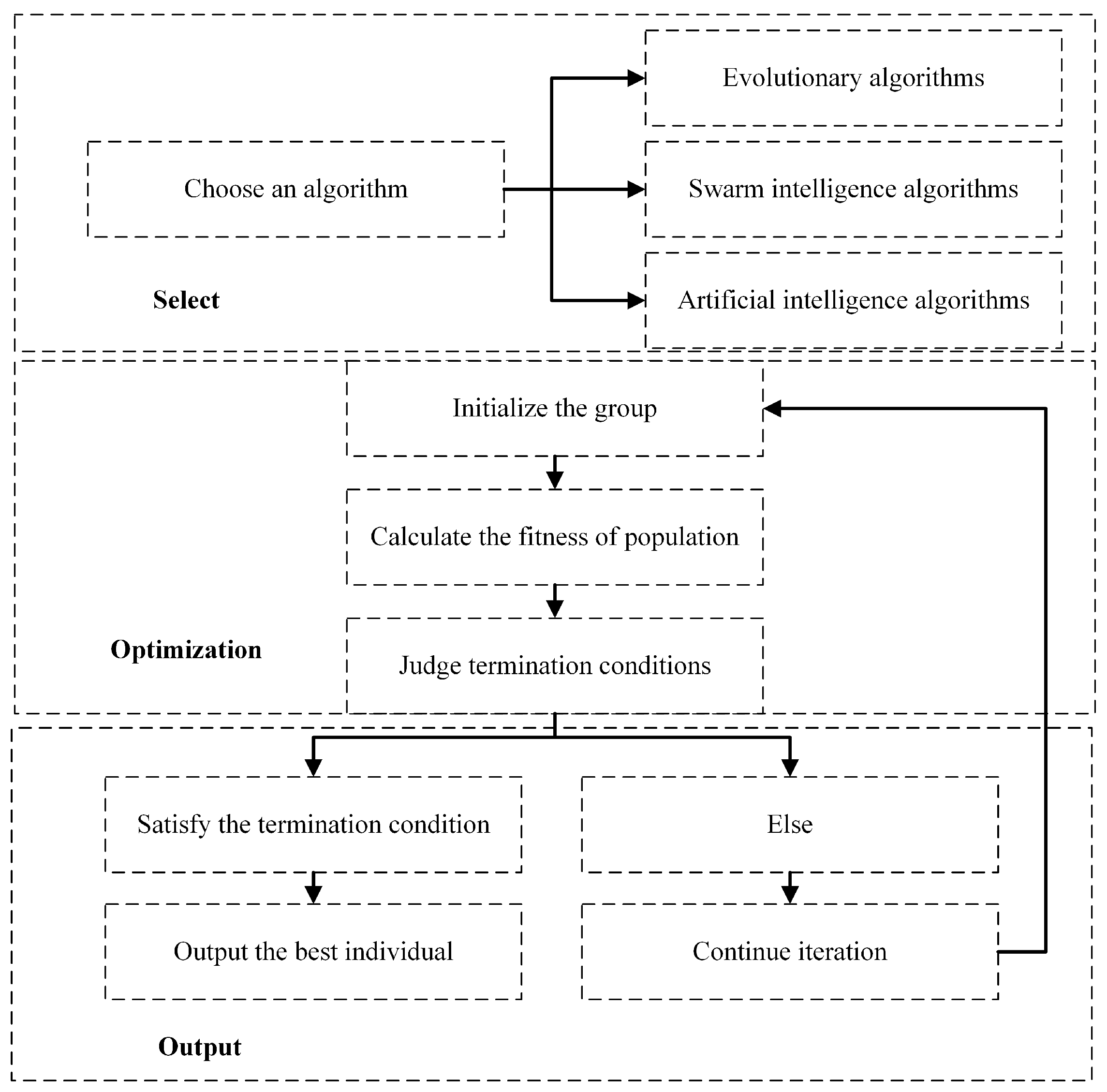
Feature selection is an important step in processing classification tasks and in the pre-processing phase of data mining, with the aim of improving the accuracy of the classifier. In order to verify the performance benefits of the proposed algorithm, we apply it to the Android malicious application detection problem and propose a framework process to solve the problem.
4.1. Android Malicious Application Detection
With the continuous advancement of time and the increase in the number of third-party application markets, many researchers have explored the detection methods of Android malicious applications from a software perspective to achieve the purpose of protecting system stability. In this paper, we focus on solving the security problem at the application level of Android by compiling the corresponding feature sets based on the source code information obtained by the decompiler tool and feeding them into the classifier model for training to classify benign and malicious applications. Due to the high dimensionality of the acquired feature attributes, it inevitably causes a dimensional disaster or increases the time and space complexity of model training, which affects the efficiency of Android malicious application detection. It is vital to choose a suitable feature selection method to reduce the number of features while improving the accuracy of the classification model.
Malicious application detection methods are frequently updated and changed with the deepening of research. The main research trends are in the following two aspects: one is based on the improvement of a single machine learning classification algorithm; the other is based on the study of feature selection methods. Machine learning methods are currently the most widely used technical means in the artificial field. The classification methods in supervised learning play a driving role in the detection of Android malicious applications (such as the KNN algorithm, Naive Bayes algorithm, Logistic Regression, and Decision Tree algorithm). The disadvantage is that the training model speed needs to be improved, and it can only make a simple judgment of the malicious software that has already appeared on the market and cannot realize the detection of unknown types of applications. Feizollah A, Nor B, Salleh R et al. [
26] evaluated the performance of K-means and Mini batch K-means clustering algorithms in Android malware detection and analyzed the network traffic of benign and malware on two algorithms. The result showed that the overall performance of the Mini batch K-means clustering algorithm was better than the K-means algorithm. Nath, Hiran V et al. [
27] applied the classification algorithm in machine learning to features such as n-gram model and byte sequence extracted from malware. The algorithm included classification methods such as decision trees and boosted decision trees. The results proved the machine learning classification algorithm could realize the simple classification of malware. However, only using machine learning algorithms to judge the quality of the application is slightly thin. Rajesh Kumar et al. [
28] proposed a method based on the combination of probabilistic statistical analysis and machine learning algorithms to reduce the dimensionality of features and achieved classification between known and unknown benign and malicious software.
Android malicious application detection based on feature selection method is divided into static analysis and dynamic analysis methods [
29]. Static analysis involves obtaining the source code of an Android application by decompiling software without running the application, analyzing it to extract relevant syntactic and semantic information, permission information in configuration files, intent, the corresponding API calls, etc., coding and mapping its code integration into vector space, and combining it with machine learning classification in order to achieve malicious application classification. In contrast, dynamic analysis is similar to the black-box testing of software. The source code structure is not taken into account, and only relevant features are obtained during the installation or use of the application, such as network traffic analysis, application power consumption, user behavioral features. Dynamic analysis has the advantage of a large feature selection space and a wide range of input classifiers. For example, Zarni Aung et al. [
30] extracted single permission as a feature for training, designed and implemented a framework based on machine learning technology classify malware and benign software. Shanshan Wang et al. [
31] conducted an in-depth study on the behavior of network traffic generated by the application during use, mapped the mobile terminal traffic information flow to the server-side, analyzed the network traffic characteristics, and combined the C4.5 algorithm to complete the detection of malicious applications. Du W, Yin H et al. [
32] proposed a method to describe Android malware that relied on API calls and package-level information in bytecode and determined the category of unknown application software based on known Android malicious applications. Compared with the classifier based on permission features, the KNN classifier’s accuracy was as high as 99%. Daniel Arp et al. proposed a lightweight detection framework: Drebin [
33]. This method extensively collected application characteristics (permissions, hardware combinations, etc.) obtained from static analysis and mapped them to the joint vector space, using traditional PCA to reduce dimensional method selection features. The biggest advantage of this framework is the ability to identify malicious applications on smartphones directly. Wang W, Gao Z, Zhao M et al. [
34] proposed an Android malicious application detection model: DroidEnsemble. The classification features in the model analyze static string features such as permissions in each application code pattern and include structural feature s such as control flow graphs and data flow graphs, such as function call graphs. The results of classifying these two types of features show that the model’s detection accuracy is greatly improved, while the false alarm rate is also reduced. The approach based on feature selection has certain advantages, but it can lead to the high dimensionality of the feature combinations, leading to the high complexity of the algorithm’s training process in space and time and affects the accuracy of the machine learning and data mining methods. Therefore, the selection of features with good detection performance is key to the method.
4.3. APK Pre-Processing
The Android application package (APK) of the third-party application market is not presented in source code but is similar to the packaged file format (zip). In order to obtain the information in the package, it is necessary to use a decompiler tool to realize the pre-processing of APK decompression. The tool used in this article, Apktool [
37], is a lightweight decompilation tool, a closed binary Android application tool, which can decode resources and applications into the most primitive state of java source code, and automatically realize file structure processing. It can be used locally and supports multiple platform analysis applications. As shown in
Figure 11 is the file resource list obtained by decompiling a real Android application using this apktool tool.
After decompiling the APK, it can see the permission information in the total configuration file Androidmanifest.xml.
Figure 12 shows a partial list of permissions for a test APK.
P is the total set of possible permissions that some applications in the android platform can request. Moreover, each android application is represented in the framework of the required permission set. Therefore, assuming that the size of
P is
N, each application is represented by a binary string
p of size
N, where each position
i of the string represents the i-th permission in a set of possible permissions, so that
. If the application does not need permission
i, then
; if the application requires permission
i, then
.
4.4. Coding
When classifying Android malware, permission features are binary coded in such a way that if total permission sets of Android applications are defined as P, then the permissions applied by each software are , coded one by one, and if a feature in permission set P appears, then a permission bit in N is flagged as 1, otherwise it is 0. An example of matching permissions for a single application is shown below:
0,0,0,0,0,0,0,0,0,0,0,1,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,1,0,0,0,1,0,0,1,0,0,0,0,0,1,0,0,1,0,0,0,0,1,0,1,1,0,0,0,1,1,0,0,0,0,0,1,0,1,0,1,0,0,0,0,0,1,0,1,1,0,0,1,0,1
There are 88 permission bits in this example. The exact number of settings is described in the numerical experiments section. When each benign application is developed, the permissions applied are very few (compared to the official permission set). The number of “1” s in the gene position of each chromosome is relatively small. The number of permissions requested by malicious applications is greater than or equal to that of benign applications.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}