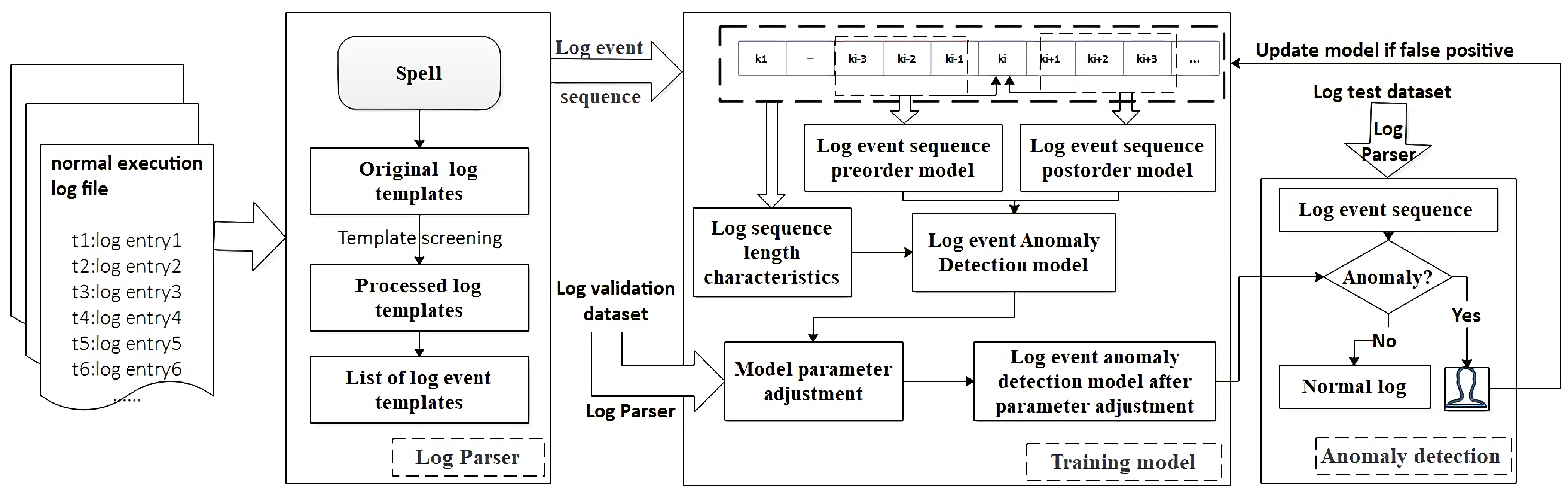
3.1. Log Parser (Spell)
In the log parsing module, we convert the original log into a structured log through the log parser. Log parsing is considered a common preprocessing of unstructured logs and is an important part of most log analysis tasks. There are many parsing methods at present, among which Spell is currently the better one. It is a log parsing method based on the longest common subsequence (LCS). The time complexity of this method for processing each log entry e is close to linear (linearly related to the size of e) and unstructured log messages are parsed into structured log templates. Although Spell is a better log analysis method at present, the log template parsed by this method is not completely correct. If it is used directly to generate log events and compose a log event sequence for anomaly detection, it is difficult to achieve optimal results.
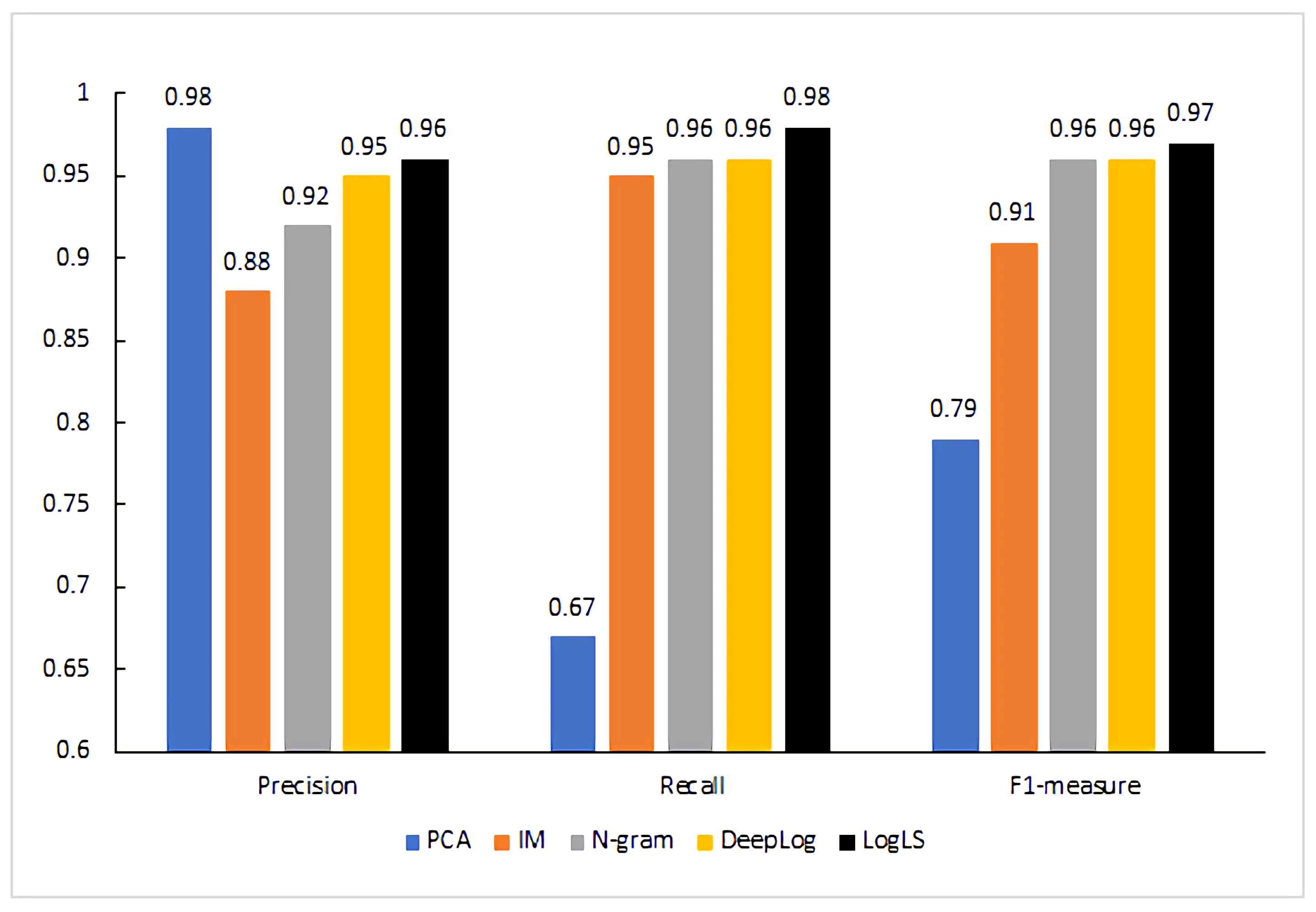
The main dataset of this article is HDFS logs, which can well reflect the effectiveness of the LogLS method.
Table 1 shows the HDFS log template parsed by the Spell method. There are 37 types of HDFS log templates obtained. We can see that some log templates are duplicated. For example, the three log event templates in {E7, E8, E9} are similar, and E8 can contain the other two. If we directly use these templates to generate log sequences, it will seriously affect the effect of log anomaly detection, so this method has room for improvement. This article adds manual deduplication steps to further optimize the effect of log parsing and achieve a higher level of detection.
To improve accuracy, we need to eliminate duplicate data in the log event template obtained by Spell. We do so by selecting a few representative log entries that conform to each event template and check whether they are repeated. If they are repeated, according to the frequency of the log event template, they are unified into the event template with the most frequent occurrences. The log events in
Table 1 are reprocessed, and the results are shown in
Table 2.
In this article, we first use the system log template to divide the unstructured log into several parts (e.g., date, time, content, etc.), and then further extract meaningful information (e.g., events) from these parts. Usually, the event consists of three parts (time stamp, signature and parameters).
Figure 3 illustrates the HDFS log parsing process. The signature attribute is the log template. The specific algorithm is implemented as follows:
The initialization program first defines a log object (LCSObject) such as the log key (LCSseq) and line number list (lineIds), and defines a log object list (LCSMap), which is used to save each log object.
Enter the log file and read it line by line.
Read a line of log, and then traverse the LCSMap to see if there is already an LCSObject in the list that has the same LCSseq (log key). If such an LCSObject exists, add the lineIds of this log to the lineIds of the LCSObject. If not, then generate a new LCSObject to LCSMap.
Keep reading the log until the end.
The template extracted from the log in
Figure 3 is “PacketResponder (*) for block (*) terminating”, where “(*)” represents the variable parameter. If you enter a new log entry “PacketRespo-nder 2 for block blk_2529569087635823495 termina-ting”, Spell’s idea is not to extract the log key directly, but to extract it in comparison. After receiving the newly input log entry, the LCSMap is traversed and an LCSObject whose LCSseq is “PacketResponder 0 for block blk_6137960563260046065 terminating” is found. Then, the LCS is calculated as “PacketResponder for block terminating”. When the length of the sequence is between 1/2 and 1 times the length of the input entry, it is judged that it belongs to the same log key, so it is merged, and the lineIds of this log entry is added to the lineIds attribute of the LCSObject.
Then, the obtained initial log template is manually filtered to obtain the final log event template. The log entries of the entire dataset are then processed to obtain log events of all log entries, which are used to form log event sequences and perform subsequent model training.
3.2. Anomaly Detection
HDFS logs are parsed to obtain the log template, and the event id of each log entry is obtained based on the log template. The value of some parameters can be used as an identifier for a specific execution sequence, such as block_id in HDFS logs. These identifiers can combine log entries together or unwrap log entries generated by concurrent processes to separate a single thread sequence. As shown in
Table 3, the HDFS log event sequence in this article is generated based on block_id.
System log detection will be performed on the log event sequence (shown in
Table 3) obtained by the log parser. Assuming that K = {
,
,
,…,
} is a log event sequence transformed by a log block, each log key represents a log path command at a certain time, and the entire log event sequence reflects the sequential execution path of the log. To detect the entire sequence, it is necessary to check whether each log event is normal. Let
be one of the n K sequences, representing the log event to be detected. The model in DeepLog takes the influence of the forward sequence on
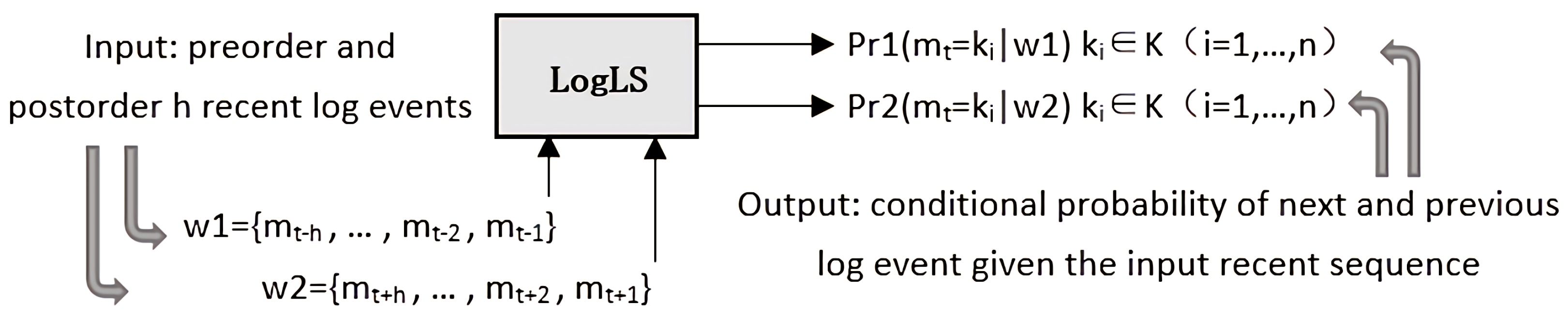
to determine whether it is abnormal. For HDFS logs, this article not only considers the impact of the forward sequence on the next log event but also considers the impact of the backward sequence on the previous log event and combines them to further determine whether the event is abnormal.
Figure 4 summarizes the classification settings. Suppose t is the sequence id of the next log event, w1 is the set of h most recent log events in the previous sequence, and w2 is the set of h most recent log events in the subsequent sequence. In other words, w1 = {
,…,
,
}, w2 = {
,…,
,
}, where each mt is in K, and is the log event from the log entry et. The same log event in w1 and w2 may appear multiple times. The output of the training phase is two conditional probability distribution models Pr1 (
=
|w1) and Pr2 = (
=
|w2) for each
.
To extract context features and potential symmetry information [
28] from sequence relationships, two long short-term memory networks (LSTMs) [
29,
30,
31] are used in LogLS to train the preorder and postorder log event sequences. Each LSTM node has a hidden state
and a cell state
, both of which are passed to the next node to initialize its state. The purpose is to obtain the probability of the current log event
through the preorder and the subsequent log event
through the model and then set a probability limit (parameters g1, g2) to determine whether the current log event is anomalous.
The formula for forward propagation is:
In Formulas (1)–(6), is the input at the current moment, is the state of all cells at the last moment, is the output of different LSTM memory blocks at the last moment, is the state of all cells at the current moment, w is the weight of each gate, and f is the activation function.
The back propagation calculation formula is:
The process of backpropagation is actually the use of chain derivation to solve the gradient of each weight in the entire LSTM. In Formulas (7)–(9), is the gradient of the input gate, is the gradient of the forget gate, and is the gradient of the output gate.
In the training phase, the normally executed log entries are used as the dataset to train the model. The purpose is to allow the model to fully learn the normal execution mode of the system log and avoid misjudgment as much as possible. Suppose a log event sequence is {E22, E5, E5, E5, E11, E9}. Given a window size of 2, the input preorder sequence and output label used to train the model are: {E22, E5→E5}, {E5, E5→E5}, {E5, E5→E11} and {E5, E11→E9}. The input postorder sequence and output label are: {E9, E11→E5}, {E11, E5→E5}, {E5, E5→E5} and {E5, E5→E22}. The LogLS model is used to obtain the probability of the current log event based on the preorder and postorder sequences. The training phase needs to find an appropriate weight distribution so that the final output of the model produces the required labels and outputs them along with the input in the training dataset. In the training process, each input or output uses gradient descent to incrementally update these weights through loss minimization. In LogLS, the input includes h log event windows w1 and w2, and the output is the log event value immediately after w1 and the log event value before w2. We use categorical cross-entropy loss [
32] for training. In the training phase, the length features and latent symmetry information of the log event sequence are counted for later use in the detection phase. After the model is trained, the verification set is used to adjust the parameters of the model to further obtain the optimal anomaly detection model parameter values.
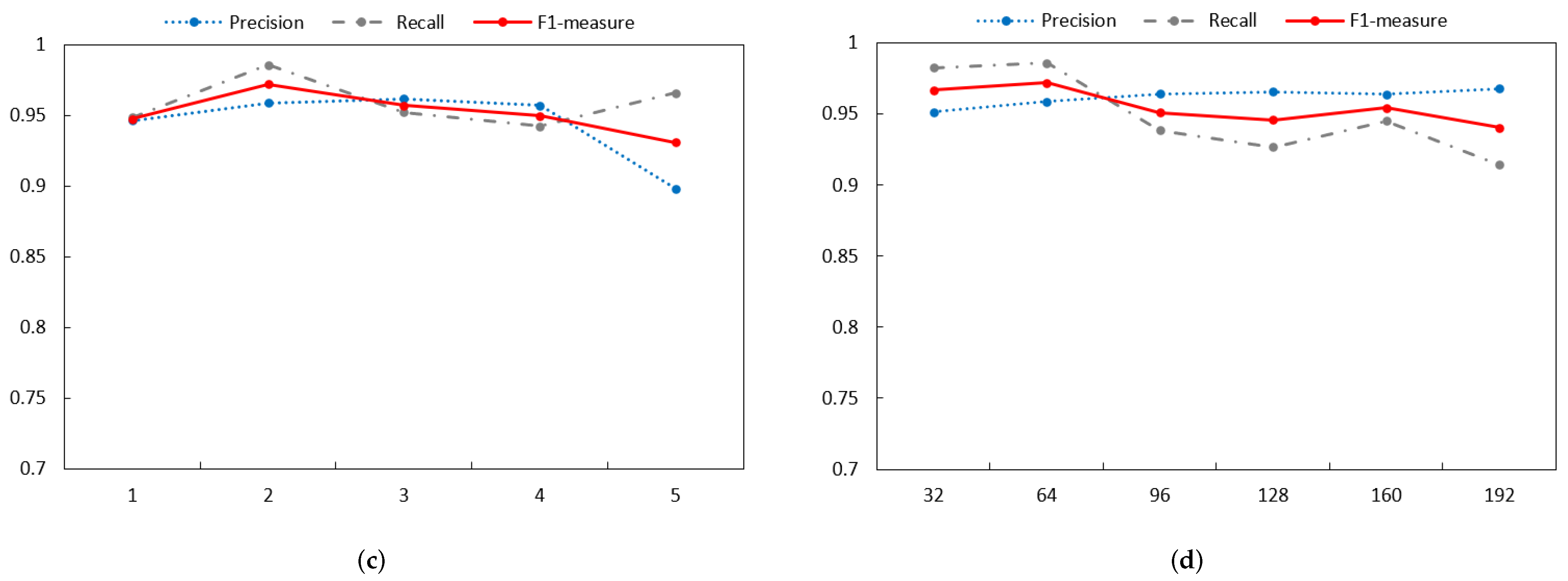
The basic method of the detection phase is the same as the training phase, but a preliminary filtering process is added. For the newly added log event sequence, first a preliminary judgment is made based on the length features obtained in the training phase, and then how to combine the two models for anomaly detection is decided. The length of the tentative log sequence is represented by K, and the following three situations will occur in anomaly detection.
When K < R (R represents the minimum length of the normal log event sequence counted during model training), the sequence is considered an anomaly sequence.
When R < K < 2*W (W represents the final model training window size), only the previous log event sequence model is selected for anomaly detection. This involves a parameter g1 (g1 represents the first g1 digit of the log event probability predicted by the previous log event model).
When K > 2*W, in this case, it is necessary to select the prelog event sequence model and the postlog event sequence model to predict together. It also needs to be subdivided, because the length of the last W of the log sequence cannot be used in the postsequence log event sequence model. Because there is no subsequent input, only the previous log event sequence model is selected at this time. Two parameters g2 and g3 are involved here (g2 represents the first g2 digits of the log event probability predicted according to the previous log event model, and g3 represents the first g3 digits of the log event probability predicted according to the subsequent log event model).
The log event sequence is input to the LogLS model, and the conditional probability of a log event to be detected is obtained. If the probability with the value of the parameters g1, g2, and g3 does not meet the parameter range, it means that it deviates from the normal log sequence and can be regarded as anomalous. Otherwise, other log events are continued to be judged until the entire log event sequence is determined. If no abnormality occurs, the log event sequence is normal.
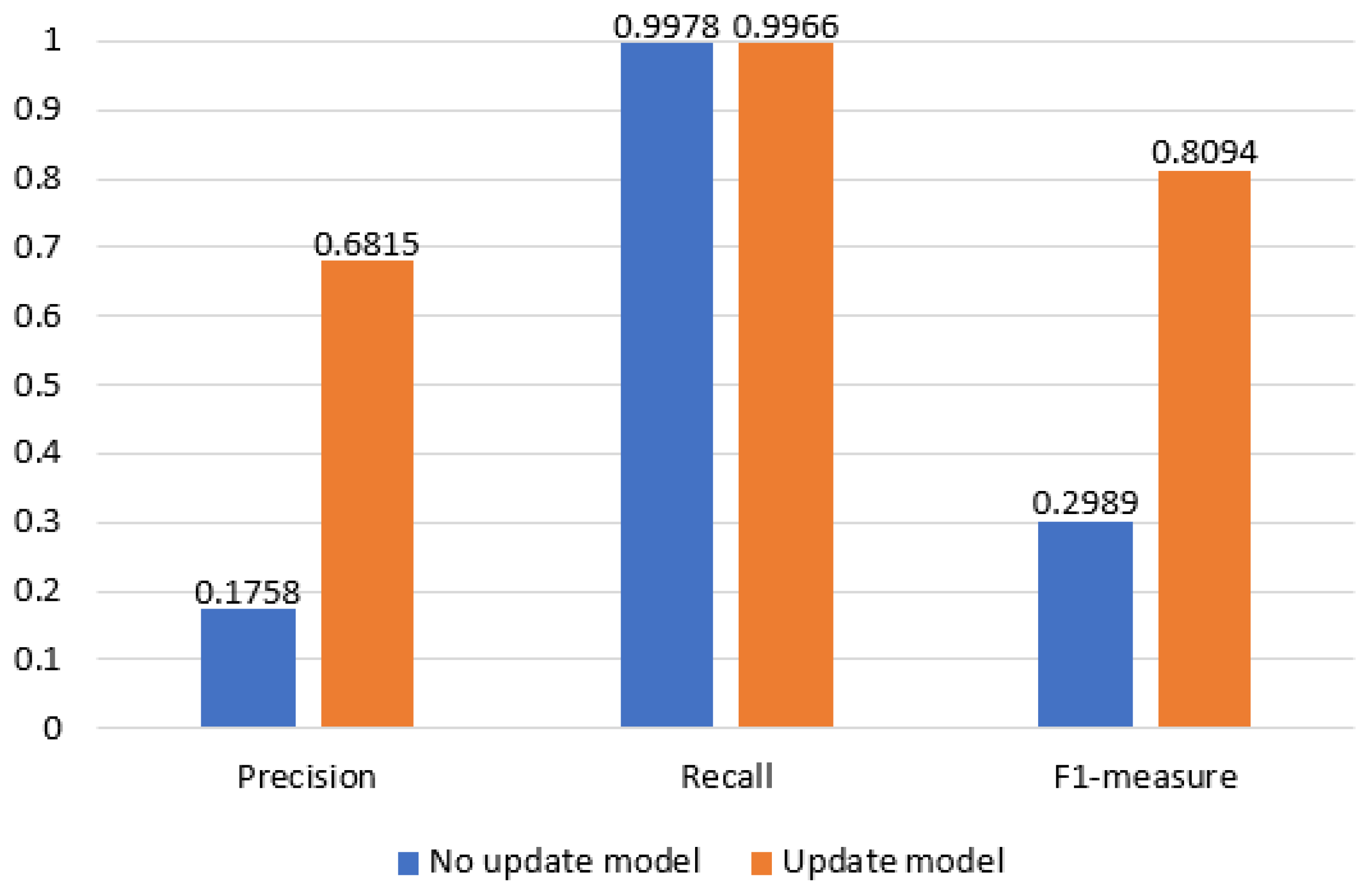
For example, when the input log event sequence is {E22, E5, E5, E5, E11, E9, E11, E23} and the given window size is 3, the sequence length is 8. This situation belongs to the third situation mentioned above, and the {E5, E11} in the sequence are predicted using the preorder and postorder models. First, for {E5}, the input w1 = {E22, E5, E5}, w2 = {E11, E9, E11}. Suppose that the log event probability obtained according to w1 is {E5:0.8, E22:0.2} and that the event probability obtained according to w2 is {E5:0.6, E23:0.2, E9:0.2}. The parameter g2 is 1, and the parameter g3 is 2, indicating that the log event predicted by w1 is E5, and the log time predicted by w2 is E5 or E23. Because the actual log event is E5, it indicates that the current log event is normal. Because the detection result is normal, the detection work continues backward. If the actual log event is not in the two predicted results, it will be judged as an abnormal log event sequence. {E9, E11, E23} in this sequence cannot be predicted using the abnormal log event sequence model obtained in the subsequent sequence because there is no subsequent log sequence of the window size, so at this time, only the previous log event model is used to make the prediction. When the actual log event that needs to be predicted is {E23}, and the input w1 = {E11, E9, E11}, assuming that the event probability obtained according to this sequence {E5:0.6, E23:0.4}, the first g2 predicted result is taken as {E5}, which does not match the actual result. Therefore, it is regarded as an abnormal log event, and the sequence is finally judged as an abnormal sequence. The abnormal result is fed back to the user, and the user can judge whether a misjudgment is made. If a misjudgment occurs, the misjudgment sequence data are recorded, and the model is later adjusted through the update mechanism. If there was no misjudgment, the sequence was directly marked as abnormal.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}