3.1. Simulation Study
With high correlated and non-normal simulated data, we want to compare the
r control charts for binary response regression models introduced in the
Section 2. So we need to generate high correlated and non-normal simulated data denoting
as input variables.
Because of relaxing the assumptions of normality, linearity and independence, copulas have been popular in the research areas of biostatics, econometrics, finance and statistics over the last three decades. A copula is a statistical method to find the dependence structure of multivariate data. By using the copula, we can have the marginal behavior of a random variable and the joint dependence of two random variables. Every joint distribution can be expressed by as where and are marginal distributions.
A bivariate copula is a function , whose domain is the entire unit square with the following three properties:
- (i)
;
- (ii)
;
- (iii)
, such that and where and , .
See [
26,
27] for the definitions of the copula in detail. To construct a highly correlated dependence structure of input variables, we employed two Archimedean copula functions. One is the Clayton copula with a dependence parameter equalling to 3 and the number of dimensions equal to 30, and the other is the Gumbel copula with a dependence parameter equal to 30 and the number of dimensions equalling to 30.
The reason of choosing the Clayton and the Gumbel copulas for generating simulated data in this research is that the Clayton copula is an asymmetric Archimedean copula, exhibiting greater dependence in the negative tail than in the positive and the Gumbel copula is an asymmetric Archimedean copula, exhibiting greater dependence in the positive tail than in the negative.
We generate a random sample of 1000 observations from each copula. The random sample is assigned to as input variables. With each simulated random sample data , we define the coefficients of parameters (’s) to be , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , so that which passes through an inverse logit function. Then, we generate the response variable y randomly by using the Bernoulli distribution with the probability with sample size 1000.
For the one (‘1’) inflated case of binary response data, we added 0.1 to the probability , such as , and for the zero (‘0’) inflated case of binary response data, we subtracted 0.1 from the probability , such as . Additionally, is used for the in-control dispersion case.
In each setup, we perform 1000 different replications of sample size of 1000.
Table 1 shows the simulation results. With the simulated data, 70% of data were assigned to the training data and 30% of data were assigned to the test data.
We apply the BVS, PCS, and NLPCS to input variables
and then we fit the binary response regression model by using the binary response variable
y and the important selected variables or the principal components or the whole data through the probit link function, logit link function, and neural network or deep learning regression models, respectively. We used the ‘nnet’ R packge [
23] for feed-forward neural networks with a single hidden layer with 30 neurons by using ‘predict’ command, and for the deep learning model, we used the ‘deepnet’ R packge [
24] with the backpropagation (BP) algorithm for training feed-forward neural networks with double hidden layers and (15, 15) neurons by using the ‘nn.predict’ command.
where Root MSE = root mean squared error,
,
number of observations,
, and
predicted value of
observations.
By using the Root MSE Formula (
5), we performed the Root MSE of each simulated in-control data of sample size 1000 with 1000 repetitions in
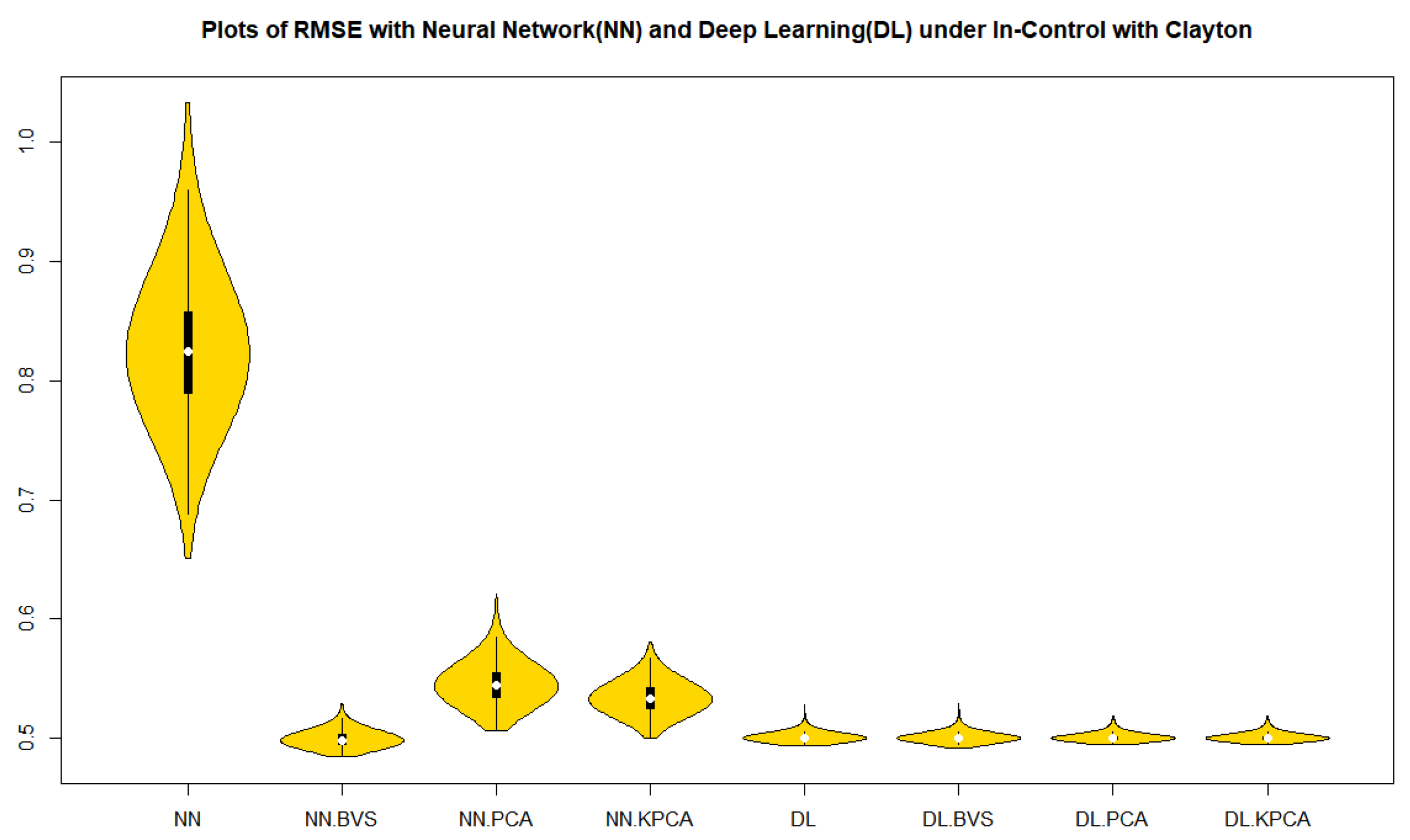
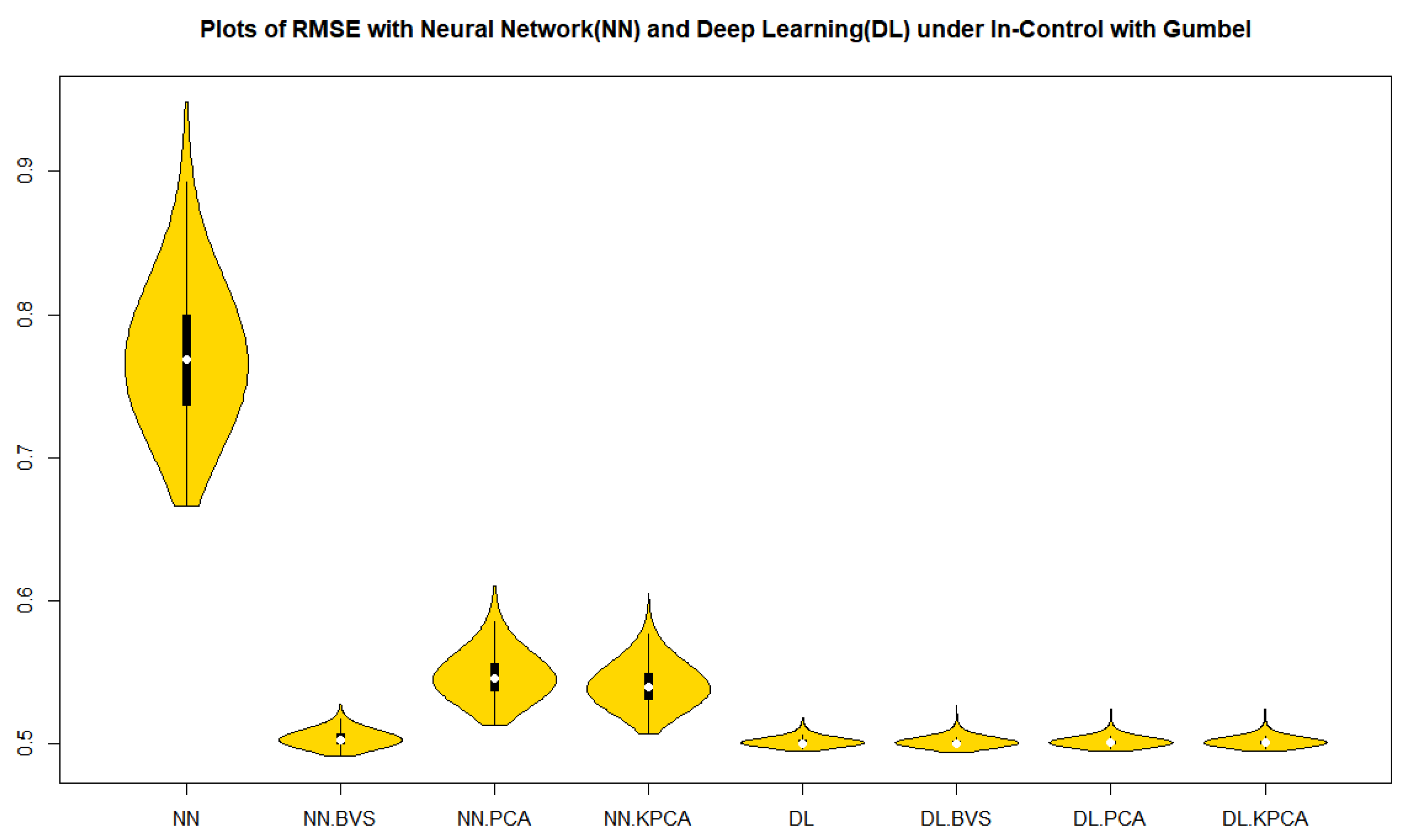
Table 1. It is a surprising result that the
r-chart based on the deep learning models with BVS, PCS, NLPCS and whole data for both the Clayton and the Gumbel copulas show a superiority to all other cases in
Table 1 in terms of the accuracy and precision by mean, median, and interquartile range (IQR).
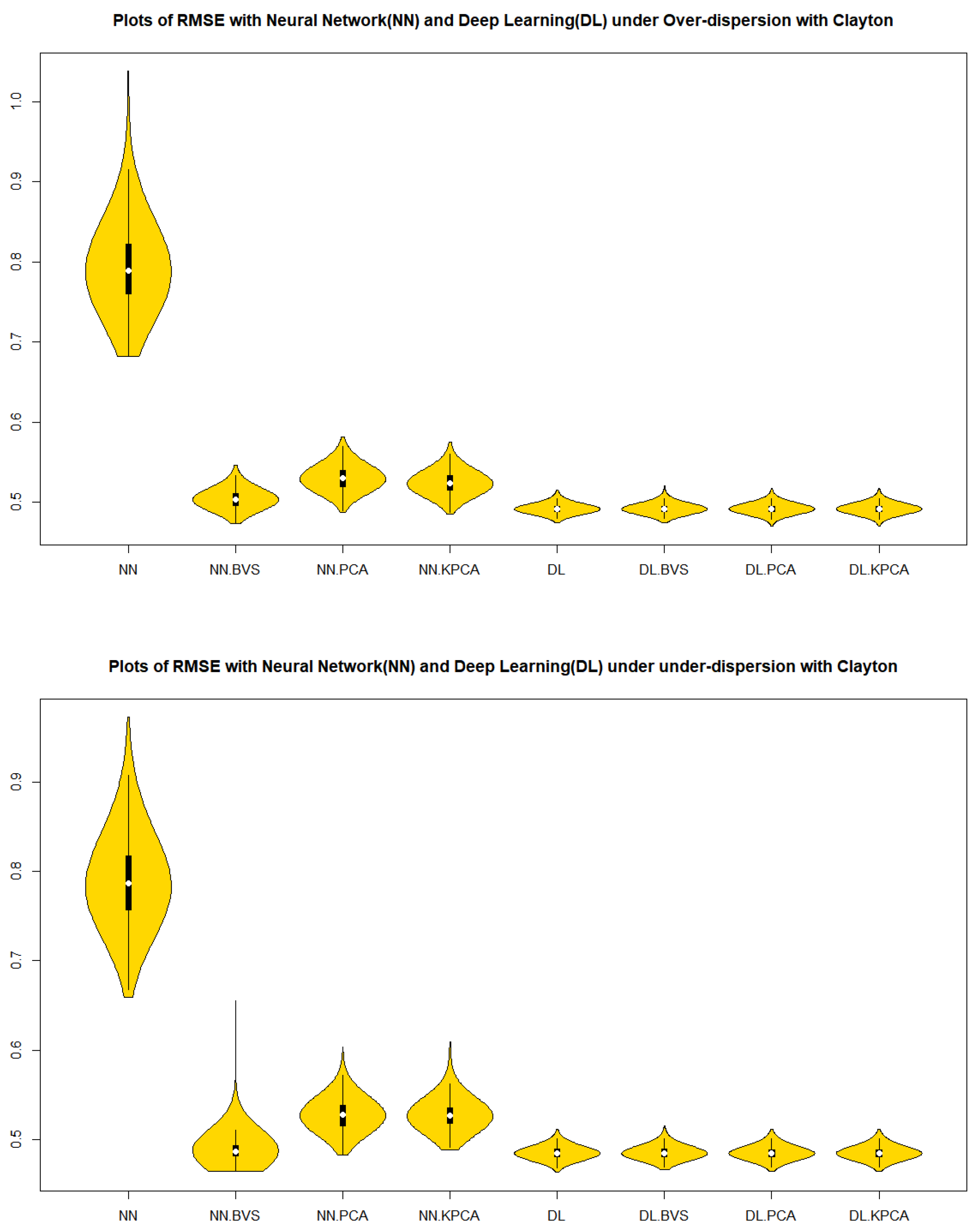
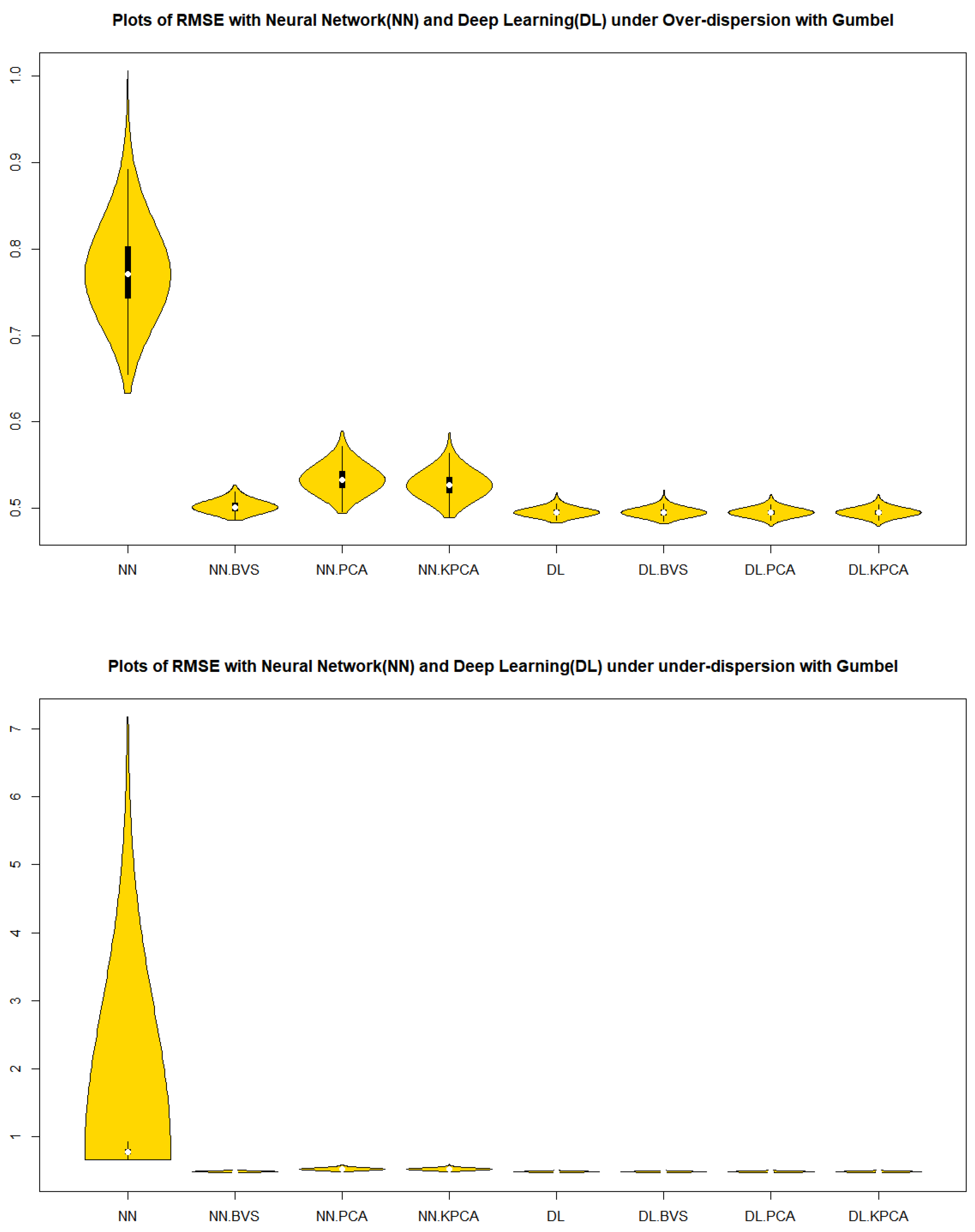
From
Figure 1 and
Figure 2 in cases of the in-control, over dispersion and under dispersion, we can observe that the residuals of deep learning regression models with BVS, PCS, NLPCS, and whole data for both the Clayton and Gumbel copulas show a superiority over the neural network regression models with BVS, PCS, NLPCS, and whole data in
Table 1 in terms of the precision by a measure of spread, IQR.
With three cases of the in-control, over dispersion, and under dispersion in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7, we apply the BVS, PCS, and NLPCS to input variables
and then we fit the binary response regression model by using the binary response variable
y and the important selected variables or the principal components through neural network or deep learning regression models, respectively. By using the deviance residuals for each model and (
4) for
, we compute the lower control limit (LCL) and upper control limit (UCL) for the process. The expected length of the confidence interval is computed by the average of the length of control limits. The coverage probability is the proportion of the deviance residuals contained in the control limits. The lower control limit and the upper control limit value for the
r-chart are calculated by means of
y minus and plus its one, two, and three standard deviations.
Mainly, we compare the results for the deep learning regression model and neural network regression model based on BVS, PCA, NLPCA, and whole data because [
6] showed that the neural network regression model (Nnet) outperformed the GLMs with probit and logit link functions based on PCA. We found that, for the in-control case, the one-inflated case, and zero-inflated case, the expected lengths of the confidence interval on the deep learning regression model (DL) based on BVS, PCA, NLPCA, and whole data are shorter than in all other cases of Nnet in
Table 2,
Table 3,
Table 4 and
Table 5 while, in terms of the coverage probability, the DL is keeping overall higher than the neural network regression model (nnet).
In terms of the ARLs, the coverage probability and the expected length of the confidence interval, we note that the r-chart based on the DL based on whole data for monitoring observations is about the same as the r-chart based on the DL based on BVS, PCA, and NLPCA.
3.2. Real Data Analysis
For the real data application, we used Wisconsin breast cancer data in the R package ‘mlbench’ [
23]. The objective of collecting the data was to identify a number of benign or malignant classes. Samples arrive periodically as Dr. Wolberg reports his clinical cases. The database, therefore, reflects this chronological grouping of the data. This grouping information appears immediately below, having been removed from the data itself. Each variable except for the first was converted into 11 primitive numerical attributes with values ranging from 0 through 10. There are 16 missing attribute values. A data frame contained 11 variables ((1) Id (Sample code number), (2) Cl.thickness (Clump Thickness), (3) Cell.size (Uniformity of Cell Size), (4) Cell.shape (Uniformity of Cell Shape), (5) Marg.adhesion (Marginal Adhesion), (6) Epith.c.size (Single Epithelial Cell Size), (7) Bare.nuclei (Bare Nuclei), (8) Bl.cromatin (Bland Chromatin), (9) Normal.nucleoli (Normal Nucleoli), (10) Mitoses, (11) Class), one being a character variable, 9 being ordered or nominal, and 1 target class.
By using the R package ‘missForest’ [
28], we imputed the missing data in the Wisconsin breast cancer data. We set the target variable (
y) to be Class (“malignant” = 0, “benign” = 1) and 9 input variables except for Id and Class variables in the Wisconsin breast cancer data. We also used the ‘nnet’ R packge [
23] with a single hidden layer with 30 neurons by using ‘predict’ command, and for deep learning model, we used the R packge ‘deepnet’ [
24] with double hidden layers and (15, 15) neurons by using ‘nn.predict’ command on the Wisconsin breast cancer data. By using the Root MSE formula (
5), we performed Root MSE of each random sample data of sample size
out of the total number of data (683) with 1000 repetitions in
Table 6. It confirms that the
r-chart based on the DL models with BVS, PCS, NLPCS and whole data show a superiority to all other cases in Nnet models in
Table 6 in terms of the accuracy and precision by mean and interquartile range (IQR).
The expected lengths of the confidence interval on the DL-based on BVS, PCA, NLPCA, and whole real data are shorter than in all other cases of Nnet in
Table 7 while, in terms of the coverage probability, DL is overall keeping higher than the Nnet. In terms of the ARLs, the coverage probability and the expected length of the confidence interval, we note that the
r-chart based on the DL based on whole real data is about the same as the
r-chart based on the DL based on BVS, PCA, and NLPCA.
Therefore, from the simulation study and real data analysis, we confirmed that the DL based r control chart for binary response data on BVS, PCA, NLPCA, and whole real data are superior to the Nnet-based r control chart for binary response data on BVS, PCA, NLPCA, and whole data in terms of the accuracy, precision, coverage probability, and expected length of the confidence interval.









{kind=link}
{kind=link}
{kind=link}
{kind=link}