1. Introduction
It is common to deal with data expressed as a proportion, percentage, rate or fraction in the continuous range
when analyzing certain random phenomena, for example, when observing the annual replacement rate related to blue collar workers [
1], the proportion of codling moth eggs that die from fumigation with methyl bromide [
2] and the percentage difference in nicotine levels in users of first and new generation e-cigarette devices [
3].
Two widely used probability distributions in data modeling such as those described above are the two-parameter beta (B) [
4] and Kumaraswamy (K) [
5] distributions. These distributions have a very flexible probability density function (pdf), presenting monotonic, unimodal and U shapes. Although these distributions are usually the first alternatives considered for modeling bounded data, it is possible to find in the statistical literature one-parameter distributions that can appropriately model datasets whose histograms show increasing or decreasing behavior. In this scenario, the power (P) distribution, which can be derived as a special case of the B and K distributions, and the Marshall–Olkin extended uniform (MOEU) [
6] and skew-uniform (SU) [
7] distributions, which are the result of the popular approach of adding a parameter to a baseline distribution in search of a more flexible distribution, can be considered viable alternatives.
A notable characteristic shared by these latter distributions is that the pdfs tend monotonically to finite values (functions of the parameters) at the extremes of the support, which in certain scenarios allows the extreme sample quantiles to be much more adequately modeled. However, on occasions, due to the curvature characteristics of the pdfs, the modeling of the most central quantiles may not be good, which in turn affects the quality of the fit of the extreme quantiles. Consequently, the performance of the P, MOEU and SU distributions is not good. In such a case, the B and K distributions, having two shape parameters, can properly model the most central quantiles due to the great flexibility exhibited by the pdfs in terms of curvature.
Motivated by the above, we formulate the following question as a starting point in this work: Based on the approach of adding parameters to a baseline distribution, is it possible to generate a parsimonious distribution that can perform better than the P, MOEU, SU, B and K distributions when modeling data whose histogram exhibits increasing or decreasing behavior?
To answer such question, we consider the Lambert-
F distribution generator [
8] defined by the cumulative distribution function (cdf) given by
, where
is a shape parameter,
is the Euler’s number and
is an arbitrary baseline cdf. This generator has the particularity that the inverse function, that is, the quantile function, can be expressed in closed form in terms of the Lambert
W function defined in
Appendix A. If the baseline distribution
is symmetric, it can be verified that
performs as a skewness parameter, allowing asymmetric shapes for the resulting pdf (for more details, see Iriarte et al. [
9]).
In this article, we introduce a new one-parameter distribution that is especially useful for modeling bounded data from a population whose pdf has a monotonic (increasing or decreasing) behavior. The proposal arises directly from the Lambert-F generator when considering a uniform (U) baseline distribution. We observe that the pdf of the proposed distribution, called the Lambert-uniform (LU) distribution, tends to finite values at the ends of the support, which in certain scenarios favors the good performance of the distribution. Consequently, the LU distribution may perform better in data modeling than the P, MOEU, SU, B and K distributions. We show that the LU distribution can be reparameterized in terms of its qth quantile. Thus, based on this result, we propose a regression model that relates the qth quantile of the response to a linear predictor through a link function. The proposed model can be considered as an alternative to quantile regression models available in the literature, such as the K quantile regression model, and performs adequately in scenarios where the histogram of the observed values of the response variable exhibits an increasing or decreasing behavior.
The article is organized as follows. In
Section 2, we propose the LU distribution, derive its main structural properties, describe the skewness and kurtosis characteristics and discuss the parameter estimation under the maximum likelihood (ML) method. In
Section 3, we propose the quantile regression model based on the LU distribution and discuss the estimation of the regression coefficients via the ML method. In
Section 4, the behavior of the estimators is evaluated in scenarios with and without covariates.
Section 5 presents three application examples illustrating the usefulness of the propose. Finally, the main conclusions are reported in
Section 6.
2. Lambert-Uniform Distribution
In this section, we define the Lambert-uniform random variable and derive the density, distribution and quantile functions.
2.1. LU Random Variable
Definition 1. A random variable X follows a Lambert-uniform distribution, with shape parameters , denoted as , if it can be represented aswhere is the principal branch of the Lambert W function and U is a uniform random variable. In Definition 1, taking into account that is a monotonic function, it is observed that X corresponds to a one-to-one transformation of the uniform random variable. Furthermore, it is observed that the analytic expression assumes values in the interval for all and , which means that X assumes values in this same interval.
Proposition 1. Let . Then, the cdf of X is given by , where and .
Proof. From Equation (
1), for
, we have that
Then, by definition of the Lambert
W function, it follows that
and the result is obtained taking into account that
, since
. Finally, note that the expression obtained is also valid for
, once
. □
The pdf of X can be obtained in a straightforward way from Proposition 1.
Corollary 1. Let . Then, the pdf of X is given by .
Consistent with Definition 1, it is observed that the cdf and the pdf of the LU distribution reduce to the cdf and the pdf of the U distribution when . Therefore, the LU distribution can be understood as an extension with one extra parameter of the U distribution.
The analytical description of the shapes for the LU pdf is simple and leads to establish that: (i)
and
. (ii)
is a constant function when
, a decreasing monotonic function when
and an increasing monotonic function when
. Property (i) shows that the pdf of the LU distribution converges to finite values (greater than 0) as
x tends to the extreme values, 0 and 1, of the support. From Property (ii), it follows that the LU distribution is appropriate to fit bounded data whose relative frequency shows increasing or decreasing behavior.
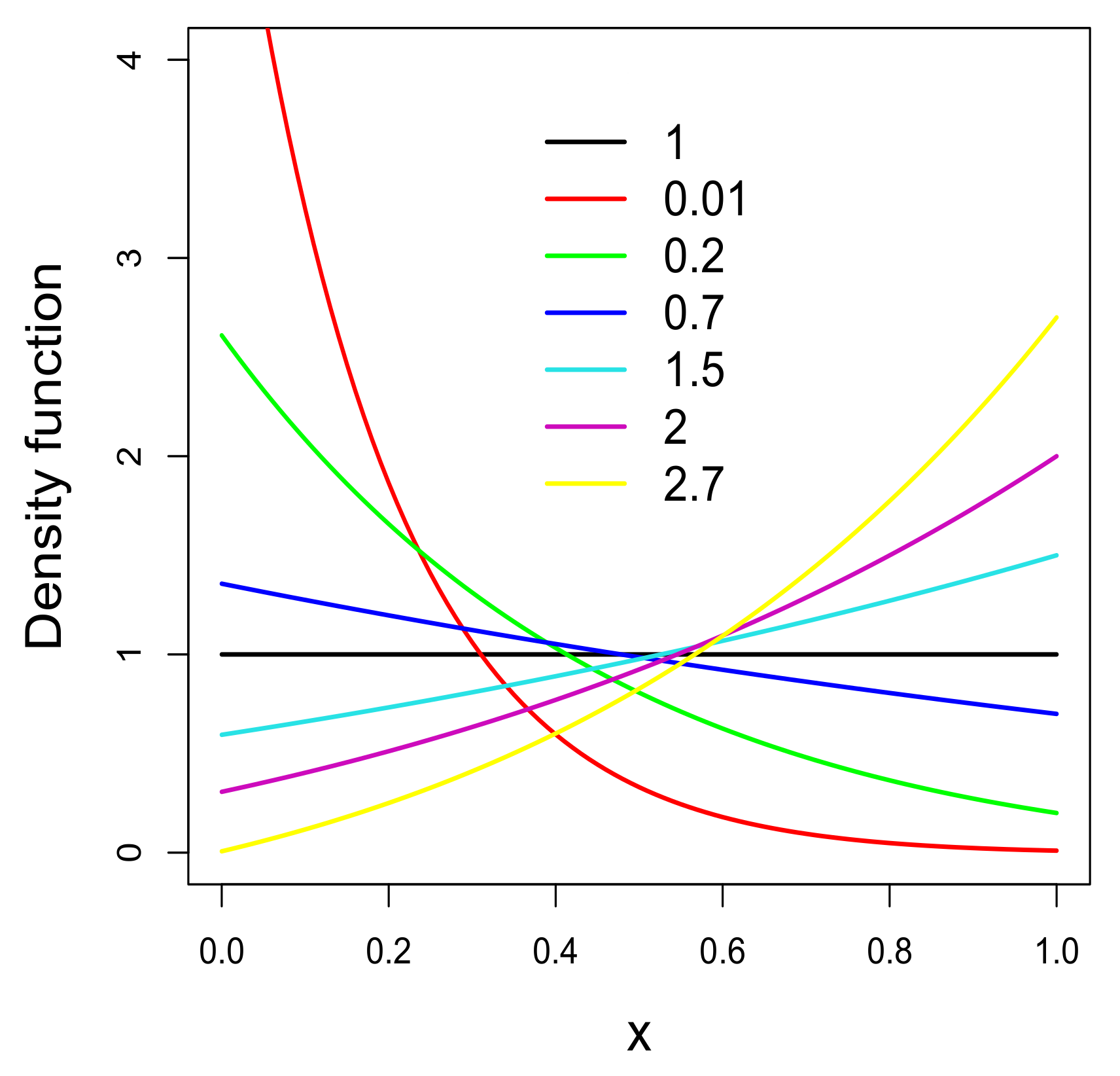
Figure 1 shows some pdf curves of the LU distribution for different values of the parameter
. Note that the behavior of the pdf curves is consistent with what is established above. In addition, note that the curvature of the pdf varies depending on its behavior at the ends of the support. Thus, the behavior of the LU pdf is similar to that of the P, MOEU and SU pdfs.
Note that, due to the behavior of the pdf at the ends of the support, the LU distribution may more adequately fit the extreme sample quantiles than a distribution whose pdf tends to
∞ and 0 at the ends of the support. In
Section 5, we see that the LU distribution may perform better in fitting data than the P, MOEU and SU distributions, even better than the two-parameter B and K distributions whose pdfs (in the monotonic case) tend to
∞ and 0 at the ends of the support.
Considering steps very similar to those of the proof of Proposition 1, the quantile function (qf) of the LU distribution can be easily derived by inverting the cdf given in Proposition 1. The resulting analytical expression for this function, for
, is given by
Since the Lambert
W function is implemented in different statistical software, Equation (
2) can be easily computed.
As a final consideration of this section, we highlight that the linear transformation , where , and , follows a LU distribution on the continuous range . Therefore, the LU distribution can be easily used to fit bounded data to any real range.
2.2. Related Distributions
It is well known that some distributions such as the exponential, Rayleigh and power, among others, can be derived as a transformation of a uniform random variable. Considering these transformations on a LU random variable, we derive the following distributions: (1) Let
, where
and
. Then,
Y follows the Lambert-exponential distribution, see Iriarte et al. [
8]. (2) Let
, where
and
. Then,
Y follows the Lambert–Rayleigh distribution (see Iriarte et al. [
8]). (3) Let
, where
and
. Then, the distribution of
Y is a two-parameter distribution that reduces to the P distribution when
. In this case, the pdf of
Y is given by
, where
. Thus, we refer to this distribution as the Lambert-power distribution.
Other distributions of the literature can be derived under consideration of appropriate transformations of LU random variables. Illustratively, we consider in this section only the three transformations described above.
2.3. Skewness and Kurtosis
In the following, a description of the skewness and kurtosis characteristics of the LU distribution is made by analyzing Fisher’s asymmetry and kurtosis coefficients. For this, the moment generating function is first calculated.
Proposition 2. Let . Then, in the case , the moment generating function of X is given by . In the case , the moment generating function is given by .
Proof. In the case
, the distribution LU reduces to standard U distribution, thus
. In the case
, we observe that
and the result is obtained considering the usual method of integration by parts and an appropriate algebra. □
Corollary 2. Let . Then, in the case , the first four raw moments of X are , , and . In the case , for , the first four raw moments are given by Corollary 3. Let . Then, in the case , the skewness () and kurtosis () coefficients assume the values 0 and 9/5, respectively. In the case , the coefficients are given bywhere , with , are as in Corollary 2. The skewness and kurtosis ranges for the LU distribution are and .
Figure 2 presents plots of the coefficients given in Corollary 3. The figure shows that the LU distribution is symmetric only in the case
, has positive skewness when
and has negative skewness when
. Furthermore, it is observed that the LU distribution can model kurtosis levels higher than the kurtosis level of the U distribution.
2.4. ML Estimation
For a random sample
, such that
, with
, the log-likelihood function is given by
where
is the mean of the observed sample. Thus, the score function is given by
From Equation (
4), it is observed that the ML estimator for
cannot be explicitly expressed. Therefore, the ML estimate of
must be obtained by solving the equation
by numerical procedures. The uniroot.all function available in the rootSolve package of the R programming language [
10] is a good option to tackle this task.
Since the ML estimator of does not have a closed form, a good alternative to obtain the ML estimate is to solve the optimization problem , subject to . To solve this problem, we use the optim function in the R programming language under the L-BFGS-B algorithm. This algorithm requires the specification of a value in the range of to initialize the iterative process. Through simulation experiments, we observe that the initial value is a good initial value.
The second partial derivative of the
function, with respect to
, is given by
Thus, under regularity conditions, we observe that the Fisher information is given by
The integral in Equation (
5) can be calculated by numerical integration, for example, the integrate function of the R programming language can be used. Then, under regularity conditions, the asymptotic distribution of
is
. Thus, the asymptotic standard error of
is given by
and the asymptotic
confidence interval for
is given by
, where
is the
upper quantile of the standard normal distribution.
3. Quantile Regression Model
In statistical modeling, the regression technique is used to quantify the relationship between the dependent variable (response) and one or more independent variables (covariates). In the case in which the interest lies in quantifying the effect on the conditional mean response, given the covariates, the classical least squares regression model and the generalized linear models are especially valued. These models have been shown to be very useful when analyzing data in various areas of knowledge. However, there are scenarios where it is equally or even more important to quantify the effect on some other measure such as the conditional median or some extreme conditional quantile of the response (see, e.g., [
11,
12]). In this scenario, a quantile regression model is appropriate because it allows quantifying the effect of the covariates on any conditional quantile of the response.
In the case of a continuous bounded range response, for example bounded to the range
, it is possible to use the well-known beta regression model (among others) to quantify the effect of the covariates on the mean response (see [
13]). Attractive alternatives to the beta regression model can be found in the literature (see, e.g., [
14]). On the other hand, from a quick review of the literature, we found the K [
15] and arc-secant-hyperbolic-normal (ASHN) [
16] regression models among the proposals for modeling the conditional quantiles of the response. In these last two models, we emphasize that the regression depends on a shape parameter that provides great flexibility and that must be estimated together with the regression coefficients.
A very good description of regression models for bounded response variables can be found in the work of Bayes et al. [
17], who proposed a mixed quantile regression model for bounded response variables.
In what follows, we propose a quantile regression model formulated from a reparameterized version of the LU distribution proposed in
Section 2.1. In this model, unlike the K and ASHN models, only the regression coefficients must be estimated. This is because it is formulated from a distribution with a single shape parameter that is linked to the linear predictor through an appropriate link function. We highlight that the performance of the proposed model is appropriate in scenarios where the histogram of the observed values of the response variable exhibits a decreasing or increasing behavior.
3.1. The LU Model
In Corollary 2, it can be seen that the mean of the LU distribution has a closed form. However, despite this, we observe that the shape parameter cannot be expressed explicitly as a function of the mean, which is a major drawback to formulate a regression model to quantify the effect of the covariates on the mean response. On the other hand, we observe that can be explicitly expressed as a function of the qth quantile, which allows reparameterizing the LU distribution in terms of its qth quantile and, consequently, formulate a quantile regression model in a simple way.
Denoting by
the
qth quantile of the LU distribution, from Equation (
2), we obtain that
. Thus, the LU distribution can be easily reparameterized in terms of the
qth quantile, obtaining (for
is known) the pdf given by
Let
be
n random variables and denote by
the observed values. Assume that each
has pdf
given in Equation (
6). The LU quantile regression model is defined by establishing that the
qth quantile
of
satisfies the functional relationship
,
, where
is the vector of covariates associated to the response
,
is a
k-dimensional vector of unknown regression coefficients and
is a strictly increasing and twice differentiable function that maps
into
(link function). For instance, the most useful well-known link functions are the logit, log-log and probit functions.
3.2. ML Estimation
From Equation (
6), the log-likelihood function is given by
and the score functions are given by
where
,
, with
. Note that
depends on the link function. For example, if the logit link is considered, that is,
, for
, then
, where
,
, with
,
.
We observe from Equation (
7) that the ML estimators for the coefficients
s cannot be expressed in closed form. Thus, the ML estimates must be obtained by solving the system of score equations using numerical procedures. In the R programming language, the multirrot function of the rootSolve package is a good alternative to solve this system of equations.
In this case, since the ML estimators do not have a closed form, a good alternative to obtain ML estimates is to solve the following optimization problem
,
,
, where
is given in Equation (
7). We solved this problem using the function optim of the R programming language and, specifically, the BFGS algorithm was applied.
Under regularity conditions, the asymptotic distribution of
is
, where
is the expected information matrix. Since the function
is not simple, it is not easy to obtain the analytical expression of this matrix. However, we obtain an approximation from the observed information matrix, whose elements are computed as minus the second partial derivatives of the log-likelihood function with respect to all the parameters (evaluated at the ML estimates). Thus, the observed information matrix is given by
where the second derivatives are presented in
Appendix C.
5. Data Analysis
In this section, three application examples are presented in order to illustrate the usefulness of the LU distribution and the LU quantile regression model. In the first, we compare the performance of the LU, P, MOEU, SU, B and P distributions in the fitting of 1000 samples generated from an LU population. Here, we highlight the virtues of the LU distribution over the aforementioned distributions, leaving open the existence of a possible real-world setting where the distributions show such performance. In the second example, we compare the performance of the LU, P, MOEU, SU, B and P distributions in fitting a real dataset. In the third example, based on a real data frame, and in order to quantify the effect of the covariates on the 0.25th, 0.5th and 0.75th quantiles of the response, we compare the performance of the LU quantile regression model with the performance of other models such as ASHN [
16] and K [
15] quantile regression models. In all three models, the logit function is considered to relate the
qth quantile of the response to the linear predictor. The pdfs of the ASHN and K distributions are given, respectively, by
where
,
,
is the hyperbolic arcsecant function,
is a shape parameter,
is a quantile parameter and
is known, and
where
is a shape parameter,
is a quantile parameter and
is known.
The regression framework for bounded responses based on the K and ASHN distributions is very similar to the regression framework based on the LU distribution presented in
Section 3.1. However, the main difference with LU regression is that it depends on a shape parameter that gives great flexibility to the modeling.
In all three examples, the parameters are estimated by maximizing the corresponding likelihood functions with the optim function in the R programming language. We compared the performance of the models by contrasting the maximum value of the log-likelihood function (
ℓ) and contrasting the values associated with the Akaike Information Criterion (AIC) [
19] and the Bayesian Information Criterion (BIC) [
20]. In general, the best model can be chosen as the one that shows the highest
ℓ value and the lowest AIC, CAIC and BIC values. In addition, we consider the usual Anderson–Darling (AD) and Cramer–von Mises (CvM) goodness-of-fit tests to assess the quality of the fits in the first and second examples. In the third example, we use these tests to assess the overall quality of fit of the regression models, by testing the hypothesis that the randomize residuals [
21] follow the standard normal distribution. These residuals follow a standard normal distribution when the overall quality of fit is appropriate. We use the ad.test and cvm.test functions available in the goftest [
22] package in the R programming language to calculate the statistics and
p-values of these tests.
5.1. Data from an LU Population
In this example, we generate 1000 random sample of size 300 from an LU population with parameter . The chosen value for is associated with a decreasing pdf that converges to the values 5.605 and 0.01 at the ends of the support.
Based on the AD and CvM goodness of fit tests, considering a significance level of 5%, we calculate the proportion of samples where the LU, P, MOEU, SU, B and K distributions fit the data appropriately. We call this the non-rejection rate. Additionally, we calculate the proportion of samples where each distribution presents the lowest AIC and BIC values, that is, the proportion of samples where each distribution exhibits the best performance. We call this the hit rate.
Table 1 reports the values associated with the non-rejection and hit rates for the LU, P, MOEU, SU, B and K distributions fitted to the 1000 samples. In the table, we observe that the two-parameter B and K distributions are capable of appropriately fitting a large proportion of samples. However, the LU distribution better fit most of the samples generated.
Calculating
for each fitted distribution in a single generated sample, we observe the limit value 5.611 for the LU distribution, 7.618 for the MOEU distribution, 2.000 for the SU distribution and
∞ for the B, K and P distributions. Now, calculating
, we observe the limit values 0.009 for the LU distribution, 0.131 for the MOEU distribution, 0.438 for the P distribution and 0 for the SU, B and K distributions. In
Figure 7, the histogram for this sample fitted with the LU, P, MOEU, SU, B and K distributions is presented. Here, it can be seen that the curvature characteristics of the LU, B and K pdfs are similar, exhibiting a similar performance in the fit of the most central sample quantiles. However, the LU pdf more appropriately fits the more extreme quantiles by tending to the values 5.611 and 0.009 at the ends of the support. The ML estimates, the AIC and BIC values and the p-values of the AD and CvM tests for each distribution fitted to this sample can be consulted in
Appendix E.
The analysis considered in this section suggests the possible existence of a real world scenario in which such performances are displayed.
5.2. Peak Horizontal Acceleration Data
We consider a dataset consisting of 182 observations on the peak horizontal acceleration (g) in earthquakes recorded by observation stations in California, USA. These data were originally analyzed by Joyner and Boore [
23] and can be found with the name attenu in the dataset package of the R programming language. Some descriptive statistics are the following: minimum, 0.003; maximum, 0.810; skewness, 1.641; and kurtosis, 6.071. The histogram of this dataset, presented in
Appendix D, shows a decreasing behavior. Thus, we hope that the LU distribution can properly fit the peak horizontal acceleration data.
Table 2 reports the ML estimates, the
ℓ, AIC and BIC values and the
p-values of the AD and CvM goodness of fit tests for each distribution fitted to the peak horizontal acceleration data. In this table, based on
p-values, considering a significance level of 5%, we observe that the SU and P distributions are not appropriate to fit the peak horizontal acceleration data. Note that the MOEU, SU, P and LU distributions are uni-parametric, however the performance shown by the LU distribution is clearly better. We also observe in
Table 2 that the LU distribution is the one with the lowest AIC and BIC values and the one with the highest
ℓ value, evidencing that this distribution must be selected over the others for the fit of the peak horizontal acceleration data.
Figure 8 presents the qqplots for the fitted distributions. This figure shows that the LU distribution fits the peak horizontal acceleration data appropriately.
Calculating for each fitted distribution, we observe the limit value 6.298 for the LU distribution, 8.923 for the MOEU distribution, 2.000 for the SU distribution and ∞ for the B, K and P distributions. Now, calculating , we observe the limit values 0.005 for the LU distribution, 0.112 for the MOEU distribution, 0.412 for the P distribution and 0 for the SU, B and K distributions. This illustrates that the performances exhibited by the LU, P, MOEU, SU, B and K distributions over this dataset are very similar to the performances exhibited in the previous section based on simulated data.
5.3. Risk Managements Practice Data
In this example, we consider the data frame presented by Schmit and Roth [
24] consisting of observations of seven variables (73 observations for each variable) consulted by means of a questionnaire sent to 374 risk managers of large US-based organizations. The variables consulted are described below: FI represents the measure of the firm’s risk management cost effectiveness, defined as total property and casualty premiums and uninsured losses as a percentage of total assets; AS represents the per occurrence retention amount as a percentage of total assets; CA indicates that the firm owns a captive insurance company; SI represents the logarithm of total assets; IN represents a measure of the firm’s industry risk; CE represents a measure of the importance of the local managers in choosing the amount of risk to be retained; and SO represents a measure of the degree of importance in using analytical tools.
Gómez-Déniz et al. [
25] considered a Log-Lindley regression model to quantify the effect of the variables AS, CA, SI, IN, CE and SO on the mean of the variable FI. In our case, we consider the LU quantile regression model to quantify the effect of such covariates on the 0.25th, 0.5th and 0.75th quantiles of the variable FI, providing a very informative scenario (which complements the one proposed by Gómez-Déniz et al. [
25]) to explain the behavior of the FI response in terms of the covariates already described. We observe that the histogram of the variable FI, presented in
Appendix D, shows a decreasing behavior. Thus, we hope that the LU model can appropriately quantify the effect of the covariates on the 0.25th, 0.5th and 0.75th quantiles of the response variable.
As already mentioned, we compare the results with those obtained with the K and ASHN quantile regression models. The regression structure assumed for is given by , where denotes the qth quantile of the LU, K and ASHN distributions.
Table 3 reports the
ℓ, AIC and BIC values for the ASHN, K and LU models fitted to the risk managements practice data. The
p-values of the AD and CvM tests of the hypothesis that the randomize residuals follow a standard normal distribution are also reported in
Table 3. In this table, we see that the
ℓ, AIC and BIC values change as the value of
q changes. This shows that the rate of change in the conditional quantile of the response FI, expressed by the regression coefficients, depends on the value of
q. On the other hand, based on the
p-values and considering a significance level of 5%, we observe that the assumption of normality of the randomize residuals of the LU and K models is not rejected. Thus, under this significance level, the global fit of these models is appropriate. Furthermore, we observe that the LU model is the one with the highest
ℓ value and the one with the lowest AIC and BIC values, suggesting that this model should be selected to quantify the effect of the covariates on the 0.25th, 0.5th and 0.75th quantiles of the response. As already pointed out in
Section 3, keeping in mind that, in the K and ASHN models a shape parameter must be estimated together with the regression coefficients, with one fewer parameter to estimate, the LU quantile regression model performs more appropriately than these models.
Table 4 reports the estimates for the coefficients of the LU models fitted to the risk managements practice data. In addition, the
z statistics and the
p-values of the significance tests of the individual regression coefficients are reported. Here, we observe that the covariates SI and IN (the logarithm of total assets and the measure of the firm’s industry risk) are statistically significant at usual nominal levels. Additionally, it is important to point out that there is a negative relationship between the 0.25th, 0.5th and 0.75th quantiles of the response (the firm’s risk management cost effectiveness) and the covariate SI, while there is a positive relationship between the 0.25th, 0.5th and 0.75th quantiles of the response and the covariate IN. On the other hand, the covariates AS, CA, CE and SO are not significant.
Figure 9 shows the estimates of the coefficients with the 95% confidence intervals of the LU regression model assuming different values for
q. Here, we observe that the estimates of the coefficients of the covariates SI and IN decrease and increase, respectively, distancing themselves more and more from the value 0 as
q increases. This illustrates a greater effect of these covariates on the high quantiles of the firm’s risk management cost effectiveness.
6. Final Comments
In this article, we propose a new one-parameter distribution for the modeling of bounded data whose histograms show increasing or decreasing behavior. The new distribution, called the Lambert-uniform distribution (LU), arises from the Lambert-F generator considering a U baseline distribution. An important aspect to highlight about the LU distribution is that its pdf tends to finite values at the ends of the support, which allows the extreme sample quantiles to be adequately modeled.
We derive the main structural properties of the LU distribution, including the moment-generating function that is used to describe the skewness and kurtosis characteristics. The quantile function of the LU distribution can be expressed in terms of the Lambert W function, which allows reparameterizing the pdf in terms of its qth quantile, resulting in a pdf with a simple, easy to compute analytical structure. Thus, we propose the LU quantile regression model that relates the qth quantile of the response to a linear predictor through a link function. The parameter estimation for the cases with and without covariates is performed with the maximum likelihood method. The estimators of the parameters do not have a closed form, so the use of some computational routine is required to obtain the estimates. We use the optim function in the R programming language to obtain the estimates. We evaluate the behavior of the estimators through two simulation studies, concluding that the maximum likelihood method provides acceptable estimates. Finally, we present three application examples in order to illustrate the usefulness of the proposal. In the first and second examples, considering datasets whose histograms show decreasing behavior, we illustrate that the LU distribution may present a better fit than the P, MOEU, SU, B and K distributions. Thus, in scenarios where the data exhibit such behavior, the LU distribution can be considered a viable alternative to commonly used distributions. In the third example, based on a real data frame, we illustrate that a quantile regression model formulated from the LU distribution performs well when modeling the 0.25th, 0.5th and 0.75th quantiles of the response (given a set of covariates), being a viable alternative to the other models such as the ASHN and K quantile regression models.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}