1. Introduction
In a real life scenarios, it is a widespread phenomenon when systems cease to function in their extreme working environments. Often systems fail to perform their intended functions whenever crossing their lower, upper or both extreme working environments. In the literature
, widely known as stress-strength reliability, has been studied extensively. A system working under such stress-strength set up fails to function when applied stress exceeds the strength of the system. Some of the notable works in this direction include Weerahandi and Johnson [
1], Surles and Pedgett [
2], Al-Mutairi et al. [
3], Rao et al. [
4], Singh et al. [
5], Almetwally and Almongy [
6], Alshenawy et al. [
7], Alamri et al. [
8], Sabry et al. [
9], Abu El Azm et al. [
10], Okabe and Otsuka [
11] and many more can be added to this list.
Furthermore, the study of stress-strength models have been extended to systems with multiple components, widely known as multicomponent systems. Even though the multicomponent stress-strength model was introduced decades ago by Bhattacharyya and Johnson [
12], it has received wide attention in recent years and studied by many researchers for complete as well as censored data. Some of the recently appeared articles include Kotb and Raqab [
13], Maurya and Tripathi [
14], Mahto et al. [
15], Mahto and Tripathi [
16], Wang et al. [
17,
18], Jha et al. [
19], Rasekhi et al. [
20], Alotaibi et al. [
21], Maurya et al. [
22], Kohansal and Shoaee [
23], Jana and Bera [
24] and many more can also be listed.
Many studies have been carried out for
as stress-strength model and the study is extended to multicomponent systems also. However very less attention is given to an equally important practical scenario when devices cease to function under extreme lower as well as extreme upper working environment. For example, some electrical equipment fail when placed under below and above some specific power supply. In a similar manner, a person’s systolic and diastolic pressure limits should not exceeded. Such applications are not limited and it is quite basic and natural, reflecting sound relationships among various real-world phenomena. It is a useful relationship in various subareas of genetics and psychology also where strength
Y should not only be larger than stress
X, but also be lower than the stress
Z. Many researchers have studied the estimation of the stress-strength parameter for many statistical models. Estimation of
based on independent samples was examined by Chandra and Owen [
25], Hlawka [
26], Singh [
27], Dutta and Sriwastav [
28], and Ivshin [
29]. The estimation in the stress-strength model under the supposition that the strength of a component lies in an interval and estimation of the probability
was obtained by Singh [
27], where
and
were independent random stress variables and
Y was a random strength variable. The estimation of
was considered by Chandra and Owen [
25] when
were normal distributions and
X was another independent normal random variable. Hanagal [
26] estimated the reliability of a component subjected to two different stresses that were independent of the strength of a component. Hanagal [
30] estimated the system reliability in the multi-component series stress-strength model. Waegeman et al. [
31] suggested a simple calculation algorithm for
and its variance using existing U-statistics. Chumchum et al. [
32] studied the cascade system with
. Guangming et al. [
33] discussed nonparametric statistical inference for
. Inference of
for n-Standby System: A Monte-Carlo Simulation Approach was obtained by Patowary et al. [
34].
Based on the censored sample, many articles that appeared include: Kohansal and Shoaee [
23] discussed Bayesian and likelihood estimation methods of reliability in a multicomponent stress-strength model under adaptive hybrid progressive censored data for Weibull distribution. Saini et al. [
35] obtained reliability of a multicomponent stress-strength system based on Burr XII distribution using progressively first-failure censored samples. Kohansal et al. [
36] introduced multicomponent stress–strength estimation of a non-identical-component strengths system under the adaptive hybrid progressive censoring. Hassan [
37] estimated the reliability of multicomponent stress-strength with generalized linear failure rate distribution based on progressive Type II censoring data.
Often, when dealing with reliability characteristics in statistical analysis even after knowing that there may be some loss of efficiency, different ways of early removals of live units known as censoring schemes are used to save time and cost. Many types of censoring schemes are well known, such as the type-II censoring scheme, progressive type-II censoring scheme, and progressive first failure censoring scheme, for example. Wu and Kus [
38] proposed a new life-test plan called the progressive first failure censoring scheme, merging progressive type-II censoring and first failure censoring schemes. It is possible to characterize the progressive first failure censoring scheme as follows: assume that
n independent groups with
k items within each group are placed on a life-test. Once the first failure
has occurred,
units and the group in which the first failure is spotted are randomly withdrawn from the experiment. At the time of the second failure
, the
units and the group in which the second failure is observed are randomly withdrawn from the remaining live
groups. At the end, when the m-th observation
fails, the rest of the live units
are withdrawn from the test. Then, the obtained ordered observations
are called progressively first-failure censored with progressive censored scheme specified by
, where
m failures and sum of all removals sums to
n, that is,
. One may notice that a special case with
reduces the progressive first-failure censoring to first-failure censoring scheme. Similarly, with
and
, first-failure type-II censoring comes as a particular case of this censoring scheme. With the assumption that each group contains exactly one unit, that is,
, the progressive first-failure censoring scheme reduces to the progressive type-II censoring scheme. Thus, a generalization of progressive censoring is progressive first-failure censoring.
Let
denoting a progressive first-failure type-II censored population sample with
pdf and
distribution function with progressive censoring scheme
. The likelihood function is based on Balakrishnan and Aggarwala [
39] and Wu and Kus [
38] on the basis of considered progressive first-failure censored sample is given as follows:
where
Kumaraswamy [
40] proposed a distribution having double bounded support by describing it’s first application in the field of hydrology. The Kumaraswamy distribution (KuD) having parameters
and
, respectively, is described by the probability density function (PDF), cumulative distribution function (CDF), and hazard rate function given as:
respectively.
In terms of properties, the KuD is more like the beta distribution which shares many of the common properties but in terms of tractability, KuD has better tractable form than the beta distribution. The densities of Kumaraswamy also share the shapes with beta distribution for various values and may have unimodal, increasing, decreasing or constant densities based on various values of it’s parameters. KuD applies to many natural phenomena, such as the height of individuals, atmospheric temperatures, and scores obtained on a test. It can be used to approximate many well known distributions, for instance, uniform, triangular, and many others. Jones [
41] found that the KuD can be applied to model reliability data resulting from various life studies. Golizadeh et al. [
42] used ungrouped data to analyze classical and Bayesian estimators for the shape parameter of the KuD and also considered the relationship between them. For more details, see Sindhu et al. [
43], Sharaf EL-Deen et al. [
44], Wang [
45], Kumar et al. [
46] and Fawzy [
47].
Therefore, we intend to introduce inference for multicomponent reliability where stress-strength variables follow unit KuD based on the progressive first-failure. The challenge of estimating the stress-strength function R, where , and Z come from three independent KuD is addressed in this paper. The likelihood estimation based on progressive first-failure censored for point estimation, asymptotic confidence interval, bootstrap -p, and t methods are also discussed. The Bayesian estimation methods based on progressive first-failure censored are obtained by using Markov chain Monte Carlo (MCMC) and Lindly’s approximation. Symmetric and asymmetric loss functions have been used for Bayesian estimation. The balanced and unbalanced loss functions have been used to estimate the reliability of multi stress–strength Kumaraswamy distribution based on progressive first-failure censored samples. Monte Carlo simulations and application examples of real data are used to evaluate and compare the performance of the various proposed estimators.
The rest of the paper is organized as follows. The classical point estimates maximum likelihood estimation and interval estimation, namely asymptotic, boot-p and boot-t are considered in
Section 2. In
Section 3, Bayesian estimation techniques are considered, including Lindley and MCMC techniques. We provide the Bayes estimate of
R in this section. Extensive simulation studies are given in
Section 4. The application example of real data are obtained in
Section 5. Finally, we conclude the paper in
Section 6.
3. Bayes Estimation
In this section, we use the Bayesian inference of R with respect to symmetric loss function as balanced squared error (BSE) and asymmetric loss function as balanced LINEX (BLINEX) loss functions considering that the three parameters and are random variables.
The use of loss function, widely known as balanced loss function (BLF), first introduced by Zellner [
51], was further suggested by Ahmadi et al. [
52] to be of the form
where
is an arbitrary loss function,
is a chosen estimate of
and the weight
By choosing
, the BLF is reduced to the BSE loss function, in the form
The associated Bayes estimate of the function
G is expressed as
where is
the MLE of
G. Furthermore, by choosing
, we get BLINEX loss function, in the form
In this case, the Bayes estimate of
G will be
where
c is taken to be nonzero, that is,
, is the shape parameter of BLINEX loss function.
3.1. Prior and Posterior Distributions
The prior knowledge is incorporated in terms of some prior distributions, and here we assume that the three parameters
and
are random variables having independent gamma priors. So, the joint prior density is written as
The joint posterior density function of
and
can be written from (5) and (9) as
Analytical computation of Bayes estimates of
R using (
10) is found to be difficult. Therefore, we are left with the option of choosing some approximation technique to approximate the corresponding Bayes estimates. At the first, we apply the Lindley approximation technique for this purpose, but the use of this technique is limited to point estimation only. So secondly, we also use MCMC technique to obtain posterior samples for parameters and then for
R to obtain the point as well as interval estimates.
3.2. Lindley’s Approximation
Here, we apply Lindley’s [
53] approximation method for obtaining the approximate Bayes estimates of
R under BSE and BLINEX loss functions and are given, respectively, by
3.3. Markov Chain Monte Carlo
The use of Lindley approximation is limited to point estimation only. Therefore, to obtain inerval estimates, we suggest to use MCMC technique to generate samples from (10) and then using the obtained samples, compute the Bayes estimates of
R. The conditional posterior distributions of the three model parameters
and
can be expressed, respectively, as
where,
denotes a Gamma(
distribution, so we use the Gibbs sampling technique to generate random sample of
. Similarly, The posterior pdf’s of
and
are Gamma(
and Gamma(
distribution, respectively. Therefore, the procedure of Gibbs sampling can be expressed as follows:
Step 1. Choose the MLEs , and , as the starting values () of , and .
Step 2. Set
Step 3. Generate from Gamma(.
Step 4. Generate from Gamma(.
Step 5. Generate from Gamma(.
Step 6. Set
Step 7. Compute .
Step 8. Repeat steps 3–7 N times.
Step 9. The approximate means of
R and
are given, respectively, by
where
M is the burn-in period.
Therefore, the Bayes estimates of
R based on BSE and BLINEX loss functions is given, respectively, by
Using the posterior samples, we construct
HPD interval of the reliability
R using the widely discussed technique of Chen and Shao [
54].
4. Simulation Study
In this section, a Monte Carlo simulation study is conducted to compare the performance of different methods described in the preceding sections. We compare the ML and Bayes estimates under SELF using gamma informative prior in terms of mean-squared errors (MSE). For the ease of simulation, we consider same group sizes , same number of groups , and same number of failures with same pre-fixed censoring schemes . In the Bayes estimation, we consider values of parameters and with corresponding hyper-parameters . For varying choices of sample size n, and number of observed failure time m, which represent 60%, 80% and 100% of the sample size. For showing behavior in different scenarios, we have considered three progressive first-failure censoring schemes, namely:
Scheme I: and for ;
Scheme II: and for ;
We obtain the average MSEs of MLE and Bayes estimator for
R over 1000 progressively first-failure-censored samples generated using an algorithm proposed by Balakrishnan and Sandhu [
55] with distribution function
from KuD. The Bayes estimates relative to both BSE and BLINEX with varying values of the shape parameter
c of LINEX loss function and various values of
. We applied MCMC technique for generating samples based on 11,000 MCMC simulation repetition and discard the initial 1000 values as burn-in for avoiding any dependency on initial value. The results of the simulation study are reported in
Table 1 and
Table 2. Moreover, to observe the behavior of different CIs in terms of different sample sizes and different parameter values, we obtained expected length and 95% coverage probability (CP) of various CIs and Bayesian credible intervals, which are given in
Table 3 and
Table 4.
Concluding on the Simulation Results
Table 1,
Table 2,
Table 3 and
Table 4 describe the simulation results of the approaches presented in this research for point estimation and interval estimation for reliability for multi-component stress–strength KuD based on progressive first-failure censored samples. We analyze the MSE, length of CIs, and CP of confidence interval values in order to conduct the required comparison between various point estimating methods. The following conclusions can be drawn from these tables:
The MSE of reliability for multi stress–strength KuD based on progressive first-failure censored samples for both ML and Bayes estimation is decreased as the number of groups n and the effective sample size m increase.
In most cases, the MSE decreases as k increases for the fixed scheme of reliability for multi stress–strength KuD based on progressive first-failure censored samples.
The Bayes estimates when compared in terms of MSEs from the ML estimates show better performance with smaller values of MSE in all the considered cases.
According to MSE and confidence interval, Scheme I is the best Scheme in the majority of situations.
In MCMC and Lindley’s, BLINEX is better than BSEL estimation.
In MCMC and in BLINEX, we note MSE decrease as c increases.
In Lindley’s and in BLINEX, we note MSE decrease as c decreases.
Boot P is better than boot T.
Complete sample has the smallest MSE and length of CI.
It is observed that Bayesian intervals are having smaller interval lengths than the classical interval estimates.
It is also observed that the CPs of asymptotic confidence intervals is quit low than the nominal level but for boot-p, boot-t and Bayesian interval estimates are showing coverage probabilities higher than nominal level.
5. Data Analysis and Application
We consider a real data set to illustrate the methods of inference discussed in this article. These strength data sets were analyzed previously by Kundu and Gupta [
56], and Surles and Padgett [
2].The first data is inverse of strength measured in GPA for carbon fibers tested under tension at gauge lengths of 20 mm, these data are 0.762, 0.761, 0.676, 0.644, 0.588, 0.555, 0.537, 0.536, 0.514, 0.511, 0.509, 0.501, 0.499, 0.495, 0.493, 0.487, 0.485, 0.477, 0.467, 0.459, 0.450, 0.446, 0.444, 0.441, 0.440, 0.440, 0.435, 0.435, 0.424, 0.420, 0.420, 0.412, 0.411, 0.411, 0.404, 0.402, 0.398, 0.398, 0.394, 0.392, 0.390, 0.389, 0.387, 0.380, 0.380, 0.379, 0.378, 0.373, 0.371, 0.367, 0.361, 0.361, 0.357, 0.356, 0.355, 0.354, 0.351, 0.347, 0.339, 0.332, 0.326, 0.324, 0.324, 0.323, 0.320, 0.309, 0.291, 0.279, 0.279. The second data is the inverse of strength measured in GPA for carbon fibers tested under tension at gauge lengths of 10 mm, these data are 0.526, 0.469, 0.454, 0.449, 0.443, 0.426, 0.424, 0.417, 0.417, 0.409, 0.407, 0.404, 0.397, 0.397, 0.396, 0.395, 0.388, 0.383, 0.382, 0.382, 0.381, 0.376, 0.374, 0.365, 0.365, 0.350, 0.343, 0.342, 0.340, 0.340, 0.336, 0.334, 0.330, 0.320, 0.319, 0.318, 0.311, 0.310, 0.309, 0.308, 0.306, 0.306, 0.304, 0.300, 0.299, 0.296, 0.293, 0.291, 0.286, 0.286, 0.283, 0.281, 0.281, 0.276, 0.260, 0.258, 0.257, 0.252, 0.249, 0.248, 0.237, 0.228, 0.199.
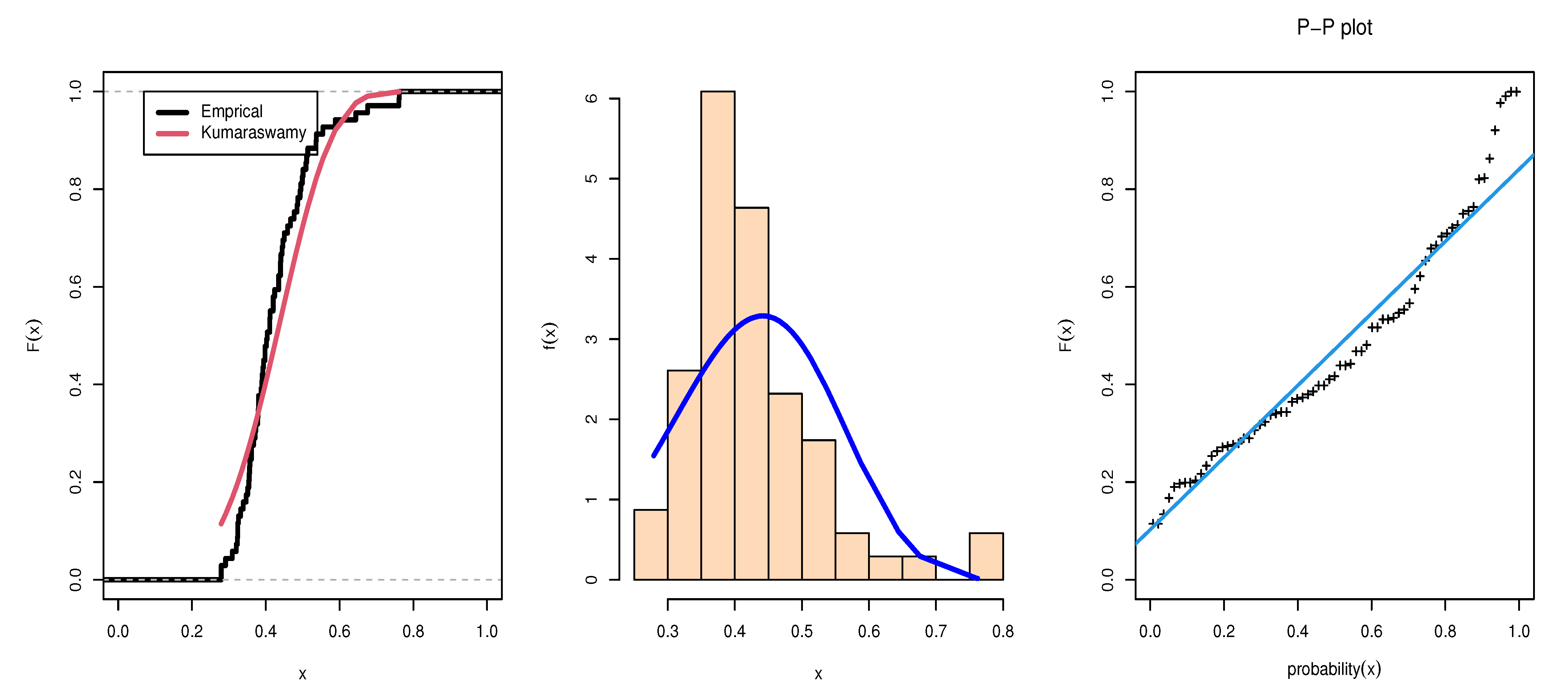
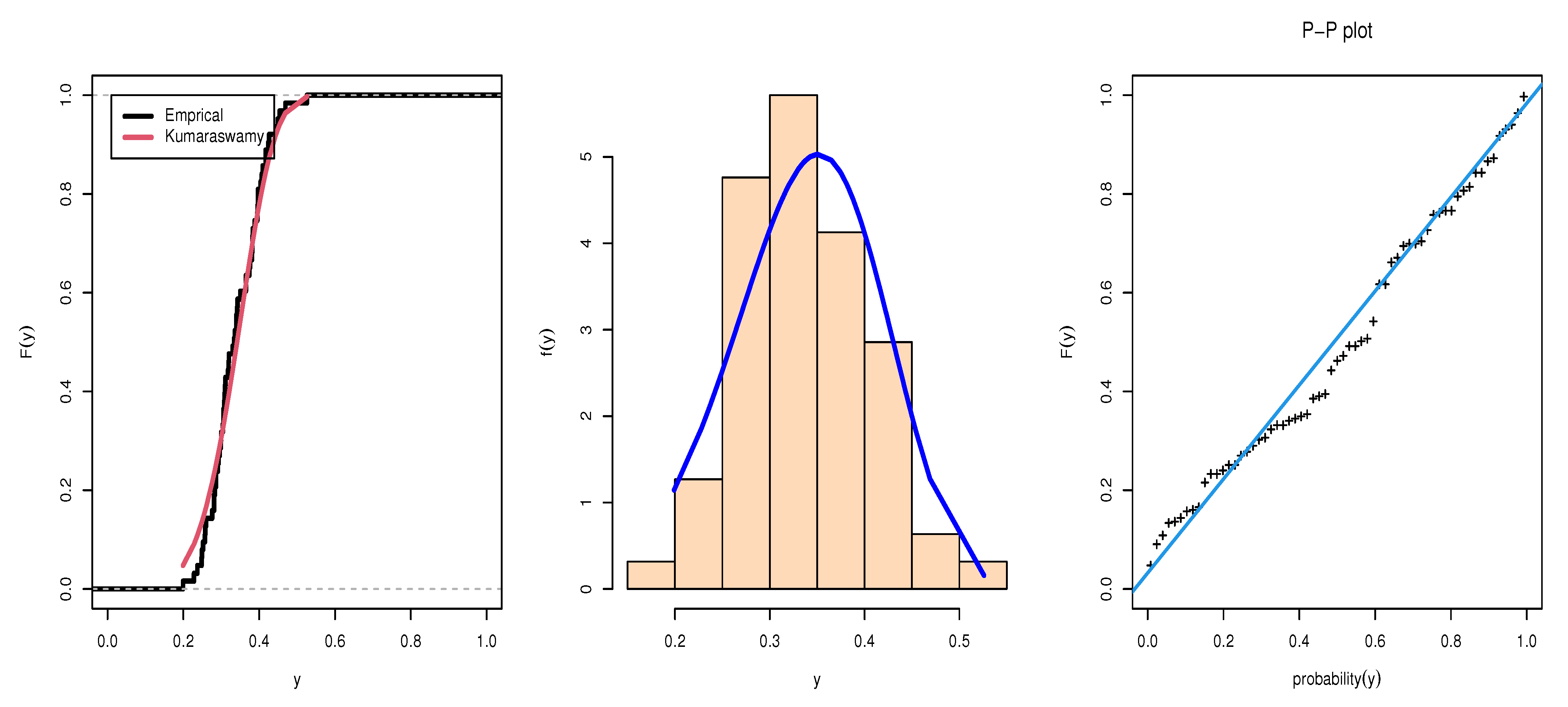
Table 5 shows the ML estimation of marginals of KuD with standard error (SE), Cramer–von Mises (CvM) Anderson–Darling (AD), Akaike information criterion (AIC), and Bayesian information criterion (BIC) statistics. The Kolmogorov–Smirnov (KS) distances and corresponding
p-values in
Table 5 show that the KuD with equal shape parameters fit reasonably well to the modified data sets.
Figure 1 and
Figure 2 give the estimated pds, CDF and PP-plot for Data set 1 and Data set 2, respectively.
The MLE and Bayesian estimation method for stress-strength reliability model are obtain for parameters of the model based on progressive first-failure in
Table 6.
The scheme 1 is Type-II first failure where
and
, where
point to replication of censored scheme.
x1 is 0.279, 0.309, 0.324, 0.332, 0.351, 0.356, 0.361, 0.373, 0.380, 0.389, 0.394, 0.402, 0.411, 0.420, 0.435, 0.441, 0.450, 0.477. x2 is 0.199, 0.248, 0.257, 0.276, 0.283, 0.291, 0.299, 0.306, 0.309, 0.318, 0.330, 0.340, 0.343, 0.365, 0.381, 0.383, 0.396, 0.404.
The scheme 2 is Progressive first failure where and . x1 is 0.279, 0.324, 0.332, 0.351, 0.373, 0.380, 0.389, 0.394, 0.402, 0.411, 0.420, 0.435, 0.441, 0.450, 0.477, 0.493, 0.501, 0.514. x2 is 0.199, 0.248, 0.257, 0.276, 0.283, 0.291, 0.299, 0.306, 0.309, 0.318, 0.330, 0.343, 0.365, 0.381, 0.383, 0.396, 0.417, 0.426.
Table 6 show Bayesian estimation is the best estimation method according to SE and reliability. Furthermore, we show scheme 2 has the reliability of 0.7803 for ML and 0.8055 for Bayesian which is a better scheme than other schemes.
Figure 3 and
Figure 4 show convergence plots of MCMC for parameter estimates of KuD for different schemes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}