1. Introduction
There is much uncertainty in decision making problems. It is not easy to describe the evaluation information with accurate numerical value, and they can only be described with linguistic values. Zadeh [
1,
2,
3] defined the linguistic term set (LTS) and applied it to express the qualitative evaluation. For example, the commonly used seven valued LTS is in the form of
, it can be used to describe how much the decision maker likes the object. However, when the decision maker hesitates about the preference of the evaluation object, the single linguistic term is no longer describe such information. So Rodríguez et al. [
4] presented the hesitant fuzzy linguistic term set (HFLTS), each of elements is a collection of linguistic terms. For example, the decision maker thinks that the audience’s opinion of the program is “favorite” or “great favorite”, the evaluation about the opinion of the program can be only expressed in the form of
. Since the HFLTS was put forward, some extensions of HFLTS were developed and applied in many fields [
5,
6,
7,
8,
9,
10,
11]. Beg and Rashid [
5] proposed the TOPSIS method of HFLTS and applied it to sort the alternative, Liao et al. [
6] defined the preference relation of HFLTS, Liu et al. [
7] applied the HFLTSs to the generalized TOPSIS method and presented a new similarity measure of HFLTS. In these studies however, all the linguistic terms in HFLTS have the same weights, it rarely happens in reality. In fact, the decision makers may have different degrees to the possible linguistic evaluations. Therefore, Pang et al. [
12] developed the HFLTS to the PLFS through adding the probabilities to each element. For example, the decision maker believes that the possibility of favorite to the program is 0.4 and the possibility of great favorite to the program is 0.6, then the above evaluation can be represented as
.
In the aboved LTS, they only describe the membership degree of elements. To improve the range of their application, Chen [
13] defined the linguistic intuitionistic fuzzy set (LIFS)
, where
, the membership
and the non-membership
satisfy the following condition:
. Furthermore, Garg [
14] defined the linguistic Pythagorean fuzzy set (LPFS)
, where
, the following condition of the membership
and the non-membership
must be satisfied:
, its advantage is it has a wider range of uncertainty than LIFS. Furthermore, in order to better describe the uncertainty in decision making problems, Liu et al. [
7] proposed the LQROS
based on the q-rung orthopair fuzzy set (QROFS) [
15], where the following condition of the membership
and the non-membership
should be met:
. Obviously, when
or 2, the LQROS is reduced to LIFS or LPFS, respectively. Although the LQROS extends the scope of information representation, it cannot describe the following evaluation information. For the given LTS
, one expert believes that 30% possibility of profit from the investment in the project is high, and 70% possibility of profit from the investment in the project is extreme high. While the other expert may believe that 10% possibility of not making a profit is extreme slowly and 90% possibility of not making a profit is slightly slowly. Up to now, we cannot apply the existing LTS to describe the above evaluation information. Motivated by this, we introduce the PLQROS by integrating the LQROS and the probabilistic fuzzy set. Then the above information can be represented by
, the detailed definition is given in
Section 3.1.
On the other side, the TOPSIS is a classical method to handle the multiple criteria decision making problems. Since it was introduced by Hwang and Yoon [
16], there were many literatures on TOPSIS method, we can refer to [
17,
18,
19,
20,
21,
22]. The TOPSIS method is a useful technique for choosing an alternative that is closet to the best alternative and farthest from the worst alternative simultaneously. Furthermore, Yoon and Kim [
23] proposed a behavioral TOPSIS method that incorporates the gain and loss in behavioral economics, which makes the decision results more reasonable. As all we know, there is no related research study the behavioral TOPSIS method in uncertain decision environments problems. Inspired by this, we study the TOPSIS method which consider the decision maker’s risk attitude and the adjusted probabilistic fuzzy set, the main contributions of the paper are given as follows:
- (1)
The operational laws of PLQROS are given based on the adjusted PLQROS with the same probability, which can avoid the unreasonable calculation and improve the adaptability of PLQROS in reality.
- (2)
The new aggregation operators and distance measures between PLQROSs are presented, which can represent the differences between PLQROSs and deal with the symmetry information.
- (3)
The behavioral TOPSIS method is introduced into the uncertain multi-attribute decision making process, which changes the behavioral TOPSIS method only used in the deterministic environment.
The remainder of paper is organized as follows: in the second section, some related concepts are reviewed. In the third section, we introduce the operational laws of PLQROSs, the aggregated operators and distance measures of PLQROSs, and we also give their corresponding properties. In
Section 4, the process steps of the behavioral decision algorithm are given. In
Section 5, a practical example is utilized to prove the availability of the extension TOPSIS method. Furthermore, the sensitivity analysis of the behavioral factors of decision maker’s risk attitude is provided. Finally, we made a summary of the paper and expanded the future studies.
2. Preliminaries
In order to define the PLQROS, we introduce some concepts of LTS, PLFS, QROFS and LQROS. Throughout the paper, assume to be a non-empty and finite set.
In the uncertain decision making environment, the experts applied the LTS to make a qualitative description, it is defined as follows:
Definition 1 ([
1])
. Assume is a finite set, where is a linguistic term and g is a natural number, the LTS S should satisfy two properties:- (1)
if , then ;
- (2)
, where .
In order to describe the decision information more objective, Xu [24] extended the LTS S to a continuous LTS , where is a natural number. The PLFS is regarded as an extension of HFLTS, which considers the elements of LTSs with different weights, the PLFS can be denoted as:
Definition 2 ([
12])
. Assume and is a LTS, the PLFS in X is defined as:where , is the linguistic term and is the corresponding probability of , U is the number of linguistic terms . Next, we introduce the concept of QROFS as follows:
Definition 3 ([
15])
. Assume , the QROFS Q is represented as:where the membership and the non-membership satisfy , is the indeterminacy degree of QROFS Q. If X = {x}, the QROFS Q is reduced to a q-rung orthopair fuzzy number (QROFN) .
Remark 1. If q = 1 or 2, the QROFS Q is degenerated to an intuitionistic fuzzy set (IFS) or a Pythagorean fuzzy set (PFS).
In some realistic decision making problems, the set should be described qualitatively. So we review the concept of LQROS as follows:
Definition 4 ([
25])
. Assume , is a LTS, the LQROS Y is represented as:where the membership and the non-membership satisfy , the indeterminacy degree . If X = {x}, the LQROS Y is degenerated to a linguistic q-rung orthopair number (LQRON) .
Definition 5 ([
25])
. Let and be two LQRONs, , , the algorithms of the LQRONs can be expressed as follows:- (a)
;
- (b)
;
- (c)
;
- (d)
.
3. The Proposed Probabilistic Fuzzy Set
Now we propose a new probabilistic fuzzy set—PLQROS, which not only allows the experts to express evaluation information with multiple linguistic terms but contains the possibility of each linguistic terms. The difficulty is how to define the operational laws of PLQROS reasonably when the corresponding probability distributions are different.
3.1. The Basic Definition of PLQROS
Definition 6. Let and be a continuous LTS, the PLQROS in X can be defined as:where is the membership and is the non-membership, respectively. For any , they satisfy with: . If X = {x}, the PLQROS is degenerated to a PLQRON , , where and .
Example 1. Let . Two groups of experts inspected the development of the company, one group may think that “the speed of company development is slightly slowly with 100% possibility, with 40% probability that it is not slightly slowly, with 40% probability that the speed of company development is not generally and with 20% probability that the speed of company development is not slightly fast”. The other group think that “with 20% probability that the speed of company development is slowly, with 60% probability that the speed of company development is slightly slowly and with 20% probability that it is generally, with 50% probability that it is not slightly fast and with 50% probability that it is not very fast”. Then the above evaluation information can be denoted as and .
According to Example 1, we can see that the probabilities and numbers of elements in
and
are not same, the general operations on PLFSs multiply the probabilities of corresponding linguistic terms directly, which may cause the unreasonable result. Therefore, Wu et al. [
26] presented a method to modify the probabilities of linguistic terms to be same, which is given as follows:
Let
be a continuous LTS,
and
;
are two PLQRONs. We adjust the probability distributions of
and
to be same, respectively. That is to say,
and
;
. Applying the method of Wu et al. [
26] to adjust the PLQRONs, the linguistic terms and the sum of probabilities of each linguistic term set are not changed, which means that the adjustment method does not result in the loss of evaluation information.
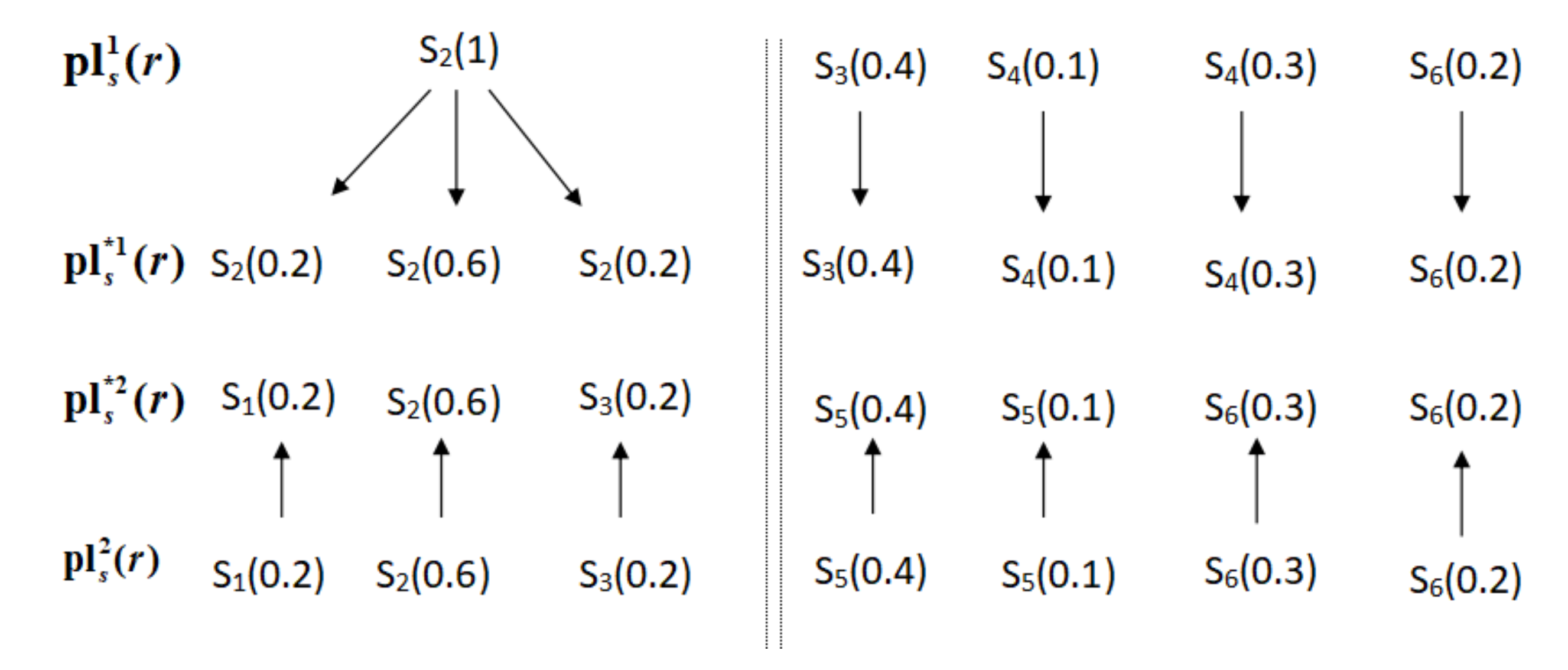
Example 2. Let , and be two PLQRONs, the adjusted PLQRONs are , and , respectively. The adjustment process is shown in Figure 1. 3.2. Some Properties for PLQRONs
Firstly, we apply the adjustment method to adjust the probabilistic linguistic terms with same probability, which can overcome the defects that may occur in process of aggregation. Then, we propose the operation rules of the adjusted PLQRONs, and their properties.
Definition 7. Let be a LTS, and are two adjusted PLQRONs, where are the subscript of , the operational laws of the PLQRONs can be expressed as follows:
- (a)
;
- (b)
;
- (c)
;
- (d)
;
- (e)
.
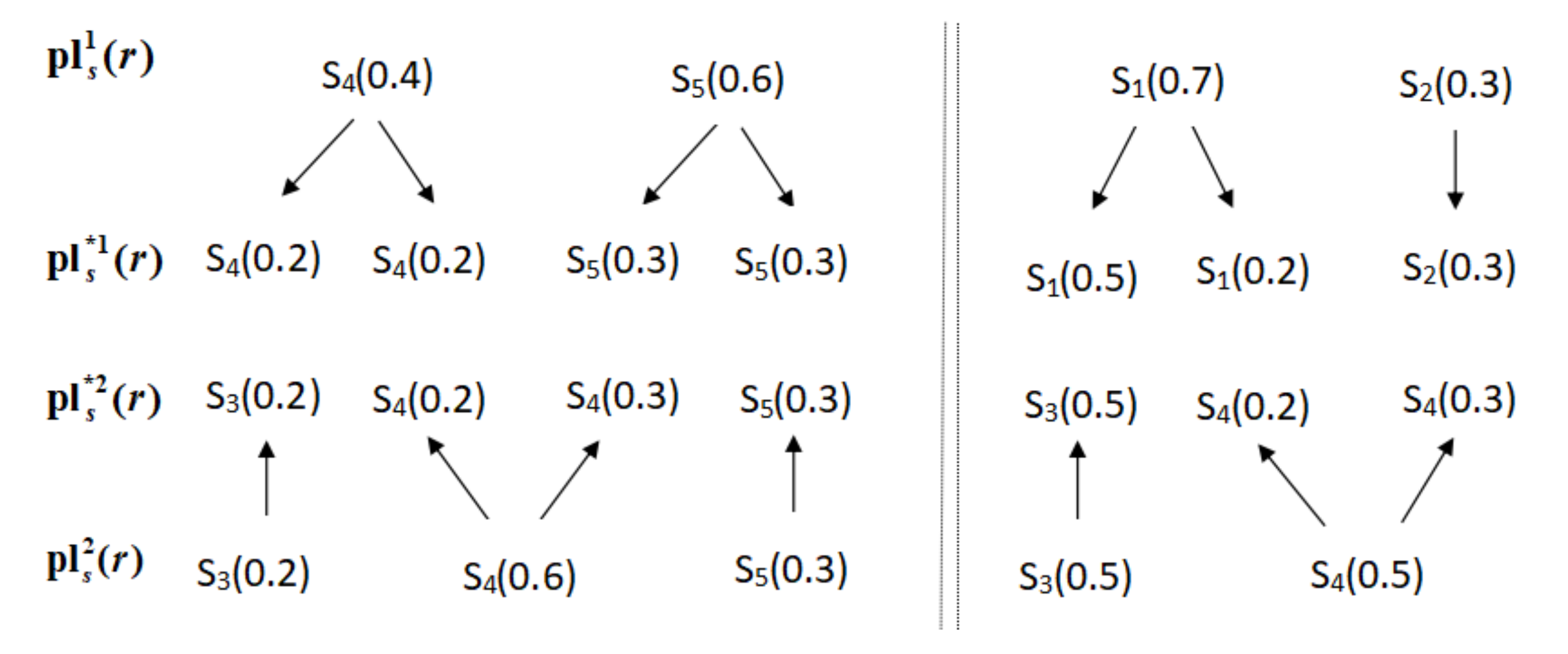
Example 3. Let , and be two PLQRONs, the modified PLQRONs are and , The adjustment process is shown in Figure 2. Let and , then we have Theorem 1. Let and , be any two adjusted PLQRONs, , then
- (1)
;
- (2)
;
- (3)
;
- (4)
;
- (5)
;
- (6)
.
Here we prove the property (1) and (3), other properties proof process are similar, we omit them.
- (1)
Therefore is obtained.
- (3)
By Definition 7, we can get
Moreover, since
let
and
, the above formulas can be denoted as:
Therefore is proved.
In order to compare the order relation of PLQROSs, we present the comparison rules as follows:
Definition 8. Assume be a LTS, for any adjusted PLQRON , , where , the score function of iswhere , and represent the number of elements in the corresponding set, respectively. The accuracy function of
is
where
,
and
represent the number of elements in the corresponding set, respectively.
Theorem 2. Let and , be two adjusted PLQRONs. and are the score function of and , the accuracy function of and are and , respectively, then the order relation of and are given as follows:
- (1)
If , then ;
- (2)
If , then
- (a)
If , then ;
- (b)
If , then ;
- (c)
If , then ;
- (3)
If , then .
3.3. The Aggregation Operators of PLQROSs
In order to aggregate the multi-attribute information well, we introduce the aggregation operators of PLQRONs as follows.
Definition 9. Let be a LTS, are n adjusted PLQRONs, where , the probabilistic linguistic q-rung orthopair weighted averaging (PLQROWA) operator can be expressed as:where is the weight vector, and it satisfies . Theorem 3. Let ; be ι adjusted PLQRONs, the weight satisfies with and , then the properties of PLQROWA are shown as follows:
- (1)
Idempotency: if are equal, i.e., , then - (2)
Monotonicity: let and be two collections of adjusted PLQRONs, for all ι, and , then - (3)
Boundedness: let , , and , then
- (1)
For all
, since
, then
Therefore is proved.
- (2)
For all
,
and
, then we have
Assume
and
,
, by (
1), we can get
Then we have , that is .
Therefore , is proved.
- (3)
For all
,
, according to the properties (1) and (2), we can easily have
Remark 2. Especially, when , the PLQROWA operator is reduced to a probabilistic linguistic q-rung orthopair averaging (PLQROA) operator: Definition 10. Let be a LTS, is a collection of adjusted PLQRONs, where , the probabilistic linguistic q-rung orthopair weighted geometric (PLQROWG) operator is given as follows:where is the weight vector and satisfies with . Theorem 4. The PLQROWG operator satisfies the properties in Theorem 3.
Proof. Because the proof is similar to Theorem 3, we omit it here. □
Remark 3. Especially, when , the PLQROWG operator is degenerated into the probabilistic linguistic q-rung orthopair geometric (PLQROG) operator Example 4. Let be a LTS, , and , be three PLQRONs, is the corresponding weight vector, then the calculation results of the PLQROWA and the PLQROWG are given as follows.
Firstly, we adjust the corresponding probability distributions of
and
, the adjusted PLQRONs obtained as follows:
If
, according to the Formula (
3), we can get
If
, according to the Formula (
4), we can get
3.4. Distance Measures between PLQRONs
In order to compare the differences between different alternatives, we introduced the distance measure between PLQRONs, which is an important tool to process multi-attribute decision problems. In this subsection, we first propose the distance measures between PLQRONs.
Definition 11. Let be a LTS, , and are two adjusted PLQRONs, where , the Hamming distance measure between and can be defined as:where , and are the subscripts of and , and represent the number of elements in and , respectively. The Euclidean distance measure
between
and
can be defined as follows:
where
,
and
are the subscripts of
and
,
and
represent the number of elements in
and
, respectively.
The generalized distance measure
between
and
can be defined as:
where
,
,
and
are the subscripts of
and
,
and
represent the number of elements in
and
, respectively.
Remark 4. In particular, if or , is degenerated into or , respectively.
Theorem 5. Assume and are two adjusted PLQRONs, the distance measure satisfies the following properties:
- (1)
Non-negativity: ;
- (2)
Symmetry: ;
- (3)
Triangle inequality: , .
Obviously, satisfies the property (1) and (2). The symmetry information can be expressed by the distance measure .
The proof of property (3) is given as follows:
Therefore is proved.
Example 5. Assume is a LTS, , and , are two adjusted PLQRONs. If , the calculation result of , is given as follows: If , we can get . If , we can get .
4. The Behavioral Decision Method
Since Hwang and Yoon [
16] proposed the TOPSIS method, it has been widely applied in solving multiple criteria group decision making (MCGDM) problems. The traditional TOPSIS [
17,
18] method is an effective method in ranking the alternative. However, in practical decision making problems, the conditions in traditional TOPSIS method does not consider the behavior factors of decision makers. Thus, Yoon and Kim [
23] introduced a behavioral TOPSIS method, which consider the behavioral tendency of decision makers and incorporate it into traditional TOPSIS method. However, in the uncertain decision making environment, how to represent the decision maker’s behavior factors is a difficult problem. In order to solve this problem, we deal with it as follows. The gain can be viewed as the earns from taking the alternative instead of the anti-ideal solution, and the loss can be considered as the decision maker’s pays from taking the alternative instead of the ideal solution, they can be expressed by the distance measure of related uncertain sets. So the behavioral TOPSIS method contains the loss aversion of decision maker in behavioral economics, and the decision maker can select the appropriate loss aversion ratio to express his/her choice preference. The method is proved to give a better choice than other methods (including traditional TOPSIS method) particularly in many fields, such as emergency decision making, selection for oil pipeline routes, etc., because the behavioral TOPSIS method precisely reflects the behavior tendency of decision maker.
Assume a group of experts
evaluate a series of alternatives
under the criteria
, let
be a continuous LTS, the evaluation of experts are represented in the form of PLQRONs
, where
;
and
;
,
. The criteria’s weight vector are
, where
, the experts’ weight vector are
, then the wth expert’s decision matrix
can be given as follows:
where are PLQRONs.The steps of decision making are given as follows:
Step 1. Apply the adjustment method to adjust the probability distribution of PLQRONs, the adjusted decision matrix of the wth expert can be denoted as .
Step 2. Apply the PLQROWA operator or PLQROWG operator to obtain the aggregated decision matrix . Furthermore, normalize the aggregated decision matrix based on the type of criteria. If it is a benefit-type criterion, there is no need to adjust; if it is a cost-type criterion, we need utilize the negation operator to normalize the decision matrix.
Step 3. Determine the ideal solution
and the anti-ideal solution
, respectively, where
For the criterion
, we apply the Formulas (
1) and (
2) to calculate
and
.
Step 4. Utilize to calculate the distance between each alternative and , , respectively. That is and , where , and .
Step 5. Calculate the value function
for alternative
.
where γ is the decision maker’s loss aversion ratio, if
, it implies the decision maker’s behavior is more sensitive to losses than gains; if
, it implies the decision maker have neutral attitude towards losses or gains; if
, it means the decision maker’s behavior is more sensitive to gains than losses;
and β reflects the decision maker’s risk aversion attitudes and the risk seeking attitudes in decision process, respectively.
Step 6. The greater value of , the better alternatives will be, then we can obtain the rank of the alternatives.
5. Numerical Example
Here we present a practical multiple criteria group decision making example about investment decision (Beg et al. [
27]), and the behavioral TOPSIS method is utilized to deal with this problem. The advantages of the behavioral TOPSIS method with PLQROSs are highlighted by the comparison analysis with the traditional TOPSIS method. Furthermore, we analyzed the stability and sensitivity of decision makers’ behavior.
5.1. Background
There are three investors
and
, who want to invest the following three types of projects: real estate (
), the stock market (
) and treasury bills (
). In order to decide which project to invest, they consider from the following attributes: the risk factor (
), the growth factor (
), the return rate (
) and the complexity of the document requirements (
). The weight vector of investors is
and the criteria’s weight vector is
. The evaluation for the criterion
is LTS
, for the criteria
is
; and the evaluation for criterion
is LTS
. Then, the decision matrices of each experts are expressed in
Table 1,
Table 2 and
Table 3.
Where represents the wth investor’s evaluation information.
5.2. The Behavioral TOPSIS Method
Step 1. According to the adjustment method, we adjust the probability distribution of decision matrices
,
and
, and the corresponding adjusted matrices
,
and
are given in
Table 4,
Table 5 and
Table 6.
Step 2. Firstly, we aggregate the adjusted decision matrices based on the PLQROWA operator. Then we normalize the aggregated matrix according to the type of criteria (criteria
and
belong to the benefit-type criteria, criterion
,
belongs to the cost-type criteria). If
, we can get the normalized decision matrix
in
Table 7.
Step 3. According to Definition 8, the score function matrix can be obtained as follows:
Furthermore, we can obtain the ideal solution as follows:
The anti-ideal solution is given as follows:
Step 4. Calculate an , respectively.
If
, here we apply that the Euclidean distance measure
, then
and
. So the separation measures between the alternative and the ideal/anti-ideal solution are obtained in
Table 8.
Step 5. Calculate the value function
about alternatives
. Here the parameters
and γ are used to describe the decision maker’s behavior tendency. Here we assume
[
28], then we have
,
,
.
Step 6. According to the values of , we have , so is the best alternative.
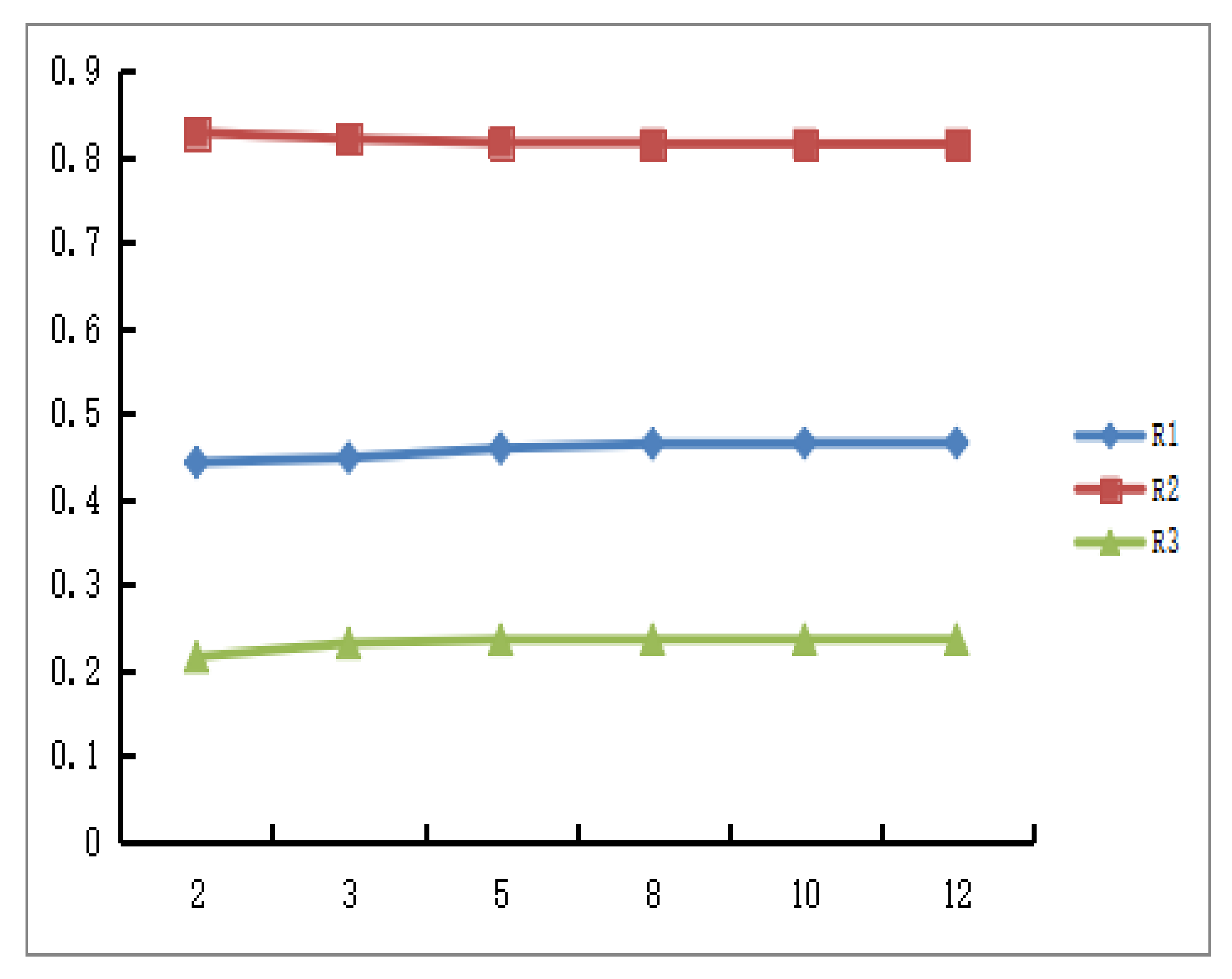
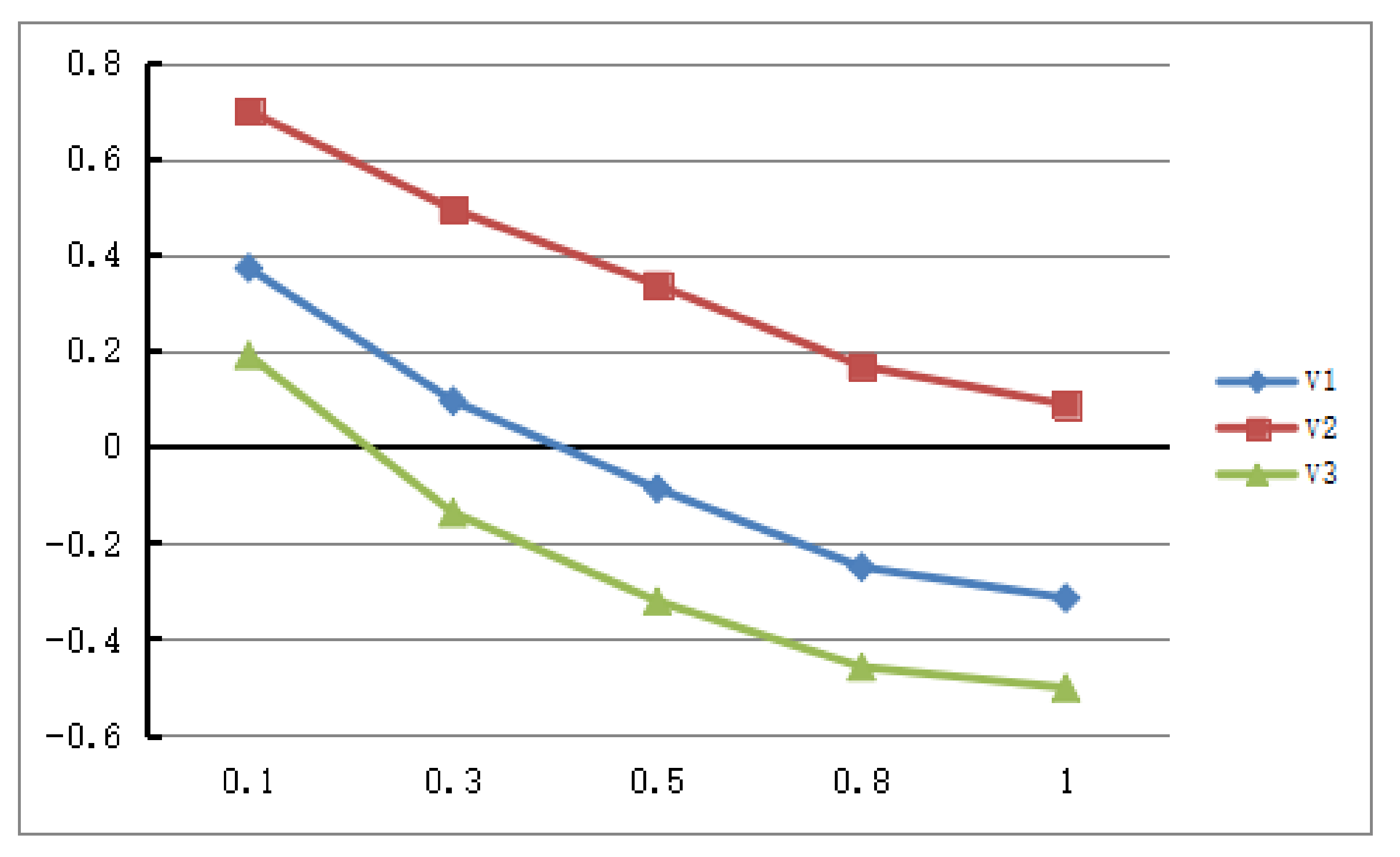
Next, we consider the relationship between the decision conclusion and the change of parameter λ. We still take the PLQROWA operator as an example. Assume
,
, and
, respectively. The
Figure 3 shows the corresponding ranking results (
Table 9 shows the detailed calculation results). Obviously, the varies of value function
is not sensitive to the parameter λ, which indicates that the parameter λ has little effect on the decision results.
5.3. Comparison Analysis with Existed Method
Here, the traditional TOPSIS method is used to compare with the behavioral TOPSIS method, the algorithm steps [
29] are given as follow.
Step 1. Adjust the probability distribution of PLQRONs, the corresponding matrices , and are obtained.
Step 2. Apply the PLQROWA operator to aggregate the evaluation information, then we normalize the aggregated decision matrix; the result is same as
Section 5.2.
Step 3. Similarly, we can obtain the positive ideal solution
as follows:
The anti-ideal solution
is also obtained as follows:
Step 4. If
, we apply
to calculate the distance of each alternative between
and
, the results are obtained in
Table 10.
Step 5. Calculate the closeness coefficient
,
By calculation, we get , and . So the ranking order of the alternatives is . The decision result is same as behavioral TOPSIS method, which shows the proposed method is effective.
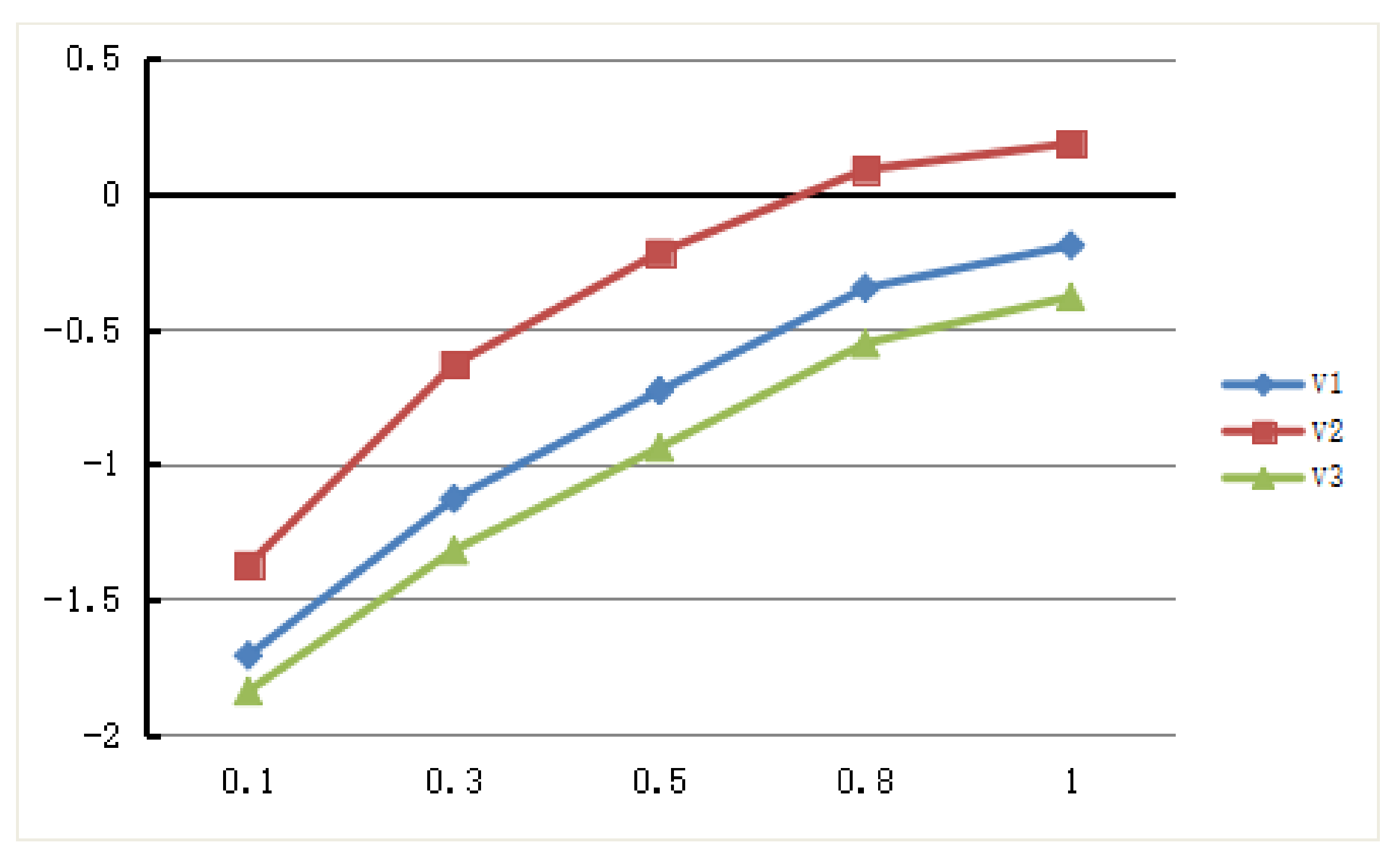
Similarly, we consider the relationship between the decision result and the change of λ based on the traditional TOPSIS method. Here
and
, the parameter
, we apply the PLQROWA operator to calculate the closeness coefficient
of each alternative,
Figure 4 shows the ranking results (
Table 11 shows the detailed calculation results). As can be seen from
Figure 4, the closeness coefficient
remains unchanged and the decision result is also tend to stable.
5.4. The Sensitivity of Decision Maker’s Behavior
Here, we make the analysis of the influence of loss aversion parameter γ, the risk preference parameter α and β in the proposed behavioral TOPSIS method.
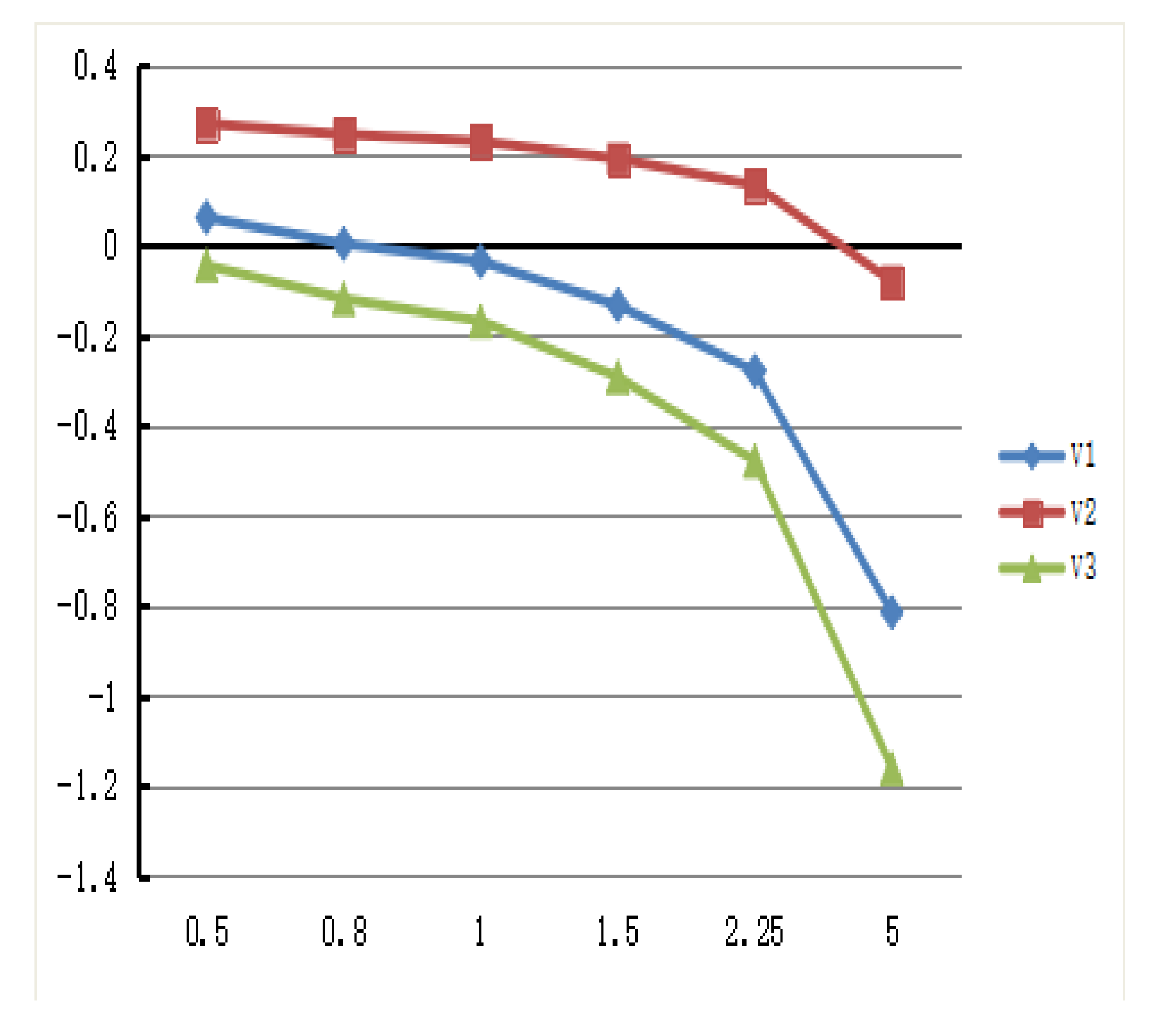
Firstly, the impact of the loss aversion parameter
γ in the value function is considered. We take the PLQROWA operator as an example, if
and
, let
, the ranking results of the value function
are shown in
Figure 5 (
Table 12 shows the detailed calculation results). As can be seen from
Figure 5, when
, the values of
,
and
are less sensitive to the change of the loss aversion parameter
γ; while
, the values of
is changing obviously. In comparison, the loss aversion parameter
γ has a significant influence on
and
. When
, the values of
decrease sharply at the same time, which means if the parameter
γ becomes larger, the loss aversion has a greater impact on the value function
.
Next, we consider the influence of the risk preference parameters
α and
β in the value function, respectively. We take the PLQROWA operator as an example, suppose that
and
, let
, the results of value functions change with the parameter
α are shown in
Figure 6. It is easy to know that the values of the function
descend with the parameter
α. We know
is always the best alternative from the
Figure 6. If
, the values of
also tend to stable.
Furthermore, assume that
and
, let
, the results of value functions change with the parameter
β are shown in
Figure 7. Similarly, we know that the values of
increase with the parameter
β, and the best alternative remains unchanged. If
, the values of
tend to stable. In conclusion, the change of value function
is consistent with expert’s risk preference, if the expert is risk averse, the parameter
α increases, he/she is more sensitive to the loss, and the overall value functions are decreasing. If the decision maker is risk appetite, when the parameter
β increases, he/she becomes more sensitive to gains, the overall value functions are increasing.
According to the above comparison analyses, we can find that the proposed method has the following advantages. First, the behavioral TOPSIS method implements the decision maker’s choice by adopting the gain and loss. Second, it has been demonstrated that the traditional TOPSIS method is a special case of the proposed behavioral TOPSIS method [
23], while the behavioral TOPSIS method involves a wider range of situations. In addition, there are three parameters (
α,
β and
γ) in the value function of
, the decision maker can choose the appropriate numerical value according to his/her risk preference and loss aversion, which makes the proposed behavioral TOPSIS method more flexible in practical application.
6. Conclusions
The main conclusions of the paper are given as follows:
- (1)
The operations of PLQROS are proposed based on the adjusted PLQROS with the same probability. Then we present the PLQROWA operator, PLQROWG operator and the distance measures between the PLQROSs based on the proposed operational laws.
- (2)
We develop the fuzzy behavior TOPSIS method to PLQROS, which consider the behavioral tendency in decision making process.
- (3)
We utilize a numerical example to demonstrate the validity and feasibility of the fuzzy behavior TOPSIS method, and we prove the superiority of the method by comparison with the traditional TOPSIS method.
Next, we will apply the proposed method to deal with the multi-attribute decision making problems, such as the emergency decision, supplier selection and investment decision, etc.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}