increasing service demands and process and store sensor data efficiently. To efficiently provide hybrid services such as storing and browsing sensor data, this study takes advantage of several open-source software to construct the proposed VMC/H system and describes our experience in utilizing them and improving them to achieve high scalability, high performance, and high availability. Virtualization technology is used to construct server clusters, which allows easier management and maintenance of server clusters, and server clusters have the advantages of high scalability, high reliability, and high efficiency.
The VMC/H system’s implementation uses LVS clustering technology, but traditional LVS load-balancing algorithms do not differentiate VMs from physical machines. They also do not consider the current loads of back-end servers that provide different services on the same physical servers, which can result in an uneven load on physical servers and a decrease in the overall system’s performance. Therefore, this study designs and implements a new load distribution algorithm for VM-based server clusters that provide multiple types of services. When the front-end server forwards requests for Web services, it considers the aggregate loads of all back-end servers on all physical servers, even if they provide different services, such as sensor services and Web services. Besides, it differentiates VMs from physical machines for balancing loads between physical servers.
To demonstrate the effectiveness of the proposed VMC/H system for IoT applications and the VMWLC/H for load balancing, they are practically implemented and use air quality monitoring as the experimental application. To meet the diverse needs of users, the VMC/H system is designed to offer sensor services for collecting and storing sensor data and Web service for accessing real-time sensor data at the same time. The experimental results show that VMWLC/H helps balance the load over servers and increase performance.
Nowadays, IoT applications are becoming more and more diverse; service providers deploy more and more sensors to obtain more accurate data. With VMWLC/H, adding additional physical servers into VMC/H system can effectively distribute the load over servers and improve system performance. Our VMC/H system with VMWLC/H can serve as a reference for developers when developing their systems for IoT applications.
Currently, the VMC/H system is constructed using LVS cluster technology, KVM virtualization technology, HDFS, and Hbase distributed non-relational database. Our future work will compare its performance with that of a VMC/H system using software-defined networking [
16,
17,
18] to design virtual server clusters. We will also study the use of other database technologies for sensor data storage, such as Cassandra [
33], to increase the performance of the overall system. Besides, deploying the VMC/H system in the practical fields and using real workloads for performance evaluation helps subsequent work in improving system performance.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}