1. Introduction
Random number and bit sequence generation is important in the development of many fields in science and technology, such as physics [
1], biology [
2], computational finance [
3], nanostructures [
4], semiconductors [
5], security [
6], data science [
7], etc. It plays a fundamental role in the application of the Monte Carlo methods in those environments where a random behavior is apparent and stochastic simulation becomes essential [
8,
9,
10].
Random number generators can produce number sequences based on sources of randomness, which can be either internal or external to the computer implementing such random generator. In the latter case, one or several natural physical phenomena can be sampled, combined, and processed, including sources such as particle duration in radioactive processes, thermal noise in an electrical resistor, noise from inactive microphones or cameras, frequency instability in an oscillator, etc. When the source of randomness is contained within the computer, resources such as the system clock, the frequency of key presses, the contents of input/output buffers, operating system statistics including processor load or memory usage, and even hard drive or network device latency are combined to distill enough randomness [
11].
Despite their name, true random generators can have some drawbacks, such as the sequence being significantly skewed, having excessive autocorrelation and, especially, that the generated sequence cannot be easily reproduced. In the case of stochastic simulation and Monte Carlo methods, it is much more convenient to employ deterministic algorithms that produce sequences that are, in practice, indistinguishable from true random sequences and can be perfectly reproduced as a function of the input or seed; these are known as pseudo random generators (or PRNGs) and, although the generated sequences are not genuinely random, they behave as such for all practical purposes [
12,
13,
14].
When employing pseudo random generators in simulation and Monte Carlo methods, the sequences produced must present long periods and a good statistical distribution, to be unpredictable. If an algebraic description of the properties of the sequences generated by a pseudo random generator is not possible (which is a fairly common occurrence), we have to resort to several statistical suites (batteries of tests) that can help detect possible uniformity deviations or dependencies [
15,
16]. One of the most popular and complete libraries is TestU01, that extends upon classical suites and includes several preconfigured groups of tests called SmallCrush, Crush and BigCrush [
17]. In a similar fashion, PracRand [
18] is also very popular and comprehensive.
The main contributions of this paper are based around the proposal of a new nonlinear filter design that can significantly improve the randomness characteristics of the sequences generated by common pseudo random generators. The results obtained by this new filter are excellent, presenting negligible performance overhead and completely correcting all defects present in the unfiltered sequences; even when using a simple counter (a completely nonrandom source) as a pseudo random generator. Due to its evolving internal state, the period of the filtered sequence is much longer than that of the input, which can be useful in cases where very long sequences are required. Furthermore, although our main focus in this paper are pseudo random sequences, the proposed filter can be also successfully applied to true random sequences without any modification.
The proposed design, although nonlinear and complex in nature, remains symmetric (balanced) in terms of the probability of each bit of the sequence, guaranteeing that all output values are equally probable. Moreover, its design employs certain concepts borrowed from symmetric ciphers [
19], such as an initialization stage, seed (or key) dependent construction and the combination of different types of operations.
The main motivation of the proposed filter design is improving the quality of pseudo random sequences, not just in terms of statistical randomness, but also in terms of unpredictability and nonlinearity, which are extremely important for applications in the fields of cryptography and information security. There are known filtering algorithms that can correct for simple statistics but introduce problems in higher order metrics (a problem commonly described as resilience). The comprehensive testing performed ensures that this does not happen with our proposal, improving on the unpredictability of simple (and otherwise unsuitable in practice) generators by virtue of its highly nonlinear design.
Perhaps, the best known algorithm that employs random s-boxes is the RC4 stream cipher, which showed some problems in recent years [
20,
21,
22] in terms of certain statistical biases. Our proposal differs from RC4 in several ways, mainly in its use of four
s-boxes that, once constructed, do not evolve with further filtering, unlike in RC4 that employs a single
s-box that is constantly evolving. Furthermore, the output sequence (
keystream) generated by RC4 is directly sourced from its s-box values, while our proposal filters an external sequence and its output is not the direct result of any of the four s-boxes. Also, its internal structure is very different to RC4, with different operations and s-box implementation, wider data paths, and additional registers and variables.
S-boxes and their applications are a current and very active field of research, comprising an abundant body of related work, from which we can highlight the following research:
Regarding pseudo randomness, chaotic systems, and the construction of s-boxes, Özkaynak [
23] has studied the relevance of chaotic systems on the construction of s-boxes, proposing with Tanyildizi [
24] an s-box construction method based on one-dimensional chaotic maps. Hussain et al. [
25] designed an alternative s-box for the Advanced Encryption Standard [
26] that is constructed from a chaotic logistic map. Lu et al. [
27] proposed an algorithm for the construction of s-boxes based on a new compound chaotic system, together with an efficient image encryption scheme based on the LSS chaotic map [
28]. Wang et al. [
29] proposed a chaotic s-box construction method based on a memorable simulated annealing algorithm. Jiang et al. [
30] created an s-box with excellent properties based on chaos theory and bent functions. Lambi [
31] applied a discrete-space chaotic map to s-box design. Zhou et al. [
32] proposed a chaos-based random s-box generation algorithm based on a 2D mixed pseudo random coupling PS map lattice.
S-boxes are also frequently linked to the subject of image encryption, with Yang et al. [
33] designing a 2D multiple collapse chaotic map with the aim of deriving an s-box and diffusion map that improve efficiency and security. Haq et al. [
34] proposed a
s-box that is employed in color image encryption, improving statistical confusion. Zhang [
35] studied a fast image cryptosystem based on a piecewise linear chaotic map and a cubic s-box, and Wang et al. [
36] analyzed image encryption based on s-boxes constructed upon a chaotic system without equilibrium.
Machine learning is an active field of research, with applications to s-boxes. More specifically, Idris et al. [
37] studied the prediction of active s-boxes on reduced Generalized Feistel Ciphers employing deep learning techniques. Among others, Zu et al. [
38], Kim et al. [
39], Mishra et al. [
40], and Bolufé-Röhler et al. [
41] also applied deep learning to s-box cryptoanalysis, design, and optimization in different types of ciphers.
This paper is divided as follows:
Section 2 introduces the concepts required to understand the specific characteristics of the pseudo random generators employed to generate the sequences to be filtered.
Section 3 describes the design of the filter, including the initialization and iteration (filtering) phases, and provides information regarding the motivation for such design.
Section 4 details the testing results and procedures in terms of randomness and performance. Finally, some conclusions are given in
Section 5.
2. Preliminaries
In the following, we detail the main characteristics of the three PRNGs that we tested with our proposed filter.
2.1. Linear-Feedback Shift Registers
Sequences generated by Feedback Shift Registers are well known since the beginning of electronics and are commonly employed in many disciplines, so there exists abundant literature regarding the subject [
19,
42,
43,
44]. We can identify two components in this type of generators: a shift register and a feedback function.
A Feedback Shift Register (FSR) is composed of an n-bit register, in which a sequential ordering of the bits was established, obtaining a structure that is similar to a FIFO (first in, first out) queue: when a new bit is introduced from the left to become the most significant bit, the remaining bits are shifted one position to the right and the least significant bit is extracted from the register as output. Also, the new bit that is introduced from the left is obtained as the result of a feedback function that takes the current state of the register as input. In this way, starting from an initial register value that acts as the seed and iterating the feedback process, each successive extracted bit conforms the output binary sequence.
The FSR generators with best characteristics are those that employ a linear feedback function and are known as Linear Feedback Shift Registers (LFSR). An n-bit LFSR can be characterized by a polynomial of degree in , achieving the highest possible period () when this polynomial is primitive.
Algorithms based on LFSRs are popular for generating pseudo random sequences since they present the following desirable characteristics:
They can be easily analyzed as they have known mathematical properties.
Their hardware implementation is simple and efficient and, although not ideal, they can also be adequately implemented in software.
As long as the feedback function is chosen from a primitive polynomial, the period of the sequence is guaranteed to be maximum.
The generated sequences have very good randomness properties in terms of basic statistics.
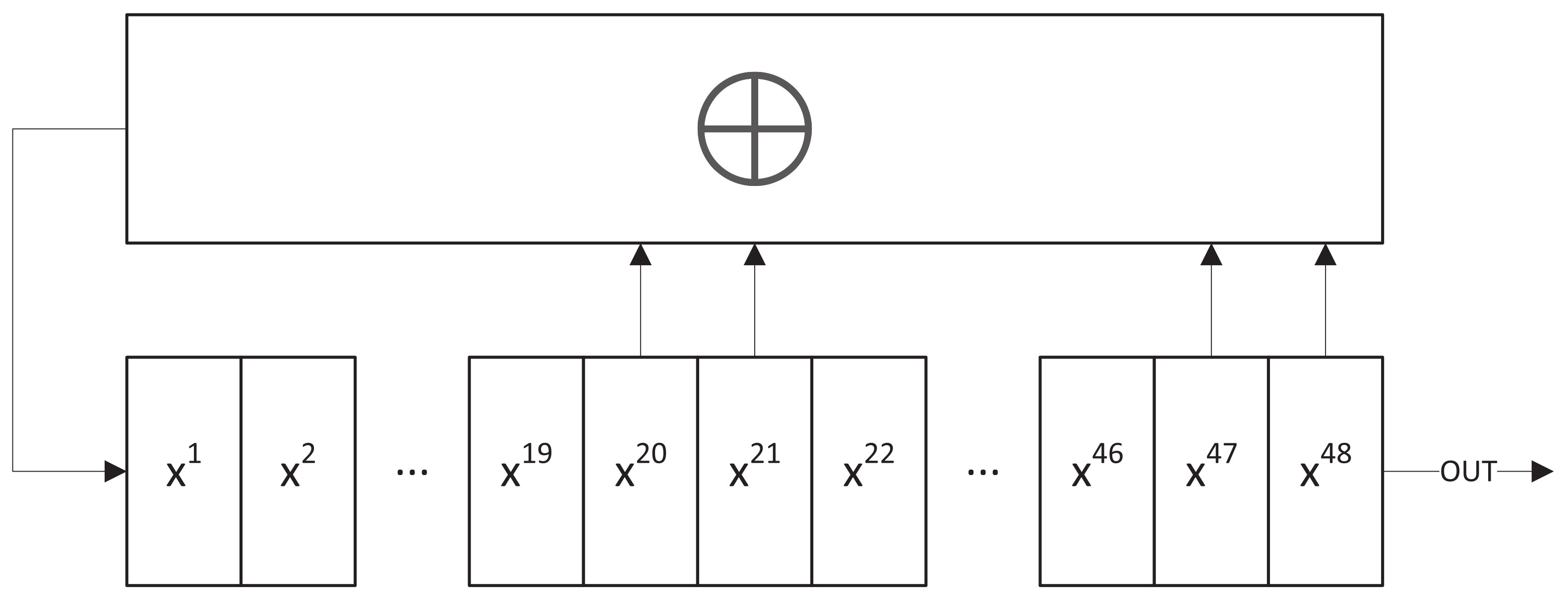
In our tests, we chose a 48-bit LFSR with a feedback function constructed from the following primitive polynomial to obtain a maximal period for the given register length (
).
and we show the corresponding LFSR diagram in
Figure 1.
2.2. Linear Congruential Generators
Introduced by Lehmer [
45] in 1951, this algorithm is widely employed as it is used by default in many programming languages. It is based on the following expression:
where the previous value (
) is multiplied by a coefficient (
a), an offset (
c) is added to it and the result modulo
m constitutes the next value of the sequence (
). The name linear congruential refers to the expression of a line (linear) in modular arithmetic (congruential).
Despite generating sequences that, from the point of view of statistical randomness, are quite good and can have a fairly long period if the parameters are chosen properly, it is unsuitable for use in cryptography or security as it is predictable. Four values of the sequence are enough to be able to determine the seed and the necessary parameters (a, c and m) with which to reproduce the whole sequence. Unfortunately, because it is so popular, it is often used by inexperienced programmers in security tasks, allowing relatively simple attacks.
We chose a common 32-bit LCG implementation in many programming languages and standard libraries, with the following values:
2.3. Simple Counters
A sequence generated by a simple counter is, obviously, neither random nor pseudo random, quite the opposite. Nevertheless, the fact that it is a predictable sequence constitutes a very challenging test for the proposed filter to successfully correct such an unsuitable sequence and provide statistically acceptable results in terms of randomness.
Furthermore, counters have interesting properties when considered as part of PRNGs. They have maximal periods for a given register size ( possible values, being n the number of bits) and provide every possible output value once and only once, exhibiting certain statistical symmetry or output bit balance.
They are also very fast, providing a great baseline to establish maximum filter performance. Moreover, a counter feeding a filter is a very similar construct to that employed in the CTR (counter) mode of block ciphers [
44].
For our testing, we have chosen a simple 32-bit counter (since that is a common integer variable size in modern implementations) that is set to an initial value (seed) and incremented accordingly:
3. Description
Substitution boxes (or s-boxes) can be thought of conceptually as lookup tables that assign an output value for each possible input value. Although they vary in size, usually they are bits (input and output values are a byte) or bits (input values are a byte and output values are a four-byte word). They provide the required nonlinearity characteristics in PRNG or cryptographic algorithms, introducing complexity while maintaining high performance.
There are two main classes regarding their design:
Static or constructed s-boxes. These are chosen carefully to achieve certain characteristics but usually employ some kind of generator function. Their main advantage is that they can achieve optimum values in certain metrics, but a weak point might be found since their data or underlying structure can be analyzed offline.
Dynamic or key-derived s-boxes. Unlike static s-boxes, the results obtained by random s-boxes cannot be guaranteed to optimal in relevant metrics, but the fact they are not based on any known underlying structure can be a definite advantage. Furthermore, when pseudo random s-boxes are dynamically generated and derived from the seed then different s-boxes can be used for each different sequence, possibly providing even better results.
Our filter proposal is based on four
key-derived s-boxes that approximate a complete
substitution box, which would be unfeasible for this application in terms of computational and storage costs. This is a technique based on previous work [
46,
47]. It also includes an additional 64-bit internal state that is sometimes used as two 32-bit registers.
It is composed of two distinct phases: an initialization phase where the different s-boxes are constructed and a filtering phase where the input sequence is transformed into the output sequence. Both of these phases are described in the following.
3.1. Initialization
To construct the set of four s-boxes, the initialization algorithm is based on the multiple states of a single s-box that are concatenated to generate wider s-boxes. We define this s-box as , with denoting the i-th position in S, and 0 being the first position and 255 the last (as per computing standards).
This s-box is evolved during initialization using a set of values called the keystream, or K, that is a vector of 256 byte values that acts as the seed for the filter. This means that there are different filter constructions possible and, since the initialization algorithm is deterministic, for a given seed value of we always obtain the same filter. As before, denotes the i-th position in K, with 0 being the first position and 255 the last.
The filter can be seeded either from an external source or directly from the first 256 bytes of the input sequence before generating any output. The latter technique is employed throughout this paper.
For simplicity, we identify the byte values within K or S as the associated integer numbers.
Initially,
S and integers
h and
l are
Then,
S is evolved in terms of
K following
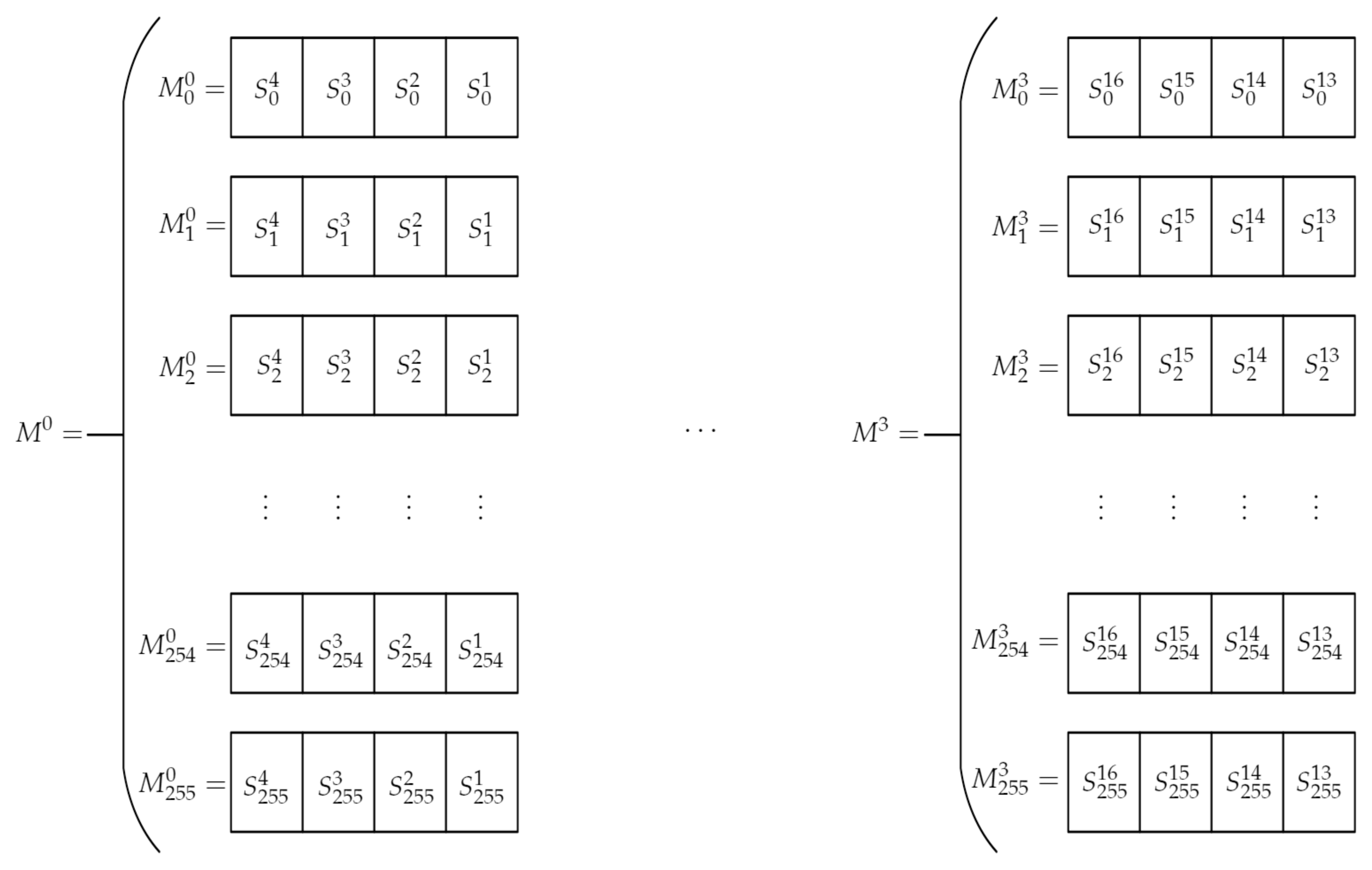
This process is repeated 256 times, swapping and values for to obtain an evolution state of S. We denote these states by a superscript, with n being the n-th evolution state of S and 0 the initial state of S. Therefore denotes the i-th position of the n-th evolution state of S.
We can now define four s-boxes, , , where represents the i-th position in , with 0 being the first position and 255 the last.
Notice that unlike
S or
K, positions in
contain 32-bit values (or four byte words) rather than bytes. These four s-boxes are constructed by the concatenation of four different evolutions of each position of
S:
This process is repeated for
to construct all four
s-boxes and requires the
to
evolution states of
S. It is graphically represented in
Figure 2.
For simplicity, we identify the 32-bit values (or four bytes) within as a vector composed from the four integer numbers associated to these four bytes.
3.2. Filtering
Besides the four s-boxes, the filter also employs a single 64-bit value that can also be addressed as two 32-bit halves, (low 32-bit half) and (high 32-bit half). Furthermore, we can also denote each byte of each half by subscript, with denoting the i-th byte of the high half of T, with 0 being the least significant byte and 3 the most significant, this is and .
Since the filter is designed to process a 32-bit word at a time, we can define
I as the 32-bit word corresponding to the filter input and
O as the 32-bit word corresponding to the filter output each iteration. So, for each 32 bits of input
With denoting the bitwise rotation of T 31 bits to the left, and ⊕ the bitwise exclusive-or between 32-bit operands.
Before filtering starts,
T is initialized with
to
The component architecture for each filter iteration is shown in
Figure 3. The storage requirements of this design are only 4104 bytes (4KiB for the four
s-boxes and 8 bytes for the 64-bit
T register).
3.3. Design Rationale
The proposed design presents several interesting aspects that are motivated in the following.
3.3.1. Data Dependent Construction
This filter follows a seed dependent construction, allowing for many different possible filter constructions. Although this characteristic adds complexity and is not common since most standard sequence filters are fixed or static, it provides better randomness results and broadens the possible applications of the proposed filter not only to simulation, but also to the fields of information security and cryptography. It is, in essence, inspired by the underlying structure of symmetric encryption algorithms such as stream and block ciphers [
19].
3.3.2. Evolving Internal State
Although the construction is seed dependent, once the filter is constructed there is no additional evolution within the sets of s-boxes to . To avoid that repeating bit patterns in the input generate similar output characteristics, the 64-bit register T acts as an evolving internal state that diffuses and decorrelates the input patterns along the output sequence, significantly improving results. As an additional benefit, it helps increase the overall period of the sequence. The fact that this register is 64-bit, while the input and output to the filter are 32-bit words, is also a technique inspired from symmetric ciphers.
3.3.3. Different Operation Types
The filter design involves different types of operations, like the exclusive-or that combines the outputs of different s-boxes, the bitwise rotation of the T register, and the additions to generate the indices in the filter initialization phase. The combination of different types of operations further improves the nonlinearity of the proposed filter.
4. Results
We include analysis of the results of the three generators described (CTR, LCG and LFSR) in terms of randomness and performance. Multiple byte units are expressed following the IEC recommended guidelines (see [
48]).
4.1. Randomness Testing
As shown in
Table 1, we performed initial statistical testing using a custom suite ([
49]) that comprises the following randomness tests extracted from [
19]:
Monobit, related to the frequency of 0 and 1 bits in the sequence.
Serial, frequency analysis of pairs of bits (00, 01, 10, and 11) in the sequence.
Poker8, analyzing the frequency of groups of 8 bits.
Poker16, like Poker8 but analyzing groups of 16bits.
Runs, considering groups of contiguous 0 bits (gaps) and 1 bits (runs).
In this initial suite, a test is considered as passed when its result is below the correction value (with a significance level of ).
Both LFSR and LCG are good PRNG in terms of basic statistics, so they pass all tests regardless of filtering. Although this might lead to the belief that they are excellent PRNG for all applications, they are still predictable and completely linear, therefore unsuitable for cryptography or information security applications and will be deemed not random in the more complex testing suites that follow.
The simple counter (CTR) is a very different case, since it is not a random algorithm, so it performs very poorly in all tests until the proposed filter greatly improves the sequence to much better results.
Further testing is performed with the TestU01 suite, specifically the included BigCrush battery that is comprised of 160 statistics [
17]; this is a much more stringent set of tests and considered among the better tools for randomness testing, since it includes and further expands on the tests proposed by NIST [
15] and those by Marsaglia [
16].
We can see in
Table 2 that all three algorithms fail a certain number of tests, while the proposed filter is able to correct the output and pass all tests; even in the extreme case of the simple counter that failed all tests without filtering.
Another well-regarded randomness testing suite is PractRand (see [
18]). This is a more modern set of tools than TestU01 but also comprehensive while supporting parallelism and iterative testing, therefore making it significantly more convenient and efficient to use.
The results in
Table 3 show that the unfiltered results are poor, with the LFSR generator failing 18 tests out of a total of 130 after testing a sequence of 128 MiB; the LCG generator failing 89 tests out of 103 after testing a sequence of 64 MiB; and the counter failing almost all tests for a testing sequence of 32 MiB. The differing sequence lengths is due to the fact that PractRand performs tests incrementally, presenting results for successive length intervals, and stops testing when results are too poor to continue. This correlates with the results obtained in the previous testing suites.
As before, filtering improves results dramatically, passing all tests for all three algorithms even after testing a full terabyte (1 TiB) sequence, which exemplifies the great qualities of the proposed filter even for longer sequences, being capable of significantly extending the period of the original pseudo random sequences.
4.2. Performance
We include performance data for all three PRNG algorithms, both unfiltered and processed with the proposed filter. These performance values were taken as the minimum value of 10 runs generating a 10 GiB sequence, to minimize system variability; and were performed on a Windows 10 64 bit computer with an Intel Core i7-5960X 3.5 GHz CPU and 32 GB of RAM. The implementation was in pure C programming language over a single computing thread.
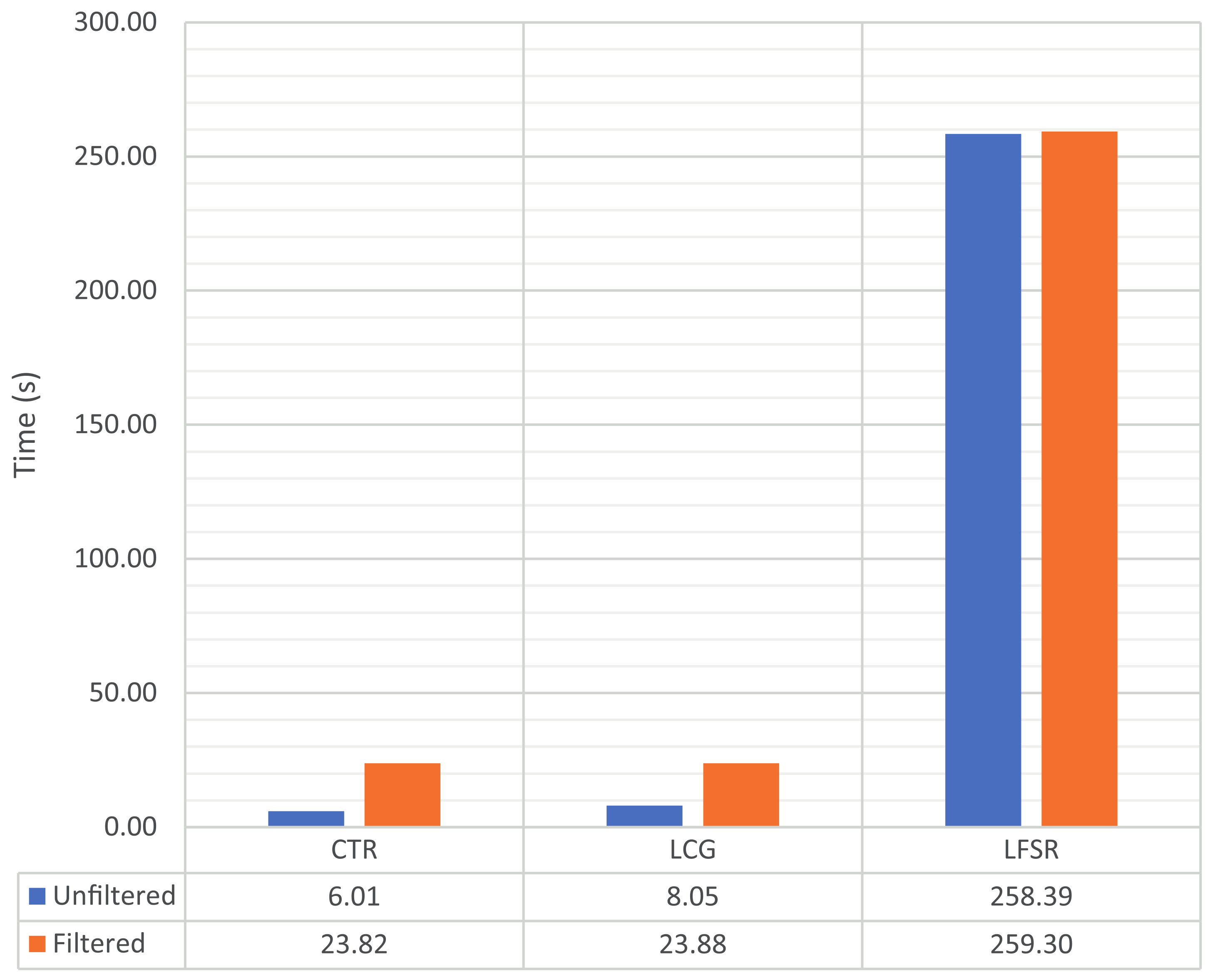
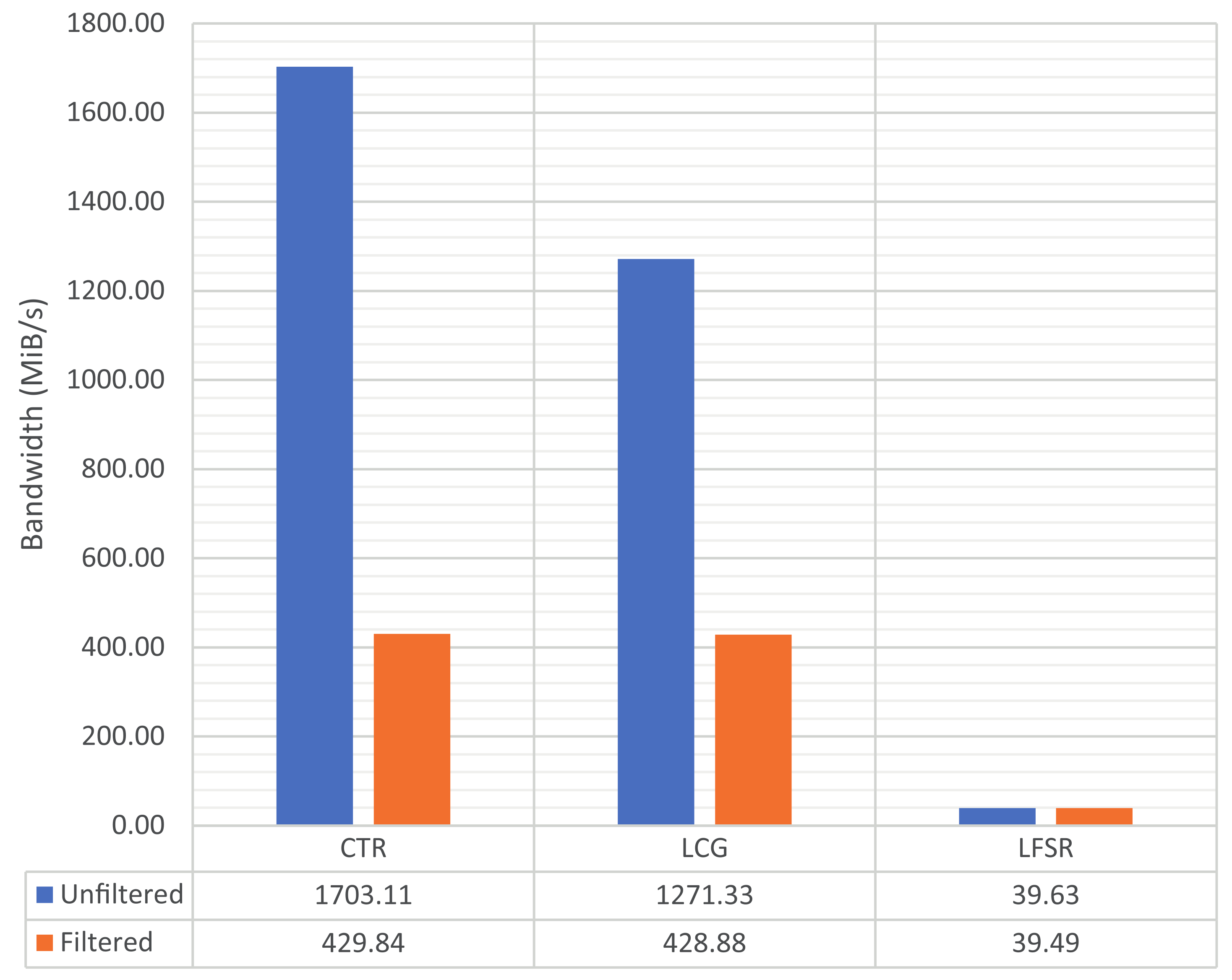
Figure 4 shows the time taken for all three PRNG to generate a sequence of the aforementioned length (10 GiB) with and without filtering, while
Figure 5 presents the real-time bandwidth performance of each algorithm with and without filtering.
To properly interpret the performance results from
Figure 4 and
Figure 5, we must consider the significance of each of the tested PRNG algorithms.
Taking into account the randomness of the sequences generated, a counter (CTR in our results) is not really a pseudo random generator since its sequences are always increasing values, and therefore easily predictable, but it is used here as a benchmark for the filtering capabilities of our proposal, that appear to be excellent since even a simple counter sequence passes all randomness tests after proper filtering. A similar occurrence happens with the linear congruential generator (LCG in our results), which is a well-known and popular PRNG algorithm for its simplicity and efficiency and was therefore included as the default basic PRNG in many programming languages, but it is predictable and will be detected as nonrandom in any tests other than the most basic. Linear feedback shift registers generators (LFSR in our results), albeit still simple algorithms, introduce a bit more complexity and produce much higher quality output sequences in terms of statistical randomness. Nevertheless, LFSRs have a very low linear complexity and are easily predictable employing the Berlekamp–Massey algorithm (see [
50]), failing in more advanced randomness tests.
The perspective of time complexity regarding each algorithm is also important. The CTR algorithm is just a simple increment instruction over a CPU register, so it is extremely fast and mostly limited by memory bandwidth, procedure call overhead, etc. The LCG algorithm is a bit slower since it requires and addition, a multiplication and a modulo operation per iteration, with most implementations choosing values such that performance is maximized while maintaining a good enough period; such is the case of the LCG tested here. Traditionally, LFSR generators were chosen for their performance and simplicity of implementation in hardware but are less ideally suited for software implementation in modern CPUs since they are oriented to single bit manipulation, although this can be optimized employing alternative implementations, like the Galois form (see [
51]).
In terms of the possible applications of these algorithms, an unfiltered CTR is not suitable by itself as a PRNG in any meaningful way for any application where randomness is required. An unfiltered LCG is only barely adequate for applications where performance is more important than statistical randomness, but it is a very poor option in any case where the quality of the randomness matters. An unfiltered LFSR is a better option when higher quality statistical randomness is required. It should be remarked that all these algorithms are predictable, and therefore not valid in isolation for applications such as cryptography or security protocols.
The filtering performance of our proposal enables the usage of these simple generators even in stringent application such as information security or cryptographic protocols because it improves randomness and the sequences pass all tests, but also introduces the required nonlinearity so that the filtered generators are no longer predictable.
We can see in
Figure 5 that proposed filter presents excellent performance, achieving almost 430 MiB/s of bandwidth in software when filtering a simple counter. Considering that it entails just a simple increment instruction, this can be taken as the raw real-time performance of the proposed filter. To put this in context, a 1 gigabit network link has a bandwidth of 125 MiB/s. Furthermore, the proposed filter overhead is negligible when applied to proper generators (around
in the case of the LFSR), while being capable of efficiently adding the required complexity to generate properly pseudo random sequences. These performance results are promising, enabling the application of the proposed filter in different computational scenarios.
Since the filtering operation is constant for each iteration, the computational complexity of the proposed algorithm is linear, , with the length of the input sequence.
5. Conclusions
We presented a new random number sequence filter design with interesting applications in many scientific and technical fields, including stochastic simulation. It is also applicable to information security and cryptography, considering that its design was motivated and inspired by many of the techniques employed in symmetric ciphers.
We also analyzed our proposal in terms of randomness and performance, obtaining excellent results. Our design was used to filter the output of different pseudo random generators, and the resulting sequences were then processed with three different statistical suites, including the well regarded TestU01 and PractRand packages. It manages to filter any statistical randomness problems in the input sequence and can even completely correct the many defects found in a nonrandom sequence, like those generated by a simple counter, transforming it into a perfectly usable random number sequence in practice.
Regarding performance, when filtering a simple counter generator, the proposed filter achieves approximately 430 MiB/s of bandwidth. This value can be taken as the nominal performance of the filter since the impact of the counter is minimal. Conversely, when filtering the output from a more complex generator, like the linear feedback shift register instance that was tested, the difference between filtered and unfiltered performance is negligible ( in this case), so the performance impact of using the proposed filter on an existing generator is extremely low.
Since it presents great performance and modest resource consumption, its implementation could be useful in embedded systems or other low power computational scenarios such as transport or digital identity systems, etc., enabling high quality pseudo random sequences and improved security in many of these applications, considering that pseudo random sequences are the basis of many cryptographic primitives such as keystream sequences in Vernam style stream ciphers for encryption or random values in challenge/response schemes for authentication, etc.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}