Unpaired Image Denoising via Wasserstein GAN in Low-Dose CT Image with Multi-Perceptual Loss and Fidelity Loss


Abstract
:1. Introduction
- (1)
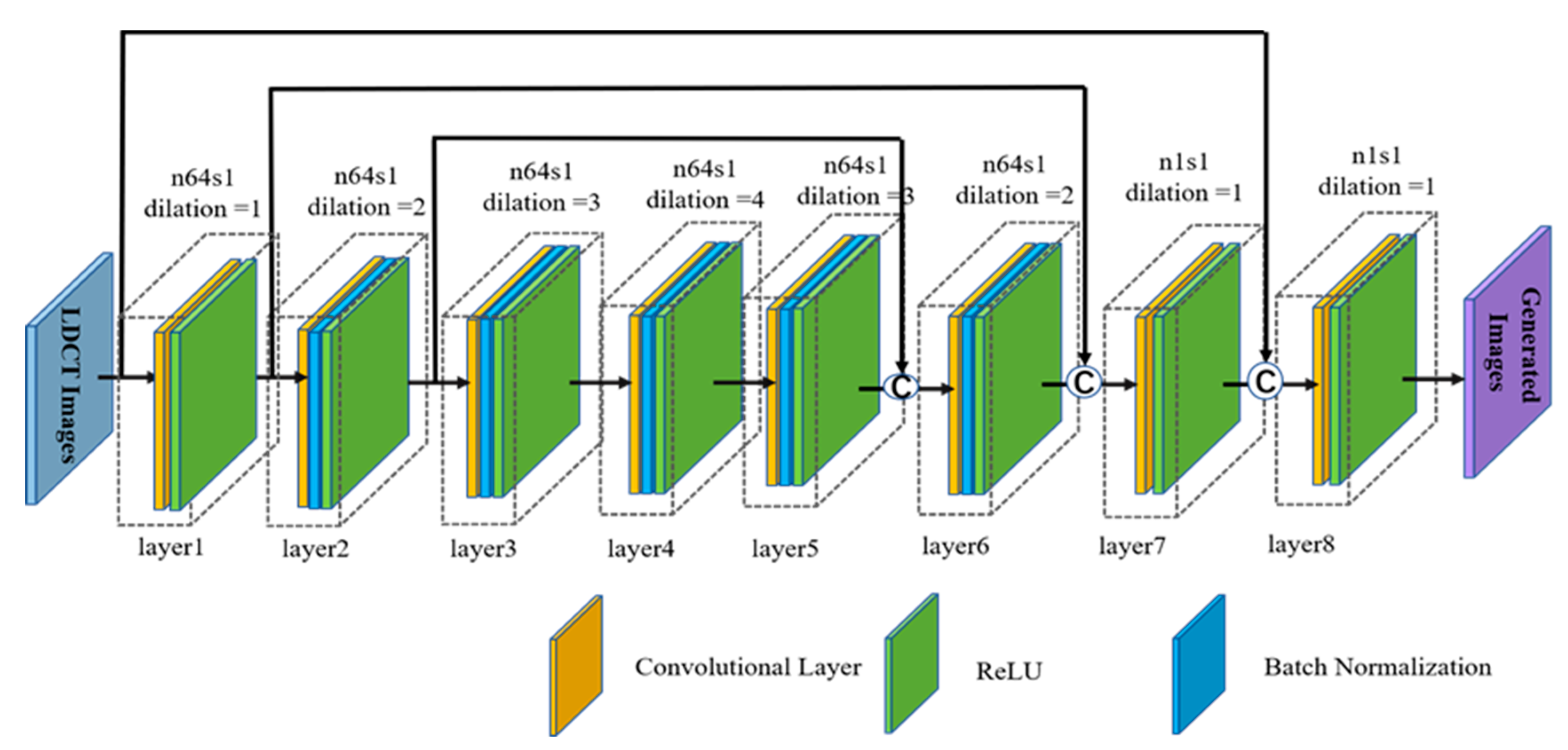
- The generator is improved by the introduction of a convolutional neural network (CNN) with eight convolutional layers which is embedded in the residual structure and utilizes dilated convolutions. This improvement can increase the receptive field of the generator and fully mine the image information.
- (2)
- For the purpose of applying the feature space distribution of the unmatched clean images to guide the LDCT image denoising task, multi-perceptual loss is adopted to measure the difference between LDCT and NDCT images in feature space.
- (3)
- Since we use unpaired images for network training, we introduce a fidelity loss, which uses L2 loss to calculate the difference between the generated image and the original image to ensure that the generated image is not distorted.
2. Methods
2.1. Wasserstein GAN
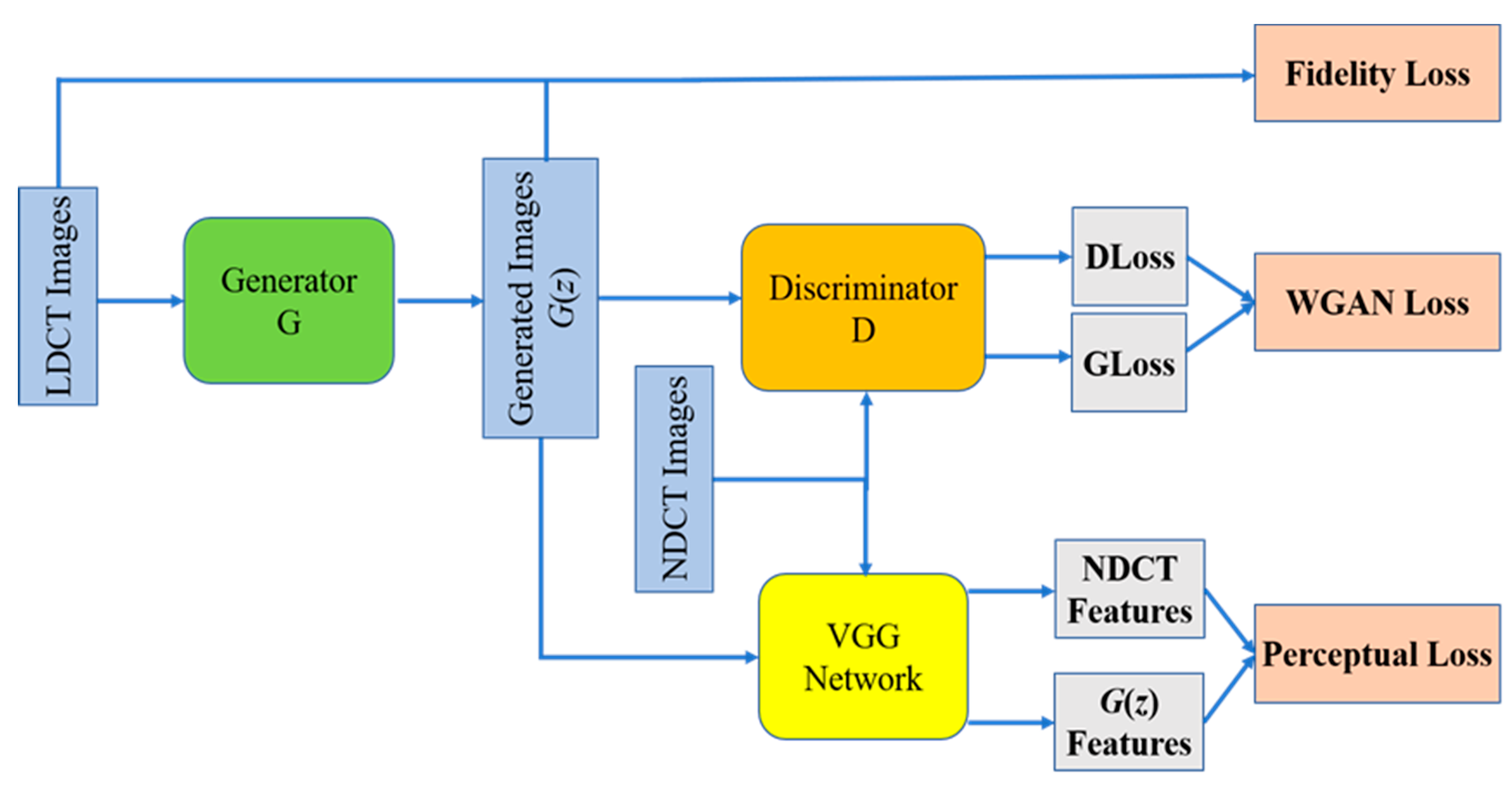
2.2. Composition of Loss Functions
2.2.1. Fidelity Loss
2.2.2. Multi-Perceptual Loss
2.2.3. Full Objective
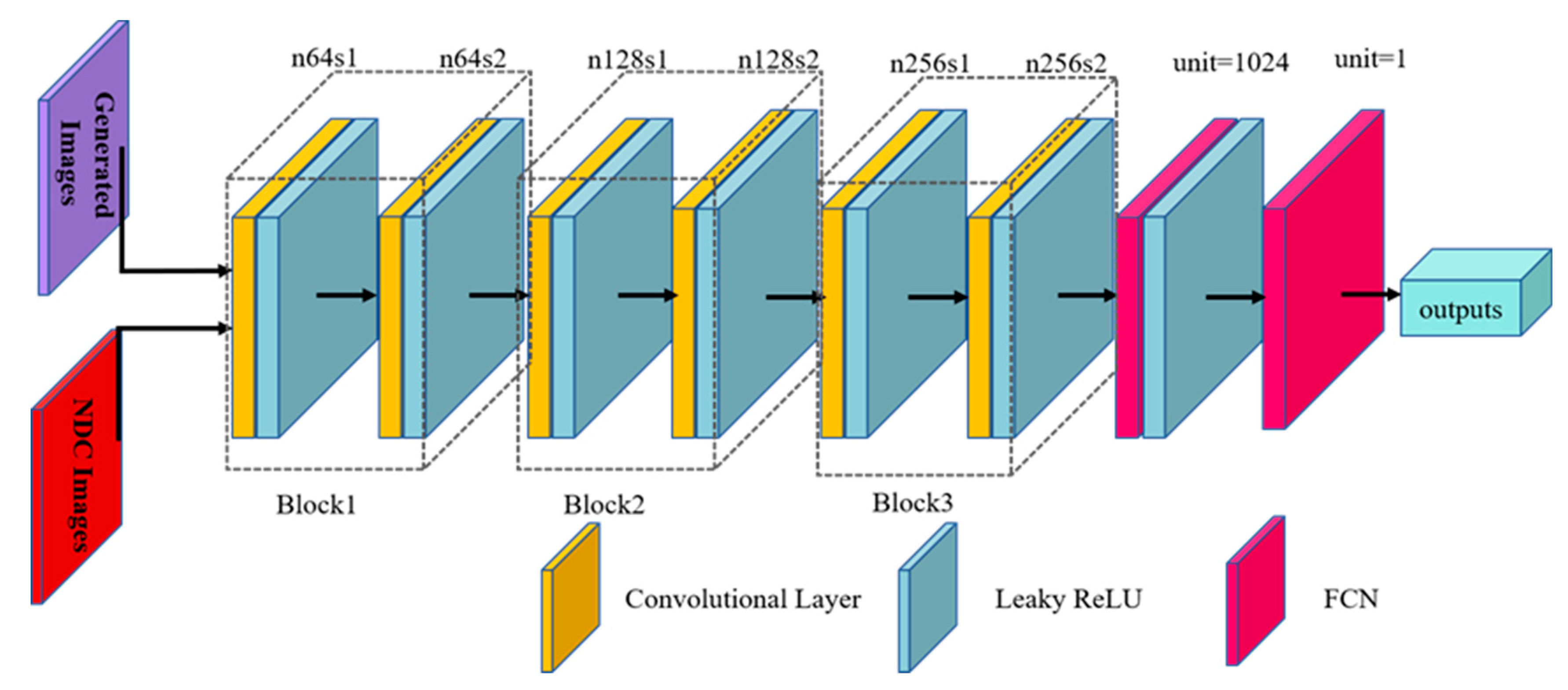
2.3. Network Structure
3. Experiments and Results
3.1. Experimental Datasets
3.2. Setting of the Parameters
3.3. Other Comparison Networks
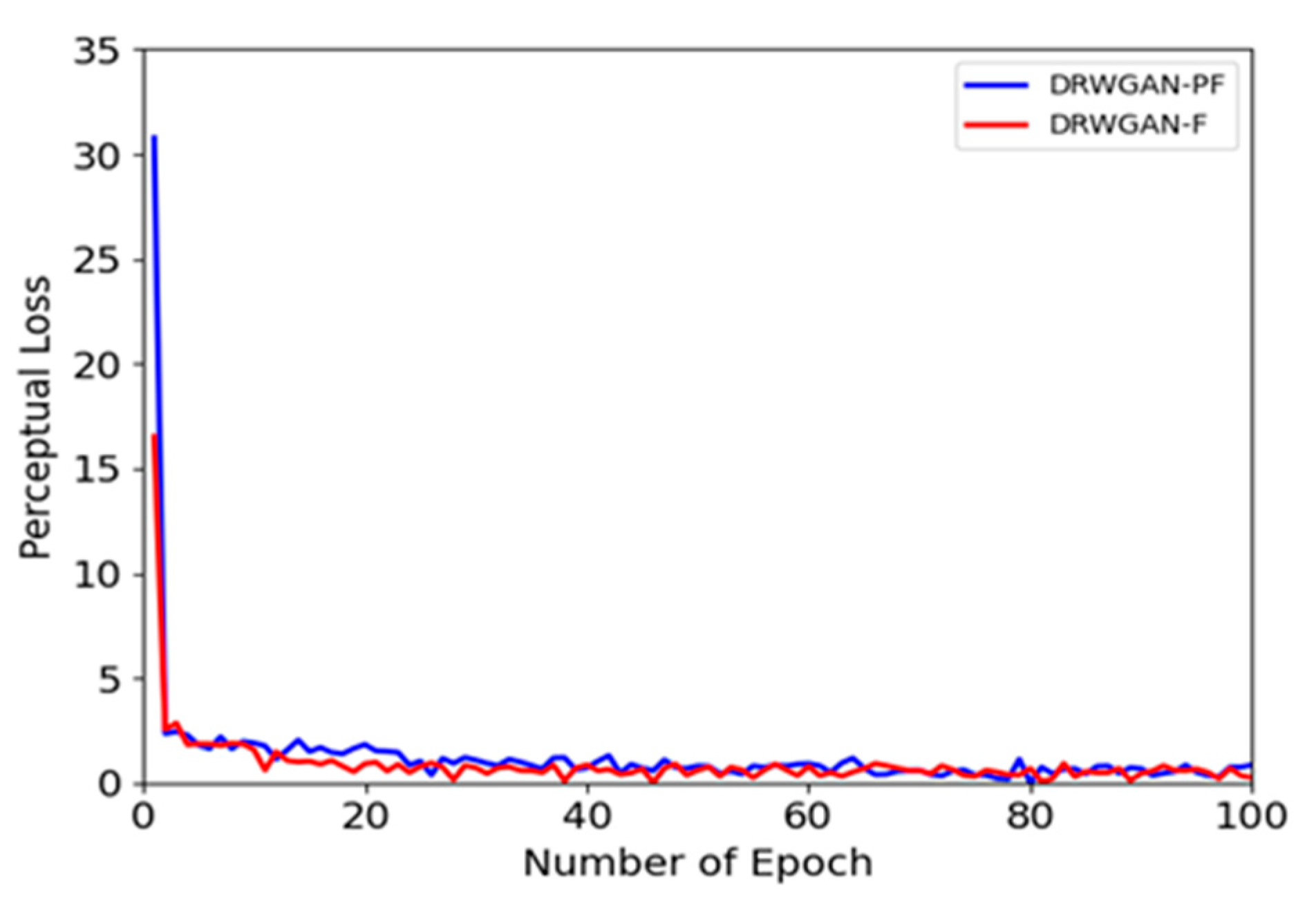
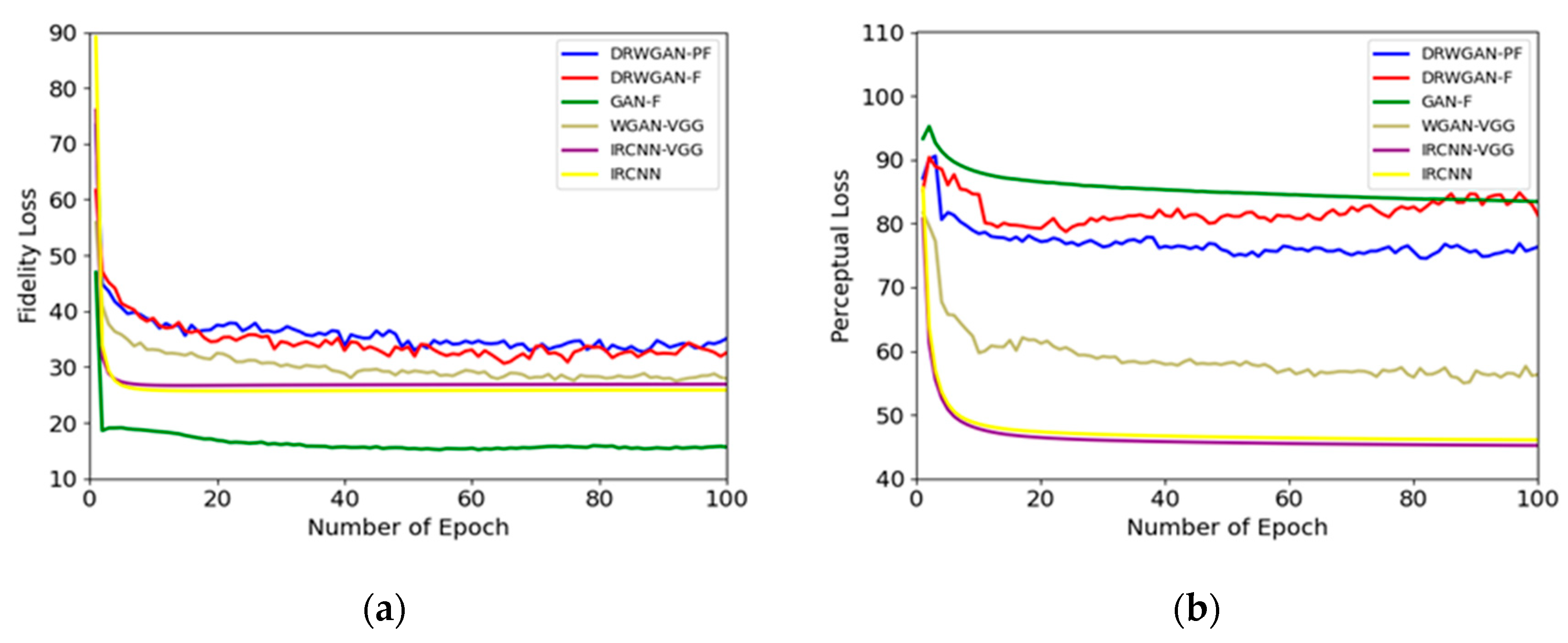
3.4. Network Convergence
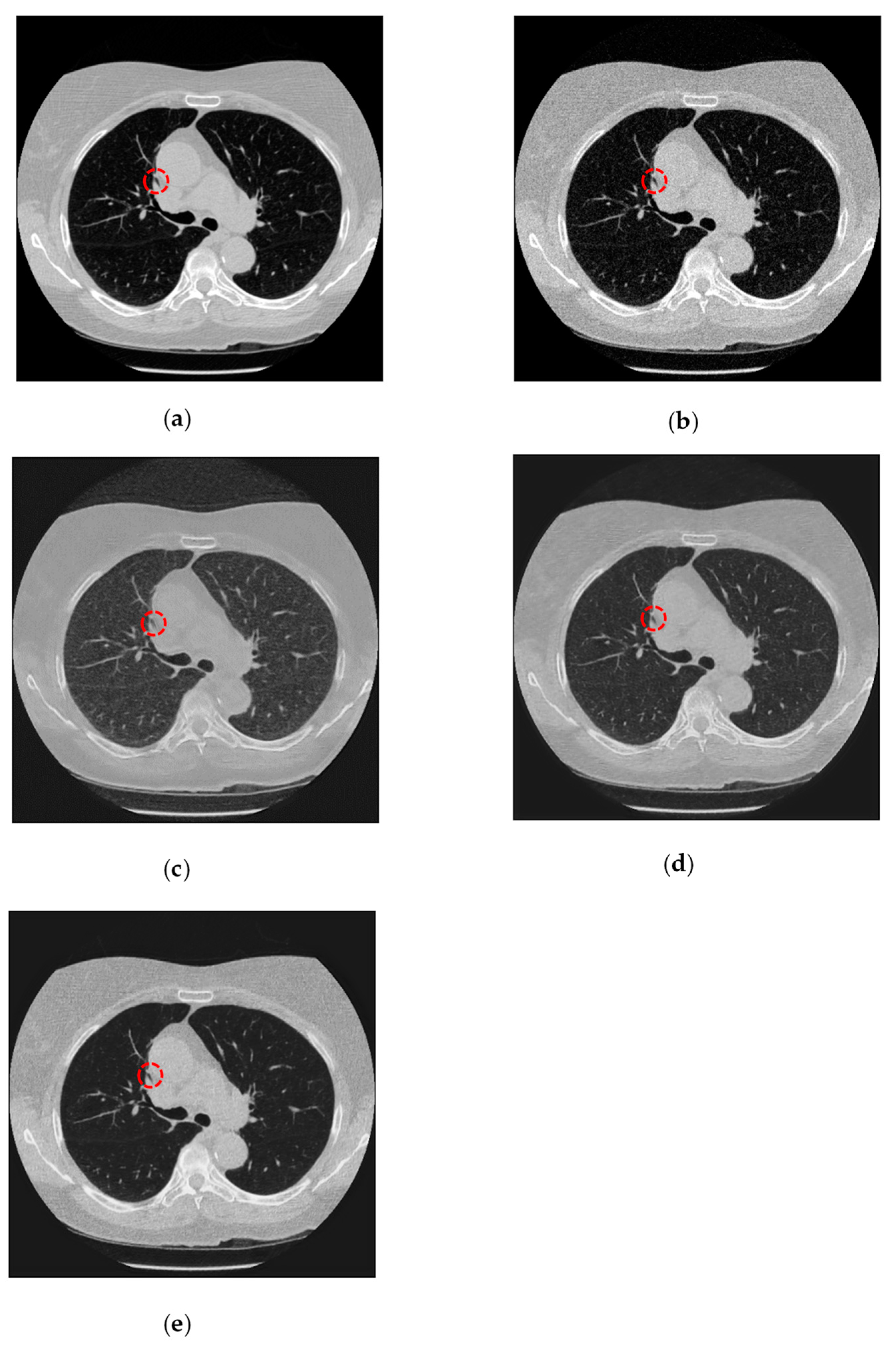
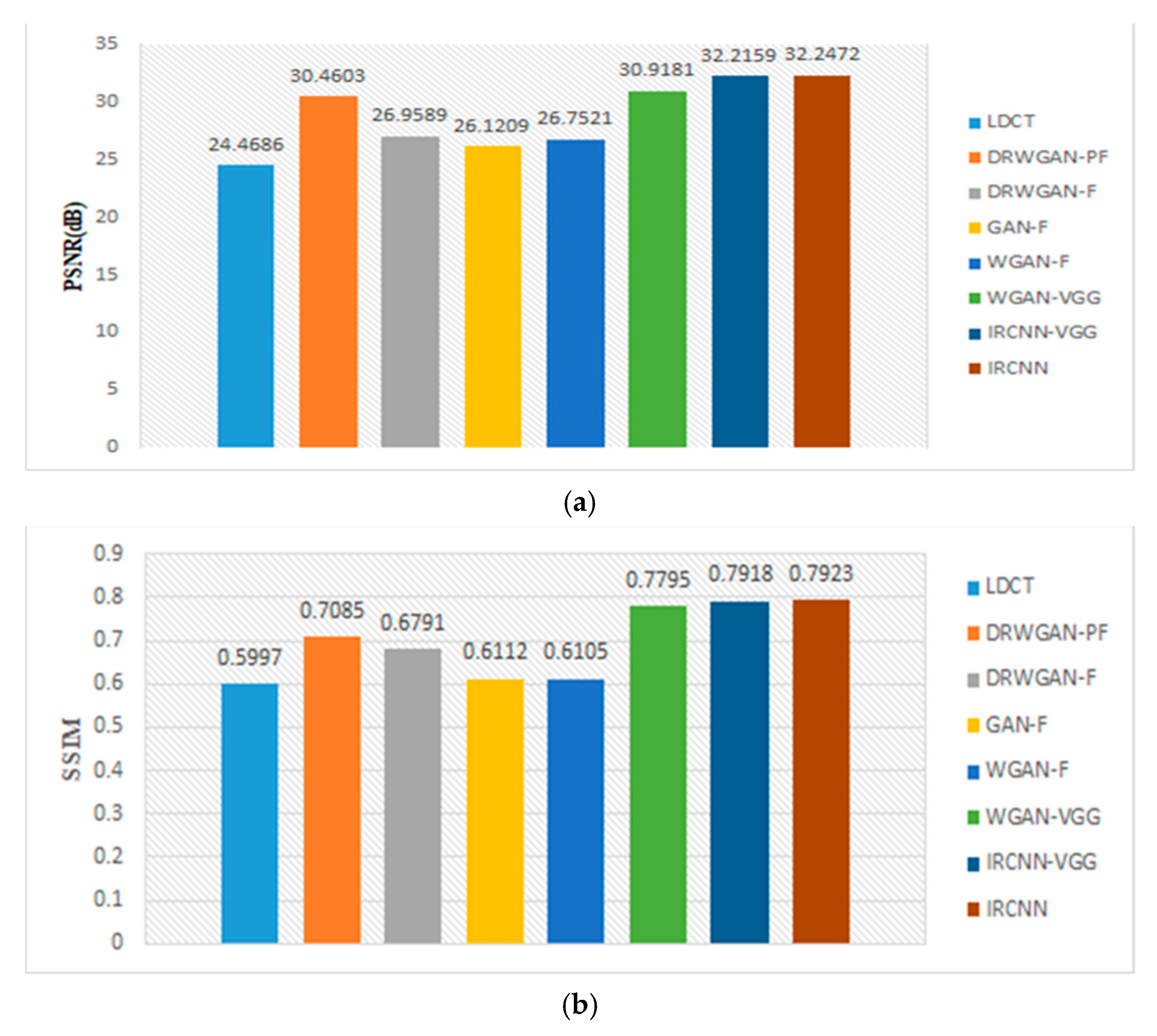
3.5. Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- de Gonzalez, A.B.; Darby, S. Risk of cancer from diagnostic X-rays: Estimates for the UK and 14 other countries. Lancet 2004, 363, 345–351. [Google Scholar] [CrossRef]
- Bindman, S.; Rebecca, C.T. Radiation and the Risk of Cancer. Curr. Radiol. Rep. 2015, 3, 1–7. [Google Scholar]
- Naidich, D.P.; Marshall, C.H.; Gribbin, C.; Arams, R.S.; McCauley, D.I. Low-dose CT of the lungs: Preliminary observations. Radiology 1990, 175, 729–731. [Google Scholar] [CrossRef] [PubMed]
- Mori, I.; Machida, Y.; Osanai, M.; Linuma, K. Photon starvation artifacts of X-ray CT: Their true cause and a solution. Radiol. Phys. Technol. 2013, 6, 130–141. [Google Scholar] [CrossRef] [PubMed]
- Whiting, B.R. Signal statistics in x-ray computed tomography. Proc. SPIE Int. Soc. Opt. Eng. 2002, 4682, 53–60. [Google Scholar]
- Wang, J.; Li, T.; Lu, H.; Liang, Z. Penalized weighted least-squares approach to sinogram noise reduction and image reconstruction for low-dose X-ray computed tomography. IEEE Trans. Med. Imaging 2006, 25, 1272–1283. [Google Scholar] [CrossRef]
- Hsieh, J. Adaptive streak artifact reduction in computed tomography resulting from excessive x-ray photon noise. Med. Phys. 1998, 25, 2139–2147. [Google Scholar] [CrossRef]
- Demirkaya, O. Reduction of noise and image artifacts in computed tomography by nonlinear filtration of projection images. Proc. SPIE 2001, 4322. [Google Scholar]
- Yu, L.; Manduca, A.; Trzasko, J.D.; Khaylova, N.; Kofler, J.M.; McCollough, C.M.; Fletcher, J.G. Sinogram smoothing with bilateral filtering for low-dose CT. Proc. SPIE Int. Soc. Opt. Eng. 2008, 6913, 691329. [Google Scholar]
- Cui, X.; Zhang, Q.; Shangguan, H.; Liu, Y.; Gui, Z. The adaptive sinogram restoration algorithm based on anisotropic diffusion by energy minimization for low-dose X-ray CT. Optik-Int. J. Light Electron Opt. 2014, 125, 1694–1697. [Google Scholar] [CrossRef]
- Smith, P.R.; Peters, T.M.; Bates, R.H.T. Image reconstruction from finite numbers of projections. J. Phys. A Math. Nucl. Gen. 2001, 6, 319–381. [Google Scholar] [CrossRef]
- Manduca, A.; Yu, L.F.; Trzasko, J.D.; Khaylova, N. Projection space denoising with bilateral filtering and CT noise modeling for dose reduction in CT. Med. Phys. 2009, 36, 4911–4919. [Google Scholar] [CrossRef] [PubMed]
- Beister, M.; Kolditz, D.; Kalender, W.A. Iterative reconstruction methods in X-ray CT. Phys. Med. 2012, 28, 94–108. [Google Scholar] [CrossRef] [PubMed]
- Sidky, E.Y.; Pan, X. Image reconstruction in circular cone-beam computed tomography by constrained, total-variation minimization. Phys. Med. Biol. 2008, 53, 4777–4807. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Gao, D.; Nie, C.; Luo, L.; Chen, W.; Yin, X.; Lin, Y. Bayesian statistical reconstruction for low-dose X-ray computed tomography using an adaptive-weighting nonlocal prior. Comput. Med. Imaging Graph. 2009, 33, 495–500. [Google Scholar] [CrossRef]
- Zhang, Q.; Gui, Z.; Chen, Y.; Li, Y.; Luo, L. Bayesian sinogram smoothing with an anisotropic diffusion weighted prior for low-dose X-ray computed tomography. Opt. Int. J. Light Electron. Opt. 2013, 124, 2811–2816. [Google Scholar] [CrossRef]
- Tang, S.; Wang, R.; Wei, Y.; Ming, J.; He, Z. Research of Tongue Image Denoising Based on Partial Differential Equation. Comput. Eng. 2012, 38, 190–192. [Google Scholar]
- Zhang, Y.; Wang, Y.; Zhang, W.; Lin, F.; Pu, Y.; Zhou, J. Statistical iterative reconstruction using adaptive fractional order regularization. Biomed. Opt. Express 2016, 7, 1015–1029. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Zhang, C.; Bian, Z.; Chen, W.; Ma, J.; Zhou, Q.; Zhou, X. Sparse-View X-ray Computed Tomography Reconstruction via Mumford-Shah Total Variation Regularization. Int. Conf. Intell. Comput. 2015, 9227, 745–751. [Google Scholar]
- Alenius, S.; Ruotsalaine, U. Attenuation correction for PET using count-limited transmission images reconstructed with median root prior. IEEE Trans. Nucl. Sci. 1999, 46, 646–651. [Google Scholar] [CrossRef]
- Zhan, H.; Ma, J.; Wang, J.; Moore, W.; Liang, Z. Assessment of prior image induced nonlocal means regularization for low-dose CT reconstruction: Change in anatomy. Med. Phys. 2017, 44, e264–e278. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, L.; Zhang, Y.; Song, Y.; Li, C.; Guo, D. Low-Dose CT Image Restoration Based on Adaptive Prior Feature Matching and Nonlocal Means. Int. J. Image Graph. 2019, 19, 1950017. [Google Scholar] [CrossRef]
- Niu, S.; Zhang, S.; Huang, J.; Bian, Z.; Chen, W.; Yu, G.; Liang, Z.; Ma, J. Low-dose cerebral perfusion computed tomography image restoration via low-rank and total variation regularizations. Neurocomputing 2016, 197, 143–160. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Shao, Y.; Jia, L.; Wang, Y.; Gui, Z. Low-Dose CT Image Denoising Model Based on Sparse Representation by Stationarily Classified Sub-Dictionaries. IEEE Access 2019, 7, 116859–116874. [Google Scholar] [CrossRef]
- Hasan, A.M.; Melli, A.; Wahid, K.A.; Babyn, P. Denoising Low-Dose CT Images Using Multiframe Blind Source Separation and Block Matching Filter. IEEE Trans. Radiat. Plasma Med. Sci. 2018, 2, 279–287. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, Y.; Zhang, W.; Liao, P.; Wang, G. Low-dose CT denoising with convolutional neural network. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging, Melbourne, Sydney, 18–21 April 2017; pp. 143–146. [Google Scholar]
- Chen, H.; Zhang, Y.; Mannudeep, K.; Lin, F.; Chen, Y.; Liao, P.; Zhou, J.; Wang, G. Low-Dose CT with a Residual Encoder-Decoder Convolutional Neural Network. IEEE Trans. Med. Imaging 2017, 36, 2524–2535. [Google Scholar] [CrossRef]
- Kang, E.; Min, J.; Ye, J. A deep convolutional neural network using directional wavelets for low‐dose X‐ray CT reconstruction. Med. Phys. 2017, 44, e360–e375. [Google Scholar] [CrossRef] [Green Version]
- Kang, E.; Min, J.; Ye, J. Wavelet Domain Residual Network (WavResNet) for Low-Dose X-ray CT Reconstruction. arXiv 2017, arXiv:1703.01383. [Google Scholar]
- Ye, J.; Han, Y.; Cha, E. Deep convolutional framelets: A general deep learning framework for inverse problems. SIAM J. Imaging Sci. 2018, 11, 991–1048. [Google Scholar] [CrossRef]
- Park, H.S.; Baek, J.; You, S.K.; Choi, J.K.; Seo, J.K. Unpaired image denoising using a generative adversarial network in X-ray CT. IEEE Access 2019, 7, 110414–110425. [Google Scholar] [CrossRef]
- Yang, Q.; Yan, P.; Zhang, Y.; Yu, H.; Shi, Y.; Mou, X.; Kalra, M.K.; Zhang, Y.; Sun, L.; Wang, G. Low-Dose CT Image Denoising Using a Generative Adversarial Network with Wasserstein Distance and Perceptual Loss. IEEE Trans. Med. Imaging 2018, 37, 1348–1357. [Google Scholar] [CrossRef] [PubMed]
- Tang, C.; Li, J.; Wang, L.; Li, Z.; Yan, B. Unpaired Low-Dose CT Denoising Network Based on Cycle-Consistent Generative Adversarial Network with Prior Image Information. Comput. Math. Methods Med. 2019, 2019, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Champion, T.; Pascale, L.D.; Juutinen, P. The ∞-Wasserstein Distance: Local Solutions and Existence of Optimal Transport Maps. SIAM J. Math. Anal. 2008, 40, 1–20. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 2808–2817. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Gholizadeh-Ansari, M.; Alirezaie, J.; Babyn, P. Deep Learning for Low-Dose CT Denoising. arXiv 2019, arXiv:1902.10127. [Google Scholar]
- Lu, H.; Hsiao, I.T.; Li, X.; Liang, Z. Noise properties of low-dose CT projections and noise treatment by scale transformations. Nucl. Sci. Symp. Conf. Rec. 2001, 3, 1662–1666. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Loss | Dataset |
|---|---|---|
| DRWGAN-PF | Unpaired | |
| DRWGAN-F | Unpaired | |
| GAN-F | Unpaired | |
| WGAN-VGG | Paired | |
| IRCNN | Paired | |
| IRCNN-VGG | Paired |
| Metric | LDCT | DRWGAN | DRWGAN-P | DRWGAN-PF |
|---|---|---|---|---|
| PSNR | 24.5241 | 23.4885 | 29.2091 | 29.6957 |
| SSIM | 0.5454 | 0.5947 | 0.6233 | 0.6916 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Z.; Xia, K.; He, Z.; Zhang, J.; Wang, S.; Zu, B. Unpaired Image Denoising via Wasserstein GAN in Low-Dose CT Image with Multi-Perceptual Loss and Fidelity Loss. Symmetry 2021, 13, 126. https://doi.org/10.3390/sym13010126
Yin Z, Xia K, He Z, Zhang J, Wang S, Zu B. Unpaired Image Denoising via Wasserstein GAN in Low-Dose CT Image with Multi-Perceptual Loss and Fidelity Loss. Symmetry. 2021; 13(1):126. https://doi.org/10.3390/sym13010126
Chicago/Turabian StyleYin, Zhixian, Kewen Xia, Ziping He, Jiangnan Zhang, Sijie Wang, and Baokai Zu. 2021. "Unpaired Image Denoising via Wasserstein GAN in Low-Dose CT Image with Multi-Perceptual Loss and Fidelity Loss" Symmetry 13, no. 1: 126. https://doi.org/10.3390/sym13010126
APA StyleYin, Z., Xia, K., He, Z., Zhang, J., Wang, S., & Zu, B. (2021). Unpaired Image Denoising via Wasserstein GAN in Low-Dose CT Image with Multi-Perceptual Loss and Fidelity Loss. Symmetry, 13(1), 126. https://doi.org/10.3390/sym13010126