
A Self-Adaptive Reinforcement-Exploration Q-Learning Algorithm

 ,
,
Abstract
:1. Introduction
2. Markov Process
2.1. Markov Reward Process (MRP)
2.2. Markov Decision-Making Process
3. Self-Adaptive Reinforcement-Exploration Q-Learning Algorithm
3.1. Q-Learning Algorithm
3.2. Adaptive Reinforcement-Exploration Strategy Design
3.2.1. Behavior Utility Trace
3.2.2. Adaptive Reinforcement-Exploration Strategy
- Introduction of the behavior utility trace to improve the probability for different actions to be chosen and to enhance the effectiveness of exploration action.
- Real-time adjustment of exploration factor in different phases until it meets the objective needs.
- Adaptive adjustment of the exploration factor of the present action according to the number of access times of the state.
3.3. Design of Reward and Penalty Functions
3.4. Algorithm Implementation
| Algorithm 1 SARE-Q algorithm. |
| Initialization: The following are initialized: The minimum exploration factor , the maximum number of iterative episodes , the maximum step size of single episode , learning rate , reward attenuation factor , utility trace attenuation factor , exploration incentive value , self-adaptive exploration factor , utilization factor of the success rate, and utilization factors and of access times. The terminal state set is set. For each state , , and the initial value of Q-Table is randomly set. The T-Table of state access times is initialized, so is the behavior utility trace table, namely, E-Table. Loop iteration (for : Initialize the initial state Update the basic exploration factor Cycle (for ): Update the exploration factor in this episode Choose an action according to the self-adaptive reinforcement-exploration strategy and Q-Table Execute the action , and acquire the instant reward and the state at the next time Update Q-Table, T-Table and E-Table Until reaching the terminal state s or the maximum step size of single episode Until reaching the maximum number of iterative episodes |
4. Simulation Experiment and Results Analysis
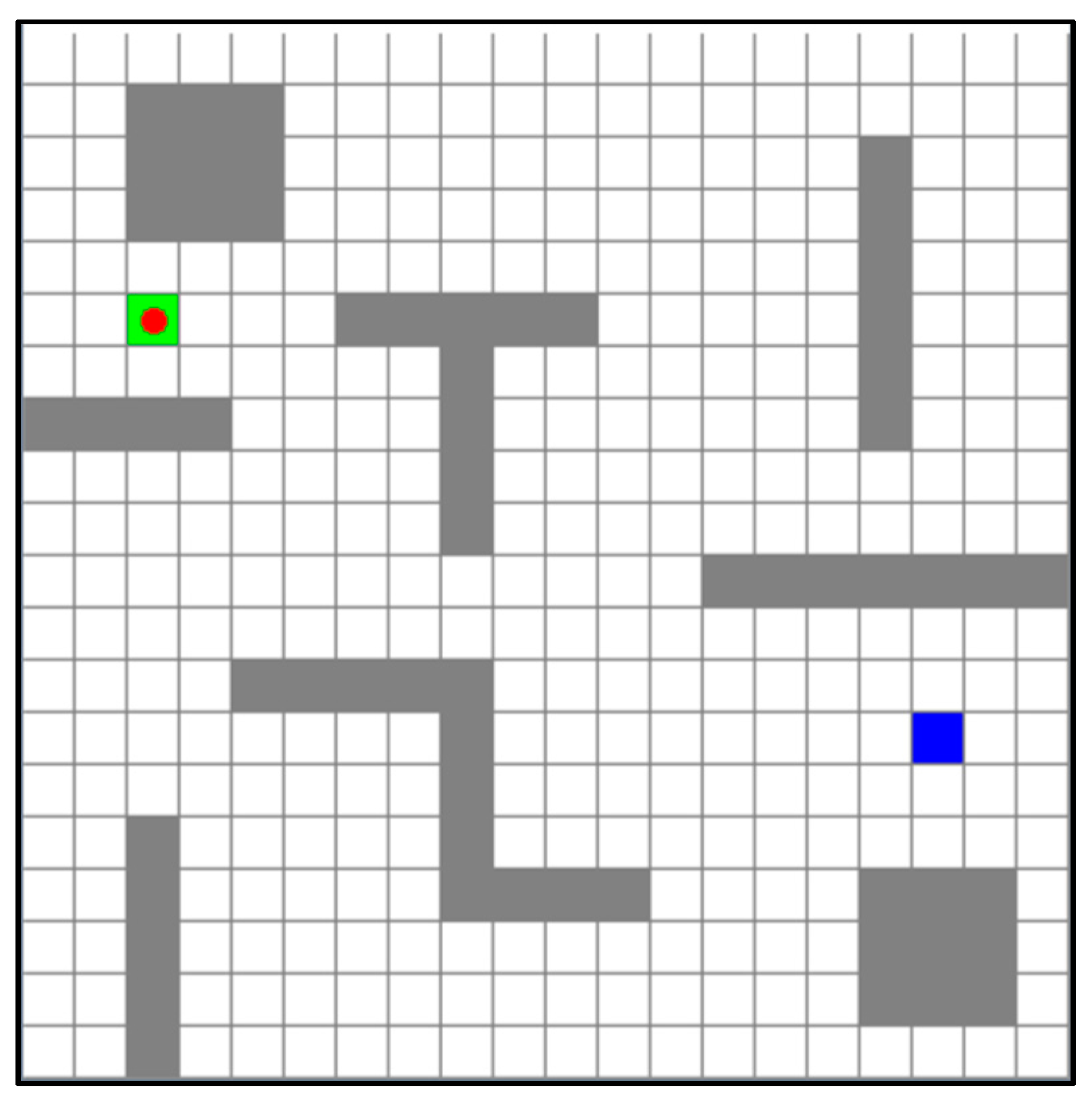
4.1. Simulation Experimental Environment and Parameter Setting
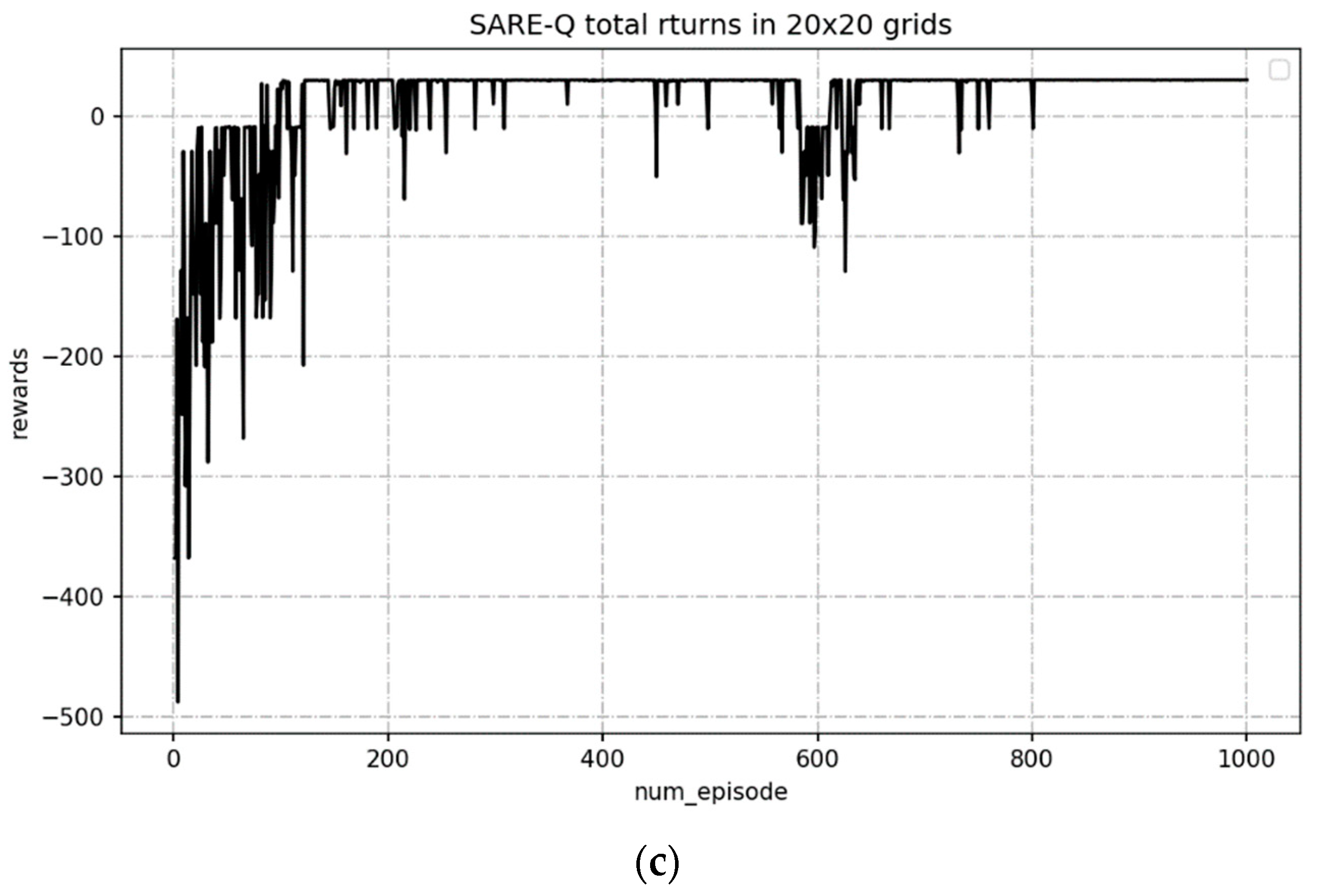
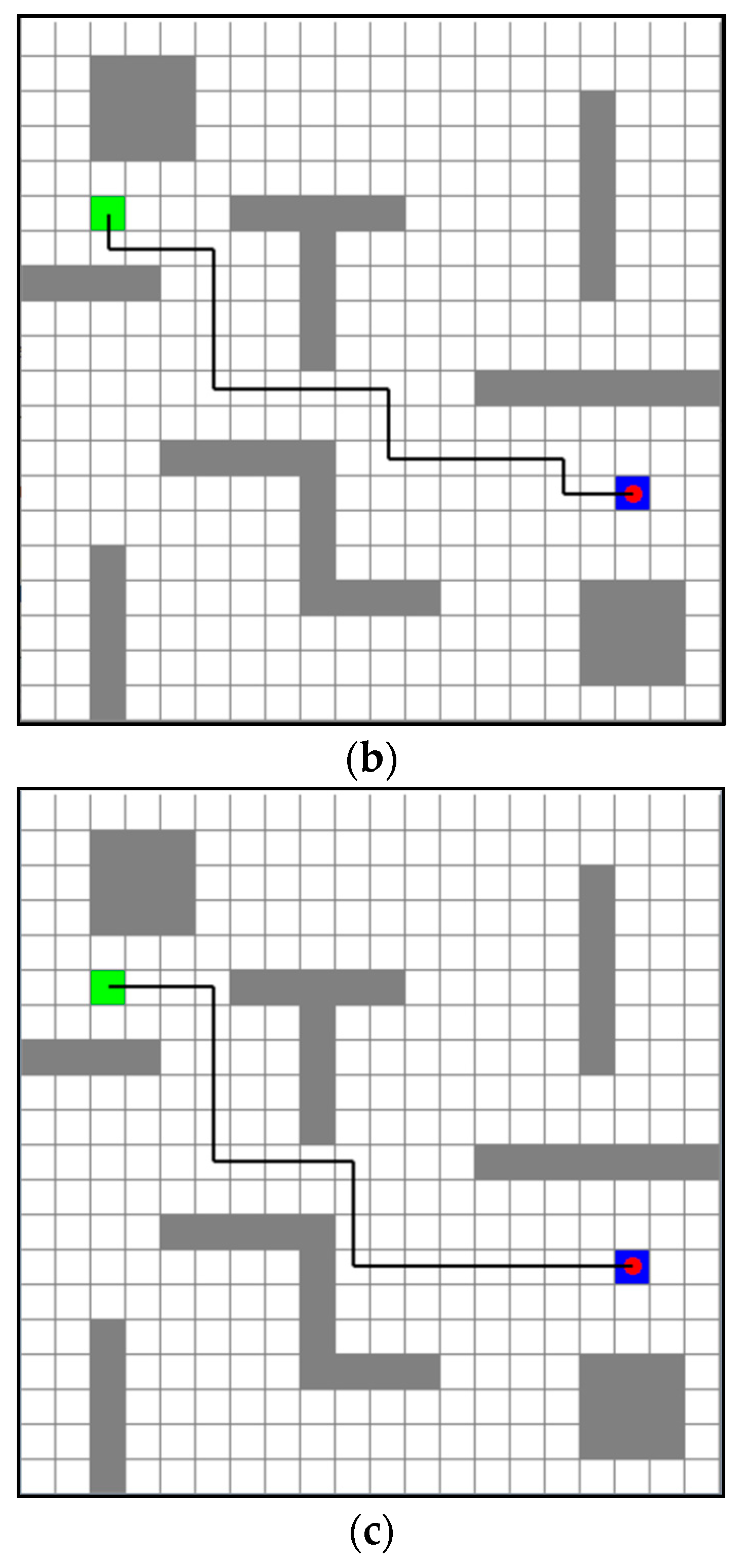
4.2. Simulation Experiment and Result Analysis
5. Conclusions
- The problems existing in the Q-Learning algorithm were studied, the behavior utility trace was introduced into the Q-Learning algorithm, and the self-adaptive dynamic exploration factor was combined to put forward a reinforcement-exploration strategy, which substituted the exploration strategy of the traditional Q-Learning algorithm. The simulation experiments of route planning manifest that the SARE-Q algorithm shows advantages, to different extents, over the traditional Q-Learning algorithm and the algorithms proposed in other references in the following aspects: average number of turning times, average inside success rate, average step size, number of times with the shortest planning route, optimal number of turning times of route, etc.
- Though being of a certain complexity, the random environment given in this study is obviously too simple compared with the actual environment. Therefore, the algorithms should be explored under the environment with dynamic obstacles and dynamic target positions in the future. Meanwhile, the algorithm was verified only through the simulation experiments, so the corresponding actual system should be established for the further verification. In addition, the SARE-Q algorithm proposed in this study remains to be further optimized in the aspect of parameter selection. How to optimize the related parameters through intelligent algorithms is the follow-up research content.
- Restricted by the action space and sample space, the traditional RL algorithm is inapplicable to actual scenarios with very large state space and continuous action space. With the integration of deep learning and RL, the deep RL method will overcome the deficiencies of the traditional RL method by virtue of the powerful character representation ability of deep learning technology. The subsequent research content lies in studying the deep RL method and verifying it in the route planning.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, X.M.; Bai, T.; Gao, Y.B.; Han, Y. Vision-Based Robot Navigation through Combining Unsupervised Learning and Hierarchical Reinforcement Learning. Sensors 2019, 19, 1576. [Google Scholar] [CrossRef] [Green Version]
- Miorelli, R.; Kulakovskyi, A.; Chapuis, B.; D’Almeida, O.; Mesnil, O. Supervised learning strategy for classification and regression tasks applied to aeronautical structural health monitoring problems. Ultrasonics 2021, 113, 106372. [Google Scholar] [CrossRef]
- Faroughi, A.; Morichetta, A.; Vassio, L.; Figueiredo, F.; Mellia, M.; Javidan, R. Towards website domain name classification using graph based semi-supervised learning. Comput. Netw. 2021, 188, 107865. [Google Scholar] [CrossRef]
- Zeng, J.J.; Qin, L.; Hu, Y.; Yin, Q. Combining Subgoal Graphs with Reinforcement Learning to Build a Rational Pathfinder. Appl. Sci. 2019, 9, 323. [Google Scholar] [CrossRef] [Green Version]
- Zeng, F.Y.; Wang, C.; Ge, S.S. A Survey on Visual Navigation for Artificial Agents with Deep Reinforcement Learning. IEEE Access 2020, 8, 135426–135442. [Google Scholar] [CrossRef]
- Li, R.Y.; Peng, H.M.; Li, R.G.; Zhao, K. Overview on Algorithms and Applications for Reinforcement Learning. Comput. Syst. Appl. 2020, 29, 13–25. [Google Scholar] [CrossRef]
- Luan, P.G.; Thinh, N.T. Hybrid genetic algorithm based smooth global-path planning for a mobile robot. Mech. Based Des. Struct. Mach. 2021, 2021, 1–17. [Google Scholar] [CrossRef]
- Mao, G.J.; Gu, S.M. An Improved Q-Learning Algorithm and Its Application in Path Planning. J. Taiyuan Univ. Technol. 2021, 52, 91–97. [Google Scholar] [CrossRef]
- Neves, M.; Vieira, M.; Neto, P. A study on a Q-Learning algorithm application to a manufacturing assembly problem. J. Manuf. Syst. 2021, 59, 426–440. [Google Scholar] [CrossRef]
- Han, X.C.; Yu, S.P.; Yuan, Z.M.; Cheng, L.J. High-speed railway dynamic scheduling based on Q-Learning method. Control Theory Appl. 2021. Available online: https://kns.cnki.net/kcms/detail/44.1240.TP.20210330.1333.042.html (accessed on 31 March 2021).
- Qiao, J.F.; Hou, Z.J.; Ruan, X.G. Neural network-based reinforcement learning applied to obstacle avoidance. J. Tsinghua Univ. Sci. Technol. 2008, 48, 1747–1750. [Google Scholar] [CrossRef]
- Song, Y.; Li, Y.B.; Li, C.H. Initialization in reinforcement learning for mobile robots path planning. Control Theory Appl. 2012, 29, 1623–1628. [Google Scholar]
- Zhao, Y.N. Research of Path Planning Problem Based on Reinforcement Learning. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2017. [Google Scholar]
- Zeng, J.J.; Liang, Z.H. Research of path planning based on the supervised reinforcement learning. Comput. Appl. Softw. 2018, 35, 185–188. [Google Scholar]
- da Silva, A.G.; dos Santos, D.H.; de Negreiros, A.P.F.; Silva, J.M.; Gonçalves, L.M.G. High-Level Path Planning for an Autonomous Sailboat Robot Using Q-Learning. Sensors 2020, 20, 1550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Low, E.S.; Ong, P.; Cheah, K.C. Solving the optimal path planning of a mobile robot using improved Q-learning. Robot. Auton. Syst. 2019, 115, 143–161. [Google Scholar] [CrossRef]
- Park, J.H.; Lee, K.H. Computational Design of Modular Robots Based on Genetic Algorithm and Reinforcement Learning. Symmetry 2021, 13, 471. [Google Scholar] [CrossRef]
- Li, B.H.; Wu, Y.J. Path Planning for UAV Ground Target Tracking via Deep Reinforcement Learning. IEEE Access 2020, 8, 29064–29074. [Google Scholar] [CrossRef]
- Yan, J.J.; Zhang, Q.S.; Hu, X.P. Review of Path Planning Techniques Based on Reinforcement Learning. Comput. Eng. 2021. [Google Scholar] [CrossRef]
- Seo, K.; Yang, J. Differentially Private Actor and Its Eligibility Trace. Electronics 2020, 9, 1486. [Google Scholar] [CrossRef]
- Qin, Z.H.; Li, N.; Liu, X.T.; Liu, X.L.; Tong, Q.; Liu, X.H. Overview of Research on Model-free Reinforcement Learning. Comput. Sci. 2021, 48, 180–187. [Google Scholar]
- Li, T. Research of Path Planning Algorithm based on Reinforcement Learning. Master’s Thesis, Jilin University, Changchun, China, 2020. [Google Scholar]
- Li, T.; Li, Y. A Novel Path Planning Algorithm Based on Q-learning and Adaptive Exploration Strategy. In Proceedings of the 2019 Scientific Conference on Network, Power Systems and Computing (NPSC 2019), Guilin, China, 16–17 November 2019; pp. 105–108. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Indexes | Q-Learning Algorithm | SA-Q Algorithm | SARE-Q Algorithm |
|---|---|---|---|
| Average operating time (s) | 2.047 | 1.739 | 1.995 |
| Average number of turning times (times) | 9.16 | 10.22 | 7.6 |
| Average success rate (%) | 30.2 | 49.7 | 66 |
| Average step size (step) | 23.38 | 24.44 | 23.16 |
| Number of times with the shortest route (times) | 83 | 88 | 92 |
| Number of turning times of the optimal route (times) | 6 | 7 | 4 |
| Evaluation Indexes | Q-Learning Algorithm | SA-Q Algorithm | SARE-Q Algorithm |
|---|---|---|---|
| Average operating time (s) | 1.43 | 1.034 | 1.147 |
| Average number of turning times(times) | 9.67 | 10.32 | 8.33 |
| Average success rate (%) | 41.9 | 71.5 | 85.5 |
| Average step size (step) | 24.24 | 24.16 | 24.04 |
| Number of times with the shortest route (times) | 89 | 93 | 98 |
| Number of turning times of the optimal route (times) | 9 | 9 | 7 |
| Evaluation Indexes | Q-Learning Algorithm | SA-Q Algorithm | SARE-Q Algorithm |
|---|---|---|---|
| Average operating time (s) | 0.819 | 0.629 | 0.79 |
| Average number of turning times(times) | 7.19 | 7.13 | 6.1 |
| Average success rate (%) | 58.4 | 70.4 | 75.2 |
| Average step size (step) | 18.1 | 18.81 | 18 |
| Number of times with the shortest route (times) | 94 | 99 | 100 |
| Number of turning times of the optimal route (times) | 5 | 5 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Tang, L.; Zhang, S.; Wang, Z.; Shen, X.; Zhang, Z. A Self-Adaptive Reinforcement-Exploration Q-Learning Algorithm. Symmetry 2021, 13, 1057. https://doi.org/10.3390/sym13061057
Zhang L, Tang L, Zhang S, Wang Z, Shen X, Zhang Z. A Self-Adaptive Reinforcement-Exploration Q-Learning Algorithm. Symmetry. 2021; 13(6):1057. https://doi.org/10.3390/sym13061057
Chicago/Turabian StyleZhang, Lieping, Liu Tang, Shenglan Zhang, Zhengzhong Wang, Xianhao Shen, and Zuqiong Zhang. 2021. "A Self-Adaptive Reinforcement-Exploration Q-Learning Algorithm" Symmetry 13, no. 6: 1057. https://doi.org/10.3390/sym13061057