
Ensemble Empirical Mode Decomposition with Adaptive Noise with Convolution Based Gated Recurrent Neural Network: A New Deep Learning Model for South Asian High Intensity Forecasting


Abstract
:1. Introduction
1.1. Research Background
1.2. Related Works
1.3. Research Significance
2. Data and Method
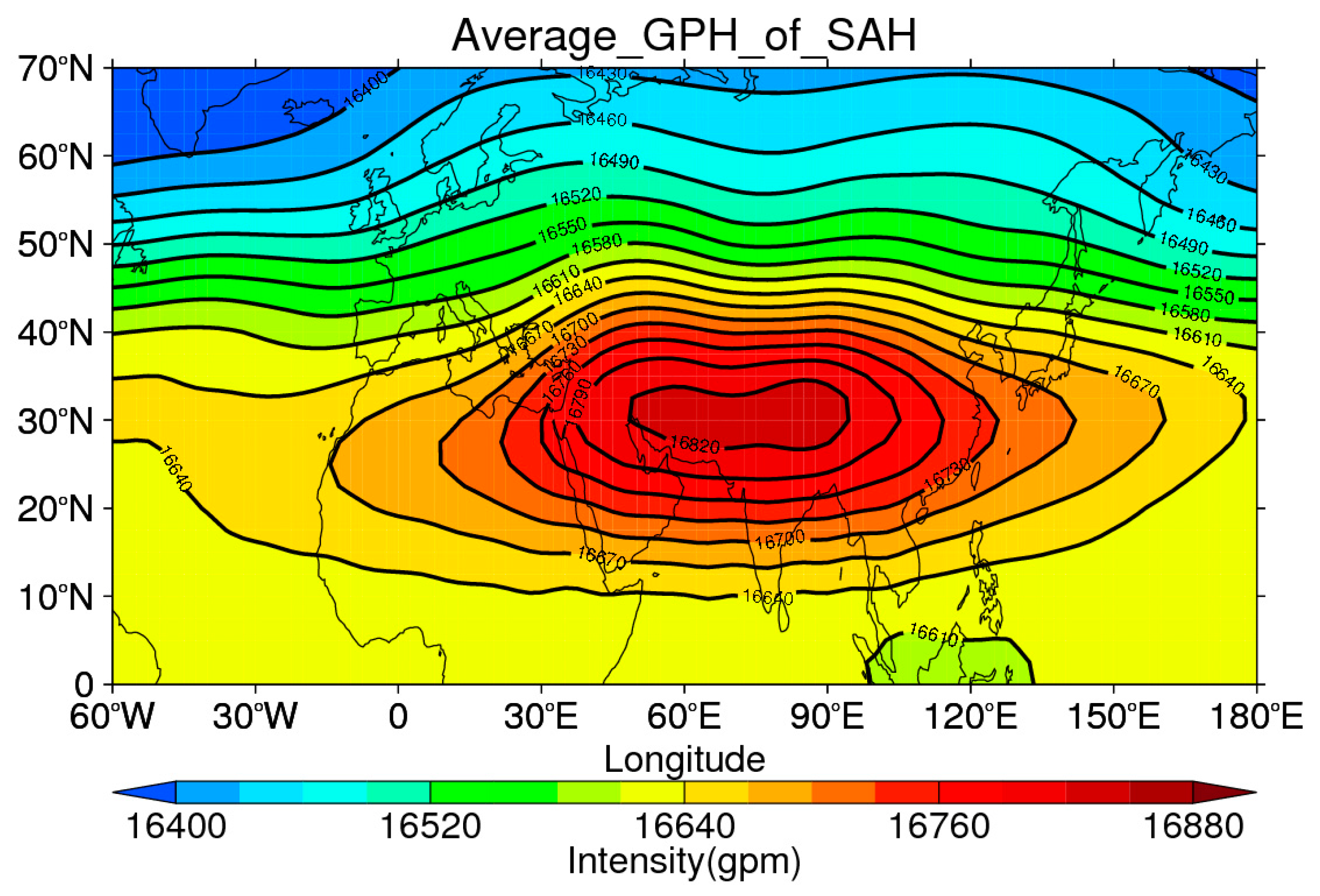
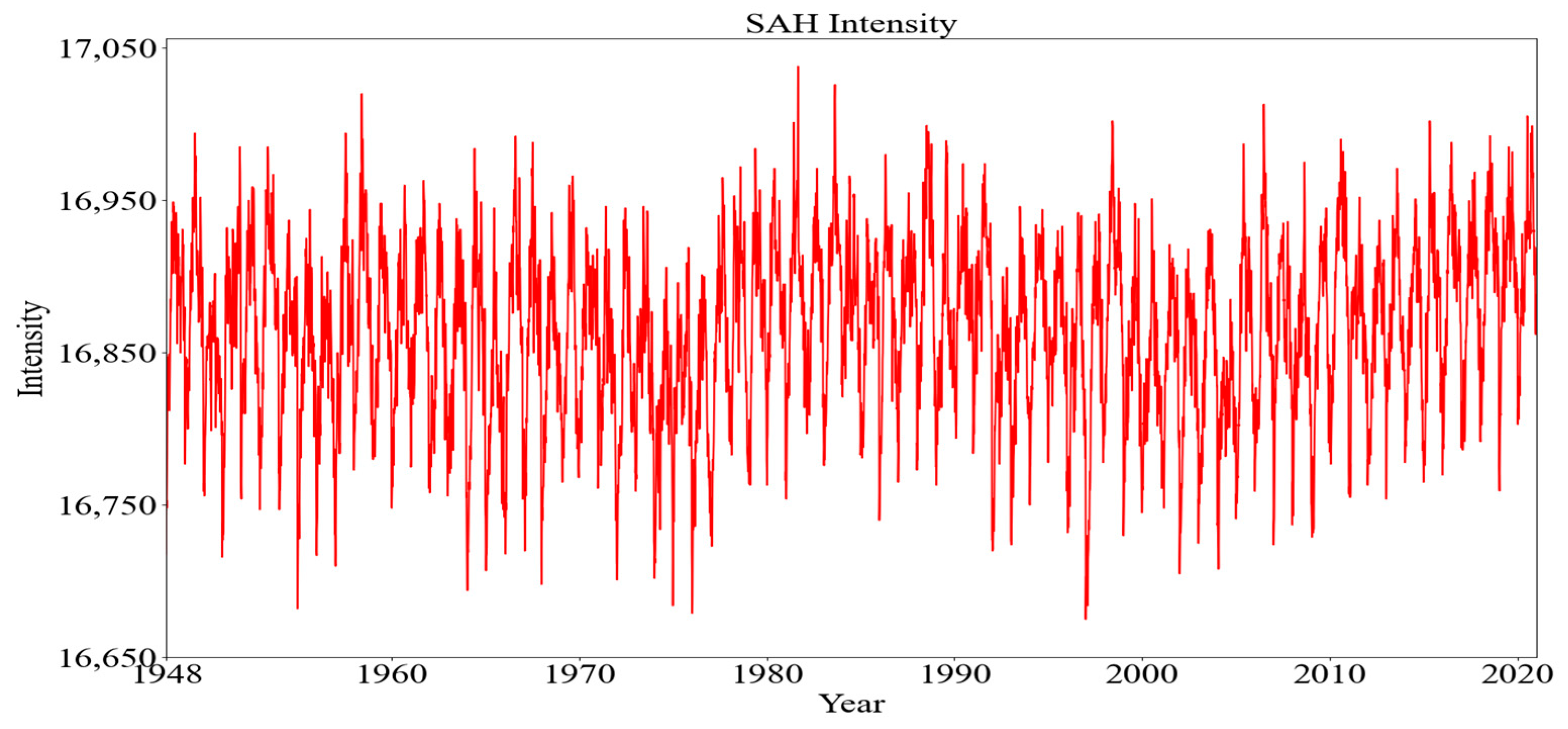
2.1. Data Description
2.2. Model and Methods
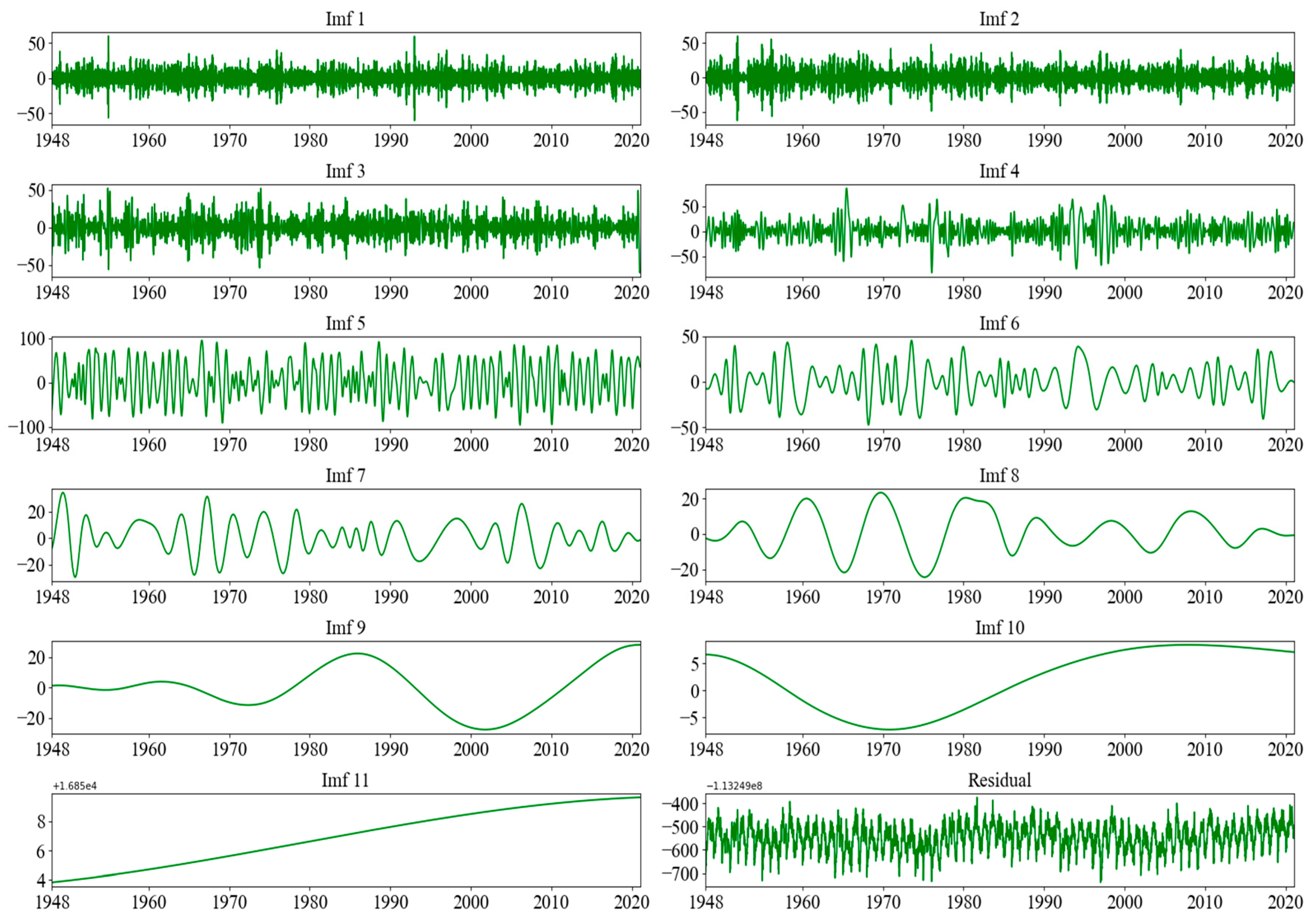
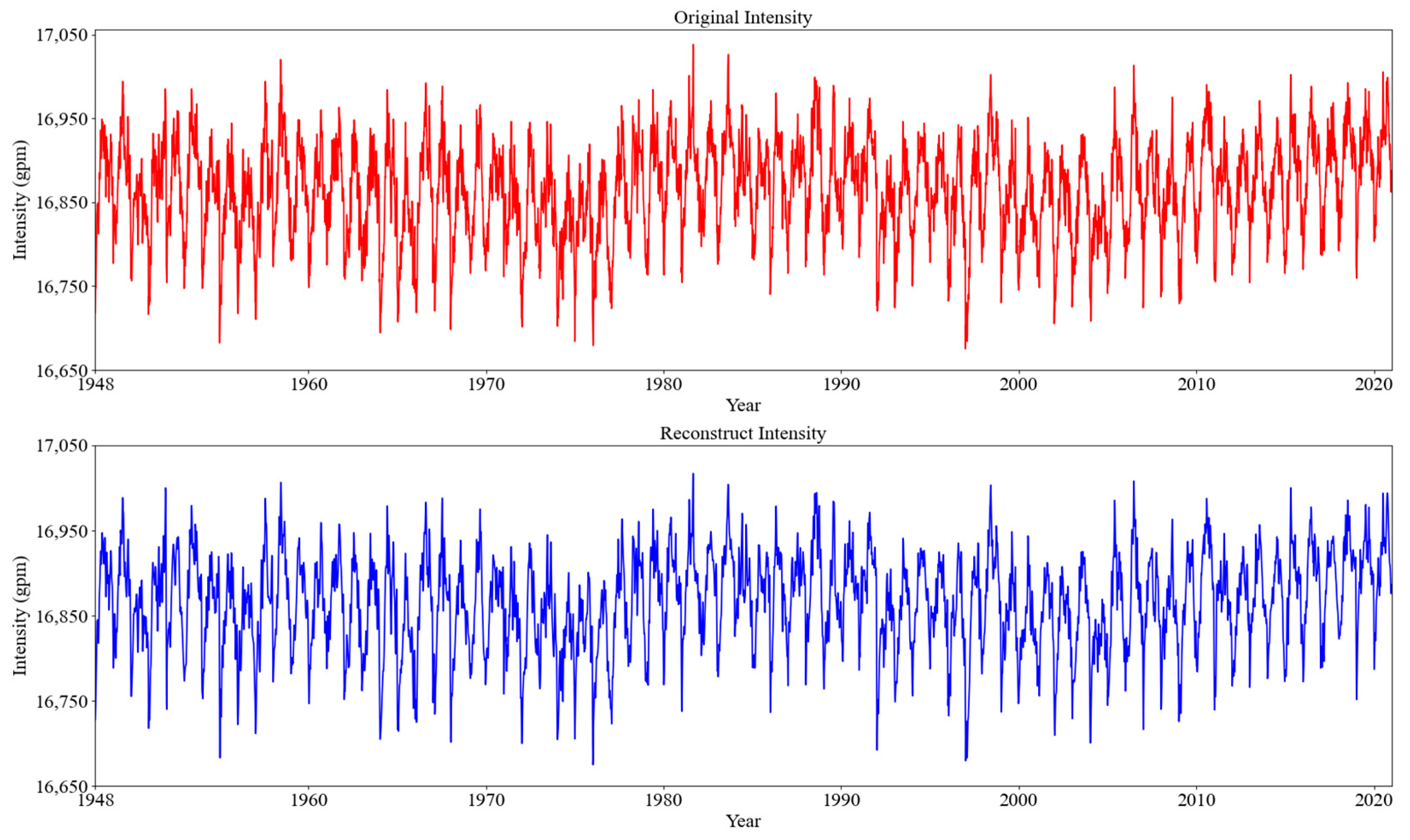
2.2.1. Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) and Permutation Entropy (PE)
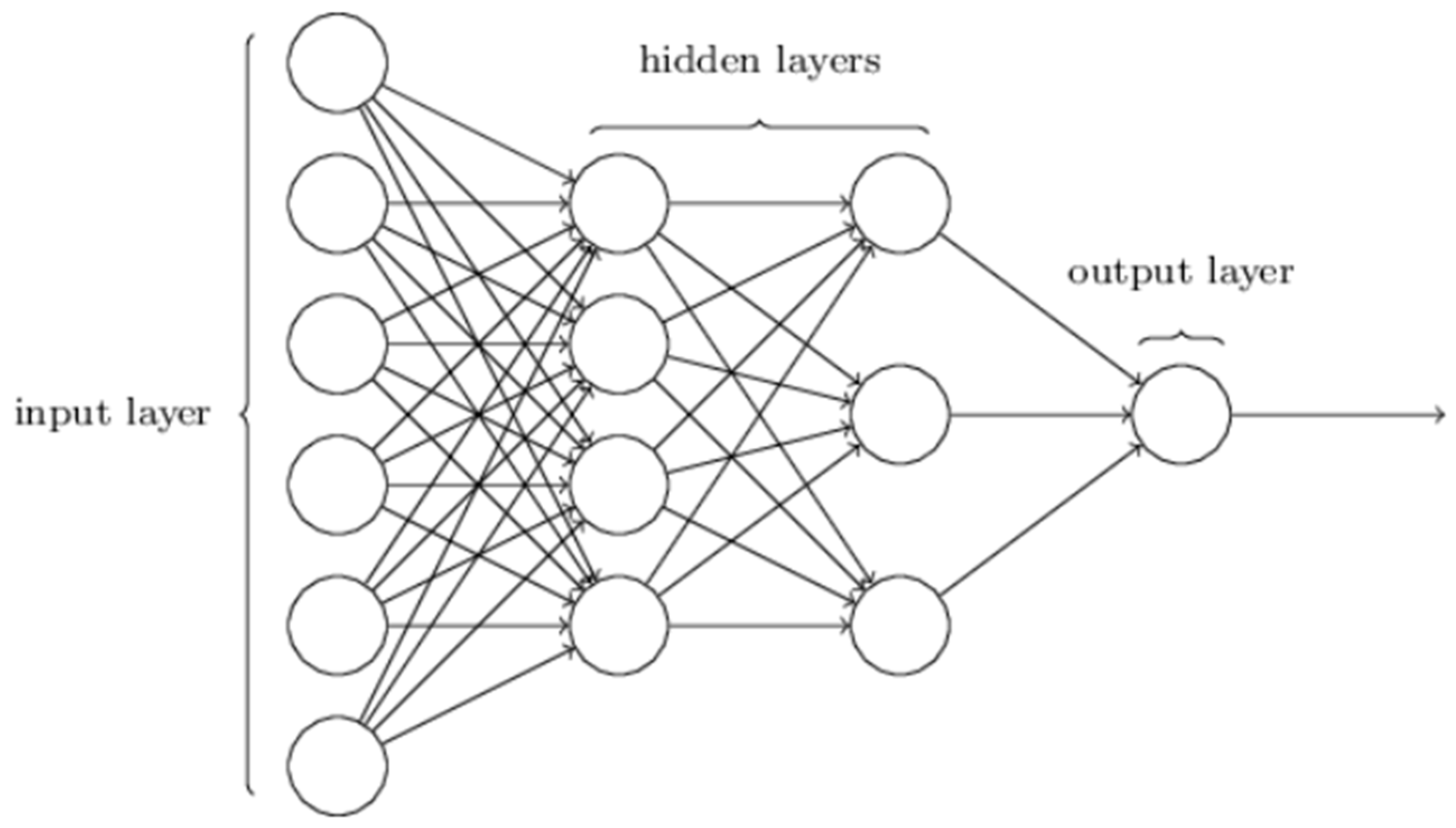
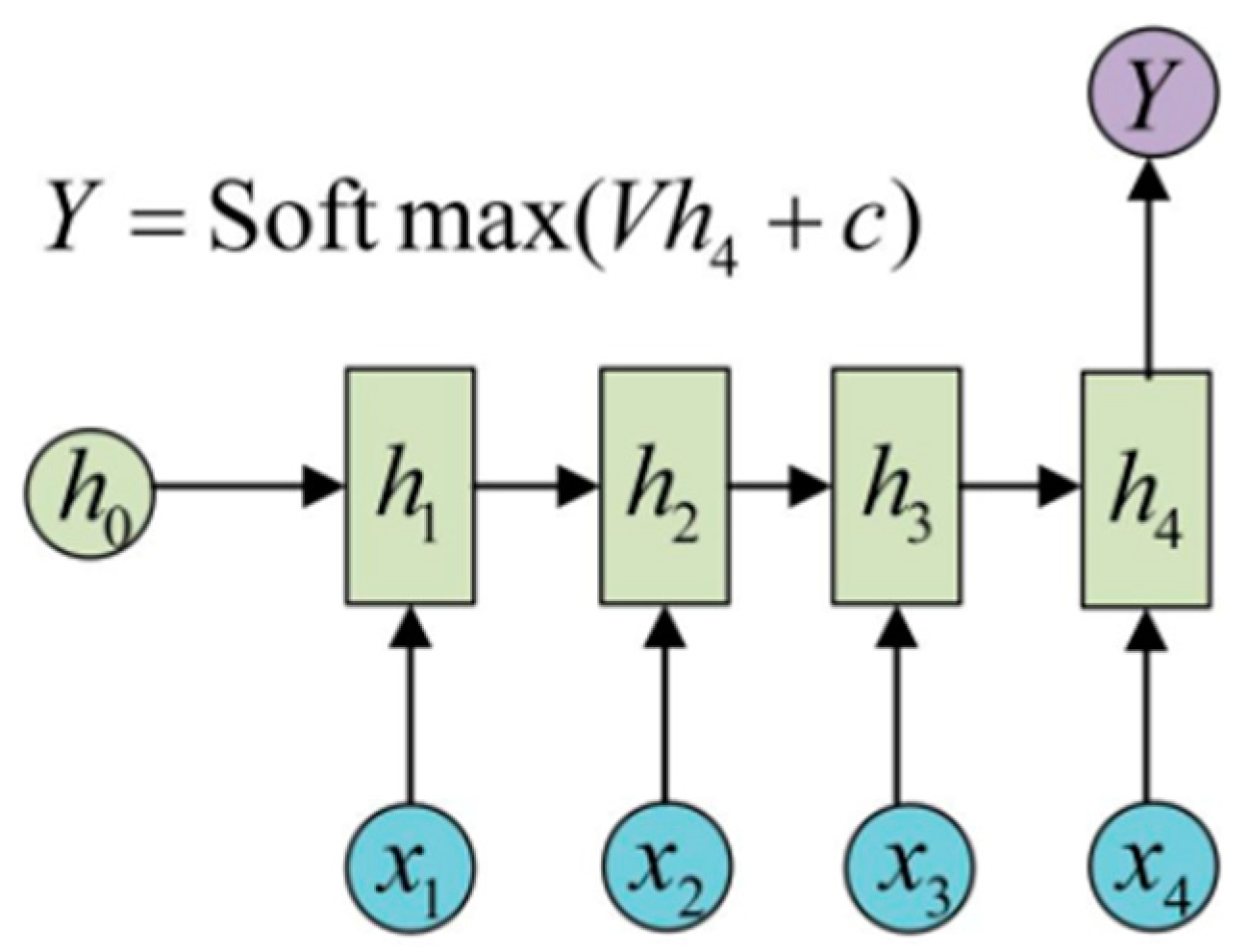
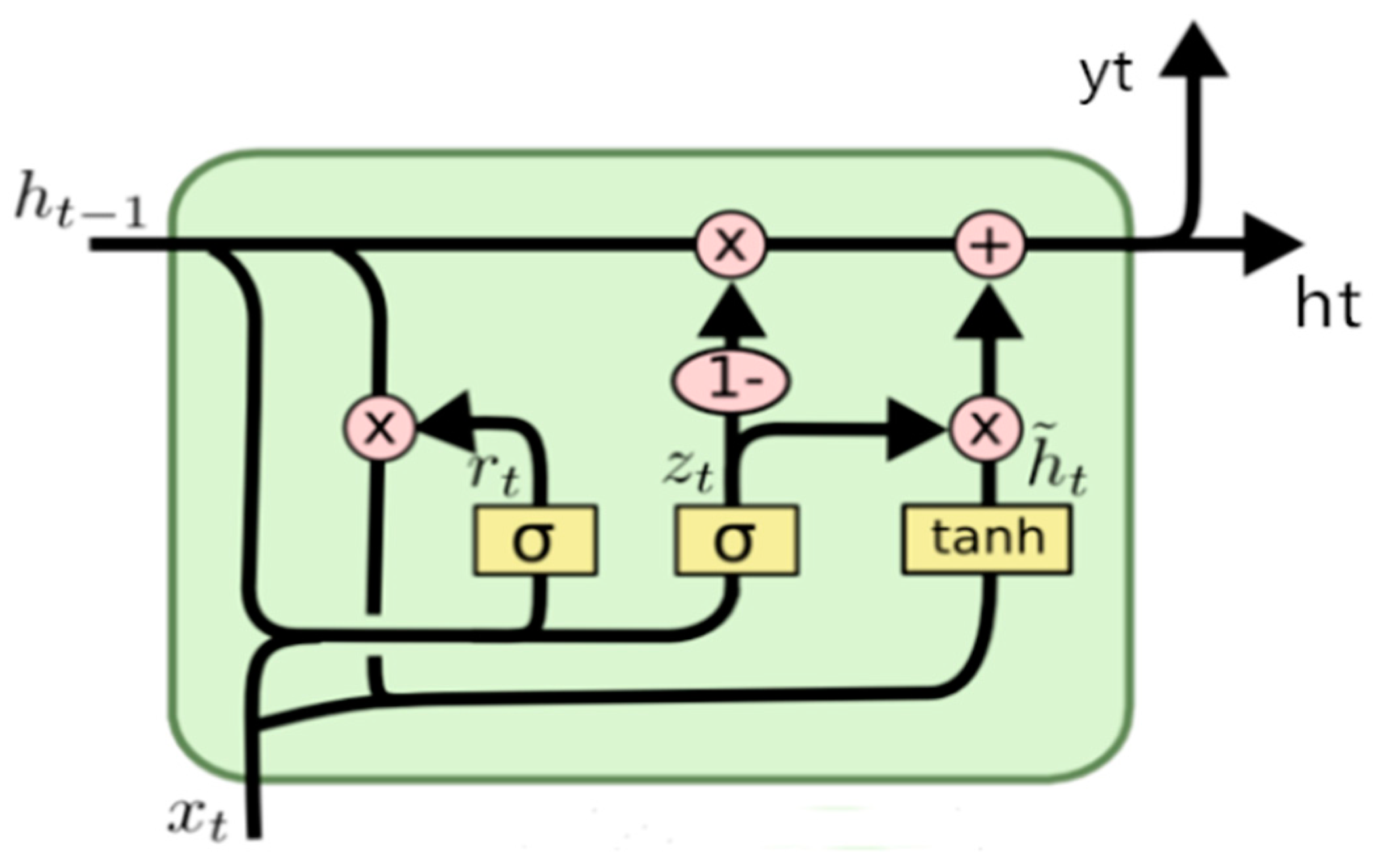
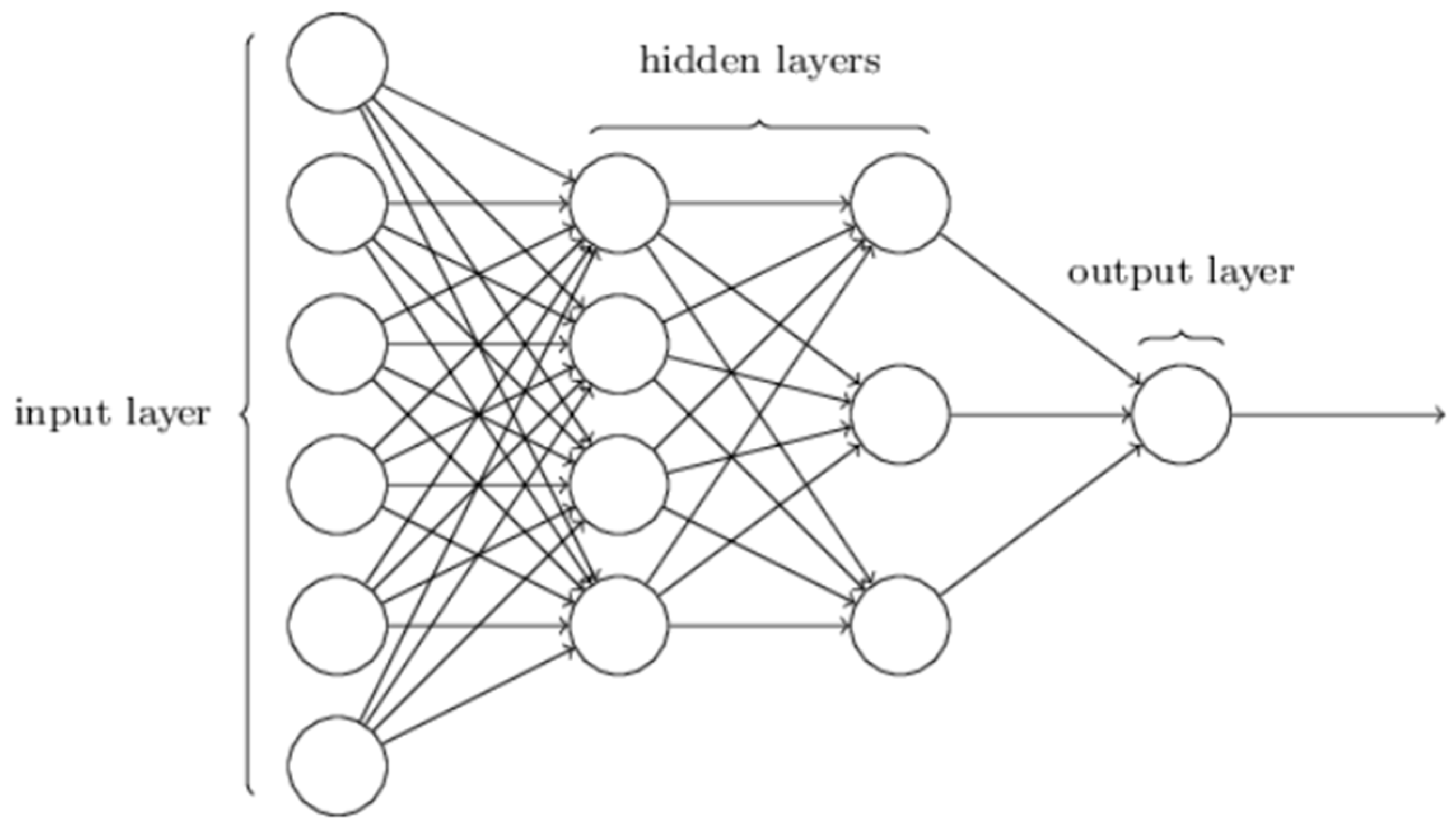
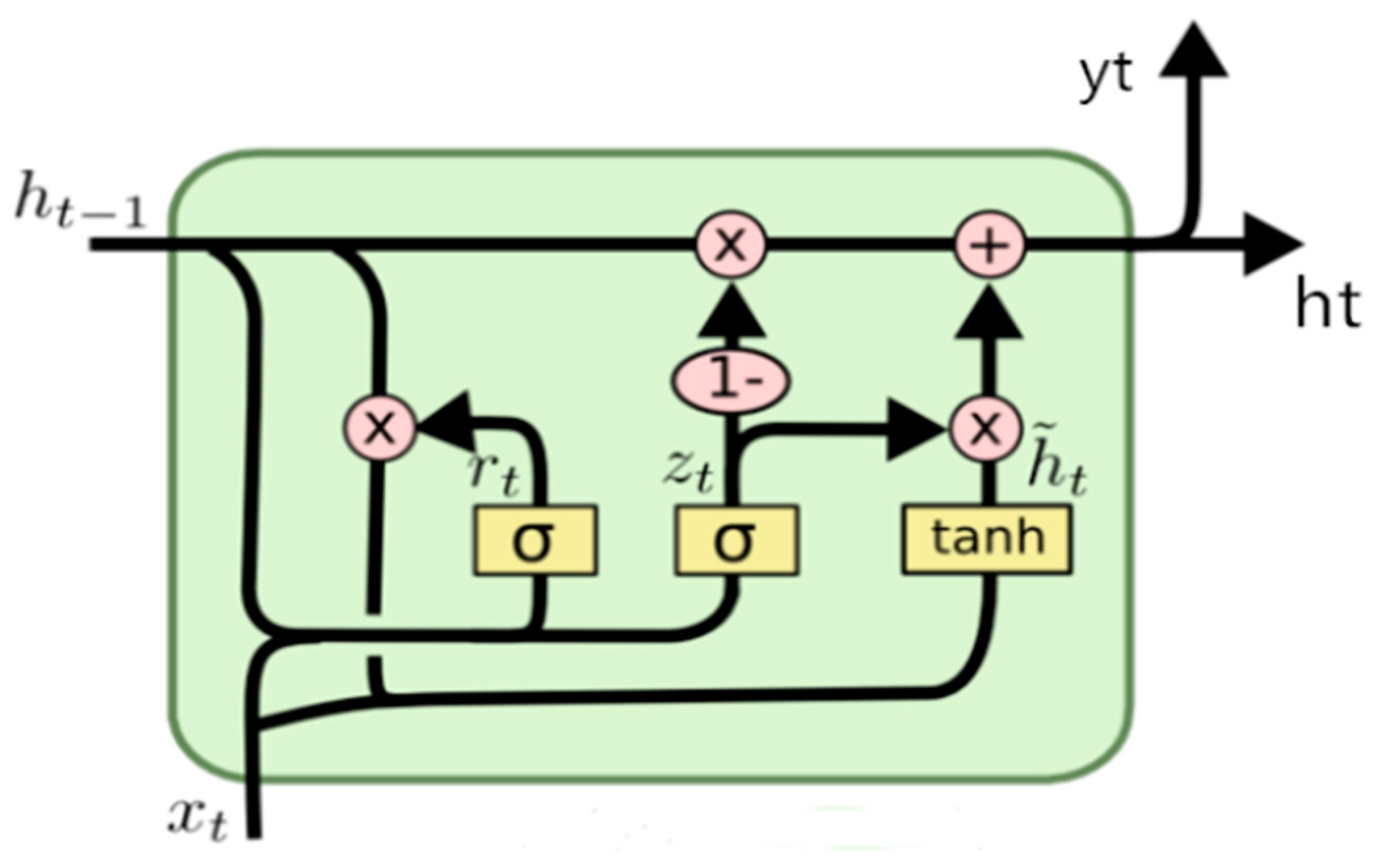
2.2.2. Multi-Layer Perceptron (MLP), Recurrent Neural Network (RNN), and Gated Recurrent Neural Network (GRU)
2.2.3. Innovation Model: Convolutional-Based GRU Network (ConvGRU) with CEEMDAN
2.2.4. Innovation Method and Strategy
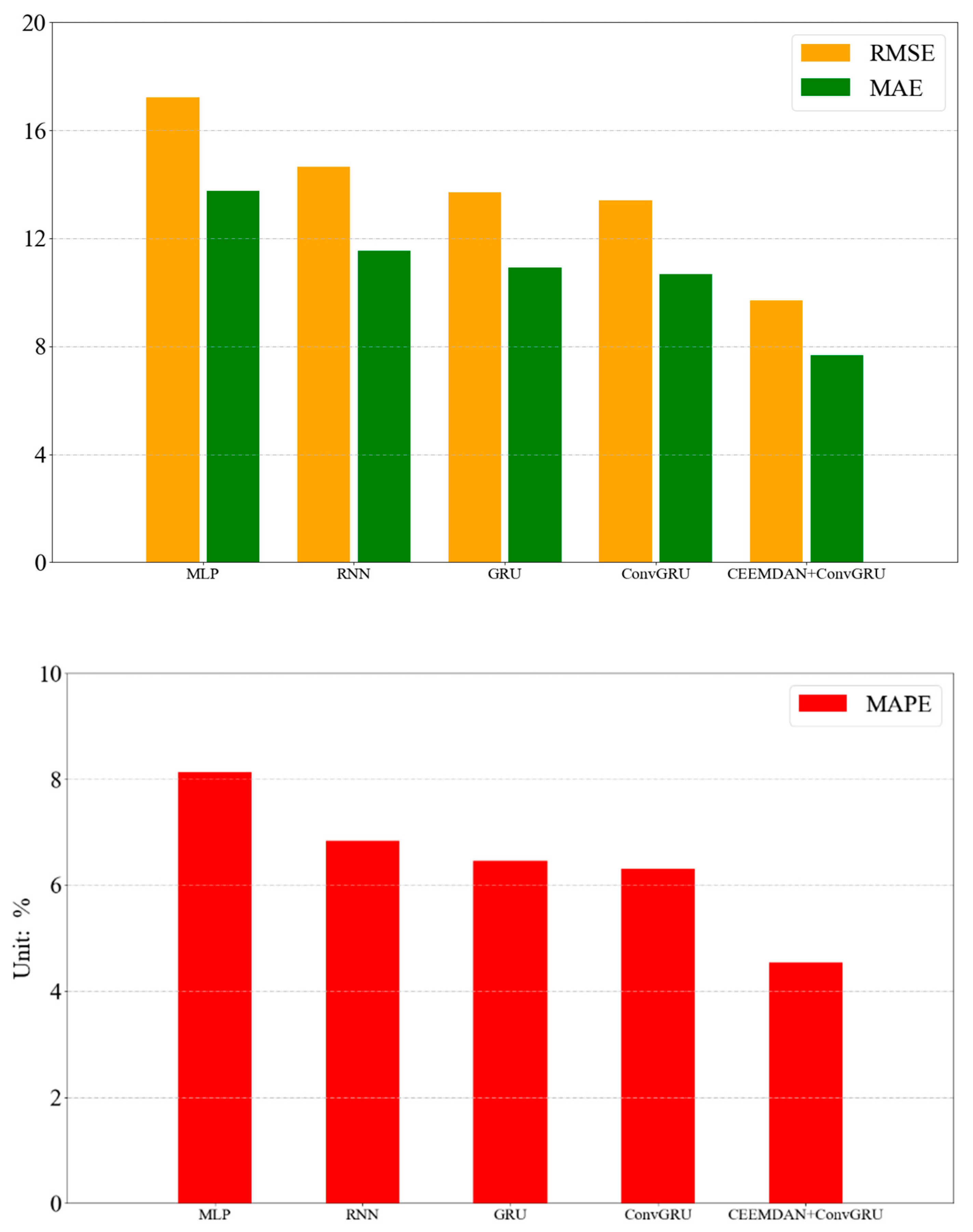
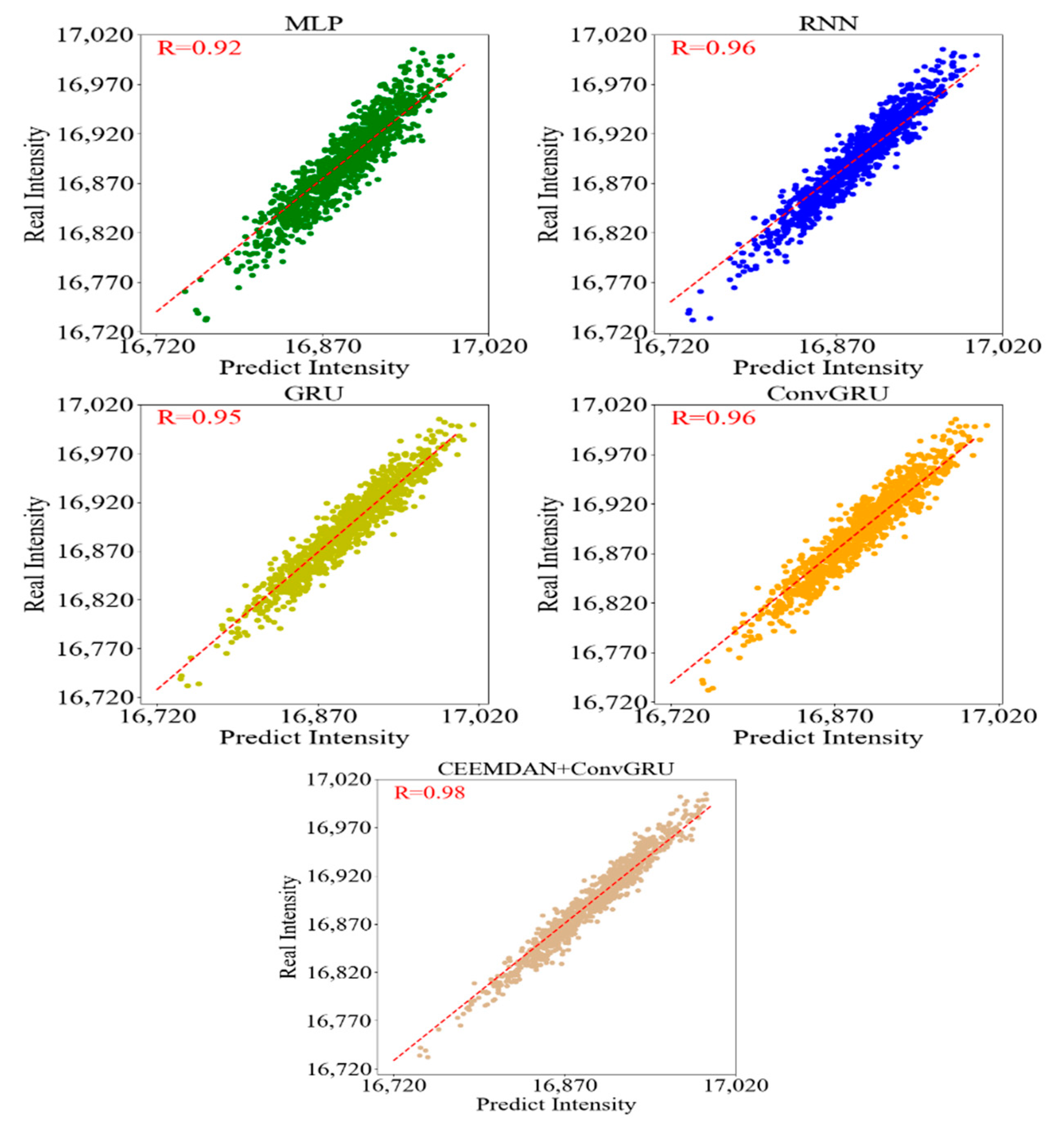
2.2.5. Evaluation of Multi-Model
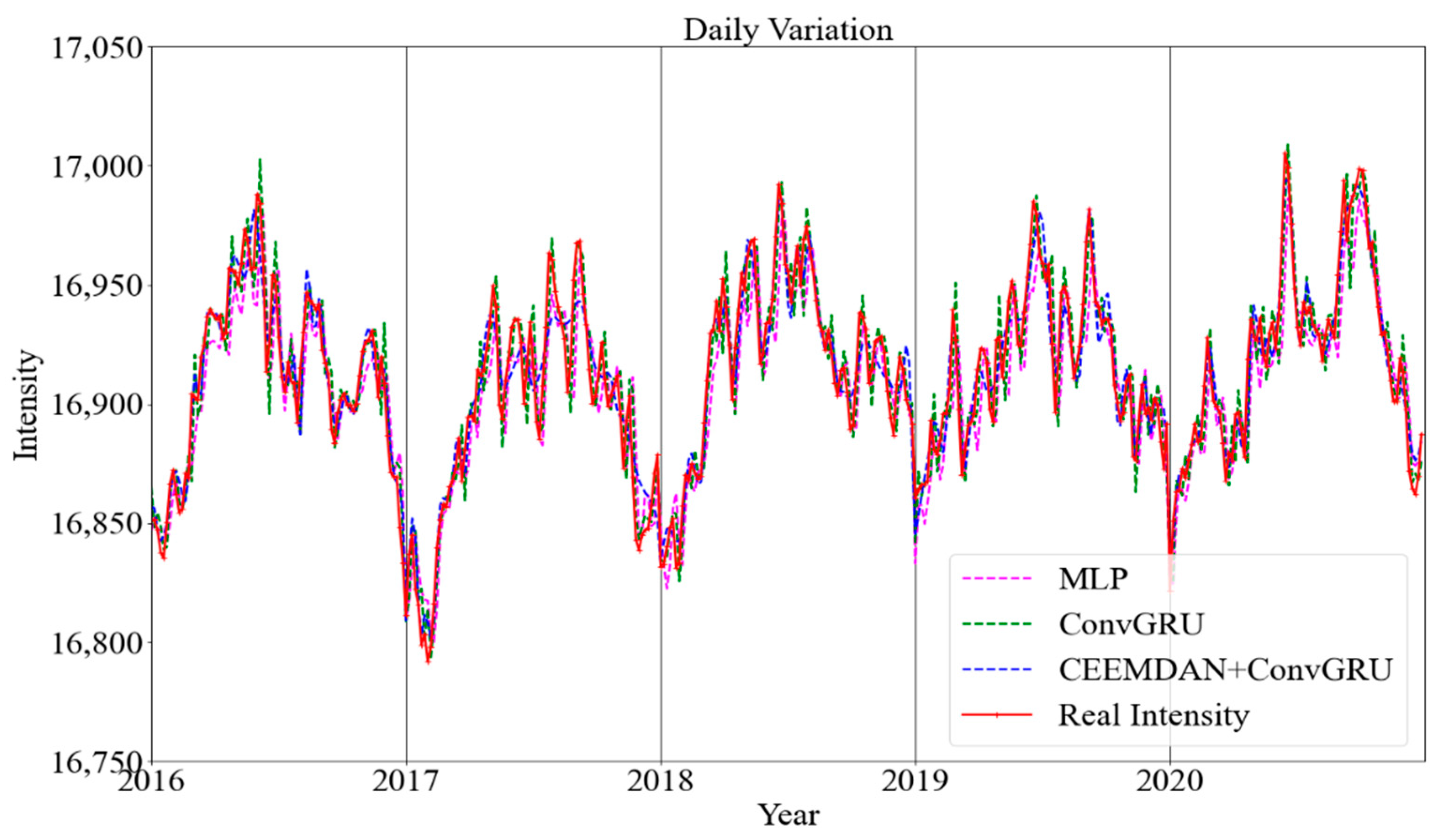
3. Results
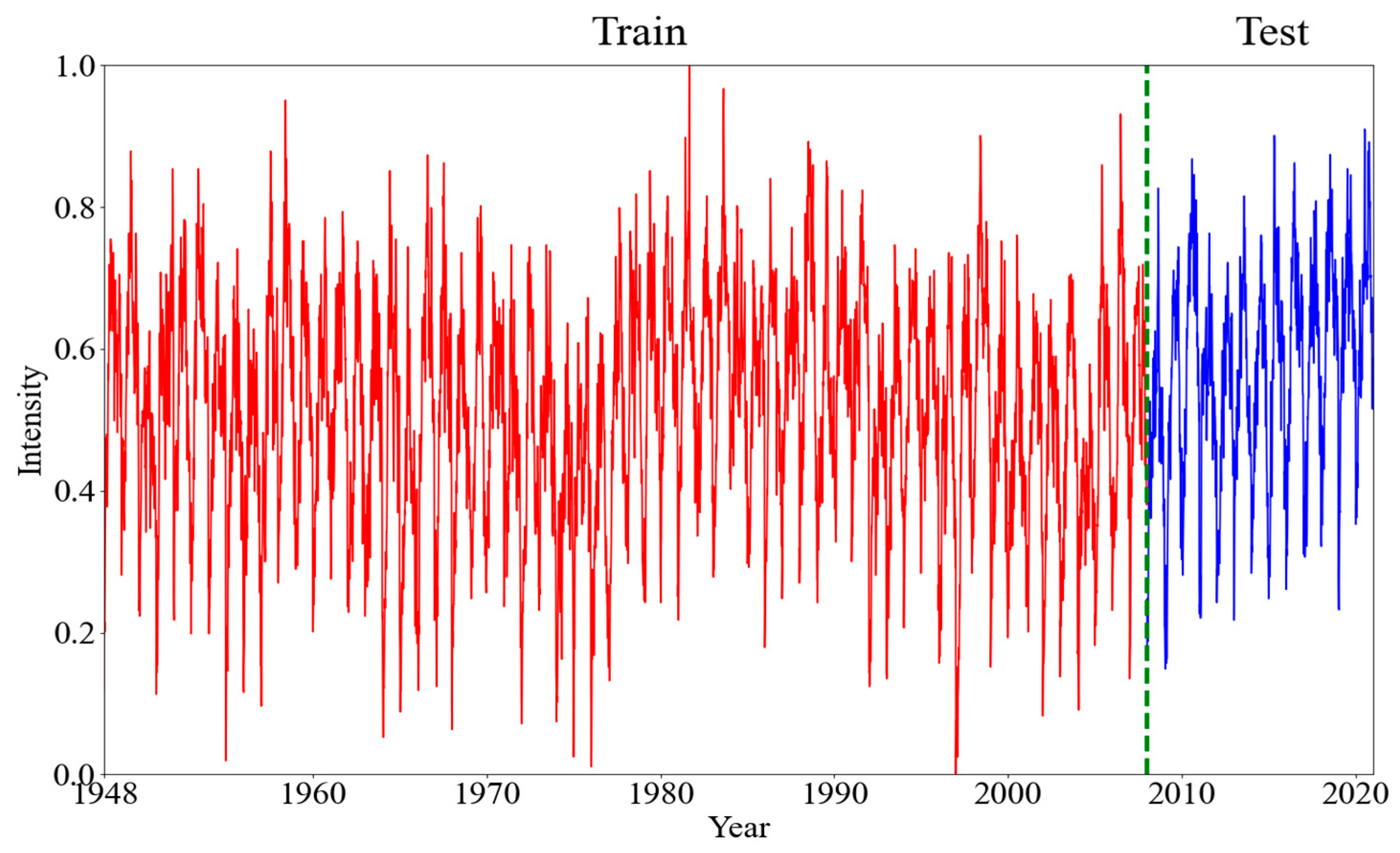
3.1. Division of Dataset
3.2. Model Training and Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tasks | Models | Main Idea | Accuracy or Degree of Improvement |
|---|---|---|---|
| Multi-year ENSO forecasts [14] | CNN | Forecasting ENSO events and the detailed zonal distribution of sea surface temperatures compared to dynamical forecast models | Lead times of up to 1.5 years |
| El Niño Index Prediction [58] | EEMD-CNN-LSTM | Provide accurate El Niño index predictions by comparing different deep learning models. | Improve the accuracy of MAE = 0.33 |
| Precipitation Nowcasting [52] | Convolutional LSTM Network | Build an end-to-end trainable model for the precipitation nowcasting problem | Captures spatiotemporal correlations better and consistently outperforms FC-LSTM |
| Precipitation Nowcasting [74] | Trajectory GRU | A benchmark for precipitation nowcasting and evaluation protocols. | MSE, MAE, B-MSE, and B-MAE improved more than previous models |
| TC Intensity prediction [76] | RNN | Predict the TC intensity by designing a data-driven intensity prediction model | The error is 5.1 m/s−1 in 24 h, and it is better than some widely used dynamic models |
| TC Intensity prediction [54] | CNN-LSTM | Design a spatio-temporal model based on a hybrid network of 2D-CNN, 3D-CNN, and LSTM | Better than the numerical forecast models and traditional ML models. |
| TC genesis prediction [77] | AdaBoost | A model is used to determine whether a mesoscale convective system (MCS) would evolve into a tropical cyclone. | Achieve a high 97.2% F1-score accuracy |
| Predictive of spatiotemporal sequences [79] | PredRNN: RNN + ST-LSTM | Spatiotemporal predictive learning can memorize both spatial appearances and temporal variations. | It shows superior predicting power both spatially and temporally |
| Automatic Oceanic Eddy Detection [42] | PCA+CNN+SVM | Detect eddies automatically and remotely by extracting higher-level features and then fuse multi-scale features to identify eddies, regardless of their structures and scales. | Achieving a 97.8 ± 1% accuracy of detection |
3.3. Model Evaluation
4. Discussion
- (1)
- The dynamic field and the corresponding chemical field of SAH have obvious symmetrical distribution. Taking the center of the anticyclone as the axis, the distribution of chemical substances in the stratosphere and troposphere is constrained by the anticyclone in the center symmetric direction. This is a common feature of the distribution of vortices and matter in the atmosphere. The prediction of SAH intensity can provide some reference for the atmospheric vortex systems of various scales, such as the prediction of tropical cyclone intensity.
- (2)
- Due to almost all systems in the atmosphere and ocean having nonlinear characteristics, the new CEEMDAN + ConvGRU model can the predict SAH intensity index well and may also be suitable for the prediction of other weather and climate systems. For example, the previous research and the prediction of extreme vortex intensity, weather and climate phenomena such as ENSO, NAO, AO, and other weather and climate phenomena, that is, the prediction of the index, which can be verified and compared with the innovation method. This method provides a new theoretical approach and scientific basis for the prediction of various intensity indices in the atmosphere.
- (3)
- In the prediction process of this study, we transform the time series characteristics of SAH time series into spatial characteristics for research. Compared with the prediction of El Niño [23], considering the temporal and spatial characteristics of its elements has a certain reference value. The time series can better capture the influence of the previous time series while predicting a single time step. In the process of forecasting, the spatial–temporal distribution characteristics of SAH-related elements are added to the forecasting model to make a multi-dimensional forecast, which has a high value for the prediction of all kinds of weather systems.
- (4)
- Heavy rainfall is one of the important and difficult points in modern numerical forecasting. SAH intensity has a significant impact on the distribution of water vapor and has a strong positive feedback on heavy rainfall in Asia. There is a teleconnection relationship between precipitation and SAH intensity. The prediction of the SAH intensity index can further accurately quantify the impact of heavy precipitation in Asia and provide a theoretical basis for the numerical prediction system.
- (5)
- The change of SAH intensity has a serious impact on extreme weather phenomena and disaster weather in Asia, especially typhoons in most parts of China and the Ozone (O3) trough in the Tibetan Plateau. The CEEMDAN + ConvGRU model can accurately predict the day-to-day variation of SAH intensity, which can provide a theoretical basis for the study of such extreme weather. Adding it into the model and new deep learning method can improve the prediction results of numerical forecasts.
- (6)
- In the region of different noise reduction processing methods, we also make an effective fusion of signal processing methods and deep learning methods in mathematics. Compared with the traditional methods, it has more feasibility for data processing. The most advanced methods such as CEEMDAN can be applied to the field of artificial intelligence and atmospheric science, which is worthy of discussion. Therefore, this research also provides a solid basis for other prediction fields in the atmosphere.
- (7)
- In the deep learning method, we combine the convolution network with GRU, which not only considers the time series features, but also extracts the spatial features of time series by using the step-by-step method. It has a certain guiding significance in the prediction of nonlinear system. Recent hybrid supervised–unsupervised techniques can be used to improve the performance of the proposed method in future works; for example, Ieracitano et al. [80] used autoencoder (AE) and MLP to classify the electrospun nanofibers, and the accuracy was as high as 92.5%; Benvenuto et al. [81] used the hybrid method of supervised–unsupervised learning to classify and predict the solar flares, and the result shows that the hybrid method is better than other supervised methods. We can learn from these methods to improve the accuracy and reduce the complexity of the model in future works.
5. Conclusions
- (a)
- In general, the ConvGRU training model is simpler than ConvLSTM, the training time is faster, and it is aimed at the nonlinear system in the atmosphere. The annual effect of the intensity variation of the SAH is not significant enough. As variants of the Recurrent Neural Network (RNN), the Gated Recurrent Neural Network (GRU) and Long–Short Time Memory (LSTM) can capture the effective information in the long-term sequence, and GRU has a simpler structure than LSTM, which also has a faster effect on the training of SAH intensity time series. Differently from the previous training and prediction methods of the time series, such as RNN and the one-dimensional convolutional neural network (CNN), we transformed the one-dimensional structure into a two-dimensional structure through time-step processing for each year’s SAH intensity data and then added two-dimensional convolutional network to the training model to better extract the change characteristics of the time series.
- (b)
- In addition, differently from the traditional deep learning models such as Multi-layer Perceptron (MLP), RNN, GRU, and ConvGRU, we used the CEEMDAN and PE method to eliminate the noise in the time series and obtain more robust data. After that, the randomness and complexity of time series were reduced, so the time series prediction data combined with the method had higher accuracy and a more stable training effect.
- (c)
- Ultimately, the method of conforming to the model provides a new idea for the prediction of time series. Because of the nonlinear variation characteristics of various weather systems in the atmosphere, influenced by various weather and meteorological elements, there are strong characteristics of mutation and randomness. Therefore, the research considers the processing and prediction of the time series of atmospheric systems to be very important.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mason, R.B.; Anderson, C.E. The development and decay of the 100 mb summertime anticyclone over Southern Asia. Mon. Wea. Rev. 1963, 91, 3–12. [Google Scholar] [CrossRef]
- Hoskins, B.J.; Rodwell, M.J. A model of the Asian summer monsoon. Part I: The global scale. J. Atmos. Sci. 1995, 52, 1329–1340. [Google Scholar] [CrossRef]
- Park, M.; Randel, W.J.; Emmons, L.K.; Bernath, P.F.; Walker, K.A.; Boone, C.D. Chemical isolation in the Asian monsoon anticyclone observed in Atmospheric Chemistry Experiment (ACE-FTS) data. Atmos. Chem. Phys. 2008, 8, 757–764. [Google Scholar] [CrossRef] [Green Version]
- Rosenlof, K.H.; Tuck, A.F.; Kelly, K.K.; Russell, J.M., III; McCormick, M.P. Hemispheric asymmetries in water vapor and inferences about transport in the lower stratosphere. J. Geophys. Res. 1997, 102, 213–234. [Google Scholar] [CrossRef]
- Jackson, D.R.; Driscoll, S.J.; Highwood, E.J.; Harries, J.E.; Russell, J.M., III. Troposphere to stratosphere transport at low latitudes as studied using HALOE observations of water vapour 1992–1997. Q. J. R. Meteorol. Soc. 1998, 124, 169–192. [Google Scholar] [CrossRef]
- Li, Q.; Jiang, J.H.; Wu, D.L.; Read, W.G.; Livesey, N.J.; Waters, J.W.; Zhang, Y.; Wang, B.; Filipiak, M.J.; Davis, C.P.; et al. Convective outflow of South Asian pollution: A global CTM simulation compared with EOS MLS observations. Geophys. Res. Lett. 2005, 32, L14826. [Google Scholar] [CrossRef]
- Randel, W.J.; Park, M. Deep convective influence on the Asian summer monsoon anticyclone and associated tracer variability observed with Atmospheric Infrared Sounder (AIRS). J. Geophys. Res. Atmos. 2006, 111, D12314. [Google Scholar] [CrossRef]
- Park, M.; Randel, W.J.; Gettelman, A.; Massie, S.T.; Jiang, J.H. Transport above the Asian summer monsoon anticyclone inferred from Aura Microwave Limb Sounder tracers. J. Geophys. Res. Atmos. 2007, 112, D16309. [Google Scholar] [CrossRef] [Green Version]
- Randel, W.J.; Park, M.; Emmons, L.; Kinnison, D.; Bernath, P.; Walker, K.A.; Boone, C.; Pumphrey, H. Asian Monsoon Transport of Pollution to the Stratosphere. Science 2010, 328, 611–613. [Google Scholar] [CrossRef] [Green Version]
- Kremser, S.; Thomason, L.W.; Von Hobe, M.; Hermann, M.; Deshler, T.; Timmreck, C.; Toohey, M.; Stenke, A.; Schwarz, J.P.; Weigel, R.; et al. Stratospheric aerosol Observations, processes, and impact on climate. Rev. Geophys. 2016, 54, 278–335. [Google Scholar] [CrossRef]
- Vogel, B.; Günther, G.; Müller, R.; Grooß, J.-U.; Riese, M. Impact of different Asian source regions on the composition of the Asian monsoon anticyclone and of the extratropical lowermost stratosphere. Atmos. Chem. Phys. 2015, 15, 13699–13716. [Google Scholar] [CrossRef] [Green Version]
- Yuan, C.; Lau, W.K.M.; Li, Z.; Cribb, M. Relationship between Asian monsoon strength and transport of surface aerosols to the Asian Tropopause Aerosol Layer (ATAL): Interannual variability and decadal changes. Atmos. Chem. Phys. 2019, 19, 1901–1913. [Google Scholar] [CrossRef] [Green Version]
- Ham, Y.G.; Kim, J.H.; Luo, J.J. Deep learning for multi-year ENSO forecasts. Nature 2019, 573, 568–572. [Google Scholar] [CrossRef]
- Kiem, A.S.; Franks, S.W. On the identification of ENSO-induced rainfall and runoff variability: A comparison of methods and indices. Hydrol. Sci. J. 2001, 46, 715–727. [Google Scholar] [CrossRef]
- Pan, X.N.; Wang, G.L.; Yang, P.C. Introducing driving-force information increases the predictability of the North Atlantic Oscillation. Atmos. Ocean. Sci. Lett. 2019, 12, 329–336. [Google Scholar] [CrossRef] [Green Version]
- Yuan, S.J.; Luo, X.D.; Mu, B.; Li, J.; Dai, J.K. Prediction of North Atlantic Oscillation Index with Convolutional LSTM Based on Ensemble Empirical Mode Decomposition. Atmosphere 2019, 10, 252. [Google Scholar] [CrossRef] [Green Version]
- Hanley, D.E.; Bourassa, M.A.; O’Brien, J.J.; Smith, S.R.; Spade, E.R. A quantitative evaluation of ENSO indices. J. Clim. 2003, 16, 1249–1258. [Google Scholar] [CrossRef]
- Mario, R.; Lee, S.; Jeon, S.; You, D. Prediction of a typhoon track using a generative adversarial network and satellite images. Sci. Rep. 2019, 9, 6057. [Google Scholar]
- Lee, J.; Im, J.; Cha, D.H.; Park, H.; Sim, S. Tropical Cyclone Intensity Estimation Using Multi-Dimensional Convolutional Neural Networks from Geostationary Satellite Data. Remote Sens. 2019, 12, 108. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Wu, G.X.; Qian, Y.F. The bimodality of the 100 hPa South Asia High and its relationship to the climate anomaly over East Asia in summer. J. Meteorol. Soc. Jpn. 2002, 80, 733–744. [Google Scholar] [CrossRef] [Green Version]
- Basha, G.; Ratnam, M.V.; Kishore, P. Asian summer monsoon anticyclone: Trends and variability. Atmos. Chem. Phys. 2020, 20, 6789–6801. [Google Scholar] [CrossRef]
- Nooteboom, P.D.; Feng, Q.Y.; López, C.; Hernández-García, E.; Dijkstra, H.A. Using Network Theory and Machine Learning to predict El Niño. arXiv 2018, arXiv:1803.10076. [Google Scholar] [CrossRef] [Green Version]
- Tangang, F.; Hsieh, W.; Tang, B. Forecasting the equatorial Pacific sea surface temperatures by neural network models. Clim. Dyn. 1997, 13, 135–147. [Google Scholar] [CrossRef]
- Zhang, H.Q.; Tian, X.J.; Cheng, W.; Jiang, L.P. System of Multigrid Nonlinear Least-squares Four-dimensional Variational Data Assimilation for Numerical Weather Prediction (SNAP): System Formulation and Preliminary Evaluation. Adv. Atmos. Sci. 2020, 37, 1267–1284. [Google Scholar] [CrossRef]
- Geng, H.-T.; Sun, J.-Q.; Zhang, W.; Wu, Z.-X. A novel classification method for tropical cyclone intensity change analysis based on hierarchical particle swarm optimization algorithm. J. Trop. Meteorol. 2017, 23, 113–120. [Google Scholar]
- Bushra, P.; Pritee, S. Climate variability and its impacts on agriculture production and future prediction using autoregressive integrated moving average method (ARIMA). J. Public Aff. 2020, 20. [Google Scholar] [CrossRef]
- Dwivedi, D.K.; Kelaiya, J.H.; Sharma, G.R. Forecasting monthly rainfall using autoregressive integrated moving average model (ARIMA) and artificial neural network (ANN) model: A case study of Junagadh, Gujarat, India. J. Appl. Nat. Sci. 2019, 11. [Google Scholar] [CrossRef]
- Wiredu, S.; Nasiru, S.; Asamoah, Y.G. Proposed Seasonal Autoregressive Integrated Moving Average Model for Forecasting Rainfall Pattern in the Navrongo Municipality, Ghana. J. Environ. Earth Sci. 2013, 3, 80–85. [Google Scholar]
- Aqsa, S.; Toshihisa, T.; Keiichi, K. Time-Series Prediction of the Oscillatory Phase of EEG Signals Using the Least Mean Square Algorithm-Based AR Model. Appl. Sci. 2020, 10, 3616. [Google Scholar]
- Arundhati, B.; GopiTilak, V.; KoteswaraRao, S. Real Time TEC Prediction during Storm Periods using AR Based Kalman Filter. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 6. [Google Scholar]
- Sun, H.Y.; Wu, J.; Wu, J.; Yang, H.Y. Hybrid SVM and ARIMA Model for Failure Time Series Prediction based on EEMD. Int. J. Perform. Eng. 2019, 15, 1161–1170. [Google Scholar] [CrossRef]
- Pham, H.T.; Tran, V.T.; Yang, B.S. A hybrid of nonlinear autoregressive model with exogenous input and autoregressive moving average model for long-term machine state forecasting. Expert Syst. Appl. 2009, 37, 3310–3317. [Google Scholar] [CrossRef] [Green Version]
- Ning, J.Q.; Liang, S.Y. Prediction of Temperature Distribution in Orthogonal Machining Based on the Mechanics of the Cutting Process Using a Constitutive Model. J. Manuf. Mater. Process. 2018, 2, 37. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.-M. Research Progress on China typhoon numerical prediction models and associated major techniques. Prog. Geophys. 2014, 29, 1013–1022. [Google Scholar]
- Tropical Cyclone Forecast Model. Available online: https://en.wikipedia.org/wiki/Tropical_cyclone_forecast_model (accessed on 1 May 2020).
- Lee, C.Y.; Tippett, M.K.; Camargo, S.J.; Sobel, A.H. Probabilistic Multiple Linear Regression Modeling for Tropical Cyclone Intensity. Mon. Wea. Rev. 2015, 143, 933–954. [Google Scholar] [CrossRef]
- Demaria, M.; Kaplan, J.J.W. A statistical hurricane intensity prediction scheme (SHIPS) for the Atlantic basin. Weather Forecast. 1994, 9, 209–220. [Google Scholar] [CrossRef]
- McDermott, P.L.; Wikle, C.K. Bayesian recurrent neural network models for forecasting and quantifying uncertainty in spatial-temporal data. Entropy 2019, 21, 184. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.; Hong, S.; Joh, M.; Song, S.-K. Deeprain: Convlstm network for precipitation prediction using multichannel radar data. arXiv 2017, arXiv:1711.02316. [Google Scholar]
- Wong, W.-K.; Shi, X.; Yeung, D.Y.; Woo, W. A deep-learning method for precipitation nowcasting. In Proceedings of the WMO WWRP 4th International Symposium on Nowcasting and Very Short-Range Forecast 2016, Hong Kong, China, 25–29 July 2016. [Google Scholar]
- Reichstein, M.; Gustau, C.V.; Bjorn, S.; Martin, J.; Joachim, D.; Nuno, C.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Du, Y.L.; Song, W.; He, Q.; Huang, D.M.; Liotta, A.; Su, C. Deep learning with multi-scale feature fusion in remote sensing for automatic oceanic eddy detection. Inf. Fusion 2019, 49, 89–99. [Google Scholar] [CrossRef] [Green Version]
- Titus, C.M.; Wanjoya, A.; Mageto, T. Time Series Modeling of Guinea Fowls Production in Kenya Using the ARIMA and ARFIMA Models. Int. J. Data Sci. Anal. 2021, 7, 1–7. [Google Scholar]
- Yan, Q.; Ji, F.X.; Miao, K.C.; Wu, Q.; Xia, Y.; Li, T.; Hashiguchi, H. Convolutional Residual-Attention: A Deep Learning Approach for Precipitation Nowcasting. Adv. Meteorol. 2020, 2020. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2014; pp. 568–576. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2014; pp. 3104–3112. [Google Scholar]
- Karevan, Z.H.; Suykens, J.A.K. Transductive LSTM for time-series prediction: An application to weather forecasting. Neural Netw. 2020, 125, 1–9. [Google Scholar] [CrossRef]
- Wang, X.; Wang, W.K.; Yan, B. Tropical Cyclone Intensity Change Prediction Based on Surrounding Environmental Conditions with Deep Learning. Water 2020, 12, 2685. [Google Scholar] [CrossRef]
- Nützel, M.; Dameris, M.; Garny, H. Movement, drivers andbimodality of the South Asian High. Atmos. Chem. Phys. 2016, 16, 14755–14774. [Google Scholar] [CrossRef] [Green Version]
- Ren, R.; Zhu, C.D.; Cai, M. Linking quasi-biweekly variability of the South Asian high to atmospheric heating over Tibetan Plateau in summer. Clim. Dyn. 2019, 53, 3419–3429. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Zhang, C.Y.; Fiore, M.; Murray, L.; Patras, P. CloudLSTM: A Recurrent Neural Model for Spatiotemporal Point-cloud Stream Forecasting. Association Advancement Artificial Intelligence. arXiv 2021, arXiv:1907.12410v3. [Google Scholar]
- Chen, R.; Wang, X.; Zhang, W.; Zhu, X.; Li, A.; Yang, C. A hybrid CNN-LSTM model for typhoon formation forecasting. Geoinformatica 2019, 23, 375–396. [Google Scholar] [CrossRef]
- Hsieh, P.C.; Tong, W.A.; Wang, Y.C. A hybrid approach of artificial neural network and multiple regression to forecast typhoon rainfall and groundwater-level change. Hydrol. Sci. J. 2019, 64, 1793–1802. [Google Scholar] [CrossRef]
- Neeraj, N.; Mathew, J.; Agarwal, M.; Behera, R.K. Long short-term memory-singular spectrum analysis-based model for electric load forecasting. Electr. Eng. 2020, 103, 1067–1082. [Google Scholar] [CrossRef]
- Stylianos, K.; Botzoris, G.; Profillidis, V.; Lemonakis, P. Road traffic forecasting -A hybrid approach combining Artificial Neural Network with Singular Spectrum Analysis. Econ. Anal. Policy 2019, 64. [Google Scholar] [CrossRef]
- Guo, Y.N.; Cao, X.Q.; Liu, B.N.; Peng, K.C. El Niño Index Prediction Using Deep Learning with Ensemble Empirical Mode Decomposition. Symmetry 2020, 12, 893. [Google Scholar] [CrossRef]
- Todd, A.; Collins, M.; Lambert, F.H.; Chadwick, R. Diagnosing ENSO and global warming tropical precipitation shifts using surface relative humidity and temperature. J. Clim. 2018, 31, 1413–1433. [Google Scholar] [CrossRef] [Green Version]
- Luo, J.-J.; Hendon, H.; Alves, O. Multi-year prediction of ENSO. In Proceedings of the Geophysical Research Abstracts, Vienna, Austria, 7–12 April 2019. [Google Scholar]
- Huang, N.; Shen, Z.; Long, S.R. The Empirical Mode Decomposition and the Hilbert Spectrum for Nonlinear and Non-Stationary Time Series Analysis. R. Soc. Lond. Proc. Ser. A 1998, 903–998. [Google Scholar] [CrossRef]
- WU, Z.H.; Huang, N.E. Ensemble Empirical Mode Decomposition: A Noise-Assisted Data Analysis Method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Yeh, J.R.; Shieh, J.S. Complementary ensemble empirical mode decomposition: A noise enhanced data analysis method. Adv. Adapt. Data Anal. 2010, 2, 135–156. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Gasto’n, S. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Prague, Czech Republic, 22–27 May 2011. [Google Scholar] [CrossRef]
- Babouri, M.K.; Ouelaa, N.; Kebabsa, T.; Djebala, A. Diagnosis of mechanical defects using a hybrid method based on complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) and optimized wavelet multi-resolution analysis (OWMRA): Experimental study. Int. J. Adv. Manuf. Technol. 2021, 112, 2657–2681. [Google Scholar] [CrossRef]
- Krishna, T.; Rahul, T.; Satish, M. Adaptive denoising of ECG using EMD, EEMD and CEEMDAN signal processing techniques. J. Phys. Conf. Ser. 2020, 1706. [Google Scholar] [CrossRef]
- Peng, Y.X.; Liu, Y.S.; Zhang, C.; Wu, L. A Novel Denoising Model of Underwater Drilling and Blasting Vibration Signal Based on CEEMDAN. Arab. J. Sci. Eng. 2021, 46, 4857–4865. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. Am. Physiol. Soc. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Sun, K.H.; Tan, G.Q.; Sheng, L.Y. Analysis of Chaotic Pseudo-random Sequence Complexity Based on Permutation Entropy. Comput. Eng. Appl. 2008, 44, 47–55. [Google Scholar]
- Frank, B.; Pompe, B.; Schneider, U.; Hoyer, D. Permutation Entropy Improves Fetal Behavioural State Classification Based on Heart Rate Analysis from Biomagnetic Recordings in Near Term Fetuses. Med. Biol. Eng. Comput. 2006, 44, 179–187. [Google Scholar] [CrossRef]
- Mariano, M.G.; Manuel, R.M. A Non-parametric Independence Test Using Permutation Entropy. J. Econom. 2008, 144, 139–155. [Google Scholar]
- Zhang, J.B.; Zhao, Y.Q.; Kong, L.X.; Liu, M. Morphology Similarity Distance for Bearing Fault Diagnosis Based on Multi-Scale Permutation Entropy. J. Harbin Inst. Technol. 2020, 27, 9. [Google Scholar]
- Chen, Y.S.; Zhang, T.B.; Zhao, W.J.; Luo, Z.M.; Lin, H.J. Rotating Machinery Fault Diagnosis Based on Improved Multiscale Amplitude-Aware Permutation Entropy and Multiclass Relevance Vector Machine. Sensors 2019, 19, 4542. [Google Scholar] [CrossRef] [Green Version]
- Shi, X.J.; Gao, Z.H.; Lausen, L.; Wang, H.; Yeung, D.-Y.; Wong, W.K.; Woo, W. Deep learning for precipitation nowcasting: A benchmark and a new model. Advances in neural information processing systems. In Proceedings of the 31th Internationla Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Pan, B.; Xu, X.; Shi, Z. Tropical cyclone intensity prediction based on recurrent neural networks. Electron. Lett. 2019, 55, 413–414. [Google Scholar] [CrossRef]
- Zhang, T.; Lin, W.Y.; Lin, Y.L.; Zhang, M.H.; Yu, H.Y.; Cao, K.; Xue, W. Prediction of Tropical Cyclone Genesis from Mesoscale Convective Systems Using Machine Learning. Weather Forecast. 2019, 34, 1035–1049. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L.; Anezakis, V.D. Commentary: Aedes albopictus and Aedes japonicus—two invasive mosquito species with different temperature niches in Europe. Front. Environ. Sci. 2017, 5. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. PredRNN: Recurrent Neural Networks for Predictive Learning Using Spatiotemporal Lstms. In Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2017; pp. 879–888. [Google Scholar]
- Ieracitano, C.; Paviglianiti, A.; Campolo, M.; Hussain, A.; Pasero, E.; Morabito, F.C. A Novel Automatic Classification System Based on Hybrid Unsupervised and Supervised Machine Learning for Electrospun Nanofibers. IEEE/CAA J. Autom. Sin. 2021, 8, 64–76. [Google Scholar] [CrossRef]
- Benvenuto, F.; Piana, M.; Campi, C. A Hybrid Supervised/Unsupervised Machine Learning Approach to Solar Flare Prediction. Astrophys. J. 2018, 853, 90. [Google Scholar] [CrossRef] [Green Version]











| Data (After Dispose) | Number (Year × Day) | Max Intensity (gpm) | Min Intensity (gpm) | Mean Intensity (gpm) |
|---|---|---|---|---|
| Training | 60 × 82 = 4920 | 17,038.00 | 16,692.00 | 16,871.99 |
| Testing | 13 × 82 = 1066 | 17,005.25 | 16,732.00 | 16,893.31 |
| Number of IMF | Value of PE |
|---|---|
| IMF1 | 0.97838 |
| IMF2 | 0.80366 |
| IMF3 | 0.65887 |
| IMF4 | 0.54547 |
| IMF5 | 0.46347 |
| IMF6 | 0.42903 |
| IMF7 | 0.41028 |
| IMF8 | 0.39685 |
| IMF9 | 0.38806 |
| IMF10 | 0.38830 |
| IMF11 | 0.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, K.; Cao, X.; Liu, B.; Guo, Y.; Tian, W. Ensemble Empirical Mode Decomposition with Adaptive Noise with Convolution Based Gated Recurrent Neural Network: A New Deep Learning Model for South Asian High Intensity Forecasting. Symmetry 2021, 13, 931. https://doi.org/10.3390/sym13060931
Peng K, Cao X, Liu B, Guo Y, Tian W. Ensemble Empirical Mode Decomposition with Adaptive Noise with Convolution Based Gated Recurrent Neural Network: A New Deep Learning Model for South Asian High Intensity Forecasting. Symmetry. 2021; 13(6):931. https://doi.org/10.3390/sym13060931
Chicago/Turabian StylePeng, Kecheng, Xiaoqun Cao, Bainian Liu, Yanan Guo, and Wenlong Tian. 2021. "Ensemble Empirical Mode Decomposition with Adaptive Noise with Convolution Based Gated Recurrent Neural Network: A New Deep Learning Model for South Asian High Intensity Forecasting" Symmetry 13, no. 6: 931. https://doi.org/10.3390/sym13060931
APA StylePeng, K., Cao, X., Liu, B., Guo, Y., & Tian, W. (2021). Ensemble Empirical Mode Decomposition with Adaptive Noise with Convolution Based Gated Recurrent Neural Network: A New Deep Learning Model for South Asian High Intensity Forecasting. Symmetry, 13(6), 931. https://doi.org/10.3390/sym13060931